一、简介:
做工业质检、医学影像分析的朋友,一定遇到过这些零样本困境:
- 新产品上线,一张缺陷样本都没有,模型直接 "瞎";
- 医疗数据隐私严格,无法获取目标域训练样本,传统方法全失效;
- 不同领域缺陷天差地别:金属划痕、PCB 错位、肿瘤、息肉,一套模型根本通吃不了。
传统异常检测依赖目标域数据,无数据就无法训练;就算用 CLIP 这类大模型,也总盯着 "物体是什么",看不到 "哪里不正常",零样本效果拉胯。
直到这篇arXiv 2026 的《AnomalyCLIP: Object-Agnostic Prompt Learning for Zero-Shot Anomaly Detection 》横空出世,彻底解决零样本异常检测(ZSAD)的泛化难题 ------ 不用目标域数据、不用手工设计百级提示、一套提示通杀工业 + 医疗,在 17 个数据集上屠榜 SOTA。
今天我就把AnomalyCLIP 从痛点→原理→创新→实验→落地讲透,算法工程师、工业视觉、医学 AI 方向都能直接用。
论文地址 :https://arxiv.org/abs/2310.18961
代码地址:https://github.com/zqhang/AnomalyCLIP
二、先搞懂:零样本异常检测的 "死结" 到底在哪?
异常检测(AD)我们很熟:判断图片有没有异常、异常在哪 ,广泛用在工业缺陷、医学病灶检测。
但零样本异常检测(ZSAD) 更极端:
模型只用辅助数据训练,目标域一张样本都不用,直接上线检测。
它面临 3 个死结:
- 无目标数据:隐私、新品、成本导致拿不到训练样本,传统监督 / 无监督全废;
- 域差异巨大:工业缺陷 vs 医学肿瘤,物体外观、背景、异常模式完全不同;
- CLIP 跑偏:CLIP 天生学 "物体语义"(猫 / 狗 / 胶囊),不学 "正常 / 异常",拿来做 ZSAD 直接拉胯。
现有方法的致命缺陷:
- WinCLIP:手工堆几百个提示,繁琐、泛化差、推理慢;
- CoOp/VAND:学物体相关提示,换个物体就崩,抓不住细粒度局部异常;
- 都只做全局特征,忽略像素级异常区域,分割一塌糊涂。
一句话:不会 "无视物体、只看异常",就做不好真正的零样本异常检测。
而 AnomalyCLIP 的核心答案只有一句:
学一套与物体无关的 "正常 / 异常" 文本提示,只看异常模式,不看物体是什么,实现跨域零样本泛化。
三、AnomalyCLIP 核心逻辑:让 CLIP"忘掉物体,只看异常"
先给你一个最直白的直觉:
- 普通 CLIP:看到图片→识别 "这是螺母"→判断类别;
- AnomalyCLIP:看到图片→无视 "是螺母还是器官"→直接判断 "这里正常 / 异常"。
