关键词:eBPF / Perf / 时间序重排 / GoTLS / 单调时间
本文说明 eCapture GoTLS 探针在 Perf 事件路径上,为缓解多 CPU / 合并读序与用户态探针时间序不一致而采用的设计思想、实现要点、验证方式与结论。
PR:https://github.com/gojue/ecapture/pull/978
1. 设计思想
1.1 要解决什么问题
GoTLS 明文事件通过 bpf_perf_event_output 进入 Perf 环形缓冲区,用户态程序通过 perf.Reader 读取。读取顺序由内核调度和用户态读取逻辑共同决定,并不保证 与探针内 bpf_ktime_get_ns() 记录的事件发生时间一致。
如果直接按照读取顺序分发事件,输出的文本、pcap 文件或下游处理逻辑会看到时间错乱或因果颠倒的片段,给问题排查和协议重组带来困难。
1.2 不解决什么问题(边界)
本机制不承诺「同一进程内任意两条事件在输出时间线上严格等于物理发生顺序」。原因在于:重排器采用有界缓冲区加固定滞后窗口的设计,那些严重迟到且时间戳较旧的事件,仍可能出现在已经发出的较新事件之后。
本机制也不替代上层按连接、文件描述符或数据流方向所做的应用层字节流重组。HTTP/1、HTTP/2、gRPC 等协议的重组仍由上层按业务键分桶后自行处理。
简而言之:保证批内有序,而非全局单调。
1.3 核心手段
在内核生成的事件中携带三个稳定的排序键:
- mono_ns :单调纳秒时间戳(与
bpf_ktime_get_ns同源) - emit_cpu:事件输出时的 CPU 编号
- seq:每个 CPU 上独立递增的序号
在用户态分发事件之前,增加一个有界重排步骤:按照 (mono_ns, emit_cpu, seq) 的字典序排序后,再依次交给 Dispatcher。
2. 实现方案(概要)
| 层次 | 内容 |
|---|---|
| eBPF | 在 go_tls_event 结构体中增加 seq 和 emit_cpu 字段;写入事件时填充 bpf_ktime_get_ns()、bpf_get_smp_processor_id() 以及 per-CPU 递增序号 |
| 解码 | GoTLSDataEvent::DecodeFromBytes 保持与 C 结构体布局一致;保留 BpfMonoNs 字段,该字段与线路上 ts_ns 同源,避免后续被墙钟换算覆盖后丢失排序依据 |
| 比较器 | LessGoTLSDataEventByPerfOrder(a, b):优先比较 BpfMonoNs,其次比较 EmitCPU,最后比较 Seq |
| 重排器 | goTLSPerfReorder 维护一个缓冲区,设置滞后窗口(lag,默认 10 毫秒)。当缓冲区内最大单调时间与最小单调时间之差达到 lag 时,将满足 mono_ns ≤ max_mono − lag 的事件划出,排序后作为一批返回。缓冲区过长时触发压力 flush(例如发掉一半)。读取循环退出时调用 flushAll 清空剩余事件 |
| 读循环 | 独立 goroutine 执行:Read → Decode → reorder.push → 对非空 batch 记录 Debug 日志 → 按序 Dispatch |
3. 逻辑说明
3.1 数据流
用户态
内核
uprobe/uretprobe
填充 ts_ns seq emit_cpu 等
bpf_perf_event_output
perf.Reader.Read
Decode GoTLSDataEvent
reorder.push
