日志模块:
程序错误或者操作错误
常见日志以及获取(记录)方式
第三方日志方案:
winston类比:wepack
pino类比vite
通用业务系统日志系统配置(学习定时任务)

按功能分类:
● 错误日志 -> 方便定位问题,给用户友好的提示
● 调试日志 -> 方便开发
● 请求日志-> 记录敏感行为
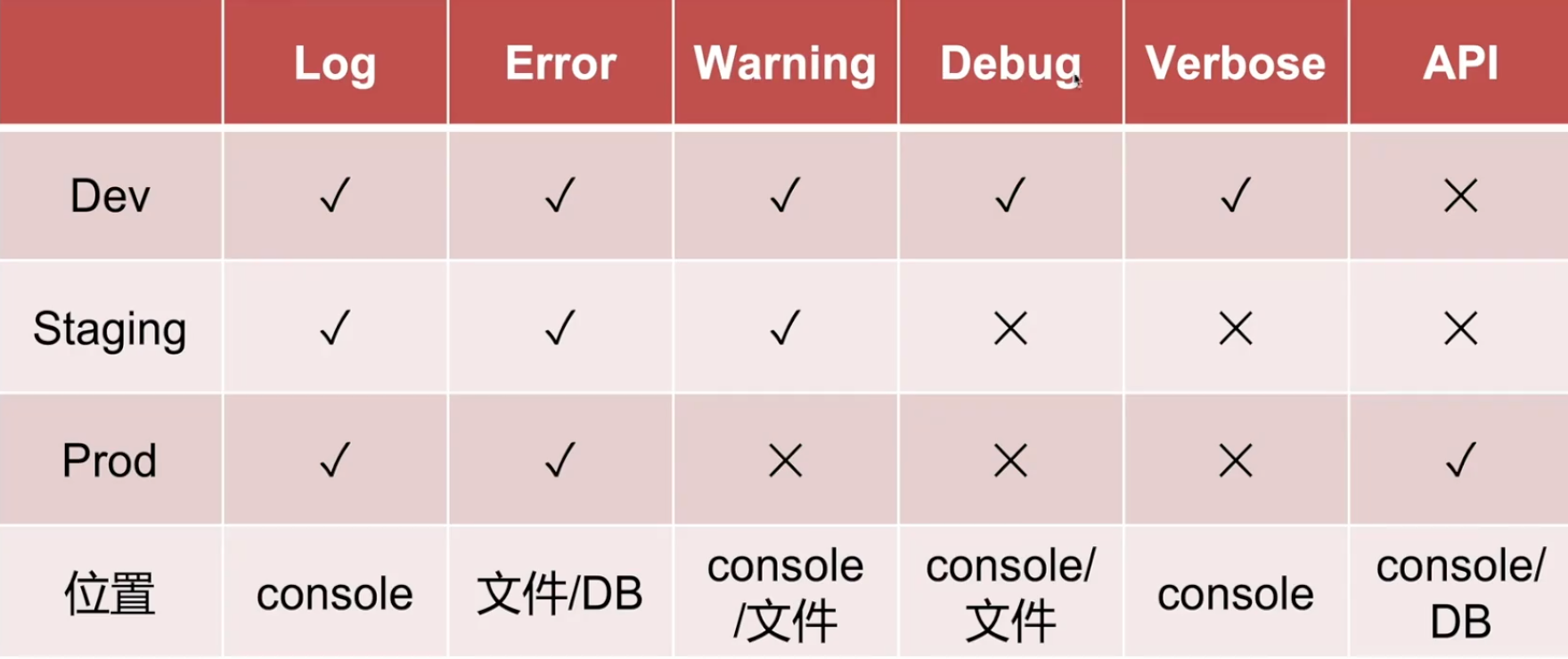
日志记录位置:
● 控制台日志->方便监看(调试用)
● 文件日志->方便回溯与追踪(24小时滚动)
● 数据库日志->敏感操作、敏感数据记录
nestjs中记录日志位置推荐
自带的日志模块:
● 局部模块声明
ts
private logger = new Logger(UserController.name);第三方日志模块:
pino
http://getpino.io/#/docs/benchmarks
https://github.com/pinojs/pino/blob/HEAD/docs/web.md#nest
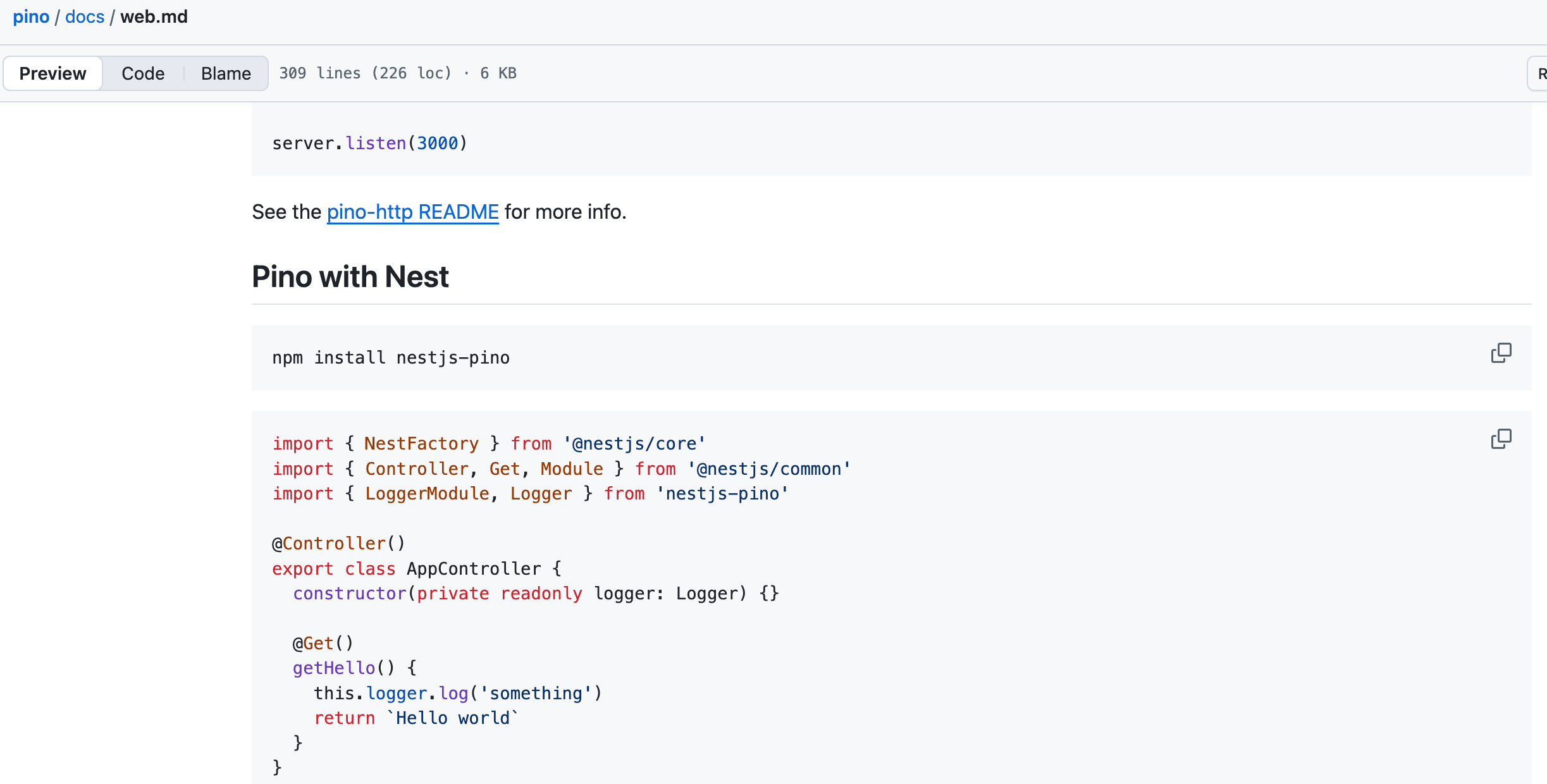
● pino不需要调用log方法,本身在安装之后只要有请求就会自动打印日志
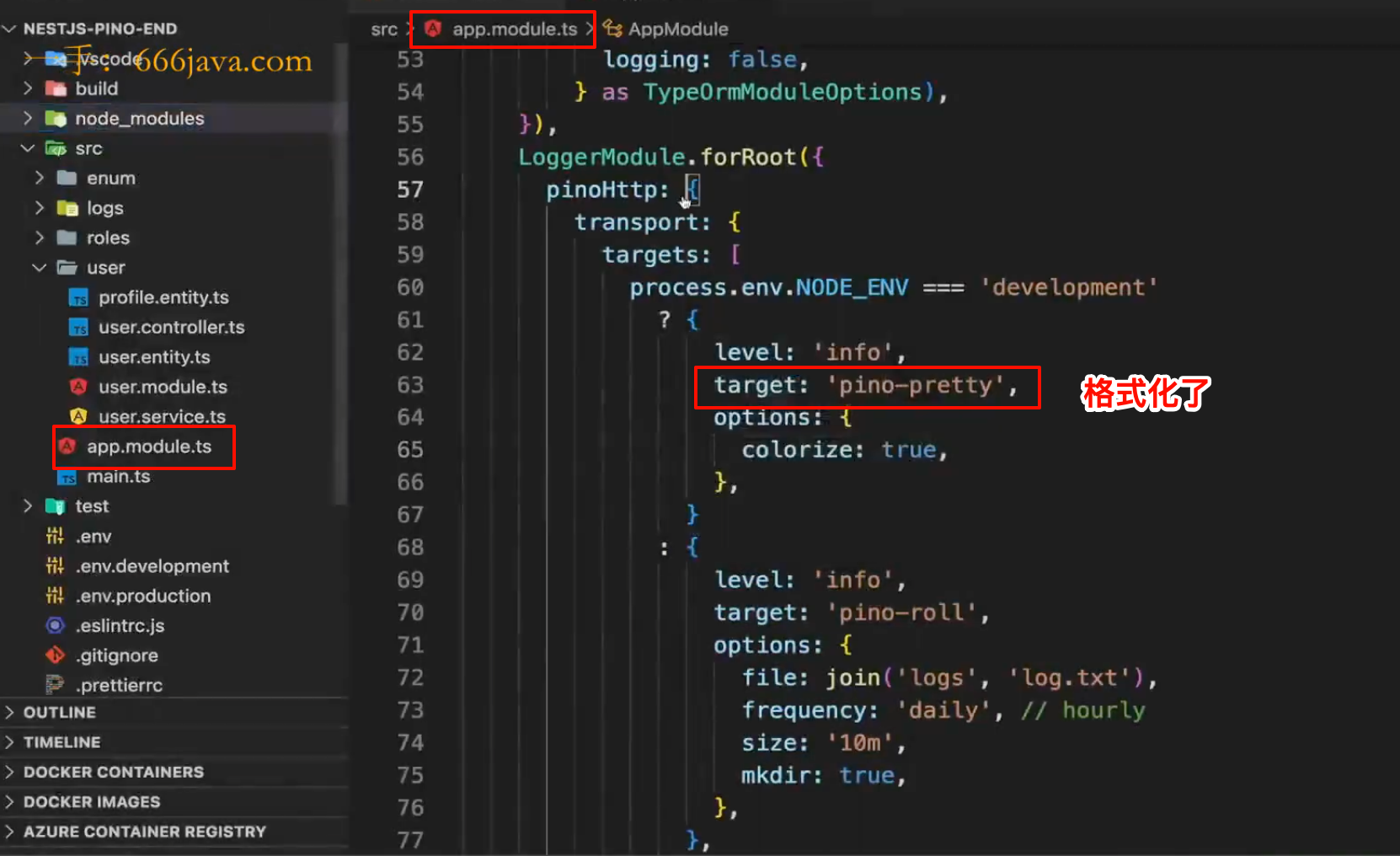
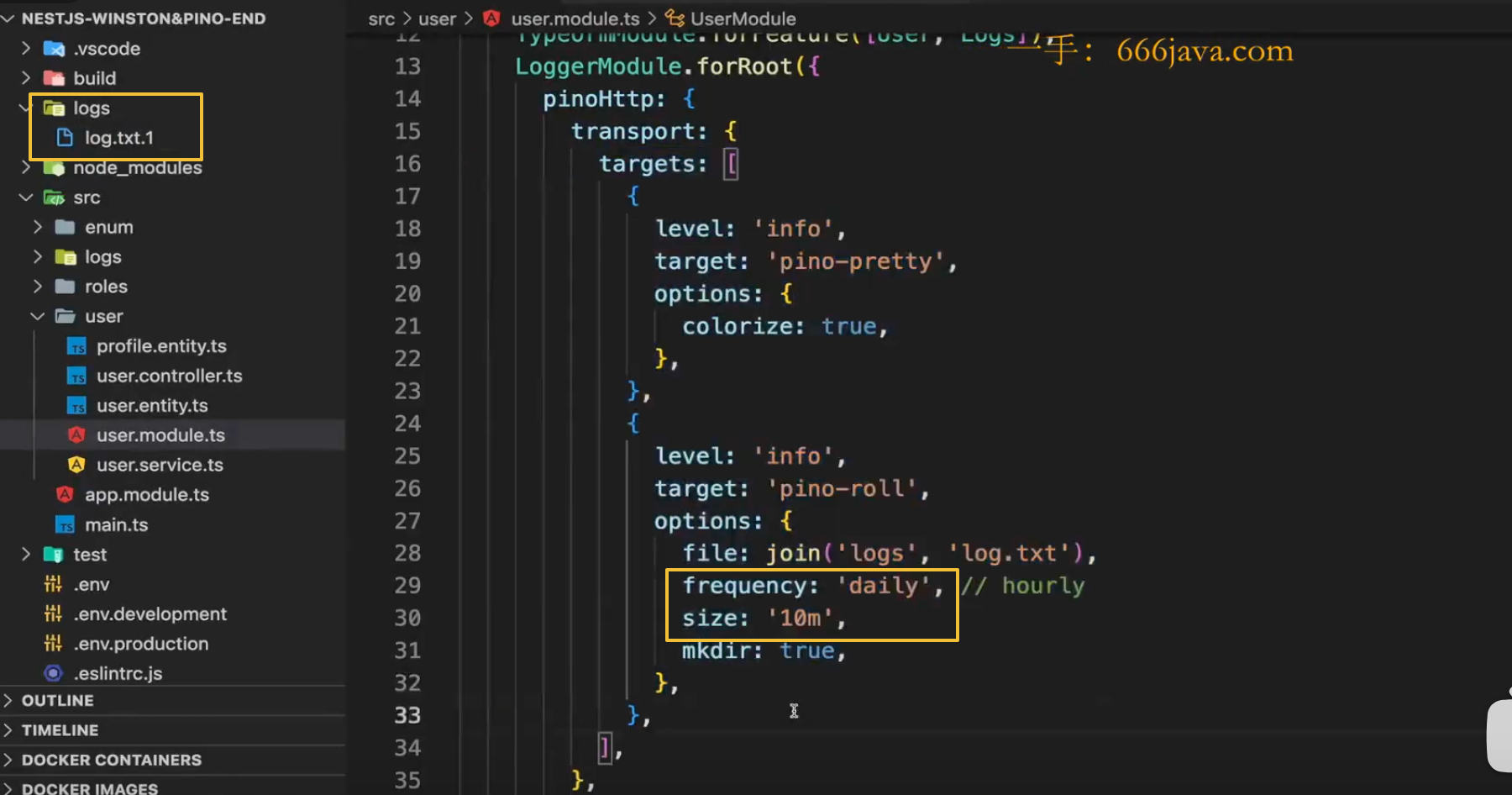
● pino的日志全部挤在一起,官方提供一个中间件来解决该问题,去格式化日志:
pnpm i pino-pretty全局使用
winston
捕获全局 exception
● 只能有一个全局异常捕获模块
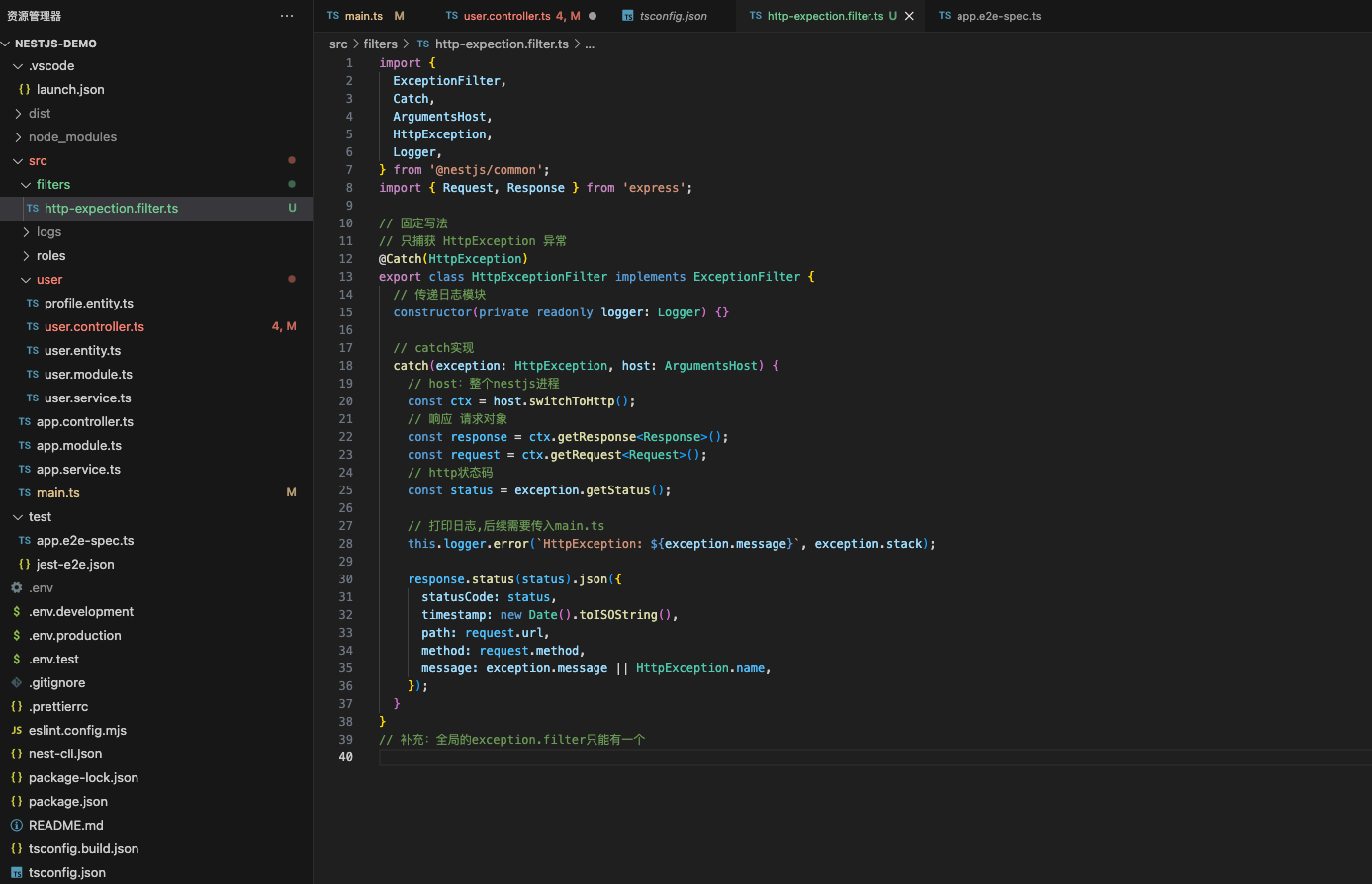
捕获局部
● 第二个命令即可,不需要日志
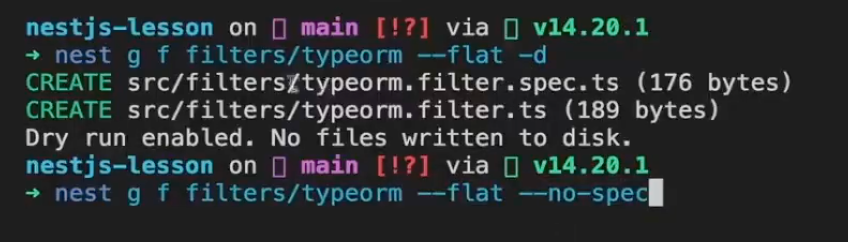
