Claude Code 的上下文窗口刚扩展到了 100 万 token,但很多人还在用 20 万时代的老习惯操作------该用 rewind 的时候用纠错,该起子 Agent 的时候死撑一个 session。这篇文章来自 Claude Code 团队负责人 Thariq,把 session 管理的核心技巧说清楚了。
什么是 Context Rot(上下文腐烂)
用过 Claude Code 的人都遇到过这种感觉:聊了很长一段时间之后,模型开始变笨------明明之前理解的东西,现在却绕来绕去。
这不是错觉,有个专门的名词叫 Context Rot(上下文腐烂)。
原理很简单:模型的注意力是有限的,上下文越长,注意力就越分散到那些早就过时的内容上------之前试过但失败的方向、已经不相关的调试信息、废弃的讨论。这些内容不会消失,一直占着位置,干扰模型对当前任务的判断。
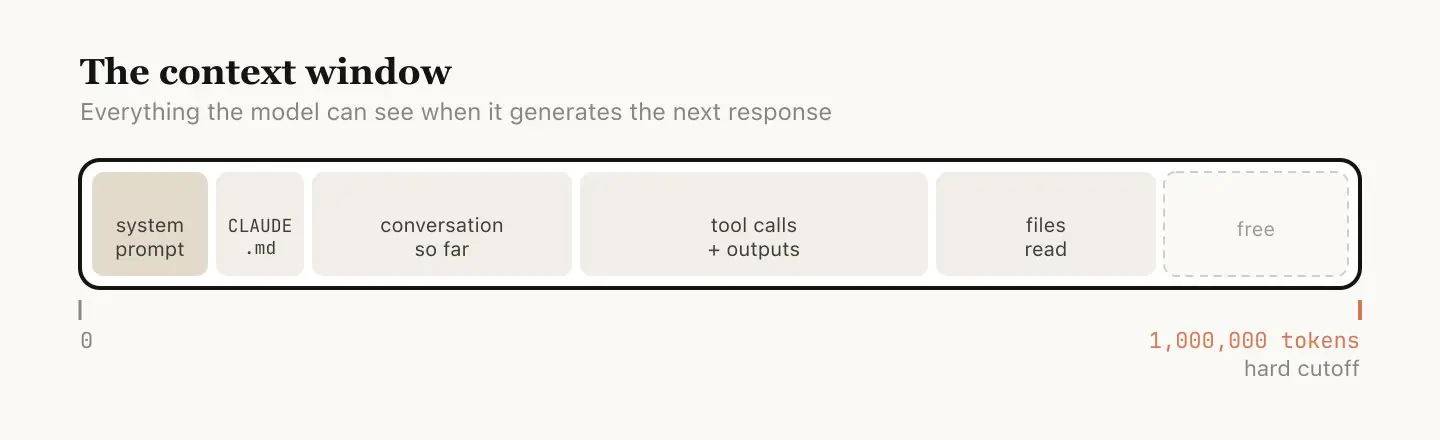
Claude Code 的上下文窗口是 100 万 token,但「能放」不等于「该放」。窗口越大,context rot 带来的问题就越需要主动管理。

每次回复之后,你有 5 个选择
Claude 完成一轮任务之后,大多数人直接继续发消息。但 Thariq 指出这个节点实际上有 5 个选项:
- 继续 --- 同一 session 接着来
