Oracle数据库索引簇表和哈希簇表概述
基本概念
表簇是一组表,它们共享公共的列,并将相关的数据存储在相同的数据块中。
当表被聚簇时,单个数据块可以包含多个表中的行。例如,一个块可以同时存储来自 employees 表和 departments 表的行,而不只是单个表中的行。
簇键是所有被聚簇的表的共有列或列集。例如,employees 表和departments 表共享 department_id 列。
创建表簇时或者创建被添加到表簇的每个表时,需要指定簇键。
簇键值是一组特定行的簇键列的值。
包含相同簇键值的所有数据(例如department_id=20),物理上存储在一起。
每个簇键值在簇或簇索引中只存储一次,而无论在这些不同表中有多少行包含这个值。
表簇优势
如果多个表主要是被查询 (而不是修改) ,且各表中的记录是经常被一起查询或联接,在这些情况下可以考虑将他们聚簇化。
因为表簇将不同表中的相关行存储在同一个数据块中,被正确使用的表簇相比非聚簇表具有下列优点:
对于被聚簇表的联接,可以减少磁盘 I/O。
对于被聚簇表的联接,可以提高访问速度。
只需更少的空间来存储相关的表和索引数据,因为簇键值不会为每行重复存储。
表簇不适合场景
会经常被更新的表,数据库块中包含多个表数据,频繁更新会导致数据块变动很大,特别是如果需要更新簇键列,会需要额外更多的工作。
经常需要全表扫描的表,数据库块中包含多个表数据,需要扫描的块更多。
需要被截断的表,数据库块中包含多个表数据,不能直接截断。
表簇典型使用场景
Oracle数据库中的数据字典表,很多都是以表簇形式存储,因为元数据表之间的关联查询特别多。
索引簇表概述
索引聚簇是使用索引来查找数据的表簇。
簇索引是一个簇键上的 B 树索引。
簇索引必须先被创建,然后才能将行插入到簇表中。
与非聚簇表上的索引类似,簇索引被单独管理,簇索引也可以与表簇存在于不同的表空间中。
示例
使用簇键 department_id 来创建聚簇 employees_departments_cluster
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 512;
CREATE INDEX idx_emp_dept_cluster ON CLUSTER
employees_departments_cluster;
备注:未指定hashkey,所以默认类型为索引表簇。