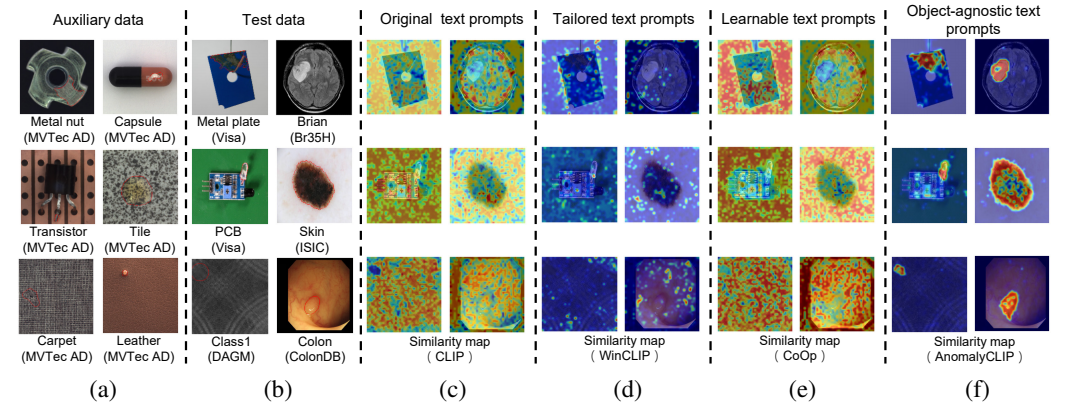
图 1:在(b)测试数据上使用(c)CLIP(Radford 等人,2021)中的原始文本提示、(d)WinCLIP(Jeong 等人,2023)中针对 AD 的定制文本提示、(e)CoOp(Zhou 等人,2022a)中用于通用视觉任务的可学习文本提示以及(f)我们 AnomalyCLIP 中的无对象文本提示的 ZSAD 结果比较。(a)展示了一组可用于学习文本提示的辅助数据。结果是通过测量文本提示嵌入和图像嵌入之间的相似度获得的。在(a)和(b)中,真实异常区域用红色圈出。(c)、(d)和(e)在不同领域中的泛化能力较差,而我们的 AnomalyCLIP 在(f)中能够很好地泛化到来自不同领域的各种类型对象的异常情况。
它的整体设计围绕3 个核心目标:
- 提示与物体无关(Object-Agnostic),只建模通用正常 / 异常;
- 同时学全局(图级有无异常)+ 局部(像素级在哪异常);
- 修正 CLIP 注意力,强化局部细粒度异常,不被物体语义带偏。
整体流程极简:
- 设计物体无关提示模板,只学 normal/abnormal 两种语义;
- 用全局 + 局部联合损失(Glocal Loss) 训练提示;
- 用DPAM 对角突出注意力优化视觉编码器,强化局部异常特征;
- 推理时:算文本 - 图像相似度→输出异常分数 + 异常分割图。
下面逐点硬核拆解。
3.1 核心创新 1:物体无关提示(Object-Agnostic Prompt)------ 真正跨域的关键
这是 AnomalyCLIP最灵魂的创新,也是它能通杀工业 + 医疗的根本。
为什么要 "物体无关"?
划痕、破损、变形、肿瘤、息肉......异常模式是通用的,但物体千差万别。如果提示里带物体名(a photo of a damaged nut),换个物体(pill、brain)直接失效。
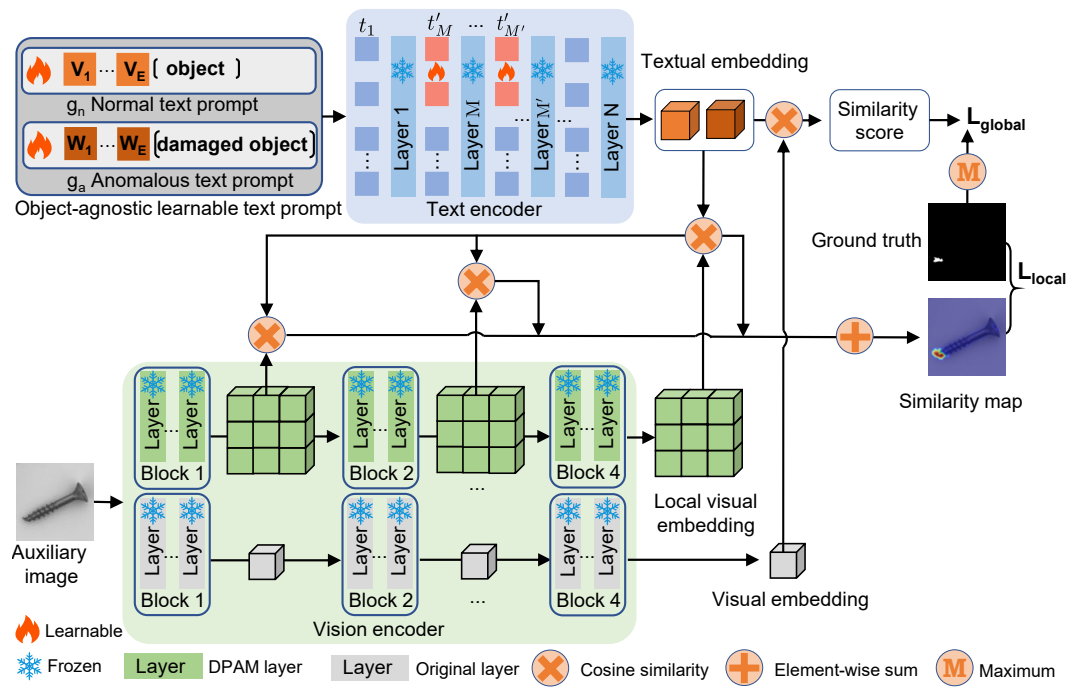
图 2:AnomalyCLIP 概览。为了将 CLIP 应用于零样本异常检测(ZSAD),AnomalyCLIP 引入了与对象无关的文本提示模板,以捕获与对象语义无关的通用正常性和异常性。然后,我们引入全局和局部上下文优化,将全局和细粒度的异常语义纳入与对象无关的文本提示学习中。最后,通过文本提示调优和 DPAM,使 CLIP 的文本和局部视觉空间中的提示学习成为可能。
AnomalyCLIP 的提示设计
它把提示分成正常 / 异常两类,彻底删掉物体类别名,只保留 object:
正常提示:gn=V1V2...VEobjectg_{n}=V1V2...VE objectgn=V1V2...VEobject
