《解码Mamba:从SSM到革命性序列建模架构的前世今生》
论文:《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》
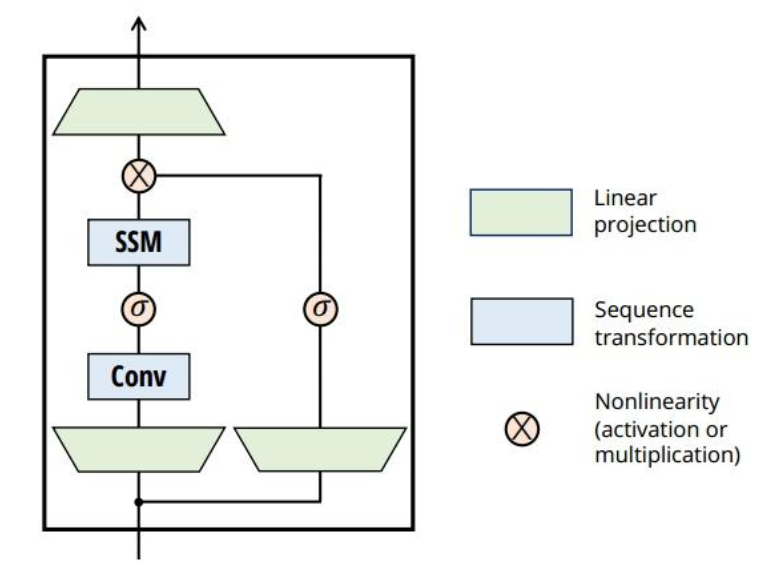
在深度学习领域,Transformer凭借其强大的全局注意力机制统治了序列建模任务,但其计算复杂度随序列长度呈平方级增长(O(N2)O(N^2)O(N2)),成为处理超长序列的瓶颈。为了突破这一限制,研究者们将目光投向另一种经典模型------状态空间模型(SSM),并由此催生了Mamba这一革命性架构。本文将带你穿越技术迷雾,从SSM的起源出发,解析Mamba如何通过HiPPO、S4的奠基,最终通过S6实现突破,并揭示其背后的数学原理与公式细节。
一、Mamba的前世:从SSM到S4的奠基之路
- 基石:状态空间模型(SSM)
SSM起源于控制理论,用于描述动态系统的状态演化。其核心思想是通过隐状态h(t)h(t)h(t)压缩历史信息,数学表达为连续时间域下的微分方程:
h′(t)=Ah(t)+Bx(t)y(t)=Ch(t) \begin{aligned} h'(t) &= \mathbf{A} h(t) + \mathbf{B} x(t) \\ y(t) &= \mathbf{C} h(t) \end{aligned} h′(t)y(t)=Ah(t)+Bx(t)=Ch(t)
其中,A,B,C\mathbf{A}, \mathbf{B}, \mathbf{C}A,B,C为可学习参数矩阵。离散化后(如零阶保持ZOH):
ht+1=exp(ΔA)ht+(ΔA)−1(exp(ΔA)−I)⋅ΔB⏟Bˉxt+1yt=Cht \begin{aligned} h_{t+1} &= \exp(\Delta \mathbf{A}) h_t + \underbrace{(\Delta \mathbf{A})^{-1} (\exp(\Delta \mathbf{A}) - \mathbf{I}) \cdot \Delta \mathbf{B}}{\bar{\mathbf{B}}} x{t+1} \\ y_t &= \mathbf{C} h_t \end{aligned} ht+1yt=exp(ΔA)ht+Bˉ (ΔA)−1(exp(ΔA)−I)⋅ΔBxt+1=Cht
SSM具备天然线性时间复杂度O(N)O(N)O(N)的优势,但传统SSM存在两大缺陷:
- 长序列记忆能力差 :参数矩阵A\mathbf{A}A易导致梯度消失或爆炸。
- 输入无关性 :参数固定,无法根据输入动态调整记忆。

- 记忆优化:HiPPO(High-Order Polynomial Projection Operators)
为解决长记忆问题,HiPPO提出通过**特定初始化矩阵AHiPPO\mathbf{A}_{\text{HiPPO}}AHiPPO**优化SSM。例如,使用Legendre多项式的对角矩阵结构:
