https://blog.csdn.net/cy413026/article/details/136461145
本人早期的文章,内容有很多错误,请尽量参考下文
1.一致性总线
一致性总线的snoop只在RN-F和Interconnect之间传输,RN-F节点是一个mst(cpu core)+cache的混合体
mst+cache作为一个整体作为mst用一组ACE/CHI bus连接到Interconnect上,而不是mst用一组mst bus连到Interconnect,cache做slv在用另一组slv bus连到Interconnect。
cpu和cache作为mst去读写更高层级的cache或者ddr,是可以合并共用一个mst bus的。
但是core0去读的数据在core1的cache,难道不是core1的cache作为slv吗?
其实不是的,这个过程是
core0作为mst发读请求到Interconnect,Interconnect查询cacheline状态发现,在其他core的cache上有副本
就向这些core发送snoop,假如core1收到snoop后发现自己的cache上是最新数据,就会响应snoop,并把最新数据作为snoop data发送给Interconnect
Interconnect再把数据转发给core0
core1 cache的数据是通过snoop通道发给Interconnect的。
看起来Interconnect和core1 cache的snoop操作类似于Interconnect做mst,core1 cache做slv。
但是在一致性互联架构中,我们不把snoop操作划分mst和slv
-----在ACE协议中,就是叫Interconnect和manager
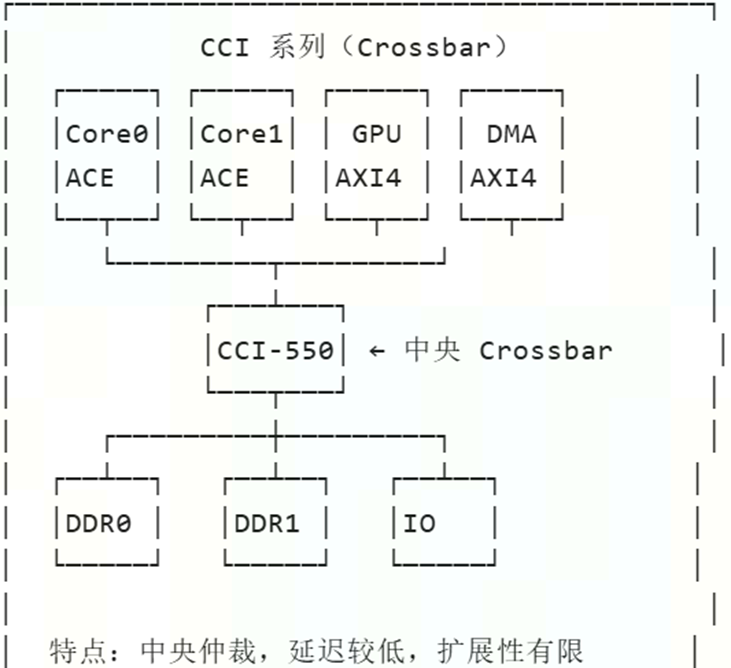
1.1 ACE与CCI550
ACE是AMBA4的AXI coherency Extensions,而CCI550(cache coherent interconnect)就是基于ACE协议的一致性互联网络
1.1.1 ACE bus信号
ACE Bus是axi bus的扩展,增加了处理snoop的3个通道,并对原有的AR/R/AW通道增加了一些信号
新增的3个通道:
snoop address(AC):Interconnect发送snoop地址到对应的cache,但这个地址来自于发起请求的mst
snoop response(CR):被snoop的cache提供snoop传输的响应
snoop data(CD):可选,是被snoop的cache发往Interconnect的数据(读事务和clean snoop),如果是读事务这个数据要经过Interconnect返回mst
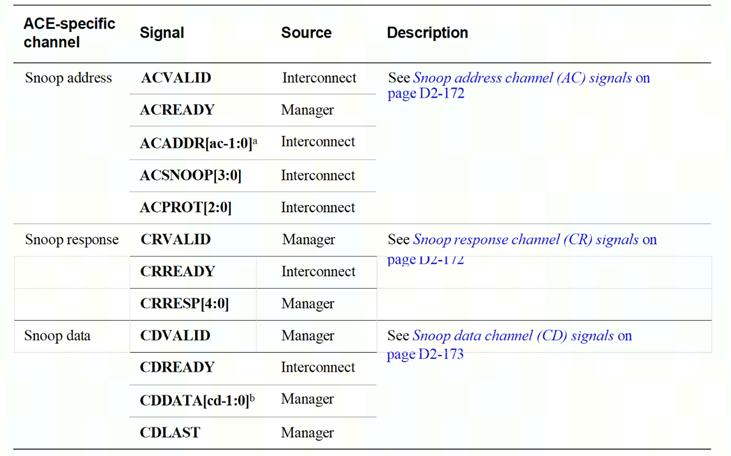
- 既然对于cache行的操作,那么就要告诉它一个地址,因为如果不给地址,那不就不知道对那个cacheline操作;
- ACPROT2:0:因为访问有安全和非安全的区别,特权及非特权,所以需要有PROT信号;
- ACSNOOP3:0 :因为snoop transaction有很多种,比如 clean, invalidae,clean share等等,这些snoop transaction就是通过 ACSNOOOP3:0 来区分的。
- CDDATAx:0 用来将snoop数据传回给 coherency总线,然后 coherency总线决定是将数据写入memory总还是传给其他master。
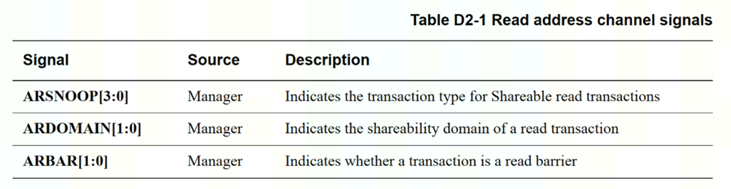
AR通道增加信号
R通道增加信号

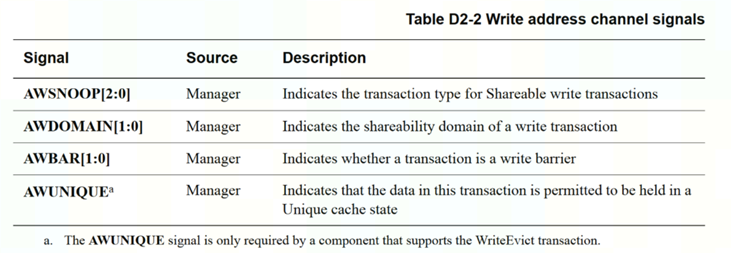
AW通道增加信号
1.1.2 CCI550互联总线
CCI550是基于snoopFilter的总线snoop,在CCI550中没有目录(directory)的概念,但是为了能够更精简的发送snoop【传统广播snoop是对所有mst进行侦听】
在cci550的crossBar位置增加了一个大表项,该表记录了:
- 缓存行位置 :记录每个缓存行可能存在于哪些 Master 的缓存中