按 mono cpu seq 排序一批
Dispatcher.Dispatch
3.2 「一批」的定义
一批指的是:某次调用 reorder.push(event) 后,缓冲区满足 flush 条件,重排器将若干事件按 LessGoTLSDataEventByPerfOrder 排序后,一次性连续 Dispatch 出去的那组事件。
触发 flush 的典型条件:
- 基于滞后窗口 :缓冲区中最早与最晚事件的
BpfMonoNs差值达到 lag(默认 10 毫秒)时,将所有满足mono_ns ≤ max_mono − lag的事件划为一批发出,其余事件保留在缓冲区中 - 压力 flush:缓冲区事件数量超过阈值(如 1024)时,排序后发掉一半
- 退出时 flush :读取 Perf 的循环退出时调用
flushAll,将剩余事件全部排序后发出
一批是重排器内部的一次输出动作,不代表一个 TCP 连接、一个 HTTP 请求或其他业务概念。
3.3 批内有序与批间回跳
- 批内顺序 :严格遵循
LessGoTLSDataEventByPerfOrder定义的字典序 - 批间关系 :不保证上一批的
last_mono ≤ 下一批的 first_mono
滞后窗口与迟到事件共同作用下,可能出现跨批的时间戳回跳现象。这属于设计边界,而非缺陷。若业务需要严格全局全序,需采用更大滞后窗口、按序阻塞直至超时等更强策略。
3.4 与墙钟时间的关系
展示或落盘时可能将 ts_ns 转换为墙钟时间,但排序必须以 BpfMonoNs(单调时间)为准 ,不能使用可能被改写后的 Timestamp 字段。
4. 配置说明
重排功能默认关闭,需要显式开启。
| 配置项 | 说明 | 默认值 |
|---|---|---|
--perf-reorder |
是否开启 Perf 事件排序 | false(关闭) |
--perf-reorder-lag-ms |
滞后窗口大小(毫秒) | 10 |
配置示例:
bash
# 开启重排,使用默认滞后窗口 10ms
./ecapture gotls --elfpath=/proc/2998/root/usr/bin/caddy --perf-reorder
# 开启重排,自定义滞后窗口为 20ms
./ecapture gotls --elfpath=/proc/2998/root/usr/bin/caddy --perf-reorder --perf-reorder-lag-ms 20JSON 配置方式:
json
{
"perf_reorder": true,
"perf_reorder_lag_ms": 10
}5. 验证方案
5.1 测试环境
- 测试对象:Nextcloud(网盘)+ Caddy(GoTLS 反向代理)
- 测试操作:上传 1MB 的 pdf、xlsx、docx 文件 → 删除所有文件 → 重复三次
- 选择原因:HTTP/2 多路复用 + 文件传输容易复现 Perf 乱序问题
5.2 验证命令
bash
# 开启重排功能
./ecapture gotls --elfpath=/proc/2998/root/usr/bin/caddy --btf=1 --debug --perf-reorder -m text 2>&1 | tee ./new-ecapture.txt
# 关闭重排功能
./ecapture gotls --elfpath=/proc/2998/root/usr/bin/caddy --btf=1 --debug -m text 2>&1 | tee ./new-ecapture.txt5.3 验证脚本
