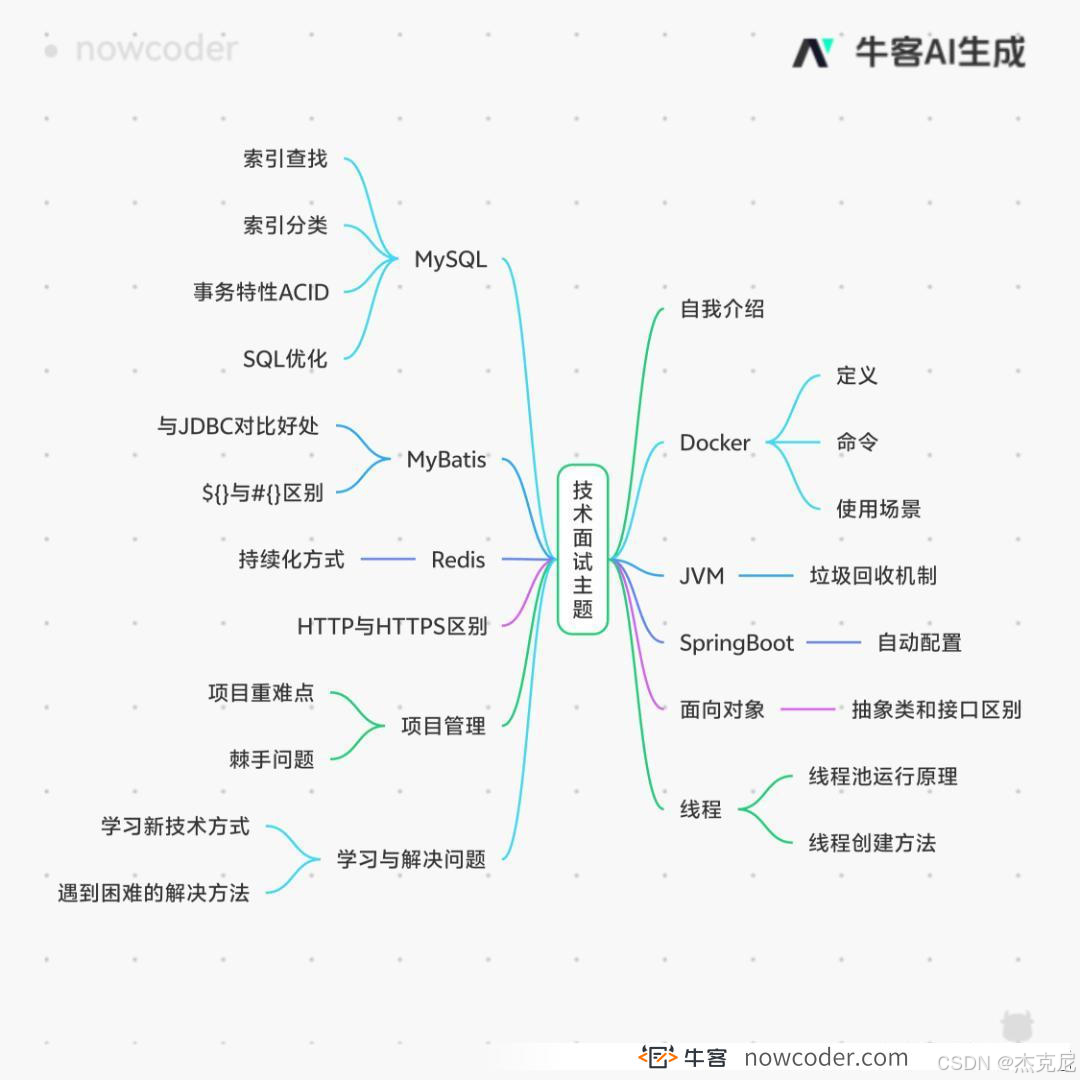
目录
[1. 自我介绍](#1. 自我介绍)
[2. 死锁的概念,如何避免死锁?](#2. 死锁的概念,如何避免死锁?)
[3. 单链表如何找到中间节点?如何找到倒数第K个节点?](#3. 单链表如何找到中间节点?如何找到倒数第K个节点?)
[4. JWT令牌与Cookie+Session的区别,为什么使用JWT?](#4. JWT令牌与Cookie+Session的区别,为什么使用JWT?)
