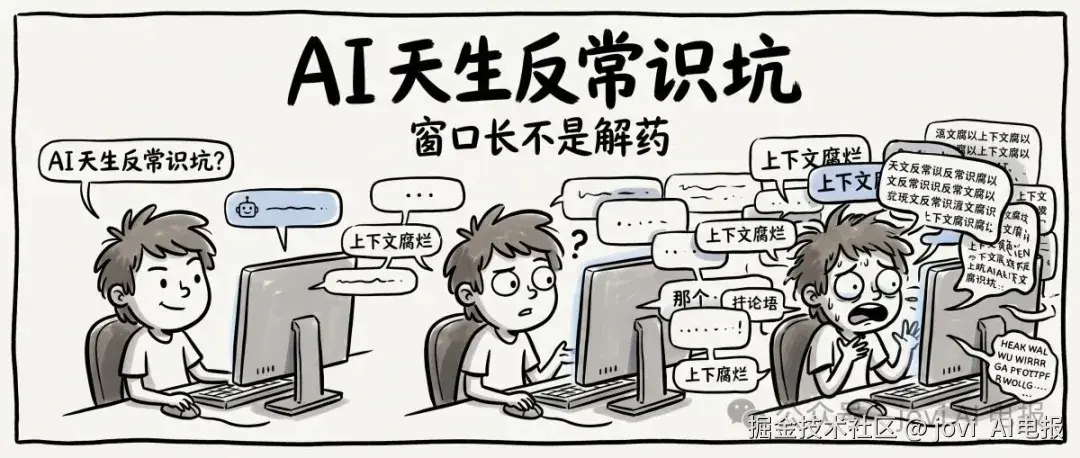
我们经常听见某某模型上下文,能装x部《三体》全集。窗口做再大,上下文腐烂都不会消失。新手老手都一样。这篇讲一个所有人都该会但大多数人忽略的基本操作:会话迁移。附可直接复制用的迁移 Prompt,和一个开源 Skill。
也就是说,你的窗口还有一大半空着,AI 已经开始"变质"了。
这篇文章要讲的就是:会话迁移------每个用 AI 的人都应该掌握的基本技能。 甭管你用的是 ChatGPT、Claude、还是什么 Agent,学会在合适的时间把有价值的信息打包、迁移到新会话继续,直接提高你用 AI 的效率和准确率。
先说会话管理
Anthropic 把这个现象叫 Context Rot------上下文腐化。上下文不是越长越好,是越长越乱。模型的注意力被稀释到大量 token 上,性能开始掉。这不是某个模型的锅,是所有 LLM 的通病。
所以问题的核心不是"怎么让 AI 记住更多",而是"怎么管理好每一次会话"。
你的上下文里装了什么
我以前也觉得窗口 200K,空间有的是。但每次对话,上下文里不止是输入和 AI 的回复。以一个典型 Agent 会话为例:
bash
总上下文(以 200K 为例)
├── 固定开销(~15-20K) ← 每轮都在,你控制不了
│ ├── 系统指令
│ ├── 工具定义、技能描述
│ └── 环境信息
├── 半固定(~5-10K) ← 你写的,每轮都在
│ ├── 人设、偏好
│ └── 项目背景
└── 动态可用(~160-180K) ← 这才是你真正能用的
├── 对话历史
├── 文件内容
└── 工具调用结果 ← 最大隐形杀手固定开销吃掉 10-15%,半固定再吃 5%。真正属于你的动态空间大概 80-85%。而这部分里,最大杀手不是你打的字------是工具调用的返回结果。搜索一次几百上千 token,读个文件几千 token,改了几轮下来可能就占了三四成空间。普通 Chatbot 没有工具调用,所以压力小很多。但 Agent 用户四五轮下来上下文就能用掉一半。
 上下文腐烂
上下文腐烂
每个会话专注一个方向
我自己以前跟 AI 对话也是想起什么问什么,没想过当前在做什么类型的事。后来发现,跟 AI 协作时基本就在做四类事:
-
• 发散找方向 --- 脑暴、探索可能性、收集信息
-
• 收敛出结果 --- 确定方案、写文章、改代码
-
• 校验纠错 --- 检查结果对不对、改 bug、调整方向
-
• 整理迁移 --- 当前阶段做完了、或者上下文太长了,打包换新会话
最常见的情况是一个会话里把这四类事全搅在一起。发散到一半突然开始执行,执行到一半又跳回去探索,中间还穿插查资料。AI 没法自动区分我们在干什么------它把所有内容当同等重要的上下文一起消化,互相干扰,越聊越乱。
更好的方式是:判断当前状态,一个会话专注一个状态。 发散就在发散会话里,执行就在执行会话里。状态切换了就换会话。后续又有新的发散想法?回到那个发散会话继续。每一次会话记录都留着,随时可以回去复查。
