使用的系统
css
gillbert@pop-os:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Pop
Description: Pop!_OS 24.04 LTS
Release: 24.04
Codename: noble硬件环境
需要安装好GPU启动,安装CUDA和cuDNN
推荐安装方式: 手动安装GPU驱动,然后使用pip命令安装CUDA和cuDNN
安装GPU驱动
我们需要根据自己的GPU型号安装对应的驱动版本,我的是RTX 2070,安装了580版本的驱动
arduino
apt install nvidia-driver-580-open安装完成后重启系统,重启后我们可以看到显卡被正常驱动了
sql
gillbert@pop-os:~$ nvidia-smi
Sat Apr 18 15:26:38 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.18 Driver Version: 580.126.18 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 2070 Off | 00000000:03:00.0 Off | N/A |
| 45% 30C P8 12W / 175W | 1MiB / 8192MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+创建虚拟环境
首先我们配置下conda环境,配置方式可以参考juejin.cn/post/760107...
使用conda切换到llm虚拟python环境
ruby
# 创建虚拟环境
conda create -n llm python=3.12
# 切换到llm虚拟环境
(base) gillbert@pop-os:~$ conda activate llm
(llm) gillbert@pop-os:~$ 下载模型
这里我们使用git下载
ruby
# 安装git
(llm) gillbert@pop-os:~$ sudo apt install git git-lfs
# 下载模型
(llm) gillbert@pop-os:~$ cd models/
(llm) gillbert@pop-os:~/models$ git clone https://www.modelscope.cn/Qwen/Qwen3.5-0.8B.git安装vLLM
安装vLLM时候会自动安装CUDA和cuDNN
ruby
# 注意:在我们激活的python环境下安装
(llm) gillbert@pop-os:~$ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
(llm) gillbert@pop-os:~$ pip install vllm启动模型
css
vllm serve Qwen3.5-0.8B --tensor-parallel-size 1 --gpu-memory-utilization 0.7 --max-model-len 4096 --host 0.0.0.0 --port 8000 --api-key 123456逐参数解释(超级通俗版)
vllm serve Qwen3.5-2B
- 作用 :启动 vLLM 服务,并加载 千问 3.5-2B 这个模型
serve= 启动 API 服务(OpenAI 兼容接口)
--tensor-parallel-size 1
- 张量并行大小
- 意思:使用 1 张显卡运行模型
- 你只有一张 RTX 2070,所以必须写
1
