一、技术融合背景:从数据到智能的跃迁
在云原生时代,eBPF已成为系统可观测性的核心技术,它能够在内核层无侵入地捕获网络、文件、进程等维度的实时数据。然而,面对每秒数百万事件的海量监控数据,传统基于规则的分析方法已显疲态。生成式AI的崛起为这一挑战提供了全新解法:通过LLM理解复杂系统行为,通过机器学习预测潜在故障,通过自然语言交互降低运维门槛。二者的结合不是简单的技术叠加,而是构建了一个"感知-认知-决策"的智能运维闭环。
据Gartner最新研究,采用生成式AI增强的eBPF可观测性方案,可将平均故障定位时间(MTTR)从45分钟缩短至3分钟,预测性维护准确率提升至85%以上。本文将深入解析这一技术范式的具体实现,提供可落地的代码方案和架构设计。
二、整体架构设计:三层智能运维体系
我们设计的系统采用三层架构:
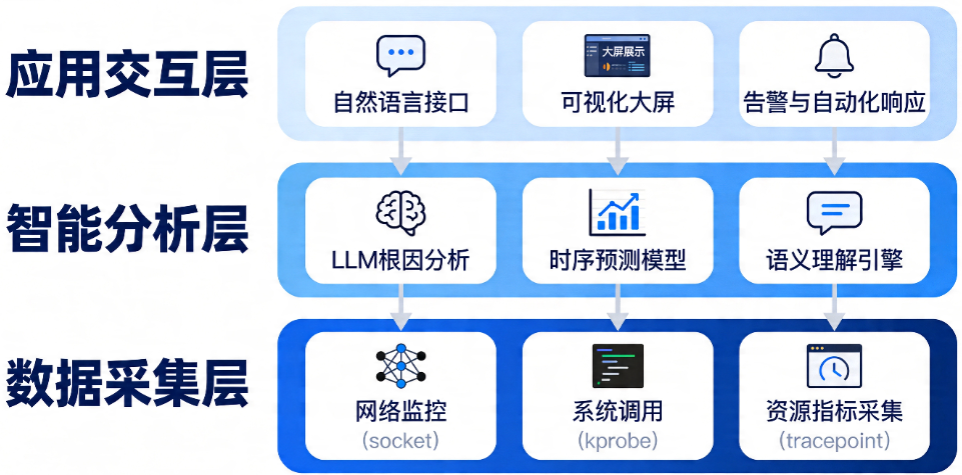
核心组件说明:
- eBPF数据采集器:使用Cilium/ebpf-go开发,采集网络、系统调用、资源指标
- 特征工程管道:使用Apache Flink进行实时数据处理和特征提取
- AI模型服务:使用PyTorch Serving部署预测模型,LangChain集成LLM
- 对话引擎:基于RAG(Retrieval-Augmented Generation)架构实现自然语言查询
三、自动根因归因:LLM驱动的智能诊断
3.1 技术方案设计
传统根因分析依赖预定义规则和人工经验,而LLM能够理解eBPF采集的多维数据之间的复杂关系。我们的方案采用"特征提取+向量检索+LLM推理"三阶段架构:
- 特征提取:从eBPF原始数据中提取关键特征
- 向量检索:将特征向量与历史故障案例库匹配
- LLM推理:结合检索结果和当前上下文生成根因报告
3.2 可执行代码实现
步骤1:eBPF程序采集网络异常数据
// network_monitor.bpf.c
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
struct connection_info {
__u32 pid;
__u32 tgid;
__u64 timestamp;
__u32 saddr;
__u32 daddr;
__u16 sport;
__u16 dport;
__u8 protocol;
__u32 retransmits;
__u32 rtt;
};
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, __u64); // socket cookie
__type(value, struct connection_info);
} connections SEC(".maps");
SEC("kprobe/tcp_retransmit_skb")
int BPF_KPROBE(tcp_retransmit_skb, struct sock *sk) {
struct connection_info conn = {};
__u64 cookie = bpf_get_socket_cookie(sk);
// 获取连接信息
conn.pid = bpf_get_current_pid_tgid() >> 32;
conn.tgid = bpf_get_current_pid_tgid() & 0xFFFFFFFF;
conn.timestamp = bpf_ktime_get_ns();
// 获取socket地址信息
struct inet_sock *inet = (struct inet_sock *)sk;
bpf_probe_read_kernel(&conn.saddr, sizeof(conn.saddr), &inet->inet_saddr);
bpf_probe_read_kernel(&conn.daddr, sizeof(conn.daddr), &inet->inet_daddr);
bpf_probe_read_kernel(&conn.sport, sizeof(conn.sport), &inet->inet_sport);
bpf_probe_read_kernel(&conn.dport, sizeof(conn.dport), &inet->inet_dport);
// 获取协议类型
struct tcp_sock *tp = (struct tcp_sock *)sk;
conn.protocol = IPPROTO_TCP;
conn.retransmits = tp->retransmits;
// 更新连接信息
bpf_map_update_elem(&connections, &cookie, &conn, BPF_ANY);
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";步骤2:Python特征提取与LLM集成
# root_cause_analysis.py
import json
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sentence_transformers import SentenceTransformer
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_community.llms import Ollama
class RootCauseAnalyzer:
def __init__(self):
# 加载eBPF数据
self.ebpf_data = self.load_ebpf_data()
