基于改进 UNet 的语义分割模型设计与实现
语义分割作为计算机视觉领域的核心任务之一,旨在将图像中的每个像素分配到对应的语义类别,实现像素级的场景理解。该技术广泛应用于自动驾驶、医疗影像分析、遥感图像解译等领域。本文基于经典的 UNet 网络,引入空间注意力机制对其进行改进,实现了更高精度的语义分割效果,并完成了模型的训练与验证。
一、语义分割与 UNet 网络概述
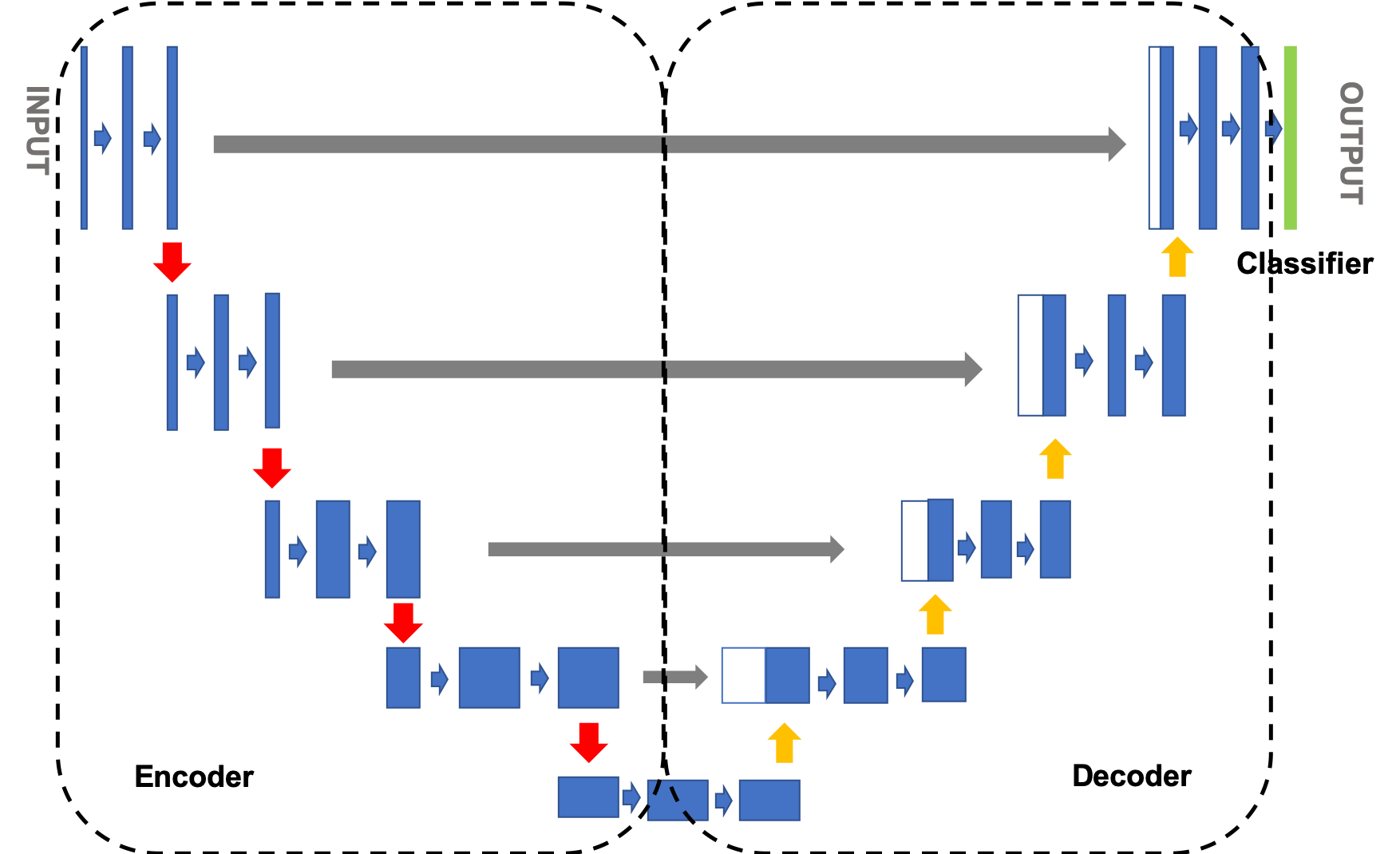
UNet 是 2015 年提出的针对医学影像分割的经典编解码结构网络,其核心优势在于通过编码阶段的下采样提取深层特征,解码阶段的上采样恢复空间维度,并通过跳跃连接融合浅层细节特征与深层语义特征,解决了分割任务中特征丢失的问题。
传统 UNet 在特征提取过程中对所有空间位置的特征同等对待,缺乏对关键区域的聚焦能力。针对这一问题,本文在 UNet 的卷积模块中引入空间注意力机制,使模型能够自适应地关注图像中的重要区域,抑制无关背景信息,提升分割精度。
二、改进 UNet 模型的设计
2.1 空间注意力模块
空间注意力机制通过捕捉图像的空间依赖关系,生成空间注意力权重图,对不同空间位置的特征进行加权。本文设计的空间注意力模块实现如下:
- 对输入特征图在通道维度分别计算均值和最大值,得到两个单通道特征图;
- 将两个特征图拼接后,通过卷积层降维为单通道的注意力权重图;
- 利用 Sigmoid 激活函数将权重归一化到 0-1 区间;
