14. 如何赋予 LLM 规划能力?
给 LLM 加规划能力主要靠这几种思路。
-
CoT 是让 LLM 把推理步骤写出来,线性地一步步推导到答案;
-
ToT 是让它同时探索多条推理路径,选最优的继续深入;
-
GoT 是图结构推理,推理节点可以复用和合并,适合更复杂的任务。
工程上我用 CoT 最多,因为实现成本最低,就是改个 prompt;ToT 效果更好但调用次数多,成本大概是 3 到 5 倍;GoT 目前还比较学术,生产环境我没见过有人真正落地用的。
要理解为什么需要规划能力,先看 LLM 在没有任何规划机制时是怎么运作的。
普通的问答模式下,LLM 接到一个问题,就直接「一口气」生成答案,中间没有任何推理过程。这对简单问题没啥大问题,但遇到需要多步推导的任务就很容易翻车。比如让它做一道需要 3 步推导的逻辑题,如果直接让它给答案,出错概率会远高于让它把每步都写出来。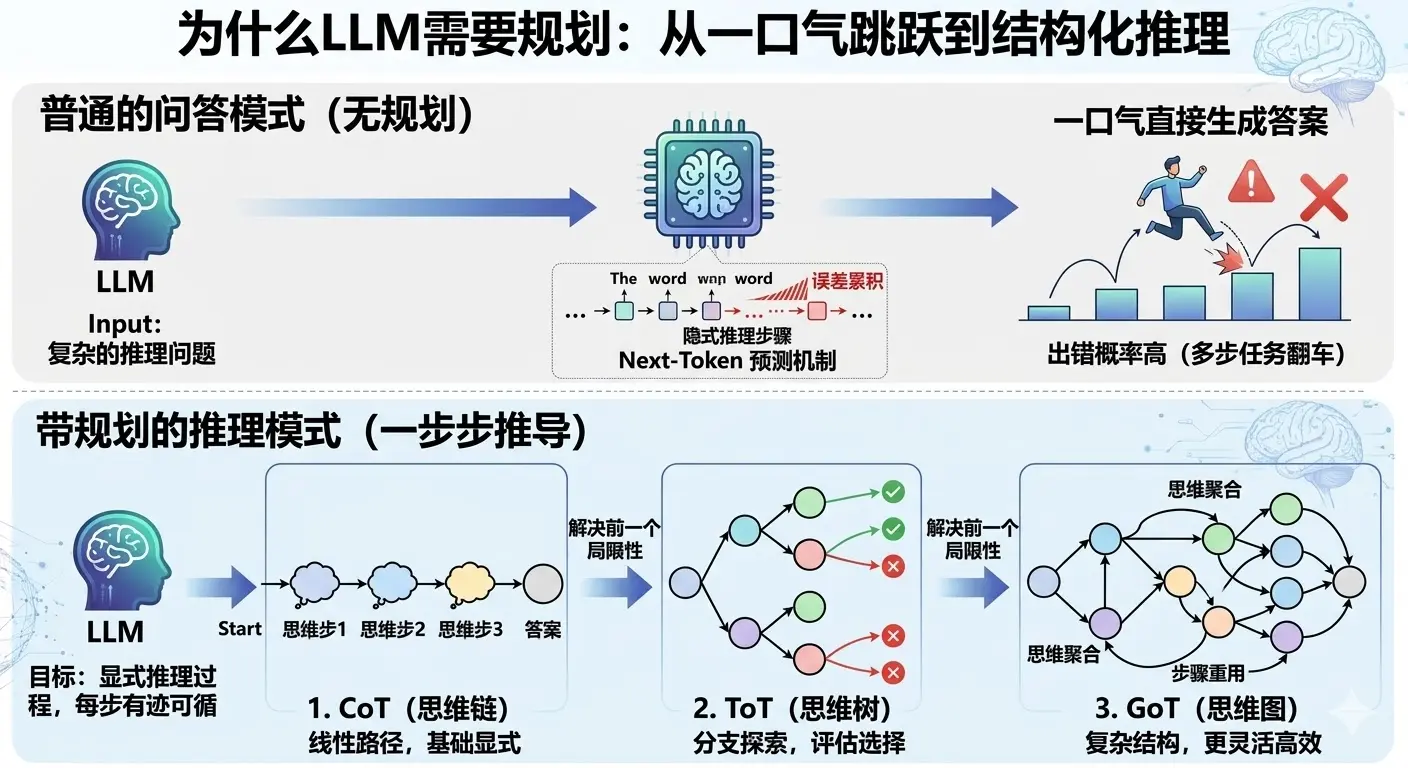
背后的原因是 Transformer 的 next-token 预测机制,每个 token 是基于前面所有 token 生成的,推理链越长、隐式的跳步越多,误差就越容易在中间某一步悄悄累积,最后给出一个看起来很自信但其实是错的答案。
「规划能力」要解决的就是这个问题:把 LLM 隐式的推理过程显式化,让它不再是「一步跳到答案」,而是「一步一步推到答案」,每步都有迹可循。
CoT、ToT、GoT 是这个方向上依次演进的三种方案,每一个都在解决前一个的局限性。
CoT:最简单的激活方式,加一句话就够了
CoT 的全称是 Chain of Thought(思维链),核心思路极其简单:在 prompt 里加一句「请一步步思考」,LLM 就会把推理过程逐步写出来,而不是直接蹦出答案。
为什么这么简单的改变就有效?