Marcel Kleineberg 提过 Token Hygiene 的四级状态模型:Active(正在用)→ Slumbering(暂时不用但保留)→ Hidden(背景信息)→ Trashed(丢弃)。套用到会话管理上:当前在推的是 Active,暂时搁置的是 Slumbering,做完的归档。不同阶段的内容,别混在一个窗口里。
会话管理的四个动作
不管你用什么工具,管理会话就是四类动作:
| 类别 | 你要做什么 | 怎么做 |
|---|---|---|
| 监控 | 知道当前状态 | Agent 用户可以查上下文用量;Chatbot 用户靠体感 |
| 清理 | 开新会话,清掉不需要的 | 开新对话就是"清理" |
| 保留 | 把有价值的信息带走 | 就是迁移------这篇文章的重点 |
| 隔离 | 某些事从一开始就不该进主会话 | 开多个对话分别处理不同任务 |
核心原则:先保留,再清理。 先把有价值的东西打包出来,再开新会话。清理之前不保留,信息就丢了。
这样做的好处是:每个会话上下文干净,模型不容易混淆,对话质量高。
但甭管你怎么管理,单次会话终究会遇到上下文过长的问题。这时候就需要迁移。
Prompt 迁移
在 AI 还没完全混乱之前,让它帮你把当前会话状态打包,复制到新会话继续。
根据项目定制你的迁移 Prompt
不同项目关注的东西不一样。写文章关心大纲、素材、风格约束;写代码关心文件路径、技术决策、已解决的报错。
我的做法是直接告诉 AI 当前项目的重点,让它帮我生成迁移 Prompt。比如:
我们在做一个内容生产系统项目,主要涉及选题策划、素材库、飞书集成。帮我写一个会话迁移的 prompt,需要保留:已确认的选题方向、已否决的方案(附原因)、当前的写作进度、关键的技术决策、还没做完的待办。输出简洁条目式,我直接复制到新会话用。
AI 会根据项目特点生成定制化的迁移 Prompt。拿它去执行迁移,按你关心的维度把状态整理出来。每个项目不一样,不需要记固定模板。
通用会话迁移 Prompt
下面这个可以直接复制粘贴,一个字不用改。适用于所有场景------写文章、做策划、写代码、调研分析都行:
bash
请帮我整理当前对话的完整状态,我要迁移到新会话继续。
先判断当前阶段:发散探索 / 收敛执行 / 校验纠错。如果同时有多条任务线,分别标注每条所处的阶段。
然后按以下结构输出,只保留确定信息,不猜测不脑补:
## 目标
主要在做什么,要达成什么。如果有多条任务线,分别列出,标出主线
## 已确认的结论
确定了的决策、方向、方案、判断。每条独立写清
## 已否决的方案(附原因)
讨论过但放弃的方向,以及迭代中不认可的角度/写法/方向。写清楚为什么------这特别重要,防止新会话重复踩坑
## 进度
按任务或文件分别标注状态:
- ✅ 已完成的:简要写结果
- 🔧 进行中的:做到哪了
- ⏳ 待办的:还没开始
涉及多个文件时,列出每个文件各自状态
## 关键约束
背景条件、偏好、限制、不能违反的规则
## 具体信息
不写出来就会丢失的值:路径、参数、链接、数据、名称、工具版本、环境依赖等。多个产出文件时说明它们之间的关系
