用统计量描述数据
-
- [知识点一、数据集中趋势的测度 ★★★](#知识点一、数据集中趋势的测度 ★★★)
- 知识点二、数据离散程度的测度★★★
- 知识点三、数据分布形状的度量★
知识点一、数据集中趋势的测度 ★★★
数据的集中趋势是指一组数据集中于某一中心的水平位置。测度集中趋势也是寻找数据一般水平的中心值或代表值。
常用的数据集中趋势测度值有众数、中位数、分位数、平均数。

例题
【单选题】下列表述正确的是(A)。
A.众数可以用于分析顺序数据
B.几何平均数可以用于分析顺序数据
C.中位数可以用于分析分类数据
D.均值可以用于分析分类数据
(一)平均数
1.算术平均数
根据所掌握数据的不同,算术平均数有不同的计算公根据未经分组数据计算的平均数称为简单平均数。假设一组样本数据为X1,X2,...,Xn,样本量为n,则简单样本平均数,计算公式为:
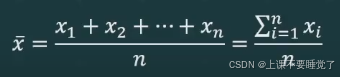
若原始数据较多且对其进行了分组,编制成了频数分布数列,这时要计算算术平均数则应采用加权算术平均数将各组变量值乘以相应的频数,然后加总求和,再除以总频数。如果数据被分为k个组,其计算公式为:
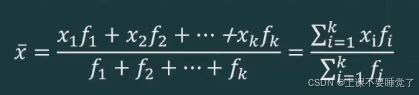
若分组资料为组距分组,资料则相应地取各组的组中值作为该组职工工资的平均水平,再代入上式计算平均工资。
如果有开口的组,
那么在上开口组时,
组中值=该组下限+(下组上限-下组下限)/2;
在下开口组时,
组中值=该组上限-(上组上限-上组下限)/2
算术平均数的计算过程使用了所有数据,因此容易受到极端值的影响,并且严格来讲,无法根据有开口组的分组数据来精确计算算术平均数。
2.几何平均数
几何平均数有两种计算方法:简单几何平均和加权几何平均法。若数据集合中每个数据只出现一次,计算其几何平均数应采用简单几何平均法,其计算公式为:

当数据集合中每个数据出现的次数不止一次时,计算平均数应采用加权几何平均法。其计算公式为:
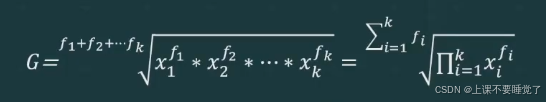
(二)中位数
中位数是将一组数据按照从小到大的顺序排列(或者从大到小的顺序也可以)之后处在数列中间位置对应的数值,是典型的位置平均数,不易受极端值的影响。中位数主要用于顺序数据,也可用数值型数据,但不能用于分类数据。
如果数列是奇数,中位数等于排序之后的第(n+1)/2个数;
如果数列是偶数,中位数等于排序之后的第n/2和
n/2+1个数的平均数。
对于一组数据来说,中位数是唯一的。
如果数据是分组数据,中位数的一种计算方法是:
①确定中位数所在组,计算公式是:
②利用公式计算中位数的近似值,计算时可以采用下限公式,也可采用上限公式,计算公式为:

