测试环境: nextcloud(docker部署网盘)+caddy(goals 反向代理 默认http2协议)
核心结论

乱序的根本原因在于观测路径而非业务数据流:BPF 程序在每次 read() 完成时,通过 bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, ...) 将明文副本写入当前 CPU 对应的 Perf ring buffer。所谓"不同 CPU",指的是多次 hook 触发时,BPF 程序可能在不同 CPU 核心上执行,导致样本被写入各自 CPU 对应的 Perf ring buffer 中,形成多生产者(多 CPU 各自 ring)单消费者(用户态合并读取)模型;合并时无法保证全局顺序等于探针触发顺序,在 HTTP/2 二进制帧与多路复用场景下(如文件上传)表现尤为明显。
1. 两条独立的 TCP 流:Client ↔ Caddy ↔ Server
在反向代理场景中,连接并非从 Client 直达 Server,而是由两段独立的 TCP 连接构成。每段连接在内核中各有独立的 struct sock,也各有独立、有序的字节流接收语义。
- 对外 HTTPS 连接 :TLS 终结于 Caddy 进程。
gotls的 uprobe 钩子挂载在 Caddy 与 Client 之间的crypto/tls明文 I/O 路径上。 - 对内连接 :Caddy 到本机 Server 是另一条 TCP 连接(通常为明文 HTTP),对应另一对 socket 与 fd。
gotls不会自动覆盖这段连接,除非单独配置 hook。
流 B: 到本机后台
流 A: 对外 HTTPS
TCP + TLS
常为明文 HTTP
Client
Caddy
Caddy
Server
2. 从网卡到 Caddy 明文:顺序由谁保证?
- 网卡收发、软中断处理、IP 层与 TCP 层解析,都可以在不同 CPU 上并行处理不同的 IP 包。但同一条 TCP 连接只对应一个
struct sock,其接收队列(sk_receive_queue)是唯一的,所有可供read()读取的数据都进入这个队列,而不是每个 CPU 各自拥有一份业务 payload。 - TCP 序号、连续前缀、乱序队列(out-of-order)保证只有逻辑连续的字节才作为流前缀交给 socket;而应用层调用
read(fd)时只关心文件描述符,不感知底层实现 - 数据包在 CPU 上完成协议栈处理后,内核(如 TCP 层)会将可交付的数据挂入该连接对应的 sock 接收队列(入队);当用户态调用
read或recv时,内核通过tcp_recvmsg等函数从同一个 sock 队列中取出数据拷贝到用户缓冲区(出队)。入队和出队可能在不同 CPU 上发生,但数据始终来自该连接唯一且有序的 sk_receive_queue,因此用户态通过 read 拿到的字节流是严格有序的 - Caddy 侧调用链:HTTPS 读取逻辑封装在
modules/caddyhttp/app.go等配置的http.Server中,实际发生在net/http与tls.Conn内部
Go 侧调用链:crypto/tls.Conn.Read→readRecord→ 从c.conn(底层net.Conn)读取密文;internal/poll.FD.Read最终调用syscall.Read(fd.Sysfd, buf),仅依赖文件描述符与缓冲区
用户态 Caddy
入向 包可在多 CPU 处理
CPUa 处理部分包
CPUb 处理部分包 可能乱序到达
同一 TCP 连接
一个 struct sock
一个 sk_receive_queue
SEQ 与 ofo 重组
线程在 CPUx 调用 read fd
内核 tcp_recvmsg 等
从该 sock 唯一队列取密文到用户缓冲
tls Conn Read 解密得明文
3. BPF 观测从何处"分叉"?
- gotls 的 hook 点:gotls 使用用户态 uprobe 或 uretprobe,钩在 Go crypto/tls(如 writeRecordLocked、Conn.Read 返回点)
- 入向 Read 路径:Client 发包经网卡、IP、TCP(多核可参与,但更新同一 sock),sk_receive_queue 入队,某线程在某 CPU 上 read(fd) 得密文,crypto/tls 解密后明文进入本次 Read 的缓冲区 b。主路径继续被 Caddy 与 net/http 消费;
与此同时 uprobe gotls_read 用 bpf_probe_read_user 拷贝 b 填入 event,再 bpf_perf_event_output(BPF_F_CURRENT_CPU)进入 perf ring,用户态 ecapture读 perf
uprobe 是旁路,不会截断或替代正常 TCP/sock 处理流程,协议栈照常运行;单次 hook 拷贝的 payload 本身是正确的、有序的一段。乱序只发生在多次 hook 产生的多条 Perf 记录之间,而非单次记录内部。ecapture用户态需要处理的是多条 Perf 事件之间的先后顺序。
Client 发包
网卡 多 CPU 可参与
IP TCP 更新同一 sock
sk_receive_queue 入队
read fd 密文进用户态
crypto tls 解密 明文进缓冲 b