[5Docker 是什么、命令、使用场景、部署](#5Docker 是什么、命令、使用场景、部署)
[6JVM 垃圾回收机制](#6JVM 垃圾回收机制)
[8 MySQL 索引怎么查找数据|索引的作用?](#8 MySQL 索引怎么查找数据|索引的作用?)
[9SpringBoot 自动配置](#9SpringBoot 自动配置)
[12MySQL 索引分类](#12MySQL 索引分类)
[13MySQL 事务 ACID](#13MySQL 事务 ACID)
[14SQL 优化](#14SQL 优化)
[15MyBatis 比 JDBC 好处](#15MyBatis 比 JDBC 好处)
[16MyBatis ${} 和 #{} 区别](#{} 区别)
[17Redis 持久化方式](#17Redis 持久化方式)
[18HTTP 和 HTTPS 区别](#18HTTP 和 HTTPS 区别)
[1、Java 常用集合](#1、Java 常用集合)
[4、IOC & AOP 理解](#4、IOC & AOP 理解)
[6、Mybatis 二级缓存](#6、Mybatis 二级缓存)
[8、MySQL 事务如何实现](#8、MySQL 事务如何实现)
[13、单例双重检查锁 DCL](#13、单例双重检查锁 DCL)
1. 自我介绍
您好,我是张世杰,目前就读于北华航天工业学院计算机科学与技术专业。我的技术方向是Java后端开发,对分布式系统和高并发场景有浓厚兴趣。
在技术能力方面,我熟练掌握Java语言和面向对象编程,熟悉Spring、Spring Boot、MyBatis等主流框架。数据库方面熟悉MySQL的使用和优化,了解Redis缓存的应用场景。对多线程编程、JVM原理、网络编程有一定理解。
项目经验方面,我做过电商平台、同城拼车等项目。在电商平台项目中,我负责核心交易流程的设计和实现,包括商品库存管理、订单创建与支付对接等。通过Redis缓存热点商品数据、异步处理订单履约及消息通知,优化了系统性能,支持每秒上千次的订单请求,保障了大促期间系统的稳定性和高并发处理能力。
我的学习能力比较强,善于通过阅读源码和实践来深入理解技术。平时会关注开源社区,学习优秀项目的设计思想。我对技术充满热情,希望能加入贵公司,在实际项目中不断提升自己,为团队创造价值。
2. 死锁的概念,如何避免死锁?
死锁的定义:
死锁是指两个或多个线程互相持有对方需要的资源,导致所有线程都无法继续执行的状态。比如线程A持有资源1等待资源2,线程B持有资源2等待资源1,两个线程互相等待,永远无法继续。
死锁的四个必要条件:
互斥条件是指资源不能被多个线程同时使用,一个线程占用资源时,其他线程必须等待。
请求与保持条件是指线程已经持有至少一个资源,同时又请求新的资源,在等待新资源时不释放已有资源。
不可剥夺条件是指线程已获得的资源,在使用完之前不能被强制剥夺,只能由线程自己释放。
循环等待条件是指存在一个线程资源的循环等待链,每个线程都在等待下一个线程持有的资源。
避免死锁的方法:
第一种方法是破坏请求与保持条件。一次性申请所有需要的资源,要么全部获得,要么全部不获得。这样不会出现持有部分资源等待其他资源的情况。但这种方式资源利用率低,而且很多时候无法预知需要哪些资源。
第二种方法是破坏不可剥夺条件。当线程申请资源失败时,主动释放已持有的资源,等待一段时间后重新申请。但这种方式实现复杂,而且可能导致活锁。
第三种方法是破坏循环等待条件。给资源编号,线程必须按照固定顺序申请资源。比如规定必须先申请编号小的资源,再申请编号大的资源。这样就不会形成循环等待。这是最常用的方法。
第四种方法是使用超时机制。申请资源时设置超时时间,超时后放弃申请并释放已持有的资源。Java的tryLock方法就支持超时。
实际应用:
在实际开发中,要注意锁的申请顺序。如果多个线程都需要申请多个锁,要保证申请顺序一致。比如转账操作,从账户A转到账户B,需要同时锁定两个账户。如果一个线程先锁A再锁B,另一个线程先锁B再锁A,就可能死锁。正确的做法是按照账户ID大小排序,总是先锁ID小的账户。
使用JDK提供的并发工具类,比如ReentrantLock的tryLock方法 ,可以设置超时时间,避免无限等待。使用并发容器如ConcurrentHashMap,内部已经处理好了锁的问题,不容易出现死锁。
定期检查系统是否有死锁。可以使用jstack工具dump线程堆栈,查看是否有线程处于BLOCKED状态且互相等待。发现死锁后分析原因,调整锁的申请顺序。
3. 单链表如何找到中间节点?如何找到倒数第K个节点?