安装:
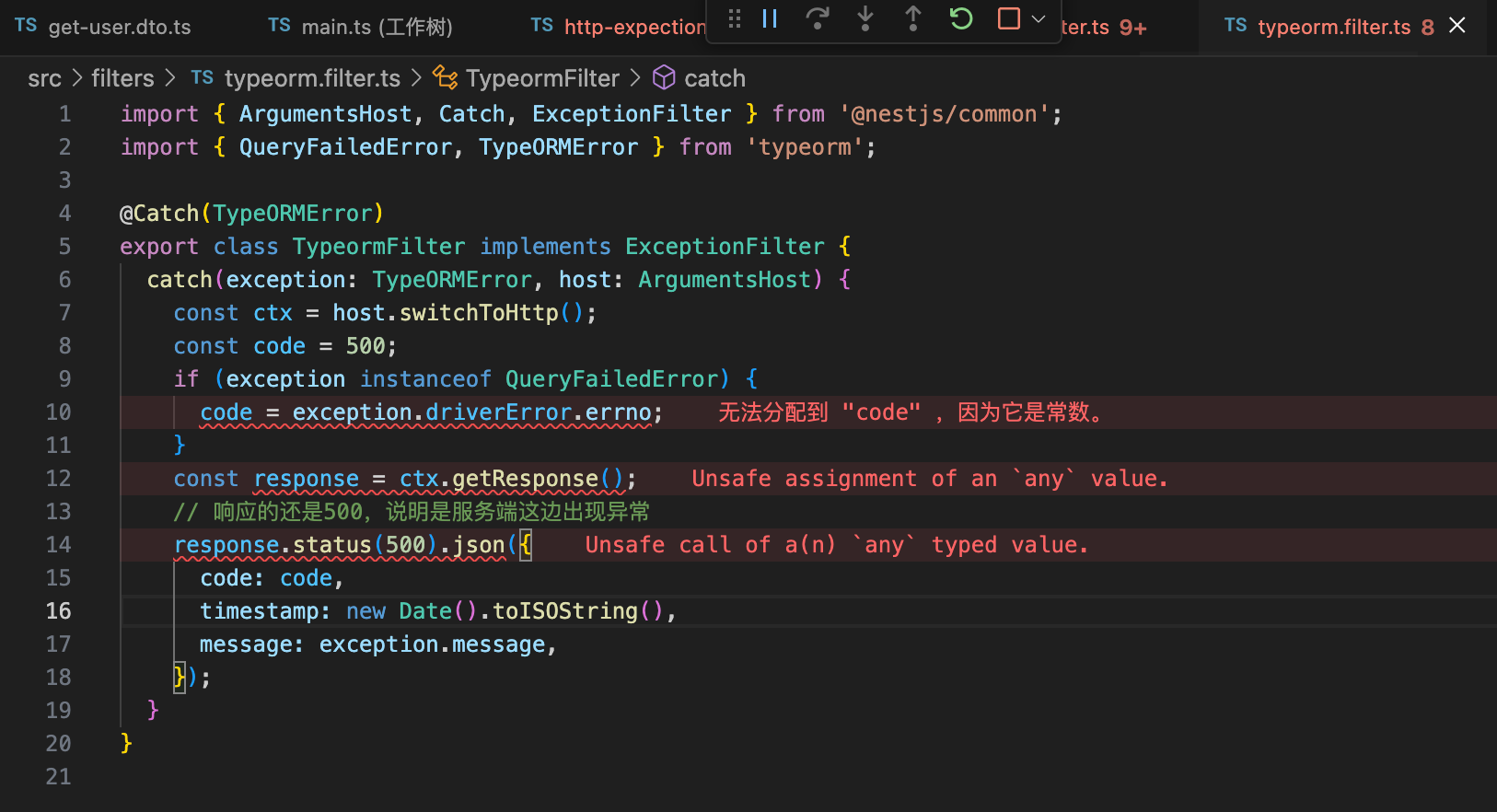
nest g f filters/typeorm --flat --no-spec修改文件:
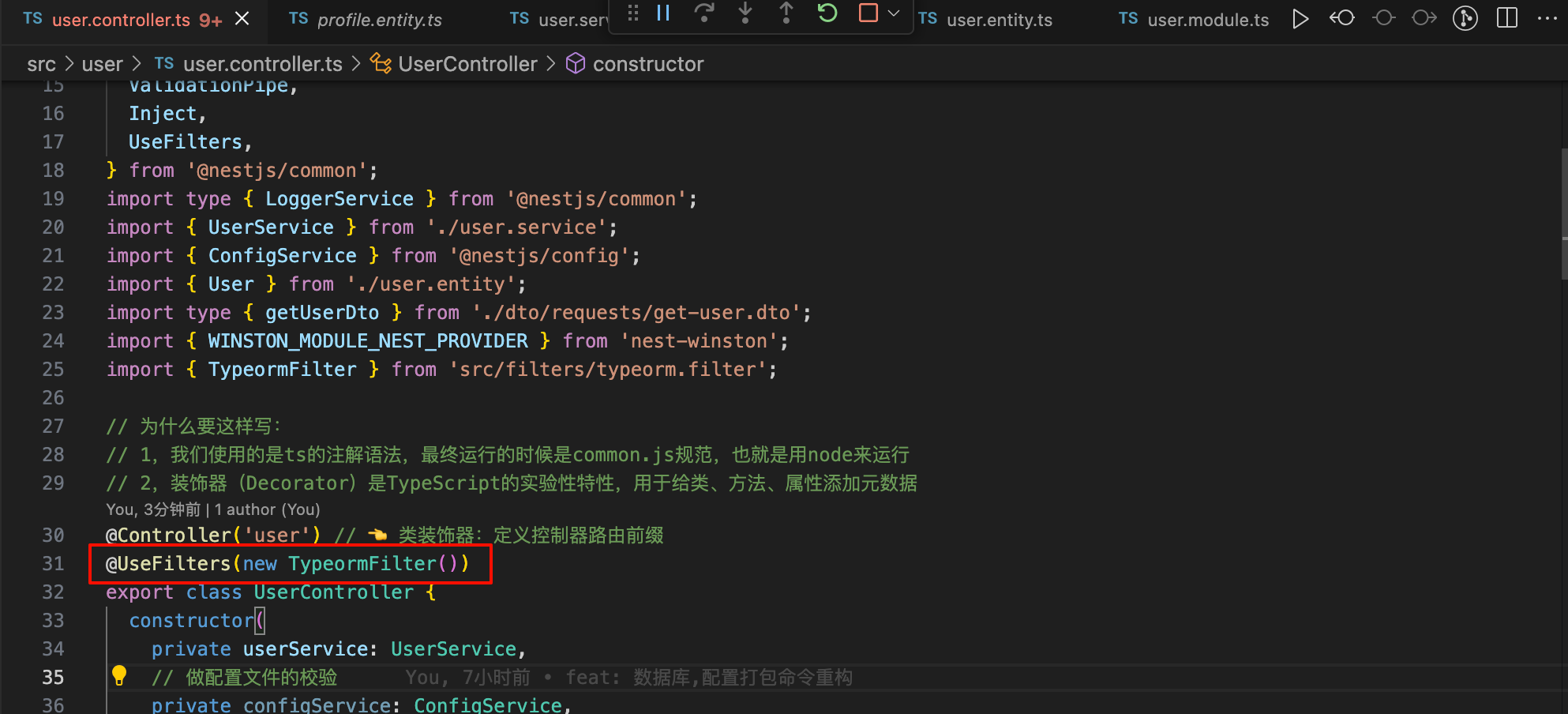
局部注册:
Nestjs注解器为什么可以生效
我们使用的是ts的注解语法,最终运行的时候是commpn.js规范,也就是用node来运行,通过指定ts配置使得代码可以正确的解析:
tsconfig.json配置:
json
{
"compilerOptions": {
// 指定生成哪个模块系统代码:'nodenext' 用于 Node.js 的 ES 模块支持
"module": "nodenext",
// 模块解析策略:'nodenext' 用于 Node.js 的模块解析算法
"moduleResolution": "nodenext",
// 是否解析 package.json 中的 exports 字段(Node.js 12+ 功能)
"resolvePackageJsonExports": true,
// 启用 ES 模块互操作性,允许从没有默认导出的模块进行默认导入
"esModuleInterop": true,
// 确保每个文件都可以安全地转译,而不依赖其他导入
"isolatedModules": true,
// 生成相应的 .d.ts 声明文件
"declaration": true,
// 移除编译输出中的注释
"removeComments": true,
// 为装饰器发出设计类型的元数据
"emitDecoratorMetadata": true,
// 启用实验性的装饰器支持(常用于 Angular、NestJS 等框架)
"experimentalDecorators": true,