Anm={2n+12m+1if n>mn+0.5if n=m0if n<m \mathbf{A}_{nm} = \begin{cases} \sqrt{2n+1}\sqrt{2m+1} & \text{if } n > m \\ n + 0.5 & \text{if } n = m \\ 0 & \text{if } n < m \end{cases} Anm=⎩ ⎨ ⎧2n+1 2m+1 n+0.50if n>mif n=mif n<m
HiPPO的数学贡献在于证明该初始化可使SSM在有限维度内近似无限记忆,为后续模型奠定基础,但仍未解决输入无关性问题。
- 效率飞跃:S4(Structured State Space)
S4将SSM推向实用,核心突破在于:
- 结构化矩阵 :将A\mathbf{A}A设计为低秩或近似对角矩阵,降低计算复杂度。
- 双重计算模式 :
- 训练时:利用卷积定理(Conv(h,exp(ΔA))\text{Conv}(h, \exp(\Delta \mathbf{A}))Conv(h,exp(ΔA)))实现并行计算。
- 推理时:循环计算ht+1=Aˉht+Bˉxt+1h_{t+1} = \bar{\mathbf{A}} h_t + \bar{\mathbf{B}} x_{t+1}ht+1=Aˉht+Bˉxt+1,保持线性时间。
公式简化后为:
ht+1=Aˉht+Bˉxt+1(循环模式)h_{t+1} = \bar{\mathbf{A}} h_t + \bar{\mathbf{B}} x_{t+1} \quad \text{(循环模式)}ht+1=Aˉht+Bˉxt+1(循环模式)
或通过卷积等价计算:
h=Conv(exp(ΔA),x)h = \text{Conv}(\exp(\Delta \mathbf{A}), x)h=Conv(exp(ΔA),x)
S4实现了理论上的线性时间与高效并行训练,但仍是线性时不变(LTI)系统,缺乏内容感知能力。
二、Mamba的今生:选择性机制与硬件优化
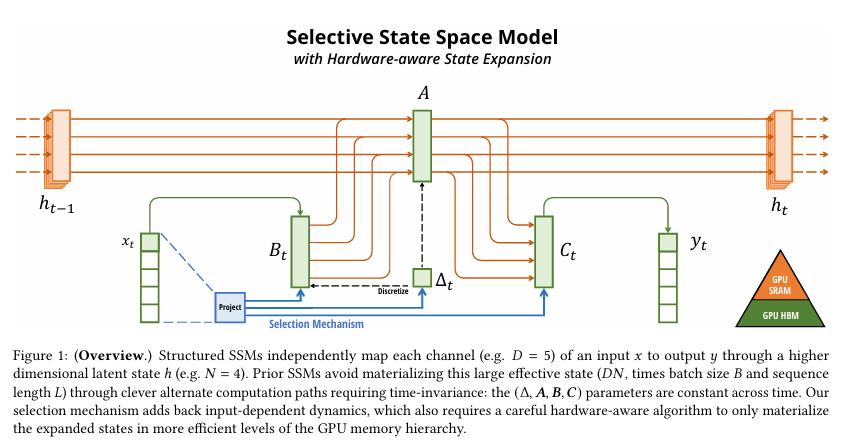
- 核心突破:S6(Selective State Space)
Mamba(即论文中的S6)的革命性在于打破LTI约束,引入输入相关的动态参数。其关键公式为:
Δt=Softplus(xtWΔ)Bt=xtWBCt=xtWCAˉt=exp(ΔtA)Bˉt=(ΔtA)−1(exp(ΔtA)−I)⋅ΔtBt \begin{aligned} \Delta_t &= \text{Softplus}(x_t W_\Delta) \\ \mathbf{B}_t &= x_t W_B \\ \mathbf{C}_t &= x_t W_C \\ \bar{\mathbf{A}}_t &= \exp(\Delta_t \mathbf{A}) \\ \bar{\mathbf{B}}_t &= (\Delta_t \mathbf{A})^{-1} (\exp(\Delta_t \mathbf{A}) - \mathbf{I}) \cdot \Delta_t \mathbf{B}_t \end{aligned} ΔtBtCtAˉtBˉt=Softplus(xtWΔ)=xtWB=xtWC=exp(ΔtA)=(ΔtA)−1(exp(ΔtA)−I)⋅ΔtBt