找中间节点:
使用快慢指针法。定义两个指针,快指针每次移动两步,慢指针每次移动一步。当快指针到达链表末尾时,慢指针正好在中间位置。
如果链表有奇数个节点,慢指针指向中间节点。如果有偶数个节点,慢指针指向中间两个节点的第一个。如果要返回第二个中间节点,可以让快指针初始指向head.next。
这个方法的时间复杂度是O(n),空间复杂度是O(1),只需要遍历一次链表。
找倒数第K个节点:
也使用双指针法。让第一个指针先走K步,然后两个指针同时移动。当第一个指针到达末尾时,第二个指针正好在倒数第K个位置。
要注意边界情况。如果K大于链表长度,第一个指针会走到null,这时要返回null或抛出异常。如果K等于链表长度,返回头节点。
这个方法的时间复杂度也是O(n),空间复杂度是O(1),只需要遍历一次链表。
给定节点找前一个节点:
单链表只能从前往后遍历,无法直接找到前一个节点。需要从头节点开始遍历,找到next指向给定节点的节点。
如果给定的是头节点,没有前一个节点,返回null。如果给定节点不在链表中,也返回null。
这个方法的时间复杂度是O(n),需要遍历链表。如果需要频繁查找前一个节点,可以使用双向链表,每个节点有prev指针指向前一个节点,这样查找前一个节点的时间复杂度是O(1)。
实际应用:
这些算法在实际开发中很有用。比如LRU缓存的实现,需要快速找到链表中间节点进行淘汰。比如链表的删除操作,需要找到待删除节点的前一个节点,修改它的next指针。
掌握这些基础算法,可以更好地理解和使用链表数据结构,在面试和实际工作中都很重要。
4. JWT令牌与Cookie+Session的区别,为什么使用JWT?
Cookie+Session机制:
传统的认证方式是Cookie+Session。用户登录后,服务器创建Session对象存储用户信息,生成Session ID返回给客户端。客户端把Session ID保存在Cookie中,后续请求都带上这个Cookie。服务器根据Session ID从Session存储中获取用户信息。
这种方式的缺点是服务器需要存储Session,占用内存。在分布式系统中,Session需要共享,要么使用Session复制,要么使用集中式Session存储如Redis。而且Cookie不能跨域,移动端APP无法使用Cookie。
JWT机制:
JWT是JSON Web Token的缩写,是一种无状态的认证方式。用户登录后,服务器生成JWT令牌返回给客户端。JWT包含用户信息和签名,客户端保存JWT,后续请求在Header中携带JWT。服务器验证JWT的签名,解析出用户信息。
JWT由三部分组成,用点号分隔。Header包含令牌类型和签名算法。Payload包含用户信息和过期时间等声明。Signature是对Header和Payload的签名,防止篡改。
JWT的优点:
第一是无状态,服务器不需要存储Session,节省内存。特别适合分布式系统和微服务架构,不需要Session共享。
第二是跨域支持好。JWT可以放在HTTP Header中,不受Cookie跨域限制。移动端APP可以方便地使用JWT。
第三是性能好。不需要每次请求都查询Session存储,只需要验证签名和解析JWT,速度更快。
第四是扩展性好。JWT的Payload可以包含任意信息,比如用户角色、权限等,不需要额外查询数据库。
JWT的缺点:
第一是无法主动失效。JWT一旦签发,在过期前一直有效,无法主动撤销。如果用户退出登录或修改密码,旧的JWT仍然可以使用。解决办法是设置较短的过期时间,或者维护一个黑名单。
第二是JWT体积大。JWT包含用户信息,比Session ID大很多,每次请求都要传输,增加网络开销。
第三是安全性问题。JWT的Payload是Base64编码,不是加密,任何人都可以解码看到内容。所以不能在JWT中存储敏感信息。而且如果密钥泄露,攻击者可以伪造JWT。
使用场景:
对于单体应用,Session方式更简单。对于分布式系统、微服务架构、移动端APP,JWT更合适。
在实际项目中,我使用JWT实现认证。用户登录后生成JWT,设置2小时过期。同时生成Refresh Token,设置7天过期。JWT过期后,用Refresh Token换取新的JWT,实现无感刷新。这样既保证了安全性,又提供了良好的用户体验。