- /rewind(Esc Esc)--- 回到某条消息重新开始
- /clear --- 清空 session,写一段手动整理的 brief 开新局
- /compact --- 让模型总结上下文,压缩后继续
- Subagents --- 把下一块工作分给子 Agent,只把结果拿回来
后四个选项都是为了对抗 context rot,只是适用场景不同。

什么时候开新 Session
原则只有一条:新任务,新 session。
100 万 token 让一些大任务变得可行了------比如从零开始搭一个全栈应用、完整重构一个模块。这类任务可以在一个 session 里跑完。
但有个常见误区:任务结束了,紧接着做关联性工作(比如刚写完功能,马上写这个功能的文档),觉得上下文有用就懒得开新 session。
Thariq 的建议是:关联任务用不用开新 session,取决于「Claude 需不需要重新读那些文件」。如果上下文里已经有了刚才操作过的文件内容,留着是合理的;如果已经是一堆无关的调试历史,开新 session 更干净。
Rewind:最被低估的功能
Thariq 说了一句很直接的话:会不会用 rewind,是判断一个人 session 管理水平的标志。
场景:Claude 读了五个文件,尝试了某个实现方向,失败了。你的第一反应可能是直接打「这个方法不行,换个思路」。
但更聪明的做法是:esc esc 回到文件读完之后那条消息,带着刚才学到的教训重新 prompt。