verify_gotls_reorder_log.py
python
#!/usr/bin/env python3
# Verify GoTLS ordering from eCapture debug logs and compare baseline vs optimized runs.
#
# Metrics:
# - Adjacent descents: count of i with keys[i-1] > keys[i] (rare on raw perf; order is
# already mostly monotone). NOT the same as total disorder.
# - Global inversion pairs: all i<j with keys[i] > keys[j] (O(n^2); capped by _GLOBAL_INV_N_MAX).
#
# Fair A/B (same load, two captures):
# python3 scripts/verify_gotls_reorder_log.py \\
# --baseline baseline.txt --compare optimized.txt
#
# baseline.txt: ecapture gotls ... --debug (no --perf-reorder)
# optimized.txt: ecapture gotls ... --debug --perf-reorder
#
# Single file (legacy):
# python3 scripts/verify_gotls_reorder_log.py capture.txt
from __future__ import annotations
import argparse
import re
import sys
from typing import List, Tuple
RE_BATCH = re.compile(
r".*batch_size=(?P<bs>\d+)\s+"
r"first_emit_cpu=(?P<fcpu>\d+)\s+first_mono_ns=(?P<fmono>\d+)\s+first_seq=(?P<fseq>\d+)\s+"
r"last_emit_cpu=(?P<lcpu>\d+)\s+last_mono_ns=(?P<lmono>\d+)\s+last_seq=(?P<lseq>\d+)"
)
RE_DISPATCH = re.compile(
r"gotls perf dispatch \((?P<label>[^)]+)\)\s+"
r"mono_ns=(?P<mono>\d+)\s+"
r"emit_cpu=(?P<cpu>\d+)\s+"
r"seq=(?P<seq>\d+)"
)
RE_ANSI = re.compile(r"\x1b\[[0-9;]*m")
def strip_ansi(s: str) -> str:
return RE_ANSI.sub("", s)
def key(mono: int, cpu: int, seq: int) -> tuple:
return (mono, cpu, seq)
def parse_batches(lines: List[str]):
batches = []
for i, line in enumerate(lines, 1):
line = strip_ansi(line)
if "gotls reorder: emitting batch" not in line:
continue
m = RE_BATCH.search(line)
if not m:
continue
batches.append(
{
"line": i,
"batch_size": int(m["bs"]),
"first": key(int(m["fmono"]), int(m["fcpu"]), int(m["fseq"])),
"last": key(int(m["lmono"]), int(m["lcpu"]), int(m["lseq"])),
}
)
return batches
def parse_dispatch_by_label(
lines: List[str], want_label: str
) -> Tuple[List[tuple], List[int]]:
keys: List[tuple] = []
line_nums: List[int] = []
for i, line in enumerate(lines, 1):
line = strip_ansi(line)
if "gotls perf dispatch (" not in line:
continue
m = RE_DISPATCH.search(line)
if not m or m.group("label") != want_label:
continue
keys.append(
key(int(m["mono"]), int(m["cpu"]), int(m["seq"]))
)
line_nums.append(i)
return keys, line_nums
def count_violations(keys: List[tuple], line_nums: List[int]):
violations = []
for i in range(1, len(keys)):
if keys[i - 1] > keys[i]:
violations.append(
(line_nums[i - 1], line_nums[i], keys[i - 1], keys[i])
)
return violations
# Max n for O(n^2) global inversion count (adjust if too slow on huge logs).
_GLOBAL_INV_N_MAX = 12_000
def count_global_inversion_pairs(keys: List[tuple]) -> Tuple[int, int]:
"""Count pairs (i, j) with i < j and keys[i] > keys[j] (total inversions vs sorted order).
This can be far larger than *adjacent* descents: one element out of place may create
only one adjacent descent but many global inversion pairs.
Returns (inversion_count, total_pairs) where total_pairs = n*(n-1)//2.
"""
n = len(keys)
if n < 2:
return 0, 0
total_pairs = n * (n - 1) // 2
inv = 0
for i in range(n):
ki = keys[i]
for j in range(i + 1, n):
if ki > keys[j]:
inv += 1
return inv, total_pairs
def analyze_file(path: str, print_batches: bool) -> int:
raw = open(path, encoding="utf-8", errors="replace").read()
lines = raw.splitlines()
batches = parse_batches(lines)
no_reorder_k, no_reorder_ln = parse_dispatch_by_label(lines, "no reorder")
after_k, after_ln = parse_dispatch_by_label(lines, "after reorder")
exit_code = 0
if print_batches and batches:
bad_intra = [b for b in batches if b["first"] > b["last"]]
bad_cross = []
for i in range(1, len(batches)):
prev_last = batches[i - 1]["last"]
cur_first = batches[i]["first"]
if prev_last > cur_first:
bad_cross.append(
(i, batches[i - 1]["line"], batches[i]["line"], prev_last, cur_first)
)
print(f"[reorder batches] parsed {len(batches)} lines")
print(
f" intra-batch (first <= last): {'OK' if not bad_intra else 'FAIL'} ({len(bad_intra)} bad)"
)
for b in bad_intra[:10]:
print(
f" line {b['line']} batch_size={b['batch_size']} first={b['first']} last={b['last']}"
)
print(
f" cross-batch (prev_last <= next_first): "
f"{'OK' if not bad_cross else 'WARN'} ({len(bad_cross)} inversions)"
)
for item in bad_cross[:15]:
idx, la, lb, pl, cf = item
print(
f" between batch idx {idx - 1}->{idx} (lines {la}->{lb}): last={pl} first={cf}"
)
if bad_intra:
exit_code = 1
def report_dispatch(keys: List[tuple], line_nums: List[int], title: str) -> int:
if not keys:
return 0
viol = count_violations(keys, line_nums)
n = len(keys)
adj_pairs = max(1, n - 1)
adj_rate = 100.0 * len(viol) / adj_pairs
print(f"{title} parsed {n} dispatches")
print(
f" adjacent descents (keys[i-1] > keys[i] only): "
f"{'OK' if not viol else 'FAIL vs probe key'} "
f"--- {len(viol)} / {adj_pairs} adjacent pairs ({adj_rate:.4f}%)"
)
print(
" note: raw perf order is already mostly time-ordered; only a few adjacent "
"steps need CPU/interleave fixes, so this count stays small."