- 缓存行存在性 :但不一定精确记录状态(如是否 Shared、Modified 等)
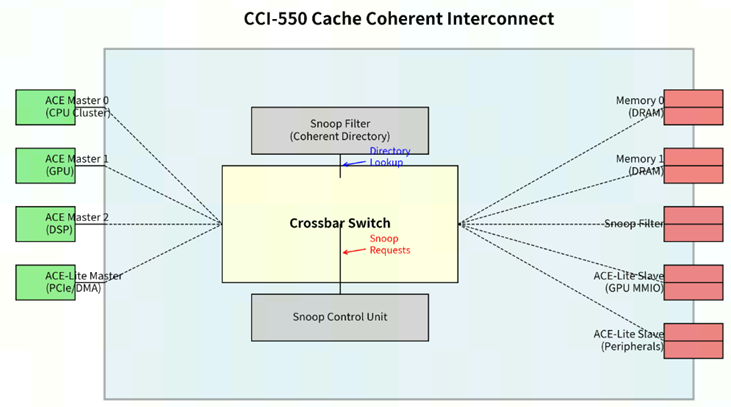
工作流程:
- 请求到达 :主设备 M1 发起一个一致性读请求(如
ReadShared)。 - 查询 Snoop Filter :请求先被送到 Snoop Filter。Snoop Filter 检查请求地址的条目:
- 如果条目显示 :这个地址的缓存行不在任何其他 Master 的缓存中 ,Snoop Filter 会立即告诉 CCI-550:"无需侦听 "。然后请求直接转发到内存控制器。这避免了所有不必要的 Snoop 广播,是性能提升的关键。
- 如果条目显示 :这个地址的缓存行可能在一个或多个其他 Master 的缓存中 ,Snoop Filter 会返回一个位图,精确指出"可能需要侦听"的 Master 列表(例如,Master 0 和 Master 2)。
- 精准侦听 :CCI-550 的侦听控制单元只向 Snoop Filter 指出的那几个特定的 Master 发送 Snoop 请求。这称为精准的、点对点的侦听。
- 响应与更新:被侦听的 Master 返回响应。如果某个 Master 实际已无此缓存行(Snoop Filter 假阳性),它会返回无效响应。Snoop Filter 根据响应更新其内部状态。
- 数据返回:CCI-550 从内存或某个 Master 的缓存收集到数据,返回给请求者 M1。
1.2 CHI与CMN600
CHI(Coherent Hub Interface)是AMBA5给出的专门的一致性协议,CMN600(coherent mesh network)是基于CHI协议构建的一致性mesh结构互联网络
1.2.1 CHI协议
CHI和以往的AXI/ACE协议最大的区别就是不在按通道传输,而是按数据包传输。
CHI是按packet/flit+credit base的方式进行通信。双向通信就是一组TX和一组RX
数据包类型按层次:
├── 请求包 (Request)
│ ├── 一致性请求
│ ├── 非一致性请求
│ └── 侦听请求
├── 数据包 (Data)
│ ├── 请求数据
│ ├── 响应数据
│ └── 窥探数据
└── 响应包 (Response)
├── 完成响应
├── 分离响应
└── 数据库响应
具体的包类型和各种包的详细功能请见另一篇文章
https://blog.csdn.net/cy413026/article/details/160226196
1.2.2 CMN600
一个2x4 mesh CMN600的框图如下
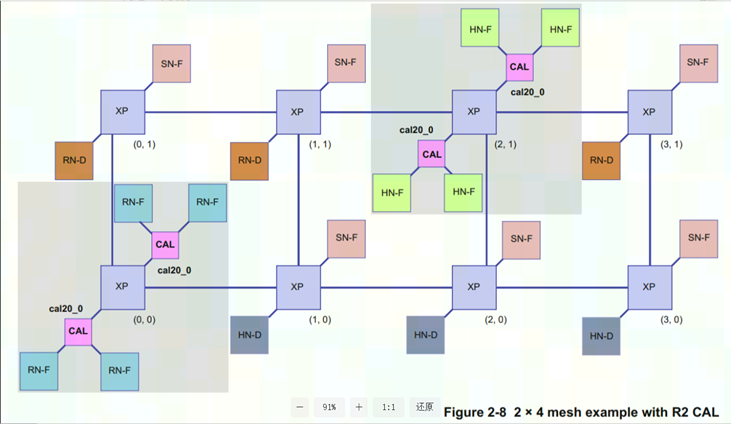
1.2.2.1 XP:cross point
主要是做路由功能,连接节点,构建mesh网络----类比noc中的router
1.2.2.2 RN ------ Master 主节点(Request Node)
连接Master 主设备端(发请求)-----类比noc中的mstBridge
- RN-F(RN-Fully Coherent) :既可以发起一致性请求,又可以接受和响应snoop,还可以发DVM消息。连接CPU 簇(DSU)等
- RN-I(RN - I/O) :只可以发起一致性请求,不可以接受和响应snoop。连接IO 主设备(PCIe、DMA、NPU、GPU),RN-I 的请求必须先到HN-I
- RN-D(I/O Coherent Request Node with DVM Support) **:**是RN-I的一个扩展,仍然不支持cacheLine的snoop,但是支持DVM的snoop
支持 DVM 消息 (Distributed Virtual Memory),但是只能接收DVM消息,不能发DVM消息;能接收并处理 DVM snoop (SnpDVMOp)
1.2.2.3 HN ------ CMN 内部 Snoop / Home 节点(Home Node)
CMN 内部核心节点Snoop / Home 节点(管一致性)------普通noc中没有的
内部节点,不接mst和slv
- HN-F:内存区域的 Home,负责 snoop CPU、维护内存数据一致性