ht+1=Aˉtht+Bˉtxt+1选择性状态更新h_{t+1} = \bar{\mathbf{A}}_t h_t + \bar{\mathbf{B}}t x{t+1} \quad \text{选择性状态更新}ht+1=Aˉtht+Bˉtxt+1选择性状态更新

核心原理:
- 选择性记忆 :通过xtx_txt动态调整步长Δt\Delta_tΔt和参数矩阵Bt,Ct\mathbf{B}_t, \mathbf{C}tBt,Ct。例如,对无关输入(如标点)可设置Δt≈0\Delta_t \approx 0Δt≈0,使ht+1≈hth{t+1} \approx h_tht+1≈ht,实现"跳过记忆"。
- 内容感知:模型根据输入动态选择"记住"或"遗忘"信息,类似注意力机制但更高效。
- 硬件感知算法:并行扫描
由于参数随时间变化,S4的卷积优化失效。Mamba设计并行扫描算法,将递归计算分解为可并行执行的阶段:
- 计算所有Δt\Delta_tΔt和参数矩阵。
- 通过前向扫描计算隐状态:
ht+1=∏i=1t+1Aˉi⋅h0+∑i=1t+1(∏j=i+1t+1Aˉj)⋅Bˉixih_{t+1} = \prod_{i=1}^{t+1} \bar{\mathbf{A}}i \cdot h_0 + \sum{i=1}^{t+1} \left( \prod_{j=i+1}^{t+1} \bar{\mathbf{A}}_j \right) \cdot \bar{\mathbf{B}}_i x_iht+1=∏i=1t+1Aˉi⋅h0+∑i=1t+1(∏j=i+1t+1Aˉj)⋅Bˉixi
该算法在GPU上通过分块和流水线优化,实现近似线性时间的并行计算。

三、Mamba的优势与公式对比
| 模型 | 核心公式 | 复杂度 | 特性 |
|---|---|---|---|
| SSM | ht+1=Aˉht+Bˉxt+1h_{t+1} = \bar{\mathbf{A}} h_t + \bar{\mathbf{B}} x_{t+1}ht+1=Aˉht+Bˉxt+1 | O(N)O(N)O(N) | 静态参数,长记忆差 |
| S4 | 同SSM + 卷积优化 | O(N)O(N)O(N) | 高效并行,但LTI |
| Mamba | ht+1=Aˉtht+Bˉtxt+1h_{t+1} = \bar{\mathbf{A}}_t h_t + \bar{\mathbf{B}}t x{t+1}ht+1=Aˉtht+Bˉtxt+1 (参数由xtx_txt生成) | O(N)O(N)O(N) | 选择性+动态参数,兼顾效率与表达能力 |
四、Mamba的应用与未来
- 超长序列建模:语言、基因组学、时间序列等领域,替代Transformer。
- 高效推理:线性复杂度与并行扫描使其在边缘设备部署潜力巨大。
- 未来方向:结合稀疏化技术进一步降低内存消耗,或探索非自回归生成。
五、总结:Mamba的本质
Mamba并非凭空创造,而是站在SSM、HiPPO、S4的肩上,通过选择性机制 破解LTI约束,用硬件优化平衡效率与表达力。它证明了: "动态参数+并行计算" 是超越Transformer范式的关键。