前言
这个章节介绍这个篇章的主题内容, sync.Mutex的底层实现. 我会按照惯例通过源码走读的形式一步步解析核心的代码逻辑, 同时也会省略掉跟核心逻辑无关的干扰项, 如系统检测追踪的逻辑.
经过前两个章节的铺垫, 这个篇章相对很多细节会清晰很多.
在进入源码走读之前, 先来看看官方为了资源分配的合理性和公平性, 它们是怎么去设计这样一个数据结构的, 这里直接进行中英文对照翻译:
golang
// Mutex can be in 2 modes of operations: normal and starvation.
Mutex 有两种操作模式: 普通模式和饥饿模式.
// In normal mode waiters are queued in FIFO order, but a woken up waiter
在普通模式下, 等待者会通过FIFO的顺序入队休眠, 但是当没有持有锁的等待者被唤醒时, 会和
// does not own the mutex and competes with new arriving goroutines over
其他新到来的goroutine 竞争锁的所有权.
// the ownership. New arriving goroutines have an advantage -- they are
而新到来的goroutine有个优势 -- 它们已经在CPU上跑了和数量可能会很多,
// already running on CPU and there can be lots of them, so a woken up
所以被唤醒的goroutine会很难抢到锁.
// waiter has good chances of losing. In such case it is queued at front
在这个场景下, 它会被重新入队到等待队列头部.
// of the wait queue. If a waiter fails to acquire the mutex for more than 1ms,
如果等待者超过1ms没有拿到锁, mutex会切换到饥饿模式.
// it switches mutex to the starvation mode.
// In starvation mode ownership of the mutex is directly handed off from
在饥饿模式下, mutex的所有权会从已释放锁的goroutine直接挂到等待队列头部的goroutine.
// the unlocking goroutine to the waiter at the front of the queue.
// New arriving goroutines don't try to acquire the mutex even if it appears
新到达的goroutine不会尝试去自旋抢锁即使锁资源已经被释放了.
// to be unlocked, and don't try to spin. Instead they queue themselves at
相反他们会入队到等待队列尾部.
// the tail of the wait queue.
//
// If a waiter receives ownership of the mutex and sees that either
如果等待者已经拿到了mutex的所有权, 只要达到下面任意一个条件即可从饥饿模式切换回普通模式:
// (1) it is the last waiter in the queue, or (2) it waited for less than 1 ms,
1. 等待队列只有这唯一一个等待者了; 2. 当前等待者的等待时间小于1ms
// it switches mutex back to normal operation mode.
// Normal mode has considerably better performance as a goroutine can acquire
普通模式下, 一个goroutine在一段时间内连续几次争夺锁这种思路会有更好的性能, 即使此时已经有
// a mutex several times in a row even if there are blocked waiters.
休眠中的等待者.
// Starvation mode is important to prevent pathological cases of tail latency.
而饥饿模式对于解决极端的尾延迟问题是重要的存在.上述中, 我们可以得到以下信息:
mutex 有两种模式, 普通模式和饥饿模式.
-
普通模式: 所有加锁的goroutine都会尝试抢锁
优点:在这种竞态环境下可以充分的利用CPU的资源提高锁的性能
缺点:会导致有些goroutine长时间抢不到锁.
-
饥饿模式: 所有的goroutine排队领锁.
优点: 所有的goroutine按照先来后到的顺序获得锁, 体现了公平性
缺点: 会频繁的进行goroutine调度和上下文切换, 会有比较大的性能损耗
这里解释一下, 为什么在普通模式下cpu会更好的被利用:
在饥饿模式下所有的goroutine需要排队, 也就是放到等待队列休眠等待. 等到轮到它的时候会被唤醒和调度. 这时就必须将被唤醒的g放回gmp的调度队列中, 然后cpu切换到被唤醒的g的上下文去执行g的代码. 这样会导致频繁的调度和上下文切换问题.
而在普通模式下, 所有的g竞争锁, 而正在使用cpu的g将更容易抢到锁, 由于当前抢到锁的g正在占用cpu, 所以不需要进行切换和调度直接执行代码. 所以说普通模式能更好地利用cpu.