别用 A 方案,foo 模块没有暴露那个接口------直接走 B。
效果的区别一目了然:
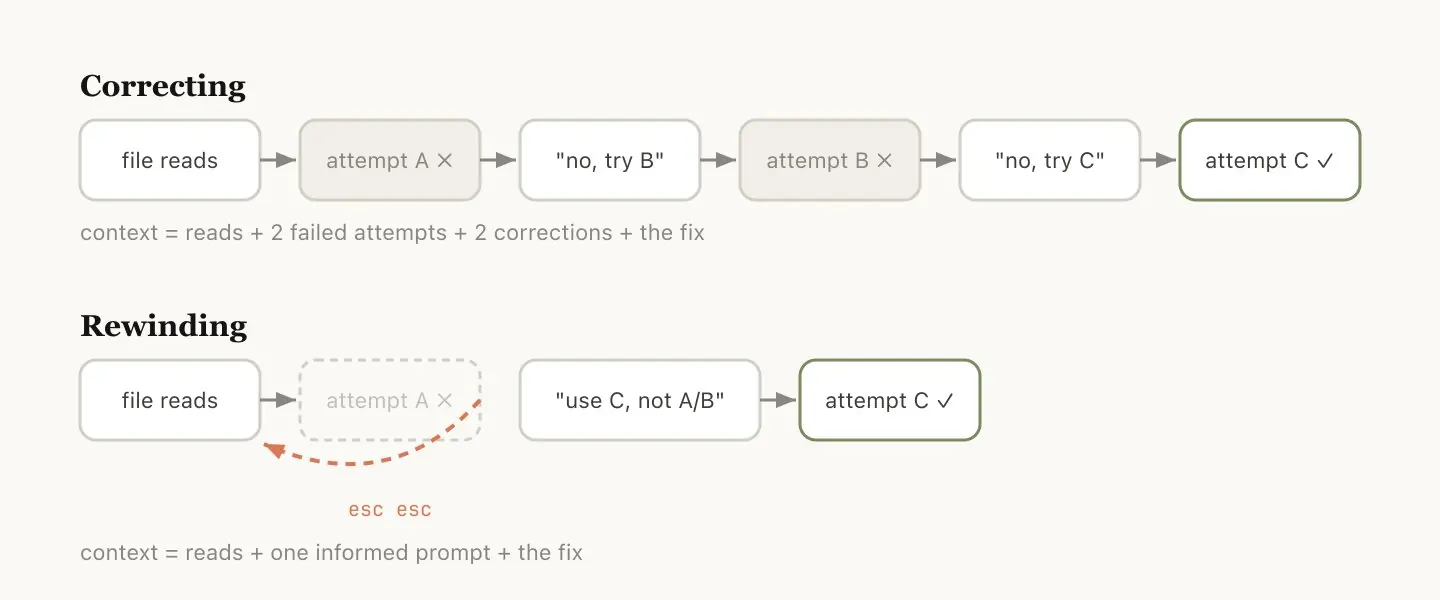
继续纠错会把「失败的尝试」全程保留在上下文里;rewind 把那段历史删掉,拿着干净的上下文重新出发。
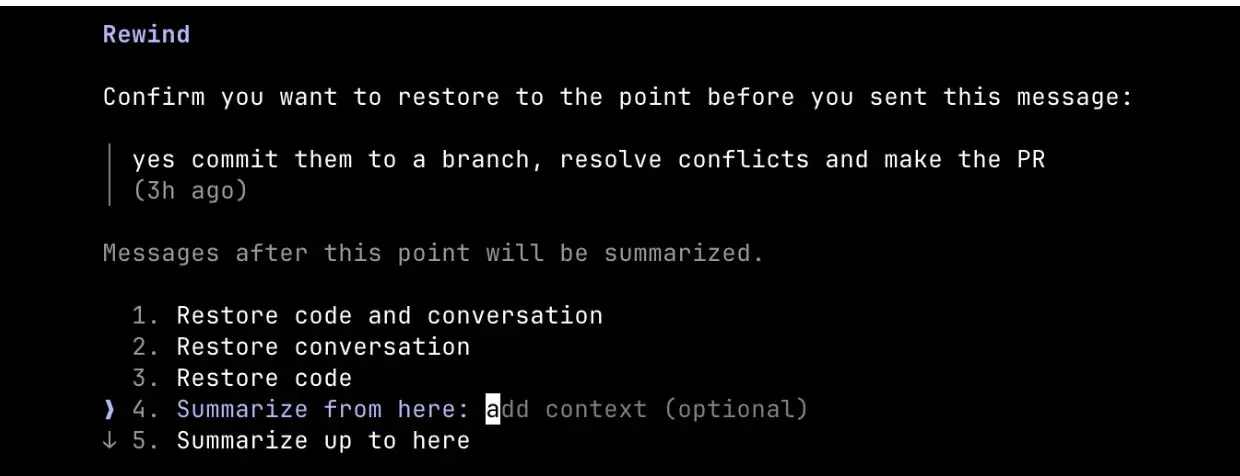
还有一个配合用法:先让 Claude「从这里总结一条交接消息」,把有用的信息提炼出来,复制好,然后再 esc esc 回到之前的节点,把那句总结粘贴进 prompt 重来。
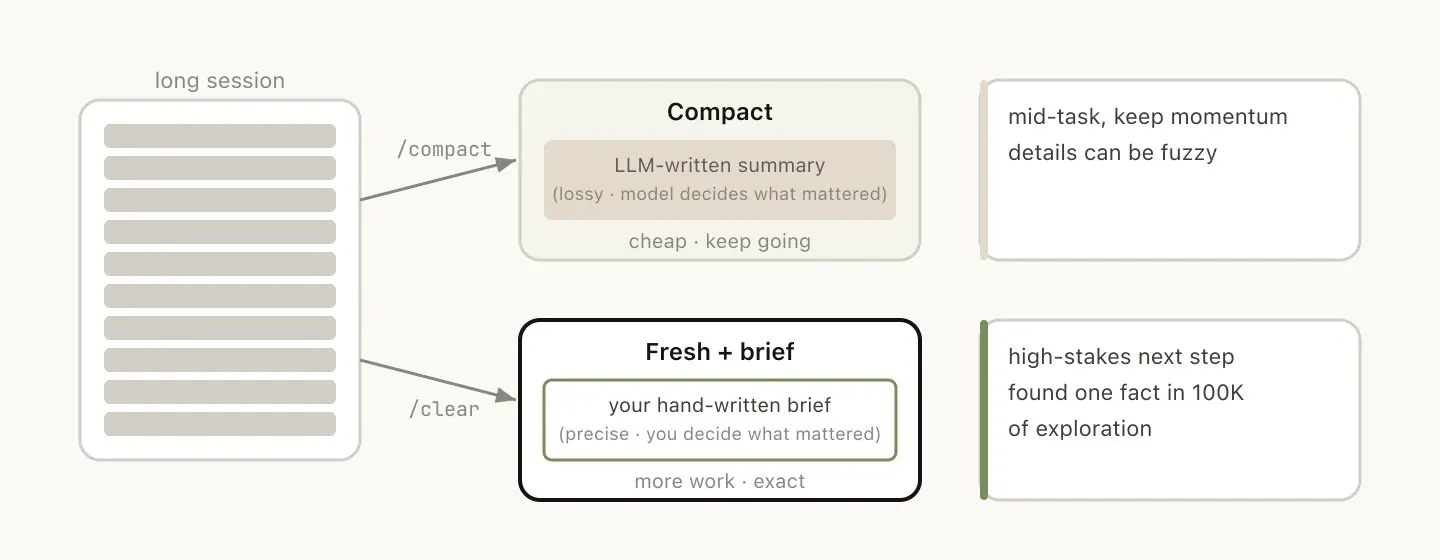
Compact vs. 手动 Clear,两种策略
session 时间长了,有两种减负方式,选哪个取决于你愿意花多少精力:
/compact :让模型自己总结对话,用摘要替换历史记录。省力,但是有损压缩------模型决定什么重要,什么被丢掉。可以加指令控制方向,比如 /compact 聚焦 auth 重构,丢掉测试调试的部分。
/clear:你手动写一段 brief,清空 session 重头开始。费力,但结果是你决定的上下文------「我们在重构 auth 中间件,约束是 X,关键文件是 A 和 B,已经排除了方案 Y」。
什么时候 compact 会翻车?
