因为OnComponentBeginOverlap 这个事件底层就被定义成一个 6 参数委托,不是只为了告诉你"碰到了谁",而是把一次 overlap 里常用的上下文都一起给你。
底层声明就在这里:
DECLARE_DYNAMIC_MULTICAST_SPARSE_DELEGATE_SixParams(... OverlappedComponent, OtherActor, OtherComp, OtherBodyIndex, bFromSweep, SweepResult)
1.OverlappedComponent
触发事件的"我方组件"。
在你图里就是那个 Box 组件本身。
- OtherActor
和这个 Box 发生重叠的"对方 Actor"。
比如:
玩家角色
敌人
一个可拾取物体
任意带碰撞并进入 Box 范围的 Actor
你图里把 **OtherActor 和 GetPlayerCharacter() 做 == 比较,**就是在判断:
这次进入 Box 的 Actor,是不是当前玩家角色。
- OtherComp
对++方 Actor 身上,真正拿来和你重叠的那个组件。++
例如玩家角色进入 Box 时,通常这里可能是:
++Capsule Component++
Mesh 上++某个碰撞组件++
其他++自定义碰撞体++
也就是说:
OtherActor = 谁来了
OtherComp = 它身上哪个组件碰到你了
- ++OtherBodyIndex++
对方++body 的索引++ ,更多是给复杂碰撞 / ++多 body 情况用的。++
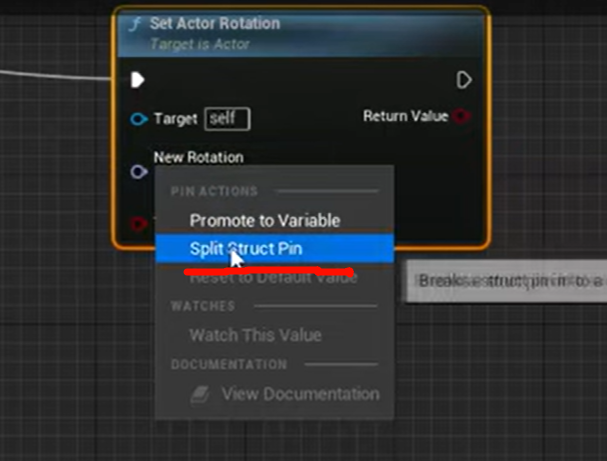
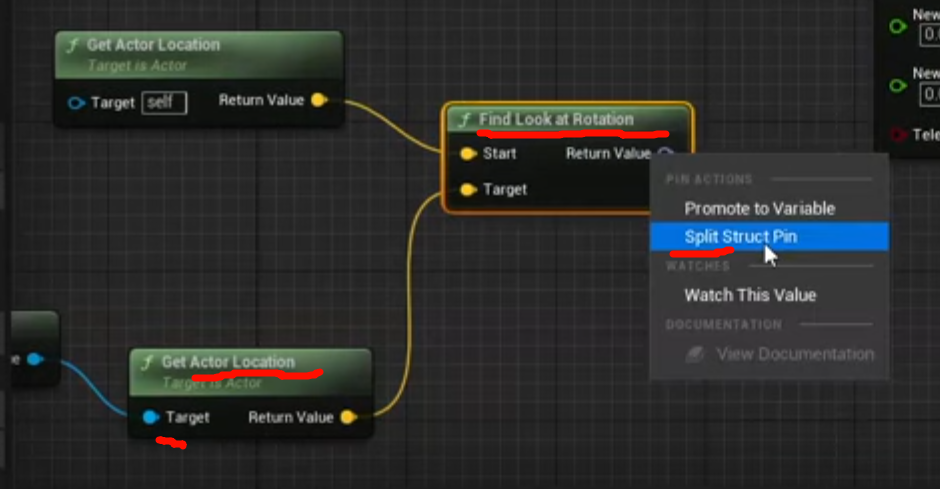
GetRelativeRotation() 节点,只不过它的返回值 FRotator 被 Split Struct Pin 之后,拆成了 3 个 float 输出:
Relative Rotation X (Roll)
Relative Rotation Y (Pitch)
Relative Rotation Z (Yaw)
从引擎源码看,这个函数本体非常简单:
FRotator GetRelativeRotation() const
return RelativeRotation;
也就是说,它就是在读取这个组件当前的相对旋转。
1. Set Relative Scale 3D
这是最常用的"缩放模型"节点。
含义:
- 设置组件相对于父组件的缩放
- 如果这个组件挂在别的组件下面,它最终显示大小会受父级影响
例如:
- 父组件 Scale =
(2,2,2) - 子组件 Relative Scale =
(0.5,0.5,0.5)
最终世界里看起来可能还是 1x
适合场景:
- 门、道具、StaticMesh 做动画缩放
- 子组件跟随父组件层级工作
- 蓝图里绝大多数"把东西放大缩小"都用它
2. Set World Scale 3D
这是设置组件在世界空间中的最终缩放。
含义:
- 你直接指定它在世界里的结果缩放是多少
- UE 会反推它的相对缩放,让它最终达到这个世界大小
适合场景:
- 不想管父组件缩放,只想让物体最终看起来就是某个大小
- 层级比较复杂时,想直接控制最终结果