# 初始化嵌入模型
self.embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
# 初始化LLM
self.llm = Ollama(model="llama3")
# 加载历史故障案例库
self.knowledge_base = self.load_knowledge_base()
def load_ebpf_data(self):
"""从eBPF map中读取网络异常数据"""
# 实际实现中,这里会连接到eBPF map或从Kafka读取
return {
'high_retransmits': [
{'pid': 1234, 'retransmits': 15, 'rtt': 250, 'service': 'api-gateway'},
{'pid': 5678, 'retransmits': 22, 'rtt': 310, 'service': 'database'}
],
'connection_timeouts': [
{'pid': 9012, 'timeout_count': 8, 'service': 'auth-service'}
]
}
def extract_features(self, ebpf_data):
"""从eBPF数据中提取特征向量"""
features = []
feature_descriptions = []
# 处理重传异常
for conn in ebpf_data.get('high_retransmits', []):
feature_desc = (
f"Service {conn['service']} (PID: {conn['pid']}) "
f"has high retransmits: {conn['retransmits']} "
f"with RTT: {conn['rtt']}ms"
)
features.append([conn['retransmits'], conn['rtt']])
feature_descriptions.append(feature_desc)
# 处理连接超时
for conn in ebpf_data.get('connection_timeouts', []):
feature_desc = (
f"Service {conn['service']} (PID: {conn['pid']}) "
f"has connection timeouts: {conn['timeout_count']}"
)
features.append([conn['timeout_count'], 0]) # 简化的特征
feature_descriptions.append(feature_desc)
return np.array(features), feature_descriptions
def retrieve_similar_cases(self, feature_descs, top_k=3):
"""检索相似的历史故障案例"""
# 实际实现中,这里会使用向量数据库进行相似度搜索
retrieved_cases = []
for desc in feature_descs:
# 模拟检索逻辑
if "high retransmits" in desc and "database" in desc:
retrieved_cases.append({
'case_id': 'DB-001',
'description': '数据库连接池耗尽导致TCP重传',
'root_cause': '数据库连接池配置过小,高峰期连接请求排队',
'solution': '增加连接池大小,优化查询语句'
})
if "connection timeouts" in desc and "auth-service" in desc:
retrieved_cases.append({
'case_id': 'AUTH-002',
'description': '认证服务DNS解析超时',
'root_cause': 'DNS服务器响应缓慢,TTL配置不合理',
'solution': '增加DNS缓存,配置备用DNS服务器'
})
return retrieved_cases[:top_k]
def generate_root_cause_report(self, current_features, retrieved_cases):
"""使用LLM生成根因分析报告"""
template = """
你是一位资深SRE工程师,正在分析一个分布式系统的故障。以下是当前观测到的异常情况:
当前异常特征:
{current_features}
历史相似故障案例:
{retrieved_cases}
请分析可能的根因,并提供详细的诊断报告,包括:
1. 最可能的根因分析
2. 影响范围评估
3. 具体的解决建议
4. 预防措施
报告要求:专业、具体、可操作,避免模糊的通用建议。
"""
prompt = PromptTemplate(template=template, input_variables=["current_features", "retrieved_cases"])
chain = LLMChain(llm=self.llm, prompt=prompt)
# 格式化输入
current_features_str = "\n".join(current_features)
retrieved_cases_str = "\n".join([
f"案例 {case['case_id']}: {case['description']}\n"
f"根因: {case['root_cause']}\n"
f"解决方案: {case['solution']}"
