前言
以前我爬取数据时被封IP封到崩溃。我的第一个爬虫才跑半个小时,TikTok 就把我 IP 封了。第二个稍微好点,撑了有大半天天,再后来直接干废了。后来又花了挺长时间,捣鼓了一套代理轮换系统,发现一点用都没有。而且不光是 TikTok。跑去爬 YouTube,签名加密直接把我卡死了;换 LinkedIn,登录墙加行为检测,连门都摸不到。那段时间我真觉得,想稳稳当当地从多个平台抓点数据,简直就是做梦。
后来我发现用一套工作流就可以搞定多平台采集,使用Bright Data MCP ,直接插进 Dify 工作流里,就这一步,彻底改变了我做数据采集的方式。今天这篇文章,我用一个真实用例来爬取TikTok + LinkedIn,手把手带你从零搭建这套工作流。
立即免费注册 Bright Data,获得$20试用额度,折扣码是"mao20"
一、为什么多平台采集这么难?
说到底,各大平台的防御逻辑各不相同:
| 平台 | 主要反爬机制 | DIY 失败率 |
|---|---|---|
| Amazon | 动态渲染、验证码、速率限制 | 极高 |
| TikTok | 签名加密、设备指纹 | 极高 |
| 登录墙、行为检测 | 极高 | |
| eBay / Temu | 地区限制、JS 渲染 | 高 |
| Google SERP | 反爬算法频繁更新 | 高 |