)
if n <= _GLOBAL_INV_N_MAX:
g_inv, g_tot = count_global_inversion_pairs(keys)
g_rate = 100.0 * g_inv / g_tot if g_tot else 0.0
print(
f" global inversion pairs (all i<j with keys[i]>keys[j]): "
f"{g_inv} / {g_tot} unordered pairs ({g_rate:.4f}% of all pairs)"
)
print(
" this matches intuition better for 'how messy' the whole stream is "
"(sorted sequence would be 0 / total)."
)
else:
print(
f" global inversion pairs: skipped (n={n} > {_GLOBAL_INV_N_MAX}; "
"would be O(n^2); use a smaller log or raise _GLOBAL_INV_N_MAX)"
)
for la, lb, ka, kb in viol[:15]:
print(f" lines {la}->{lb}: {ka} > {kb}")
if len(viol) > 15:
print(f" ... and {len(viol) - 15} more")
return 1 if viol else 0
if no_reorder_k:
if report_dispatch(
no_reorder_k,
no_reorder_ln,
"[no userland reorder --- raw perf dispatch order]",
):
exit_code = 1
if after_k:
if report_dispatch(
after_k,
after_ln,
"[after userland reorder --- dispatch order]",
):
exit_code = 1
if (
not batches
and not no_reorder_k
and not after_k
):
print(
"no parsable GoTLS ordering lines.\n"
" Need DBG lines:\n"
" gotls perf dispatch (no reorder) mono_ns=... emit_cpu=... seq=...\n"
" and/or gotls perf dispatch (after reorder) ...\n"
" Run: sudo ./ecapture gotls ... --debug [--perf-reorder]"
)
return 1
return exit_code
def compare_files(baseline: str, optimized: str, strict: bool) -> int:
def load_dispatch(path: str, label: str):
lines = open(path, encoding="utf-8", errors="replace").read().splitlines()
keys, lnums = parse_dispatch_by_label(lines, label)
viol = count_violations(keys, lnums)
n = len(keys)
pairs = max(1, n - 1)
rate = 100.0 * len(viol) / pairs
if n <= _GLOBAL_INV_N_MAX:
g_inv, g_tot = count_global_inversion_pairs(keys)
else:
g_inv, g_tot = -1,0
return n, len(viol), rate, g_inv, g_tot
b_n, b_v, b_r, b_gi, b_gt = load_dispatch(baseline, "no reorder")
o_n, o_v, o_r, o_gi, o_gt = load_dispatch(optimized, "after reorder")
print("=== Fair compare (same workload recommended) ===")
print(f"baseline (no --perf-reorder): {baseline}")
print(f" dispatches={b_n} adjacent descents={b_v} rate={b_r:.4f}% of adjacent pairs")
if b_gi >= 0 and b_gt > 0:
print(
f" global inversion pairs={b_gi} / {b_gt} "
f"({100.0 * b_gi / b_gt:.4f}% of all pairs)"
)
print(f"optimized (--perf-reorder): {optimized}")
print(f" dispatches={o_n} adjacent descents={o_v} rate={o_r:.4f}% of adjacent pairs")
if o_gi >= 0 and o_gt > 0:
print(
f" global inversion pairs={o_gi} / {o_gt} "
f"({100.0 * o_gi / o_gt:.4f}% of all pairs)"
)
print("---")
if b_n == 0:
print("ERROR: baseline log has no 'gotls perf dispatch (no reorder)' lines.", file=sys.stderr)
return 2
if o_n == 0:
print(
"ERROR: optimized log has no 'gotls perf dispatch (after reorder)' lines.",
file=sys.stderr,
)
return 2
delta = b_v - o_v
if delta > 0:
print(
f"Conclusion: violations reduced by {delta} (baseline {b_v} → optimized {o_v})."