// 允许从没有默认导出的模块进行默认导入(与 esModuleInterop 配合使用)
"allowSyntheticDefaultImports": true,
// 指定 ECMAScript 目标版本:ES2023
"target": "ES2023",
// 生成相应的 .map 源映射文件,便于调试
"sourceMap": true,
// 指定输出目录
"outDir": "./dist",
// 解析非相对模块名的基准目录
"baseUrl": "./",
// 启用增量编译,提高后续编译速度
"incremental": true,
// 跳过类型声明文件(.d.ts)的类型检查
"skipLibCheck": true,
// 启用严格的 null 检查
"strictNullChecks": true,
// 禁止对不一致的文件引用大小写报错
"forceConsistentCasingInFileNames": true,
// 禁用对隐含 any 类型的检查(设为 false 更宽松)
"noImplicitAny": false,
// 禁用对 bind、call、apply 的更严格检查
"strictBindCallApply": false,
// 禁用 switch 语句中贯穿情况的检查
"noFallthroughCasesInSwitch": false
}
}关键信息:
@Get,这种注解器在后台去做了解析工作,使得可以正确解析出请求的路由
// 为装饰器发出设计类型的元数据 "emitDecoratorMetadata": true,
// 启用实验性的装饰器支持(常用于 Angular、NestJS 等框架) "experimentalDecorators": true,Turbo Console Log
快速生成console注释
ctrl + alt + L
