目录
[pickle 和 shelve模块](#pickle 和 shelve模块)
[将数据保存到二进制文件 pickle.dump()](#将数据保存到二进制文件 pickle.dump())
[读取文件中的数据,并进行pickle处理 pickle.load()](#读取文件中的数据,并进行pickle处理 pickle.load())
[json.load() 读取数据](#json.load() 读取数据)
在python -- 文件与异常中提到 "存储复杂数据",提到了使用 pickle和shelve两个模块分别如何来持久化和读取数据。为了方便,直接将这部分内容复制到此,同时添加另一种方式:使用模块json来存储数据
------- 使用 pickle / shelve 模块 持久化数据 内容 start -------
如何将列表、字典之类更为复杂的信息存储到文本文件中呢?除了将其转换为字符串再保存到文本文件中,Python提供了一个方法,只需一行代码就可以将复杂数据保存到文件中去,还可以在单个文件中存储一个小型的数据库(功能就像字典)
下面用到的pickle和unpickle适用于存取结构化信息。更为复杂的信息则需要更高的性能和灵活性。数据库和XML是两种流行的复杂数据存取手段。
需要引入pickle 和 shelve模块
import pickle, shelve
pickle 和 shelve模块
pickle模块可以对复杂数据进行序列化处理并保存到文件中。
shelve模块也可以进行序列化处理并将结果保存到文件中,而且还可以对这些结果进行随机访问。
通过pickle处理对象
创建文件
f = open("pickles1.dat", "wb")
经过pickle处理的对象只能被写入到二进制文件,不能被写入到文本文件中,所以访问模式与上面访问文本文件的模式有所不同
访问模式
| 模式 | 说明 |
|---|---|
| "rb" | 读取二进制文件。如果文件不存在,Python会给出一个错误 |
| "wb" | 写入二进制文件。如果文件已存在,内容会被覆盖。如果文件不存在,则会被创建出来 |
| "ab" | 向二进制文件添加内容。如果文件已存在,新数据被添加进去。如果文件不存在,会被创建出来 |
| "rb+" | 读写二进制文件。如果文件不存在,报错 |
| "wb+" | 读写二进制文件。如果文件已存在,覆盖其内容。如果文件不存在,则创建一个 |
| "ab+" | 读取二进制文件以及向二进制文件添加内容。如果文件已存在,新数据被添加进去。如果文件不存在,被创建出来 |
可以进行pickle处理的对象
- 数字 number
- 字符串 string
- 元组 tuple
- 列表 list
- 字典 dictionary
将数据保存到二进制文件 pickle.dump()
pickle.dump(待pickle的数据, 用于存储的文件)
variety = "sweet", "hot", "dill"
pickle.dump(variety, f)
将variety所指向的列表序列化冰整体保存到pickles1.dat中
读取文件中的数据,并进行pickle处理 pickle.load()
pickle.load(file)函数用于获取反序列化的数据。file入参为序列化对象所在的文件
variety = pickle.load(f)
读取文件中的序列化对象,将其反序列化后产生的列表复制给variety
总结pickle的两个方法
| 函数 | 说明 |
|---|---|
| dump(object, file, bin) | 将object序列化后写入file。如果bin 为True,则object将以二进制格式写入。如果bin为False,则object将以文本格式写入(虽然效率比较低,但可读性更好)。bin默认值为False |
| load(file) | 从文件中读取下一个序列化对象,将其反序列化之后返回 |
通过shelf保存序列化对象
将多个列表shelve到单个文件中。
创建shelf,shelve.open()
shelve.open(文件, 访问模式),shelve的open()函数,所操作的文件中存放的是序列化对象而不是字符。访问模式是可选的,如果不指定,默认为"c"打开一个文件。
s = shelve.open("pickles2.dat")
调用shelve.open()是,Python可能会在指定的文件名后面添加一个扩展名。为了支持新创键的shelf对象,Python还可能会创建出额外的文件。
shelve访问模式
| 模式 | 说明 |
|---|---|
| "c" | 打开一个文件以便读写。如果文件不存在,就创建一个 |
| "n" | 创建一个写文件以便读写。如果文件已存在,则覆盖其内容 |
| "r" | 读取一个文件。如果文件不存在,报错 |
| "w" | 写入一个文件。如果文件已存在,报错 |
添加列表到shelf
shelf的用法类似于字典(dictionary),键"variety"和值 "sweet", "hot", "dill"是一对。
shelf对象的键只能是字符串。
s"variety" = "sweet", "hot", "dill"
Python先将对shelf文件的修改写入到一个缓冲区,然后再定期将缓冲区中的内容写入到文件。为了确保文件能反映出所有对shelf的修改,可以使用shelf的sync()方法。
s.sync() # 确保数据被写入
关闭文件的close()方法,也会实现sync()的功能。
shelf获取序列化对象
由于shelf的用法与字典类似,所以可以通过指定键的方式随机访问其中的系列化对象。
s"variety"
关闭文件
s.close()
------- 使用 pickle / shelve 模块 持久化数据 内容 end-------
json模块存储数据
导入json模块
import json
json.dump()存储数据
需要两个参数,第一个:要存储的数据,第二个:可用于存储数据的文件对象
filename = "numbers.json"
numbers = 2, 3, 4, 5, 7, 11, 13
with关键字在不需要访问文件后将其关闭,不需要手动调用close()方法关闭了
with open(filename, "w") as f_obj :
numbers =json.dump(numbers, f_obj)
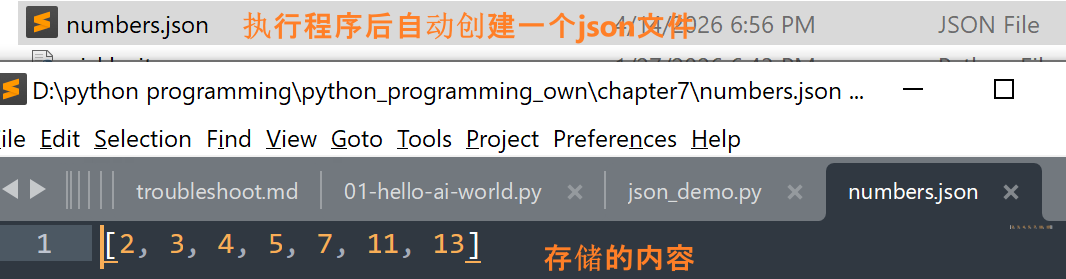
执行代码后,会在同一文件夹中创建一个numbers.json文件,里面保存的就是numbers列表,如图
json.load() 读取数据
json.load()会加载存储在json文件中的信息,将内容读取到内存中
filename = "numbers.json"
with open(filename) as f_obj :
numbers =json.load(f_obj)
打印读取的内容
print(numbers)
打印结果:

示例:保存和读取用户输入的信息 remember_me.py
python
#! python
# 如果以前存储了用户名,就加载它
# 否则,就提示用户输入用户名并存储它
import json
filename = 'username.json'
try :
with open(filename) as f_obj :
username = json.load(f_obj)
except FileNotFoundError :
username = input("What is your name? ")
with open(filename, 'w') as f_obj :
json.dump(username, f_obj)
print("We'll remember you when you come back, " + username + "!")
else :
print("Welcome back, " + username + "!")