数据结构
golang
type Mutex struct {
state int32
sema uint32
}state: 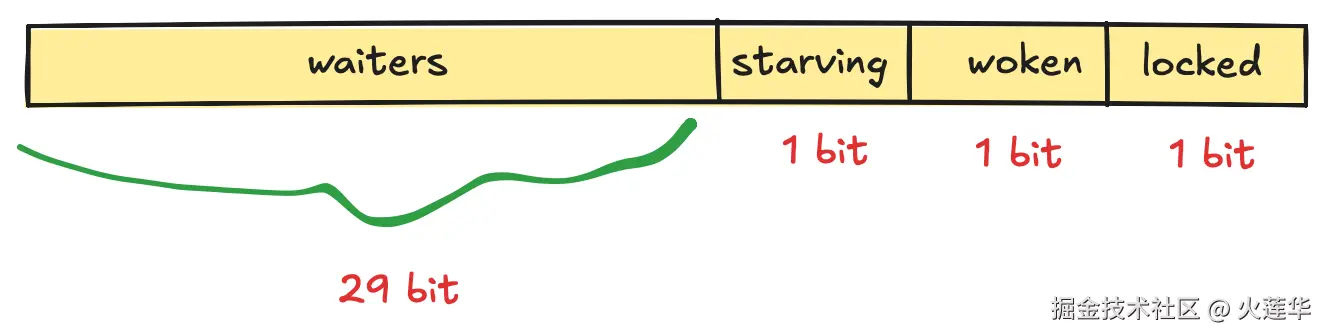
state根据bit位分为4块. 对应枚举:
golang
const (
mutexLocked = 1 << iota
mutexWoken
mutexStarving
mutexWaiterShift = iota- 第一位标志位, 是否有goroutine占用锁
- 第二位标志位, 是否有被唤醒的g
- 第三位标志位, 当前是否是饥饿模式
- 第四位之后, 代表休眠的goroutine数
sema则是在part2介绍的semaphore.
Lock
加锁, 如果锁被占用, 则阻塞, 直到锁被释放.
源码:
golang
func (m *Mutex) Lock() {
// fast path
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// slow path
m.lockSlow()
}fast path
state 为0 表示此时并没有g在竞争锁, 这时我们直接占用锁就行了.
slow path
这个场景就比较复杂了, 由于它构筑了无锁化的调度逻辑(系统线程之间无锁), 很多逻辑分支都杂糅在一段代码里, 很大程度提升了代码的复杂程度, 所以这次我们一个分支一个分支的去解析代码, 尽量让整个流程简单易懂.
核心源码:
golang
func (m *Mutex) lockSlow() {
starving := false
awoke := false
iter := 0
old := m.state
for {
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
new := old
if old&mutexStarving == 0 {
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
break
}
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}普通模式下的锁竞争
我们假设当前是普通模式, 选择性忽略饥饿模式的逻辑
在普通模式下, fast path阶段抢不到锁, 说明此时有锁竞争. 第一步, 加入竞争行列, 对应代码:
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
* if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
* awoke = true * }
* runtime_doSpin()
iter++
old = m.state
continue
}
if 的第一个条件old&(mutexLocked|mutexStarving) == mutexLocked 如果为true说明此时锁被占用, 第二个条件 runtime_canSpin(iter) 判断当前是否继续自旋.
而是否可以自旋的判断:
golang
active_spin = 4
func sync_runtime_canSpin(i int) bool {
if i >= active_spin || ncpu <= 1 || gomaxprocs <= sched.npidle.Load()+sched.nmspinning.Load()+1 {
return false
}
if p := getg().m.p.ptr(); !runqempty(p) { // p的本地队列不为空
return false
}
return true
}- 自旋次数是否超过4次
- 当前是否单核cpu(单核cpu相当于空转, 没有任何意义)
- 这个条件
gomaxprocs <= sched.npidle.Load()+sched.nmspinning.Load()+1中,
gomaxprocs指代当前程序最大p数,
npidle指代空闲的p数,
nmspinning指代正在自旋寻找g的m数量, 该m绑定p, 也是指没有执行g的p,
npidle+nmspinning指没有执行g的p的数量, 而+1表示加上当前p.
所以这个条件的意思是除了当前正在跑的g, 是否还有其他g并发在跑, 如果没有那持有锁的g很可能在当前p的等待队列, 所以没有必要自旋 - p本地队列还有其他g在等待调度, 这时与其自旋还不如让出p资源跑本地其他g更有效率
到下一步假设我们抢不到锁, 则会执行下面的代码:
golang
if !awoke && old&mutexWoken == 0 &&
old>>mutexWaiterShift != 0
&& atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken)
{ awoke = true }awoke是个bool值, 表示当前g是不是被唤醒的g, 这里有两种情况:
- 当前g不是被唤醒的g, 也就是awoke为false
- 当前g确实是被唤醒的g, awoke为true(后面的代码会有这个逻辑)
如果是false, 而且此时当前g正在抢锁, 为了不要多一个竞争对手, 当前g会假装我是唤醒的g, 让mutex不要再唤醒其他g加大我的竞争压力了. 所以这里会尝试设置awoken标志
接着开始自旋: runtime_doSpin()
golang
active_spin_cnt = 30
func sync_runtime_doSpin() {
procyield(active_spin_cnt) // 当前cpu自旋30次
}再往下走有两种情况, 一种是抢到锁了, 一种是在经过一定的自旋之后还是抢不到锁.
