摘要
K8s Scheduling Framework 是 Kubernetes 1.15+ 引入的调度器插件化架构,1.19 版本Stable状态。 它将调度过程抽象为多个可扩展的阶段(扩展点),允许开发者通过编写插件自定义调度行为,而无需修改核心调度器代码。
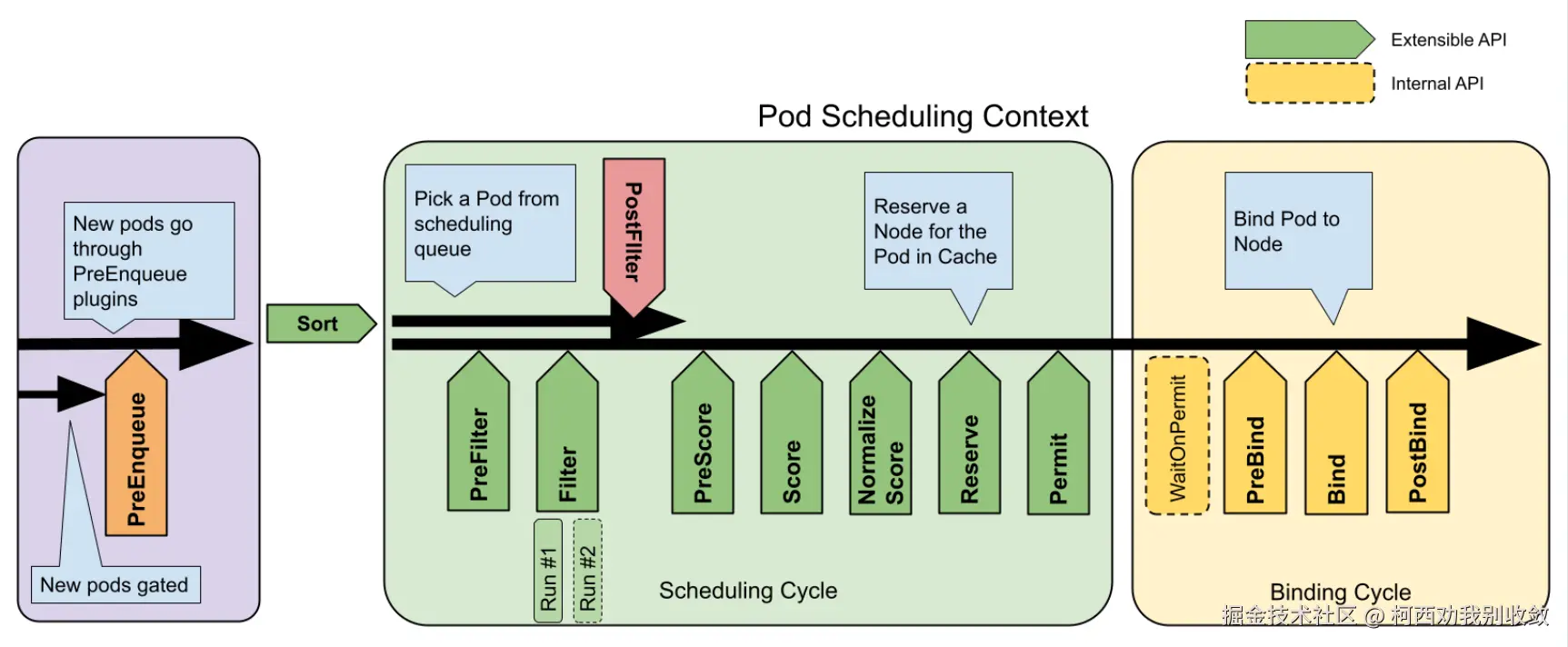
scss
┌───────────────────────────────────────────────────────────────────────────────┐
│ Pod Scheduling Context │
├───────────────────┬─────────────────────────────┬─────────────────────────────┤
│ Scheduling │ Scheduling Cycle │ Binding Cycle │
│ Queue │ (寻找合适的Node) │ (将Pod绑定到Node) │
└───────────────────┴─────────────────────────────┴─────────────────────────────┘调度流程
Pod Create 提交后会先在调度对队列(阶段一)种等待,直到准入调度后开始经历Filter/Score两个周期,最后进入到Bind绑定节点周期,从而完成创建。
阶段一:Scheduling Queue 调度队列
- PreEnqueue(入队前检查)
作用: Pod进入调度队列前的准入检查,决定Pod是否可以进入队列
经典案例:
| 场景 | 说明 |
|---|---|
| Scheduling Gates | K8s 1.27+ 特性,Pod被"gated"时暂停调度,等待外部条件满足(如等待数据准备完成) |
| PodGroup检查 | Gang Scheduling中,检查PodGroup是否满足最小成员数要求 |
阶段二:Scheduling Cycle 调度周期
⚠️ 各扩展点间串行执行,为Pod选择最合适的Node,必须快速完成(<100ms)
备注:Score阶段是存在多个Score插件并发执行的。
QueueSort
作用 :QueueSort 扩展用于对 Pod 的待调度队列进行排序,以决定先调度哪个 Pod,QueueSort 扩展本质上只需要实现一个方法 Less(Pod1, Pod2) 用于比较两个 Pod 谁更优先获得调度即可,同一时间点只能有一个 QueueSort 插件生效。
经典插件:
- PrioritySort:按Pod的PriorityClass排序,高优先级Pod先调度