本质是因为 LLM 的输出是顺序生成的,当它先输出推理步骤,这些推理内容会进入上下文,影响下一个 token 的生成。换句话说,「写下来的推理过程」本身就成为了后续生成的依据,帮助 LLM 不跳步、不乱想。就好比你在纸上演算数学题,把每一步写出来之后,下一步出错的概率会比在脑子里算要低得多,原理是一样的。
CoT 有两种触发方式。
- 第一种叫 Zero-shot CoT,就是直接在 prompt 末尾加「让我们一步步思考」,LLM 自己展开推理,不需要额外例子;
- 第二种叫 Few-shot CoT,给几个带有完整推理过程的例子,让 LLM 模仿这种推理格式来回答新问题,效果通常更稳定。
CoT 的局限很明显:它只有「一条推理路径」。如果一开始走错了方向,整条链就歪了,没有任何纠偏机制。
ToT:从「一条链」到「一棵树」,解决走错方向的问题
ToT 的全称是 Tree of Thoughts(思维树),针对的正是 CoT「一旦走错就全错」的问题。
核心改变是把「生成一条推理链」变成「同时探索多条推理路径,边探索边剪枝,最终选出最优路径」。用一个生活类比来理解:CoT 像你做题时只想了一个解法,一路做到底;ToT 像你先想了三种可能的解题思路,评估了一下哪种最靠谱,选了最好的那条继续深入,另外两条直接放弃。
ToT 的执行流程可以分三步来理解。首先是生成多个候选思路,让 LLM 针对同一个问题给出 3 个不同的初步方向,而不是只走一条路。然后是评估每个思路的可行性,用另一个 LLM 调用(或同一个 LLM 带上评估 prompt)给每个思路打分,判断哪个最有希望。最后是选优继续深入、剪掉差的,只保留分数高的思路,再展开下一层推理,反复循环直到得出最终答案。
这个「生成 -> 评估 -> 剪枝」的循环,让 LLM 不再是「一条道走到黑」,而是有了探索多条路、选好的走、发现走错了还能回头的能力。代价也很明显:原来 CoT 一次生成就搞定,ToT 需要多次 LLM 调用(多条路径 × 多层深度 × 每层还要评估),成本是 CoT 的 3-5 倍甚至更高。
GoT:从「树」到「图」,解决推理结果不能复用的问题
GoT 的全称是 Graph of Thoughts(思维图),是在 ToT 基础上再进一步的进化。
ToT 虽然引入了多路径探索,但它是树形结构,不同分支之间完全独立,两条推理路径上的中间结论无法互相借用。GoT 把推理结构换成了图,允许不同路径的中间结果合并、复用,也就是说一个推理节点可以接收来自多个前置节点的输出作为输入。
举个具体例子:如果任务是「分别研究竞品 A 和竞品 B,然后做综合对比分析」。ToT 里研究 A 和研究 B 是两条独立的路径,各自得出结论;但「综合对比分析」这一步需要同时用到两条路径的结论,在树形结构里很难自然表达,因为树的每个节点只有一个父节点。GoT 的图结构允许把「研究 A 的节点」和「研究 B 的节点」的输出,汇聚到「综合对比分析节点」,这种「多个中间结论合并输入到下一步」的操作在图里是一等公民,表达起来非常自然。
GoT 能建模的推理模式比 ToT 更丰富,也更接近人类实际处理复杂任务的思考方式。但落地复杂度很高,目前主要还是学术研究场景,生产环境里极少见到真正用起来的。
三者的演进关系
把这三者放在演进视角里看,逻辑非常清晰。
CoT 解决了「要不要把推理显式化」的问题,答案是要,把过程写出来就能显著减少跳步出错。ToT 解决了「走错方向怎么办」的问题,答案是先多探索几条路,边走边评估边剪枝。GoT 解决了「不同推理路径的中间结论能不能复用」的问题,答案是把结构从树换成图,自然支持结论汇聚与复用。每一步都是在前一步的基础上发现局限、针对性改进。