5Docker 是什么、命令、使用场景、部署
Docker:轻量级容器引擎,把应用 + 环境打包,一次构建到处运行。
常用命令:
docker pull 拉镜像
docker run 运行容器
docker ps 查看运行中容器
docker build 构建镜像
docker logs 查看日志
使用场景:统一开发 / 测试 / 生产环境、微服务部署、快速扩容。
部署流程:写 Dockerfile → 构建镜像 → 运行容器 → 映射端口 / 挂载目录。
6JVM 垃圾回收机制
垃圾回收就是JVM自动回收不再使用的堆内存对象避免内存溢出。
判断对象死亡:可达性分析(GC Roots 不可达即回收)。
分代回收:
新生代:对象存活短,用复制算法。
老年代:对象存活久,用标记整理 / 标记清除。
常见回收器:Serial、Parallel、CMS、G1。
现在主流用的是G1
7抽象类和接口区别
- 定义修饰
抽象类 :
abstract class接口 :
interface
- 构造方法
抽象类有构造方法,用于子类初始化
接口没有构造方法,不能实例化
- 继承数量
抽象类:单继承,一个类只能继承一个抽象类,使用extends关键字
接口:多实现,一个类可以实现多个接口,使用interface关键字
- 静态代码块
抽象类:可以有静态代码块
接口:不能有静态代码块
8 MySQL 索引怎么查找数据|索引的作用?
MySQL 索引底层是B + 树 ,查询时从根节点逐层二分查找,快速定位叶子节点。主键索引叶子存整行数据,查到直接返回;普通索引叶子只存主键,需要回表查询 完整数据。联合索引必须满足最左前缀匹配,才能正常走索引。

9SpringBoot 自动配置
Spring Boot 的自动配置主要基于 @EnableAutoConfiguration 注解。它通过 SpringFactoriesLoader 加载 META-INF/spring.factories 文件中定义的自动配置类。每个自动配置类都会通过 @Conditional 系列注解来判断是否满足条件,只有满足条件时才会生效。比如 @ConditionalOnClass 会检查类路径中是否存在特定的类,@ConditionalOnMissingBean 会检查容器中是否已经存在特定的 Bean。
10线程池运行原理
- 先检查线程池状态,不是运行状态,直接拒绝任务
- 当前工作线程 < 核心线程数 → 新建核心线程执行任务
- 核心线程已满,但阻塞队列没满 → 任务放进队列排队
- 队列也满了,但总线程还没到上限 → 新建非核心救急线程执行任务
- 线程拉满、队列也满 → 触发拒绝策略,默认直接抛出异常
11线程创建方法
继承 Thread
实现 Runnable
实现 Callable(带返回值)
线程池创建(推荐)
12MySQL 索引分类
主键索引、唯一索引、普通索引、联合索引、聚簇索引、二级索引。
13MySQL 事务 ACID
A 原子性:要么全成功,要么全失败。
C 一致性:事务前后数据合法。
I 隔离性:事务之间互不干扰。
D 持久性:提交后永久生效。
14SQL 优化
建立合适索引,避免全表扫描。
避免
select *、避免索引失效(函数、隐式转换、or)。大表分页用延迟关联。
合理分库分表。
用 explain 分析执行计划。
15MyBatis 比 JDBC 好处
简化 JDBC 样板代码。易操作
SQL 与代码分离,易维护。
自动结果集映射。
支持缓存、动态 SQL、插件。
16MyBatis ${} 和 #{} 区别
#{}:预编译,防 SQL 注入,参数用?占位。
${}:字符串直接拼接,不防注入,用于表名 / 字段名动态传入。
17Redis 持久化方式
RDB:定时快照,文件小、恢复快,可能丢数据。
AOF:记录每一条写命令,实时性高,文件大。
混合持久化(推荐):RDB+AOF 结合。
18HTTP 和 HTTPS 区别
HTTP 明文传输,不安全,端口 80。
HTTPS 加密传输,SSL/TLS 证书,端口 443,防窃听 / 篡改。
19介绍项目重难点?