vbnet
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:name: high-priority
value: 1000000 # 数值越大优先级越高preemptionPolicy: PreemptLowerPriority
description: "关键业务Pod"-
PreFilter
快速失败检查,过滤掉不符合要求的Pod
Pre-filter 扩展用于对 Pod 后续Filter阶段需要的信息进行预处理,或者检查一些集群或 Pod 必须满足的前提条件,快速失败检查。如果 pre-filter 返回了 error,则调度过程终止。
经典插件与案例:
| 插件 | 功能 | 案例 |
|---|---|---|
| NodeResourcesFit | 计算Pod请求的资源总量 | 检查节点是否有足够CPU/Memory |
| NodePorts | 检查Pod需要的NodePort是否冲突 | 避免端口冲突导致服务无法创建 |
| VolumeBinding | 检查PVC绑定状态 | 等待PV provision完成 |
yaml
apiVersion: v1
kind: Pod
spec:
volumes:
- name: data
persistentVolumeClaim:
claimName: my-pvc # 如果PV还未创建,PreFilter会标记"等待"-
Filter
逐个检查Node是否满足Pod的硬性要求,排除不符合的节点
Filter 扩展用于排除那些不能运行该 Pod 的节点,对于每一个节点,调度器将按顺序执行 filter 扩展;如果任何一个 filter 将节点标记为不可选,则余下的 filter 扩展将不会被执行。调度器可以同时对多个节点执行 filter 扩展。
经典插件与案例:
| 插件 | 功能 | 实际案例 |
|---|---|---|
| NodeSelector | 匹配node标签 | nodeSelector: {disktype: ssd} |
| NodeAffinity | 复杂的节点亲和性 | 优先选择同可用区节点 |
| Taint & Toleration | 处理节点污点 | GPU节点只调度AI任务 |
| PodTopologySpread | Pod拓扑分布 | 10个副本均匀分布在3个可用区 |
| NodeResourcesFit | 资源充足性检查 | 确保节点剩余CPU > 请求值 |
调度器里对于NodeSelector NodeAffinity Taint&Toleration 比较的顺序,谁先谁后?