工程上怎么选?CoT 几乎是所有任务的标配,加一句话、零成本,直接加到 system prompt 里就行。ToT 在准确率要求很高、任务比较复杂的场景值得考虑,但要做好调用成本增加 3-5 倍的心理准备。GoT 目前工程落地不成熟,主要了解它的思想即可,真实项目里不必强行引入。
工程里真正常用的规划模式:Plan-and-Execute
CoT、ToT、GoT 说的都是「怎么让 LLM 把推理过程做得更好」,但在真实的 Agent 项目里,还有一种更贴近工程实践的规划模式,叫做 Plan-and-Execute(先规划再执行)。
这个模式的思路很直白:面对一个复杂任务,先让 LLM 制定一份完整的执行计划,把任务拆成若干步骤,然后一步一步执行,每完成一步就检查一下进度,必要时调整后续计划。你可以把它理解成「先写大纲再动笔」的写作方式,而不是拿到题目就开始一口气往下写。
为什么需要这种模式?因为 CoT 虽然能让 LLM 逐步推理,但它是「边想边做」的,走到哪算哪,没有全局视角。对于一个需要调用多个工具、经历多个环节的复杂任务来说,如果没有一个整体规划,LLM 很容易在某一步跑偏,后面的步骤全都白费。Plan-and-Execute 的核心价值就是:先用一次 LLM 调用建立全局视角,再用后续调用逐步落地,把「规划」和「执行」分成两个阶段来做。
具体执行流程分三步。
- 第一步,Planner(规划器)接收用户任务,生成一份步骤清单,比如「第一步搜索相关资料,第二步整理关键信息,第三步撰写总结报告」。
- 第二步,Executor(执行器)按照清单一步步执行,每步可能涉及工具调用或 LLM 推理。
- 第三步,也是容易被忽略的关键,每执行完一步,会有一个 Re-planner(重新规划器)回顾当前进展,判断原来的计划还适不适用,如果中间发现了新的信息或者某步执行结果不符合预期,就动态调整后续步骤。
这个模式和 ReAct 是什么关系?ReAct(Reasoning + Acting)是一种让 LLM 在每一步都先「思考」再「行动」再「观察」的循环模式,它的特点是每步都是即时决策,没有提前规划。Plan-and-Execute 则是在 ReAct 的基础上加了一层全局规划,你可以理解成 ReAct 负责每一步怎么执行,Plan-and-Execute 负责这些步骤的整体编排和动态调整。两者不是替代关系,而是经常搭配使用的。
工程上 Plan-and-Execute 的好处很明显:规划和执行分离之后,规划阶段可以用更强的模型(比如 GPT-4)来保证方向正确,执行阶段可以用更快更便宜的模型来提高效率,成本和质量都能分别优化。LangGraph 里就内置了这种模式的支持,用起来相当方便。
答好这道题有几个层次。首先要说清楚为什么需要规划能力,LLM 默认「一口气」生成答案,没有显式推理过程,多步推理任务容易跳步出错,规划机制就是把隐式推理过程显式化。然后要说三种机制的演进逻辑:CoT 解决「要不要把推理写出来」,ToT 解决「走错了方向怎么纠偏」,GoT 解决「不同路径的中间结论能不能复用」,每一个都是针对上一个的局限性改进。最容易被忽略的考点是工程取舍:CoT 几乎零成本;ToT 效果更好但调用次数是 CoT 的 3-5 倍,要明确说出这个数字;GoT 目前学术阶段,生产环境没有成熟落地。面试里如果能把工程成本和适用场景说清楚,比只讲原理要加分得多。
15. 讲讲 Agent 的反思机制?为什么要用反思?具体怎么实现?