一个典型场景:长时间调试之后,autocompact 触发,把调试过程压缩了。但下一条消息是「去修一下 bar.ts 里的那个 warning」------因为 session 重心在调试,那个 warning 可能根本没进摘要。
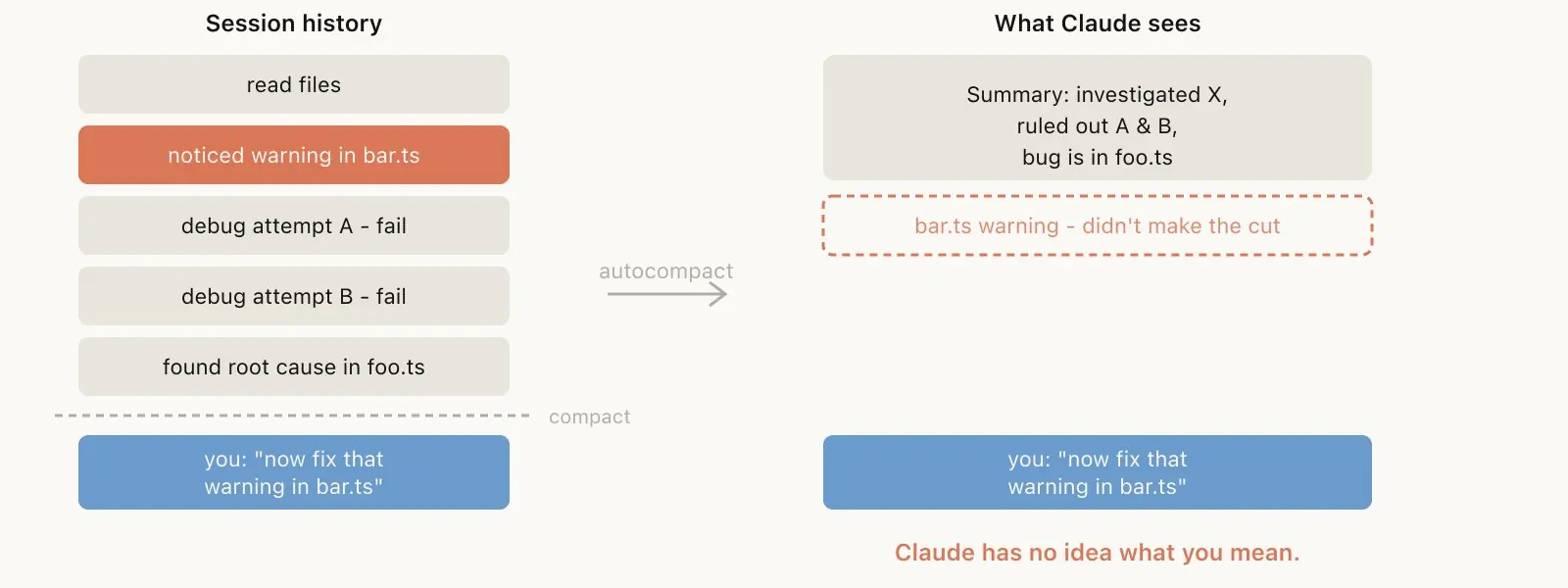
规律就是:context rot 最严重的时候,恰好也是模型判断力最差的时候 ,这时候的自动 compact 质量往往不理想。有了 100 万 token,可以更早触发 /compact,主动给它一个方向,别等到被动触发。
Subagents 不是拿来并行的
很多人把 Subagents 理解成「并行干活的工具」,但 Thariq 给了一个更清晰的定位:Subagents 是一种上下文管理策略。
判断标准只有一个问题:这块工作产生的中间过程,我之后还需要吗?还是只需要最终结果?