默认 Taint&Toleration比较靠后,可以通过配置调度器配置Profile来调整。
PostFilter
Filter阶段无可用节点时的补救措施:帮助无家可归的Pod找妈妈
这些插件在 Filter 阶段后调用,但仅在该 Pod 没有可行的节点时调用。 插件按其配置的顺序调用。如果任何 PostFilter 插件标记节点为"Schedulable", 则其余的插件不会调用。典型的 PostFilter 实现是抢占,试图通过抢占其他 Pod 的资源使该 Pod 可以调度。
yaml
# 案例:高优先级Pod抢占低优先级资源
apiVersion: v1
kind: Pod
metadata:
name: critical-pod
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
spec:
priorityClassName: system-cluster-critical # 关键系统Pod
containers:
- name: app
resources:
requests:
memory: "4Gi" # 如果节点不足,会抢占低优先级Pod抢占低优先级Pod是杀掉Pod的还是什么操作?

案例:抢占操作要求释放有控制器的Pod进入Terminating
makefile
#流程图
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Deployment │ │ Pod-1 │ │ Pod-2 │
│ (控制器) │◄──────── │ (被抢占驱逐) │ │ (正常运行) │
│ replicas=2 │ 检测到 │ Terminating│ │ │
└──────┬──────┘ Pod缺失 └─────────────┘ └─────────────┘
│
│ 对比当前状态 vs 期望状态
│ (2 running ≠ 2 desired)
│
▼
┌─────────────┐
│ 创建新Pod │────▶ 进入调度队列 ────▶ 可能再次遇到抢占...
│ Pod-3 │ (如果资源仍不足)
└─────────────┘
#时间线
T0: 高优先级Pod-A需要调度,但资源不足
└─► 调度器选择牺牲者:低优先级Pod-B(属于Deployment-X)
T1: 抢占发生
├─► 向Pod-B发送SIGTERM(优雅终止)
├─► Pod-B进入Terminating状态
└─► 释放资源
T2: Pod-A调度成功,绑定到节点,开始启动
T3: Deployment控制器发现:
├─► 当前running Pod数:1 (Pod-C)
├─► 期望replicas:2
└─► 差异:-1
T4: Deployment创建新Pod-D(Replacement)
└─► Pod-D进入调度队列
T5: 如果资源仍紧张,Pod-D可能:
├── 调度到其他有资源的节点 ✅
├── 触发新一轮抢占(驱逐其他低优先级Pod)⚠️
└── 无法调度,Pending状态 ⏳总结:集群资源紧张的时候,一个抢占行为,可能会触发一连串抢占发生,形成抢占雪崩
PreScore
作用: 为Score阶段预处理数据,计算打分所需的共享信息
这些插件用于执行 "前置评分(pre-scoring)" 工作,即生成一个可共享状态供 Score 插件使用。 如果 PreScore 插件返回错误,则调度周期将终止。
经典插件与案例
- NodeResourcesFit:计算节点资源分配比例,供后续打分使用
Score
为通过Filter的节点打分,分数越高越优,可能会有多个Score插件并发计算得分
这些插件用于对通过过滤阶段的节点进行排序。调度器将为每个节点调用每个评分插件。 将有一个定义明确的整数范围,代表最小和最大分数。 在标准化评分阶段之后,调度器将根据配置的插件权重 合并所有插件的节点分数。
| 插件 | Score逻辑 | Score目的 |
|---|---|---|
| NodeResourcesLeastAllocated | 优先选择资源使用率低的节点 | 集群负载均衡,避免热点 |
| NodeResourcesMostAllocated | 优先选择资源使用率高的节点 | 提高节点利用率,节省成本 |