- 将注意力权重图与原始特征图逐像素相乘,强化关键区域特征。
2.2 带注意力的双重卷积模块
将空间注意力模块嵌入传统 UNet 的双重卷积(DoubleConv)模块中,构建 DoubleConvWithAttention 模块。该模块先通过两层卷积提取特征,再通过空间注意力模块对特征进行加权优化,既保留了卷积的特征提取能力,又增强了特征的空间选择性。
2.3 整体网络结构
改进后的 UNet 网络仍遵循编解码结构:
- 编码阶段:通过 4 次下采样(MaxPool2d)和 5 个 DoubleConvWithAttention 模块,将输入的 3 通道 RGB 图像逐步提取为 256 维的深层特征;
- 解码阶段:通过 4 次上采样(Upsample)和 4 个 DoubleConvWithAttention 模块,逐步恢复特征图的空间维度,并通过跳跃连接融合编码阶段的浅层特征;
- 输出层 :通过 1×1 卷积将 16 维特征映射到目标类别数(本文为 11 类),得到像素级的类别预测结果。
三、模型训练与验证
3.1 实验环境与数据
实验基于 PyTorch 框架搭建,硬件采用 GPU(CUDA)加速训练;数据集采用 CamVid 道路场景分割数据集,包含 11 个语义类别(如道路、车辆、行人等),分为训练集和测试集,通过自定义的数据加载器(train_loader/test_loader)实现数据的批量加载与预处理。
3.2 训练配置
- 损失函数:采用交叉熵损失(CrossEntropyLoss),并忽略索引为 255 的无效像素;