快速创建模块:
● 快速创建Logs模块:
nestjs g mo logs -dTypeCLI的使用
● 使用ormconfig.ts去进行数据库配置
npm install ts-node --save-dev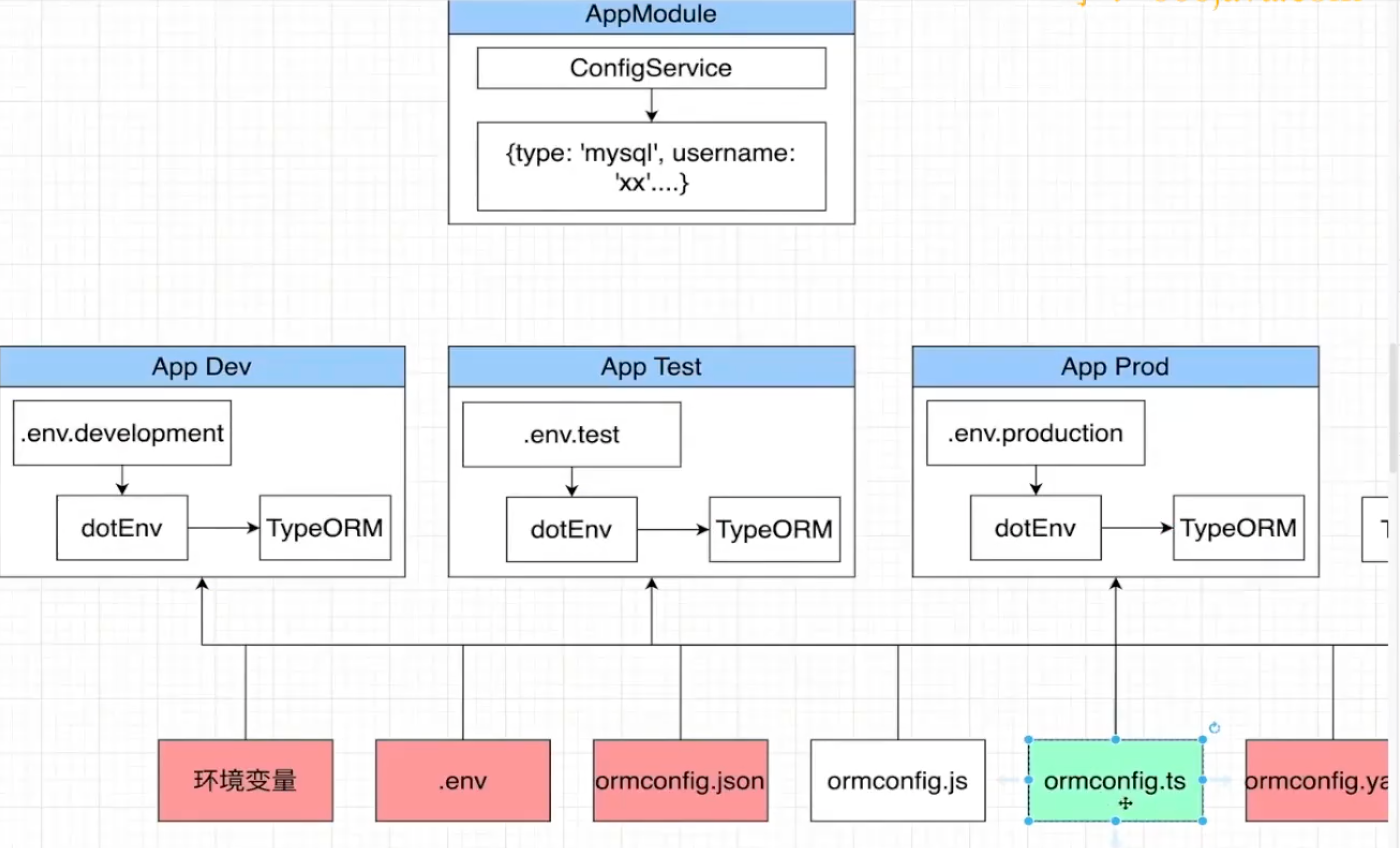
-
需要使用DataSource来包裹配置文件:
-
运行typeorm命令指定获取需要连接数据库的具体结构
npx typeorm init --database mysql
使用typeorm在多个不同的环境下去读取不同的配置文件:
通过环境变量解析不同文件,通过dotENV解析不同配置
Control模块:
管路由的,可以定义全局的路由前缀,也可以定义模块的路由前缀
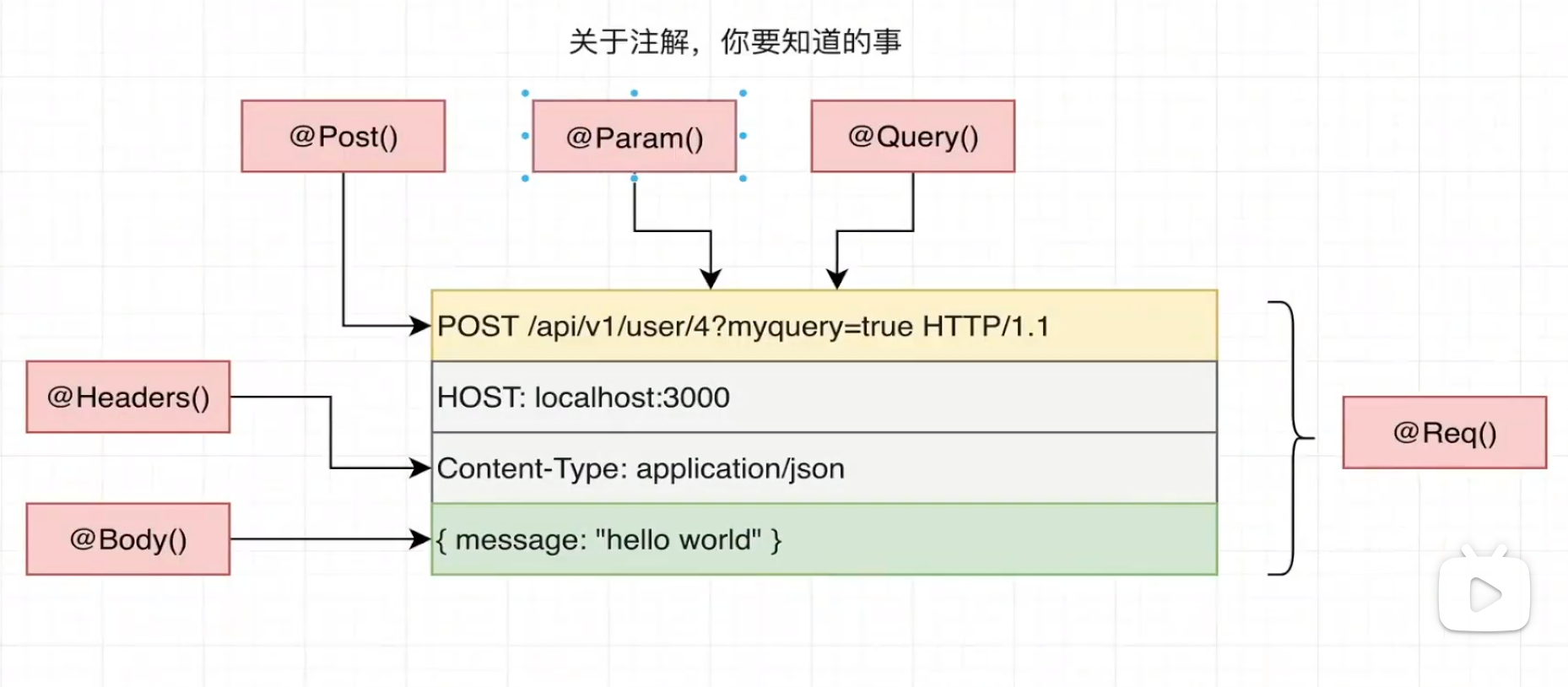
通过注解获取请求相关的参数
查询的两种方式:
-
使用typeorm的find方法
-
使用typeorm的queryBuilder方法
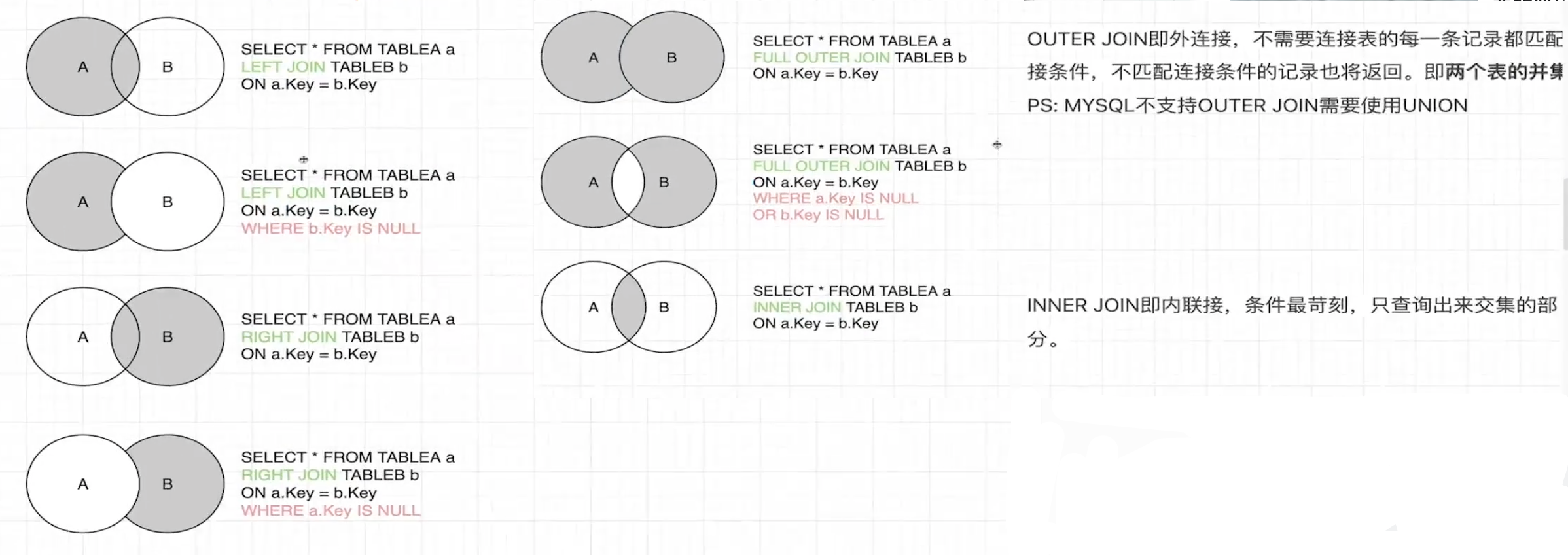
常见的几种数据库查询方式
我的理解是,图中的阴影代表查询的范围,不代表最终的查询结果
● left join也就是以一张主表为中心,去查询别的副表中也有并且符合条件的
● inner join 也就是查询的范围是两张表都有的部分,查询的只是范围
连续进行条件筛选
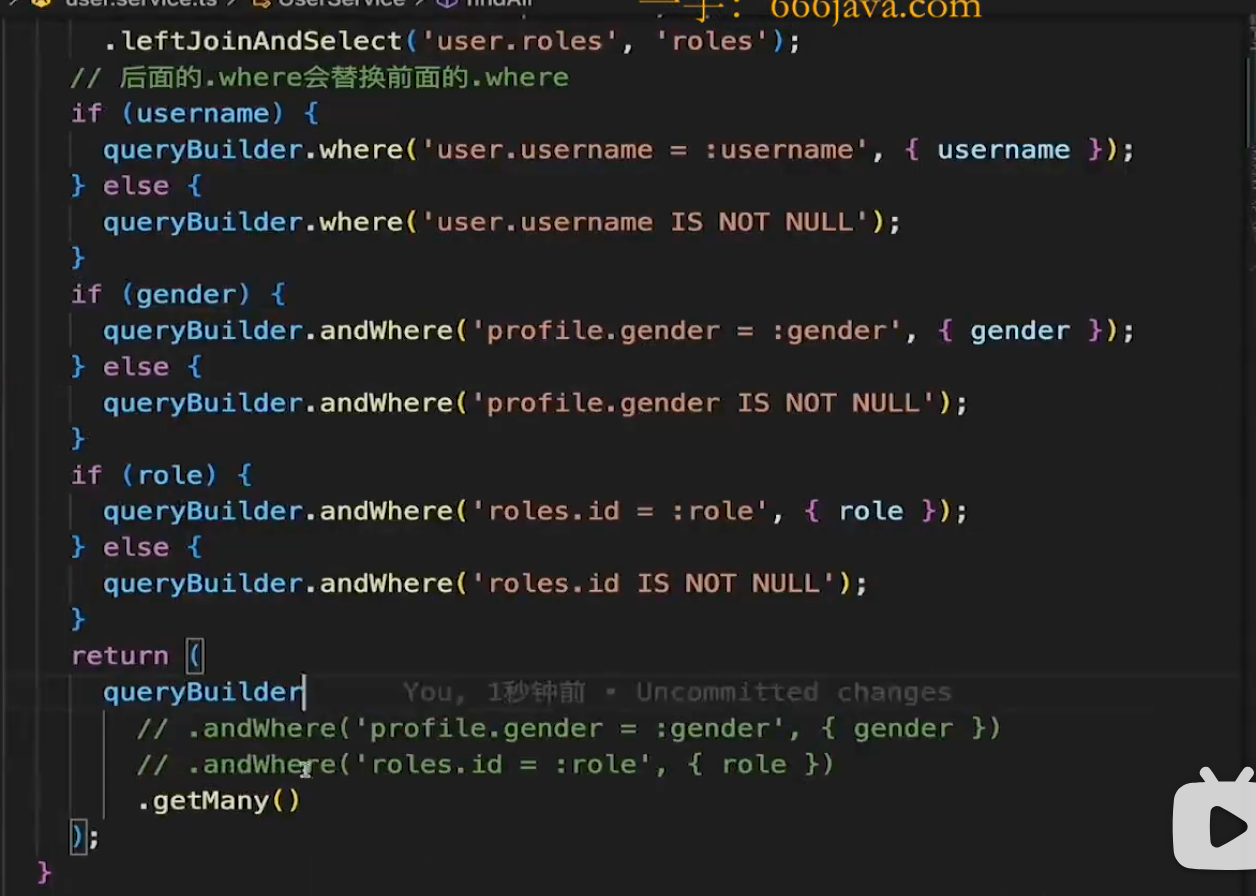
优化版本:
想法: 可以使用1=1来简写不存在的情况(如果存在就传递条件,否则就传递1=1)
实现,封装where函数
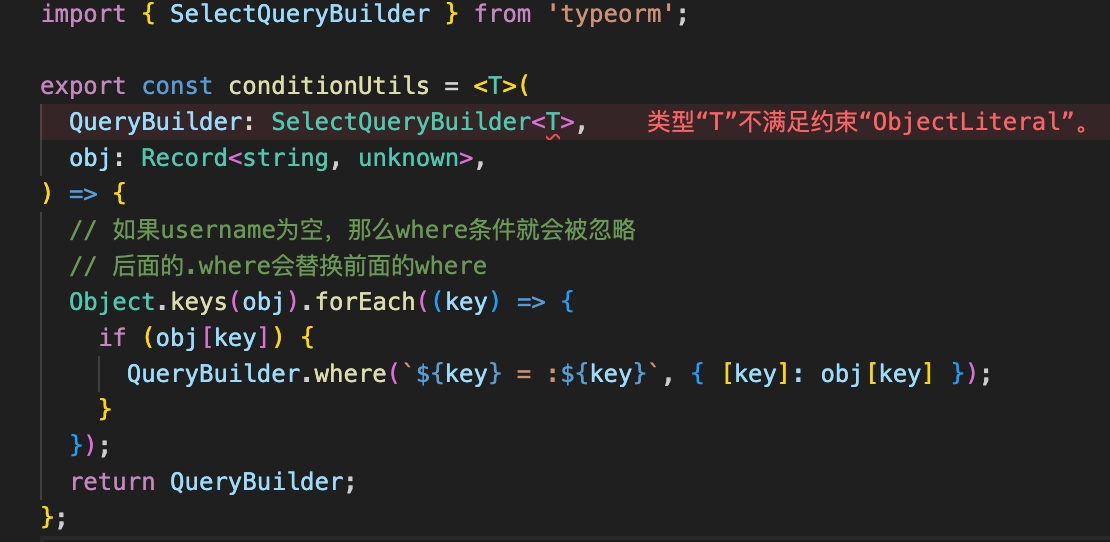
建立索引
难道说查询一个用户存不存在是靠传递过来username就查username这么low的方法吗?