订单并发重复下单、超卖问题 用Redis 分布式锁保证同一用户同一时间只能创建一笔有效订单,防止并发脏数据。
Redis 缓存穿透、击穿、雪崩问题空值缓存、布隆过滤器、过期时间随机打散、多级缓存降级保护。
订单超时未支付自动取消 采用 RabbitMQ死信队列,延迟消息处理超时订单,自动回滚库存、恢复菜品状态。
用户登录身份安全 & 接口权限控制JWT 令牌登录校验,拦截器统一鉴权,刷新令牌有效期,防止越权访问。
分布式环境下事务一致性 订单创建、扣减库存、状态变更多表操作,使用 Seata 保证分布式事务最终一致性。
高并发场景下单接口压力大异步处理通知、短信推送、状态更新,同步只处理核心下单逻辑,提升接口吞吐量。
21怎么学习新技术?
我会去网站上找对应的课程进行系统学习,如果课程学习质量不好我会去看官方文档,最后尝试做一些题和代码进行巩固
22js和java有什么异同点?
语法结构很像,都支持面向对象思想
- 语言类型
Java :强类型、静态编译语言定义变量必须声明类型
int a = 1;JS :弱类型、动态解释语言不用写类型
let a = 1;,变量类型随时变
- 运行平台
Java:运行在JVM 虚拟机,后端服务器
JS:运行在浏览器内核 / Node.js,前端页面
- 面向对象方式
Java:类 class 先定义类,再 new 对象
JS:原型链 prototype,基于原型继承
- 线程 & 并发
Java:多线程、线程池、并发安全、JVM 垃圾回收
JS:单线程,事件循环 EventLoop,没有多线程并发
- 用途
Java:后端开发、微服务、数据库、业务逻辑
JS:网页交互、前端页面、Ajax 请求、浏览器特效
23跨域是怎么解决的?
2.Nginx 反向代理跨域
Nginx 把前端请求转发到后端,浏览器只和 Nginx 同源,不跨域。
- 后端网关 Gateway 统一配置跨域
微服务项目,网关一层配置 CORS,所有服务不用单独配置。
24设计数据库了吗?
先梳理业务需求,把用户、菜品、订单、地址、分类这些核心实体全部拆出来
遵循三大范式设计表,尽量减少数据冗余,避免重复字段
理清表之间关系:一对一、一对多、多对多,合理建立外键关联逻辑
高频查询字段提前建立合适索引,优化订单、菜品查询速度
考虑业务并发,订单表、用户表做好字段类型规范,预留扩展字段
加上创建时间、更新时间、逻辑删除字段,方便后续维护和数据追溯
25数据结构里面常用的排序算法以及各自的时间复杂度?
- 冒泡排序
最好:O (n)
最坏 / 平均:O(n²)
稳定排序
- 选择排序
最好 / 最坏 / 平均:O(n²)
不稳定
- 插入排序
最好:O (n)
最坏 / 平均:O(n²)
稳定
- 快速排序(最快常用)
最好 / 平均:O(nlogn)
最坏:O (n²)
不稳定
- 归并排序
最好 / 最坏 / 平均:O(nlogn)
稳定
- 堆排序
最好 / 最坏 / 平均:O(nlogn)
不稳定
26进制的转换?
- 十进制 → 二进制:除 2 取余,逆序排列
- 二进制 → 十进制:按位权展开相加
27计算机网络TCP的三次握手和四次挥手?
