目录
二、InfoGCN++:通过预测未来学习表征以实现在线骨架人体动作识别
[🎯 核心问题](#🎯 核心问题)
[💡 核心创新:预测未来,辅助识别](#💡 核心创新:预测未来,辅助识别)
[🔧 关键技术细节](#🔧 关键技术细节)
[1. Neural ODE 用于运动预测](#1. Neural ODE 用于运动预测)
[2. 多任务学习](#2. 多任务学习)
[3. 因果 Transformer](#3. 因果 Transformer)
[📊 实验结果](#📊 实验结果)
[🏆 主要贡献](#🏆 主要贡献)
[🔗 与你之前工作的关联](#🔗 与你之前工作的关联)
[📊 核心区别一览](#📊 核心区别一览)
[🔍 详细对比](#🔍 详细对比)
[1. 任务本质不同](#1. 任务本质不同)
[2. 技术路线对比](#2. 技术路线对比)
[3. 架构设计哲学](#3. 架构设计哲学)
[🔗 深层联系](#🔗 深层联系)
[💡 总结](#💡 总结)
[1. InfoGCN++ vs GRPO](#1. InfoGCN++ vs GRPO)
[2. SimpliHuMoN vs GRPO](#2. SimpliHuMoN vs GRPO)
场景1:基于GRPO优化SimpliHuMoN的运动生成质量
[一、SimpliHuMoN + GRPO:从"模仿真值"到"追求最优"](#一、SimpliHuMoN + GRPO:从"模仿真值"到"追求最优")
[二、InfoGCN++ + GRPO:感知-决策闭环是什么意思](#二、InfoGCN++ + GRPO:感知-决策闭环是什么意思)
三、为什么InfoGCN++不适合直接+GRPO做"识别优化"
[一、SimpliHuMoN + GRPO = "学走路/学动作"的能力](#一、SimpliHuMoN + GRPO = "学走路/学动作"的能力)
[二、InfoGCN++ + GRPO = "看准时机、找对角度观察"的能力](#二、InfoGCN++ + GRPO = "看准时机、找对角度观察"的能力)
[直接给结论:SimpliHuMoN + GRPO(学动作)更迫切](#直接给结论:SimpliHuMoN + GRPO(学动作)更迫切)
一、前言
仅供参考,未经实验验证。
二、InfoGCN++:通过预测未来学习表征以实现在线骨架人体动作识别
| 项目 | 内容 |
|---|---|
| 标题 | InfoGCN++: Learning Representation by Predicting the Future for Online Human Skeleton-based Action Recognition |
| 作者 | Seunggeun Chi, Hyung-gun Chi, Qixing Huang, Karthik Ramani |
| 机构 | 普渡大学 (Purdue University)、德克萨斯大学奥斯汀分校 (UT Austin) |
| 发表 | arXiv:2310.10547, 2023年10月16日 |
| 代码 | GitHub - stnoah1/infogcn2 |
🎯 核心问题
传统骨骼动作识别方法(包括其前身 InfoGCN)存在致命缺陷 :必须等待整个动作序列完全结束后才能进行分类。这在实时场景中是不可接受的------比如机器人交互、监控系统,延迟可能长达10秒。
例如,识别"穿鞋"这个动作,传统方法需要等动作完全结束才能给出结果,而 InfoGCN++ 可以在动作进行过程中就实时判断。
💡 核心创新:预测未来,辅助识别
InfoGCN++ 的核心思想是:
通过预测未来的骨骼运动,来构建更完整的动作表征,从而在仅观察到部分序列时就能准确识别动作。
具体实现上,它引入了 Neural Ordinary Differential Equations (Neural ODE) 来建模隐藏状态的连续演化:
https://engineering.purdue.edu/cdesign/wp/wp-content/uploads/2023/10/2310.10547.pdf
架构组成
组件 功能 Embedding Layer 将3D骨骼数据投影到潜在空间 Encoder 使用 Transformer + 因果掩码 + SA-GC 提取时空特征 Future Motion Predictor 利用 Neural ODE 预测未来 N 帧的表征 Future Motion Prediction Decoder 将预测表征解码为3D骨骼坐标 Action Classification Decoder 基于当前+预测表征进行动作分类
🔧 关键技术细节