然后在该簇中创建雇员表和部门表,并指定 department_id 列为簇键,如下所示 (省略号表示放置列定义的地方)
CREATE TABLE employees ( ... )
CLUSTER employees_departments_cluster
(department_id);
CREATE TABLE departments ( ... )
CLUSTER employees_departments_cluster
(department_id);
最后,将行添加到 employees 表和 departments 表中。
数据库在物理上将雇员表和部门表中每个部门的所有行都存储在相同的数据块中。
数据库以堆的形式存储行,并使用索引定位他们。下图显示了包含 employees 表和 departments 表所构成的employees_departments_cluster 表簇。
数据库将部门 20 的雇员所在的行存储在一起,部门 110 的行也存储在一起,依次类推。如果表未被聚簇,那么数据库将不保证相关的行被存储在一起。
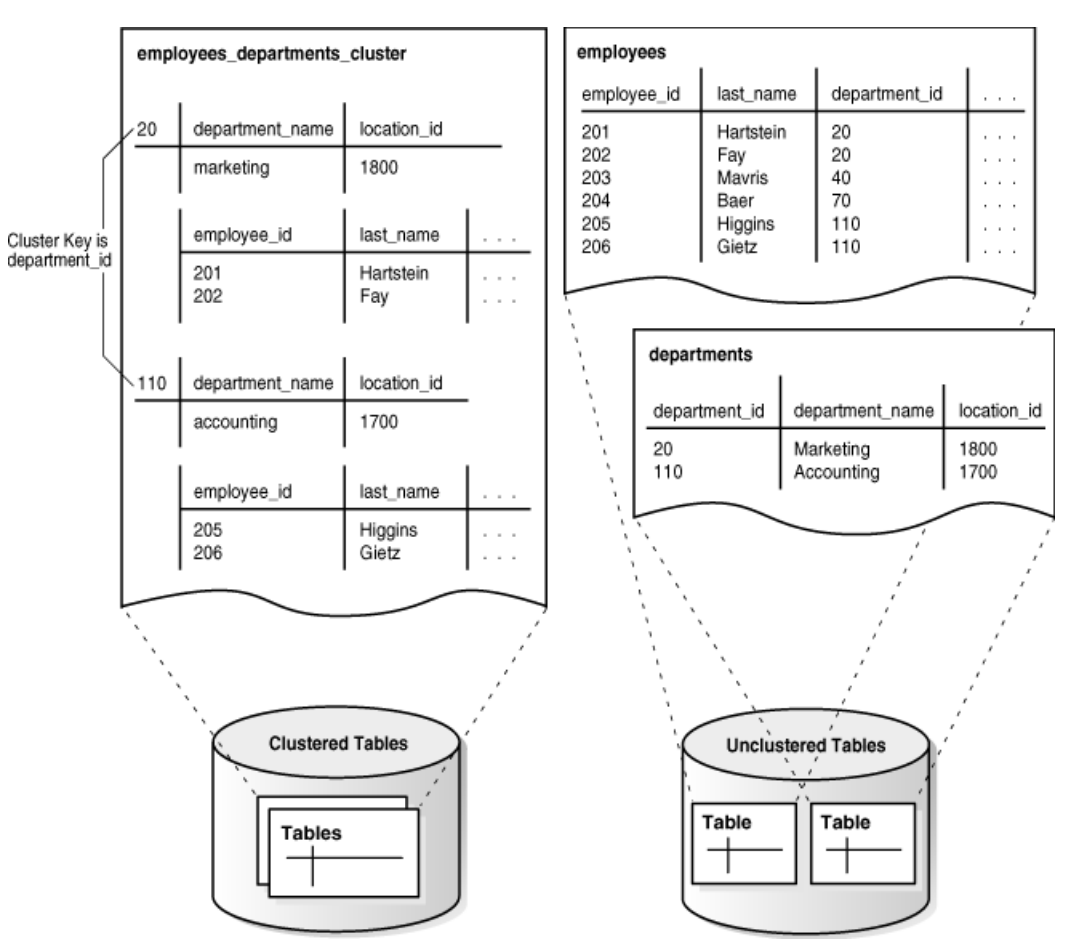
B 树簇索引把簇键值与数据所在块的数据库块地址 (DBA) 关联起来。例如,键 20 的索引条目显示包含部门 20 的雇员数据所在块的地址:20,AADAAAA9d
哈希簇表概述
哈希表簇没有单独的簇索引存在。
对一个哈希簇来说,数据本身就是索引。
除了索引键被替换为一个哈希函数之外,哈希簇就像一个索引聚簇。
为查找或存储在哈希簇中的一个行,数据库将哈希函数应用到行的簇键值。得出的哈希值对应到一个聚簇中的数据块,数据库则按发出的语句读写该块。
哈希是一种可选的表数据存储方法,用来提高数据检索的性能。
哈希簇的一个限制是只能等值查询,在非表簇键上的范围扫描不可用(除非单独建立索引)。
哈希表簇优势
在满足以下条件时,哈希簇可能是有益的:
经常被查询,但不经常被修改的表。
哈希键列经常使用等值条件查询 ,例如, WHERE department_id = 20。对于这样的查询,簇键值是已经过哈希运算的。哈希键值直接指向存储行的磁盘区域。
表创建规划之初,可以合理地猜出哈希键的数目,和每个键值所存储的数据的大小。
相对索引表簇,hash表簇优劣
