
AI 助理又"已读不回"?别慌,ArkClaw 智能诊断与自动修复
是不是感觉拥有 ArkClaw 专属助理之后,仿佛打开了新世界的大门?无论是日常聊天、信息查询,还是处理各种自动化任务,它都像一个不知疲倦的数字伙伴,低成本、高效率地改变着我们的工作流。但......美好的时光总是短暂的,当你发现你的助理突然变得"高冷"------问话转圈圈、已读不回,甚至开始"自暴自弃"般地无限重启时,是不是瞬间感觉从云端跌落?
揭秘:"已读不回"与"无限重启"背后到底发生了什么?
当我们向 ArkClaw 助理抛出一个问题时,背后是一套精密的协作流程。任何一个环节卡顿,都可能导致我们看到的"掉线"现象。其核心原因主要有两类:
原理一:网关与插件的"内部矛盾"
ArkClaw 的强大之处在于其开放的插件生态,但这也可能成为不稳定的根源。当你兴冲冲地安装一个社区大神开发的第三方插件,或者手动修改了某些高级配置后,问题可能就悄然而至了。
- 不兼容的"外挂" :某些第三方插件可能没有经过严格测试,其内部逻辑与 ArkClaw 的核心网关存在冲突。当网关尝试加载这些插件时,会触发保护机制,选择"重启"来避免更严重的数据错乱。这就像给一台精密的引擎加了不匹配的零件,引擎为了自保,只能选择熄火。
- 错误的"咒语" :错误的配置,比如一个多余的逗号、错误的缩进,都可能导致 ArkClaw 的"大脑"------配置解析器无法正常工作。在这种情况下,系统同样会采取保护性重启,尝试恢复到上一个已知的健康状态。
原理二:大模型侧的"资源枯竭"
有时候,你的助理看起来在线,但就是不回复,或者回复慢得像在"思考人生"。这往往不是 ArkClaw 本身的问题,而是它背后的"智慧源泉"------大语言模型(LLM)的 API 接口"累了"。
- API 限流:每个大模型服务都会有并发请求限制(Rate Limiting)。如果你在短时间内发送了大量请求(比如让它同时处理多个任务,或者接入了一个高并发的业务场景),就很容易触发模型的限流策略。这时,API 会暂时拒绝新的请求,你的助理自然也就"已读不回"了。
- 资源耗尽:即使没有达到明确的限流阈值,过于复杂的请求或高并发也可能耗尽模型服务侧的瞬时计算资源,导致响应时间急剧增加,从用户的角度看,就是消息一直在"转圈圈"。
ArkClaw 的"听诊"艺术
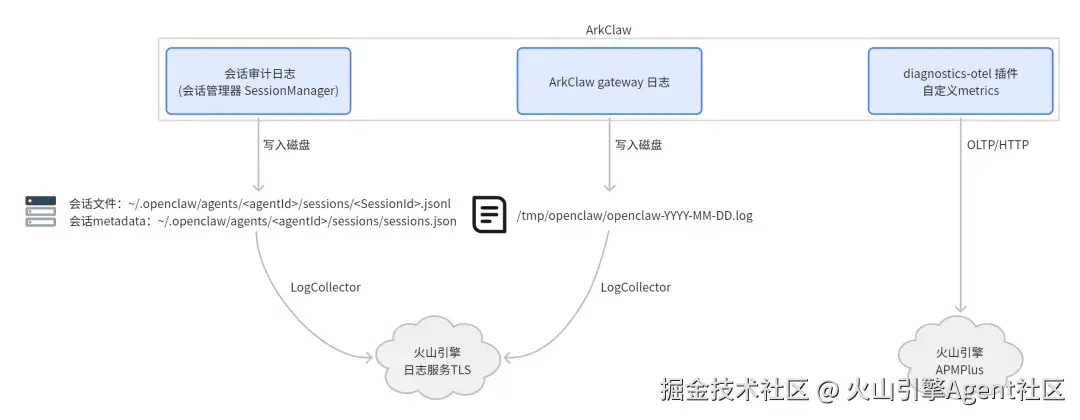
面对这些复杂的问题,ArkClaw 内部有一套强大的"听诊"机制。它会实时联动多维度的可观测系统,像一位经验丰富的医生,从不同维度串联线索,精准定位病灶:
- 基础监控:基础监控包括 ArkClaw Gateway 进程存活、监听端口以及进程 CPU、Memory 等负载基础信息,可以第一时间确认 ArkClaw Gateway 健康状态、是否存在资源瓶颈。
- 网关日志:网关日志不仅涵盖了网关运行日志,还包含插件子系统 (比如 channels/feishu)、cron 定时任务以及 exec 脚本执行的日志,有助于我们迅速定位因配置错误、插件配置错误致使 ArkClaw Gateway 启动失败、异常重启的根本原因,明晰定时任务和脚本执行失败的缘由;同时通过网关日志可以发现因模型限流、回退链路等模型调用异常事件。
- 会话诊断日志:会话诊断日志可以追溯包括 Agent 处理用户消息时的 skills、模型以及工具调用记录与耗时等,帮助我们了解会话级别的问题,可以通过 SessionID 来确认是否存在上下文打满、记忆丢失等问题。
- OpenClaw指标:diagnostics-otel 包含了消息队列、会话管理、成本统计以及 webook 处理等指标,可以帮助我们了解 ArkClaw Gateway 是否存在消息队列堆积、会话卡住等问题。
通过这套组合拳,ArkClaw 能快速判断出问题的根源,是内部冲突还是外部压力。
破局:从"手工恢复"到"自动修复"
改个配置突然启动失败、装个新插件网关直接崩、线上好好的服务突然没响应,排查半天不知道问题出在哪?过去,解决上述问题需要你像个侦探一样,手动翻阅日志、检查配置、禁用插件,过程繁琐且容易出错;今天,你只需要点击"自动修复 ArkClaw"按钮就能轻松实现修复,接下来我们把 ArkClaw 自带的"一键自愈"全流程给你捋明白。
先搞清楚:你遇到的问题到底是哪类?
第一类:系统层/基础设施的锅
这类问题跟 OpenClaw 本身没关系,是底层环境出问题了:
- 机器内存 /CPU 跑满,进程被系统杀了;
- 磁盘空间满了;
第二类:OpenClaw 本身的问题
这类是业务层故障,属于 OpenClaw 运行时出的问题:
- 改完配置启动失败、插件装完直接崩溃;
- 升级版本后兼容性问题,服务异常重启;
- ArkClaw 执行过程把自己改坏了;
配置备份:安全的守护者
在深入了解修复机制之前,我们先来说说 OpenClaw 的 config.bak 备份机制------这可是自动修复能够成功的重要保障!
为什么要有备份?
- 在覆盖现有配置前,先留一份最近一次的"已知可用"备份,便于快速回滚
怎么来的?