每增加一个采集目标,就意味着要多维护一套独立的爬虫逻辑。这种重复劳动的边际成本,是任何个人开发者或小团队都难以承受的。但是如果让 AI 工作流接管采集逻辑,让企业级基础设施处理反爬问题,这样就会非常便利了
二、Bright Data MCP + Dify
MCP 的核心作用是定义模型可调用的能力,让 AI 智能体与数据库、API、浏览器等外部世界打通,实现各类外部工具的快速接入。该工作流主要流程如下:
用户输入(平台 + 关键词 + URL) → Dify Workflow → Bright Data MCP Server → TikTok / LinkedIn 采集→ LLM处理→ 结构化 JSON 输出 → 报表 / 数据库 / LLM
Dify 提供可视化 Workflow,不用写爬虫逻辑,Bright Data MCP 处理所有平台的解封、代理、指纹,让你彻底告别封号和验证码。两者结合,就是一套 AI 驱动的多平台数据采集流水线。另外Bright Data MCP为 AI Agent 提供实时 Web 访问能力的服务,包含 60+ 数据采集工具,例如:
- Web Scraper API
- SERP API
- Browser API
- Datasets
- Crawl API
它允许 AI Agent 直接访问互联网数据,而无需处理代理、反爬或封锁问题,效率非常高。
1、准备