一个网络中可以有多个HN-F,每个HN-F处理一段地址空间,XP可以根据地址把请求路由到不同的HN-F
每个HN-F只维护自己地址空间内的directory
每个HN-F维护的地址空间不重叠
- HN-I:IO 区域的 Home,只管 IO 节点的入口转发、排序、协议转换
HN-I只做RN-I请求的转发,如果需要访问cache,就转发给HN-F来进行snoop,如果需要访问ddr/Device,就转发给SN
网络中可以有多个HN-I,比如一个IO device配置一个HN-I
HN-I的接受请求的地址空间可以重叠,因为HN-I只是用地址做路由,没有directory
- HN-D :Distributed Virtual Memory Home Node,它在 CMN 里只有一个、全局唯一,专门干一件事
负责全局广播 DVM 消息,统一刷新整个系统所有 RN 的 TLB / 地址翻译缓存。
- 接收来自 CPU(RN-F)或 MMU 的 DVM 请求
- 作为 全局唯一有序点(POS) 保证顺序
- 向所有 RN-F、RN-D 广播 DVM 消息
- 收集响应,完成全局 TLB 同步
作用:
- 统一snoop 广播点
- 统一事务序控制点(POS)
- 统一路由转发中心
1.2.2.4. SN ------ Slave 从节点(Slave Node)
连接Slave 从设备端(收请求、响应)----类比noc的slvBridge
- SN-F:DDR 内存控制器
- SN-I:MMIO 外设、PCIe BAR、寄存器空间
作用:只响应读写,不发起请求
1.2.2.5 DVM
DVM 就是系统级的:
- TLB 无效化(TLB Invalidate)
- ASID / VMID 同步
- 地址空间切换广播
当 CPU 改了页表、清空 TLB 时,不能只清自己的,还要通知:
- 其他 CPU 簇(RN-F)
- 带 SMMU 的 IO 设备(RN-D)让它们一起失效 TLB,保证虚拟地址翻译全局一致。
这个广播的发起者、控制点,就是 HN-D 。HN-D 的请求来源只能是RN-F
RN‑D 的角色是:
- 只能接收 HN-D 广播的 DVM 消息
- 用来刷新自己的 SMMU TLB
- 不能主动发请求给 HN-D
1.3 CCI550与CMN600的区别
1.3.1 snoop的区别
CCI550使用简化目录做snoopFilter,CMN用完整的目录做snoopFilter
|-------|----------------------------------|-------------------------------------|
| 特性 | 完整理想目录 | CCI-550 Snoop Filter (简化目录) |
| 状态跟踪 | 精确跟踪每个缓存行在每个Master的缓存状态(I/S/E/M) | 通常只跟踪存在性(Present/Absent),状态通过其他机制推断 |
| 条目结构 | 对每个缓存行,为每个Master保存状态位 | 对每个缓存行,为每个Master保存1个"存在位" |
| 假阳性 | 无 | 可能存在,但可接受 |
1.3.2 在处理I/O mst请求时的区别
I/O device(比如DMA,GPU)在作为mst时需要访问cpu的cache,是需要snoop cache的状态,但是device本身是不接受snoop,也不响应snoop的。
在CCI550,Device通过ACP(Accelerator Consistency Port,就是ACE-lite协议)接到Interconnect的crossbar,由这个crossbar来发起snoop或者转发到slv口
在CMN600中,IO Device全部接到RN-I节点,然后RN-I节点把所有Device请求发送到HN-I,由HN-I来转发,如果需要snoop就转发到HN-F,如果不需要snoop就转发到SN
1.3.3 总体区别
|------------|-------------------------------|-------------------------------|
| 特性 | CCI-550 | CMN (如 CMN-700) |
| 拓扑 | 集中式交叉开关 | 分布式网状网络 |