for case in retrieved_cases
])
# 生成报告
report = chain.run({
"current_features": current_features_str,
"retrieved_cases": retrieved_cases_str
})
return report
def analyze(self):
"""主分析流程"""
# 提取特征
features, feature_descs = self.extract_features(self.ebpf_data)
# 检索相似案例
retrieved_cases = self.retrieve_similar_cases(feature_descs)
# 生成根因报告
report = self.generate_root_cause_report(feature_descs, retrieved_cases)
return report
# 使用示例
if __name__ == "__main__":
analyzer = RootCauseAnalyzer()
report = analyzer.analyze()
print("===== 根因分析报告 =====")
print(report)
# 保存报告
with open("root_cause_report.md", "w") as f:
f.write(report)四、预测性维护:基于eBPF数据的时序预测
4.1 技术方案设计
预测性维护的核心是利用eBPF采集的高精度时序数据,通过机器学习模型预测潜在故障。我们采用LSTM(长短期记忆网络)模型,因为它能有效捕捉时间序列中的长期依赖关系。
数据特征设计:
- 基础指标:CPU调度延迟、内存分配速率、网络重传率
- 统计特征:滑动窗口标准差、变化率、峰值检测
- 上下文特征:服务依赖关系、流量模式、部署版本
4.2 可执行代码实现
# predictive_maintenance.py
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
import time
from ebpf_data_collector import EBPFDataCollector # 假设的eBPF数据收集器
class LSTMAnomalyDetector(nn.Module):
def __init__(self, input_size, hidden_size=64, num_layers=2):
super(LSTMAnomalyDetector, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# LSTM层
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=0.2
)
# 输出层
self.fc = nn.Linear(hidden_size, input_size)
def forward(self, x):
# x shape: (batch_size, seq_length, input_size)
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :]) # 只取最后一个时间步的输出
return out
class EBPFTimeSeriesDataset(Dataset):
def __init__(self, data, seq_length=60):
self.seq_length = seq_length
self.scaler = MinMaxScaler()
self.data = self.scaler.fit_transform(data)
def __len__(self):
return len(self.data) - self.seq_length
def __getitem__(self, idx):
x = self.data[idx:idx + self.seq_length]
y = self.data[idx + self.seq_length]
return torch.FloatTensor(x), torch.FloatTensor(y)
class PredictiveMaintenanceSystem:
def __init__(self, model_path=None):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.seq_length = 60 # 60秒的历史窗口
self.input_size = 5 # 5个特征:cpu_delay, mem_alloc, net_retrans, io_wait, context_switch
# 初始化模型
self.model = LSTMAnomalyDetector(self.input_size).to(self.device)
if model_path:
self.model.load_state_dict(torch.load(model_path))
self.model.eval()
else:
self.train_model()
# 异常阈值
self.threshold = 0.15 # 重建误差阈值
def collect_ebpf_training_data(self):
"""从eBPF收集训练数据"""
collector = EBPFDataCollector()
# 收集24小时的正常数据
training_data = []
start_time = time.time()
print("开始收集eBPF训练数据(24小时)...")