1. Neural ODE 用于运动预测
将未来运动预测建模为初值问题 (IVP):
Zt :当前时刻的隐藏表征(初始值)
fθ :由神经网络参数化的 ODE 函数(使用 SA-GC 层)
使用 Runge-Kutta 方法求解
2. 多任务学习
同时优化两个目标:
任务 损失函数 作用 未来运动预测 Lrec (MSE) + Lfeat (表征匹配) 让模型学会预测未来骨骼轨迹 动作分类 Lcls (交叉熵) 最终的动作识别目标 3. 因果 Transformer
编码器使用因果掩码,确保模型只能关注历史帧,不能"偷看"未来,这保证了在线推理的合法性。
📊 实验结果
在三个标准数据集上测试:
NTU RGB+D 60
NTU RGB+D 120
NW-UCLA
与现有方法相比,InfoGCN++ 在在线动作识别 任务上达到同等或更优 的性能,同时具有连续实时推理的独特优势。
🏆 主要贡献
首个将 Neural ODE 应用于在线骨骼动作识别的工作------通过预测未来运动来增强部分观测下的识别能力
多任务学习框架------同时学习动作识别和未来运动预测,相互促进
真正的在线推理------每帧都能输出结果,无需等待动作结束,适用于实时应用
🔗 与你之前工作的关联
你之前关注过 NTU RGB+D 骨骼提取 和 MMAction2 格式转换,这篇论文正好是该领域的最新进展。如果你在做在线动作识别或实时系统,InfoGCN++ 的方法论非常值得参考------特别是它用 Neural ODE 做运动预测的思路,可以迁移到其他需要实时预测的场景。
一句话总结:InfoGCN++ 通过"预测未来"来解决骨骼动作识别的实时性问题,用 Neural ODE 建模运动演化,实现了真正的在线、逐帧动作识别。
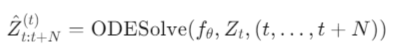
三、InfoGCN++与SimpliHuMoN
你觉得InfoGCN++的动作预测跟SimpliHuMoN的区别和联系是什么?哪个做动作预测做的更好?
这两篇论文虽然都涉及"人体运动预测",但目标、场景和任务定义完全不同。下面从多个维度进行对比分析:
📊 核心区别一览
维度 InfoGCN++ (2023) SimpliHuMoN (2026) 核心任务 在线动作识别 (Action Recognition) 人体运动预测 (Motion Prediction) 输入 当前+历史骨骼序列(部分观测) 历史骨骼序列(完整观测窗口) 输出 动作类别标签 (如"踢腿"、"走路") 未来3D骨骼坐标 (具体姿态+轨迹) 预测目的 辅助分类------通过预测未来来更好识别当前动作 直接生成------预测未来具体运动 应用场景 实时监控系统、人机交互、AR/VR 自动驾驶、机器人规划、体育分析 数据集 NTU RGB+D 60/120, NW-UCLA Human3.6M, AMASS, ETH-UCY, 3DPW 评估指标 分类准确率 (Top-1/Top-5 Accuracy) 位移误差 (ADE/FDE, APE/JPE) 多模态 单一路径预测 K个多样化未来假设
🔍 详细对比
1. 任务本质不同
InfoGCN++ 的"预测"是手段,不是目的:
它预测未来骨骼运动的潜在表征(latent representation)
目的是让模型在只看到动作前30%时,就能判断"这是踢腿"
预测结果不直接输出骨骼坐标,只用于增强分类能力
SimpliHuMoN 的"预测"就是目的:
它直接输出未来每一帧的具体3D关节坐标
要回答的问题是:"这个人接下来2秒会走到哪里、摆出什么姿势?"
输出是可渲染的骨骼动画,不是类别标签
2. 技术路线对比
技术点 InfoGCN++ SimpliHuMoN 核心模块 Neural ODE + SA-GC + 因果Transformer 纯Transformer Decoder 时间建模 Neural ODE 建模连续潜在流 自注意力建模离散时序 空间建模 自注意力图卷积 (SA-GC) 隐式通过注意力学习 多任务 分类 + 预测(辅助) 单一预测任务 不确定性 确定性预测 多模态输出 (K个假设) 架构复杂度 较复杂(多组件耦合) 极简(纯Transformer堆叠) 3. 架构设计哲学
InfoGCN++ 是"专用架构":
继承 InfoGCN 的骨骼图卷积先验
引入 Neural ODE 的物理动机(连续运动演化)
为骨骼数据量身定制
SimpliHuMoN 是"通用极简":
去掉所有领域特定设计(不用GCN、不用DCT、不用扩散模型)
证明"简单Transformer + 注意力"就能做好
同一模型无缝切换:轨迹预测、姿态预测、联合预测
🏆 "哪个做动作预测更好?"