不不不。
将username设置为唯一的键值,就比如新增用户,那么下次新增相同用户的时候就会主动报索引的错误了
唯一索引 = 对不可重复的字段进行索引值限定的数据库约束
实现: 索引+约束
-- 唯一索引实际上是:索引(快速查找) + 约束(数据完整性) -- 就像字典的:- 索引功能:按字母顺序快速查找- 约束功能:不允许重复的单词条目唯一索引和普通索引:
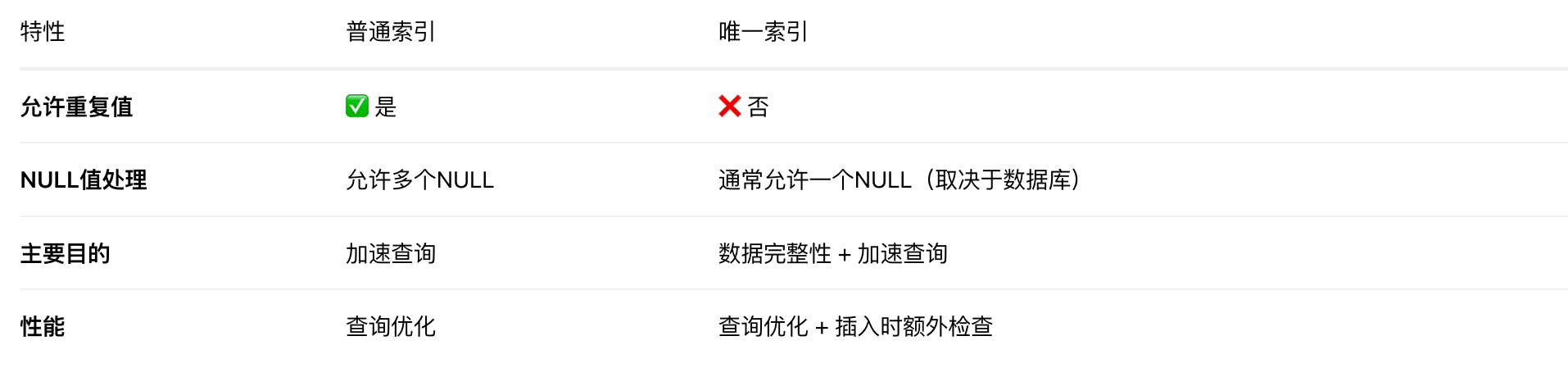
唯一索引和主键

唯一索引的底层原理
B+树结构:
唯一索引通常使用B+树实现: 根节点 ↓中间节点(范围划分) ↓ 叶子节点(实际数据指针 + 唯一值) 查找过程:从根节点到叶子节点,确保快速定位插入时的检查流程:
-- 当插入新记录时的内部流程:1. 检查唯一索引树中是否存在相同值2. 如果存在 → 抛出唯一约束违反错误3. 如果不存在 → 插入新记录并更新索引
interface和type都在什么场景下使用?
js有两种不同规范,一种是export function,另一种是export class。
type更适合export function,interfance更适合export class
换句话,export class在扩展能力比export function扩展能力很强
同样export function的组合能力比export class能力很强
像extends和prototype就不一样,像consturctor运行和call/apply就不一样,同样ts中也不一样,class直接get/set达到实体类的效果
● 类型系统层级:type更灵活,interface更适合 OOP
● 编程范式差异:class面向对象,function函数式
● 语言特性:不同语法有不同的设计意图和适用场景
总结:
需要对已有类型进行组合或者推导就用type,单纯定义对象属性用interface/class
使用编辑器自带的debug程序调试
● 启动调试进程
● 发送一个需要测试的请求
● 在监视中去筛选需要监视的变量