)
elif delta == 0:
print("Conclusion: same violation count (try longer/heavier load or check logs).")
else:
print(
f"Note: optimized has more violations ({o_v} vs {b_v}); lag reorder can still invert across batches."
)
if strict and o_v >= b_v:
return 1
return 0
def main() -> int:
ap = argparse.ArgumentParser(description="Verify GoTLS perf dispatch ordering from eCapture logs.")
ap.add_argument("logfile", nargs="?", help="single log to analyze")
ap.add_argument("--baseline", metavar="FILE", help="log from run without --perf-reorder")
ap.add_argument("--compare", metavar="FILE", help="log from run with --perf-reorder")
ap.add_argument(
"--strict",
action="store_true",
help="with --baseline/--compare, exit 1 unless optimized violations < baseline",
)
ap.add_argument(
"--no-batch-report",
action="store_true",
help="with single file, skip gotls reorder batch line report",
)
args = ap.parse_args()
if args.baseline and args.compare:
return compare_files(args.baseline, args.compare, args.strict)
if args.logfile:
return analyze_file(args.logfile, print_batches=not args.no_batch_report)
ap.print_help()
return 2
if __name__ == "__main__":
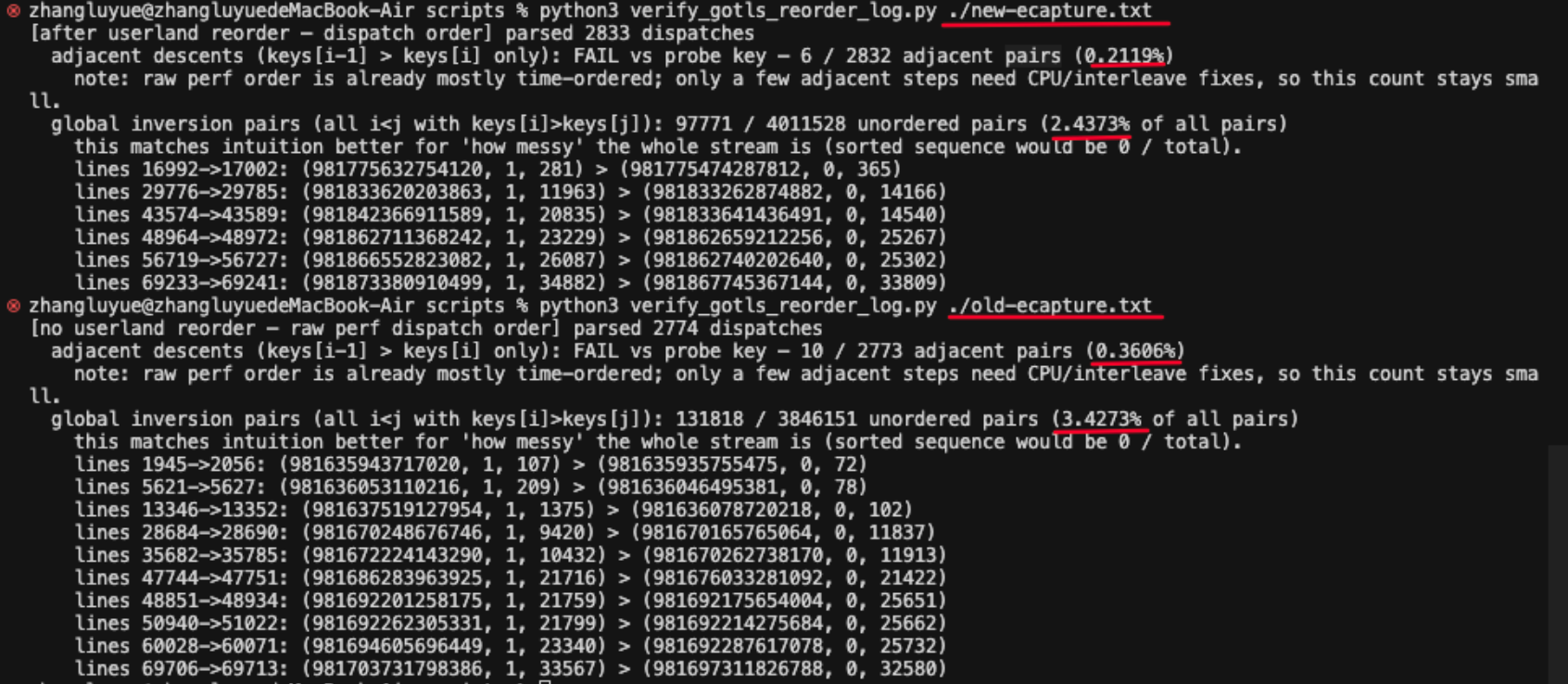
raise SystemExit(main())5.4 测试结果
| 指标 | old(无 reorder) | new(有 reorder) |
|---|---|---|
| dispatch 条数 | 2774 | 2833 |
| 相邻逆序 | 10(0.36%) | 6(0.21%) |
| 全局逆序对占比 | 3.43% | 2.44% |
6. 总结
| 维度 | 内容 |
|---|---|
| 目标 | 缓解 GoTLS Perf 路径上读序与探针单调时间序不一致的问题,提升默认输出的可读性与下游处理的友好度 |
| 手段 | 内核侧为事件附加 (ts_ns, emit_cpu, seq) 三元组,用户态通过滞后有界重排后分发 |
| 保证 | 批内顺序与 LessGoTLSDataEventByPerfOrder 一致;不保证任意两条事件在全时间线上严格有序 |
| 使用建议 | 上层使用方应按连接、方向、数据流等业务键分桶,桶内使用同一套键进行协议级重组。强合规场景需自行评估滞后窗口边界,或通过增大缓冲区、调整策略来满足需求 |