| Snoop 决策者 | 中心的 Snoop Filter + 控制逻辑 | 分布式的 Home Node |
| 目录粒度 | 系统级中心目录,但为精简过滤器 | 地址映射,每个地址的 HN 拥有其全目录 |
| Snoop 方式 | 由中心向特定 Master 发起的"精准组播" | 由 Home Node 向特定 RN 发起的"点对点请求" |
| 可扩展性 | 较差,受限于交叉开关端口和 Snoop Filter 容量 | 优秀,可通过增加节点扩展 |
2.Rxxx和A55的内存一致性接口
| 架构层次 | 组件类型 | 玄铁 Rxxx (C910/C920) | ARM Cortex-A78 、A55 | 主要差异 |
|---|---|---|---|---|
| 集群内 | 一致性控制器 | CIU (Cluster Interconnect Unit) | DSU-110 (DynamIQ Shared Unit) | 1. 协议:目录 vs 总线侦听 2. 可扩展性:CIU 更好 |
| 内部互连 | 交叉开关 + 目录总线 | ACE 总线 + 侦听过滤器 | 玄铁用目录,ARM用总线侦听 | |
| L3 缓存 | 共享 SLC (System Level Cache) | 共享 LLC (Last Level Cache) | 功能类似,名称不同 | |
| 接口协议 | 玄铁自定义 CHI或ACE | AMBA 5 CHI 或 ACE | 协议不同,不兼容 | |
| 多集群 | 互连总线 | CCIX-600 (Cluster Coherent Interconnect) | CCI-550/CCI-700 (Cache Coherent Interconnect) | 1. 拓扑:星形 vs 交叉开关 2. 目录:完整 vs 简化 |
| 一致性协议 | 目录协议 (MOESI) | Snoop Filter + 侦听混合 | 玄铁目录更精确 | |
| 接口类型 | RN-F 接口 (Request Node) | ACE 或 CHI-F 接口 | 接口定义不同 | |
| 扩展能力 | 4-8 个 Cluster | 2-4 个 ACE Master | 玄铁扩展性略好 | |
| 系统级 | 大规模互连 | 可选玄铁 Mesh 网络 | CMN-600/700 (Coherent Mesh Network) | ARM CMN 更成熟 |
| I/O 一致性 | DCP(Device coherence port, 其实类似于ACE-lite接口) | ACE-Lite(arm叫acp接口Accelerator Consistency Port) 或 CHI-I | 功能类似,实现不同 |
1.IO一致性接口用ACE-lite,与ACE相比没有snoop的3个通道,但是ar/aw/w通道的axsnoop,axdomain和barriar,unique信号还是有的
axsnoop可以让HN-F/RN-F执行ReadNoSnoop,ReadOnce,CleanUnique
----也就是说IO Device不接收snoop,但可以发一些snoop操作让RN-F执行
如果IO一致性(RN-I)接口不需要上述的功能,可以直接使用axi接口
2.如果系统只有单cluster,不需要CCIX/CCI/CMN这些网络,CIU/DSU的输出可以选择ACE接口,并把snoop相关信号floating或tie-off以兼容AXI接口
3.一致性总线的barrier trans
3.1 ACE的barrier trans
本节以ACE的barrier transaction为介绍对象,也可为理解CHI协议的barrier提供帮助。
3.1.1 mem barrier和sync barrier
ACE 支持内存屏障(memory barrier)和同步屏障(sync barrier):
- 内存屏障:由主设备发出,以保证指定域(domain)中的另一个主设备如果可以观察屏障之后发出的任何trans,那么这个主设备必须能够观察屏障之前发出的每个trans。
- 同步屏障:由主设备发出,以保证屏障完成时,相应域中的每个主设备都可以观察到在屏障之前发出的所有事务。系统域(axdomain=2'b11)同步屏障有一个额外的要求,即在屏障事务之前发出的所有事务必须在屏障完成之前到达它们指定的端点从属设备。