举例:
如果父组件已经缩放了 2x,你还想让子组件世界里看起来是 1x,那就用这个更直观。
3. Set Absolute Scale
这个不是"设置缩放值",而是一个开关/模式。
含义:
- 控制这个组件的 Scale 是否要脱离父组件继承
- 勾上后,这个组件的 Scale 更接近"按世界绝对值处理"
- 不勾时,Scale 会继续跟随父组件层级继承
适合场景:
- 你把组件挂在一个会缩放的父节点下面
- 但你不希望这个子组件跟着一起变大变小
比如:
- 角色身上挂了一个特效组件
- 角色整体被缩放时,你不想特效大小也变
这时会考虑它
4. Set Bounds Scale
这个不是改模型肉眼可见的大小,而是改 Bounds(包围盒/包围范围) 的缩放。
含义:
- 调整渲染/可见性/裁剪相关使用的包围体大小
- 不会真的把模型变大或变小
- 更像是"告诉引擎,这个东西的可见范围按更大/更小来算"
适合场景:
- 顶点动画、WPO(World Position Offset)把模型表面拉出原始包围盒
- 特效、抖动、风吹、shader 位移导致模型超出原 bounds
- 物体明明还看得到,却被错误裁剪掉
如果你只是想"让门放大一点",不要用它。
5. Set Mass Scale
这个是物理质量缩放,不是模型尺寸缩放。
含义:
- 改的是刚体质量的倍率
- 不改变物体显示大小
- 只影响物理表现,比如更难推动、惯性更大等
适合场景:
- 开启了物理模拟
- 想让某个部件更重/更轻
- 不改 mesh 尺寸,只改物理手感
比如:
- 箱子看起来一样大
- 但你想让它"像铁箱一样重"
- 就可以调 mass scale
6. Set All Mass Scale
这是 Set Mass Scale 的"全体版本"。
含义:
- 对组件里所有相关 body / bone / physics body 一起设置质量倍率
- 常见于复杂物理对象、skeletal mesh、多 body 组件
适合场景:
- 不是只改单个 body
- 而是整个物理对象都一起变重/变轻
普通 Static Mesh Component 场景里,很多时候你未必会明显感觉和 Set Mass Scale 区别有多大,但在复杂物理对象里区别会更明显。
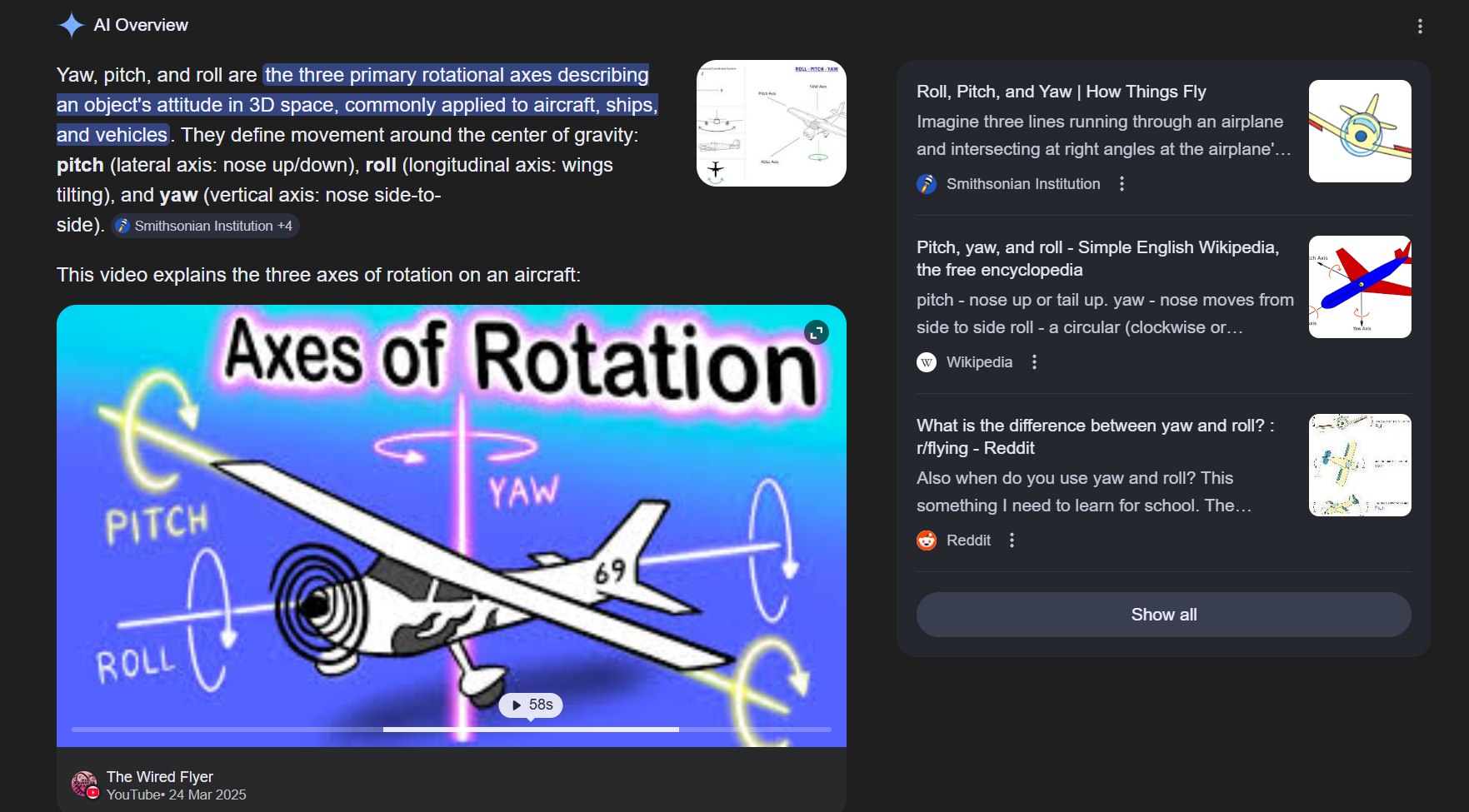
UE 蓝图里常见这几类执行机制:
Custom Event:本质上是一次事件调用,走 ProcessEvent()
Set Timer by Event:注册到 FTimerManager
Timeline:组件每帧 TickComponent()
Delay 这类 latent 节点:交给 Latent Action Manager
它们的共同点:
默认都不是开新线程跑,而是被 UE 放进主循环里,在合适的时机回调。

像 Delay 这种节点,体验上有点像"暂停后恢复",但底层通常也是注册 latent action,等世界 Tick 时机成熟再回到指定执行点,例如 LatentActionManager 最终也会回调 ProcessEvent()。
所以更准确的描述是:
UE 蓝图不是"协程优先",而是"事件 + Tick + Timer + Latent Action"共同模拟出异步感。