- Bright Data 账号(免费试用包含 $20 额度 + 每月 5,000 次免费 MCP 请求)
- Dify 账号(云端或本地部署均可)
- Bright Data MCP Server API Token
- DeepSeek API Key
点击这里注册 Bright Data 账号,新用户直接获得试用额度。
2、实战教程:TikTok + LinkedIn 社媒红人与趋势数据采集
这套工作流对营销与社媒分析团队来说最有实战价值。
(1)配置 Bright Data MCP Server
登录到亮数据后台控制面板,点击左侧"AI网关"菜单,然后选择"MCP"
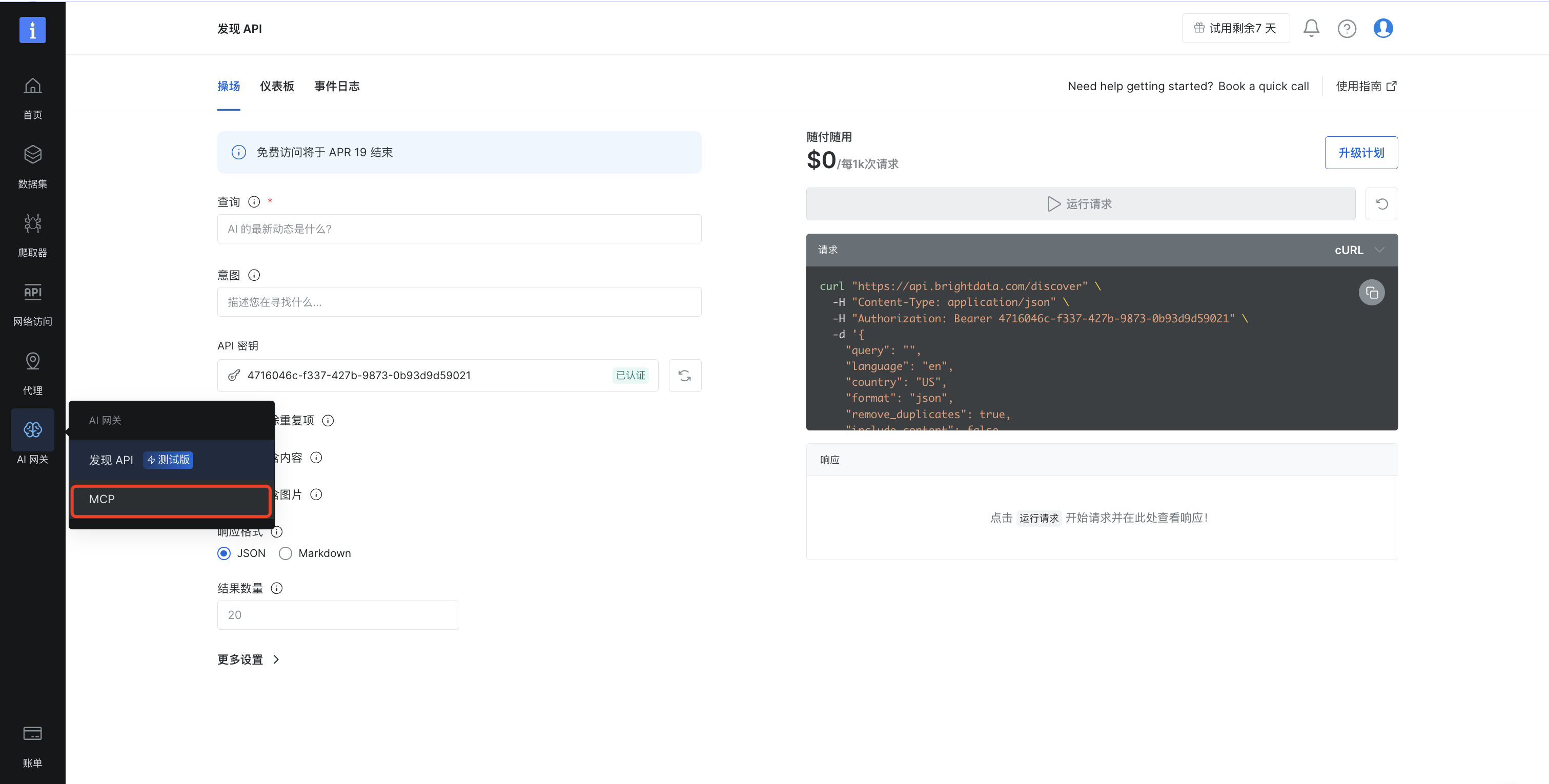
在"选择工具"中选择"电子商务",然后点击继续配置
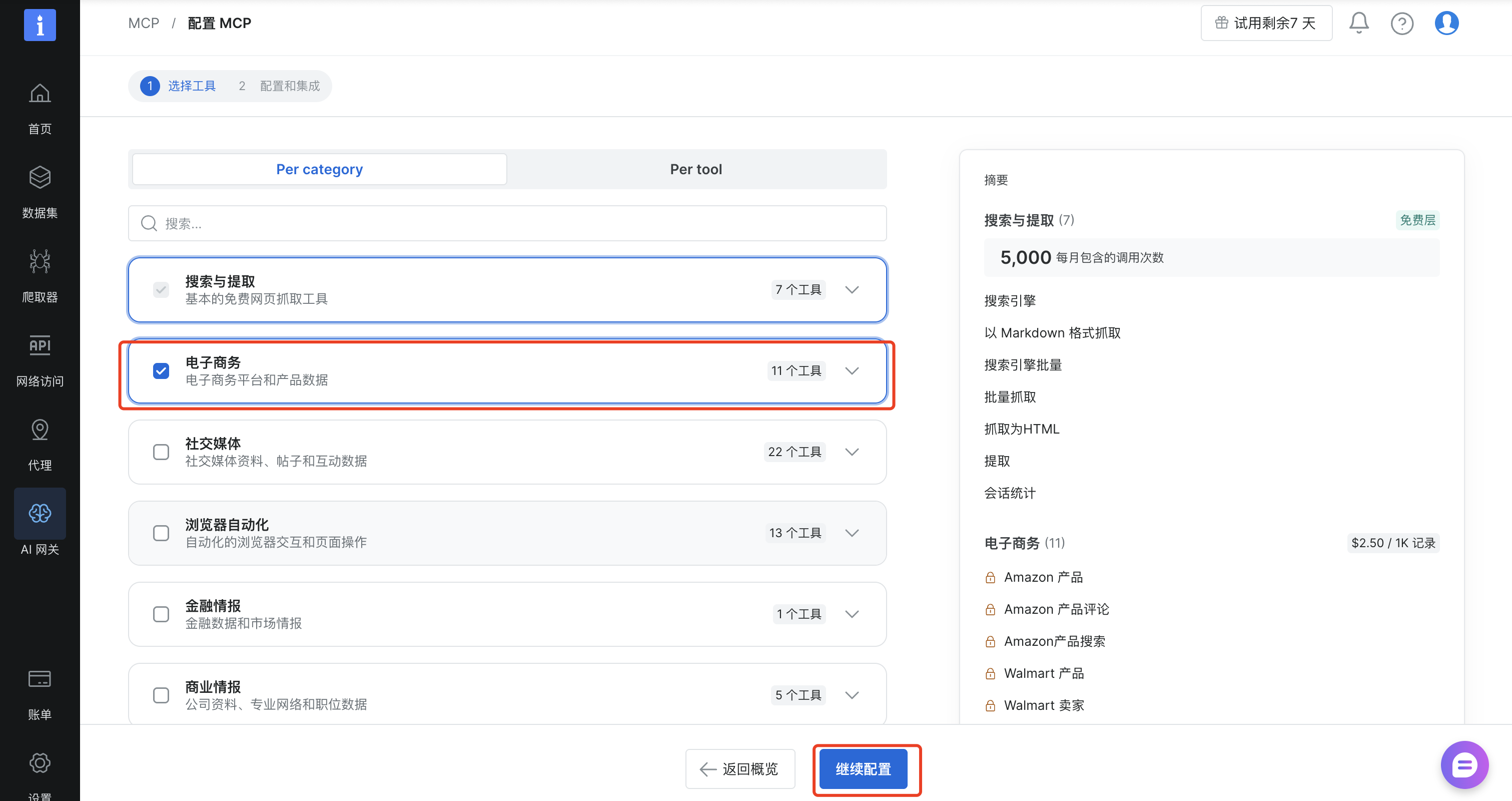
在配置和集成中选择"远程",使用官方的托管服务
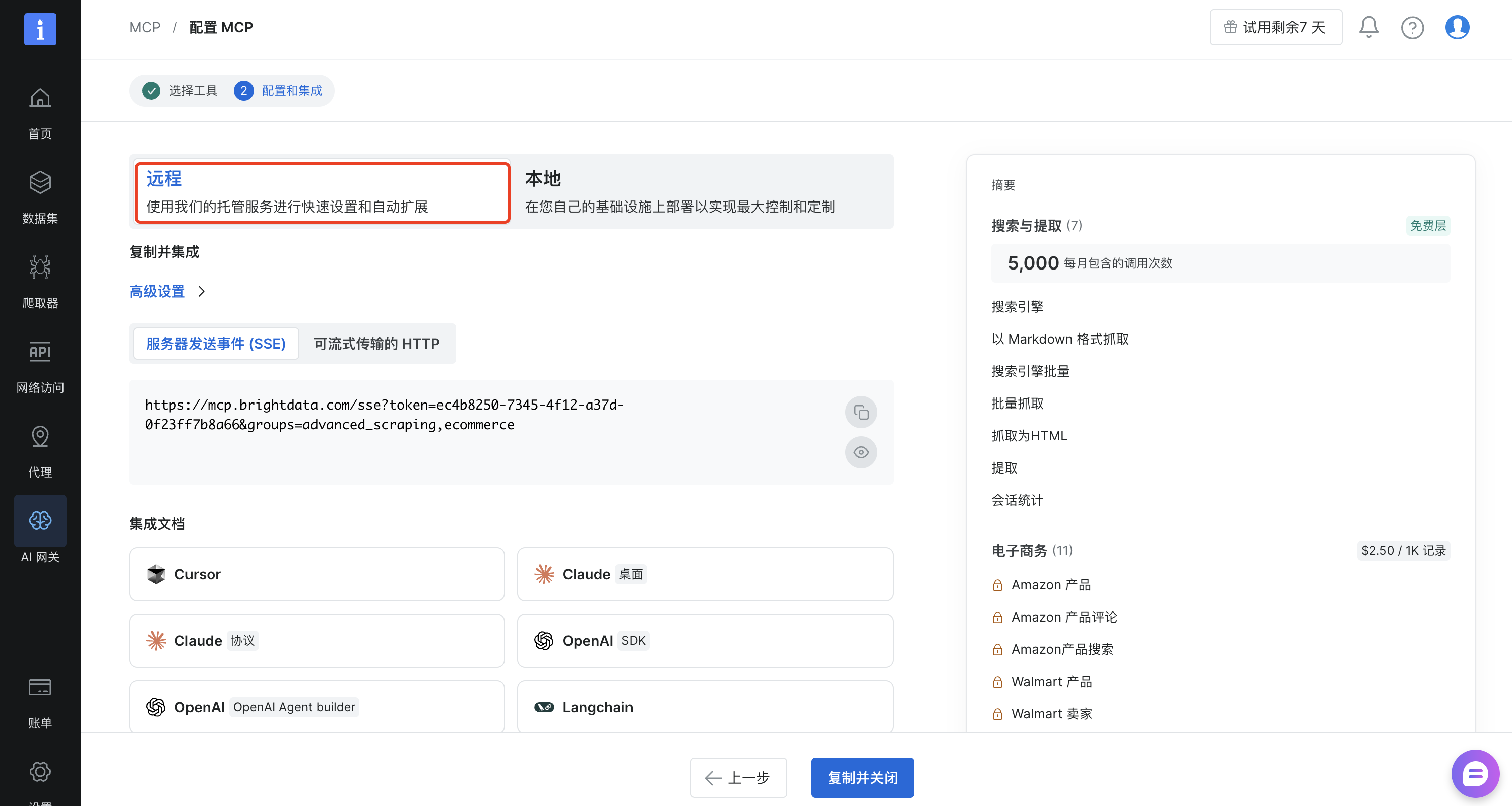
接下来就可以看到我们的的MCP配置已经设置成功了
(2)在 Dify 中添加LLM、 Bright Data MCP 工具
这里我本地部署了Dify,然后安装deepseek、bright data mcp插件,进行安装
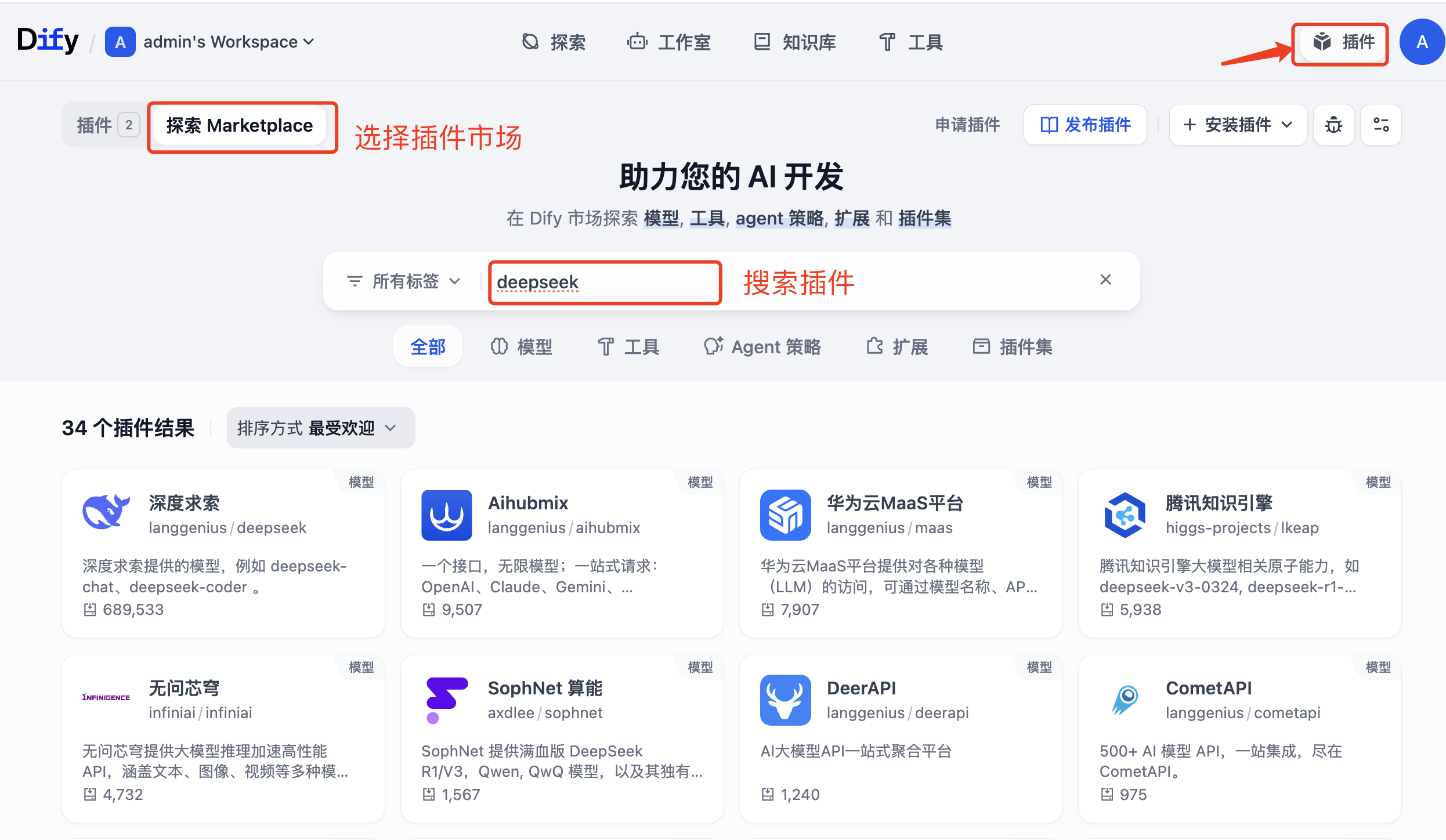