如果只需要结果,交给 Subagent------它在自己独立的 100 万 token 里折腾,把总结交回来,主 session 的上下文完全不受影响。
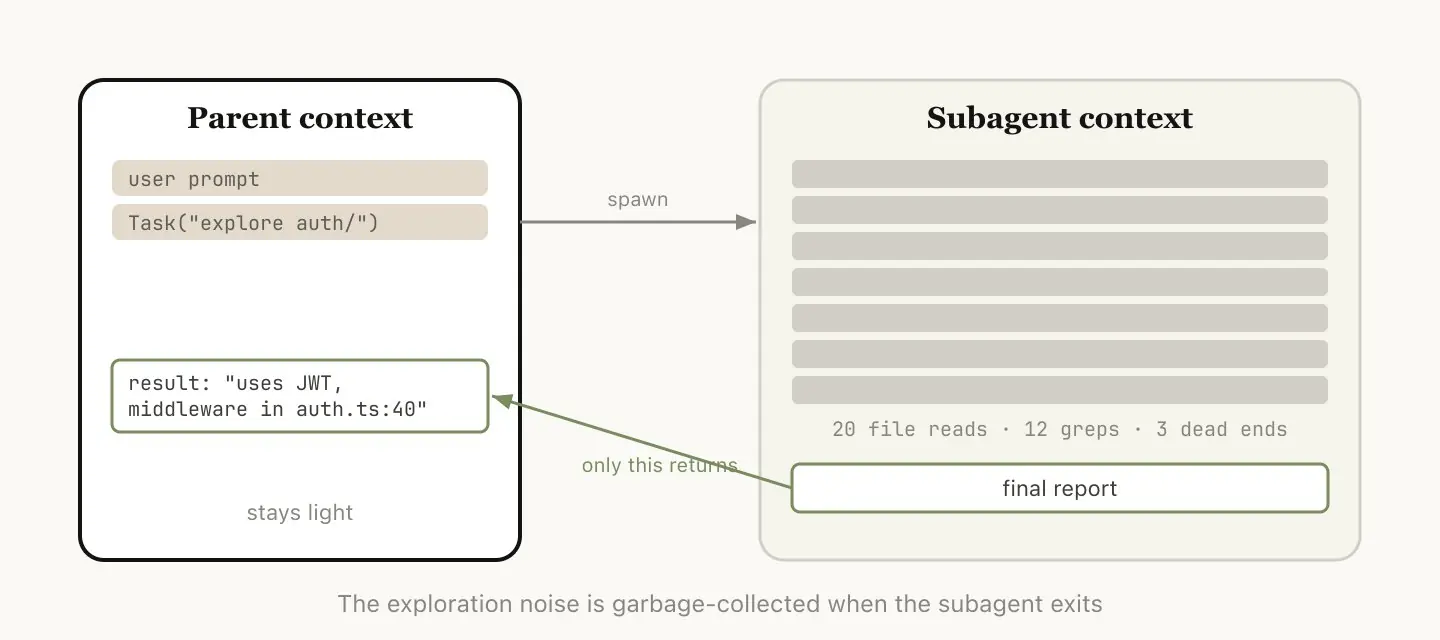
几个实际用法:
"起一个 subagent,根据这个 spec 文件验证一下刚才的实现"
"起一个 subagent,读一下那个 codebase 里的 auth 实现方式,然后你按同样的方式在这里实现"
"起一个 subagent,根据 git 变更写这个功能的文档"
本质上是把「只需要结论、不需要过程」的工作隔离出去,保持主 session 的上下文质量。
一句话总结
有用留着,没用砍掉。
不同情境下怎么选,Thariq 做了一张决策表:

100 万 token 是更大的操作空间,不是「可以不管上下文」的借口。管好上下文,模型就一直好用;任由 context rot 积累,窗口再大也没用。
🦞 想和一群 AI 玩家一起交流实战经验?
在公众号对话框回复「小龙虾 」,加入龙虾养成群------一个专注 AI 工具提效、工作流搭建、自动化实操的交流社群。
只聊 AI 实战干货,一起玩转效率工具 👇
参考链接
- Thariq 原文:x.com/trq212/stat...