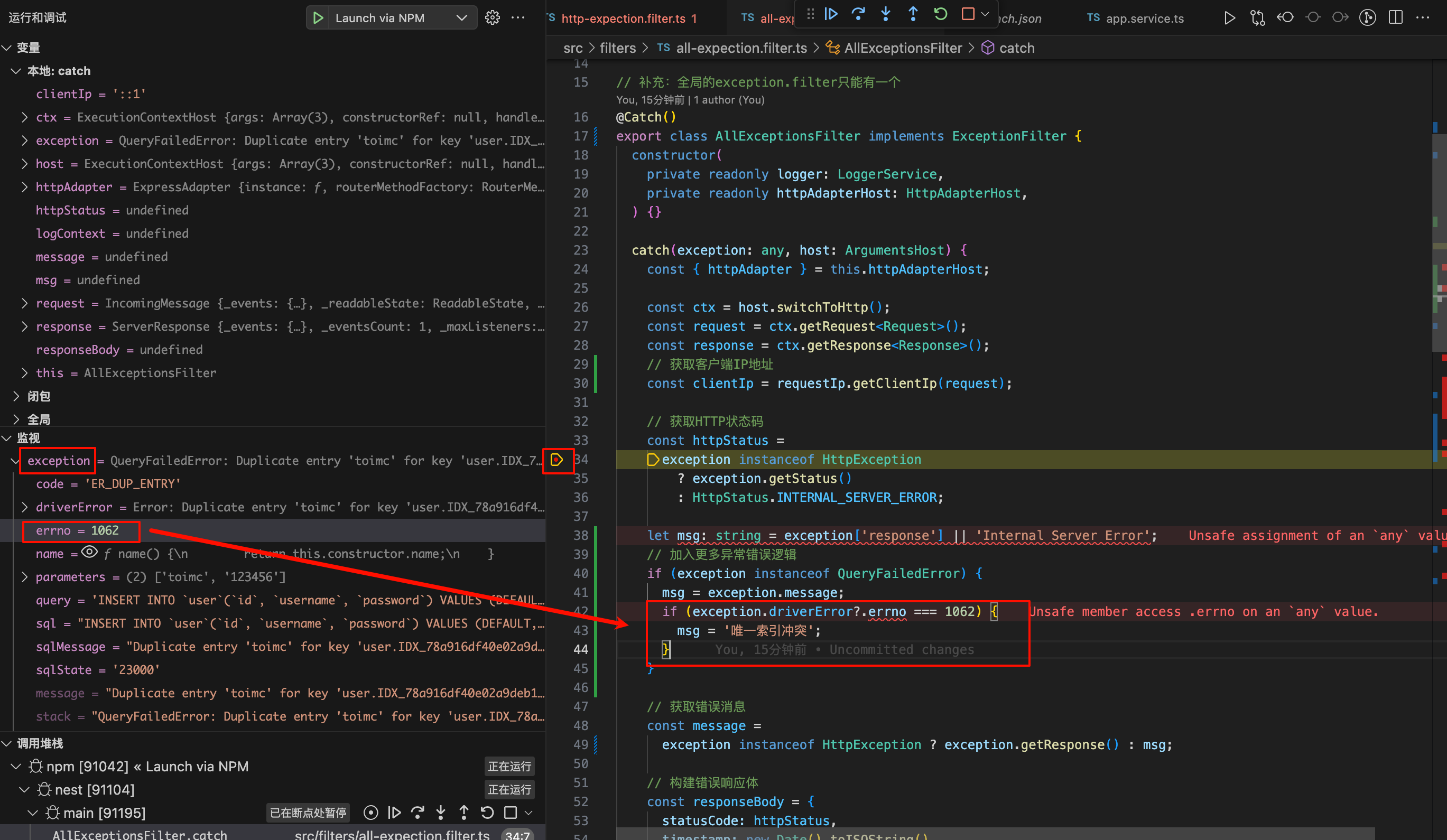
对于规范方法名称
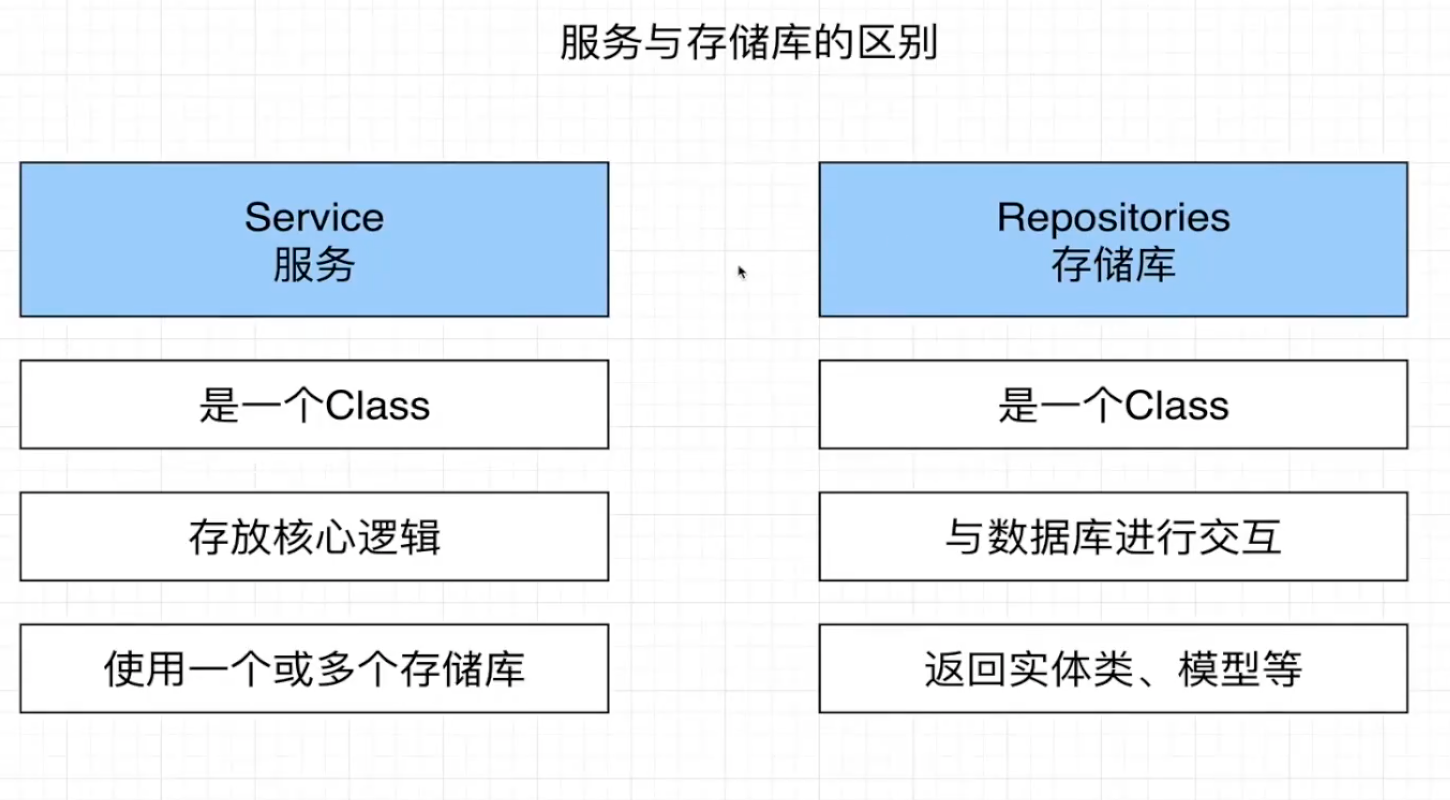
● Controller语义化命名
● Service和Repositories是对应关系,方法名称可以一样,有些情况下都不需要拆Service文件和Repositories,只有业务逻辑复杂的情况下才去考虑拆成两个文件

把Service和Repositories分开的好处就是,核心逻辑单独放,查询数据库的逻辑单独放,这样假如我们后续不想要使用TypeOrm去查询数据库,而去用SQL或者prisma的时候只需要去替换TypeOrm即可
存储库,一般来说一个存储库对应一个实体类
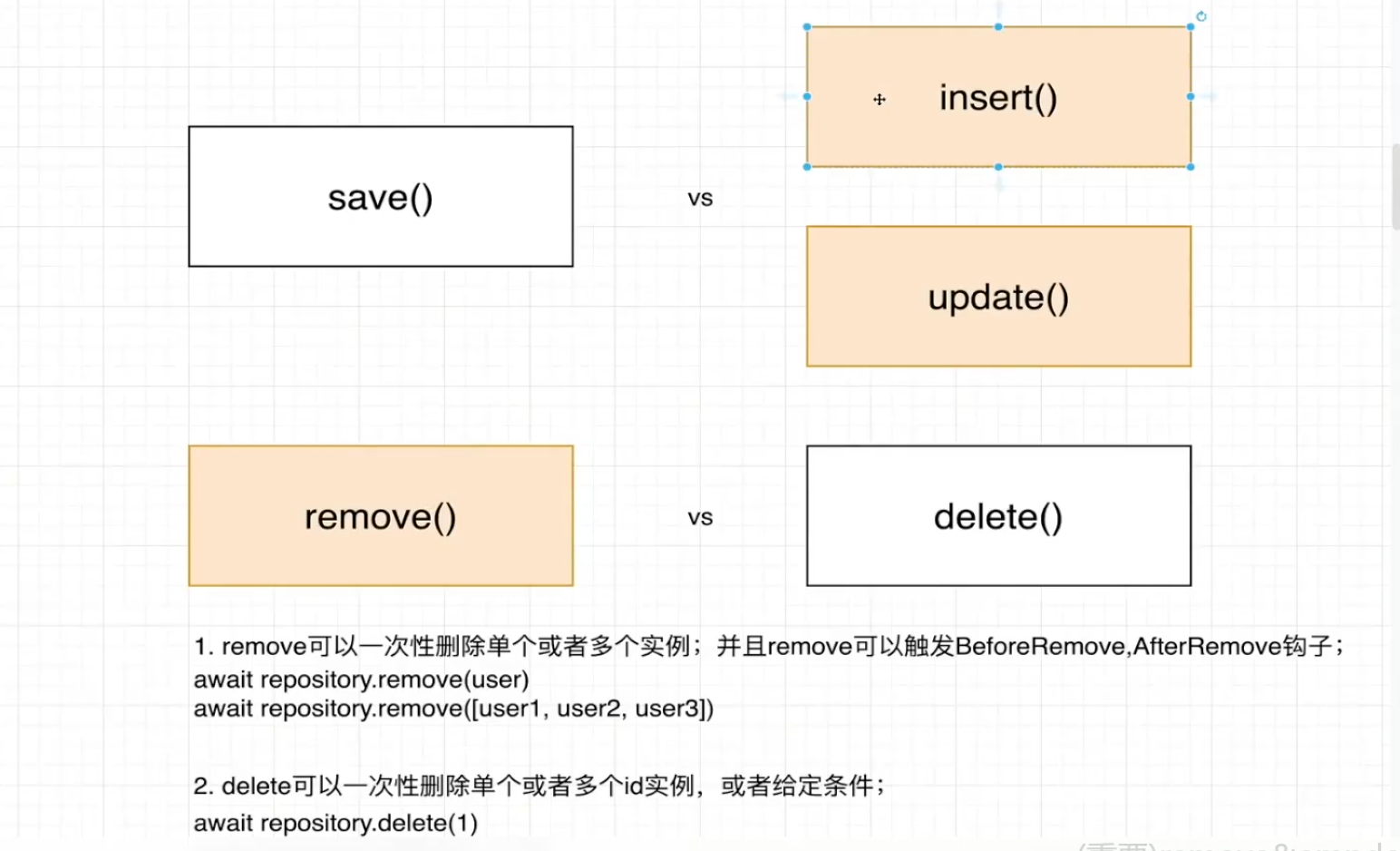
TypeORM中不同方法之间的区别,平时建议用remove 和insert
● remove可以触发typeorm上的钩子方法
不建议使用delete,因为delete是硬删除
remove触发实体监听器和订阅者相关的生命周期函数,允许我们在remove成功后做一些额外操作
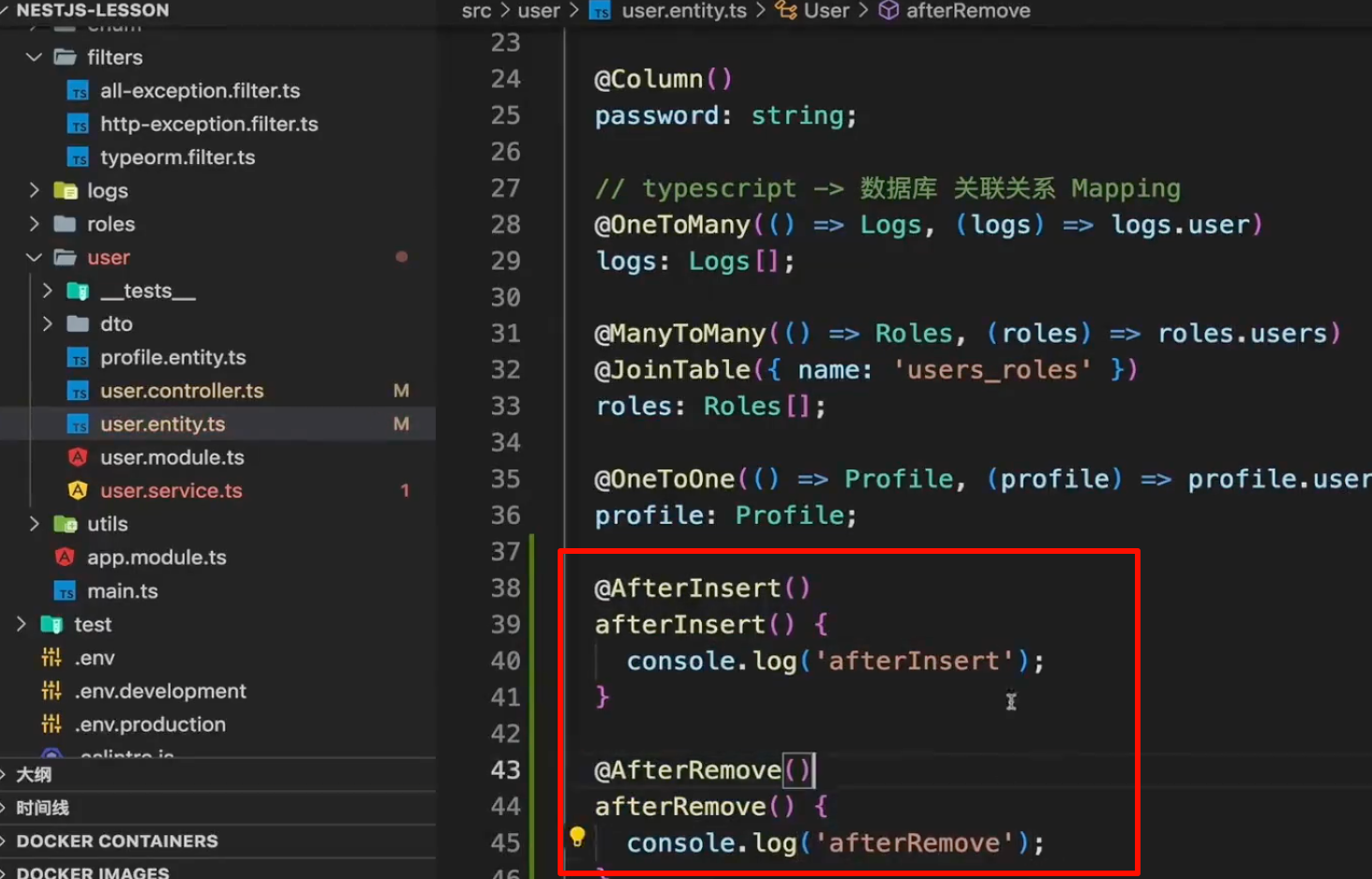
注意,这些生命周期是需要注册在实体类的下面的,监听的是实体
总结:使用remove的好处就是可以触发生命周期,记录被删除的时间等相关信息,一般用于去处理敏感数据的时候使用,如果是不重要的直接使用delete也可以,但是delete没有生命周期,删除了之后无法找到相关痕迹哦
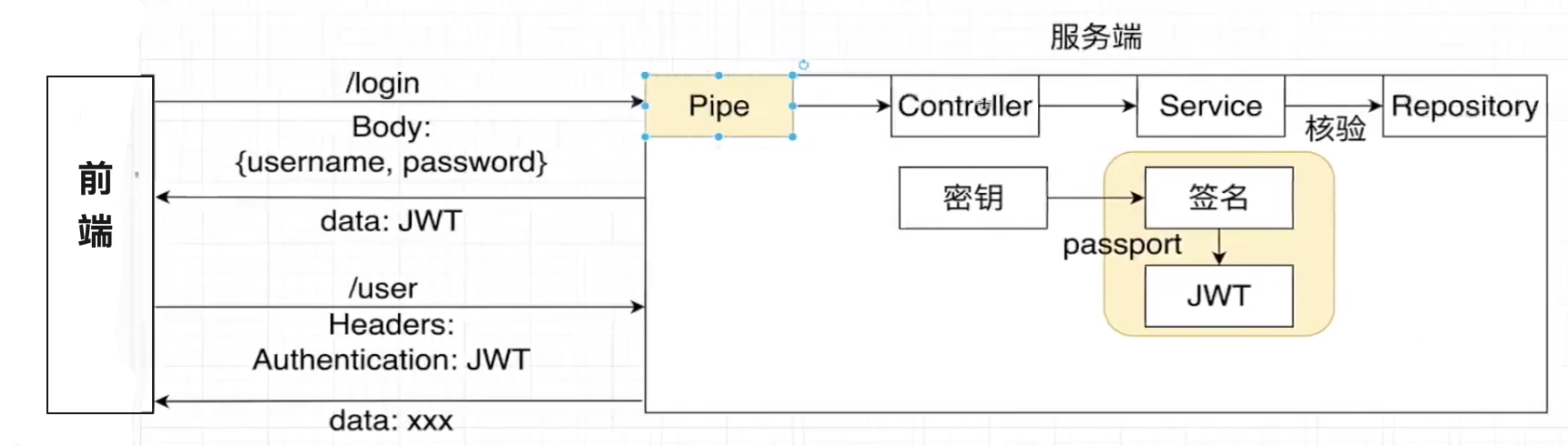
JSON Web Token(JWT)
即使请求头中的数据一样,如果不满足发送端和服务器的证书相匹配的话,服务器也是会拒绝该请求的

session是保存在服务器端,cookie保存在客户端


由于token是无状态的,所以中间人可能够劫持到数据,这一点是毋庸置疑的,但是呢为什么还说JWT还是非常安全的呢?