反思机制我的理解是:让 Agent 在完成一个步骤或整个任务后,自我评估输出质量,判断有没有问题,不达标就重试或调整策略。
用反思的原因是 LLM 第一次输出不一定是最优的,加一轮自我检查能显著提升质量,相当于人写完东西自己再看一遍。
代价是多至少一次 LLM 调用,token 消耗和延迟都会增加,所以我在工程里通常只在质量要求高的关键节点启用反思,不是每步都做。
LLM 也面临同样的问题。它每次生成输出,本质上是在「一口气」完成的,没有机会停下来检查。
第一次输出常见的毛病有这几类:逻辑跳跃(推理步骤不完整,中间少了关键推断)、遗漏细节(任务里要求了某些点,但没有全部覆盖到)、事实错误(模型幻觉导致的错误信息)、表达含糊(意思到了但说得不清晰)。
这些问题,如果给 LLM 一个「回头检查」的机会,它自己是有能力发现并修正的。反思机制就是给它加上这个环节。
核心循环:生成 -> 评估 -> 改进
反思机制的核心思路来自 Self-Refine 论文,整个流程就是「生成 -> 评估 -> 改进」的循环。
这个循环靠两个 prompt 来驱动。第一个负责评估,让 LLM 扮演「检查者」的角色,专门去找问题:
任务:{task}
当前输出:
{current_output}
请评估以上输出:
1. 有没有事实错误或逻辑问题?
2. 有没有遗漏重要内容?
3. 表达是否清晰准确?
如果输出已经足够好,回复「PASS」;
否则指出具体问题并给出改进建议。这个评估 prompt 的设计有几个值得注意的地方。
首先,它给出了明确的检查维度(事实、逻辑、完整性、表达),而不是让 LLM 自由发挥。这很重要,没有方向的评估往往流于表面,LLM 可能只是说「输出看起来不错」,没有真正找到问题。给出具体维度,它才会有针对性地逐项审查。
其次,「PASS」机制是必须有的,这是给 LLM 一个「足够好就停」的出口。如果没有这个机制,LLM 为了反思而反思,可能对一个已经很好的输出挑不必要的小毛病,反而把原本对的东西改错。
如果评估结果不是 PASS,就把评估意见喂进第二个改进 prompt:
原始任务:{task}
当前输出:{current_output}
评估意见:{reflection}
请根据评估意见改进输出:改进 prompt 有一个关键点:它同时传入了原始任务、原始输出、评估意见这三样东西,缺任何一个都会让改进变得盲目。只有任务没有原始输出,LLM 不知道在什么基础上改;只有原始输出没有评估意见,LLM 不知道改哪里;只有评估意见没有任务,LLM 可能改着改着偏离了原始目标。三者都在,它才能有针对性地修改,而不是把内容全部重写一遍。
两个 prompt 循环调用,直到 LLM 自己回复 PASS,或者超过最大轮次强制退出,整个外层逻辑不过是一个普通的 for 循环。
两个粒度:步骤级 vs 任务级
反思可以在两个粒度上触发,它们有不同的适用场景,代价也不一样,选哪种需要根据任务特点来判断。
步骤级反思是在每个工具调用或推理步骤完成后立即检查。它的好处是错误早发现早纠正,不会让一个小错误在后续步骤里层层放大。
想象一下 Agent 在做多步信息检索:第一步选了一个不精准的搜索关键词,后续所有步骤都在错误的信息上继续,到最后才发现,前面的工作全废了。
步骤级反思能在第一步就发现关键词的问题,马上纠正,后续步骤都建立在正确基础上。适合这种粒度的场景是步骤之间强依赖、前一步错了后面会全错的任务。代价是每一步都多一次 LLM 调用,整体延迟和 token 消耗会大幅增加,一个 10 步的任务可能实际要调用 20 次 LLM。
任务级反思是整个任务执行完之后做一次整体评估。好处是开销更小,整个任务只多一次 LLM 调用;而且从整体视角审视,能发现步骤级看不到的问题,各个步骤单独看都是对的,但整体结论前后矛盾,或者各部分之间衔接不自然,这种问题只有从整体视角才能看出来。