| NodeResourcesBalancedAllocation | 优先选择CPU/Memory使用均衡的节点 | 避免资源碎片化 |
| ImageLocality | 优先选择已有镜像的节点 | 加速Pod启动(大镜像场景) |
| InterPodAffinity | 根据Pod亲和性打分 | 将前端Pod调度到靠近缓存Pod的节点 |
| NodeAffinity | 根据节点亲和性偏好打分 | 优先选择SSD节点,HDD也能用 |
ImageLocality是如何获取该节点是否包含已有镜像
ImageLocality插件读取 Node对象的Status字段:
dart
# kubectl get node node-1 -o yaml apiVersion: v1 kind: Node status: images: # kubelet定期上报节点上的镜像列表 - names: - docker.io/library/nginx@sha256:abc123... - docker.io/library/nginx:latest sizeBytes: 192089424 - names: - docker.io/library/busybox@sha256:def456... sizeBytes: 1234567场景描述
yaml
Pod需要镜像:
- my-app:1.0 (500MB)
- sidecar:2.0 (50MB)
Node A状态:
images: [nginx, redis] # 无所需镜像
Score: 0分
Node B状态:
images: [my-app:1.0] # 有主镜像
Score: 50分 (500MB/1000MB * 100)
Node C状态:
images: [my-app:1.0, sidecar:2.0] # 全都有
Score: 55分 (550MB/1000MB * 100) → 最高分,选中Node C-
NormalizeScore
作用: 将不同Score插件的分数统一到0-100范围,便于加权计算
这些插件用于在调度器计算 Node 排名之前修改分数。 在此扩展点注册的插件被调用时会使用同一插件的 Score 结果。 每个插件在每个调度周期调用一次。
Reserve
作用: 临时占用资源,防止并发调度时的资源冲突(原子操作)
经典插件
- VolumeBinding:预绑定PVC到PV
- DynamicResources:预留DRA(动态资源分配)资源
scss
// 伪代码:Reserve阶段
func Reserve(pod, node) {
// 1. 在缓存中标记"此Pod将使用这些资源"
cache.AssumePodScheduled(pod, node)
// 2. 预绑定PVC(异步操作)
volumeBinder.BindPVCs(pod)
// 如果后续失败,需要Unreserve回滚
}关键特性
-
如果Reserve成功但后续失败,会触发 Unreserve 回滚
-
保证调度的一致性,避免资源泄漏
Permit(许可)
作用: 调度决策后的拦截点
-
Approve:批准,进入Binding阶段
-
Deny:拒绝,Pod返回队列重试
-
Wait:等待外部条件(超时机制)
经典案例
| 场景 | 实现 | 说明 |
|---|---|---|
| Gang Scheduling | Coscheduling插件 | 等待PodGroup所有成员都调度成功才放行 |
| Quota限制 | 自定义插件 | 检查命名资源配额,超限则等待 |
| 设备拓扑感知 | GPU拓扑插件 | 等待最佳GPU拓扑组合可用 |
bash
# Gang Scheduling案例(使用scheduler-plugins) apiVersion: v1
kind: Pod
metadata:name: pod-a
labels:pod-group.scheduling.sigs.k8s.io/name: job-123pod-group.scheduling.sigs.k8s.io/min-available: "3" # 需要3个Pod一起调度spec:schedulerName: scheduler-plugins-scheduler如果资源不够Gang组所有成员就绪启动,会进入什么阶段呢?