因为一般来说我们会对通信信道去进行加密,让中间人无法劫持到这个请求,即使截取到了,没有对应的SSL证书,也无法获取到加密的数据,通过这种形式我们可以保证数据传递到安全性
鉴权与守卫
shell
npm install @nestjs/jwt passport-jwtnpm install @types/passport-jwt --save-devnpm install passport nest g s auth -d nest g mo auth通过管道做数据校验
vaildator
管道有两个典型的应用场景:
● 转换:管道将输入数据转换为所需的数据输出(例如,将字符串转换为整数)
● 验证:对输入数据进行验证,如果验证成功继续传递;验证失败则抛出异常
在这两种情况下,管道参数(arguments) 会由控制器(controllers)的路由处理程序进行处理。Nest会在调用这个方法之前插入一个管道,管道会先拦截方法的调用参数,进行转换或是验证处理,然后用转换好或是验证好的参数调用原方法。
Nest自带很多开箱即用的内置管道。你还可以构建自定义管道。本章将介绍先内置管道以及如何将其绑定到路由处理程序(route handlers)上,然后查看一些自定义管道以展示如何从头开始构建自定义管道。
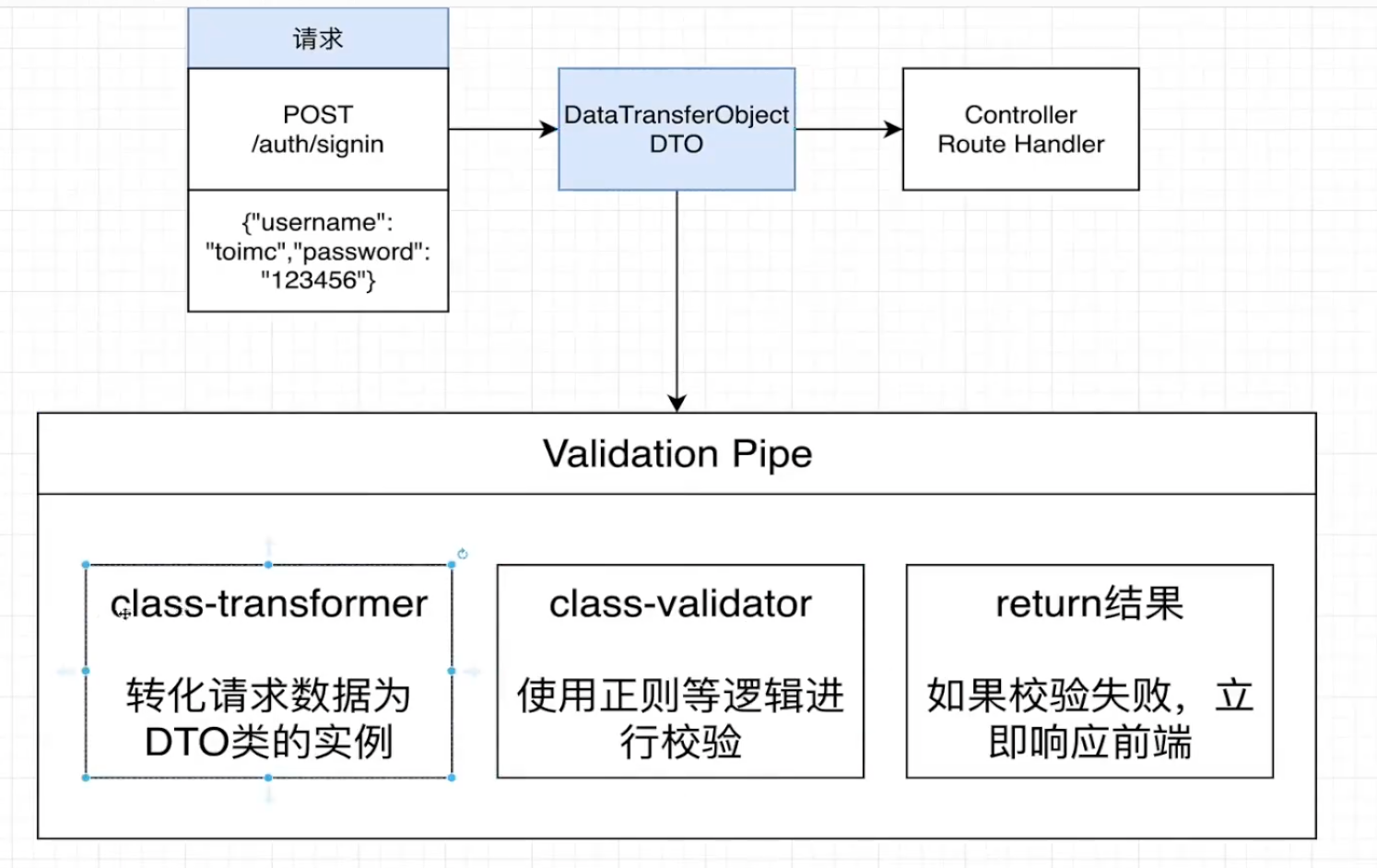
管道的类型:

Nestjs中创建管道的过程
-
全局配置管道
-
创建class类,即Entity,DTO
-
设置校验规则
-
使用该实体类或者DTO
安装依赖:
npm i --save class-validator class-transformer定义校验规则:
● 不使用if else去判断,使用管道去校验
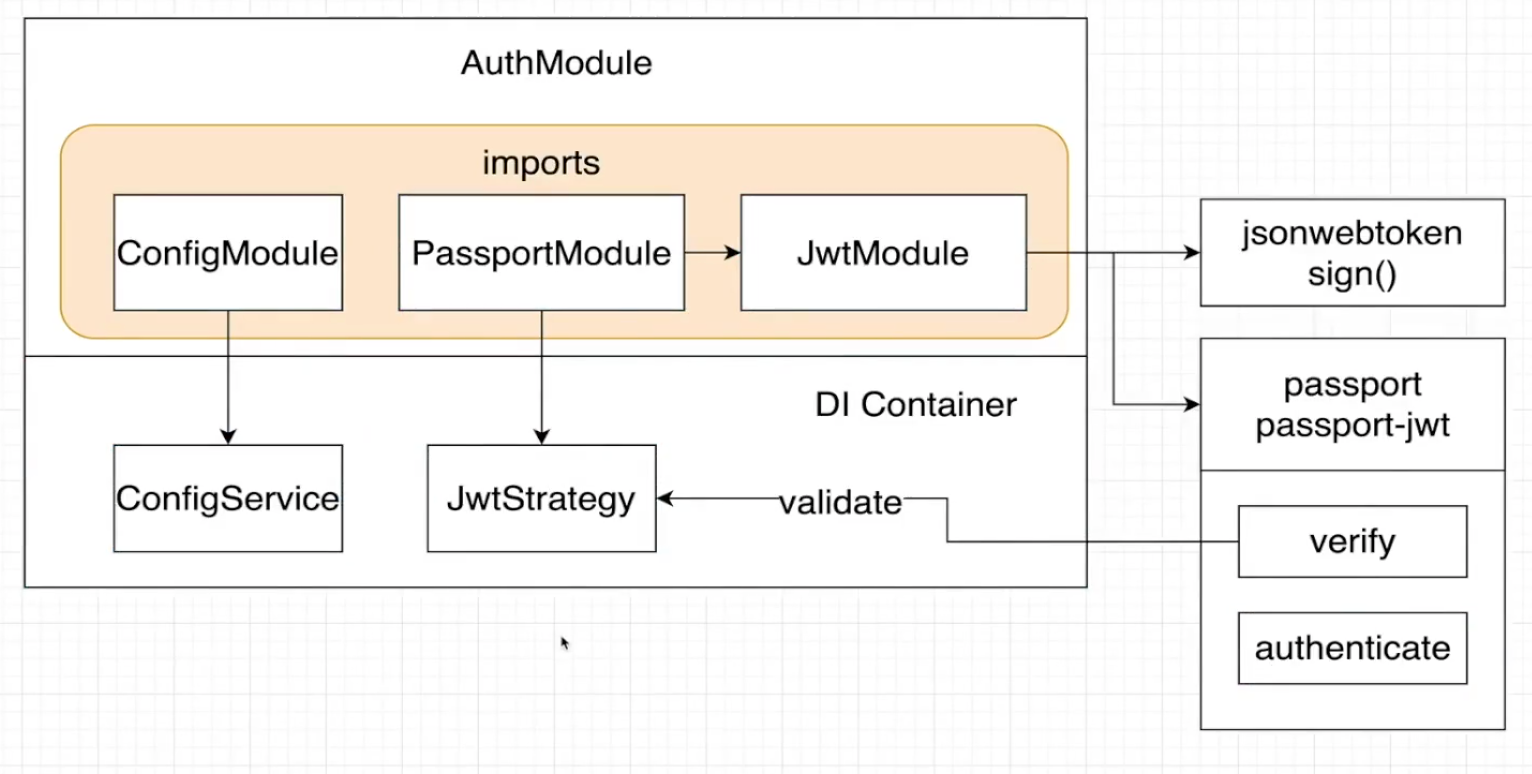
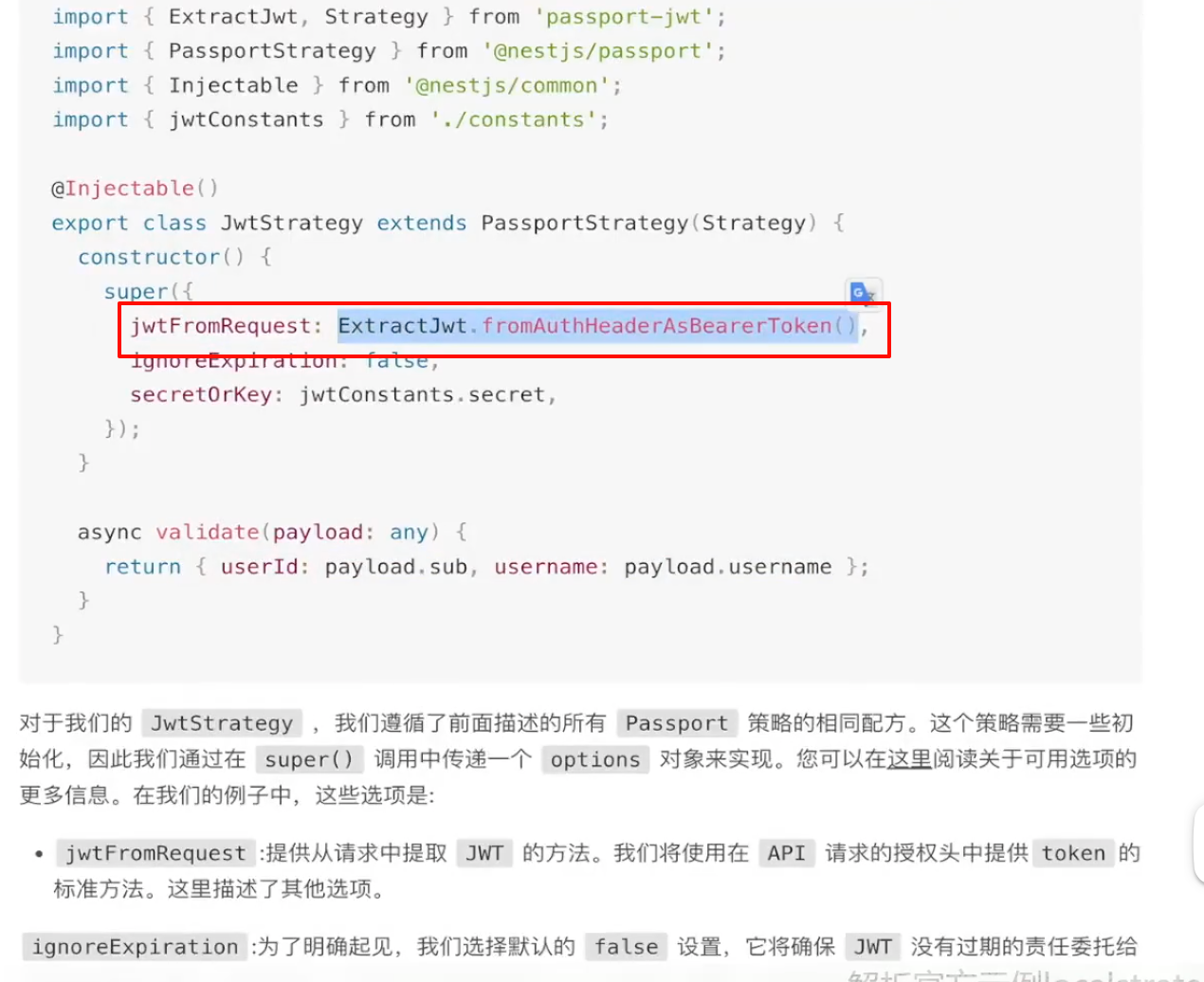
路由鉴权 Jwt Strategy或者Local Strategy作为策略,或者说为什么能够实现路由鉴权,其实内部也是去实现了validate方法,而vaildate方法最后调用也是去查询数据库,变成了原子化操作。
所以我们可以进一步理解其为什么叫做策略,其实就是将很多重复操作去集成为某一"策略"帮助我们去简化代码

Guards内部使用策略,在校验成功后自动返回一个变量,这里我们只需要接受即可,也就是将返回值赋值给了 req.user
return req.user

解释:
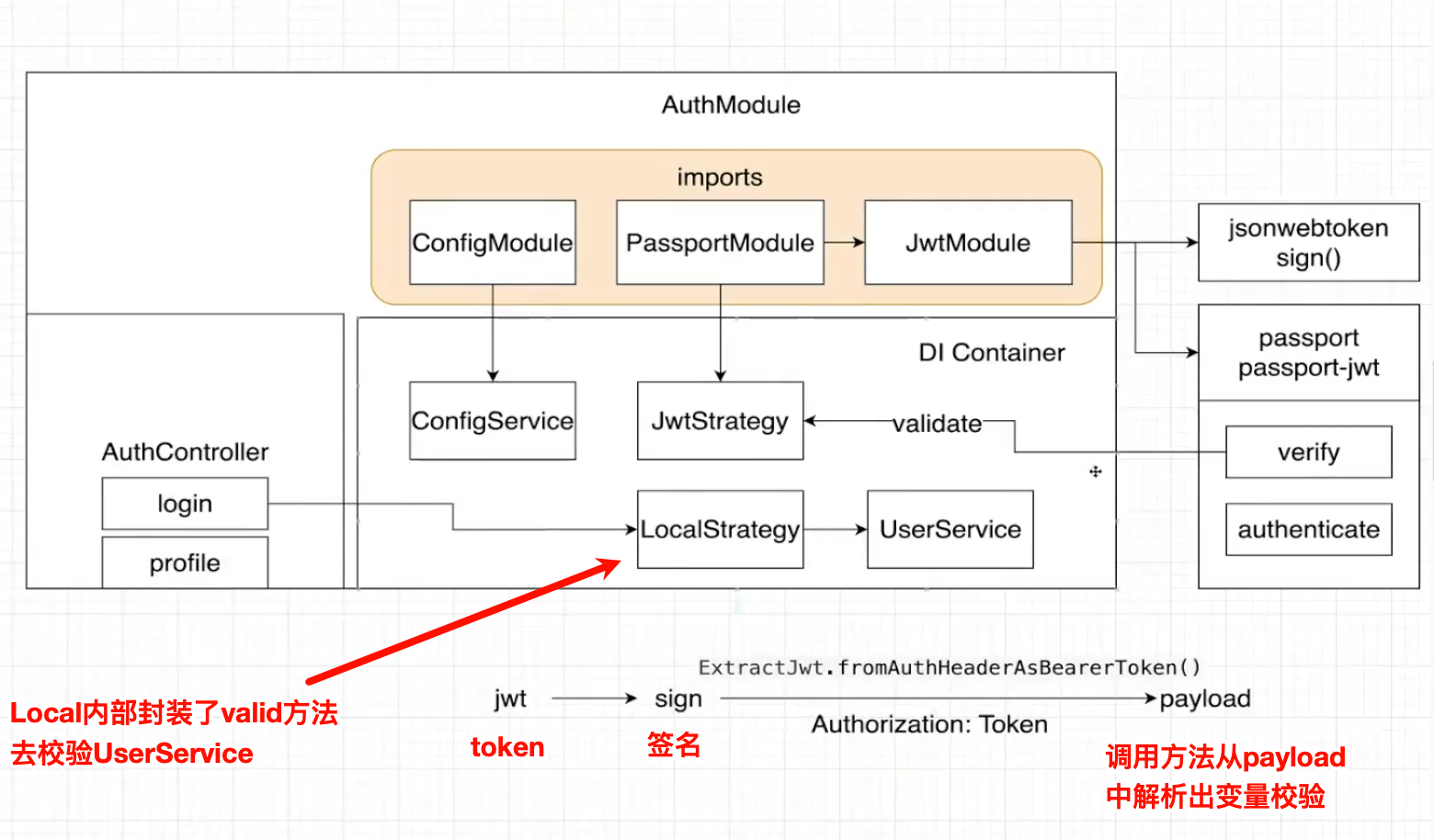
● login过程是需要签名的,走的是本地 Local Strategy,去查询数据库校验的UserService
● profile过程是需要jsonwebtoken签名后的token(Header中的 Authorization toekn)去请求后端接口的,而这个签名的token是否安全由Jwt Strategy来决定的,通过Jwt Strategy校验payload(图中最下面的部分)
● 两者是相反的策略(Strategydd)
login和profile都是在AuthController模块中的,细细品味这个。。。
测试:
测试不是被动触发的,而是主动去执行测试用例
json
{
// 不写测试的"隐藏成本"
"不写测试的隐藏成本": {
"线上Bug修复": "2-8小时/次",
"紧急发布": "团队加班",
"客户投诉": "商誉损失",
"技术债务": "代码越来越难改"
},
// 写测试的"前期投入"
"写测试的前期投入": {
"编写测试": "+30% 开发时间",
"维护测试": "+10% 维护成本",
"收益": {
"提前发现Bug": "节约 80% 线上问题",
"重构信心": "代码持续健康",
"新人上手": "测试即文档"
}
}
}技术门槛:
ts
// 写业务代码
function createUser(userData) {
return db.users.create(userData); // 相对简单
}
// 写测试代码
describe('用户创建', () => {
it('应该验证必填字段', async () => {
// 需要理解测试框架、异步、mock 等概念
const mockDb = { create: jest.fn() };
const service = new UserService(mockDb);
await expect(service.createUser({}))
.rejects.toThrow('缺少必填字段');
});
});```
#### 测试方法:
##### 1. 单元测试:
● 直接调用:就像 service.createUser()这样直接执行
● 同步执行:立即得到结果
● 内存操作:不启动服务器,不发送 HTTP 请求