代价是如果任务中途某步出了大问题,到最后才发现,前面的执行都已经浪费了。适合步骤之间相对独立、最终输出的整体质量更重要的场景,比如生成一份报告。
多 Agent 互评:为什么「他人审视」比「自我检查」更好
除了单 Agent 的自我反思,还有一种效果通常更好的方式,多 Agent 互评:专门设置一个独立的 Critic Agent,让它来审查执行 Agent 的输出。
为什么独立的审查比自我反思效果更好?你可以类比代码 review 的场景:一个人写完代码自己检查,和让同事来 review,发现的问题质量往往不一样。自己写的东西自己看,容易「视觉疲劳」,会不自觉地补脑跳过问题,潜意识里倾向于认为自己的逻辑是正确的。
在 LLM 里同样如此:单 Agent 自我反思时,评估者和生成者是同一个模型,它在生成输出时形成的一套「内部逻辑」,做评估时也会沿用这套逻辑,对自己输出的错误不够敏感,容易陷入「自洽」。而独立的 Critic Agent 没有这种包袱,它的唯一职责就是「找问题」,视角更客观,更容易发现执行 Agent 自己看不出来的漏洞。
互评的具体流程是:执行 Agent 生成输出,Critic Agent 审查并给出具体批注,执行 Agent 根据批注修改,Critic Agent 再次确认。
什么时候值得用这种方式?质量要求非常高的场景,比如生成代码后让独立的测试 Agent 来验证、生成分析报告后让事实核查 Agent 交叉验证。代价是又多一个 Agent 的调用成本,系统复杂度也更高,所以并不是所有场景都需要互评,普通场景用自我反思就够了。
进阶:Reflexion 和 LATS,把反思做得更深
前面讲的 Self-Refine 是最基础的反思模式,学术界在此基础上还有更进一步的探索,了解这些能帮你在面试里展现更深的理解。
第一个是 Reflexion,这篇论文的核心思路是:不仅让 Agent 反思当前输出的质量,还要让它把「失败经验」存下来,下次遇到类似任务时直接参考,避免重蹈覆辙。
你可以理解成 Self-Refine 是「写完作文当场改」,Reflexion 是「把这次犯的错记在笔记本上,下次写作文之前先翻一遍笔记」。
Reflexion 引入了一个「经验记忆」的概念,每次反思产生的教训会被存储起来,作为后续任务的参考上下文。这个思路在需要重复执行类似任务的场景里特别有价值,比如一个代码生成 Agent,第一次写出了有 bug 的代码,反思后不仅修好了这次的 bug,还把「这类 bug 的成因和避免方法」记下来,下次生成类似代码时就不太容易犯同样的错。
第二个是 LATS(Language Agent Tree Search),它把反思和树搜索结合了起来。前面讲规划能力时提到过 ToT(思维树),LATS 的思路是把蒙特卡洛树搜索(MCTS)和反思结合起来:通过 MCTS 同时探索多条路径,每条路径执行之后都会做评估和反思,反思结果作为经验反馈给后续的路径探索。这样一来,Agent 不仅能同时探索多条路径,还能从已经走过的路径里学到教训,让后续的探索更有针对性。代价当然也更大,既有多路径的成本又有反思的成本,目前主要还是学术研究场景。
还有一种思路叫辩论式反思,不是让一个 Agent 自己审查自己,而是让多个 Agent 互相辩论。比如设置一个「正方 Agent」和一个「反方 Agent」,正方提出一个方案,反方专门挑毛病、提反对意见,正方再针对反对意见优化方案。这种对抗式的反思比单方面审查更能暴露深层问题,因为反方的「职责」就是找漏洞,它会比一个只是「检查一下有没有问题」的 Critic Agent 更积极地挖掘问题。工程上偶尔会在高质量要求的场景里用到这个模式,比如重要的商业决策分析、法律文本审查等。
工程权衡:怎么用才合理?