这个问题需要拆解,因为它们预测的"东西"不同:
场景一:你需要"识别现在正在做什么"
→ InfoGCN++ 更好
它是唯一设计用于在线分类的
SimpliHuMoN 根本不输出动作类别
在 NTU 数据集上,InfoGCN++ 能在动作进行到一半时就准确判断类别
场景二:你需要"预测接下来具体怎么动"
→ SimpliHuMoN 更好
直接输出未来骨骼坐标,误差指标(ADE/FDE)上达到SOTA
支持多模态预测(K=6个可能的未来),捕捉运动不确定性
计算效率更高(比EMPMP快1.8倍)
场景三:你需要"既识别又预测"
→ 可以组合使用
用 InfoGCN++ 做实时动作识别
用 SimpliHuMoN 做未来运动生成
两者是互补关系,不是竞争关系
🔗 深层联系
尽管任务不同,两篇论文共享一些思想:
共同点 说明 Transformer 时序建模 都用自注意力处理时间维度 骨骼数据表征 都处理3D人体关节坐标 端到端学习 都避免复杂的多阶段流水线 关注实时性 都强调计算效率(在线推理/高吞吐)
💡 总结
InfoGCN++ 是"用预测辅助识别",SimpliHuMoN 是"直接预测未来运动"。
你的需求 选择 实时监控中判断"他在做什么" InfoGCN++ 自动驾驶中预测"行人接下来会怎么走" SimpliHuMoN 机器人需要预判人类意图并规划动作 两者结合 两篇论文代表了人体运动理解的两个互补方向:感知(Recognition) vs 预测(Forecasting)。SimpliHuMoN 在"预测未来运动"这个子任务上确实更专业、更强大,但它无法替代 InfoGCN++ 在实时分类场景中的价值。
四、与GRPO结合的可能性
你觉得它们各自跟GRPO算法的区别和联系是什么?在什么情况下可能跟GRPO算法结合使用?结合使用后能发挥什么作用?哪个更有利于结合?
一、三者核心定位对比
维度 InfoGCN++ SimpliHuMoN GRPO 本质 在线骨架动作识别模型(图神经网络) 人体运动预测模型(Transformer) 强化学习优化算法(策略优化) 输入 部分观测的3D骨架序列 历史运动轨迹/姿态(可单独或联合) 任务提示/状态(通用) 输出 动作类别 + 未来运动预测 K个未来运动提案(轨迹+姿态) 策略更新方向(相对优势) 核心机制 Neural ODE + Transformer编码器 + SA-GC图卷积 自注意力堆叠,统一处理空间/时间依赖 组内相对优势估计 + 无critic网络 优化目标 多任务学习:分类损失 + 运动预测MSE损失 多模态未来运动生成(不确定性建模) 最大化组内相对奖励,保持与参考策略的KL散度 应用领域 实时动作识别、人机交互 自动驾驶、机器人规划、动画生成 LLM对齐、多智能体通信、视觉生成
二、与GRPO的区别与联系
1. InfoGCN++ vs GRPO
区别:
范式差异 :InfoGCN++ 是监督学习 框架,通过多任务损失(分类+预测)直接优化;GRPO 是强化学习算法,通过采样-评估-更新的循环优化策略
数据利用:InfoGCN++ 需要成对的(骨架序列,动作标签)数据;GRPO 只需要可验证的奖励信号(如答案正确性、任务完成度)
输出性质 :InfoGCN++ 输出确定性预测;GRPO 优化的是概率策略,输出动作分布
联系:
InfoGCN++ 的未来运动预测头可被视为一种"策略",生成未来帧的提案
两者都涉及多任务/多目标优化:InfoGCN++ 联合优化识别与预测;GRPO 通过组采样隐式探索多样性
2. SimpliHuMoN vs GRPO
区别:
生成模式 :SimpliHuMoN 生成 K个确定性提案 表示运动不确定性;GRPO 通过组采样探索策略空间,本质也是生成多个候选但用于相对评估
学习信号:SimpliHuMoN 使用监督的MSE/距离损失;GRPO 使用相对奖励优势,无需绝对价值估计