barrier的操作是在指定的domain中,不是靠地址来区分的。
3.1.2 理解内存barrier和同步barrier的区别
1.内存barrier关注的是barrier前trans和barrier后trans的顺序,只要保证barrier之后的trans在总线上在barrier前trans后面,且不会超车之后,内存barrier就可以返回resp。
----没有要求内存barrier完成时,指定domain中所有mst都观察到barrier前后的trans,甚至不要求其他mst观察到barrier之前的trans。
----------定义只说了某个mst如果观察到了barrier之后的trans,就必须能观察到barrier之前的trans
----------它等价于只要保证barrier之后的trans在总线上在barrier前trans后面,且不会超车之后,内存barrier就可以返回resp
----所以mem barrier在resp时不需要等其他mst的反馈
----而且此时barrier前的trans和barrier后的trans是否已经写到slv端是不能保证的。
2.同步barrier是不关心barrier之后的trans,要求barrier完成之时,domain内所有mst都能观察到barrier之前的trans
-------Interconnect要确认domain中所有的mst都能观察到barrier之前的trans,那么是需要其他mst的反馈信息
-------sync barrier只有system shareable domain要求barrier完成时barrier前的trans都到达slv,其他情况不需要
3.2 怎么使用memory barrier?
内存 barrier用于:屏障普通内存事务(Read / Write)
典型指令有:DMB(data mem barrier )指令
普通内存访问事务
- Read
- Write
- Atomic
- Exclusive
典型场景
- CPU 写共享内存
- DMA 写 buffer
- 多核之间共享数据
使用场景示例
Core0: write flag = 1 write data = x DMB //data mem barrier write ready = 1Core1: poll ready 1 DMB //data mem barrier read flag read data由于core1 polling发现barrier(DMB)之后的ready=1,那么说明barrier之前的 write flag和write data数据也是可见的,此时read flag=1,data=x
core1的DMB是为了防止core1的read跑到了poll ready 1之前。
第一误区:core0发barrier的时候别的mst不能发trans
----这里显然是不对的,core1在一直poll ready
第二个误区:core0 barrier的时候core1无法读写flag,data
----是可以读写flag和data的,只是无法确认读的是什么值,也无法确认是否把core1要写的值写进去了
3.3 同步barrier
sync barrier也可以完成3.2节的core0写flag,data,core1来读数据。但是无论是mem barrier还是sync barrier,其他mst都不会看到barrier的resp,barrier的resp
只会返回给发起barrier的mst,所以即使使用sync barrier,core1在判读能否读到最新的flag和data时,仍需要"ready=1"标志位
sync barrier可以完成mem barrier的保证顺序功能,但是sync barrier的延迟更大,成本更高,所以mem barrier能够胜任的,就用mem barrier。
3.4 barrier的trans描述及要求
3.4.1 读写barrier及barrier pair
Barrier事务可以是读事务或写事务,定义如下:
读取屏障交易:主组件在读地址通道上发出读屏障事务,并在读数据通道上返回响应。没有数据传输发生。
写入屏障事务:主组件在写地址通道上发出写屏障,并在写响应通道上返回响应。没有数据传输发生。