要求:条目式输出,每条自包含。新会话的 AI 看了就能直接接上。这个 Prompt 背后是经过实战验证的设计。结构来自 Hermes Agent 的上下文压缩模板------Hermes 每次自动压缩会话时都用一套 12 段结构来保留关键信息(目标、约束、已完成的操作、当前状态、待办、关键决策......),经过大量实际使用验证有效。我把它从 12 段精简到 6 段,保留了最有信息密度的部分。
这个迁移 Prompt 已经整理成了一个开源 Skill,可以直接集成到 Claude Code、Hermes 等 Agent 中使用。Skill 里还包含了质量自检清单和常见踩坑点(多任务并行、软性否决、多文件跟踪等)。如果你用的是支持 Skills 的工具,一条命令就能装上:
GitHub: github.com/uwings/session-migration-prompt
"已否决的方案"这条我自己经常漏。只记得留下了什么,忘了标注扔掉了什么,结果新会话又把放弃的方案重新走一遍------这是迁移最常见的踩坑点。不只是技术方案,写作中的方向变更、明确不喜欢的写法,都属于"已否决",一并标注。
时机 :不用等窗口快满了才迁移。微软的研究显示大概 39% 左右就开始衰减。要求高的任务,40-50% 就可以迁移;要求没那么高的,60-70% 也行。多篇研究和用户经验的共识是:70-75% 是一个关键临界点------再早了浪费上下文容量,再晚质量已经退化了。感觉到"开始有点不对劲"就动手。
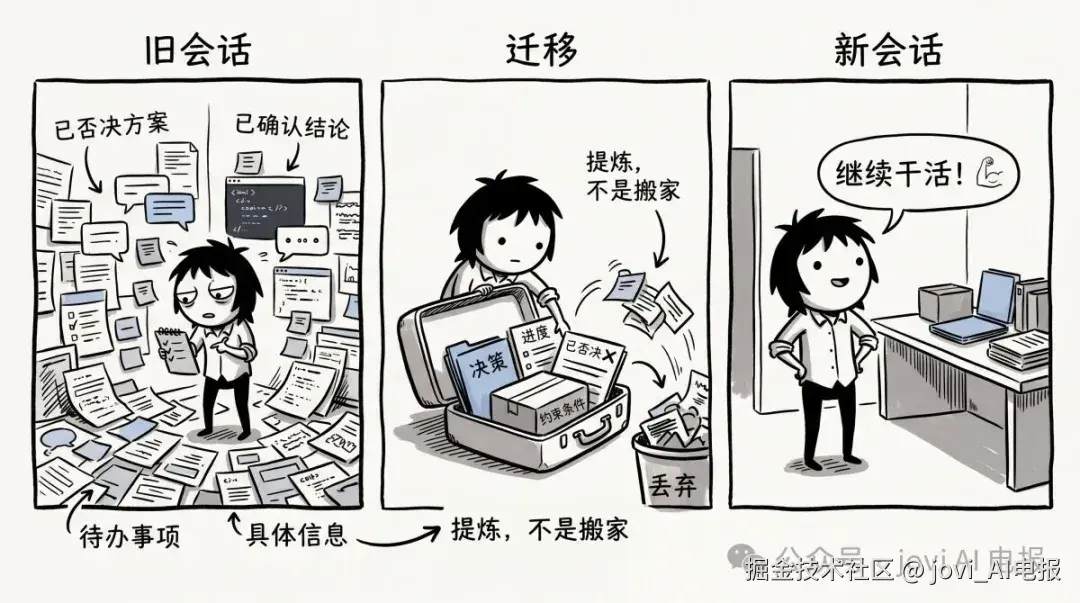 会话迁移流程
会话迁移流程
但这里有个关键问题------你得能识别"不对劲"才行。
模型的上下文窗口就像人的工作记忆------塞进来的东西越多越杂,推理质量越差。这不是缺陷,是当前架构的固有特性。所以"上下文管理"不单是 AI 的技术问题,它其实是人和模型之间的注意力协同:思路理清楚了,模型输出自然跟着上去。迁移就是一次整理------不单是给 AI 搬数据,也是帮自己重新捋一遍"我们在干什么、走到哪了、接下来要什么"。
AI 不会告诉你它已经偏了。它的语气从头到尾都很确定。你给的信息越多,按理说它应该越做越好,但有时候反而越做越差。不是你的错觉,多轮对话就是这样:轮数越多,偏移越大,但输出的流畅度和自信度完全不变。
这会产生一种隐蔽的风险:把 AI 的表达流畅当成了自己的认知升级。用久了,回去跟真实的人沟通,会觉得对方"好慢"、"好浅"。但这把尺子本身就是弯的------丈量世界的标准,已经被 AI 的输出风格悄悄重新校准了。如果发现自己跟大多数人越来越聊不到一块儿去,也许可以先想一想,是不是这把尺子的问题。
所以迁移不只是技术操作。你能识别 AI 的输出质量在下降,你才知道什么时候该迁移。识别力不够,迁移再好也用不上。
如何识别,可以参考公众号以前发的 AI认知路径系列的文章。
文档中转
任务跨度大的时候------写系列文章、做系统设计、长期调研------与其靠 Prompt 搬运,不如一开始就让 AI 把关键产出写进文件。对话丢了文件还在。
用 Agent 的时候(Hermes、Claude Code 等):到关键节点,让 AI 把有价值的东西写入文件。对话里的结论、搜集来的素材、阶段性草稿,都让它直接写成本地文件。迁移时新会话只需要读这些文件就能接上。