- 只有在"覆盖已有配置文件"时才生成备份。首次创建配置文件不会产生 .bak
- 触发点:
writeConfigFile在落盘前检查目标是否已存在,存在则执行备份维护流程,例如 openclaw config set 和 openclaw doctor --fix 都会产生备份文件。 - ⚠️ 注意:手动修改配置文件并不会自动进行备份
"一键自愈"核心流程
1. 前置安全校验:修复启动前自动加锁,避免同一实例同时触发多个修复任务引发冲突
2. 状态同步:实例状态更新为「修复中」,修复期间禁止手动操作实例,保障流程稳定
3. 分层修复:
- 先解决系统层问题:自动检测并修复资源耗尽、实例卡死等底层异常
- 再解决应用层问题:自动执行官方修复脚本,一键处理配置回滚、异常插件清理、兼容性适配等问题
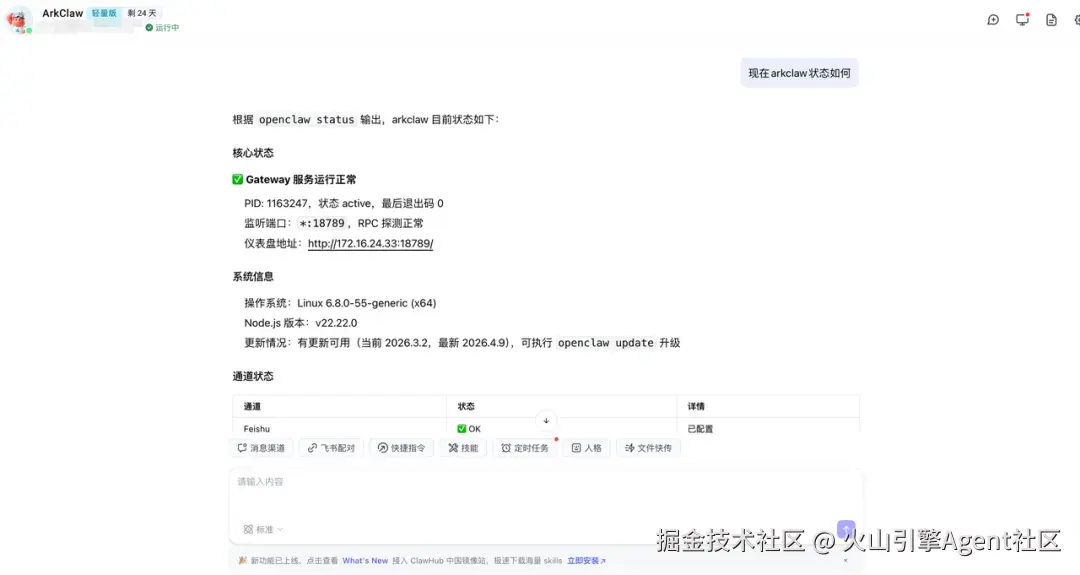
4. 结果反馈:修复完成后自动将实例状态恢复为「运行中」,同步推送修复结果通知
示例:ArkClaw 实例配置异常,完成自动修复
- ArkClaw 实例因配置异常
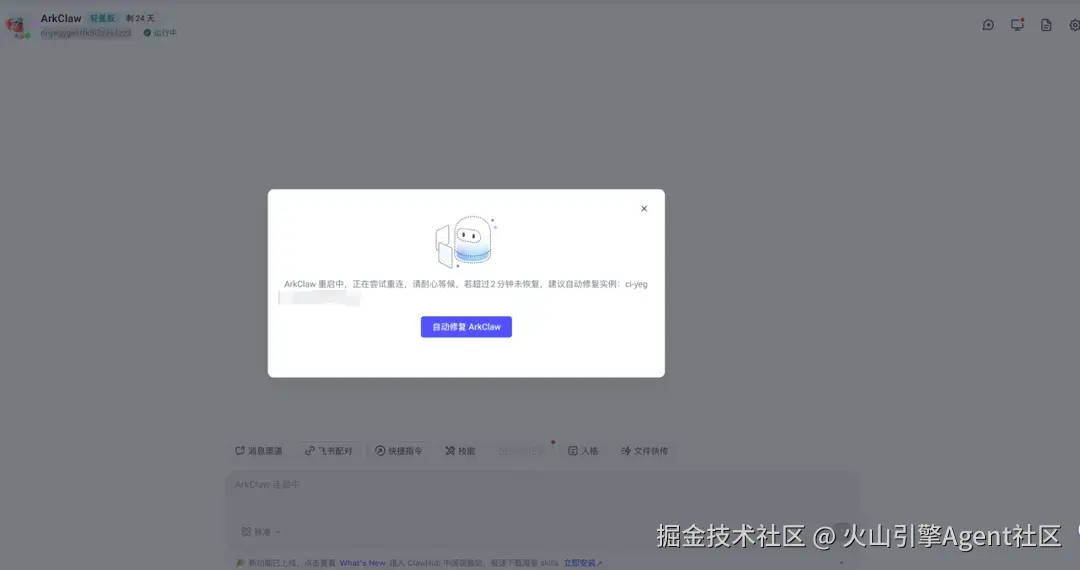
- 控制台点击自动修复
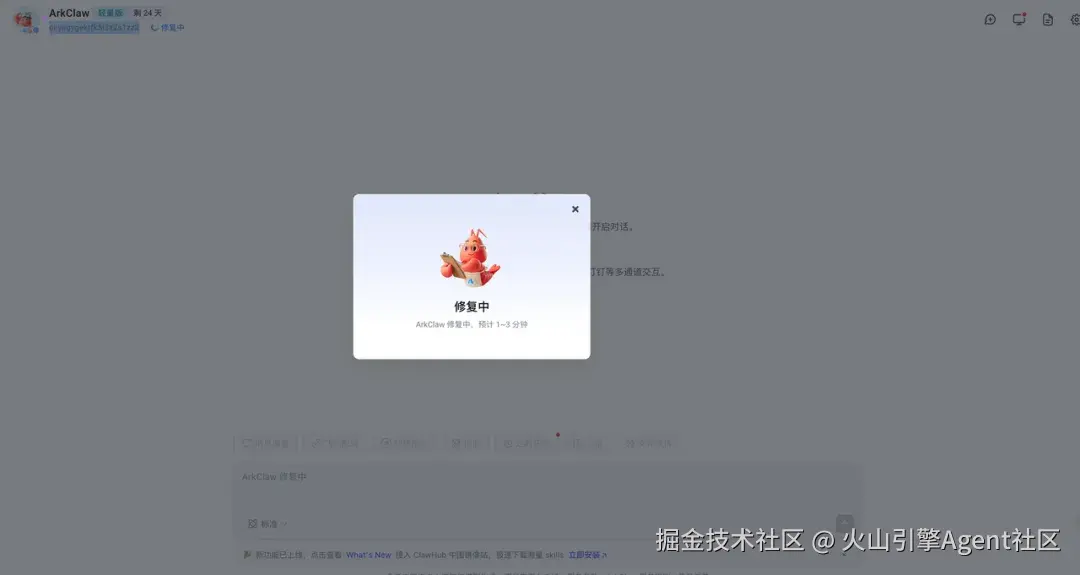
- 查看修复效果
分层修炼:给不同玩家的 ArkClaw 使用指南
新手玩家:稳字当头
对于刚接触 ArkClaw 的你,我们建议:
- 遇事不决,先执行自动修复:这是最快、最安全的恢复手段。