7. 上层应用建议(eCapture 之外)
- 不要假设 eCapture 输出为严格全局全序
- 按业务键分桶 (五元组、pid+fd、读写方向等),桶内按
mono_ns → emit_cpu → seq排序或归并 - READ 与 WRITE 事件使用独立的状态机或缓冲区,避免将双向 TLS 明文混在一起处理
- 若需要可审计的因果顺序 ,应在架构层面显式接受或缓解迟到事件的风险,例如:
- 增大滞后窗口
- 设置超时强制 flush
- 引入端到端的序列号
8. Mac 打包capture踩坑记录
8.1 背景
测试环境为 Linux AMD64,但由于 AWS 上的 Linux 机器无法访问 Docker Hub,且 clang、Go 版本老旧难以升级,因此选择在 Mac 上用 Docker Ubuntu 进行交叉打包。
提示:eCapture 最好在原生 Linux 上打包。Mac 打包会因缺少头文件和 Docker 网络导致各种问题
8.2 搭建 Docker 镜像环境
bash
# 在本地 ecapture 目录下执行
docker run -it \
--name ebpf-builder \
-v $(pwd):/workspace \
--platform linux/amd64 \
--privileged \
ubuntu:22.04 \
bash
# 安装依赖
apt-get update
apt-get install -y --no-install-recommends \
make git wget \
clang-14 llvm-14 \
libbpf-dev \
linux-tools-common linux-tools-generic \
linux-headers-generic \
gcc libelf-dev libz-dev pkg-config
file libpacp-dev
# 创建符号链接
ln -sf /usr/bin/clang-14 /usr/bin/clang
ln -sf /usr/bin/llc-14 /usr/bin/llc
ln -sf /usr/bin/clang++-14 /usr/bin/clang++
# 安装 Go(需匹配 ecapture go.mod 中指定的版本)
wget --no-check-certificate https://go.dev/dl/go1.24.3.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.24.3.linux-amd64.tar.gz
rm go1.24.3.linux-amd64.tar.gz
# 设置环境变量
export PATH=$PATH:/usr/local/go/bin
export GOARCH=amd64
export ARCH=x86_64
# 打包
make all
# 打包后的二进制文件位于bin/ecapture8.2.2 copy core btf文件vmlinux.h
# 在真实的 AMD64 Linux 机器上执行
sudo apt-get install -y linux-tools-common linux-tools-generic bpftool
# 生成 vmlinux.h
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
# 查看文件大小确认生成成功
ls -lh vmlinux.h
wc -l vmlinux.h
# 拷贝放到/kern/bpf/x86/vmlinux.h8.3 遇到的问题及解决方案
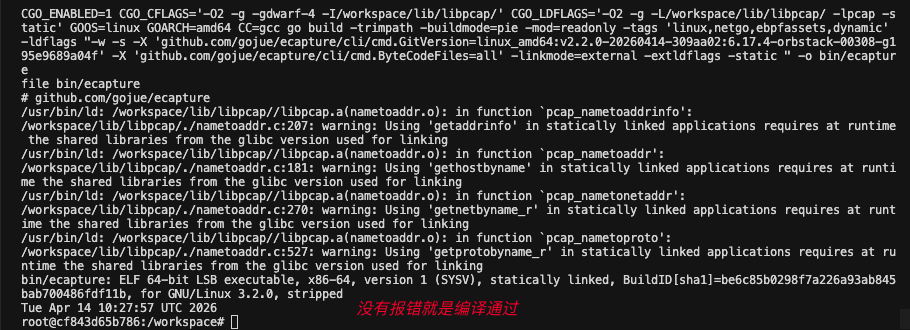
