重要概念
-
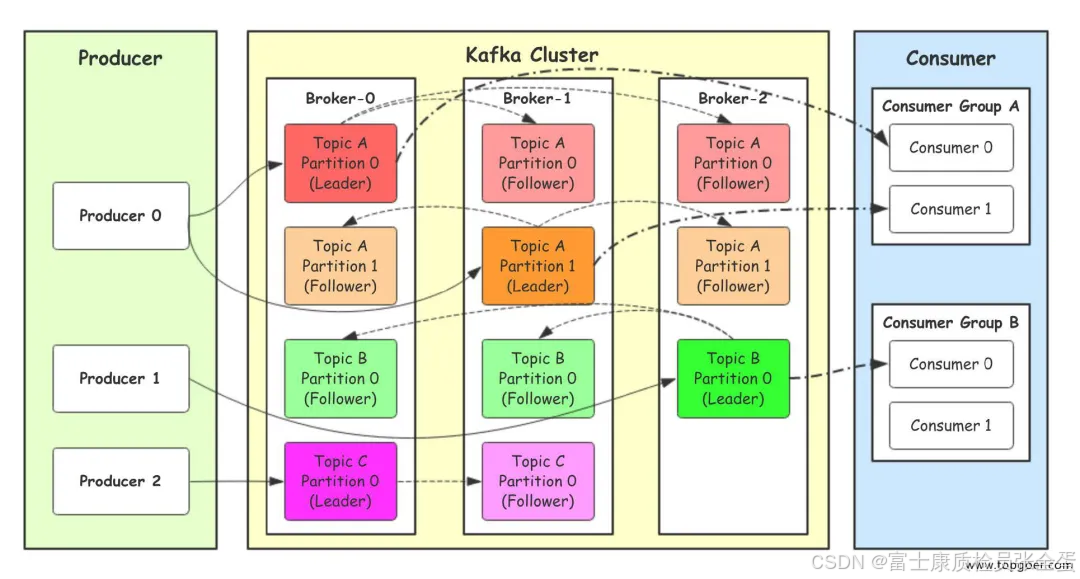
Broker: Kafka 的基本单元,负责存储和传递消息。一个 Kafka 集群由多个Broker组成。
-
Topic: 消息的分类,每条消息都属于一个特定的 Topic。用户可以通过 Topic 来组织和管理消息。
-
Producer: 消息的生产者,负责将消息发送到指定的 Topic。
-
Consumer: 消息的消费者,从 Kafka 中读取消息的客户端。
-
Consumer Group: 一组消费者,能够共同消费同一Topic 的消息。每条消息只能被同一 Consumer Group 中的一个Consumer消费,但可以被多个不同的Consumer Group消费。
-
Partition: 每个 Topic 可以分为多个 Partition,Partition 内部消息有序存储,并且可以分布在不同的 Broker 上,以实现负载均衡和高可用性。
一个消费者组就是一个容器,这个容器当中可以存放若干消费者,我们在启动消费者的时候可以指定这个消费者在哪一个组里面。如果不去指定,那么kafka会自动的去创建消费者组。
为什么要有分区呢?其实就是为了提高消费能力,有了多个分区,那么就可以去启动多个消费者同时去消费数据。而这个分区是物理上的概念就是物理上的分组。每一条消息只能选择一个分区进行写入。也就是只能进入一个队列。