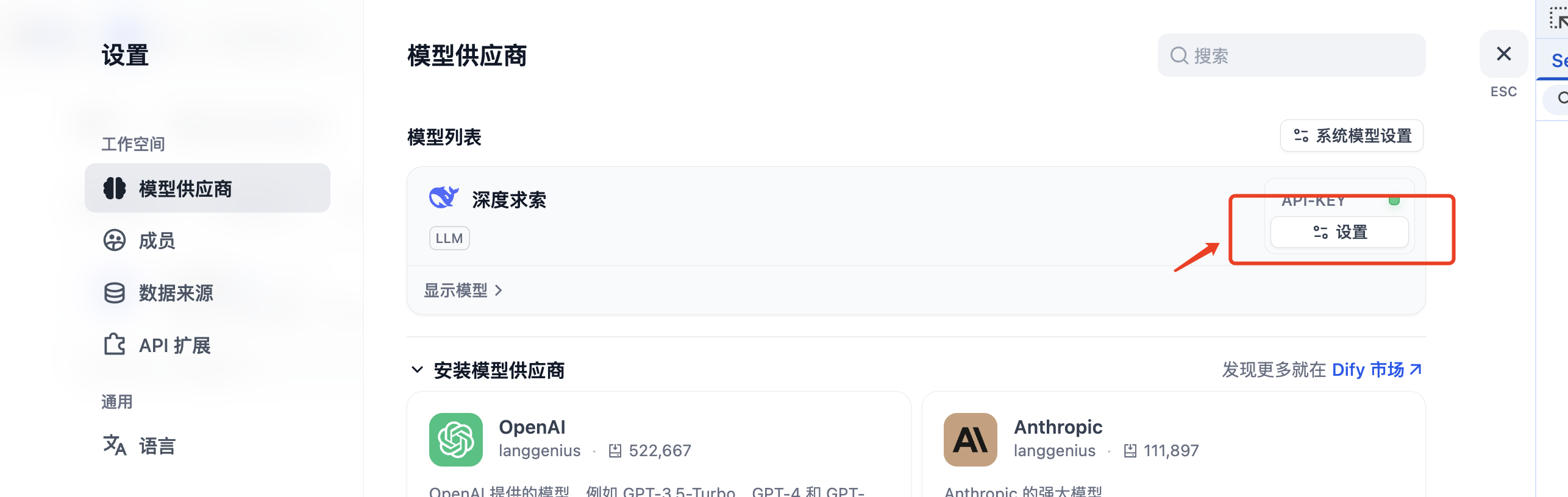
安装之后,需要从DeepSeek拿到API KEY 以及从Bright Data拿到API KEY进行授权
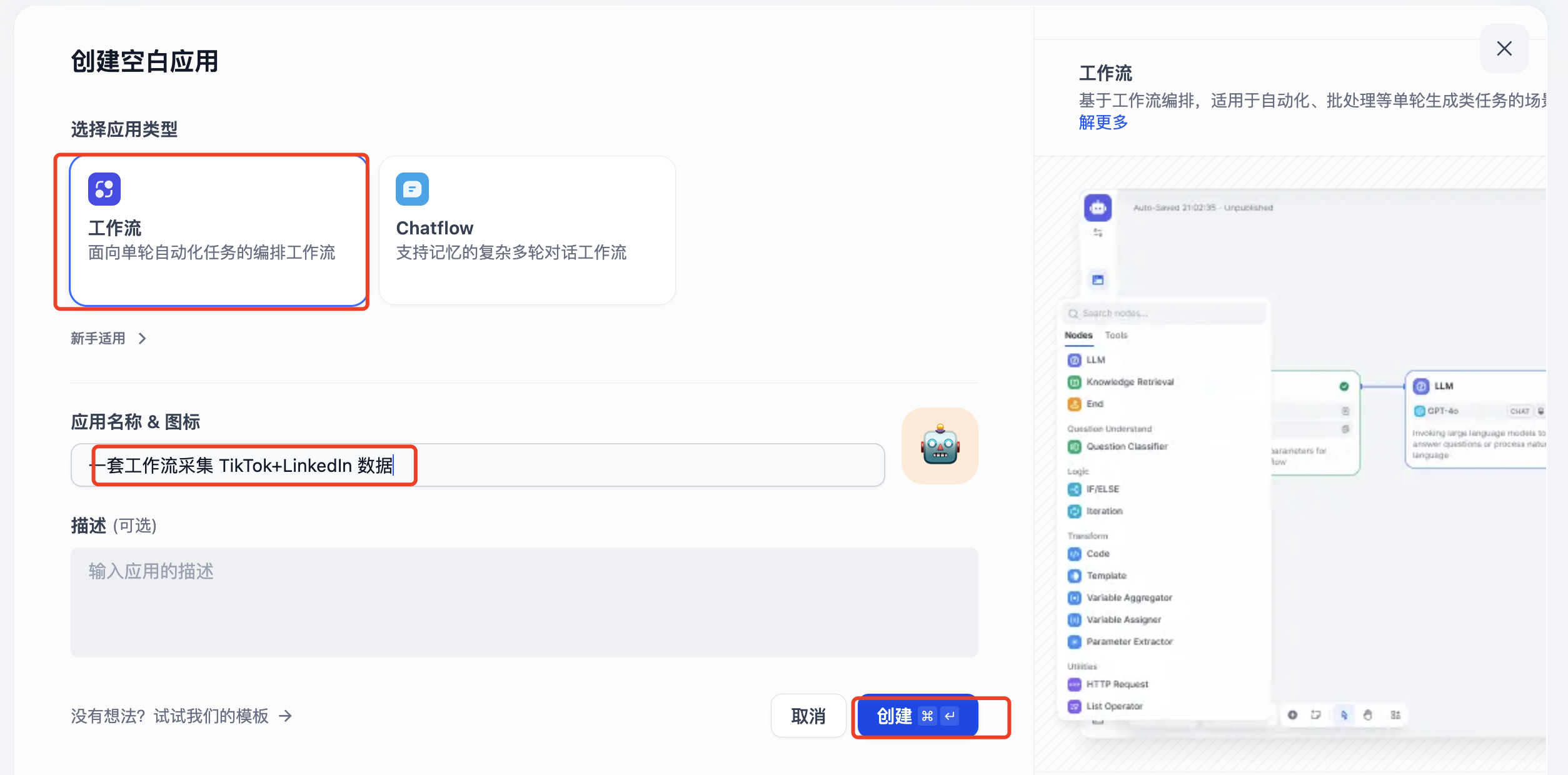
(3)创建 TikTok + LinkedIn 社交媒体采集 Workflow
首先创建一个工作流应用,输入应用名称
点击开始节点的"+",为开始节点添加变量
为开始节点添加一个下拉选项变量
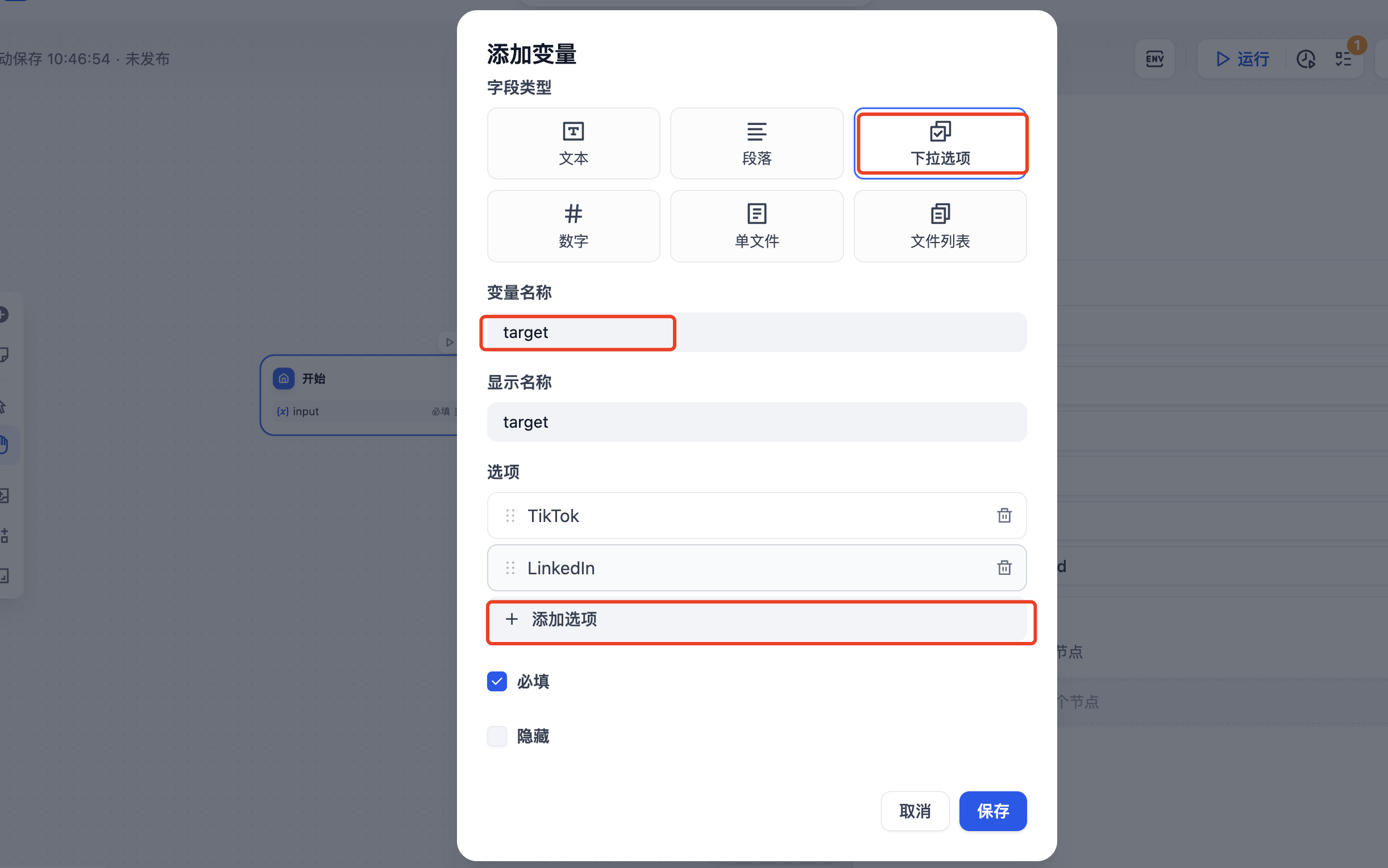
为开始节点添加一个输入的变量
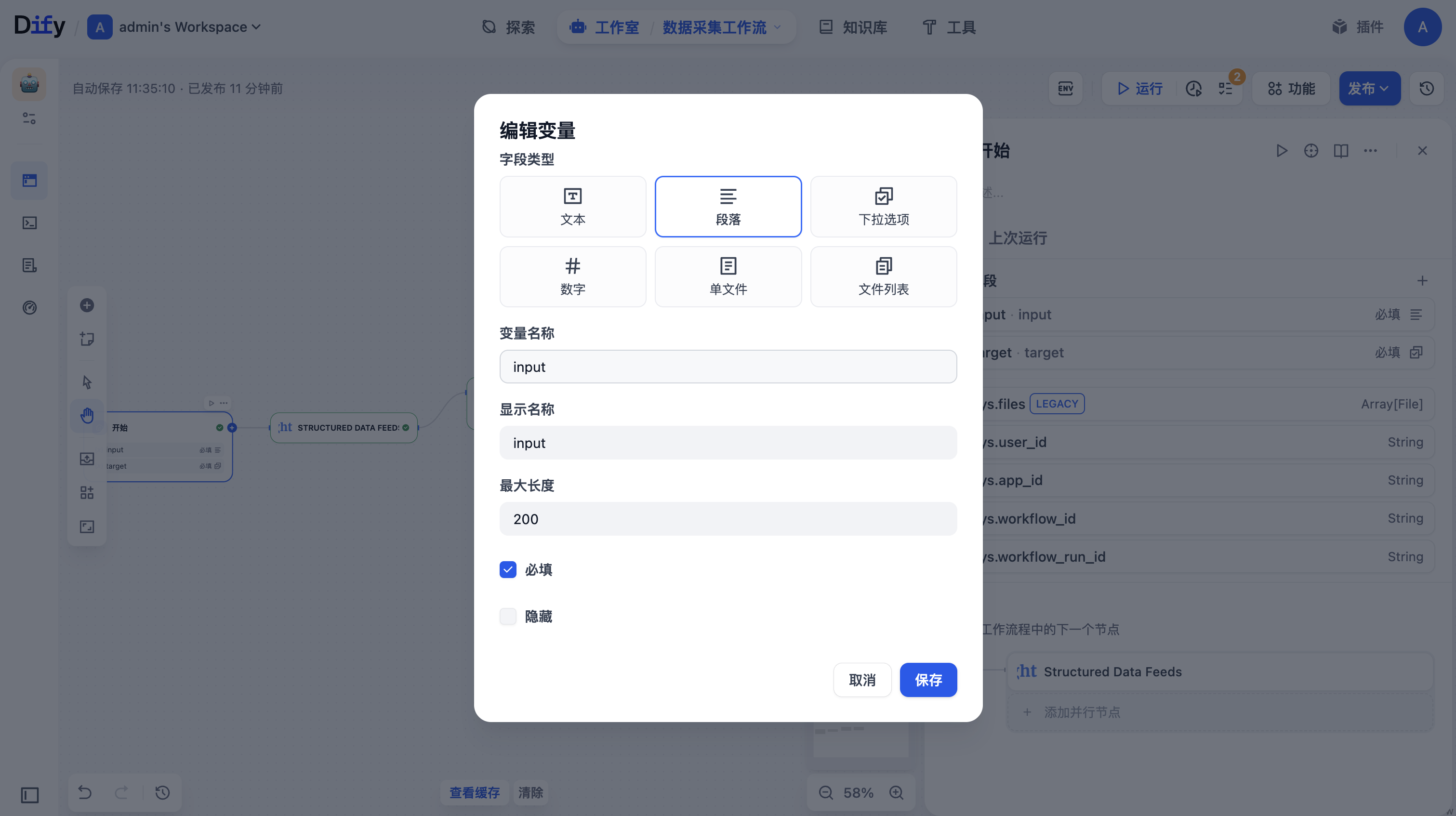
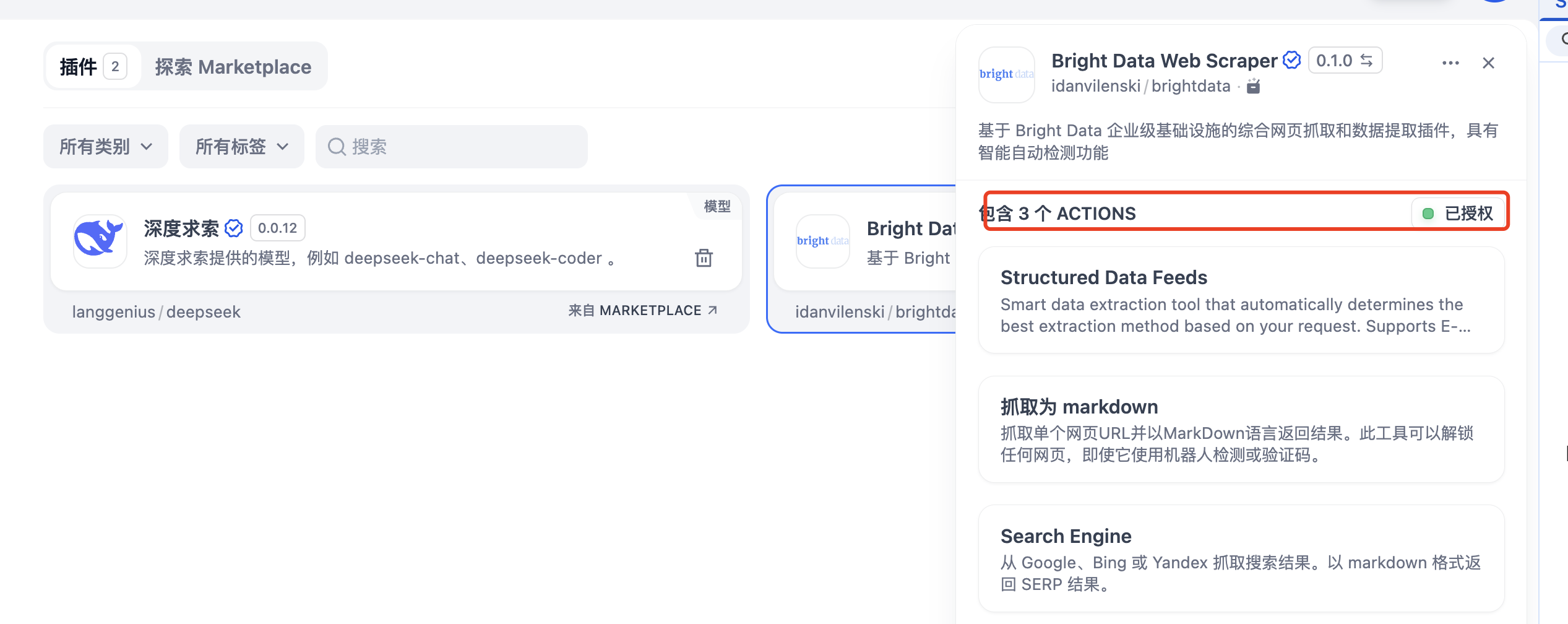
接下来就是我们的重点了,开始节点设置之后,就该设置MCP Server节点了, 点击开始节点后面的"+",然后在弹出的窗口中选择"工具"菜单,在下面列表选择"Bright Data 网页抓取器"中的"Structured Data Feeds",其中"Bright Data 网页抓取器"提供了三种抓取方式
- Structured Data Feeds(结构化数据源):智能数据提取工具,根据您的请求自动确定最佳提取方法。支持电商、社交媒体、商业智能和内容平台。只需描述您想要的数据或提供URL!