异常提示:ga=W1W2...WEdamagedobjectg_{a}=W1W2...WE damaged objectga=W1W2...WEdamagedobject
对比一下:
| 方法 | 提示形式 | 泛化能力 |
|---|---|---|
| CLIP | a photo of a cls | 极低 |
| WinCLIP | 手工缺陷提示 | 低 |
| CoOp | 可学习 + cls | 中 |
| AnomalyCLIP | 可学习 + damaged + object | 极高(跨域) |
效果:
训练时用工业数据,推理直接杀到医疗影像,肿瘤、息肉、结节全能检,一套提示走天下。
3.2 核心创新 2:全局 + 局部联合优化(Glocal Context Optimization)
CLIP 原本只做图级分类 ,异常检测需要图级检测 + 像素级分割 。
AnomalyCLIP 提出联合损失 ,同时搞定两个任务:
Ltotal=Lglobal+λ∑Ml∈MLlocalMl \mathcal{L}{total} = \mathcal{L}{global} + \lambda \sum_{M_l \in \mathcal{M}} \mathcal{L}_{local}^{M_l} Ltotal=Lglobal+λMl∈M∑LlocalMl
-
λ=4\lambda = 4λ=4(论文默认)
-
同时优化图像级检测与像素级分割
① 全局损失 LglobalL_{global}Lglobal(图像级)
Lglobal=−∑iyilogP(ga,fi)+(1−yi)logP(gn,fi) \mathcal{L}{global} = -\sum{i} y_i \log P(g_a, f_i) + (1-y_i)\log P(g_n, f_i) Lglobal=−i∑yilogP(ga,fi)+(1−yi)logP(gn,fi) -
用交叉熵,对齐文本嵌入 ↔ 全局图像嵌入;
-
让模型学会:这张图整体是正常还是异常。
② 局部损失 L_local(像素级)
异常往往是小区域、细粒度 ,必须做像素级监督:
Llocal=Focal(⋅)+Dice(⋅) \mathcal{L}_{local} = \text{Focal}(\cdot) + \text{Dice}(\cdot) Llocal=Focal(⋅)+Dice(⋅)
- 上采样局部 patch 特征,得到逐点异常概率;
- 用Focal Loss解决正负样本极度不平衡(异常区域通常很小);
- 用Dice Loss强化分割重叠度,精准定位异常边缘。
为什么这样设计?