ACE的barrier要求无论何时都要awbarrier和arbarrier成对发送,无论barrier之前的trans是否是读写都有。
即使实际只需要对aw或ar一个通道进行保续,也需要发barrier pair
在定义barrier之前的trans时,只看本身通道,比如有一个rd trans是在arbarrier之前,但是在awbarrier之后,仍然认为是barrier之前。
3.4.2 barrier相关信号
3.4.2.1 axbar
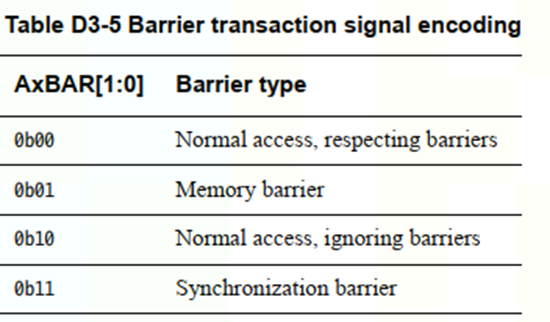
3.4.2.2 axdomain
axdomain信号定义了barrier的作用域,和地址无关

3.4.2.3 其他信号
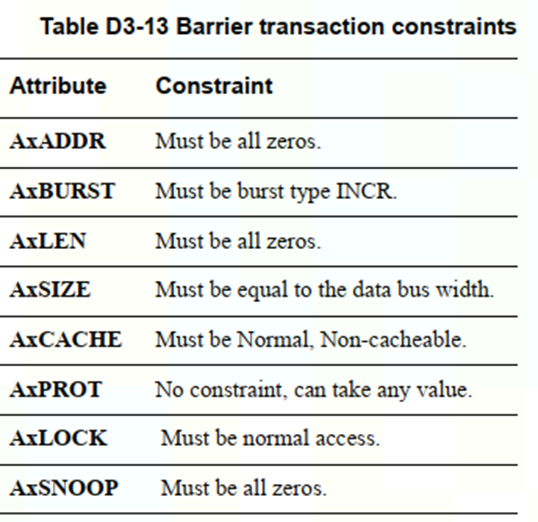
注意axaddr==0

其他user-defined信号 比如user都为0,或者不存在。
3.4.3 barrier resp与 domain boundry
怎么判断domain的boundry决定了Interconnect在哪里可以返回barrier的resp
这里不详述,可参考AXI-ACE5的spec D8.3节
3.4.4 barrier trans的其他要求
这里只摘取部分要求
barrier对mst的要求:
barrier请求支持outs,ACE接口的支持不超过256个outs,ACE-lite接口的outs没有限制
因为barrier之后的请求是不能影响barrier前面的请求的,如果barrier后的请求影响barrier及前面trans的完成,就不能发barrier。
所以barrier与barrier之间没有关系。多个barrier也是顺序执行的,所以可以outs
barrier的outs是从awbarrier/arbarrier哪个先valid开始,到awbarrier/arbarrier的resp都握手计算
barrier对slv的要求:
一般情况下barrier请求在Interconnect就可以完成,但是如果Interconnect比较简单没做barrier的处理,或者像barrier请求从IO mst 到HN-I直接到SN-I没有
经过Interconnect组件中的barrier处理,就出现了barrier直接到slv口的情况。
此时对于ace-lite slv接口要求,要么aw通道反压,去等待ar通道的barrier;要么ar通道反压,去等待aw通道的barrier。
协议没有要求到ACE slv口的barrier互等,默认是在Interconnect做掉了----认为既然是ACE slv,那么Interconnect是支持snoop和barrier的。
----ACE的slv,说明slv参与了一致性,需要接受snoop,一般就是ddr的last level cache。
----很多情况下在ddr侧的llc是作为SN节点,是不参与cache的一致性的
barrier对Interconnect的要求:
当合并多个stream时【mux_nto1】,互连必须确保以相同的顺序在读取和写入通道上发出屏障对。不得交织barrier pair
----awbar0和arbar0是一对,来自mst0,awbar1和arbar1是一对来自mst1,2to1mux时,aw先选mst0,ar先选了mst1
----结果就是2to1之后,aw是bar0,对应ar上bar1,就出现了交织
规范建议 ACE 互连组件停止读取屏障,直到收到相应的写屏障
3.4.5 Device访问与barrier
Device空间访问是强序的,但这个强序只限于一个mst到slv的单一通路上的局部保续。
如果有多个mst,多条通路访问同一个Device是不能保证顺序的,这时候需要barrier这种全局的保续手段
// 启动DMA的典型序列write DMA_SRC; // 写源地址write DMA_DST; // 写目标地址DSB; // 确保前两个写完成write DMA_START; // 启动DMA4.一致性总线的DVM trans
DVM(Distribute virtual memory)事务支持虚拟内存系统的维护,并用于传递无法使用正常一致性事务传送的操作.