- 抓取为 markdown:抓取单个网页URL并以MarkDown语言返回结果。此工具可以解锁任何网页,即使它使用机器人检测或验证码。
- Search Engine:从Google、Bing或Yandex抓取搜索结果。以markdown格式返回SERP结果。
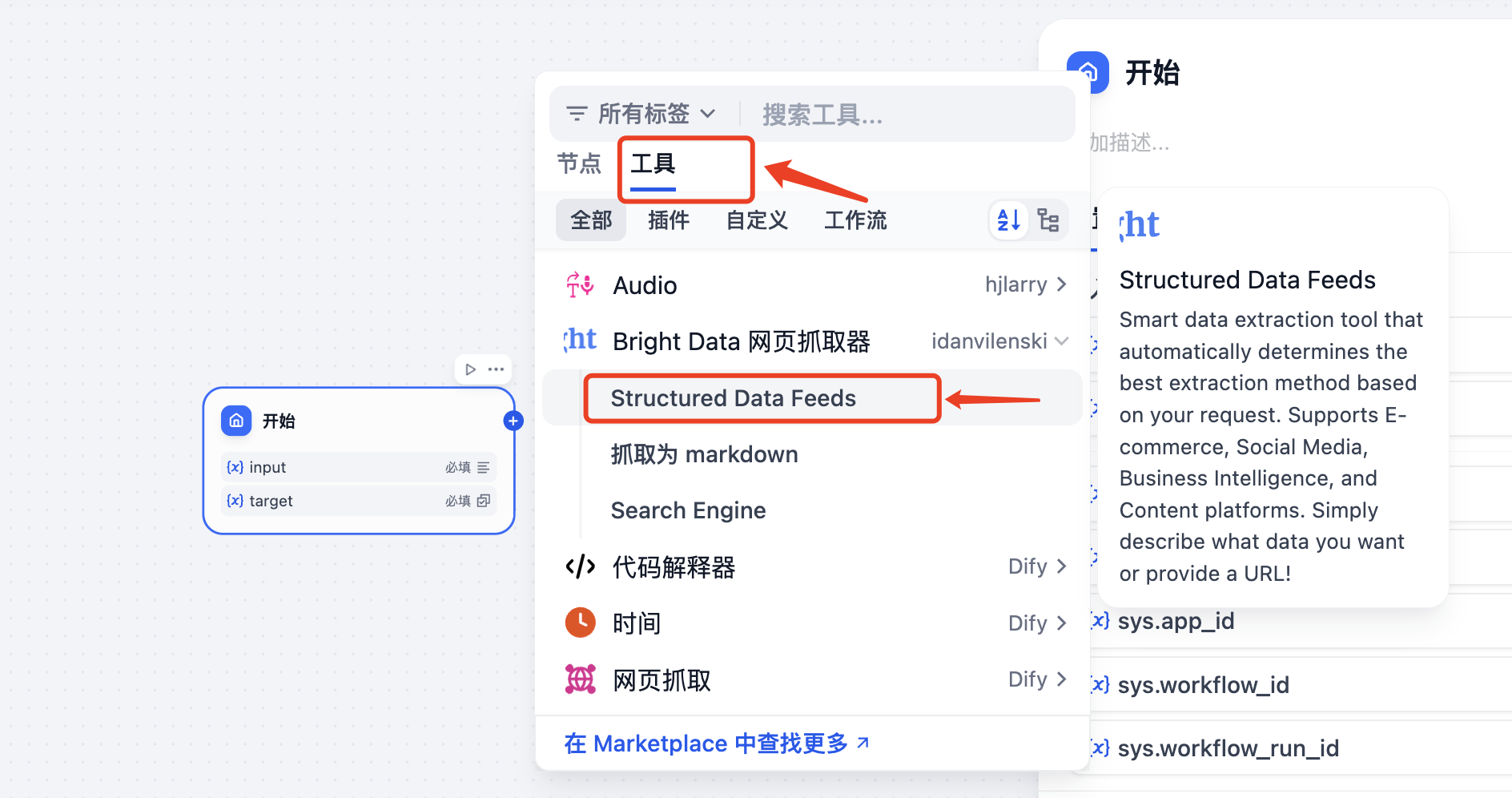
如果没有设置授权,这里会提示进行授权
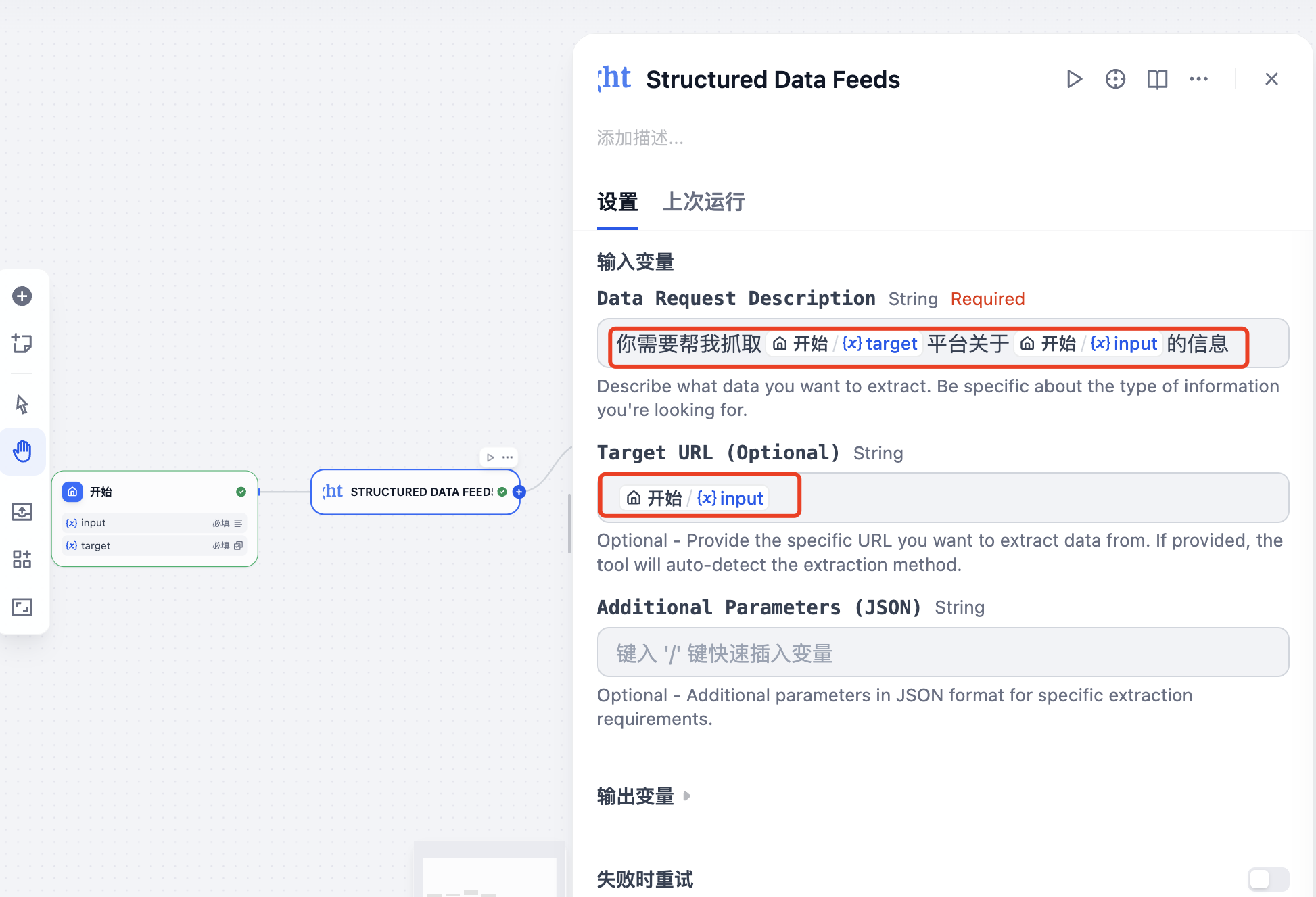
接下来需要设置该节点:
- Data Request Description:描述你想提取什么数据。具体说明你正在寻找的信息类型。
- Target URL (Optional):提供要从中提取数据的特定URL。如果提供,该工具将自动检测提取方法。
- Additional Parameters (JSON):JSON格式的其他参数,用于特定的提取要求。
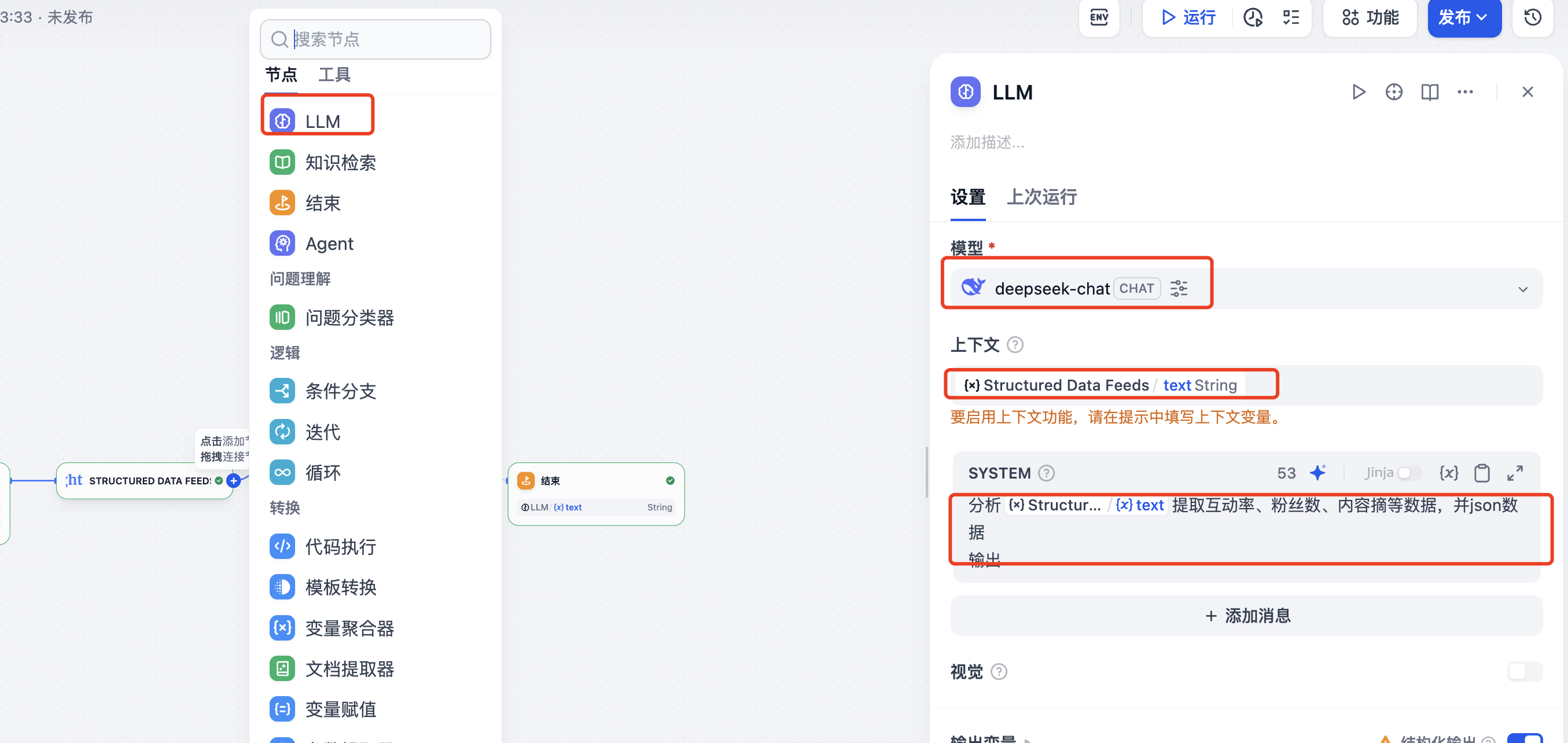
然后也是重点,设置LLM节点,需要大模型对抓取到的数据进行分析,过滤
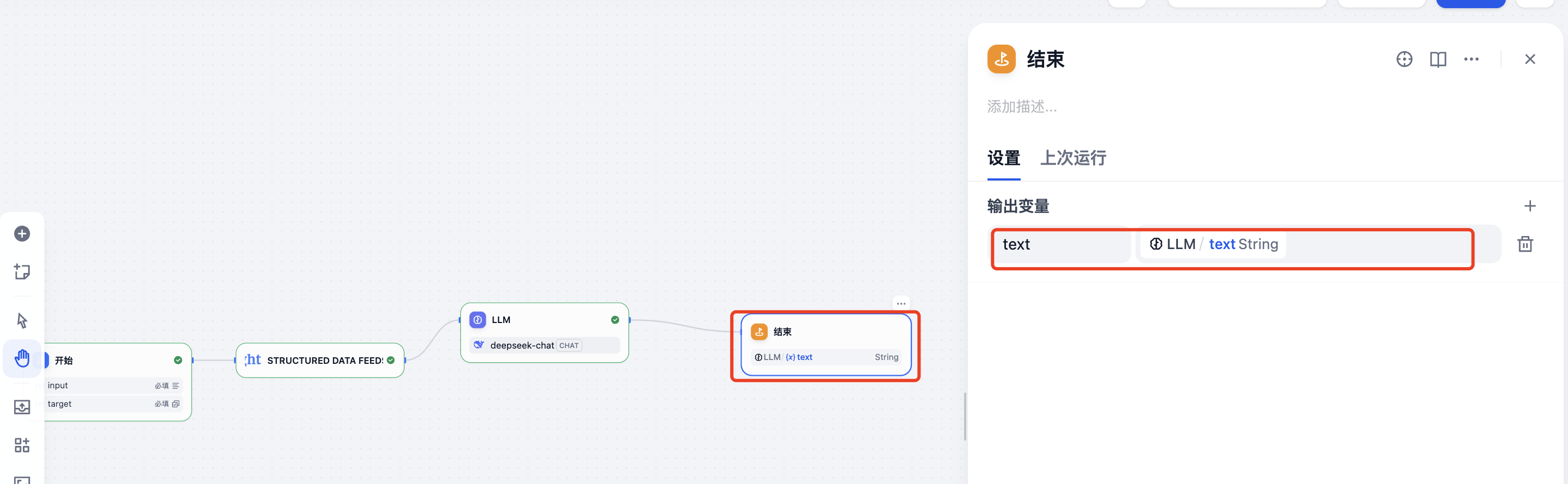
接下来我们可以设置结束节点,直接输出结果
也可以将结果存储到数据库,点击下面的"HTTP"请求,
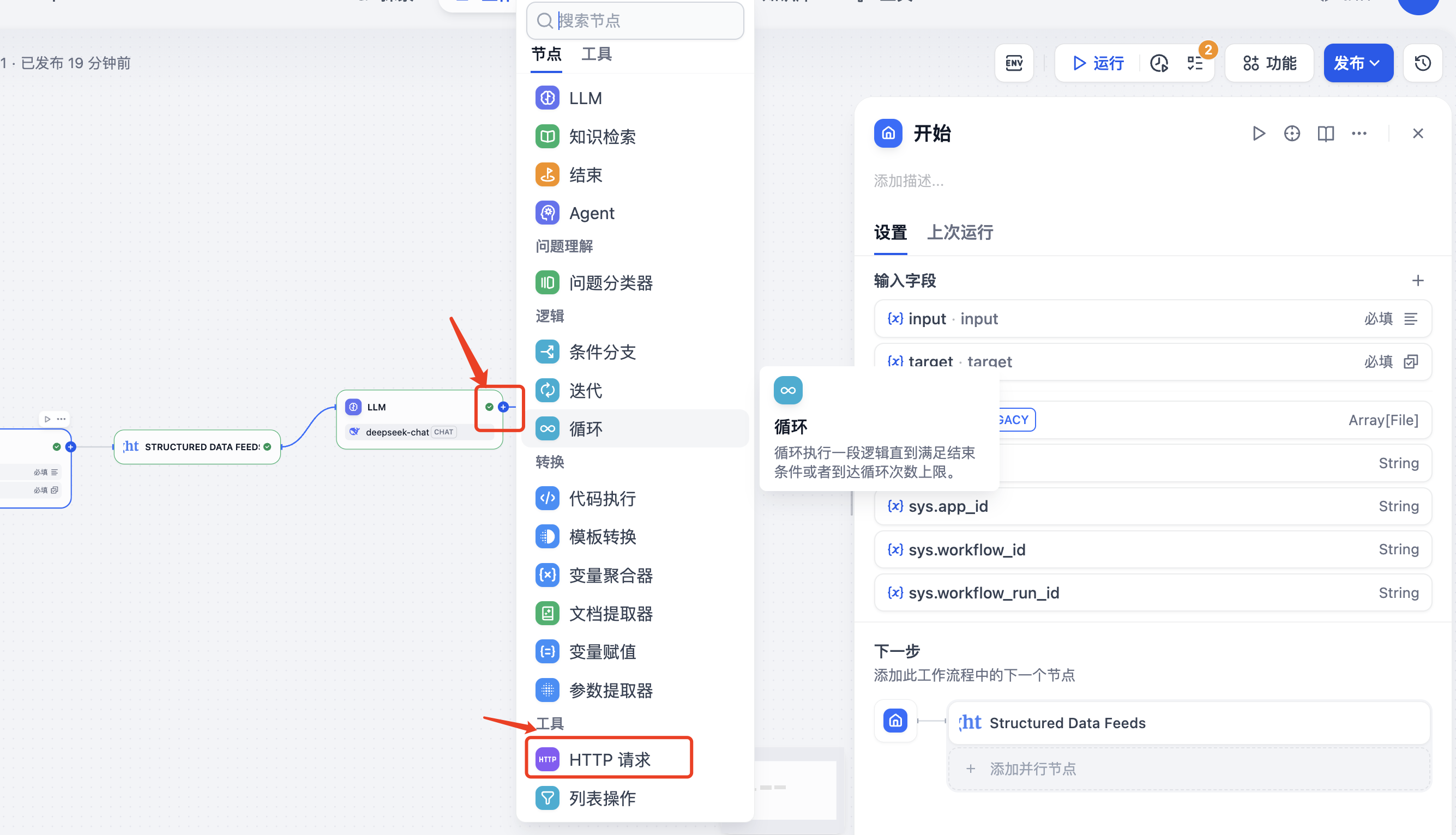
填写HTTP请求的的地址以及参数,就可以把数据保存到数据库
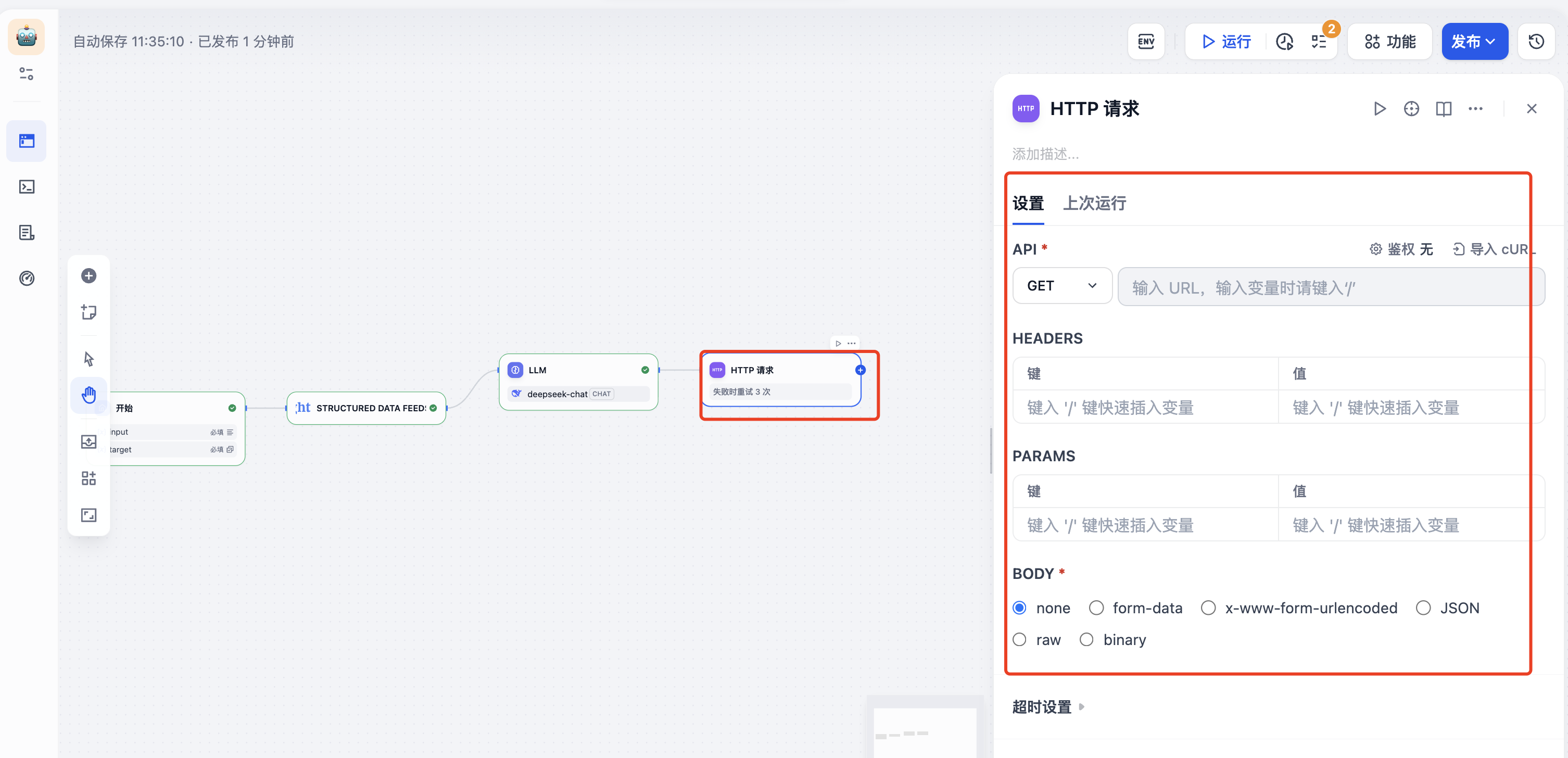
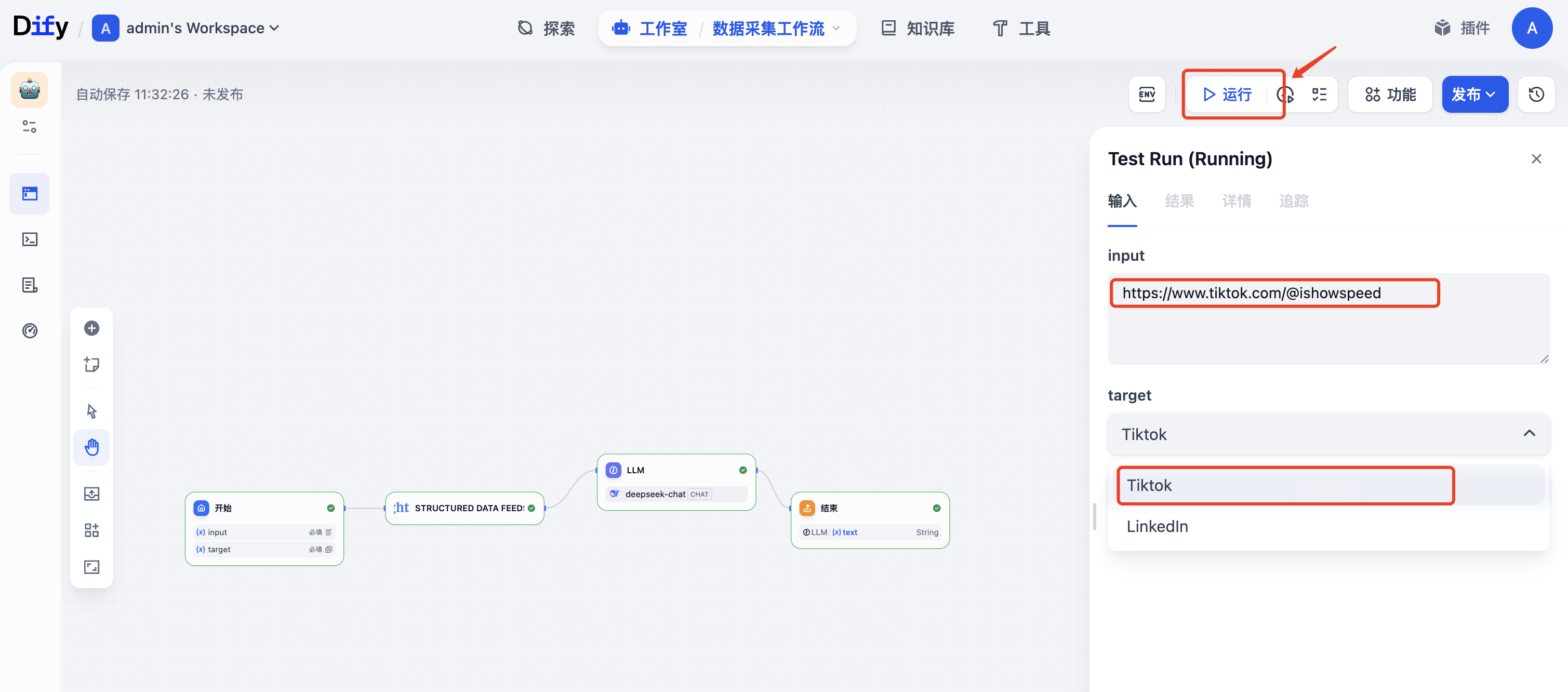
(4)运行
点击"允许",输入爬取的链接,以及选择平台