- 不盲抄配置 :网络上的高级配置可能很诱人,但在理解其含义之前,不要轻易复制粘贴。错误的配置是导致重启的首要原因。
- 优先使用"绿标插件" :在 ArkClaw 的官方市场中,经过认证的插件会被打上"绿标" 。这些插件经过了更严格的测试,兼容性和稳定性更有保障。
进阶玩家:性能与稳定的平衡艺术
如果你已经开始用 ArkClaw 对接一些轻量业务,那么你需要关注:
-
合理设置并发与超时:在配置文件中,你可以找到 concurrency 和 timeout 两个关键参数。
-
concurrency:定义了 ArkClaw 可以同时向大模型发送多少个请求。默认值通常较低,如果你业务量大,可以适当调高,但要确保不超过你所使用模型 API 的限制,避免被限流。
-
timeout:定义了等待模型返回结果的最长时间。如果你的网络环境不稳定,或者某些请求确实需要长时间处理,可以适当延长超时时间,防止因"假死"而过早中断请求,引发雪崩。
-
-
参考阈值 :对于个人项目,建议并发数不超过 5,超时不超过 120 秒。这为大多数场景提供了足够的缓冲,同时避免了资源滥用。
结语:工具的边界与人的智慧
工具的强大,最终需要与使用者的智慧相结合。理解其背后的原理,遵循最佳实践,才能真正将 AI 助理的能力发挥到极致,让它成为一个稳定可靠的伙伴。
虾友集结令,邀友享返券
ArkClaw 优惠上新,邀请好友首次订阅 ArkClaw 立得 10% 实付金额返券,多邀多得,>> 立即邀请
欢迎订阅火山方舟 Coding Plan,多模型随心用,养虾更划算。