- 只全局:能判断有无异常,不知道在哪;
- 只局部:能定位,容易误检噪声;
- 联合优化:有无 + 定位一起学,检测 + 分割双 SOTA。
3.3 核心创新 3:DPAM 对角突出注意力(Diagonally Prominent Attention Map)
CLIP 的视觉编码器有个大毛病:
自注意力总盯着物体语义 token,忽略局部异常细节,导致分割模糊、定位不准。
如图所示:原始 Q-K 注意力会被少数物体 token 带偏,注意力呈条状,局部特征被破坏,分割模糊、漏检小缺陷。
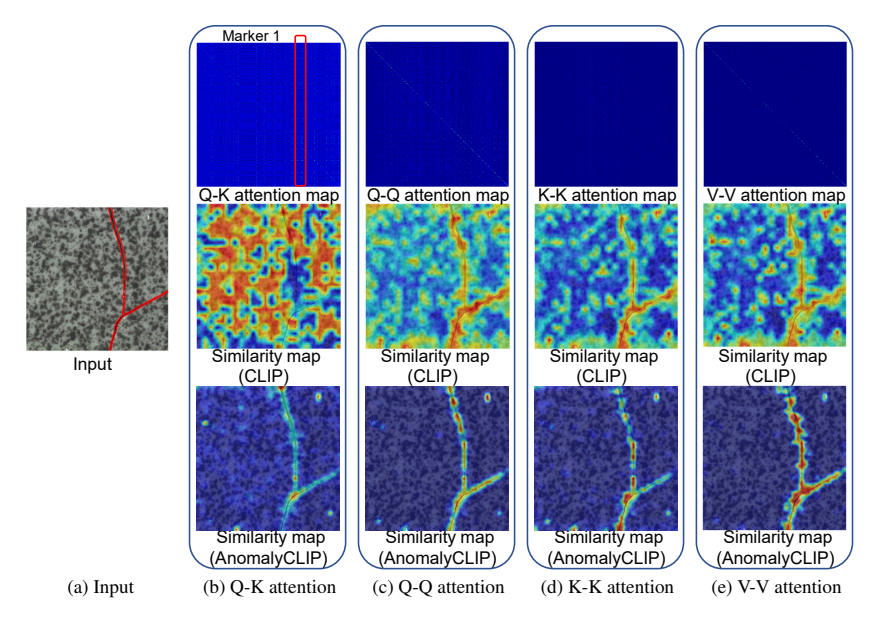
图 3:DPAM 可视化。
DPAM 怎么做?
注意力权重:
aijvv=exp(vivj⊤D) a_{ij}^{vv} = \exp\left(\frac{v_i v_j^\top}{\sqrt{D}}\right) aijvv=exp(D vivj⊤)
直接把 CLIP 的Q-K 自注意力 替换成对角突出的自注意力,支持三种模式:
- Q-Q、K-K、V-V(论文默认 V-V 效果最好)
核心思想:
让每个位置更多关注自己,减少跨位置干扰,保留细粒度局部异常语义。
效果:
- 注意力图呈强对角分布;
- 异常分割边缘更准、小缺陷不漏检;
- 视觉编码器全程冻结,只改注意力,训练极快、超稳。
3.4 核心创新 4:文本空间精调(Textual Space Refinement)
为了让文本嵌入更区分 "正常 / 异常",AnomalyCLIP 在文本编码器里插入可学习 token:
- 替换文本编码器前 N 层的前缀 token 为可学习向量;
- 逐层精调文本空间,强化正常 / 异常的判别性;
- 参数量极小,只训提示和少量 token,CLIP 主体冻结。
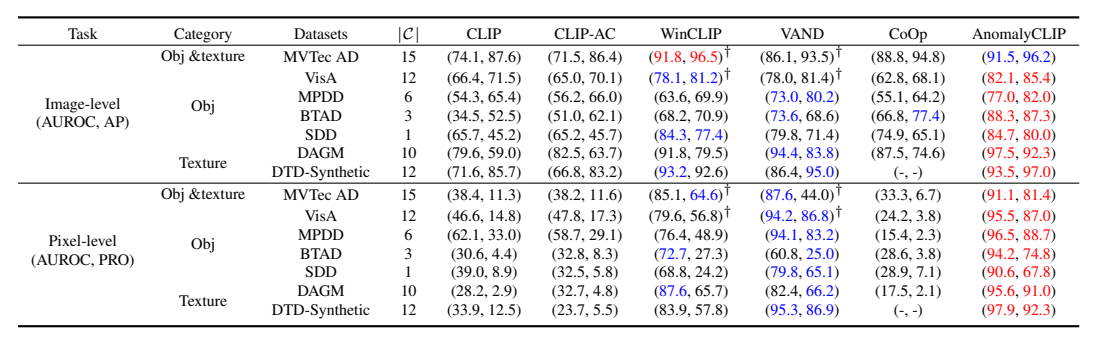
表 1:ZSAD 在工业领域的性能对比。表现最佳的项目以红色突出显示,次优的项目以蓝色突出显示。t 表示源自原始论文的结果。
四、训练 & 推理流程(代码级)
4.1 训练流程
- 加载 CLIP(ViT-L/14@336px)
- 冻结图像编码器、文本编码器
- 初始化物体无关提示
- 构建 Glocal Loss
- 开启 DPAM(V-V)
- 插入文本精调 token
- 在 MVTec AD/VisA 上训练
- 保存提示参数
4.2 推理流程(零样本)
- 图像 → CLIP 视觉编码器 → 全局特征 + 局部 Patch 特征
- 计算相似度:
- 图像级:
score = cosine(vis_feat, g_a) - 像素级:逐 Patch 计算相似度
- 图像级:
- 异常图 = 上采样 + 高斯平滑
- 输出:异常分数 + 异常分割图
五、实验结果|17 数据集全面屠榜
5.1 工业数据集(MVTec AD)
- 图像级 AUROC:91.5%
- 像素级 AUROC:91.1%
- PRO:81.4%
5.2 医疗数据集(零样本跨域)
训练数据:工业 MVTec AD
测试数据:医疗影像
- HeadCT(脑肿瘤):93.4%
- Br35H(脑肿瘤):94.6%
- ISIC(皮肤癌):89.7%
- 结肠息肉、甲状腺结节全部 SOTA
5.3 消融实验(完整版)
| 配置 | 像素 (AUROC,PRO) | 结论 |
|---|---|---|