(三)分位数
把顺序排列的一组数据分割为若干等分的分割点的数值即为相应的分位数。
【两等分】中位数是分位数中最简单的一种,它将数据等分成两分。
【四等分】由于四分位数则是将数据按照大小顺序排序后,把数据分割成四等分的三个分割点上的数值。对原始数据,四分位数的位置一般为(n+1)/4,(2(n+1))/4,(3(n+1))/4。如果四分位数的位置不是整数,则四分位数等于前后两个数的加权平均。
(四)众数
众数,是指一组数据中出现次数或出现频率最多的数值,它是一种位置平均数,不易受极端变量值的影响。
众数主要用于测度分类数据的集中趋势,也可以用来测度顺序数据和数值型数据的集中趋势。一组数据可以有多个众数,也可能不存在众数,对于未分组的数值型数据我们一般很少使用众数。
【总结】平均数、中位数和众数
平均数:
易被多数人理解和接受,实际中用的也较多
但它的主要缺点是更容易受少数极端数值的影
响,对于严重偏态分布的数据,平均数的代表性较差。
中位数和众数:
提供的信息不像平均数那样多,但它们也有优
点,如不易受极端值的影响,具有统计上的
稳健性。
当数据为偏态分布,特别是偏斜程度较大时,
可以考虑选择中位数和众数,这时它们的代表
性要比平均数好。
例题
【单选题】众数常用来反映数据的集中趋势,它(D)。
A.不适用分类数据
B.不适用严重偏态的数据
C.不受极端变量值的影响
D.受极端变量值的影响
【判断题】顺序数据无法计算中位数。(❌️)
【单选题】5名股票经纪人的年收入分别为19万元,
28万元、46万元、39.5万元和150万元。以下指标中,更适宜反映5名经纪人收入水平的是©。
A.简单平均数
B.加权平均数
C.中位数
D.众数
知识点二、数据离散程度的测度★★★
反映数据离中趋势或离散程度的常用测度指标有:异众比率、极差、四分位距、平均差、标准差、方差和离散系数等。
(一)异众比率
异众比率是指非众数组的频数占总频数的比率,其计算公式为:
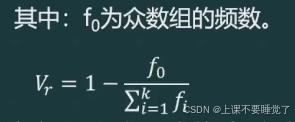
异众比率主要用于衡量众数对一组数据的代表程度。异众比率越大,说明非众数组的频数占总频数的比重越大众数的代表性越差;异众比率越小,说明非众数组的频数占总频数的比重越小,众数的代表性越好。
【单选题】在一项对4G用户的调查中调查了1000人其中有663人使用移动运营商的网络,则异众比率是(A)。
A.33.7%
B.66.3%
C.150.8%
D.50.8%
(二)极差
极差又称全距,是最简单的离散指标,它是一组数据中的最大值和最小值之差,用R表示。其计算公式为:
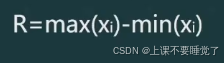
(三)四分位距
四分距是上下四分位数之差,也称为样本的内距或四分位差,用Qd表示。其计算公式为:

其中QU、QL,分别表示上四分位数(第三个四分位数)和下四分位数(第一个四分位数)。

此外,由于中位数处于数据的中间位置,因此四分位距的大小在一定程度上也说明了中位数对一组数据的代表程度。四分位距主要用于测度顺序数据的离散程度。对于数值型数据也可以计算四分位距,但它不适合分类数据。
(四)平均差
平均差是一组数据与其均值之差的绝对值的平均数
也称为平均绝对差,它利用了全部数据计算,因此容易受到极端值的影响,主要用于数值型数据,因其数学性质较差,不常使用。其计算公式为:
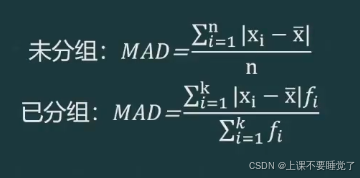
(五)方差与标准差【重点】
方差(variance)是将各个变量值与其均值离差平方
的平均数。它反映了样本中各个观测值到其均值的平均离散程度;标准差是方差的平方根。


总体方差的分母为N,而样本方差的分母却为n-1(自由度),这是因为当我们用n-1为自由度的样本方差s2去估计总体方差σ2时,它恰好是σ2的无偏估计量。
在一个统计样本中,其标准差越大,说明它的各个观测值分布的越分散,它的集中趋势代表性就越差。
反之,其标准差越小,说明它的各个观测值分布得越集中,它的集中趋势代表性就越高。
【判断题】标准差是测量每一个数值与平均值的差异程度。(❌️)
【解析】标准差是各个变量值与其均值离差平方的平均数的算术平方根,它反映了样本中各个观测值到其均值的平均离散程度。平均差是一组数据与其均值之差的绝对值的平均数,平均差反映了每一个数值与平均值的差异程度。
(六)离散系数【重点)
为什么要计算离散系数?因为标准差的大小会受到数据本身数值大小或者计量单位不同的影响,如:

虽然这两个数列的标准差相同,但是两数列的差异程度却不相同。明显地,第一个数列的差异程度要大于第二个数列。
离散系数也称作变异系数、标准差系数,它是将一组数据的标准差除以其均值,用来测度数据离散程度的相对数。其计算公式是:

(七)标准分数【重点】
标准分数(Z-score)也称作标准化值或Z分数,它是
变量值与其平均数的离差除以标准差后的值,用以测定某一个数据在该组数据中的相对位置。其计算公式为:

【单选题】张红是某大学一年级的学生,她参加了微积分的两次考试,第一次考试中,全班的平均成绩75分标准差10分,第二次考试中,全班的平均成绩是70分,标准差是15分,张红每次考试成绩都是85分,假定考试分数近似从正态分布,则张红两次考试的成绩在班里的相对位置©。
A.不相同,第一次比第二次好
B.不相同,第二次比第一次好
C.相同
D.因为不知道班里人数而无法判断
【多选题】抽样调查得到6 户家庭的住房面积(平方米)分别是:60、80、80、90、100、130,这6户
家庭住房面积的(ACE)。
A.平均数为 90
B.中位数为 80
C.众数为 80
D.极差为 60
E.方差为 560
知识点三、数据分布形状的度量★
集中趋势和离散程度是数据分布的两个重要特征。但要全面了解数据分布的特点,我们还须知道数据分布的形态是否对称,偏斜程度以及分布的扁平程度如何。偏态和峰态可以用来测度数据的分布形状。
(一)偏态系数
数据的不对称性称为偏态,测度数据的偏斜程度用偏态系数(SK),偏态系数的计算方法有很多(如皮尔逊偏态系数、鲍莱偏态系数、矩偏态系数等)
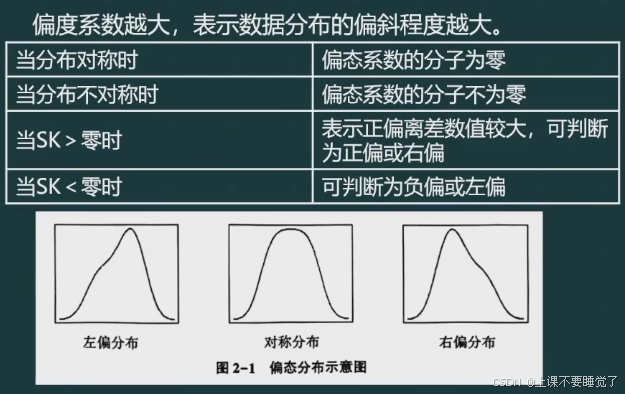
当数据呈单峰对称分布时,均值、中位数、众数三者大小相等;
①当呈左偏分布时:众数>中位数>均值;
②当呈右偏分布时:均值>中位数>众数。
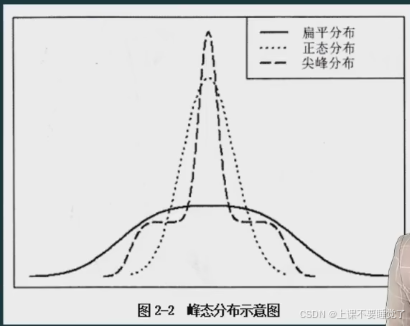
(二)峰度系数
峰态通常是与标准正态分布相比较而言的。如
果数据服从标准正态,则峰度系数等于零;若峰度系数的值明显不为零,则表明数据的分布比正态分布更平或更尖。