普通 gameplay 蓝图里的:
- 输入事件
- overlap 事件
- timer 回调
- timeline update
- custom event
绝大多数都在 Game Thread 上跑。
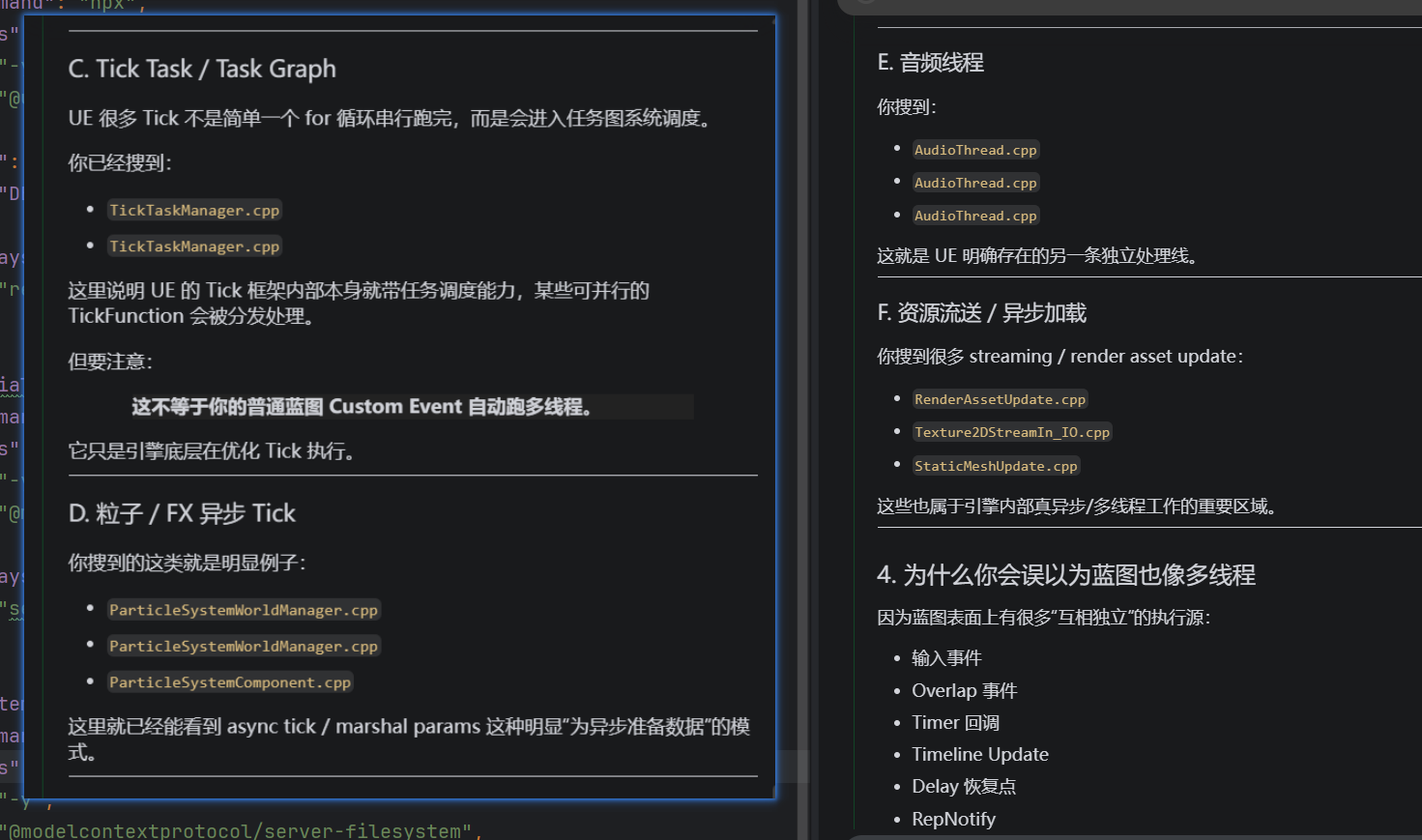
UE 引擎当然内部有很多真异步系统,比如:
- 渲染线程
- 物理异步
- 资源流送
- 某些 FX async tick
但那不等于"你的蓝图 Custom Event 自动跑到别的线程"。
不是 C# 那种 async/await,也不是 Lua coroutine 那种真正 yield/resume 对象。
coq
flowchart TD
A[Game Thread / World Tick] -->|Process| B[Input Events]
A -->|Update| C[TimerManager Tick]
A -->|Advance| D[Timeline Tick]
A -->|Resume| E[Latent Action]
A -->|Execute| F[Blueprint ProcessEvent]
G[Render Thread] -->|Perform| H[Rendering Work]
I[Physics Thread] -->|Simulate| J[Physics Step]
K[Audio Thread] -->|Handle| L[Audio Processing]
M[Streaming Thread] -->|Manage| N[Asset Loading]
这个概念比具体语言更大,不属于某一门语言独占。
很多语言都有各自形式的协程或协程近亲:
- C#:
async/await - C++20:语言级 coroutine
- Python:
async/await、generator - Lua:coroutine
- JavaScript:
async/await、generator - Kotlin:coroutine
- Go:虽然叫 goroutine,但更偏轻量线程,不完全等同传统 coroutine
所以"协程"是通用编程概念,不是 C# 专属术语。
- 协程可以完全跑在单线程里
- 多线程也完全不需要协程
- 协程经常被用来写"异步但看起来同步"的代码
- 线程经常被用来做并行计算
AActor、APawn、ACharacter 这些对象本体,通常是:
- UObject 基类数据
- 反射/GC 所需字段
- 各种 bool、float、struct、指针
- 少量数组/容器对象本身
这一部分一般是 KB 级别或几十 KB 级别思考,而不是上来就 MB。
实例带出来的整体内存
ACharacter 默认就挂了几个重组件:
- USkeletalMeshComponent* Mesh
- UCharacterMovementComponent* CharacterMovement
- UCapsuleComponent* CapsuleComponent
- 编辑器下还有 UArrowComponent* ArrowComponent
这些组件自己也各有对象开销。
再往上,如果 Mesh 绑定了:
- Skeletal Mesh
- Skeleton