| Base | 46.8,15.4 | 基线 |
| +DPAM | 68.4,47.4 | 局部增强 |
| +物体无关提示 | 89.5,81.2 | 性能暴涨 |
| +文本精调 | 91.1,81.4 | 最终 SOTA |
六、核心代码片段(可直接运行)
python
# 物体无关提示模板
normal_prompt = ["{} object" for i in range(8)]
abnormal_prompt = ["{} damaged object" for i in range(8)]
# Glocal Loss
class GlocalLoss(nn.Module):
def __init__(self, lambda_local=4):
super().__init__()
self.global_loss = nn.CrossEntropyLoss()
self.focal = FocalLoss()
self.dice = DiceLoss()
self.lambda_local = lambda_local
def forward(self, global_out, local_out, global_label, mask_label):
l_global = self.global_loss(global_out, global_label)
l_local = self.focal(local_out, mask_label) + self.dice(local_out, mask_label)
return l_global + self.lambda_local * l_local
# DPAM:V-V Self-Attention
def dpam_attention(v):
attn = (v @ v.transpose(-2,-1)) / torch.sqrt(torch.tensor(v.shape[-1]))
attn = attn.softmax(dim=-1)
return attn @ v七、落地部署指南(工业 / 医疗直接用)
7.1 环境配置
- Python 3.8+
- PyTorch 2.0
- OpenCV
- OpenCLIP
7.2 训练步骤
7.3 推理步骤
- 加载模型 + 提示
- 输入任意图片(工业/医疗)
- 输出:是否异常 + 异常位置图
八、AnomalyCLIP vs AnomalyDiffusion|选型指南
| 模型 | 核心能力 | 适用场景 | 数据要求 |
|---|---|---|---|
| AnomalyDiffusion | 小样本缺陷生成 | 缺少缺陷样本 | 少量缺陷 |
| AnomalyCLIP | 零样本检测+分割 | 完全无数据、跨域 | 目标域 0 样本 |
结论:
- 0 样本、跨域、快速上线 → AnomalyCLIP
- 有少量缺陷,想扩充数据 → AnomalyDiffusion
九、总结|AnomalyCLIP 强在哪里
- 物体无关提示:真正实现跨域零样本
- 全局+局部联合学习:检测+分割一步到位
- DPAM 注意力:修复 CLIP 局部特征丢失问题
- 文本空间精调:异常判别性大幅提升
- 17 数据集 SOTA:工业 + 医疗全场景屠榜
一句话总结:
零样本异常检测的本质,不是认识更多物体,而是学会什么是正常、什么是异常。