理解了反思机制的原理和进阶方案之后,还需要知道工程上怎么合理地用它,不然反而会让系统变慢、变贵、甚至陷入死循环。
什么场景值得开反思?输出质量要求高、错误代价大的关键节点,比如最终报告生成、重要决策的推理过程,以及任务比较复杂、LLM 容易遗漏细节的场景,这些是反思最能发挥价值的地方。
什么场景不值得开?简单直接的任务,比如格式转换、简单问答,加反思纯粹是浪费。实时性要求高的场景也一样,一次反思至少多一次完整的 LLM 调用,延迟可能从 1 秒涨到 3 秒,有些应用场景根本接受不了。
最重要的是防死循环,必须设最大轮次,通常设 2-3 轮,绝对不能依赖 LLM 自己判断停止。原因是 LLM 有时会陷入「为了改而改」的循环,每次评估都觉得还有地方能优化,改完又有新的「问题」,每轮改动都很小但实质没有进步,系统就一直在转圈。硬性的轮次上限是唯一可靠的退出机制。
最后要对整体代价有清醒认知:每轮反思包含一次评估和一次改进,3 轮反思意味着在原始生成之外额外增加 6 次 LLM 调用,延迟和成本都会大幅增加,这是工程上做取舍的核心数字。反思是提升质量的有效手段,但不是免费的,用在刀刃上才有价值,不是每步都做。
答好这道题有几个要点。
首先要说清楚反思的闭环结构:两个 prompt 各司其职,评估 prompt 专门找问题,改进 prompt 结合原始任务和批注做定向修改,缺任何一个环节都会失效。
其次,评估 prompt 的两个关键设计要能说出来:给出具体检查维度,以及设置「PASS」出口,否则 LLM 要么流于表面、要么无限挑毛病。
第三,步骤级和任务级反思的区别很容易被忽略:前者错误发现得早但开销大,后者能看到整体问题但前期做的无效工作难以挽回,要根据任务特点选择。
第四,最容易被遗漏的工程要点是防死循环:必须硬性设置最大轮次(2-3轮),不能依赖 LLM 自己停止。
最后,如果能提到多 Agent 互评比自我反思效果更好,并说出原因(同一模型对自己的输出有「自洽」偏见),会是一个加分点。
16. 如何设计多 Agent 的协作与动态切换机制?
协作靠两件事:消息传递和共享状态。消息传递是 Agent 完成自己的工作后把结果发出去,下一个 Agent 取用;共享状态是所有 Agent 共同读写一个状态对象,记录任务进展和中间结果。
动态切换靠 Orchestrator 来做,有两种方式:一种是静态路由,提前写好规则「任务类型 A 就找 Agent X」;另一种是让 LLM 动态决策,根据当前情况实时判断该把任务交给谁。
我的实践是两种混用,主流程用静态路由保证稳定,边缘情况才交给 LLM 动态判断。
在展开细节之前,先从全局视角理解一下多 Agent 协作的几种主要模式。工程实践中常见的协作模式大致分为三类:
- 第一类是流水线模式,Agent 之间按固定顺序依次执行,前一个完成后交给下一个,像工厂的装配线;
- 第二类是层级模式,有一个 Orchestrator(指挥者)负责分配任务、收集结果,其他 Agent 各自执行分配到的子任务;
- 第三类是协商模式,多个 Agent 之间没有严格的上下级关系,通过互相沟通、辩论来达成一致。
这三种模式不是互斥的,一个复杂系统里经常会混合使用。理解了这个大分类之后,再来看具体的通信方式和路由策略就很清晰了。
先说协作:Agent 之间怎么传递信息
你可以把多 Agent 系统想象成一个公司里的多个部门:研究部、开发部、测试部各司其职。部门之间传递信息,有两种方式。
-
第一种方式,像发邮件。研究部完成了资料整理,就把报告「发」出去,开发部收到邮件后再开始工作。这就是「消息传递」的思路,Agent 完成自己的工作后把结果发送到一个消息队列,下游的 Agent 订阅自己感兴趣的消息,取到了再开始处理。这种方式最大的优点是解耦,研究 Agent 不需要知道谁在等它的结果,只管发;接收方也不需要知道消息是谁发的,只管处理。缺点是需要一个「邮件服务器」,也就是消息中间件来维护这套机制,部署成本稍高一些。
-