--gpu-memory-utilization 0.7
- GPU 显存利用率上限 = 70%
- 0.7 = 最多占用 70% 显存
- 好处:不会爆显存,系统不会卡
- RTX 2070 8G 显存非常适合这个值
--max-model-len 4096
- 模型最大上下文长度 = 4096
- 简单说:一次最多能处理 4096 个 tokens(文字)
- 约等于 3000 个汉字 的对话长度
--host 0.0.0.0
- 允许局域网所有设备访问
- 手机、其他电脑、Open WebUI 都能连
- 如果只允许本机用:改成
127.0.0.1
--port 8000
- 服务端口号:8000
- 访问地址:
http://localhost:8000
--api-key 123456
- API 密钥
- Open WebUI 连接时需要填这个密钥
启动Open WebUI
Open WebUI 是一款可扩展、功能丰富且易用的自托管 AI 平台 ,专为完全离线运行 而设计。它支持 Ollama 以及各类 OpenAI 兼容接口,是一款强大的、不依赖特定服务商的解决方案,可用于本地模型与云端模型。
创建新的python虚拟环境
lua
# 创建open-webui虚拟环境
(base)gillbert@pop-os:~$ conda create -n open-webui python=3.12
# 激活虚拟环境
(base) gillbert@pop-os:~$ conda activate open-webui
(open-webui) gillbert@pop-os:~$安装Open WebUI
kotlin
# 配置清华源
(open-webui) gillbert@pop-os:~$ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装open-webui