每个主题都有三个分区,这就是不同的分区。

一个分区可以有多个副本,在创建topic的时候可以指定副本因子,如果为3,那么每个分区会有3个副本。
当然副本当中也会分为leader和follower这样的角色,leader负责客户端的读写请求的。生产者生产的消息要存在partition中,那么就和leader去交互。消费者需要去消费这个分区的数据,那也是和leader去交互。follower工作很简单,就是保持和leader的数据同步。
一个partition可以分为多个段,段中存放的是message的信息。这里面log和index就组成了一个segment。.log当中储存的是数据,而index里面存放的是一些索引信息。

生产者生产的消息按照offset有序的存储于每个分区之内,生产者生产的消息按照这样的顺序存储起来。而消费者可以从最新的offset开始消费,也可以从指定的或者更早的。
offset其实就是一条消息在一个分区当中的位置的索引。
对下面图片的理解:
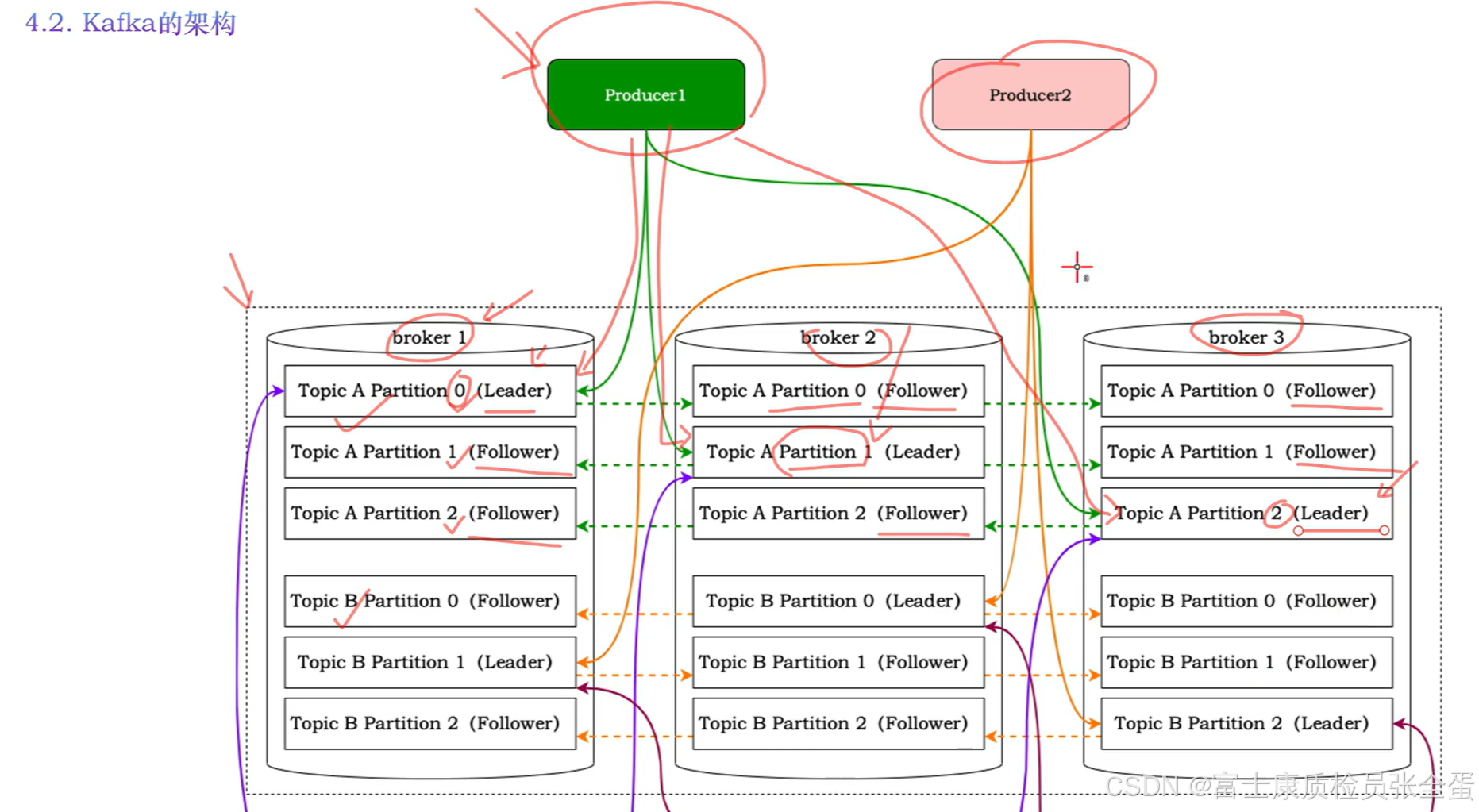
首先起点是生产者,生产者负责生产消息,这条消息生产完之后是要保存在指定的topic当中的。假设是往topicA中去存放的,而这条消息可能会放在不同的分区里面。