第二种方式,像共享白板。公司里所有部门都盯着同一块白板,上面写着「当前任务是什么、进展到哪一步了、各部门完成了什么」。研究部写上「资料整理完成」,开发部一看,知道可以开始了,于是接手并写上「代码开发中」。这就是「共享状态」的思路,所有 Agent 都读写同一个状态对象。LangGraph 就是用这个思路来设计的,它有一个贯穿所有 Agent 的 State,每个 Agent 执行完就往 State 里写入自己的结果,下一个 Agent 直接从 State 里读取前面的产出。
这两种方式怎么选?如果各 Agent 之间的依赖关系比较强,前一步的结果要直接传给后一步,用共享状态更直接。如果你希望 Agent 之间尽量解耦,互相不知道对方的存在,用消息传递更合适。
状态管理:多 Agent 共享状态的设计要点
既然提到了共享状态,这里有必要展开聊一下状态管理的设计,因为这是多 Agent 系统里最容易出 bug 的地方之一。
为什么状态管理这么重要?你想,多个 Agent 都在读写同一个状态对象,如果设计不好,很容易出现一个 Agent 写入的结果被另一个 Agent 意外覆盖,或者读到了一半更新的脏数据。这就像公司那块共享白板,如果没有任何规则,两个人同时往白板上写东西,写完之后谁也看不懂。
工程上设计共享状态时有几个关键点需要考虑。
首先是状态结构要分层,通常会把状态分成「全局状态」和「局部状态」两层。全局状态存放所有 Agent 都需要读取的信息,比如用户的原始请求、当前任务进展、最终输出,这些是共享的。
局部状态存放每个 Agent 自己的中间结果,比如搜索 Agent 找到的候选文档列表、代码 Agent 生成的草稿代码,这些在 Agent 内部使用,不会直接暴露给其他 Agent,避免信息污染。
其次是写入规则要明确。最简单也最可靠的做法是「只追加不覆盖」,每个 Agent 完成工作后把结果追加到状态里,而不是修改已有的字段。LangGraph 的 State 更新机制就是这个思路,你定义好 State 的 schema,每个节点返回的是一个「增量更新」,框架帮你合并到全局状态里,这样就不会出现互相覆盖的问题。
最后是错误状态的处理。如果某个 Agent 执行失败了,它的错误信息也应该写入状态,而不是悄悄吞掉。后续的 Agent 或者 Orchestrator 读到这个错误状态后,才能做出正确的决策,比如跳过这一步、换一个 Agent 重试、或者直接终止任务。
再说切换:Orchestrator 怎么决定叫谁
「切换」就是决定下一步把任务交给哪个 Agent,这个决策动作在系统里叫做「路由」。Orchestrator 就是那个负责做路由决策的角色。
路由有两种策略。
静态路由,就是提前把规则写死。比如任务描述里包含「搜索」就找 Researcher Agent,当前步骤已经是「代码写完了」就找 Reviewer Agent,找不到匹配规则就回到 Orchestrator 兜底。
这就像工厂流水线,每道工序完成后,下一步去哪个工位是固定的,效率高、可预测、好调试。但它覆盖不了你没预料到的情况,如果任务走了一条你没定义规则的路径,系统就不知道该怎么办了。
动态路由,则是把「下一步找谁」的决策权交给 LLM 来做。Orchestrator 把当前任务描述、已经完成了什么、还有哪些 Agent 可以调用,全部告诉 LLM,让它判断「现在应该叫哪个 Agent 来做下一步」。
这种方式的优点是灵活,能处理任何你没预先设计的路径,任务走到一个边缘情况时,LLM 也能做出合理判断。缺点是每次路由都要多一次 LLM 调用,增加了延迟和成本,而且 LLM 偶尔也会路由错,系统行为的可预测性就降低了。
两种路由策略的对比可以用一张图来理解:动态路由在代码层面是怎么实现的?其实核心就是让 LLM 做一次分类决策,把可用的 Agent 列表和当前上下文传给它,让它返回应该调用哪个 Agent。下面是一个简化的示例
def dynamic_route(task_context: str, available_agents: list[str]) -> str:
"""让 LLM 根据当前上下文决定下一步调用哪个 Agent"""
prompt = f"""当前任务状态:
{task_context}