- Anim Blueprint
- Physics Asset
- 材质
- Morph Target
- Cloth
- IK / Pose Cache
那内存就会迅速上去,但这已经不是"Character 类本身"了。

逻辑的"离散性"是一种事后重构(Post-hoc Reconstruction)
依据 Henri Bergson 的观点,理智(Intellect)为了操作方便,将连续的生命体验切割成离散的片段。
-
代码假象 :所谓的"逻辑代码"(如 A→B)是逻辑推导完成后的空间化残留。正如你在 3D 渲染中看到的一帧静态图像,它是由背后无数复杂的、连续的微分方程动态演化而来的。
-
Vibe 的本质:复杂的逻辑推导在执行瞬间,并非在执行指令集,而是一种**"势能的自动塌陷"**。当你的意识结构与问题结构实现高度耦合时,结论是"滑向"你的,而非被你"算"出来的。
Ludwig Wittgenstein 在《哲学研究》中对"遵循规则"的讨论:
-
逻辑的直观性:规则并不是在每一步都指导我们,因为那会导致无限倒退(我们需要另一条规则来解释如何应用这条规则)。
-
执行逻辑 :最终,我们是"盲目地"遵循规则。这种"盲目"并非无知,而是一种**"深层的本能化耦合"。在这种状态下,逻辑就是一种 Vibe,一种不需要代码解析的、直接的行动趋势**。
EditAnywhere
这个属性可以在编辑器里改。
BlueprintReadOnly
蓝图里能读,不能直接写。
Category=Input
在编辑器 Details 面板里把它归到 Input 分类。
meta=(AllowPrivateAccess="true")
即使这个字段在 C++ 访问级别上是 private/protected,也允许 UE 反射系统暴露它给蓝图/编辑器使用。
很多属性虽然本质可变,但不希望你:
- 在任意蓝图节点里随手改
- 绕过逻辑约束
- 忘记更新依赖系统
所以才会出现这种组合:
- 可编辑
- 可读
- 不可直接写
- 但可以通过函数改
这是一种很典型的封装手法。
flowchart TD
APlay 启动游戏世界 --> B确定当前地图使用的 GameMode
B --> CGameMode 创建 PlayerController
C --> DGameMode 生成或指定 Default Pawn
D --> EPlayerController Possess Pawn
E --> F输入系统把键鼠输入送给 Controller 或 Pawn
F --> GPawn 移动并更新 Camera 视角
Xibalba, the Maya underworld, is accessible through caves and cenotes in Belize and the Yucatan Peninsula, notably the ATM cave or Xibalba Dive Center in Tulum . Tours offer rappelling, cave tubing, and cenote swimming. For a virtual experience, the region is a remote exploration target in Elite Dangerous.
