本人参考:斋藤康毅:《深度学习入门1》,《深度学习入门2》。宋老师课程资料。黑马程序员《深度学习从入门到精通》
底层原理:https://blog.csdn.net/2302_80118884/article/details/159921583?spm=1001.2014.3001.5501
神经网络基础与核心组件
1. 神经元模型与前向传播
- 计算公式 : z=w⋅x+bz = w \cdot x + bz=w⋅x+b,继而通过激活值 a=f(z)a = f(z)a=f(z)。
- 全连接层 (FCNN) : 第 NNN 层每个神经元与 N−1N-1N−1 层所有神经元相连。特点是数据以二维形状(Batch, Features)传递。
2. 激活函数 (Activation Function)
- 作用: 引入非线性因素,使网络能拟合复杂函数。
- Sigmoid : 映射至 (0,1)(0, 1)(0,1)。易导致梯度消失,常用于二分类输出层 。

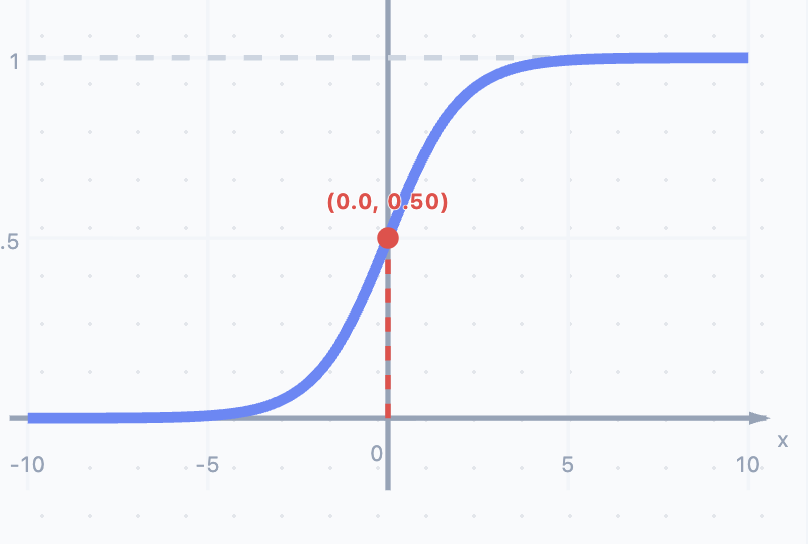
如图 :考虑到sigmoid函数值域在0,1之间,y(1-y)势必小于1。反向传播过程中,若是sigmoid层数量比较多,会造成梯度消失
-
Tanh : 映射至 (−1,1)(-1, 1)(−1,1),以 000 为中心,收敛快于 Sigmoid,用于隐藏层。
-
ReLU (首选) : max(0,x)max(0, x)max(0,x)。计算简便,有效缓解梯度消失,但需注意"神经元死亡"问题。

-
Softmax : 将输出转换为概率分布(和为1),用于多分类输出层。
3. 参数初始化 (Initialization)
- Xavier (Glorot) 初始化 : 保持输入输出方差一致。适用于 Sigmoid / Tanh。
- He (Kaiming) 初始化 : 考虑了 ReLU 零点附近的特性。适用于 ReLU 及其变体。
4. 损失函数 (Loss Function)
- 分类任务 :
nn.CrossEntropyLoss: 多分类(内含 Softmax)。nn.BCELoss: 二分类。
- 回归任务 :
nn.L1Loss(MAE): 对异常值鲁棒。
会导致某些权重值变为0,减少特征。可用于对模型进行轻量化。也可防止过拟合nn.MSELoss(L2): 惩罚大误差。
会导致权重值减小,防止过拟合。nn.SmoothL1Loss: 结合 L1 和 L2,误差小时平滑,误差大时线性。
优化算法与正则化
1. 优化器 (Optimizers)
- SGD: 基础梯度下降。
- Momentum: 引入动量(指数加权平均),加速通过平缓区,减少震荡。
- RMSProp: 自适应学习率,限制梯度平方的累积,适合非稳态目标。
- Adam (全能): 结合 Momentum 和 RMSProp,自适应学习率且稳定。
2. 学习率策略 (LR Scheduler)
- 目的: 前期大学习率快速收敛,后期小学习率避免震荡。
- 常用:
StepLR(等间隔)、MultiStepLR(指定轮次)、ExponentialLR(指数衰减)。
3. 正则化 (防止过拟合)
-
Dropout : 训练时随机让部分神经元失效 (p=0.2∼0.5p=0.2\sim0.5p=0.2∼0.5),测试时全部开启。需配合
model.train()/model.eval()。 -
Batch Normalization (BN):
- 对 Batch 数据进行标准化,解决内部协变量偏移。
- 位置: 通常在"线性层/卷积层"之后,"激活函数"之前。
- 效果: 加速收敛,提升模型稳定性。
PyTorch 框架速查
底层原理:https://blog.csdn.net/2302_80118884/article/details/159921583?spm=1001.2014.3001.5501
1. 张量 (Tensor) 操作
- 创建 :
torch.tensor(data),torch.randn(size),torch.zeros(size)。 - 转换 :
- Tensor 转 NumPy:
t.numpy()(共享内存) 或t.numpy().copy()。 - NumPy 转 Tensor:
torch.from_numpy(arr)。
- Tensor 转 NumPy:
- 形状变换 :
reshape(shape): 改变形状。squeeze()/unsqueeze(dim): 压缩/增加维度为1的轴。transpose(d1, d2)/permute(dims): 交换维度。view(): 仅限连续内存 Tensor,不连续需先调用contiguous()。
- 拼接 :
cat(现有维度拼接),stack(新建维度拼接)。
2. 自动微分 (Autograd)
- 设置
requires_grad=True开启追踪。 loss.backward()计算梯度,x.grad获取梯度值。optimizer.zero_grad()必须在每次反向传播前清空梯度。detach(): 分离张量,使其不再参与梯度计算。
3. 构建模型模板 (nn.Module)
python
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, output_dim)
)
def forward(self, x):
return self.net(x)4. 标准训练循环
optimizer.zero_grad():梯度清零。output = model(input):前向传播。loss = criterion(output, target):计算损失。loss.backward():反向传播(算梯度)。optimizer.step():更新权重。scheduler.step():更新学习率(可选)。
调优 CheckList
- 输入数据是否进行了 StandardScaler 或 MinMaxScaler ?
例如,输入数据单位不同,容易导致不平衡 - 隐藏层是否使用了 ReLU ?
有效防止梯度消失,过拟合 - 是否在全连接层添加了 BatchNorm 和 Dropout?
- 优化器是否首选 Adam?
- 学习率是否设置了衰减策略?
- 训练时是否使用了
model.train(),评估时是否使用了model.eval()和with torch.no_grad():?