ini
PodGroup需要3个Pod,当前只有2个就绪
│
▼
┌───────────────────┐
│ Permit阶段 │
│ Coscheduling插件 │
│ 检查PodGroup │
│ minAvailable=3 │
│ current=2 ❌ │
└───────────────────┘
│
▼
┌─────────────────┐
│ Permit: Wait │◄──── 进入等待状态
│ timeout=30s │ (默认等待时间)
└─────────────────┘
│
┌────┴────┐
▼ ▼
┌──────────┐ ┌───────────┐
| 超时(30s) | | 第3个Pod |
| 到达 | | 进入Permit|
└────┬─────┘ └────┬──────┘
│ │
▼ ▼
┌────────┐ ┌───────────┐
| Permit: | | current=3 │
| Deny | | ✅ Approve│
| 拒绝 | | 全部放行 │
└────┬────┘ └───────────┘
│
▼
┌──────────────┐
| Pod返回队列 │
| 重新调度 │
| (backoff机制)│
└──────────────┘- 详细行为
| 场景 | 行为 | 结果 |
|---|---|---|
| 等待期间第3个Pod到达 | 所有Pod Permit: Approve,同时进入Binding | ✅ Gang成功 |
| 等待超时(默认30s) | 所有等待的Pod Permit: Deny,返回调度队列 | ❌ Gang失败,重试 |
| Pod被删除 | 从PodGroup中移除,重新计算minAvailable | 可能满足条件 |
- 配置参数
shell
# Coscheduling插件配置(scheduler-plugins) apiVersion: kubescheduler.config.k8s.io/v1 kind: KubeSchedulerConfiguration profiles: - schedulerName: coscheduling-scheduler plugins: permit: enabled: - name: Coscheduling pluginConfig: - name: Coscheduling args: permittedWaitingTimeSeconds: 30 # Permit等待超时时间 deniedWaitingTimeSeconds: 3 # 拒绝后冷却时间 podGroupGCIntervalSeconds: 30 # PodGroup清理间隔- 场景案例
yaml
# 需要3个Pod组成Gang,分布式训练
apiVersion: v1
kind: Pod
metadata:
name: worker-0
labels:
pod-group.scheduling.sigs.k8s.io/name: ai-training-job-001
pod-group.scheduling.sigs.k8s.io/min-available: "3"
spec:
schedulerName: scheduler-plugins-scheduler
containers:
- name: training
image: pytorch/pytorch:latest
resources:
limits:
nvidia.com/gpu: 4 # 每个Pod需要4 GPU
---
# 同时创建 worker-1, worker-2
# 场景1:集群只有8 GPU(2个节点各4 GPU)
# - worker-0调度到Node A,Permit: Wait
# - worker-1调度到Node B,Permit: Wait
# - worker-2无法调度(无足够GPU),等待超时
# - worker-0,1被Deny,全部重试
# 场景2:集群有12 GPU(3个节点各4 GPU)
# - 3个Pod分别调度到3个节点,Permit都Wait
# - 第3个Pod到达后,current=3 >= minAvailable
# - 3个Pod同时Approve,同时Binding,同时启动
# - 分布式训练正常开始(避免部分启动导致NCCL超时)阶段三:Binding Cycle 绑定周期
异步执行,不影响下一个Pod的调度,可以较慢
PreBind
作用: 绑定Node前的最终检查/准备工作
经典插件
- VolumeBinding:确认PV已绑定,执行最终的Volume操作
- NodeLabeling:为节点打标签(如标记GPU已分配)
Bind
作用 : 调用API Server将Pod spec.nodeName 设置为选中节点
经典案例
- DefaultBind:默认绑定插件
- 自定义Bind插件:多集群调度器中,将Pod绑定到远程集群
PostBind
作用: 绑定成功后的清理/记录工作
经典插件
- 清理Reserve状态:释放预留缓存
- 调度事件记录:发送调度成功事件
- Metrics上报:记录调度延迟等指标
Scheduler Profile 配置示例
yaml
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
plugins:
# 批处理场景:优先资源均衡
score:
enabled:
- name: NodeResourcesBalancedAllocation
weight: 100
- name: NodeResourcesLeastAllocated
weight: 40
disabled:
- name: NodeResourcesMostAllocated
# 启用Gang Scheduling
permit:
enabled:
- name: Coscheduling
# 存储敏感场景
preBind:
enabled:
- name: VolumeBinding
- schedulerName: cost-optimized-scheduler
plugins:
# 成本优化:优先填满节点
score:
enabled:
- name: NodeResourcesMostAllocated # 优先高利用率
weight: 100
- name: ImageLocality # 减少镜像拉取
weight: 50每个扩展点都提供了精细控制调度行为的能力,可以根据业务需求组合使用。