架构:SimpliHuMoN 是端到端Transformer;GRPO 是通用优化框架,可套在任何可微策略上
联系:
SimpliHuMoN 的 K个提案机制 与 GRPO 的 G个组采样 理念相通:都是通过多样性采样捕捉不确定性
两者都关注时间序列决策:SimpliHuMoN 预测未来运动;GRPO 可优化序列生成(如代码、推理链)
三、结合使用场景与方式
场景1:基于GRPO优化SimpliHuMoN的运动生成质量
何时结合:
当运动预测需要超越MSE的复杂目标时(如物理合理性、风格一致性、任务完成度)
当需要自适应多样性:SimpliHuMoN的K个提案可通过GRPO评估,保留高质量提案、抑制低质量提案
结合方式:
SimpliHuMoN生成K个未来运动提案 → 环境/物理引擎/下游任务评估奖励 → GRPO计算组内相对优势 → 更新SimpliHuMoN参数(替代原始MSE损失)发挥作用:
消除MSE的均值回归问题 :GRPO可学习生成高奖励但非平均的运动(如竞技体育中的最优轨迹)
引入可验证奖励:如"是否成功避开障碍物"比"与真值的L2距离"更有指导意义
自动调整多样性:GRPO的组内比较自然适配SimpliHuMoN的K提案结构
场景2:基于GRPO优化InfoGCN++的在线决策策略
何时结合:
当动作识别需要主动感知策略(如机器人决定何时/如何调整视角以获得更好骨架观测)
当InfoGCN++作为更大智能体系统的感知模块,需要与决策层联合优化
结合方式:
智能体根据当前信念状态选择观测动作(如摄像头移动) → InfoGCN++从部分观测识别动作并预测未来 → 环境给出任务级奖励(如交互成功率) → GRPO优化整个感知-决策联合策略发挥作用:
端到端优化:避免InfoGCN++的识别准确率与下游任务奖励不匹配
主动学习:GRPO可训练智能体选择最有信息量的观测时机,InfoGCN++提供状态表征
场景3:多智能体/人机协作中的通信拓扑学习
已有先例:Graph-GRPO 已将GRPO用于优化LLM多智能体的通信图拓扑。
https://arxiv.org/abs/2603.02701
类似地:
InfoGCN++ + GRPO:
将人体骨架的关节拓扑视为可学习的通信图
GRPO优化"哪些关节连接对识别当前动作最关键"
SimpliHuMoN + GRPO:
- 在多智能体运动预测中,GRPO优化智能体间的注意力权重(谁应该关注谁的运动意图)
四、哪个更有利于结合?
SimpliHuMoN更有利于与GRPO结合,理由如下:
因素 SimpliHuMoN InfoGCN++ 输出结构 天然生成 K个候选提案 ,与GRPO的组采样G个响应结构完美对齐 输出单一分类结果+预测,需改造才能产生多样候选 不确定性建模 显式建模运动不确定性,GRPO的相对评估可直接比较"哪个提案更好" 预测未来帧是确定性回归,缺乏内在多样性机制 奖励适配性 运动预测的奖励可来自物理模拟/下游任务,天然适合RL 动作识别的奖励通常是离散正确率,稀疏且延迟 架构兼容性 TransformerDecoder可无缝接入策略梯度,保留自回归特性 GCN+NeuralODE的结构对策略梯度更新更敏感 训练稳定性 自注意力机制对梯度更新更鲁棒;GRPO的clip机制提供额外保护 图卷积的邻接矩阵学习在RL探索中可能不稳定 具体优势分析:
结构同构性:SimpliHuMoN的"K个提案" = GRPO的"G个组采样",无需修改架构即可接入。InfoGCN++需要额外添加采样头或变分推断层才能产生多样候选。
连续动作空间 :GRPO最初为离散文本生成设计,但已扩展到连续控制(如流体天线位置优化https://arxiv.org/abs/2601.13506)。SimpliHuMoN的3D运动生成是连续空间,与GRPO的扩展方向一致。
多模态统一:SimpliHuMoN可处理轨迹、姿态或联合输入,GRPO可分别对不同模态的奖励进行组内归一化,实现细粒度信用分配。