8.3.1 问题一:找不到 Linux 内核头文件(nocore 版本依赖)
现象 :make all 时报错找不到 kconfig.h 等头文件

原因:Mac Orbstack Ubuntu 22.04 使用的是宿主机提供的自定义内核,而非 Ubuntu 官方内核
解决方案 :由于我们使用的是 core 版本(不需要 nocore 的头文件依赖),可以跳过 nocore 编译
8.3.2 问题二:缺少 bison/yacc/flex等libpacp.a的依赖
现象:

解决方案:
bash
apt-get install -y libpcap-dev在搭建镜像环境时已经下载了,正常不会再出现这个问题
8.3.3 问题三:Go bindata 工具缺失
现象 :

解决方案:
我有vpn,在容器外:go install github.com/shuLhan/go-bindata/cmd/go-bindata@latest
容器内因为网络问题会下载失败,也有其他的解决方案。
8.3.4 问题四:go版本不匹配
现象:

解决方案:
卸载go1.20.0,在容器中通过wget下载解压使用ecapture go.mod中的版本,即go1.24.3
在搭建镜像环境时已经下载了,正常不会再出现这个问题;如果下的不对,参考搭建镜像环境中的go下载和配置
8.4 core 与 nocore 版本区别
Core(默认 make ebpf / make all 里的 CO-RE 路径)(core: Compile Once -- Run Everywhere)
- 头文件:用
vmlinux.h(一般由bpftool btf dump ... /sys/kernel/btf/vmlinux生成),配合bpf_core_read.h等。 - 读内核结构:用
BPF_CORE_READ/PT_REGS_*_CORE(见kern/go_argument.h),带 BTF 重定位,加载时按实际运行内核的类型信息做适配。 - 编译:
clang -target bpfel直接产出 CO-RE 用的*_core.o。 - 适用:运行机内核 带 BTF(常见
CONFIG_DEBUG_INFO_BTF=y),希望同一份字节码尽量跨小版本内核跑。
Nocore(make nocore / ebpf_noncore)
- 宏:编译时定义
DNOCORE,kern/ecapture.h走 内核源码/构建目录里的linux/types.h等,不包含vmlinux.h那套 CO-RE 头。 - 读寄存器/结构:直接按头文件里的布局访问,例如
((x)->ax)、PT_REGS_PARM1(x),没有BPF_CORE_READ那层重定位。 - 编译:依赖
KERN_BUILD_PATH/KERN_SRC_PATH下的一串include(Makefile 里那一长串-I),再llc -march=bpf生成*_noncore.o。 - 适用:没有 BTF 或必须和某套固定内核头文件严格对齐的老内核/特殊环境;代价是更绑编译时的内核版本。
8.5 犟种尝试:编译 nocore 版本(失败)
问题的起因是 make all 时报错缺少 kconfig.h(详见 8.3.1)。但即便搞定这个文件,还有一整套头文件依赖等着填坑。
8.5.1 尝试一:官方初始化脚本(AI 推荐的)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/gojue/ecapture/master/builder/init_env.sh)"结果:报错依旧,问题没解决。
8.5.2 尝试二:安装 Ubuntu 内核头文件
apt-get update
apt-get install -y linux-headers-$(uname -r)