(open-webui) gillbert@pop-os:~$ pip install open-webui启动
设置代理,由于Open Web UI需要下载一些模型,访问外网速度会很慢,因此我们设置下代理(在open-webui虚拟环境下执行)
ini
# 把 192.168.0.2:10809 换成你的代理(http 或 socks5)
export http_proxy="http://192.168.0.2:10809"
export https_proxy="http://192.168.0.2:10809"
export all_proxy="socks5://192.168.0.2:10809"
# 本地/内网不走代理(必须加)
export no_proxy="localhost,127.0.0.1,::1,192.168.0.0/16,.local"
# 大写变量(有些程序只认大写)
export HTTP_PROXY="$http_proxy"
export HTTPS_PROXY="$https_proxy"
export ALL_PROXY="$all_proxy"
export NO_PROXY="$no_proxy"Open WebUI默认监听在8080端口
kotlin
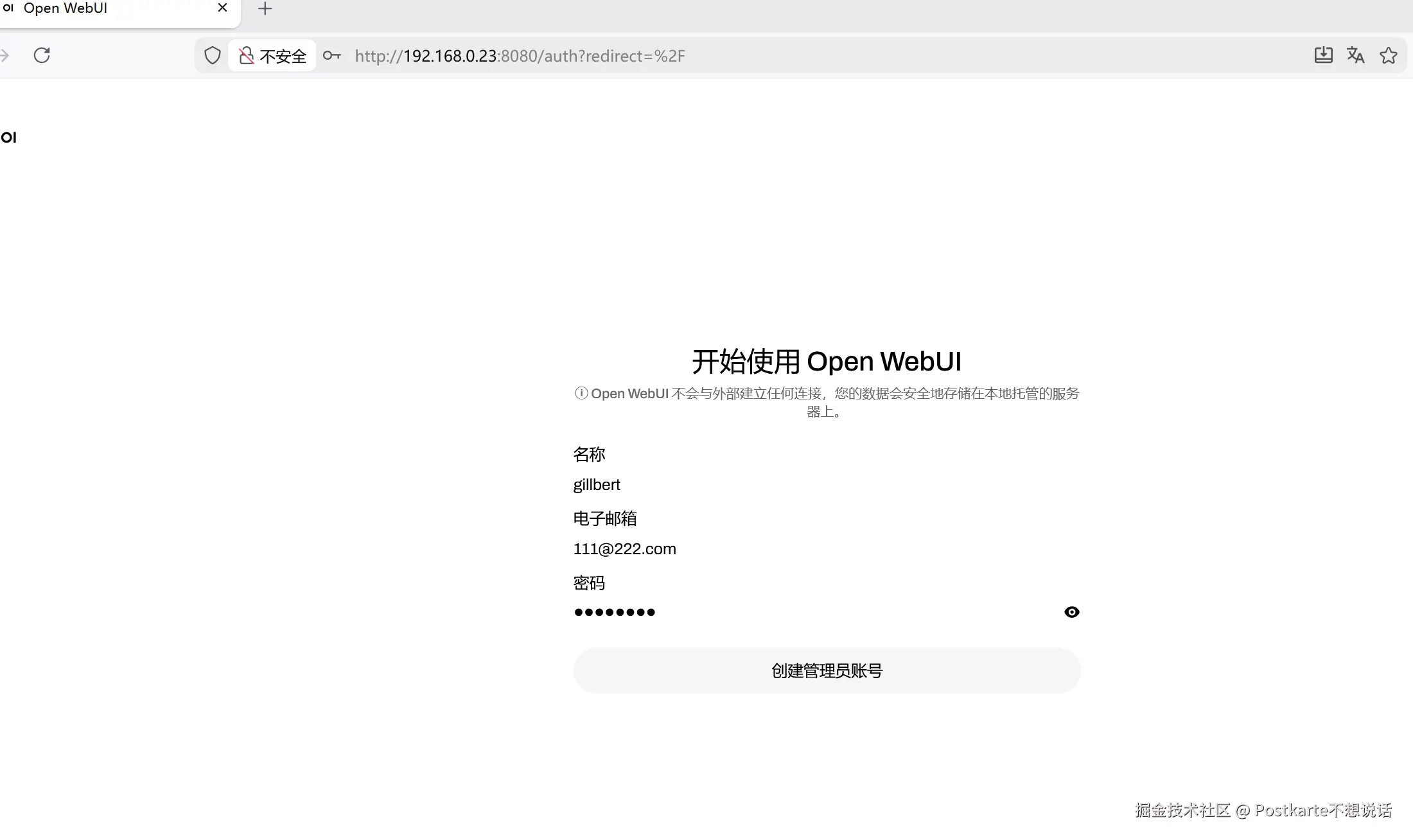
(open-webui) gillbert@pop-os:~$ open-webui serve 服务启动后访问8080端口,首先创建账号
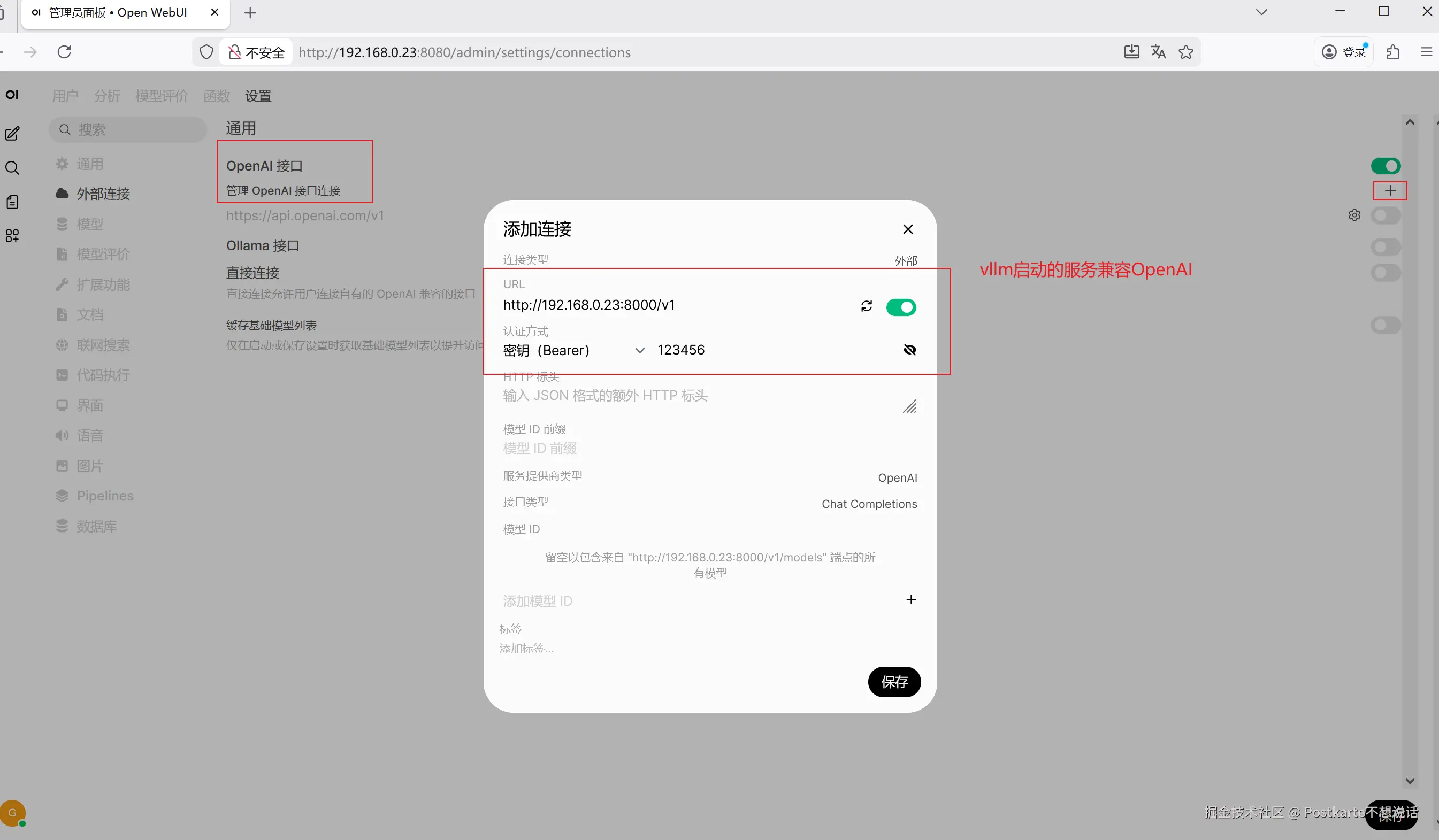
配置模型,这里配置上前面我们使用vLLM启动的模型
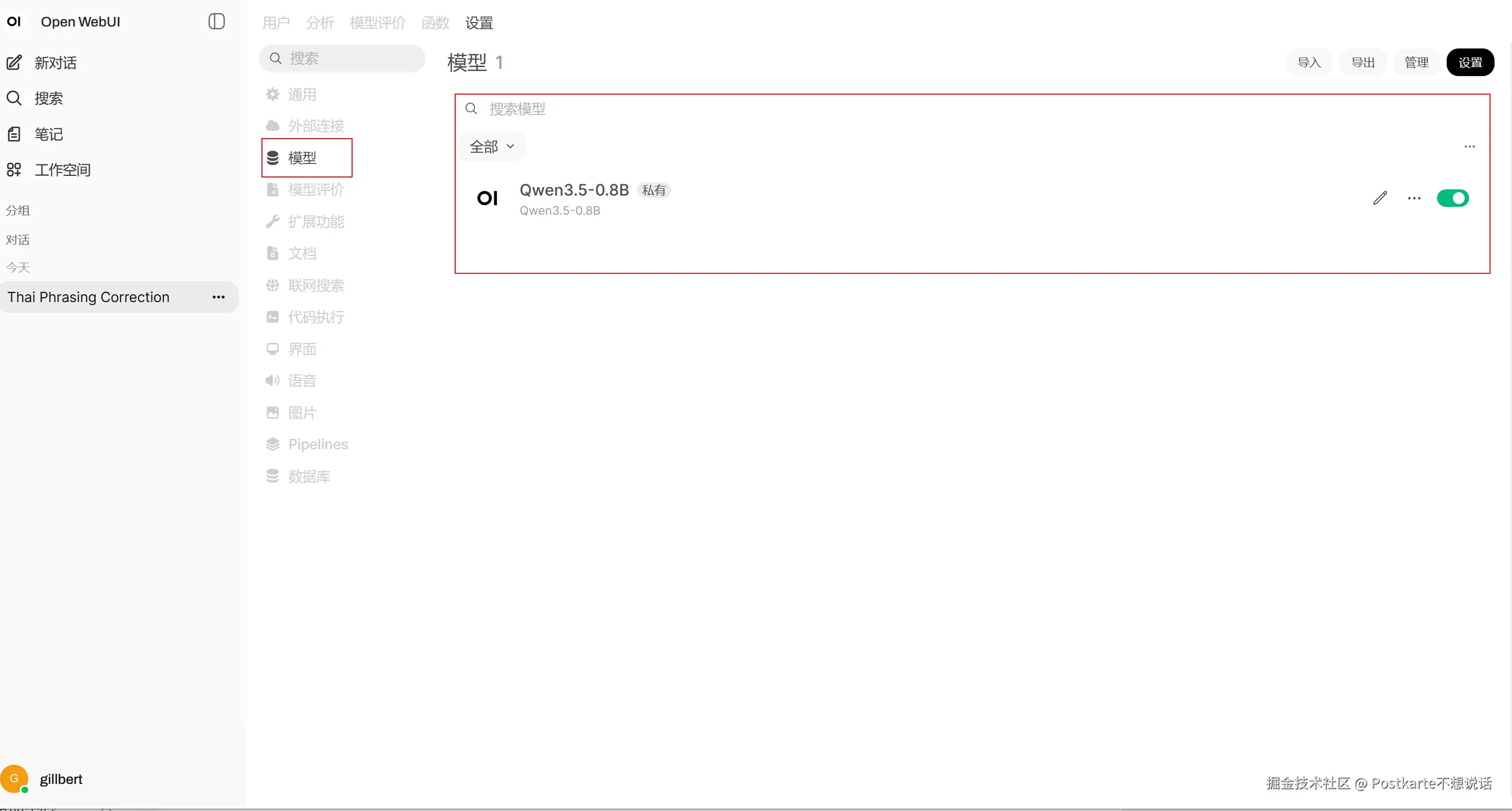
测试对话正常使用了