主路径 Caddy net http 消费
观测 uprobe gotls_read
bpf_perf_event_output CURRENT_CPU
perf ring 按 CPU 分槽
用户态ecapture读 perf 乱序
4. PERF_EVENT_ARRAY 与 bpf_perf_event_output、乱序根因
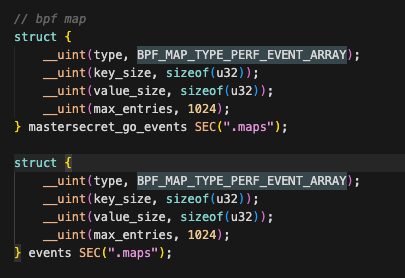
BPF_MAP_TYPE_PERF_EVENT_ARRAY 以 CPU 为索引关联 Perf 环形缓冲区,每个逻辑 CPU 对应一个槽位(即一块 ring buffer)。bpf_perf_event_output(ctx, events, BPF_F_CURRENT_CPU, data, size) 将事件写入当前运行 BPF 程序的 CPU 所对应的那块 ring,而非按文件描述符(fd)或连接进行分槽。
这一设计旨在高并发场景下,让每个 CPU 写入自己的缓冲区,从而减少多核争抢单一队列所带来的锁竞争。其代价是:用户态必须从多个 ring 中合并读取事件,而合并后的顺序不保证等于全局 hook 的时间顺序 。原因在于,多个 CPU 的 ring 各自存在积压,当用户态的 perf.Reader 轮询合并读取时,先返回的记录未必是全局时间上最早的那一条。
这种"乱序"是当前 BPF 输出模型的常见特性,并非实现缺陷。补救措施通常有两种:
- 在用户态按时间戳等字段进行排序 : eCapture GoTLS Perf 事件有序下发
- 改用
BPF_MAP_TYPE_RINGBUF(共享内存环形缓冲区)作为传输设计
4.1 RINGBUF vs PERF:对比与选型
| 特性 | PERF (BPF_MAP_TYPE_PERF_EVENT_ARRAY) |
RINGBUF (BPF_MAP_TYPE_RINGBUF) |
|---|---|---|
| 缓冲结构 | 每 CPU 一个 ring | 全局共享一块 ring (MPSC) |
| 写入 | 样本进入当前 CPU 对应槽 | 所有 CPU 提交到同一 FIFO |
| 用户态读取 | 多缓冲区轮询合并,顺序易乱 | 单 reader,顺序为提交序(通常更直观) |
| 全局全序保证 | 无,需 ktime 排序 | 无,极端情况仍需 ktime 兜底 |
| 内核版本要求 | 广泛支持,成熟 | 较新内核(常见 5.8+) |
| 大包/吞吐 | 久经考验 | 需调优 ring 大小,注意丢包 |
需要注意的是,BPF_MAP_TYPE_RINGBUF 采用多生产者单消费者(MPSC)模型,所有 CPU 竞争写入同一块共享 ring,会引入新的竞争 ,在高并发场景下性能可能不如 Per-CPU 的 PerF 方案。因此,RINGBUF 更适合对顺序要求较高、但对并发写入性能不那么极致的场景,而非无条件替代 PERF。
BPF_MAP_TYPE_RINGBUF
CPU0 写共享 ring
内核自旋锁保护
(多核竞争)
CPU1 写共享 ring
CPU2 写共享 ring
用户态单队列读取
(顺序好)
BPF_MAP_TYPE_PERF_EVENT_ARRAY
CPU0 写 ring0
(无竞争)
用户态合并读取
(可能乱序)
CPU1 写 ring1
(无竞争)
CPU2 写 ring2
(无竞争)
5. 常见误区澄清
| 误区 | 事实 |
|---|---|
| eBPF 丢掉了 sock 的顺序 | 单次 hook 拷贝的 payload 是正确有序的;乱的是多次事件之间的投递顺序。 |
| 乱序是 eBPF 独有的 | 镜像抓包没有 Perf 多 ring 合并问题,但 TCP 层段乱序与重组依然存在。 |
单次 bpf_perf_event_output 会打乱字节 |
不会。单次 output 拷贝的是连续片段。乱序发生在多次事件之间。 |
| 乱序与 Go 语言有关 | 无关,这里不是goroutine之类的引入的。是 Perf 传输与合并读模型导致的。 |
| Caddy 正常 read 与 hook 采样乱序 | hook 拷贝的是已解密的明文切片;乱的是观测事件顺序。差别在于数据结构:业务是单 sock 队列,观测是每 CPU 的 Perf ring。 |
5.1 eBPF Perf 观测与镜像抓包对比
| 特性 | eBPF Perf 观测 | 镜像抓包 (如 tcpdump) |
|---|---|---|
| 面临网络层乱序? | 是(IP包可能乱序到达) | 是(IP包可能乱序到达) |
| 内核是否已为应用排序? | 是,应用read()到的是已排序流 |
否,抓取的是排序前的原始包 |
| 有"多缓冲区合并"问题? | 有,这是其乱序主因 | 没有,数据从单一通道顺序读取 |
| 最终用户看到的数据顺序 | 经过合并,可能乱序 | 未经合并,可能乱序(但反映了网络真实到达顺序) |
6. ecapture gotls实现相关文章
文章都在ecapture专栏里
eCapture GoTLS Perf 事件有序下发
ecapture捕获TLS明文流量
ecaptureConnect Events获取
ecapturego1.20 tls fd抽取
ecapture eBPF hook gotls 收包乱序根因分析
ecapture gotls:三种模式实现说明与上层应用职责