1.文档概述
本文档旨在详细说明基于图片所示架构的车辆远程信息处理(Telematics Service Platform, TSP)数据处理平台。该平台是一个典型的、基于现代大数据技术的实时数据管道,负责接收、处理、存储来自海量车辆的数据,并为上层应用提供数据服务。其核心设计理念是高吞吐、低延迟、可扩展和湖仓一体。
2.整体架构总览
平台采用分层、解耦的流式处理架构,数据流向从左至右,依次为:数据源 -> 接入层 -> 计算层 -> 存储层 -> 应用层。各层之间通过标准协议或消息队列连接,确保了系统的模块化和可扩展性。
架构核心价值:实现车辆数据从产生到应用的全链路、实时与批处理一体的处理能力,支撑车辆监控、数据分析、智能服务等业务场景。
3.组件详细说明
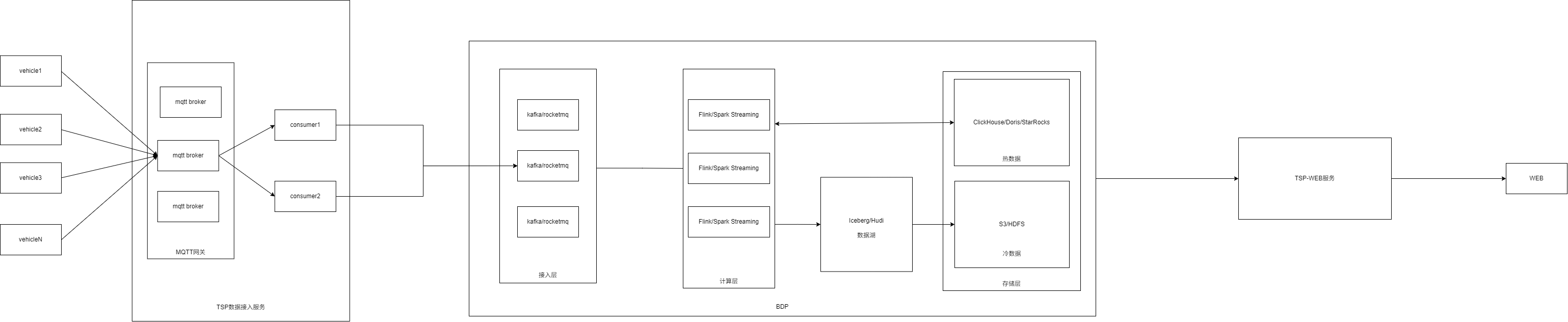
3.1数据源与接入层
3.1.1车端 (Vehicle)
角色:数据生产者。车辆通过车载T-Box,将车辆状态(如车速、电池电压)、事件、故障码等数据实时上报。
协议:通常使用轻量级的 MQTT 协议,适用于网络不稳定的物联网场景,支持低功耗和发布/订阅模式。
3.1.2MQTT Broker 集群
角色:消息代理,负责接收所有车辆上报的数据。
功能:实现消息的接入、路由和分发。采用集群部署以保证高可用性和横向扩展能力,应对百万级车辆并发连接。
输出:将消息分发给后端的消费客户端。
3.1.3消费者 (Consumer )
角色:数据接入服务。作为MQTT Broker的客户端,主动拉取或接收推送的车辆数据。
功能:进行初步的数据校验、解析和格式化,将不同车型或协议的数据转换为系统内部统一的数据格式。它也作为第一道流量控制和缓冲层。
3.1.4Kafka 集群 (Kafka)
角色:分布式消息队列,架构中的"中枢神经"和"缓冲池"。
功能:
解耦:隔离了数据生产(车辆接入)和数据消费(实时计算)的速度,防止上游洪峰压垮下游处理系统。
缓冲:以高吞吐、持久化的方式缓存数据,确保数据不丢失。
分发:下游的流计算任务(Flink/Spark Streaming)以消费者身份从Kafka中订阅并消费数据。
部署:多节点集群部署,通过分区(Partition)机制实现数据的水平切分和并行处理。
3.2计算层
3.2.1 实时流计算引擎
(Flink / Spark Streaming)
角色:数据加工厂。从Kafka中持续消费数据流,进行复杂的实时计算。
核心处理逻辑:
数据清洗:过滤无效、重复数据。
数据转换:格式转换、字段映射、单位换算等。
数据聚合:进行窗口化计算(如每分钟车辆在线数、每秒平均车速)。
数据丰富:关联静态数据(如车辆型号、归属用户)。
事件检测:基于规则实时判断并输出告警事件(如电池热失控风险)。
输出:处理后的数据被同时写入下游的热数据存储和数据湖。
3.3存储层
存储层采用 "湖仓一体" 架构,兼顾实时访问与大规模历史数据分析。
3.3.1热数据存储
(ClickHouse / Doris / StarRocks)
角色:高性能OLAP(在线分析处理)数据库。
特点:针对实时查询高度优化,支持海量数据的秒级/毫秒级聚合分析。
存储内容:存放最近一段时间(如最近7天)的明细数据和高度聚合的统计结果。
服务场景:直接服务于TSP-WEB服务的实时监控大屏、实时报表、实时告警等低延迟、高并发查询需求。
3.3.2 数据湖 (冷数据存储)
角色:全量、低成本、持久化的数据存储基地。
组成部分:
底层存储 (S3 / HDFS):对象存储(如AWS S3)或分布式文件系统,提供近乎无限的、廉价可靠的存储空间。
表格式 (Iceberg / Hudi):位于存储之上的元数据管理层。它将散落在S3/HDFS上的数据文件(Parquet/ORC)组织成一张张具有数据库表特性的"表",提供ACID事务、时间旅行、模式演进、隐藏分区等高级功能。
存储内容:所有原始和加工后的历史数据。
服务场景:支撑历史数据回溯、离线大数据分析、机器学习模型训练、审计等场景。
3.4应用层
3.4.1 TSP-WEB服务
角色:面向用户的统一数据服务网关。
功能:
API 提供:对外提供RESTful API,接收前端或第三方系统的数据查询请求。
查询路由:根据查询的时间范围和数据维度,智能地决定是从热数据存储(查近期快数据)还是从数据湖(查全量历史)中获取数据。
业务逻辑封装:封装复杂的业务查询逻辑,对前端提供简单、清晰的接口。
认证与鉴权:确保数据访问的安全性。
3.4.2 WEB前端
角色:数据可视化与交互界面。
形式:可以是内部运营平台、车企服务商门户等,以图表、地图、表格等形式展示车辆状态、统计报表、报警信息等。
4.数据流转流程
4.1数据上报
车端通过MQTT协议,将数据发布到MQTT Broker集群。
4.2数据接入
TSP数据接入服务(消费者)从Broker拉取数据,进行初步处理后,推送至Kafka集群的相应Topic。
4.3实时计算
Flink/Spark Streaming作业订阅Kafka Topic,对数据进行清洗、转换、聚合等实时处理。
4.4双路写入
处理后的数据被同时写入两条通路:
通路一(热存储):写入ClickHouse/Doris/StarRocks,供实时查询。
通路二(数据湖):通过Iceberg/Hudi格式,持久化写入S3/HDFS,作为唯一事实源。
4.5数据服务
用户通过WEB前端发起请求,TSP-WEB服务接收请求,根据逻辑查询热存储或数据湖,将结果组装后返回给前端展示。
5.架构核心优势与价值
5.1实时性
基于Kafka+Flink的流处理链路,确保数据从产生到可查秒级延迟。
5.2可靠性
Kafka提供高可靠消息存储,数据湖(Iceberg/Hudi)提供ACID保证,确保数据不丢、不错。
5.3扩展性
每一层(MQTT Broker, Kafka, 计算集群, 存储)均可独立水平扩展。
5.4经济性
"热+冷"分层存储,在保证实时性能的同时,利用对象存储低成本存储海量历史数据。
5.5开放性
基于数据湖开放格式(Iceberg),数据不被特定引擎锁定,可供Spark、Presto、Flink等多种计算引擎直接分析。