实时性匹配:SimpliHuMoN是离线预测模型,GRPO的训练开销主要在前向采样,两者在部署-训练节奏上兼容。InfoGCN++强调18ms实时推理,GRPO的组采样会引入延迟,破坏实时性承诺。
五、结合后的潜在挑战
挑战 说明 奖励设计 人体运动的"好/坏"定义复杂,需设计可自动验证的奖励(如物理约束、关节限制) 模式崩溃 GRPO可能导致SimpliHuMoN的K个提案趋同,丧失多样性,需配合熵正则化 长程依赖 运动预测的长序列与GRPO的信用分配冲突,可借鉴WS-GRPO https://arxiv.org/abs/2602.17025 或过程奖励模型 参考策略漂移 运动生成需保持与真实人体运动分布的KL约束,避免生成不自然动作
结论
SimpliHuMoN与GRPO的结合更具天然优势 :两者在"多候选采样-相对评估"的结构上高度同构,SimpliHuMoN的Transformer架构对策略梯度更友好,且运动预测任务更容易定义可验证的强化学习奖励。结合后可实现从模仿学习到偏好优化的跃迁,使运动生成不仅"像真",而且"更优"。
InfoGCN++与GRPO的结合更适合感知-决策闭环场景,但需克服实时性约束和图结构稳定性问题,更适合作为更大智能体系统的子模块而非独立结合。
五、与GRPO结合能做什么
你的意思是SimpliHuMoN与GRPO的结合可以帮助SimpliHuMoN选择到更好的动作预测,使得它的动作预测更准?我没理解你说的那句"结合后可实现从模仿学习到偏好优化的跃迁,使运动生成不仅"像真",而且"更优"。还有为什么你说InfoGCN++与GRPO的结合更适合感知-决策闭环场景?我没理解InfoGCN++与GRPO的结合能做什么?
一、SimpliHuMoN + GRPO:从"模仿真值"到"追求最优"
先理解SimpliHuMoN原本的局限
SimpliHuMoN现在的训练方式(监督学习):
输入:过去2秒的运动轨迹 输出:K个未来2秒的预测提案 训练目标:让这K个提案尽可能"接近"数据集里的真值轨迹 损失函数:MSE(均方误差)= 预测轨迹与真值轨迹的L2距离问题出在哪?
假设你在训练一个投篮动作预测模型:
真值数据 问题 业余球员的投篮轨迹 MSE让模型模仿"平均水平",而不是"最优水平" 各种风格的投篮(单手/双手/抛投) MSE让模型学到"四不像"的平均轨迹 包含失误的轨迹(投偏、滑倒) MSE同样强迫模型模仿这些"坏样本" 结果:模型生成的动作"像人做的",但不一定"好用"------对机器人控制来说可能效率低,对动画来说可能缺乏表现力。
结合GRPO后发生什么变化
GRPO把训练目标从"像真值"变成"拿高分":
输入:过去2秒的运动轨迹 SimpliHuMoN生成:G组(比如8组)未来运动提案 评分器给每组打分: - 物理合理性:是否违反关节限制?是否穿模? - 任务完成度:投篮是否命中?是否高效到达目标? - 风格一致性:是否符合指定风格(如"优雅"/"爆发性")? GRPO计算:这组8个提案中,哪个相对更好? 更新方向:多生成高分的,少生成低分的关键区别:
监督学习(原来) GRPO(结合后) 学习目标 模仿数据集中的"平均真值" 优化自定义的"奖励函数" 对坏样本的处理 被迫模仿 自动识别并避免 对多样性的利用 K个提案都学同一个平均 K个提案探索不同策略,保留最优 结果 "像真"(类似训练数据) "更优"(符合任务需求) 具体例子:
假设你要训练一个辅助康复的外骨骼预测人的下一步动作:
只用SimpliHuMoN:预测出"普通人走路的平均水平",但康复患者步态异常,模型预测不准
SimpliHuMoN + GRPO :奖励函数定义为"预测轨迹与实际轨迹的误差小 + 预测提前量足够外骨骼准备 + 不预测危险动作",模型学会针对康复场景优化,而不是模仿普通步态
二、InfoGCN++ + GRPO:感知-决策闭环是什么意思
先理解InfoGCN++原本的能力边界
InfoGCN++是一个被动的识别器:
输入:摄像头看到的部分骨架(可能遮挡、可能角度不好) 输出: 1. 当前动作类别(如"挥手") 2. 未来几帧的骨架预测(辅助识别) 特点:18ms实时,但"给什么看什么",不会主动改变观测局限场景:
想象一个服务机器人需要识别老人是否"摔倒":
情况 InfoGCN++的问题 老人被沙发挡住半边身体 骨架不完整,识别准确率暴跌 摄像头从侧面拍,看不到躯干倾斜 无法判断是"弯腰捡东西"还是"失去平衡" 光线暗,关节点检测噪声大 预测未来运动不可靠 InfoGCN++本身无法解决这些问题------它只能"尽力从当前不好的输入中猜出答案"。
结合GRPO后:机器人学会"主动看"
GRPO在这里优化的不是InfoGCN++本身,而是使用InfoGCN++的决策策略:
状态:当前摄像头画面 + InfoGCN++的识别置信度 动作空间(GRPO优化): - 摄像头向左转15° - 摄像头向右转15° - 摄像头走近2米 - 等待0.5秒(看动作发展) - 启动备用传感器(如雷达) 执行动作 → 获得新的观测 → InfoGCN++重新识别 → 环境给奖励 奖励设计: +10:正确识别"摔倒"并触发警报 +5:正确识别"正常活动",避免误报 -5:识别错误 -1:每多走一步/每多等一秒(效率惩罚)这就是"感知-决策闭环":
┌─────────────┐ 控制 ┌─────────────┐ │ 决策模块 │ ─────────────→ │ 传感器 │ │ (GRPO优化) │ │ (摄像头等) │ └─────────────┘ └─────────────┘ ↑ ↓ └──────────────────────────────┘ InfoGCN++识别结果 + 奖励信号具体例子:
场景 没有GRPO 有GRPO 老人部分被遮挡 机器人直接猜测,可能误报 机器人主动移动获得更好视角,再判断 动作模糊(伸懒腰 vs 举手求救) 基于单帧硬猜 机器人等待0.5秒看后续发展,再决定 夜间低光照 骨架噪声大,识别随机 机器人切换红外传感器,用更适合的输入 关键洞察 :GRPO不直接修改InfoGCN++的识别能力,而是训练一个"摄影师"策略,知道什么时候该移动、等待、切换传感器,让InfoGCN++始终在"好条件"下工作。
三、为什么InfoGCN++不适合直接+GRPO做"识别优化"
你可能想问:为什么不能像SimpliHuMoN那样,直接用GRPO优化InfoGCN++的识别准确率?
障碍 解释 输出是离散分类 InfoGCN++输出"动作类别"(如1000个类),GRPO的组采样需要比较"哪个输出更好",但分类结果是互斥的,难以直接比较 奖励极其稀疏 识别对了=1,错了=0,没有中间梯度。GRPO需要组内相对优势,但"对/错"二元信号太粗糙 实时性被破坏 InfoGCN++的核心卖点是18ms实时。GRPO需要采样多组、评估、更新,训练时可行,但推理时无法"试多个摄像头角度再决定" 图结构不稳定 InfoGCN++的GCN依赖骨架拓扑,GRPO的探索性更新可能破坏图卷积的邻接矩阵学习 对比SimpliHuMoN的优势:
SimpliHuMoN InfoGCN++ 输出 K个连续轨迹(可直接比较哪个更平滑/更合理) 离散类别(难以比较"挥手"和"招手"哪个"更好") 评估 轨迹可以用物理引擎打分(连续奖励) 分类只能用对/错(稀疏奖励) 多样性 K个提案天然适合GRPO组采样 单一分类结果,需额外造采样 实时要求 离线预测,允许计算开销 在线识别,必须18ms内完成
四、总结对比
结合方式 本质 解决什么问题 类比 SimpliHuMoN + GRPO 用GRPO替代MSE损失,直接优化运动生成质量 动作预测"不够优"、受限于数据集平均水平 从"模仿前辈"到"追求满分" InfoGCN++ + GRPO 用GRPO训练"摄影师策略",间接提升识别条件 识别输入"不够好"、被动接受观测 从"固定机位"到"导演调度" 哪个更直接有用?