4.1 DVM的三种trans类型
4.1.1 DVM操作(DVM operation)
这些事务传达特定的操作,由支持DVM的组件发出,包含的操作有
• TLB Invalidate
• Branch Predictor Invalidate
• Physical Instruction Cache Invalidate
• Virtual Instruction Cache Invalidate
• Synchronization----经确认就是DVM sync,列到DVM operation是因为,sync和其他operation都需要用ARADDR或ACADDR的不同取值来区分
• Hint (性能暗示)
这些发送DVM operation的组件可以是支持DVM的RN-F或者RN-D,也可以是支持DVM的HN-F或者HN-D转发RN-F/D的operation
DVM 操作可能需要多个事务来传达所需的信息。在这种情况下,第一笔trans用araddr/acaddr0来表示是否需要另一笔trans。
4.1.2 DVM 同步(DVM sync)
这是组件发出的同步事务,用于检查它之前发出的所有 DVM 操作是否已完成
也就是组件发完DVM operation之后一定要发DVM sync
----一个发送sync的组件只能有一个未完成的sync trans
----组件接收到DVM complete之后才能发下一个sync----sync和complete是一一对应的
----但是接收sync请求的组件,最多可以接收256个请求
发送sync的组件可以是支持DVM的RN-F或者RN-D,也可以是支持DVM的HN-F或者HN-D转发RN-F/D的operation
当收到sync请求时,组件必须确保:
- 当主设备不能再使用无效转换并且所有先前可能使用无效转换的事务完成时,TLB 无效操作完成
- 当来自任何虚拟地址或指定虚拟地址的预测指令提取的缓存副本已失效并且无法再由关联的主机访问时,分支预测器无效操作完成
- 当主设备无法再访问已无效的地址位置的高速缓存副本时,指令高速缓存无效操作完成。
如果TLB invalid 的完成需要先保证先前事务完成,此时可以在先前事务后面发barrier,以确定先前的事务已完成。
一个组件一旦收到同步信号,组件应该停止发起新的DVM operation,但是需要等待未完成的operation结束。
4.1.3 DVM 完成(DVM complete)
该事务是为了响应 DVM 同步事务而发出的。它由已接收多个 DVM 操作和随后 DVM 同步的组件发出。它是DVM operation的接收者发出的
DVMComplete 表示所有必需的操作和任何关联的事务均已完成。
这些组件可以是接收DVM operation/sync的RN-F,RN-D,HN-F,HN-D,SN-D
4.2 DVM trans的信号与通道
4.2.1 DVM使用的通道
DVM的操作对象 TLB,Instruct cache,Branch Predictor都是只读的,所以DVM仅对只读结构进行操作。只读结构没有clean的概念。
但是当operation发到Interconnect上后,会需要snoop其他mst,所以DVM trans需要Snoop通道参与。
-----没有从Interconnect到mst的ar通道,所以只能使用snoop通道
DVM trans没有数据传输,使用ar/ac通道发operation和complete,使用r/cr通道收集对应的响应
4.2.2 DVM的信号
4.2.2.1 AR(C)ADDR 信号
DVM主要靠ar(c)addr和ar(c)snoop信号来传输信息
SBZ:should be zero
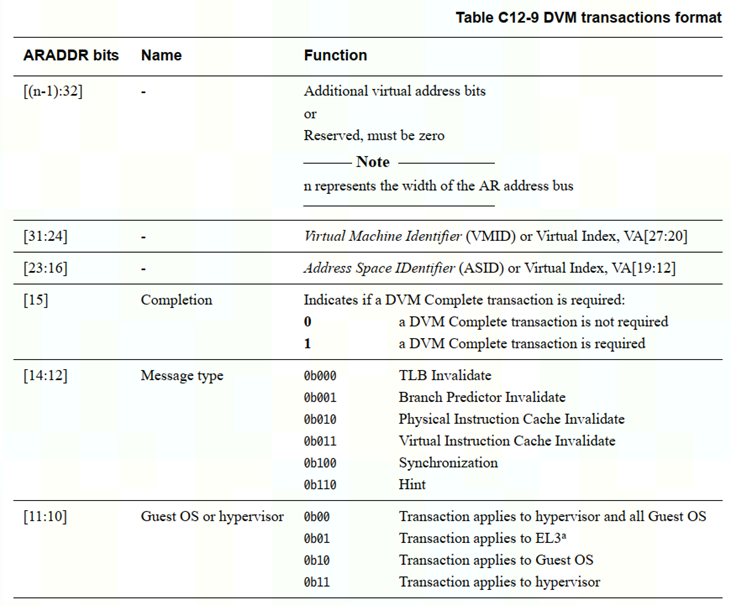
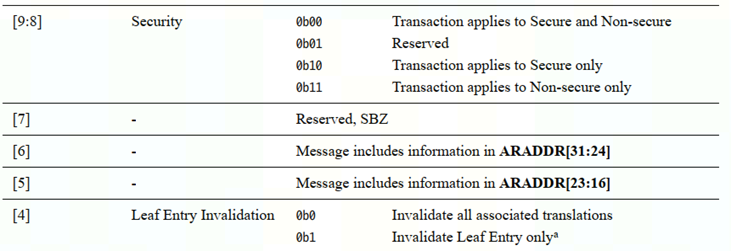
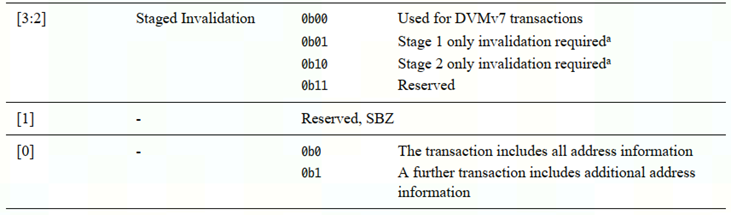