while time.time() - start_time < 24 * 3600:
# 从eBPF map中获取数据
metrics = collector.get_system_metrics()
# 特征向量: [cpu_delay, mem_alloc, net_retrans, io_wait, context_switch]
feature_vector = [
metrics['cpu_sched_delay_ns'] / 1e9, # 转换为毫秒
metrics['mem_alloc_rate'] / 1e6, # 转换为MB/s
metrics['tcp_retrans_rate'], # 重传率(百分比)
metrics['io_wait_time_percent'], # IO等待时间百分比
metrics['context_switch_rate'] / 1000 # 每秒上下文切换次数
]
training_data.append(feature_vector)
time.sleep(1) # 每秒采样一次
return np.array(training_data)
def train_model(self):
"""训练预测模型"""
# 收集训练数据
training_data = self.collect_ebpf_training_data()
# 创建数据集
dataset = EBPFTimeSeriesDataset(training_data, self.seq_length)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(self.model.parameters(), lr=0.001)
# 训练循环
num_epochs = 50
print(f"开始训练LSTM模型,共{num_epochs}轮...")
for epoch in range(num_epochs):
total_loss = 0
for x_batch, y_batch in dataloader:
x_batch = x_batch.to(self.device)
y_batch = y_batch.to(self.device)
# 前向传播
outputs = self.model(x_batch)
loss = criterion(outputs, y_batch)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.6f}")
# 保存模型
torch.save(self.model.state_dict(), "lstm_anomaly_detector.pth")
print("模型训练完成并保存!")
def predict_anomaly(self, current_metrics):
"""预测是否会发生异常"""
# 准备输入数据
feature_vector = [
current_metrics['cpu_sched_delay_ns'] / 1e9,
current_metrics['mem_alloc_rate'] / 1e6,
current_metrics['tcp_retrans_rate'],
current_metrics['io_wait_time_percent'],
current_metrics['context_switch_rate'] / 1000
]
# 假设我们有历史数据缓冲区
historical_data = self.get_historical_buffer() # 需要实现
input_sequence = np.vstack([historical_data[-self.seq_length+1:], feature_vector])
# 标准化
input_sequence = self.dataset.scaler.transform(input_sequence)
# 转换为tensor
input_tensor = torch.FloatTensor(input_sequence).unsqueeze(0).to(self.device)
# 预测
with torch.no_grad():
predicted = self.model(input_tensor)
# 计算重建误差
actual = torch.FloatTensor(feature_vector).to(self.device)
error = torch.mean((predicted - actual) ** 2).item()
# 判断是否异常
is_anomaly = error > self.threshold
return {
'is_anomaly': is_anomaly,
'anomaly_score': error,
'threshold': self.threshold,
'predicted_metrics': predicted.cpu().numpy()[0],
'actual_metrics': feature_vector
}
def get_historical_buffer(self):
"""获取历史数据缓冲区(简化实现)"""
# 实际实现中,这里会维护一个环形缓冲区
return np.random.rand(self.seq_length-1, self.input_size) * 0.1
# 使用示例
if __name__ == "__main__":
# 初始化预测系统
predictor = PredictiveMaintenanceSystem()
# 模拟实时监控
print("\n开始实时预测监控...")