在虚线里面时候应该kafka集群,这个kafka集群当中有3个broker,每个broker上面都存有分区的副本。现在有topic A B,这两个都有三个分区partition 0 1 2,同时副本因子也是3。也就是说partition 0除了在broker1,在另外的几台节点上面也会存在副本。在这些之间也是存在leader和follower角色区分的。
在broker1上面partition 0是leader,那么partition1的leader在broker2上面。如果生产者的消息需要存放在partition 0里面,那么应该和broker1上面的leader去交互,去做一个写数据的请求,把数据保存在leader文件当中。接下来partition0的两个副本是需要和leader进行数据的同步操作的,同样producer要将数据放在1分区里面,那么producer就需要和broker2上面的1分区的leader做交互。因为分区1的leader在broker2上面。这样可以确定这条消息被成功保存下来了。
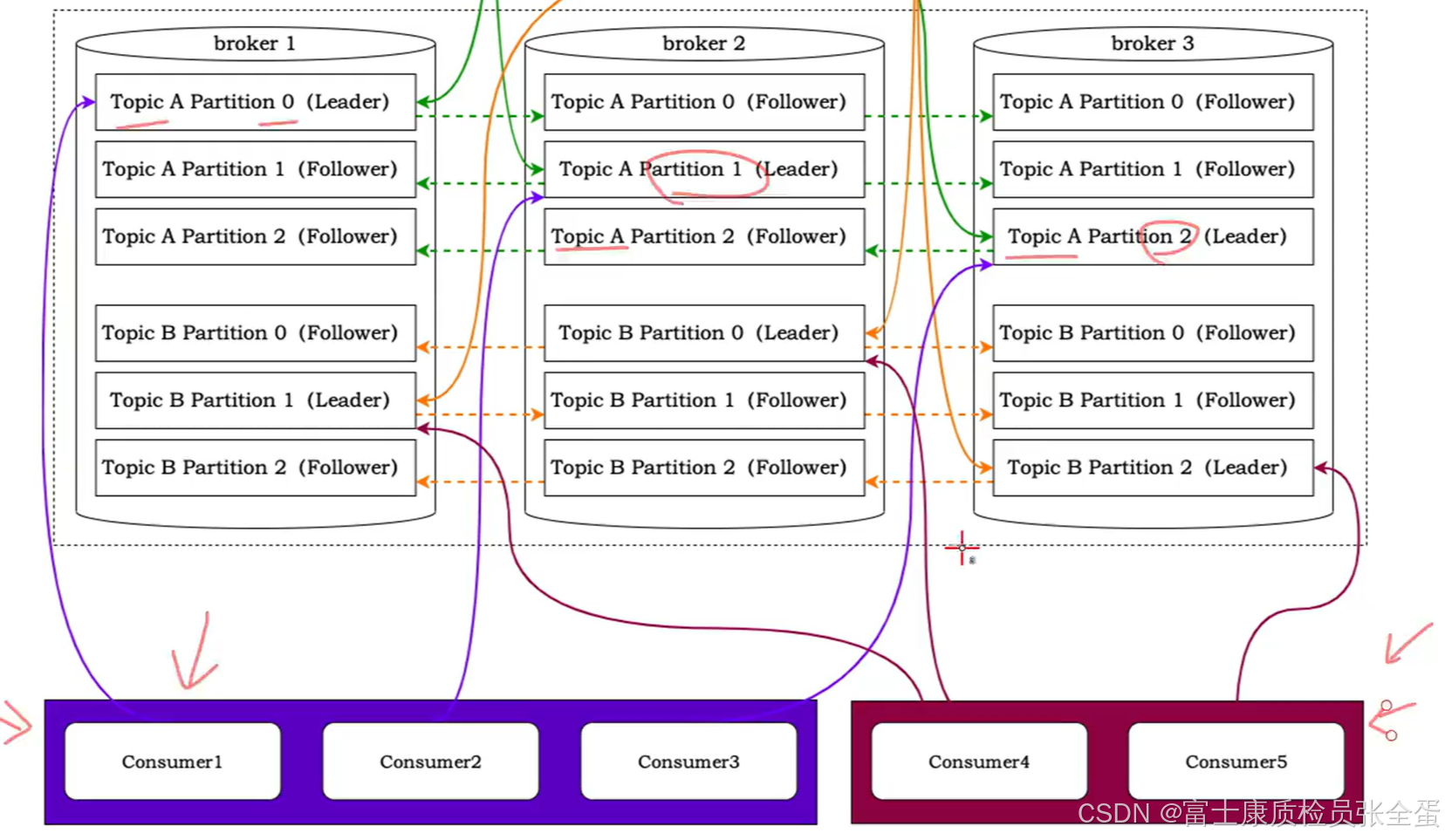
第一个消费者组有3个消费者,这样刚好各自消费一个分区,每个消费者各自消费一个分区的数据。
对于酒红色的来说只有两个消费者,这样其中两个消费者其中一个会消费两个分区中的数据,而另外一个消费者消费一个分区的数据。