对索引化聚簇,数据库用存储在一个单独的索引中的键值查找表行。要查找或存储已索引的表或索引化聚簇中的一个行,数据库必须执行至少两个 I/O 操作:(1)为查找或存储在索引中的键值,需要一个或多个 I/O。(2)为读取或写入表或表簇中的行,还需要一个 I/O。
**优势:**哈希表簇,针对键值查找表行,无需访问索引,直接通过计算的hash值,定位到具体的数据块。
**劣势:**如果是针对键值范围查询,hash表簇只能全表扫描。索引表簇则可以直接顺序访问索引来定位数据。
创建哈希簇
簇键是由簇中各表共享的单键列或复合键列(与索引聚簇的键类似)。
哈希键值是插入到簇键列的实际值或可能值。例如,如果簇键是 department_id,那么哈希键键值可能是 10、 20、 30,等等。
Oracle 数据库使用一个哈希函数,接受任意多个哈希键值作为输入,经过排序并哈希到有限数量的桶。每个桶都有一个唯一的数字 ID,称为哈希值。
每个哈希值都映射到哈希键值(部门 10、 20、 30,等等)对应行所在块的数据库块地址。
使用 CREATE CLUSTER 语句创建一个哈希簇(与创建索引化聚簇类似),但得加上一个哈希键。哈希值的数量取决于哈希键。
创建示例
表规划之初,可能存在的部门的数量是 100,所以 HASHKEYS 设置为 100。
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 8192 HASHKEYS 100;
创建聚簇 employees_departments_cluster 后,可以在该簇中创建employees 表和 departments 表。然后可以将数据装载到哈希簇中
CREATE TABLE employees ( ... )
CLUSTER employees_departments_cluster
(department_id);
CREATE TABLE departments ( ... )
CLUSTER employees_departments_cluster
(department_id);查询哈希簇表示例
由数据库确定如何哈希用户输入的键值。例如,假设用户经常执行如下的查询, 为 p_id 输入不同的部门 ID 号:
SELECT *
FROM employees
WHERE department_id = :p_id;
SELECT *
FROM departments
WHERE department_id = :p_id;
SELECT *