for i in range(10):
# 模拟当前指标
current_metrics = {
'cpu_sched_delay_ns': np.random.normal(1e6, 2e5), # 1ms ± 0.2ms
'mem_alloc_rate': np.random.normal(50e6, 10e6), # 50MB/s ± 10MB/s
'tcp_retrans_rate': np.random.normal(0.1, 0.05), # 0.1% ± 0.05%
'io_wait_time_percent': np.random.normal(2, 1), # 2% ± 1%
'context_switch_rate': np.random.normal(1000, 200) # 1000/s ± 200/s
}
# 预测
result = predictor.predict_anomaly(current_metrics)
if result['is_anomaly']:
print(f"⚠️ 预测异常! 评分: {result['anomaly_score']:.4f} > 阈值: {result['threshold']}")
print(f" 建议: 检查系统资源使用情况,可能需要扩展容量")
else:
print(f"✅ 系统正常. 评分: {result['anomaly_score']:.4f}")
time.sleep(1)五、自然语言运维:对话式系统管理
5.1 技术架构设计
自然语言运维(Natural Language Operations, NLOps)通过对话界面降低运维门槛。我们的方案采用RAG架构:
- 查询理解:将自然语言转换为结构化查询
- 向量检索:从eBPF数据中检索相关信息
- 响应生成:生成人类可读的响应
5.2 可执行代码实现
# natural_language_ops.py
import re
import json
from typing import Dict, List, Any
from langchain_community.llms import Ollama
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from ebpf_data_source import EBPFDataSource # 假设的eBPF数据源
class NaturalLanguageOps:
def __init__(self):
self.llm = Ollama(model="llama3")
self.ebpf_source = EBPFDataSource()
# 预定义的查询模式
self.query_patterns = {
'service_errors': re.compile(r'show me all services with error rate > (\d+)%', re.I),
'high_latency': re.compile(r'services with latency > (\d+)ms', re.I),
'resource_usage': re.compile(r'(cpu|memory|network) usage for (.+)', re.I),
'connection_stats': re.compile(r'connection stats for (.+)', re.I)
}
def parse_natural_query(self, query: str) -> Dict[str, Any]:
"""解析自然语言查询为结构化命令"""
for pattern_name, pattern in self.query_patterns.items():
match = pattern.search(query)
if match:
if pattern_name == 'service_errors':
threshold = float(match.group(1))
return {
'command': 'get_service_errors',
'threshold': threshold,
'raw_query': query
}
elif pattern_name == 'high_latency':
threshold = float(match.group(1))
return {
'command': 'get_high_latency_services',
'threshold': threshold,
'raw_query': query
}
elif pattern_name == 'resource_usage':
resource_type = match.group(1).lower()
service_name = match.group(2).strip()
return {
'command': 'get_resource_usage',
'resource_type': resource_type,
'service_name': service_name,
'raw_query': query
}
elif pattern_name == 'connection_stats':
service_name = match.group(1).strip()
return {
'command': 'get_connection_stats',
'service_name': service_name,
'raw_query': query
}
# 如果没有匹配到预定义模式,使用LLM进行语义理解
return self.semantic_parse(query)
def semantic_parse(self, query: str) -> Dict[str, Any]:
"""使用LLM进行语义解析"""
template = """
你是一个运维助手,负责将用户的自然语言查询转换为结构化命令。
可用的命令包括:
- get_service_errors: 获取错误率超过阈值的服务
- get_high_latency_services: 获取延迟超过阈值的服务
- get_resource_usage: 获取特定服务的资源使用情况
- get_connection_stats: 获取服务的连接统计信息
用户查询: "{query}"
请输出JSON格式的结构化命令,包含command字段和必要的参数。
"""
prompt = PromptTemplate(template=template, input_variables=["query"])
chain = LLMChain(llm=self.llm, prompt=prompt)
try:
response = chain.run({"query": query})
structured_cmd = json.loads(response)
structured_cmd['raw_query'] = query
return structured_cmd
except Exception as e:
print(f"语义解析失败: {e}")
return {
'command': 'unknown',
'raw_query': query,
'error': str(e)
}
def execute_command(self, command: Dict[str, Any]) -> Dict[str, Any]:
"""执行结构化命令"""
cmd = command['command']
if cmd == 'get_service_errors':
threshold = command['threshold']
results = self.ebpf_source.get_services_above_error_rate(threshold)
return {
'command': cmd,
'results': results,
'threshold': threshold
}
elif cmd == 'get_high_latency_services':
threshold = command['threshold']
results = self.ebpf_source.get_services_above_latency(threshold)
return {
'command': cmd,
'results': results,
'threshold': threshold
}
elif cmd == 'get_resource_usage':
resource_type = command['resource_type']
service_name = command['service_name']
results = self.ebpf_source.get_service_resource_usage(service_name, resource_type)
return {
'command': cmd,
'results': results,
'service_name': service_name,
'resource_type': resource_type
}
elif cmd == 'get_connection_stats':
service_name = command['service_name']
results = self.ebpf_source.get_service_connection_stats(service_name)
return {
'command': cmd,
'results': results,
'service_name': service_name
}
else:
return {
'command': 'unknown',
'error': f'未知命令: {cmd}',
'suggestion': '请尝试查询"show me all services with error rate > 1%"或"services with latency > 100ms"'
}
def generate_response(self, command_result: Dict[str, Any]) -> str:
"""生成人类可读的响应"""
template = """
你是一个专业的运维助手,需要将技术数据转换为自然语言响应。
命令结果: {command_result}
请用中文生成一个清晰、专业的响应,包含关键数据和建议。
"""
prompt = PromptTemplate(template=template, input_variables=["command_result"])
chain = LLMChain(llm=self.llm, prompt=prompt)
response = chain.run({
"command_result": json.dumps(command_result, indent=2)
})
return response
def process_query(self, query: str) -> str:
"""处理自然语言查询的完整流程"""
print(f"🔍 解析查询: '{query}'")
# 1. 解析查询
structured_cmd = self.parse_natural_query(query)
print(f"📋 结构化命令: {structured_cmd}")
# 2. 执行命令
command_result = self.execute_command(structured_cmd)
print(f"📊 命令结果: {command_result}")
# 3. 生成响应
response = self.generate_response(command_result)
print(f"💬 生成响应: {response}")
return response
# 使用示例
if __name__ == "__main__":
nlops = NaturalLanguageOps()
# 示例查询
queries = [
"show me all services with error rate > 1%",
"services with latency > 100ms",
"CPU usage for database service",
"connection stats for api-gateway",
"which service is using the most memory?"
]
for query in queries:
print("\n" + "="*50)
print(f"用户查询: {query}")
print("-"*50)
response = nlops.process_query(query)
print("\n" + "="*50)
time.sleep(2) # 避免API调用过快六、实践挑战
6.1 性能优化
- eBPF程序开销:使用BPF_MAP_TYPE_PERCPU_ARRAY减少锁竞争,采样率动态调整
- LLM推理延迟:采用模型量化(4-bit量化),结果缓存,异步处理
- 数据处理瓶颈:使用Apache Flink进行流式处理,特征预计算
6.2 安全合规
- 数据脱敏:在eBPF层过滤敏感信息,LLM输入自动脱敏
- 访问控制:基于RBAC的查询权限管理,操作审计日志
七、结语
生成式AI与eBPF的融合代表了智能运维的新范式。通过代码示例我们可以看到,这一技术栈已经具备实际落地的条件。它不仅解决了传统运维的痛点,更重新定义了人与系统的关系------运维工程师从"救火队员"转变为"系统教练",专注于高层次的决策和优化。
在这个技术变革中,eBPF提供了系统级的"眼睛",生成式AI提供了智能的"大脑",而自然语言交互则提供了友好的"界面"。三者结合,构建了一个真正智能化、自动化的运维新世界。随着技术的成熟,我们有理由相信,未来的系统将具备自我感知、自我诊断、自我修复的能力,而人类工程师将专注于创造更大的业务价值。这不仅是技术的进步,更是运维理念的革命性跃迁。