axis 更准确是"连续输入轴"或"数值维度",不是"键位"本身。
你可以这样理解:
axis 说的是"一个方向上的输入量",例如:
-
水平轴:左 ↔ 右
-
垂直轴:前 ↔ 后
-
鼠标 X:向左移动 ↔ 向右移动
-
手柄扳机:0 到 1 的压下程度
-
摇杆 X/Y:-1 到 1 的偏移量
改动是不是"小而确定"?
是:优先走 master
Shelve 和 Git Stash 很像,但不是一回事。
shelf 是 JetBrains IDE 自己管理的补丁;stash 是 Git 自己的机制。所以 shelf 更偏 IDE 内部临时操作。
Shelf 本来就不是版本管理。
它是 JetBrains 设计出来的一个"临时搁置未提交改动"的补丁仓,目标不是建立可靠历史,而是让你把一坨没做完的改动先挪开,再继续别的事。JetBrains 官方文档明确把 unshelve 描述成"把 postponed changes 移回 pending changelist",并且说明 unshelved changes 默认可以继续保留在 shelf 里,供以后再次复用。
Unshelve 时有一个选项叫 "Remove successfully applied files from the shelf"。只有你勾了它,成功应用的文件才会从当前 shelf 中标记为已应用并移出正常视图。
就算已经 unshelved 过,JetBrains 仍允许这些变更被再次复用;文档明确说 "All unshelved changes can be reused until they are removed explicitly by selecting Delete" 。也就是:不手动删,它就留着。
- unshelve = 取出来并销毁原件
而是更像:
-
unshelve = 从抽屉里拿一份出来用
-
shelf 里原记录默认还保留
这也是你会觉得"没意义"的原因:
因为你脑子里期待的是 stash / commit / local history 那种"状态推进式"的模型;
而 shelf 更接近 patch clip board,是"临时存个补丁,随时再贴一次"。
同一个文件的改动可以被你在不同时刻反复 shelve 成多个条目;JetBrains 官方还明确写了,shelved change 可以按需要应用多次。
你今天改 DefaultInput.ini shelve 一次,
过一会儿再改它,再 shelve 一次,
Shelf 里就会出现多个都涉及同一个文件的记录。它不是"一个文件只能有一个槽位",而是"一个 shelf 条目里可以包含这个文件的某次改动"。JetBrains
至于 VS Code,原生没有 Rider 这种 shelf 机制。VS Code 官方文档重点提供的是 Git 的 source control、staging、commit、diff、branch、worktree、stash 这些能力,没有内建一个独立于 Git 的 JetBrains-style Shelf 面板。
VS Code 里最接近的替代物是:
- Git stash:把当前未提交改动临时收起来。VS Code 官方文档专门把 stash 作为 Git 工作流的一部分来讲。
Multi Diff / Source Control:看多文件改动,但这只是查看变更,不是 shelf 存档。
git status 能查到的是当前工作区相对 Git 的状态,
-
哪些文件被修改了
-
哪些文件已经
stage -
哪些文件是新文件
-
哪些文件被删除了
-
当前分支情况
例如它会告诉你:
-
modified -
new file -
deleted -
untracked files
但它查不到这些更细的东西:
-
具体改了哪几行
这个要用
git diff -
某个文件以前怎么变过
这个要用
git log/git log -- file -
谁改的某一行
这个要用
git blame -
IDE 里 shelf 那种"我临时存过几份补丁"
这个不是 Git 的职责
所以如果你是在问:
"我当前项目里哪些文件变了,git status 能不能查到?"
答案是:能。
如果你是在问:
"像 Rider shelf 里那种同一个文件被存了几次、或者具体新增了哪几行,git status 能不能查到?"
答案是:不能,只能看到文件级状态。
如果想看"到底改了哪几行",下一步就该用:
overflow-visible!