可用的 Agent:
{chr(10).join(f'- {agent}' for agent in available_agents)}
请根据当前进展,判断下一步应该交给哪个 Agent 来执行。
只返回 Agent 名称,不需要解释。"""
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
selected = response.choices[0].message.content.strip()
return selected # 返回选中的 Agent 名称实际项目里通常还会加一些保护措施,比如校验返回的 Agent 名称是否在可用列表中、设置默认的 fallback Agent、记录路由决策的日志以便后续分析等。
Handoff 模式:Agent 之间的「接力棒」
除了由 Orchestrator 集中做路由决策,还有一种更去中心化的切换方式叫 Handoff(交接),这个模式在 OpenAI 的 Swarm 框架里被用来演示和推广。需要注意的是,Swarm 是一个教育性/实验性框架,OpenAI 官方明确说它不是生产级工具,但它对 Handoff 模式的展示非常直观,很适合理解这个概念。
Handoff 的思路是:不需要一个中央的 Orchestrator 来决定「下一步找谁」,而是让当前正在执行的 Agent 自己决定「我做完了,接下来应该把任务交给谁」。你可以理解成接力赛跑,每个运动员跑完自己那一棒之后,直接把接力棒递给下一个人,不需要裁判在旁边喊「下一个是谁」。
这种模式的好处是每个 Agent 对自己的任务边界最清楚,它知道自己做完了什么、还缺什么,由它来决定下一步找谁,往往比一个外部的 Orchestrator 判断得更准确。而且没有中央节点的瓶颈,系统的扩展性更好。
缺点也很明显:没有全局视角。如果 Agent A 把任务交给了 Agent B,但 Agent B 又觉得这不是自己的活儿,再交给 Agent C,甚至 Agent C 又交回给 Agent A,就形成了死循环。
所以用 Handoff 模式时,必须设计好每个 Agent 的职责边界,并且加上防循环的机制,比如记录任务已经经过了哪些 Agent,如果发现重复经过同一个 Agent 就强制终止。
工程上怎么用
实践中最稳健的做法是两种路由组合用:主流程用静态路由,把确定性的节点切换都写成规则,保证绝大多数情况下系统行为稳定可预测;只在遇到没有匹配规则的边缘情况时,才交给 LLM 动态决策。这样静态路由负责「保底」,动态路由负责「兜住异常」,两者互补。
至于 Handoff 模式,它适合那种每个 Agent 职责边界非常清晰、任务流向相对确定的场景。如果你的系统里 Agent 数量不多、每个 Agent 的输入输出接口定义得很明确,用 Handoff 比用中央 Orchestrator 更简洁。但如果 Agent 数量多、任务流向复杂,还是建议用 Orchestrator 来统一调度,避免 Agent 之间的交接变成一团乱麻。
通信方式的选择同理:如果你的多 Agent 流程是一条相对清晰的流水线,各步骤之间有明确的前后依赖,就用共享状态,简单直接;如果你的系统需要让多个 Agent 独立并行、互相不感知对方的存在,就用消息传递,解耦清晰。
答好这道题有几个层次。首先,协作机制要说出两种通信方式的本质区别:消息传递的核心是解耦,发送方不需要知道接收方是谁,适合 Agent 之间需要独立运行的场景;共享状态的核心是直接,所有 Agent 读写同一个对象,LangGraph 就是这个思路,适合各步骤依赖关系明确的流水线型任务。
这两种选哪个,取决于 Agent 之间的依赖有多强。其次,动态切换要说出静态路由和动态路由各自的优缺点:静态路由稳定可预测,但覆盖不了没预料到的边缘情况;动态路由灵活,但每次多一次 LLM 调用,且行为不可预测。
最容易被忽略的点,也是最能体现工程经验的答法,就是说出「主流程静态路由保底,边缘情况才交给 LLM 动态决策」的混合策略。这个答法面试官一听就知道你真的做过多 Agent 系统。