```ts
// user.service.spec.ts - 单元测试
import { UserService } from './user.service'; // 直接导入代码
describe('UserService', () => {
let service: UserService;
beforeEach(() => {
service = new UserService(); // 直接创建实例
});
it('应该创建用户', () => {
// 🎯 直接调用函数,就像普通代码一样
const result = service.createUser('张三', 'zhang@example.com');
// ❌ 这里会报错:缺少 phone 参数
});
});2. E2E测试:
● 通过执行测试文件批量测试(触发测试用例中的接口)
● 需要提前配置注入测试环境
● HTTP 请求:像浏览器一样发送请求
● 完整应用:测试运行中的真实服务器
○ 当然测试环境,我是指真正的可以配置一个专门用来测试的环境
● 网络通信:通过 localhost 端口通信
ts
// user.e2e-spec.ts - E2E 测试
describe('用户管理 API', () => {
it('创建用户', async () => {
// 🎯 发送 HTTP 请求到运行中的服务器
const response = await global.pactum()
.post('/users')
.withJson({
name: '张三',
email: 'zhang@example.com'
// ❌ 缺少 phone 参数
})
.expectStatus(400); // 期望返回 400 错误
expect(response.json.error).toBe('缺少 phone 参数');
});
});测试执行时刻
shell
# 当你运行测试时:
npm test user.e2e-spec.ts
# 时间线:
[14:30:00] 开始执行测试
[14:30:01] 测试代码发送 POST /users 请求 ← 主动触发!
[14:30:01] 服务器处理请求并返回响应
[14:30:01] 测试验证响应
[14:30:01] 测试结束降低测试门槛:
方案1:测试代码生成工具
ts
// 工具自动生成测试骨架
// 输入:业务代码
function createUser(name, email) {
if (!name) throw new Error('姓名必填');
return repository.save({ name, email });
}
// 输出:基础测试用例
describe('createUser', () => {
it('should create user with valid data', () => {
// 自动生成的基础测试
});
it('should throw error when name is empty', () => {
// 自动生成的边界测试
});
});方案2:重点测试,非全面测试
ts
// 只测试核心业务逻辑,不追求100%覆盖率
// ✅ 值得测试的(高ROI)
describe('支付流程', () => {
it('用户支付后订单状态更新', () => { ... });
it('库存不足时阻止支付', () => { ... });
});
// ❌ 可以不测试的(低ROI)
describe('工具函数', () => {
it('add函数应该能加数字', () => { ... }); // 过度测试
});方案3:测试模板和规范
ts
// 团队统一的测试模板
// tests/templates/service.test.template.js
describe('{{serviceName}}', () => {
beforeEach(() => {
// 标准化的setup
});
it('should handle valid input', () => {
// 标准化的测试结构
});
it('should throw error for invalid input', () => {
// 标准化的错误测试
});
});实际的团队渐进式策略
ts
// 只要求测试"赚钱"和"赔钱"的流程
const CRITICAL_FLOWS = [
'用户注册', // 影响获客
'支付流程', // 影响收入
'数据导出', // 影响客户信任
'管理员操作' // 影响安全
];基础设置支持
# 团队提供的测试工具
devDependencies:
test-utils: '^1.0.0' # 封装复杂测试逻辑
mock-server: '^2.0.0' # 简化外部依赖模拟
coverage-check: '^1.0.0' # 自动覆盖率检查