三、TCP 三次握手(建立连接)
客户端发送 SYN 报文,请求连接,进入 SYN_SENT
服务器收到,回复 SYN+ACK 报文,同意连接,进入 SYN_RCVD
客户端收到,回复 ACK 报文,双方进入 ESTABLISHED,连接成功
四、TCP 四次挥手(断开连接)
客户端发 FIN,请求关闭写通道
服务器 ACK 确认,先把剩余数据传完
服务器发 FIN,关闭自己写通道
客户端 ACK 确认,等待超时,连接彻底断开
1、Java 常用集合
- List:ArrayList(数组,查询快增删慢)、LinkedList(链表,增删快查询慢)
- Set:HashSet(无序不重复)、TreeSet(有序)
- Map:HashMap(键值无序)、TreeMap(键有序)、ConcurrentHashMap(线程安全)
- 区别:List 有序可重复,Set 无序不可重复,Map 键唯一键值对存储
2、集合遍历方式
- 普通 for 循环
- 增强 for 循环
- 迭代器 Iterator
- Lambda 表达式 forEach 遍历
3、线程池
核心 5 参数:核心线程数、最大线程数、空闲线程存活时间、阻塞队列、拒绝策略执行流程:核心线程→队列→非核心线程→拒绝策略好处:复用线程、降低开销、控制并发、避免频繁创建销毁线程
4、IOC & AOP 理解
- IOC:控制反转,把对象创建、交给 Spring 容器管理,不用 new 对象,解耦
- AOP:面向切面编程,不修改原有代码,动态增强方法比如统一日志、事务、权限校验
5、循环依赖
Spring 单例 Bean 互相注入,A 依赖 B,B 依赖 A,造成死循环Spring 用三级缓存解决单例 setter 循环依赖构造器循环依赖无法解决
6、Mybatis 二级缓存
- 一级缓存:SqlSession 级别,默认开启,会话关闭失效
- 二级缓存:Mapper 映射级别,跨 SqlSession 共享,多事务会脏数据,一般不建议开启
8、MySQL 事务如何实现
基于UndoLog 重做日志、RedoLog 回滚日志MVCC 多版本并发控制,保证 ACID 四大特性:原子、一致、隔离、持久
13、单例双重检查锁 DCL
- 第一次判锁:不用每次都加锁,提高效率
- 加 volatile:禁止指令重排序,避免半初始化对象
- 第二次判锁:防止多线程并发重复创建实例
16、Dockerfile
构建镜像脚本文件,指令:FROM 基础镜像、ADD 拷贝文件、RUN 执行命令、EXPOSE 端口、CMD 容器启动命令
1、雪花算法是什么怎么做?
64 位 Long 型 ID,分段组成:
- 符号位:1 位,固定 0
- 时间戳:41 位,毫秒时间,自增
- 机器 ID:10 位,区分分布式多台服务器
- 序列号:12 位,同一毫秒内自增序号
特点:全局唯一、有序递增、分布式不重复、性能极高
2、不用雪花算法行不行?当然可以,有替代方案
不用雪花,可以用这些:
-
MySQL 主键自增 单节点好用,简单方便缺点:分布式多库多表会重复 ID,无法水平扩容
-
UUID 全局唯一缺点:无序杂乱、字符串长、B + 树索引性能极差,不适合做主键
-
Redis 自增 INCR分布式全局唯一 ID缺点:依赖 Redis 持久化,宕机丢号、序号不连续
前端使用vue用了哪些API
一、核心常用 API
生命周期钩子
onMounted挂载、onUpdated更新、onUnmounted销毁页面初始化请求数据、定时器销毁都用这个路由 API
router.push跳转页面useRoute获取路由参数、路径useRouter编程式导航组件通信
props父传子emit子传父provide / inject祖孙跨层级传值
响应式 API(Vue3)
ref基本类型响应式reactive对象数组响应式watch监听数据变化computed计算属性网络请求 API 封装Axios请求请求拦截器统一加 JWT 令牌响应拦截器统一处理异常、跨域
Pinia 状态管理
defineStore定义仓库存取、修改全局共享数据(用户信息、订单状态)
毕业实习学了什么?
学习项目整体业务流程,从需求分析、数据库设计、接口开发到前后端联调完整开发流程
末尾页:
本文主要涵盖了计算机技术相关的多个核心知识点,包括自我介绍、技术概念解析和实际应用场景。首先介绍了个人背景和技术专长,重点提及Java后端开发能力及分布式系统经验。随后详细解释了死锁的概念及四种避免方法,单链表查找节点的双指针算法,以及JWT与Session的认证机制对比。在数据库方面,涉及MySQL索引原理、事务ACID特性及SQL优化策略。此外还包含Docker基础、JVM垃圾回收、SpringBoot自动配置等系统知识,以及HTTP/HTTPS区别、Redis持久化等网络与缓存技术。最后总结了数据结构