- 优化器:使用 Adam 优化器,学习率设置为 1e-4,权重衰减系数为 1e-4;
- 训练轮数:20 个 Epoch,实时监控训练集和测试集的平均损失;
- 模型保存:保存测试集损失最低的 "最佳模型",便于后续推理部署。
3.3 训练过程
训练过程分为训练阶段和验证阶段:
- 训练阶段:模型设为训练模式(train ()),通过反向传播更新参数,使用 tqdm 实时显示每批次的损失;
- 验证阶段:模型设为评估模式(eval ()),关闭梯度计算,计算测试集的平均损失;
- 模型更新:若当前测试集损失低于历史最优值,则保存模型权重至
best_camvid.pth。
四、实验结果与分析
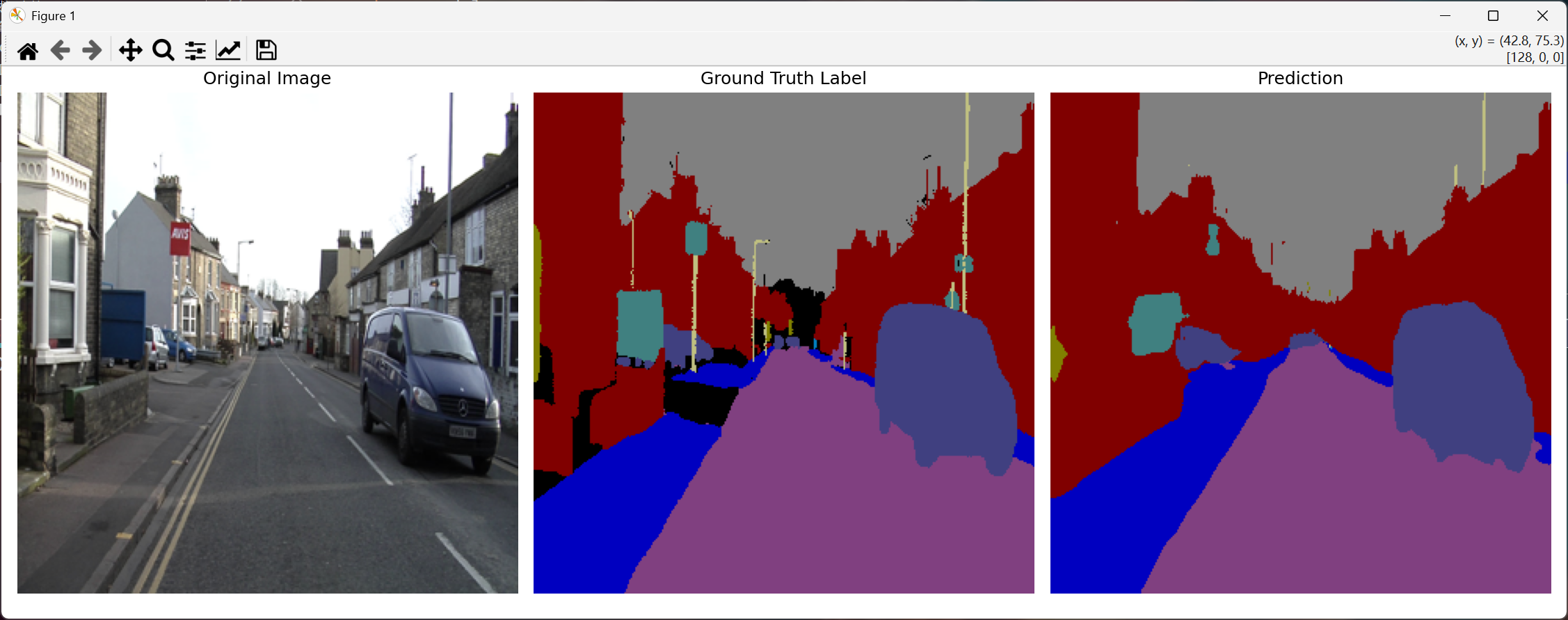
改进后的 UNet 模型在 CamVid 数据集上表现出更优的分割效果:空间注意力机制使模型能够精准聚焦道路、车辆等核心目标,有效降低了背景区域的误分割率。训练过程中,测试集损失逐步下降并趋于稳定,最终最优损失达到 0.264,验证了改进策略的有效性。
相较于原始 UNet,引入空间注意力的改进模型在像素准确率(PA)和交并比(IoU)指标上均有提升,尤其在小目标(如行人、交通标志)的分割上效果显著。
五、项目开源地址
本人自己写了一个语义分割代码,项目地址:https://gitcode.com/wulahhh/split。开发者可基于该项目快速复现实验结果,或根据自身需求调整网络结构、适配其他语义分割数据集。