Bash
git diff
git diff 默认看的就是 unstaged diff;而 --staged、HEAD 这些是对 diff 比较范围的进一步细分。
顺手给你一个最实用的记忆法:
-
想看"我刚敲但还没 add 的内容"
git diff -
想看"我已经 add 了什么"
git diff --staged -
想看"我现在总共改了什么"
git diff HEAD
staged 的本质是:
你在告诉 Git,"这些改动我要纳入下一次 commit 的候选集合。"
staged 不会把改动从工作区拿走。
你 git add 之后,文件内容还在那里,代码还在项目里,只是 Git 额外记住了"这一版我要提交"。
shelf 会把改动从工作区移走。
你 shelve 之后,当前文件通常会回到没改之前的状态,改动被存成一个补丁条目。
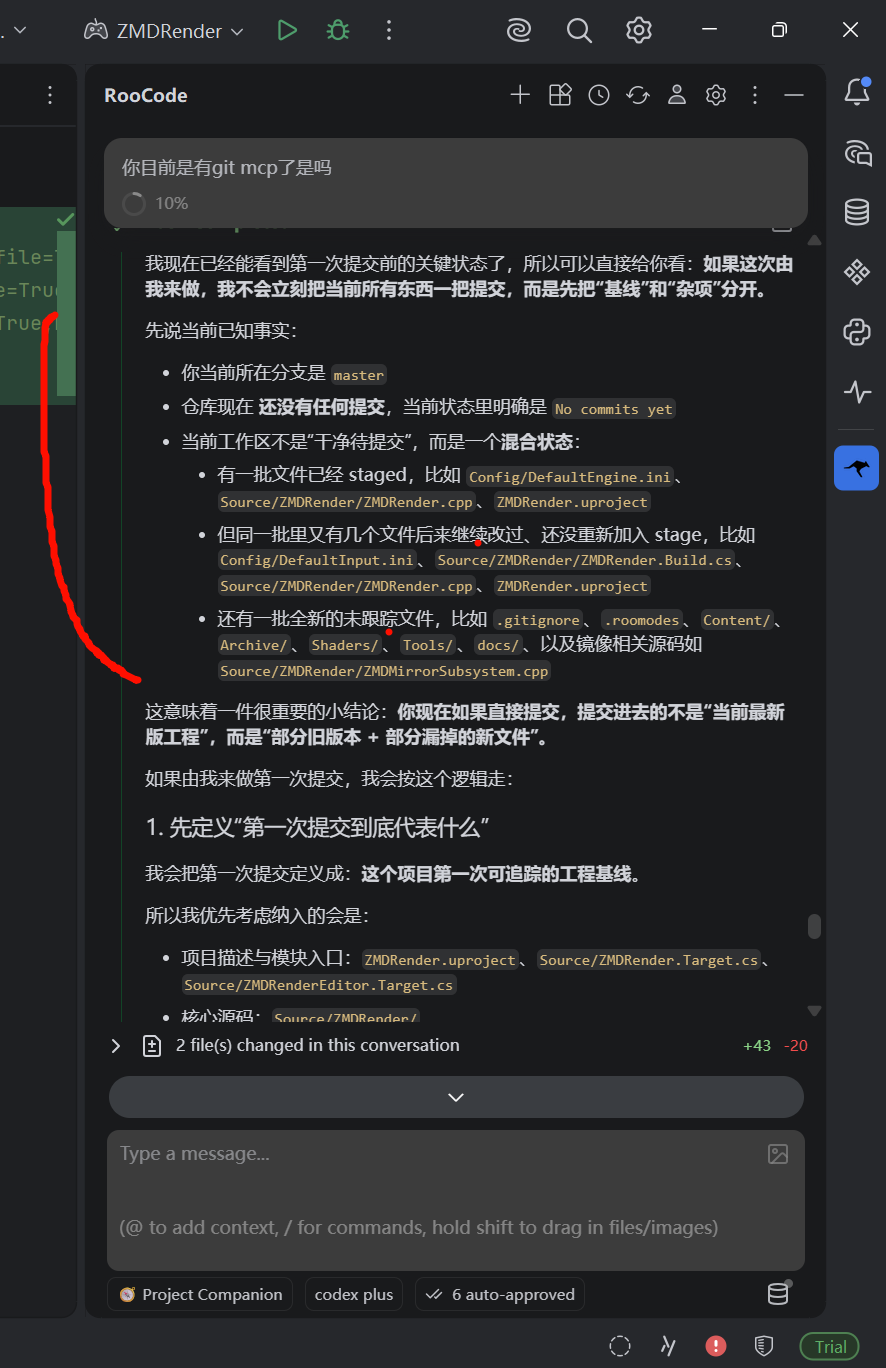
第一次提交建议内容:
Config/
Source/
ZMDRender.uproject
.gitignore
提交说明我会写成类似:
Initialize Unreal project structure and core runtime code
如果你希望把 Roo 配置也作为项目协作规则保留下来,那我会把:
.roomodes
.roo/rules-project-companion/
一起并入第一次提交,或者单独第二条提交:
Add Roo project companion workflow configuration
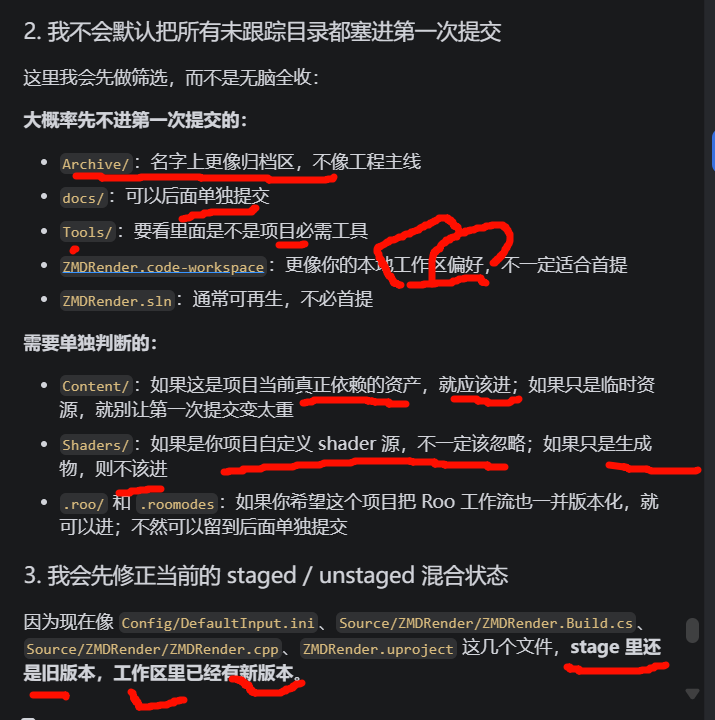
- 为什么我不建议第一次就全塞进去
因为我已经从当前状态看见三个风险:
首提会混入旧 stage 和 新工作区 的错位版本
首提会混入太多"还没分类"的目录,比如 Archive/、Tools/、docs/
首提如果把 Content/ 一口气全带上,仓库体积和后续历史都会马上变重
一直挂在 Unversioned Files 里、又长期不打算 Add / Resolve 的文件,通常就该考虑放进 .gitignore。不然它们会一直污染工作区视图,让你很难一眼看清真正该提交的内容。
只对你个人机器有意义
比如本地路径配置、用户偏好、临时测试文件。
这类通常也适合 ignore,除非团队明确要求纳入版本控制。
本地自动生成物项目可重复生成并非项目正式资产适合 ignore。
长期 unversioned 且永远不准备提交的文件,适合进 .gitignore;