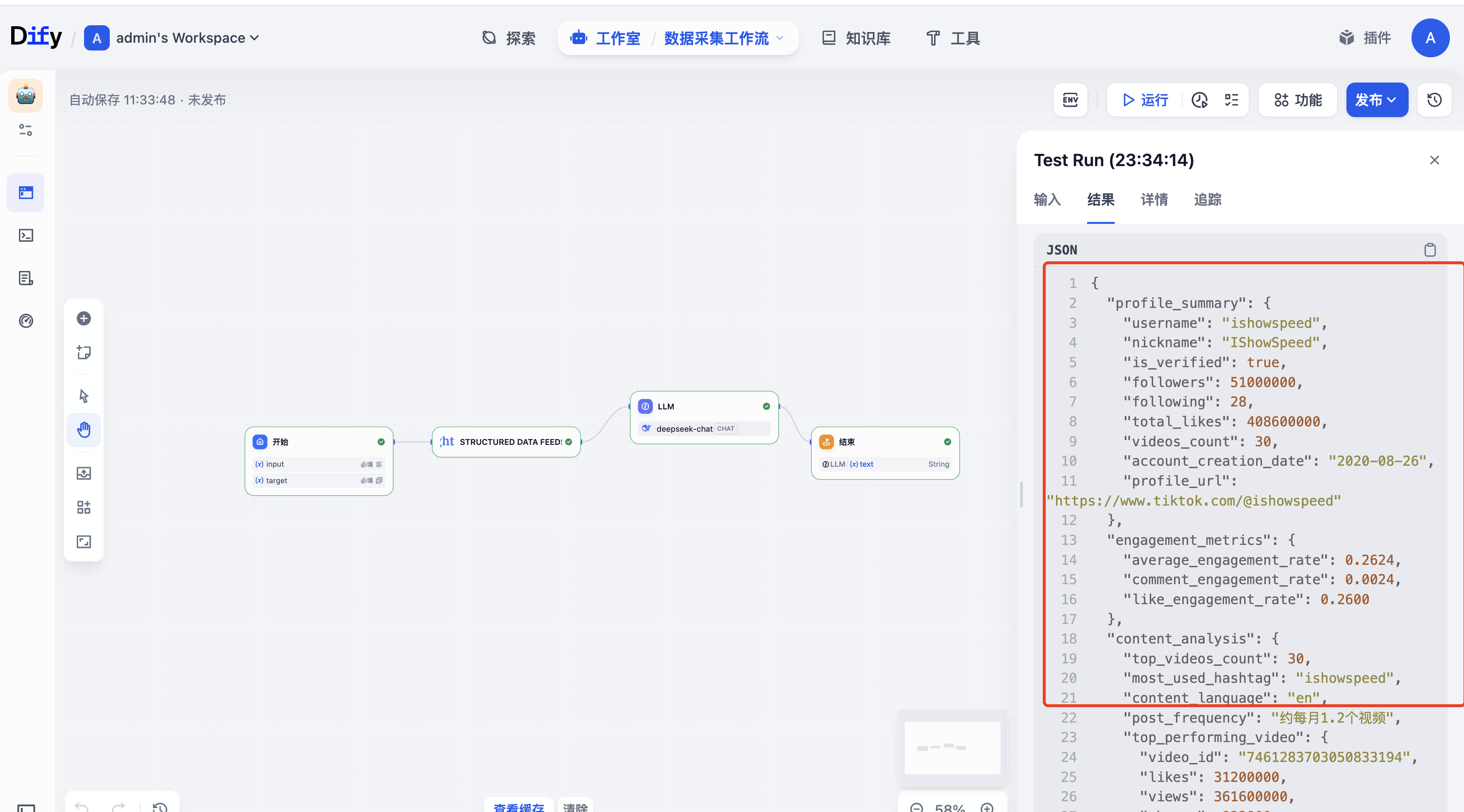
最终可以看到爬取到的数据
点击发布中的运行
最终我们可以重新走一下流程,输入爬取的地址:
https://www.tiktok.com/@ishowspeed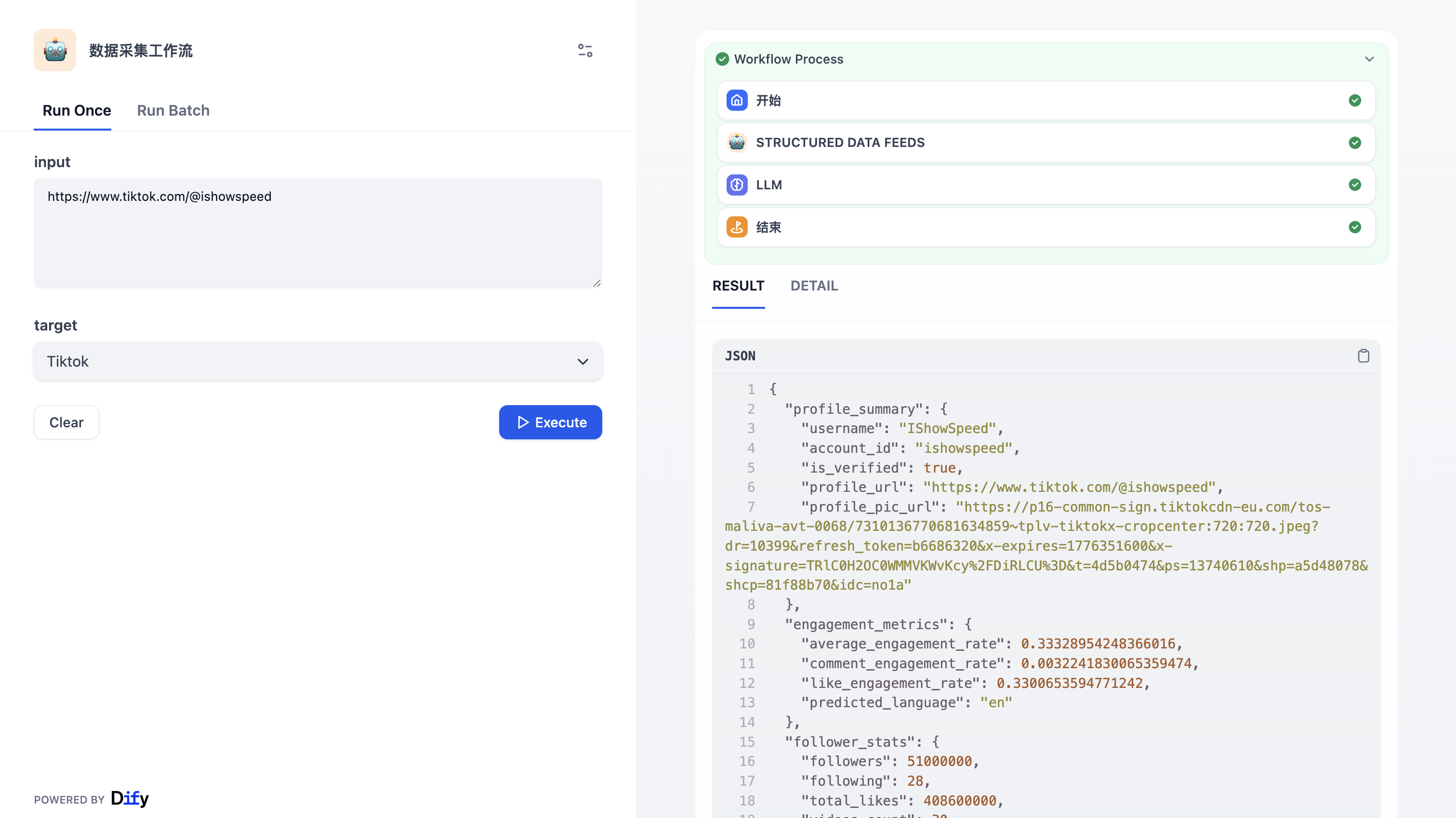
最终输出结果如下:
{
"profile_summary": {
"username": "ishowspeed",
"nickname": "IShowSpeed",
"is_verified": true,
"followers": 51000000,
"following": 28,
"total_likes": 408600000,
"videos_count": 30,
"account_created": "2020-08-26",
"profile_url": "https://www.tiktok.com/@ishowspeed"
},
"engagement_metrics": {
"average_engagement_rate": 26.24,
"like_engagement_rate": 26.00,
"comment_engagement_rate": 0.24,
"predicted_language": "en"
},
"top_performing_content": [
{
"video_id": "7259764735678221611",
"likes": 36800000,
"views": 326800000,
"shares": 1400000,
"comments": 243900,
"post_date": "2023-07-25",
"description": "#ishowspeed"