一种好用的模式是 HANDOFF------开新会话前让 AI 写一份交接文档:当前进度、试了什么、什么有效、什么没用、下一步。新会话只读这个文件就能接着做。跟迁移 Prompt 做的事一样,只不过产出落到了文件里,比复制粘贴更稳。
Claude Code 的创造者 Boris Cherny 的个人做法也值得参考:他不依赖自动压缩------先让 AI 写摘要,自己确认摘要的准确性 ,然后清空上下文重开。由人控制什么被保留,不交给 AI 来猜。这个思路对 Chatbot 用户一样适用:迁移 Prompt 生成的结果,你快速浏览一遍再粘贴,确认没有遗漏。
用 Chatbot 的时候(ChatGPT、Claude 网页版):没有写入文件的能力,手动把关键内容存下来,或者回去翻历史会话记录(想用的时候能找到,就必须做会话的管理)。
什么时候该迁移:一张参考表
我以前也对迁移时机有误解------以为要等上下文快满了才需要......不是。
| 场景 | 建议迁移时机 | 大概轮次 | 说明 |
|---|---|---|---|
| 普通对话/问答 | 50-60% | 20-30轮 | 简单问答没那么敏感,可以撑久一点 |
| 写文章(需严谨) | 40-50% | 10-15轮 | 工具调用多,中间产物占空间大 |
| 代码/Agent任务 | 40-50% | 8-12轮 | 搜索、读文件、执行命令产生大量中间信息 |
| 探索/头脑风暴 | 60-70% | 25-40轮 | 对精度要求低,乱一点也无所谓 |
几个常见的理解偏差:
"窗口大就不用迁移了" --- 错。窗口大只是推迟了问题,衰减比例不会变。200K 窗口的 40% 一样会开始变质。行业把窗口从 4K 做到 1M,从来没说过"窗口够大就不用管理上下文"。
"等 AI 开始乱了我再迁移" --- 晚了。AI 混淆之后整理出来的东西已经不可信了。迁移要在 AI 还清醒的时候做。
"迁移就是把对话复制一遍" --- 不是。迁移是提炼,不是搬家。你需要的是决策、进度、待办和约束,不是把几十轮对话原封不动搬过去。搬过去一样会乱。
"结果不对,改 Prompt 就行" --- 不一定。一看到结果不对就反复改 Prompt、反复拉扯,最后越改越乱。更稳妥的做法是先判断问题属于哪一类:
-
任务没压实 --- 你要的是判断,它给你润色;你要的是能直接发的结果,它给你一段解释。问题不在 Prompt,在你自己没把事说清楚。
-
信息没给够 --- 方向没完全错,但总是虚、泛、不贴你的场景。你脑子里有前提条件但没说出来。
-
它在乱补 --- 内容很顺,语气很稳,但里面有些信息你根本没给。最麻烦的不是它乱,是它像真的。
-
上下文已经脏了 --- 前面纠正过,后面又绕回去了。旧方向、旧要求反复冒出来。你越改越乱套。
前三个靠补条件和卡边界能解决。第四个,唯一的办法就是换会话------也就是迁移。脏了以后继续在原会话里补,常常是在脏水里洗布。
Agent 用户要多留个心眼
上面那张表对普通 Chatbot 够用了。但如果你用的是 Agent(Hermes、Claude Code 等),情况不太一样。