只是暂时还没处理的正式项目文件,不适合。
一个文件已经进过仓库,后来你再把它写进 .gitignore,Git 也不会自动停止跟踪它。那种情况要先把它从索引里移除。
推荐用"英文类型前缀 + 中文主体说明"这一套。最稳,团队里也最不容易乱。
核心格式可以直接用:
type(scope): 中文说明
例如:
feat(login): 新增手机号登录
fix(render): 修复角色阴影闪烁问题
refactor(ui): 重构背包面板刷新逻辑
docs(readme): 补充安装步骤说明
这样做的好处很直接:
英文部分负责"结构化"和"可筛选性",适合看日志、做 changelog、配合规范工具。
中文部分负责"具体表达",你自己和中文团队看起来都快,不容易为了凑英文浪费精力。
更完整一点可以这样约定:
type(scope): 中文动词开头的简短说明
比如:
feat(input): 增加手柄震动支持
fix(animation): 修正跑步状态切换卡顿
perf(urp): 降低透明材质 overdraw
chore(repo): 更新 gitignore 规则
常见 type 建议统一成这些就够了:
feat 新功能
fix 修复
refactor ++重构++
++perf 性能优化++
docs 文档
++style 格式调整,不改逻辑++
test 测试
chore 杂项、配置、依赖、脚本
你如果想再规范一点,正文可以遵守这几个原则:
第一,尽量写"做了什么",不要只写"改了一下"。
第二,中文部分别太长,一行能看懂最好。
第三,多个改动不要硬塞一条 message,能拆 commit 就拆。
第四,避免情绪化词,比如"终于修好了""神秘 bug"。
一旦通过 git message 这种东西,把改动、模块、边界、责任 这些思维练出来,UE 会突然变得可切割、可理解"。
给你的东西太"大一坨"了。你一进去就像面对一整片系统:
输入
角色
组件
动画
蓝图
C++
相机
UI
关卡
GameMode
Controller
各种编辑器暴露参数
你最难受的是没法自然地把它切开。
而 git message 这套东西,表面看只是提交格式,实际上它在逼你练一种更底层的能力:
"这次改动到底是什么?"
"它属于哪个模块?"
"它的边界到哪?"
"我是不是一口气改了太多东西?"
"这个改动应该算 fix 还是 feat?"
"scope 应该写 camera 还是 character 还是 input?"