},
{
"video_id": "7461283703050833194",
"likes": 31200000,
"views": 361600000,
"shares": 923800,
"comments": 357100,
"post_date": "2025-01-18",
"description": "#ishowspeed"
},
{
"video_id": "7567543028659785015",
"likes": 25300000,
"views": 287800000,
"shares": 1400000,
"comments": 192500,
"post_date": "2025-11-01",
"description": "#ishowspeed"
}
],
"content_analysis": {
"total_top_videos": 30,
"average_video_likes": 11200000,
"most_used_hashtag": "#ishowspeed",
"content_frequency": "Regular posting since 2021",
"peak_performance_period": "2023-2025"
},
"recent_activity": {
"latest_video_date": "2026-03-25",
"earliest_video_date": "2021-09-05",
"activity_timeline": "4+ years of consistent content creation"
}
}
复制(5)体验感受
我跑了一个之前两小时就会被封的相同查询。结果它可以持续一直跑一天,都没有封禁,真的惊艳到我了
| 指标 | 自定义爬虫 | Bright Data MCP + Dify |
|---|---|---|
| 封锁率 | 超过 60% | 低于 1% |
| 数据成功率 | 约 40% | 超过 99% |
| 新平台接入时间 | 1 至 2 周 | 低于 30 分钟 |
| 月均维护时间 | 超过 20 小时 | 低于 2 小时 |
| 成本(1 万条数据) | 工程时间成本极高 | 按成功付费,成本可控 |
3、成本分析
| 方案 | 前期投入 | 月均维护 | 10 万条数据成本 |
|---|---|---|---|
| 自建爬虫 | 2 至 4 周工程时间 | 超过 20 小时/月 | 工程成本难以量化 |
| Bright Data MCP + Dify | 不到 1 天配置 | 低于 2 小时/月 | 按成功采集付费 |
Bright Data 采用"只为成功采集付费"的定价模式,价格从 $1.50/1K 请求起,无月度承诺。自建方案看似"免费",实际上浪费大量时间、持续维护的成本、以及数据封锁导致的数据损失,都是被严重低估的隐性支出。
总结
之前被各大平台封到怀疑人生,到一套工作流打通 TikTok、LinkedIn多平台采集,不需要再为每个网站单独写一套爬虫,也无需操心代理池和验证码。Dify Workflow 替代多套独立爬虫,Bright Data MCP 帮我搞定所有封锁问题。 立即免费注册 Bright Data,可以免费获取$20额度,5 分钟内搭建你的多平台数据采集流水线,只为成功采集的数据付费。
- Bright Data MCP 文档:https://github.com/brightdata/brightdata-mcp
- Dify 官网:https://dify.ai# 前言