Agent 的特点是:每一轮对话不只是文字,它还会调用工具------读文件、搜代码、执行命令------每一次工具调用都会往上下文里塞大量中间产物。一轮 Agent 对话产生的 token 可能是普通对话的 5-10 倍。
所以 Agent 用户面临的不是"聊了几十轮要不要迁移"的问题,而是"没几轮上下文就快满了"的问题。
Hermes 默认的上下文压缩阈值是 50%------用到一半就开始压。但系统 prompt 本身就要吃掉 10-15% 的窗口空间(persona、memory、skills 列表),再加上前几轮工具调用,可能四五轮就触发压缩了。压缩一次损失一批细节,压缩两三次早期信息就开始混淆。Agent 变得不太可用。
怎么办?两个调整:
第一,调高压缩阈值。 把 50% 调到 75%。让它晚一点压,多留一些空间给实际工作。当然也不能太高(比如 90%),否则压的时候缓冲空间不够,摘要质量反而差。75% 是一个实际跑下来比较稳的值。
第二,迁移时机可以比 Chatbot 晚一点------但前提是有判断能力。 Agent 的输出看得懂、能判断对不对,那即使开始有点偏了,也能及时纠正、及时迁移。但如果自己也不太确定它对不对,那还是早点迁移更安全。迁移时机的早晚,说到底取决于能不能识别 AI 的输出质量在下降。
Claude Code 在这方面体验好一些,部分原因是上下文窗口大,工程化做的不错,部分是子 Agent 机制把中间产物隔离了------主会话只拿到结论,噪声留在子会话里。但底层问题一样,只是推迟了。
Claude Code 的自动压缩有一个值得注意的问题:上下文接近满时(大约 93%)自动触发,用一个独立的 AI 对整个对话做摘要。听起来不错,实际用下来多数用户反馈压缩后"忘记了一切"------压缩是有损的。
其实你也可以主动用子 Agent 来隔离。比如搜索资料的时候,别在主会话里搜------让子 Agent 去搜,搜完只把结论带回来。搜索结果动辄几千上万 token,全塞进主会话很快就满了。用子 Agent 隔离之后,主会话的上下文压力小很多,能多跑好几轮。
不只是搜索。任何会产生大量中间产物的操作------批量文件读取、代码分析、数据整理------都可以丢给子 Agent。主会话只拿结论。而且子 Agent 在干净的上下文里工作,没有主会话的历史干扰,搜索和分析结果反而更客观。
会话管理是预防,Prompt 迁移是急救(现在算是基本操作了),文档中转是长期保险。迁移不是搬家,是提炼。 从一大堆对话里提炼出决策、进度、待办和约束,用干净的上下文接着推。
会话迁移这件事,不是什么高级技巧。它是每个用 AI 的人都应该知道、也应该会做的事。行业一直在把窗口做大来推迟问题,但窗口再大,上下文腐烂也不会消失。学会管理你的会话,在合适的时间迁移,这是你能为自己做的最实际的事。
最后说一句不那么舒服的话:AI 用久了,很容易觉得自己变强了。有时候确实变强了。也有时候,只是把 AI 的表达流畅当成了自己的认知升级。它替你说了、替你总结了、替你论证了,你把这些当成了自己的。拿着一把被 AI 重新校准过的尺子去丈量世界,会觉得哪里都偏了------除了你自己。
我现在会时不时停下来想一下:这个判断是我自己想通的,还是 AI 说得太顺我就信了。也说不准每次都能分清。