C++ 为什么麻烦
C++ 当然能热更新,甚至有些引擎和工具链专门做 DLL 热重载。
但它难点很多:
第一,编译链接成本高。
你改一点逻辑,通常要重新编译、重新链接。
第二,ABI 和内存布局敏感。
如果类结构改了、虚表变了、成员变量顺序变了,旧对象在内存里的布局和新代码可能对不上。
这时不是简单替换函数就完了,可能直接崩。
第三,函数指针、模板、内联、跨模块符号,都会让替换变复杂。
你想只换一小块逻辑,结果牵连一堆编译产物。
所以 C++ 热更新能做,但通常更适合:
-
编辑器开发时的 live coding
-
DLL 级模块热重载
-
对结构变化限制很严的热修复
它不太适合"线上大规模频繁改业务脚本"。
C# 为什么也能,但常见场景不如 Lua 传统
C# 有反射、Assembly Load、IL 热更、甚至 HybridCLR 这类方案。
它确实能很强。现在很多 Unity 项目也用 C# 热更新方案,而不是 Lua。
但问题在于:
-
需要处理程序集加载和隔离
-
AOT 平台上限制更多,尤其 iOS
-
裁剪、泛型、反射、IL2CPP 兼容性要考虑
-
工程链路比 Lua 更重
JS、Python 其实也很适合做热更新逻辑,因为它们也是动态语言。
但它们在游戏客户端里没有 Lua 那么经典,主要因为:
-
嵌入成本和运行时体积
-
性能和可控性
-
与 C/C++ 引擎绑定的传统生态
-
历史包袱和行业积累
Lua 在游戏行业属于"刚好够用,而且早就被验证很多年"。
决定热更新难度的,不只是语言,而是这四件事:
码是不是运行期可替换
解释型/字节码型/动态语言更容易。
状态能保留,只替换行为函数,热更就简单很多。
如果状态和逻辑强耦合,热更就容易炸。
因为人在做事时,脑子里的真实状态通常不是结构化的。
最开始往往是模糊的、连续的、带情境的、带目的感的。
比如你实际想的可能是:
"我想让这个角色动起来更自然一点。"
"这里的输入映射好像不对。"
"这个模块边界让我不舒服,应该拆一下。"
"这个项目配置终于像样了一点。"
这些都属于自然意图。它们是真实的,但它们不规整,不适合直接进入工程系统。
而一旦你要落到代码、文件、版本管理、任务记录里,就必须把这种连续的意图,压缩成离散的结构:
这是 feat 还是 fix
scope 是 input 还是 character
这次提交到底只处理一个问题,还是混了三个问题
这一步,本质上就是一种"翻译":
把人的模糊意图,翻译成系统可处理的结构单元。
工程活动,本质上不是直接操纵代码,而是不断在"意图"和"结构"之间做映射。
提交结果的哈希是 7645c0b,提交里,Git 规则文件 .gitignore,
后续再判断的内容,
如果你只是刚提交完,想改最近一次 commit message,最常用的是:
overflow-visible!
Bash
git commit --amend
这会打开编辑器,让你改最近一次提交的 message。
如果你只想直接改 message,不改文件内容:
overflow-visible!
Bash
git commit --amend -m "新的 message"
比如:
overflow-visible!
Bash
git commit --amend -m "fix(input): 修正默认输入映射冲突"
但要注意一个关键分界。
如果这次提交还没 push 到远程 ,基本随便改。
如果这次提交已经 push 了,你本地 amend 以后,commit 的哈希会变,就不是原来那个提交了,这时再推送通常要:
overflow-visible!
Bash
git push --force-with-lease
探索式工作流里,可能会削弱"一次只推进一个小结论"的感觉
- 更多分叉确认 / 多征求你的选择 → 这是交互策略,不只是 verbosity
在此时间后关闭硬盘 的意思是:
如果系统判断这个硬盘在这段时间内没有活动,就会让它进入一种更省电的状态。之后你再访问它,它会被重新唤醒。
对你来说,体感上会像这样:
-
盘一段时间没动
-
系统把它"睡了"
-
你一打开 Rider / 访问项目
-
盘先要醒一下
-
然后才开始真正读文件
所以不是"永远关掉"或者"消失不能用",而是:
-
机械硬盘:可能真的停转,再访问时重新转起来
-
外接 SSD / 硬盘盒:通常是控制器、桥接芯片、链路进入省电待机,不一定像机械盘那样"转停",但效果类似,都会带来访问恢复延迟
问题在于,Rider 和 UE 很讨厌这种状态切换。
因为它们会做很多:
-
大量小文件读取
-
索引
-
文件变化监听
-
项目模型分析
-
缓存写入
这些操作不一定是持续满载,而是"读一阵,停一阵,再读一阵"。
所以如果你设成 1 分钟,系统就很容易把外接盘反复睡掉。
PCIe 总线链路本身的省电策略,不是单纯"CPU 性能"或者"显卡频率"。
你可以把它理解成:
-
你的 SSD、独显、无线网卡、某些控制器
-
都可能通过 PCIe 和主板/芯片组通信
-
Windows 可以让这条 PCIe 链路在空闲时进入更省电的状态
-
这套机制就叫 ASPM(Active State Power Management,主动状态电源管理)
你截图里提示也写了:
关闭所有链接的 ASPM
也就是说你现在这个选项控制的是:
要不要让 PCIe 链路在空闲时降功耗。
用 Character 的好处
自带"站在地上走"的那套运动语义
自带重力、地面判定、走路逻辑那一类基础设施
你可以没有人物模型,只保留胶囊体 + 相机
以后如果你想加模型,再往上挂就行,不会推倒重来
也就是说,Character 不等于"必须是第三人称带人形网格"。它更像是"已经帮你准备好了地面角色运动底盘"。