FROM employees e, departments d
WHERE e.department_id = d.department_id
AND d.department_id = :p_id;解释说明
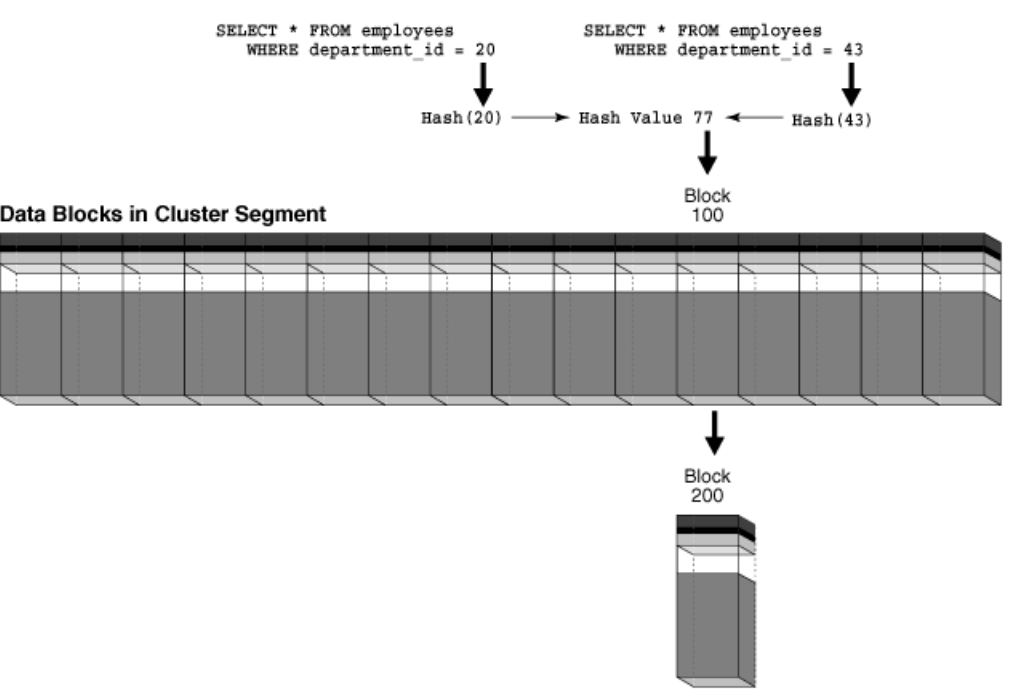
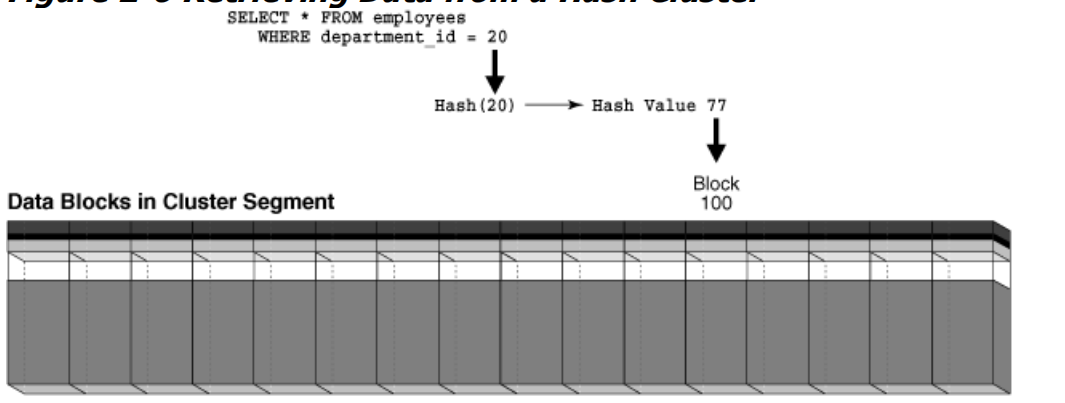
如果某个用户查询 department_id = 20 的雇员,那么数据库可能将此值哈希到桶 77。
如果某个用户查询 department_id = 10 的雇员,那么数据库可能将此值哈希到桶 15。
数据库使用内部生成的哈希值来定位包含请求的部门的雇员行所在的数据块。
将哈希簇段显示为一行水平排列的块。如图所示,查询只需单个 I/O就可以检索到数据。
哈希簇变体
单表哈希簇
是哈希簇的一个优化版本,一次只支持一个表。
哈希键和行之间存在一一映射。
当用户需要通过主键快速访问表时,单表哈希簇会很有用。例如,用户经常通过 employee_id 查找一个雇员表中的雇员记录。
排序哈希簇
存储哈希函数的每个值对应的行,通过某种方式,数据库可以有效地把他们按已排定的顺序返回。
数据库在内部执行优化的排序。对于需要总是按排定顺序来消费数据的应用程序,这种技术可能会更快的检索到数据。例如,应用程序可能总是按订单表的 order_date 列进行排序。
哈希簇存储
Oracle 数据库为哈希簇分配空间的方式不同于索引表簇。
在上面创建示例中,HASHKEYS 指定可能存在的部门数,而 SIZE 指定与每个部门相关联的数据的大小。
数据库将基于以下公式计算存储空间:HASHKEYS * SIZE / database_block_size,因此,如果示例中的块大小是 4096 字节,那么数据库至少要为该哈希簇分配 200 个数据块。
哈希冲突
多个输入的值(不同值)被哈希为相同的输出值称为哈希冲突。
Oracle 数据库并不限制可以向哈希簇中插入的哈希键值的数目。例如,即使 HASHKEYS 是 100,但这不会阻止你向部门表中插入 200 个不同的部门。但是,当插入的哈希键值的数目超过哈希键(HASHKEYS 的设定)数目时,则会发生哈希冲突,哈希簇检索效率会降低。
可以通过重新创建具有不同HASHKEYS 值的表簇来解决这个问题。
当哈希冲突发生时,从哈希簇检索数据,如下图所示: