1、方案总览
基于通用大数据实施方案框架,深度融合汽车行业「研产供销服」全价值链场景,构建以 "多模态数据智能中台"为核心, "数据智能引擎"与"空间智能引擎(数字孪生)" 为两翼的一体化平台,实现乘用车「横向协同」与商用车「纵向贯通」的双轮驱动,全面赋能车企数智化转型。
整体架构遵循:
数据采集 → 数据存储 → 数据治理 → 数据分析 → AI 建模 → 数字孪生 → 业务应用
核心目标:
- 打破数据孤岛,实现全域数据融合
- 数据驱动研发、生产、营销、服务全流程优化
- 构建 AI 能力,实现预测性维护、智能决策
- 打造数字孪生工厂与数字孪生车辆,实现虚实交互
- 满足汽车数据安全与隐私保护合规要求
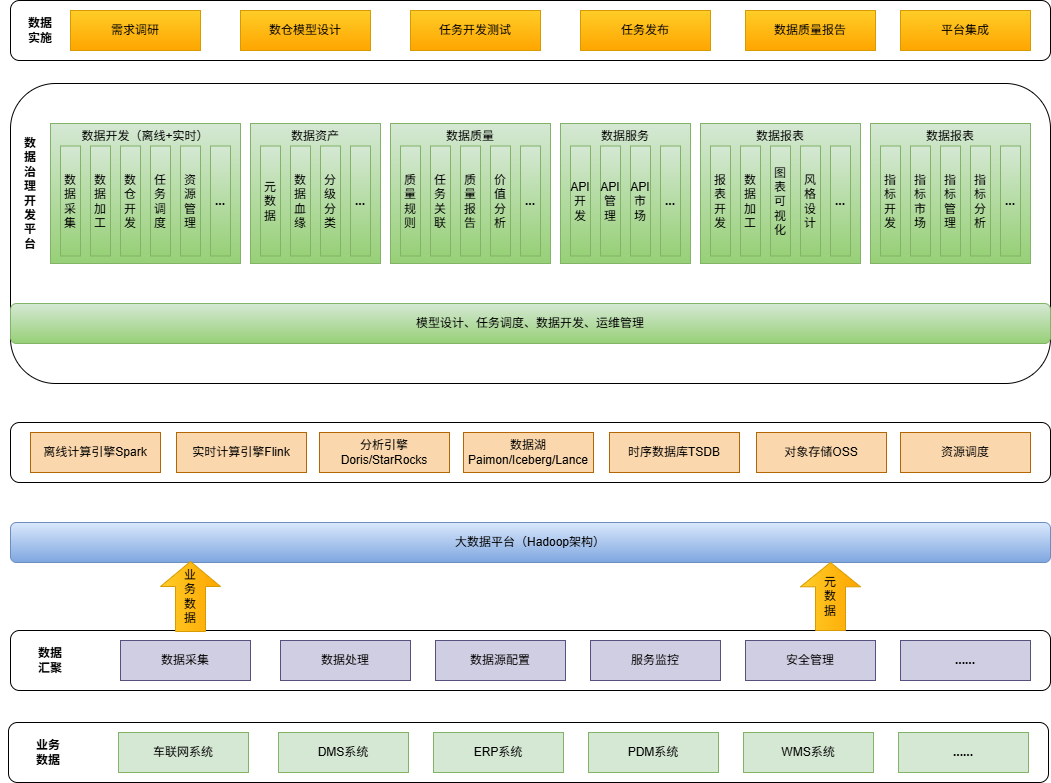
2. 数仓建设版图
2.1 数据应用层
- 数智营销:OneID 用户统一、360° 画像、精准触达、AB 实验、营销效果分析
- 数智研发:数字孪生样车、左移测试、仿真分析、OTA 效果评估、故障根因分析
- 数智生产:数字孪生工厂、生产透明化、柔性制造、能耗优化、质量追溯
- 数智质量:全链路 PDCA、预测性质量、主动防错、缺陷分析
- 数智物流:供应链控制塔、端到端可视化、JIT/JIS 保障、物流成本优化
- 数智交付:订单全程可视化、透明交车、交付效率提升
- 数智售后:车联网监控、预测性维保、远程诊断、UBI 保险、二手车残值评估
2.2 数据服务层
- 指标中心:统一指标口径(销量、产能、能耗、电耗、故障率等)
- 人群圈选:车主标签、客群分组、运营策略下发
- 分析探测:经营驾驶舱、实时大屏、专题分析、自助取数
- AI 服务:预测模型服务、推荐服务、异常检测服务
- 数字孪生服务:工厂 / 车辆可视化服务、仿真服务
- API 服务:标准化 REST API、数据共享服务
2.3 数据资产层
- 车辆全生命周期资产(VIN 为主键)
- 用户 OneID 资产(统一用户视图)
- 生产制造数据资产(设备、工艺、质量)
3. 大数据技术架构
3.1 接入层
- 车端 T-BOX、车机、传感器、充电桩、换电站
- 业务系统:PLM、ERP、SCM、SRM、WMS、MES、DMS、CRM
- 用户端:APP、小程序、官网、社交媒体
- 第三方:地图、天气、路况、监管平台、保险数据
- API 网关、WAF、Nginx、负载均衡
3.2 数据采集层
- 实时采集:MQTT/EMQX(车联网)、Kafka、Flink CDC、Debezium(业务库)
- 离线采集:DataX、Spark、FTP、API 同步
- 数据源:MySQL、PostgreSQL、MongoDB、Kafka、RocketMQ、日志文件
3.3 数据计算层
- 实时计算:Flink(车联网流、实时监控、预警)
- 批处理计算:Spark(日终统计、画像构建、离线分析)
- AI 计算:TensorFlow/PyTorch(模型训练)、Flink ML/Spark ML(在线推理)
- 统一调度:DolphinScheduler / Airflow
3.4 数据存储层
- 时序数据:TDengine / IoTDB(车联网 BMS 数据)
- 数仓存储:Hive(历史批量)、Paimon / Iceber
4.1 数据来源范围
- 车端数据:T-BOX、BMS、电机、电控、ADAS、定位、故障码
- 生产数据:MES、PLC、传感器、质量检测设备
- 营销数据:线索、订单、用户行为、广告投放
- 售后数据:维修记录、保养记录、投诉记录、OTA 升级
- 供应链数据:供应商、采购、库存、物流
- 第三方数据:地图、天气、路况、保险、征信
4.2 标准数仓分层
- ODS(原始数据层):原始车端报文、业务库数据、日志数据
- DWD(明细数据层):清洗、结构化、关联 VIN / 用户 ID / 时间
- DWS(汇总数据层):按天 / 小时 / 车辆 / 用户聚合、构建宽表、指标库
- ADS(应用数据层):面向业务场景的报表、大屏、预警、预测、AI 特征
- DIM(公共维度层):日期、地区、车型、车辆、用户、设备、供应商等统一维表
4.3 计算与存储策略
- 实时:Flink → Kafka → Doris / TDengine/ IoTDB(监控与预警)
- 离线:Spark → Hive / Paimon / Iceberg / Lance(统计分析、画像)
- AI 建模:Python → Hive / Paimon / Iceberg / Lance(特征工程、模型训练)
- 数字孪生:实时数据 + 仿真引擎 → 可视化平台
5. 技术选型清单
5.1 存储类
- 业务库:MySQL、PostgreSQL、Oracle
- 数仓:Hive、Paimon 、 Iceberg 、Lance
- 时序库:TDengine/IoTDB(车联网数据)
- OLAP 分析库:Doris / StarRocks
- 对象存储:OSS / Ozone
- 缓存:Redis Cluster / Kvrocks
5.2 计算类
- 实时计算:Flink
- 离线计算:Spark、Tez、MapReduce
- AI 计算:TensorFlow、PyTorch、Scikit-learn、XGBoost
- 数字孪生:Unity、Unreal Engine、Digital Twin Platform
5.3 采集与中间件
- 采集:Flink CDC、Debezium、DataX、EMQX
- 消息队列:Kafka、Pulsar 、RocketMQ
- 网关:Spring Cloud Gateway / Nacos
5.4 开发与前端
- 开发语言:Java、Python、Shell、SQL
- 前端:Vue、React
- 可视化:DataEase、Grafana、数字孪生可视化工具
6. 服务规划与集群部署
6.1 Hadoop 集群(基础大数据底座)
- NameNode:3 节点
- DataNode:5 节点及以上
- CPU:16/32/64 核
- 内存:32/64/128GB
- 磁盘:系统盘 100GB,数据盘数据盘 1TB+
6.2 Doris 集群(OLAP 分析核心)
- FE:3 节点及以上
- BE:3 节点及以上
- CPU:32/64/128 核
- 内存:64/128/256/512GB
- 磁盘:系统盘 100GB,数据盘 1TB+(推荐 SSD)
6.3 TDengine /IoTDB集群(时序数据)
- 3 节点高可用
- CPU:32 核 +
- 内存:64GB+
- 磁盘:SSD 1TB+(高 IOPS)
6.4 AI 与数字孪生集群
- 节点:4 节点及以上(GPU 节点)
- CPU:32/64 核
- 内存:128/256GB
- GPU:NVIDIA A100/V100
- 磁盘:1TB+
7. 数仓标准与规范制定
7.1 分层规范
ODS → DWD → DWS → ADS → DIM
7.2 表命名规范
- ODS:
ods_业务系统_表名 - DWD:
dwd_业务域_业务过程_df/di - DWS:
dws_业务域_颗粒度_周期 - ADS:
ads_应用场景_指标_周期 - DIM:
dim_维度名
7.3 字段命名规范
- 布尔:
is_xxx - 枚举:
xxx_type - 计数:
xxx_cnt - 金额:
xxx_amt - 比率:
xxx_rate - 时长:
xxx_dur
7.4 生命周期规范
- ODS:1 年(365 天)
- DWD / DIM:3 年(1095 天)
- DWS:3~5 年
- ADS:5 年(1825 天)
7.5 分区规范
- 一级分区:
dt(日期) - 二级分区:
vin/user_id/factory_id - 最多二级分区,避免过深分区
8. 数据模型建设规范
8.1 建设原则
- 高内聚、低耦合
- 公共维度与公共指标下沉
- 口径统一、可扩展、高性能与成本平衡
8.2 核心模型建议
- 用户域:用户 OneID 表、用户画像表、用户行为表
- 车辆域:车辆基础信息表、车辆状态事实表、故障告警事实表、OTA 升级表
- 生产域:生产工单表、设备状态表、质量检测表、工艺参数表
- 营销域:线索表、订单表、渠道表、活动效果表
- 售后域:维修记录表、保养记录表、投诉记录表、配件更换表
- 供应链域:供应商表、采购订单表、库存表、物流记录表
9. 数据治理与质量保障
9.1 数据治理体系
- 数据标准:统一指标、统一维度、统一口径(如销量、产能、电耗)
- 数据质量:DQC 监控(非空、唯一、范围、枚举、一致性)
- 元数据:表 / 字段 / 任务 / 权限全链路管理
- 数据血缘:全链路追踪,支持影响分析
- 数据生命周期:自动归档、冷数据迁移
9.2 数据质量规则
- 车辆 VIN 码唯一性校验
- 车端数据上报频率与完整性校验
- 生产工艺参数范围校验
- 用户隐私数据脱敏规则
- 国标 GB/T 32960 数据格式校验
10. 数据安全与合规体系
10.1 数据安全
- 身份认证与权限控制(RBAC)
- 数据脱敏:位置、手机号、身份证等敏感信息脱敏
- 数据加密:传输与存储加密
- 操作审计:全链路日志留痕
- 分级分类:公开 / 内部 / 敏感 / 机密数据分层管理
10.2 合规与监管
- 国标 GB/T 32960:车辆运行数据自动上报
- 汽车数据安全管理规定:最小必要原则、数据不出域、脱敏与加密
- 个人信息保护法:匿名化、去标识化、用户授权机制
- 网络安全法:等保三级合规
11. 核心业务应用场景
11.1 乘用车:全价值链数智化
- 数智营销:精准线索孵化、用户画像、个性化推荐、营销效果评估
- 数智研发:数字孪生样车、虚拟测试、OTA 效果分析、故障根因定位
- 数智生产:数字孪生工厂、生产透明化、柔性制造、能耗优化
- 数智售后:预测性维保、远程诊断、车联网监控、二手车残值评估
11.2 商用车:全生命周期价值管理
- 买车:TCO 总拥有成本分析、科学选型决策
- 用车:驾驶行为分析、能耗优化、路线规划
- 管车:车队监控、金融风控、电子围栏、防盗预警
- 养车:预测性维保、最大化出勤率、降低运维成本
- 换车:数据赋能残值评估、提升二手车价值
12. 项目实施计划
12.1 第一阶段:奠定基石
- 平台搭建:集群部署、环境初始化、账号权限规划
- 数据接入:核心业务系统、车联网数据接入
- 数仓建设:ODS/DWD 核心模型建设
- 数据治理:标准制定、DQC 配置
- 建设周期:1-3个月(人天)
12.2 第二阶段:试点突破
- 上线经营驾驶舱、核心业务报表
- 试点数智营销 / 数智售后场景
- AI 模型 POC(如故障预测、需求预测)
- 数字孪生工厂 / 车辆原型搭建
- 建设周期:3-6个月(人天)
12.3 第三阶段:全面深化
- 全业务域数据模型覆盖
- AI 能力规模化部署(预测性维护、智能调度)
- 数字孪生全面应用(工厂、车辆、供应链)
- 数据文化建设与赋能
- 建设周期:6-12个月(人天)
13. 风险评估与应对策略
| 风险类型 | 风险描述 | 风险等级 | 应对策略 |
|---|---|---|---|
| 数据质量风险 | 车端数据乱码、缺失、异常值多 | 中 | 边缘预处理、实时清洗、DQC 强校验 |
| 实时延迟风险 | 高并发车端上报导致延迟升高 | 中 | Kafka 削峰、Flink 优化、时序库加速 |
| 存储成本风险 | 车联网时序数据体量大、存储成本高 | 中 | 冷热分离、压缩策略、归档迁移 |
| 合规风险 | 隐私数据泄露、国标上报不达标 | 高 | 脱敏加密、审计、自动上报流程 |
| AI 模型风险 | 模型精度不足、泛化能力差 | 中 | 高质量数据采集、特征工程优化、模型迭代 |
| 数字孪生风险 | 模型复杂度高、仿 |
14. 方案价值预估
14.1 方案价值
- 降本:研发周期缩短 30%+,生产效率提升 20%+,运维成本降低 30%+
- 提效:营销转化率提升 15%+,交付周期缩短 20%+,故障响应时间缩短 60%+
- 增收:精准营销带来销量增长,增值服务收入提升,二手车残值提升 5%+
- 合规:满足汽车数据安全、个人信息保护、国标上报等监管要求
- 转型:从「卖车」向「卖服务 + 卖数据」的商业模式升级
14.2 标杆案例参考
- 高端新能源品牌:全域数据基座 + OneID,营销转化率 + 15%,研发数据准备缩短 95%
- 领先商用车集团:数智中枢 + 车联网,车辆在线率 + 20%,停运时间 - 30%
- 民营龙头车企:数据中台 + 数字孪生,研发左移测试,样车成本大降