在云原生网络(如 Cilium、Calico)的演进过程中,veth-pair 一直是连接容器与宿主机的功臣。然而,随着对高性能、低延迟的极致追求,传统 veth 的协议栈开销逐渐成为瓶颈。
Linux 6.7 内核引入了 netkit ------ 这不是一个普通的网卡驱动,它是首个以 eBPF 为核心设计理念的虚拟网络设备。本文将从内核实现、代码开发、部署加载到调试监控,全方位解析 netkit。
1. 为什么 netkit 是 eBPF 的"天生一对"?
传统的 veth 在重定向流量时,往往需要经过繁琐的 skb 转换和协议栈钩子(Hooks)。而 netkit 的设计目标是:将网络决策权完全交给 eBPF。
核心优势:
-
零冗余路径 :netkit 摒弃了传统驱动中一些过时的元数据处理,其
xmit路径直接与 eBPF 程序集成。 -
模式灵活 :支持 L2(以太网帧)和 L3(IP 包)模式。在 L3 模式下,它可以像
tun设备一样工作,但性能更高。 -
元数据透传 :利用
skb->cb或 eBPF 标志位,netkit 可以高效地在不同 Network Namespace 间传递上下文。
内核源码分析:eBPF 如何介入?
在 drivers/net/netkit.c 中,核心函数 netkit_xmit 展示了它与 eBPF 的结合方式:
// 内核源码示意
static netdev_tx_t netkit_xmit(struct sk_buff *skb, struct net_device *dev) {
struct netkit_priv *priv = netdev_priv(dev);
int ret;
// 关键点:直接运行挂载在该设备上的 eBPF 程序
ret = netkit_run_bpf(priv->prog, skb);
switch (ret) {
case NETKIT_PASS:
// 通过内部队列直接发往对端 (peer)
netkit_enqueue_skb(priv->peer, skb);
break;
case NETKIT_DROP:
kfree_skb(skb);
break;
case NETKIT_REDIRECT:
// 执行 BPF 重定向逻辑,实现极速转发
return bpf_redirect_info_make_res(skb);
}
return NETDEV_TX_OK;
}2. 实战:编写内核态 eBPF 程序
我们要实现一个具备"黑名单过滤"和"流量统计"功能的程序。
内核态代码:netkit_kern.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
// 定义一个 Map 用于统计丢包数量
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 1);
__type(key, __u32);
__type(value, __u64);
} drop_stats SEC(".maps");
SEC("netkit/ingress")
int netkit_ingress_prog(struct __sk_buff *skb) {
__u32 key = 0;
// 这里可以添加复杂的逻辑,例如根据 IP 过滤
// 演示:如果返回 NETKIT_DROP,包将被丢弃且不走协议栈
// 返回 NETKIT_PASS,包将送往对端
return NETKIT_PASS;
}
char _license[] SEC("license") = "GPL";3. 实战:编写用户态加载器与交互
用户态程序负责加载内核代码,并读取 Map 数据进行监控。
用户态代码:netkit_user.c(基于 libbpf)
#include <stdio.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <unistd.h>
int main() {
struct bpf_object *obj;
int prog_fd, map_fd;
// 1. 加载 eBPF 字节码
obj = bpf_object__open("netkit_kern.o");
if (bpf_object__load(obj)) return 1;
// 2. 获取 Map 句柄进行后续读取
map_fd = bpf_object__find_map_fd_by_name(obj, "drop_stats");
printf("eBPF 程序已就绪,准备挂载至 netkit 设备...\n");
// 持续观察 Map 数据
while (1) {
__u64 value;
__u32 key = 0;
bpf_map_lookup_elem(map_fd, &key, &value);
printf("当前丢包总数: %llu\n", value);
sleep(2);
}
return 0;
}4. 构建、部署与挂载
编译流程
使用 clang 编译内核态,gcc 编译用户态。
# 编译内核态
clang -O2 -g -target bpf -c netkit_kern.c -o netkit_kern.o
# 编译用户态
gcc netkit_user.c -lbpf -o netkit_loader创建设备与挂载
netkit 的创建方式与 veth 类似,但可以指定 mode。
# 1. 创建一对 netkit 设备 (nk0 和 nk1)
ip link add nk0 type netkit mode blackhole peer name nk1
# 2. 将内核程序挂载到 nk0 的 ingress 路径
# 注意:netkit 使用 bpftool 的 net attach 接口
bpftool net attach netkit_ingress obj netkit_kern.o dev nk0
# 3. 启动设备
ip link set nk0 up
ip link set nk1 up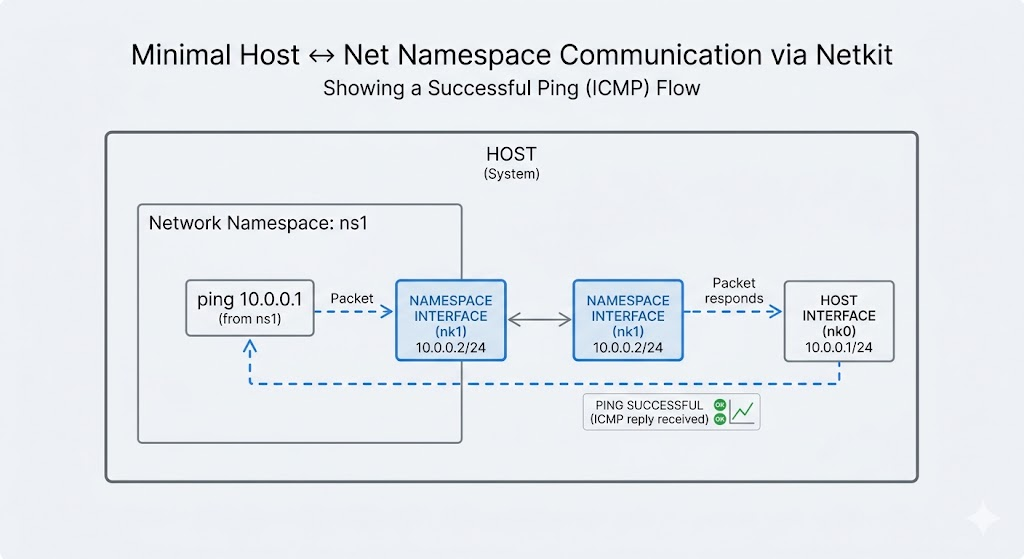
5. 调试:如何监控 netkit 上的 eBPF?
在 CSDN 的实际开发环境中,bpftool 是最权威的调试工具。
检查挂载状态
bpftool net show dev nk0你会看到类似 netkit_ingress id 42 的输出,这证明程序已生效。
实时查看内核日志
在 eBPF 中使用 bpf_printk() 打印调试信息,通过以下命令查看:
bpftool prog tracelogMap 数据
如果你的计数器没有变动,直接 Dump Map 内容验证:
# 假设 Map ID 为 10
bpftool map dump id 106. 总结:netkit 改变了什么?
netkit 的意义在于它重塑了边界 。在传统的网络模型中,驱动程序负责收发包,eBPF 只是旁路的观察者或钩子;而在 netkit 中,eBPF 本身就是驱动控制逻辑的一部分。
对于高性能容器网络(如未来的 Cilium 架构),netkit 提供了比 veth 更短的路径、更少的锁竞争以及更纯粹的 eBPF 编程体验。如果你正在优化容器网络的 QPS,netkit 绝对值得你立刻上手。