结果:失败。原因是 Mac Orbstack Ubuntu 22.04 使用的是宿主机提供的自定义内核,不是 Ubuntu 官方内核,所以找不到对应的头文件包
8.5.3 尝试三:安装 Ubuntu 默认通用头文件
apt-get install -y linux-headers-generic
# 查找头文件位置
find /usr/src -name "kconfig.h" 2>/dev/null
# 拷贝放到/kern/bpf/x86/linux/kconfig.h
# 创建软链到其他问题没用哈8.5.3.1 补上 kconfig.h 依赖的 generated/autoconf.h
mkdir -p ./kern/bpf/x86/generated
# 创建空的 autoconf.h
cat > ./kern/bpf/x86/generated/autoconf.h << 'EOF'
#ifndef __AUTOCONF_H__
#define __AUTOCONF_H__
/* Empty autoconf.h for eBPF compilation */
#define CONFIG_X86_64 1
#define CONFIG_64BIT 1
#endif
EOF8.5.3.2 解决完 kconfig.h,又来 types.h
types.h 背后还挂着一堆头文件依赖。我也想过直接从 Linux 源码里把需要的头文件都拷过来,但考虑到版本不匹配的风险和投入产出比,最终放弃编译 nocore 版本。
结论:在非原生 Linux 环境(尤其是 Mac Docker)上强行编译 nocore 版本,性价比极低。有这功夫,直接打 core 版本就完事了。
8.6 另一种编译 core 版本的方式(未走完)
这趟走到 make lib/libpcap.a 成功了,理论上能走通。但既然 make all 更省事,就不折腾手动了
Bash
make clean
make ebpf # 只生成 bytecode/*_kern_core.o
# 只把 *_core.o 打进 assets(官方 Makefile 的 assets 会强制 ebpf_noncore,所以要手写一步)
go run github.com/shuLhan/go-bindata/cmd/go-bindata \
-ignore '.*_less52\.o' \
-pkg assets -o assets/ebpf_probe.go \
./bytecode/*_core.o
sed -i '1s/^\/\/ Code generated/\/\/go:build ebpfassets\n\/\/ Code generated/' assets/ebpf_probe.go
# 先编 libpcap(与 Makefile 里一致)
make lib/libpcap.a
# 再手动 go build(照 functions.mk 里参数),并指定只用 core字节码:
# BYTECODE_FILES 需与 cli 里约定一致,常见是 core 或 all,看你仓库 cli 实现
CGO_ENABLED=1 \
CGO_CFLAGS='-O2 -g -gdwarf-4 -I$(pwd)/lib/libpcap/' \
CGO_LDFLAGS='-O2 -g -L$(pwd)/lib/libpcap/ -lpcap -static' \
go build -trimpath -buildmode=pie -mod=readonly \
-tags 'linux,netgo,ebpfassets,dynamic' \
-ldflags "-w -s -X 'github.com/gojue/ecapture/cli/cmd.ByteCodeFiles=core' ..." \
-o bin/ecapture ./cli