如果operation需要多个trans【araddr0=1'b1】,那么附加trans的araddr格式如下

araddr14:12:3bit表示了不同的operation类型。

4.2.2.2 AR(C)SNOOP信号
DVM operation 和sync时 AR(C)SNOOP=4'b1111
DVM complete 时AR(C)SNOOP=4'b1110
也就是说DVM trans的snoop3:1=3'b111
4.2.2.3 C(R)RESP信号---响应信号
DVM没有data transfer,所以响应信号的rdata无效,只看rresp和cresp
如果组件可以执行请求的操作,则它必须通过将 CRRESP 设置为0b00000 来响应。
如果组件无法执行请求的操作,则必须通过将 CRRESP 设置为0b00010 来响应。 通常,此响应指示不支持的消息。
不允许组件将 CRRESP 设置为0b00010以响应 DVM 同步或 DVM 完成。
------也就是说如果组件不支持DVM operation就回0b00010,后面也不会再给它发DVM sync也不需要回complete
如果所有响应的 CRRESP 均为0b00000 ,则互连组件将 RRESP 设置为0b0000
如果任何响应的 CRRESP 为0b00010 ,则互连组件将 RRESP 设置为0b0010。
4.2.2.4 其他信号的约束

4.3 DVM的流程及规则
4.3.1 DVM operation流程
1.始发主组件在其读地址通道(AR通道)上发出 DVM 操作事务。
2.互连组件使用适当的探听地址通道(AC通道)将事务分发到所有参与组件。
3.每个参与组件使用探听响应通道(CR通道)确认收到消息。
4.互连组件使用原始主组件的读取数据通道(R通道)收集确认并响应原始DVM事务。
注意这里AC/CR通道发送的不是snoop trans,而是DVM operation
4.3.2 DVM sync和DVM complete 流程
1.始发主组件在其读地址通道上发出 DVM 同步。(AR通道)
2.互连组件使用适当的探听地址通道将DVM同步分发到所有参与组件。(AC通道)
3.每个参与组件使用探听响应通道确认接收到 DVM 同步。(CR通道)
4.互连组件使用原始主组件的读取数据通道收集确认并响应原始DVM同步。(R通道)
----以上是DVM sync的流程和普通的DVM operation流程完全一致
----DVM sync的响应只表示收到了sync请求,并没有实际完成
5.每个参与组件在完成所有必要的操作后必须发出 DVM Complete。DVM Complete 由每个参与组件使用其读取地址通道发出。读地址通道上的 DVM Complete 必须仅在同一主设备的探听地址通道上的关联 DVM 同步握手之后发出。(AR通道)
6.互连组件可以使用发出DVM Complete的组件的读数据通道立即响应DVM Complete事务。(R通道)
7.互连组件观察所有 DVM Complete 事务,并且当它从每个参与组件接收到 DVM Complete 时,它使用最初发出 DVM Sync 的主组件的探听地址通道来发出 DVM Complete。(AC通道)
8.始发主组件使用探听响应通道确认 DVM Complete 的接收。(CR通道)
4.3.3 multi-part DVM operation 流程
multi-part DVM operation就是operation需要多拍ar/ac的请求
----从araddr的format看出来 最多只支持2拍请求,因为第二拍的araddr0=0 表示没有后续的请求了
1.multi-part DVM 消息始终作为连续事务发送,并且不能在它们之间插入其他事务。发出multi-part DVM 消息的主组件必须能够发出消息的后面部分,而不需要发生任何其他外部操作。
2.multi-part DVM 消息的每个事务在探听响应和读取数据通道上都有一个响应。
3.multi-part DVM 消息的每个事务必须使用相同的 AXI ID