如果你要生成更好的运动 (动画、机器人控制、游戏NPC):SimpliHuMoN + GRPO 更直接,效果更显著
如果你要让识别系统更智能地获取信息 (安防机器人、辅助看护):InfoGCN++ + GRPO 有价值,但实现更复杂,且InfoGCN++只是闭环中的一个模块
这就是为什么我说SimpliHuMoN与GRPO的结合"更有利于"------它们的结构天然匹配,目标直接互补,实现路径清晰。
六、与GPRO结合的通俗理解
我用最生活化的例子来解释,你就能立刻明白哪个更迫切。
一、SimpliHuMoN + GRPO = "学走路/学动作"的能力
通俗理解:像健身教练教动作
场景1:康复机器人帮中风患者走路
阶段 发生了什么 只用SimpliHuMoN 机器人看医院里其他患者怎么走路,然后模仿"平均步态"。但患者A腿没力、患者B重心不稳,平均步态对谁都不合适,甚至可能让康复者摔倒 +GRPO之后 机器人每次尝试几种走法,看哪种让患者走得更稳、更省力、更不容易摔 。奖励就是"没摔倒+走得远+患者说不累"。慢慢学会针对这个人、这个阶段的最优步态 场景2:游戏里的NPC队友
阶段 发生了什么 只用SimpliHuMoN NPC模仿人类玩家的动作数据,遇到坑就跳、遇到门就推。但有时跳得太早撞头,推门的角度不对卡住 +GRPO之后 NPC尝试几种应对方式,发现"等0.5秒再跳"或"侧身推门"奖励更高。学会不只是模仿,而是做得更聪明 核心能力 :生成动作的质量 ------预测下一步做什么,而且做得更好、更适合当前目标。
二、InfoGCN++ + GRPO = "看准时机、找对角度观察"的能力
通俗理解:像摄影师或侦探的观察策略
场景1:家用看护机器人看老人有没有摔倒
阶段 发生了什么 只用InfoGCN++ 摄像头固定放在墙角,老人走到沙发背后时只能看到半边身子,机器人硬猜:"可能是弯腰?" 结果老人真摔了,没识别出来 +GRPO之后 机器人发现"当前画面遮挡太多,置信度低",于是主动走到侧面 、或者等1秒看后续动作 、或者启动另一个摄像头 。确保自己在看清楚之后再判断 场景2:自动驾驶看行人要不要过马路
阶段 发生了什么 只用InfoGCN++ 摄像头看到一个人站在路边,动作模糊(可能在等公交,也可能要冲出来)。系统必须立刻猜,猜错就出事 +GRPO之后 系统判断"这个动作太模糊,看不准",于是稍微减速同时观察0.5秒 ,看到行人脚尖转向马路才确认"他要过马路"。用时间换准确性 核心能力 :观察策略的质量 ------不是"看什么",而是**"怎么看、什么时候看、从哪看"**。
三、对人类/机器人来说,哪个更迫切?
直接给结论:SimpliHuMoN + GRPO(学动作)更迫切
为什么?看人类进化顺序
能力 人类什么时候学会的 多基础/多迫切 生成动作(走路、抓握、躲避) 婴儿0-2岁,不学就会死 生存级基础 策略性观察(找角度、等时机) 猎人数年经验,智者晚年才精通 高级认知 机器人同理:
需求层级 对应能力 紧迫性 先能活/能干活 生成合理的动作,别把自己摔了,别撞到人 必须先解决 再干得好 动作更优、更省能、更自然 重要,但排第二 最后干得聪明 观察策略优化,知道什么时候该多看一眼 锦上添花 具体场景对比
假设你要造一个"机器人护工"照顾老人:
优先级 问题 需要哪个能力 P0(没有就不可用) 机器人扶老人起身时,手怎么放、劲怎么使,别把人胳膊拽脱臼 SimpliHuMoN + GRPO P1(体验差) 扶人的动作生硬,老人不舒服 SimpliHuMoN + GRPO 优化得更柔 P2(偶尔失误) 老人在卧室角落摔倒,摄像头被柜子挡住半边,没识别到 InfoGCN++ + GRPO 让机器人走进去看 P3(高级功能) 机器人预判老人"可能要摔",提前站在旁边准备扶 两者都需要 没有P0,机器人根本不敢用。P2/P3是"更好用",不是"能用"。
四、一个更扎心的现实
问题 现状 "生成动作"做得好吗? 很差 。现在的机器人走路像丧尸,机械臂抓鸡蛋会碎,辅助康复外骨骼步伐僵硬。这是卡脖子问题 "观察策略"做得好吗? 也不完美,但至少有替代方案------多装几个摄像头、用雷达补盲、让人远程监控。不是最优解,但能凑合 换句话说:
SimpliHuMoN + GRPO 解决的是**"机器人能不能像人一样动"** ------现在答案是基本不能,所以最迫切
InfoGCN++ + GRPO 解决的是**"机器人观察时能不能更聪明"** ------现在答案是勉强能,可以后面再优化