先来分析第一种情况, 假设当前g抢到锁了, 接下来会走这里:
golang
new := old
if old&mutexStarving == 0 {
new |= mutexLocked // 不处于饥饿模式, 抢锁,置为locked
}new即是要更新的mutex状态, 由于抢到锁了, 添加locked标志 接着:
golang
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // and + xor 移除唤醒标志
}这里由于自己抢到锁了, 所以事不关己了, 移除awoken标志, 将唤醒机会让出去
golang
if atomic.CompareAndSwapInt32(&m.state, old, new) { // 抢锁
if old&(mutexLocked|mutexStarving) == 0 { // 抢到锁 正常模式抢占到锁,退出
break
}
} else {
old = m.state // 更新失败, 重新走一遍流程
}更新state成功, 抢到锁成功, 结束; 没更新成功, 继续回去抢锁. 至此, 该分支逻辑结束
我们来看另一种情况, 没抢到锁的情况:
golang
if old&(mutexLocked|mutexStarving) != 0 { // 通过自旋也没抢到锁或处于饥饿模式的情况
new += 1 << mutexWaiterShift // 等待队列+1
}给了机会没抢到锁, 意味着当前g需要进入等待队列了, 所以更新waiter + 1(按位进1)
golang
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // and + xor 移除唤醒标志
}当前g要休眠了, 将机会让给等待队列下一个g去竞争锁.
golang
if atomic.CompareAndSwapInt32(&m.state, old, new) { // 抢锁
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime() // 开始等待计时
}
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 唤醒之后的逻辑
... ...
} else {
old = m.state // 更新失败, 重新走一遍流程
}如果state更新失败, 则回去重新获取新的state值, 并重新执行之前的流程.
如果state更新成功, 当前g就要进入等待队列了,
这里queueLifo决定当前g是插入等待队列头部还是尾部, 从代码可以看出如果是第一次休眠则排在队尾, 否则排在队头. 表明队列中的g是依序等待唤醒的, 就算第一次唤醒抢锁失败, 下一次也会在差不多的位置重新尝试, 这体现了一种公平性调度原则.
之后调用semaacquire方法进入等待队列, semaacquire不了解的可以去看看part2部分.
最后是唤醒后的逻辑:
golang
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs // 唤醒后发现等待时间超过 starvationThresholdNs 进入饥饿模式
old = m.state // 唤醒后更新状态
awoke = true // 非饥饿模式下,如果被唤醒的话,unlock操作已将awoken标志置为1且等待队列-1,此时只需更新本g awoken 状态即可
iter = 0starving表示当前是否进入饥饿模式,
唤醒后如果发现等待时间超过1ms(starvationThresholdNs), 则进入饥饿模式(starving == true), 此时还没更新饥饿状态(mutex.state还没更新), 这里我们先假设starving == false.
将当前g置为唤醒后的g(awoke = true), 重置自旋计数, 重新回去竞争锁. 此时woken标志位已经在unlock流程置为1, 不需要修改.
该分支逻辑结束
饥饿模式下的锁分配
分为两种情景, 处于饥饿模式但状态还没更新: starving为true, 但是starving标志位为0; 饥饿状态已经更新 starving标志位为 1
先来分析第一种情况, 这个需要从g唤醒后进入饥饿模式, 且回到循环开头的代码开始追踪:
golang
if old&mutexStarving == 0 {
new |= mutexLocked // 饥饿标志位为0, 抢锁,置为locked
}
... ... // 这里的代码不会执行
if starving && old&mutexLocked != 0 { // 饥饿标记且锁被抢占, 则转换为饥饿模式, 如果有饥饿标记可是却抢到锁, 则不进入饥饿模式
new |= mutexStarving // 有饥饿标志,需更新为饥饿模式
}
if awoke { // 抢到更新权, 不需要阻止其他goroutine进行唤醒
// The goroutine has been woken from sleep,
// so we need to reset the flag in either case.
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // and + xor 移除唤醒标志(当前g 不再自旋)
}这时不会去自旋抢锁, 会直接获取锁, 更新为starving标志位为1, 唤醒标志位为0, 更新状态, 结束. 如果状态更新失败, 则会重复上述流程.
此时当前mutex正式进入饥饿模式:
golang
if old&(mutexLocked|mutexStarving) != 0 { // 通过自旋也没抢到锁或处于饥饿模式的情况
new += 1 << mutexWaiterShift // 等待队列+1
}
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // and + xor 移除唤醒标志(当前g 不再自旋)
}饥饿模式下, 不会进行自旋. 真正有效执行的代码会从上面这里开始.
饥饿模式下, 当前g会直接进入等待队列休眠, 所以更新等待的goroutine长度并同时移除唤醒标志.
golang
if atomic.CompareAndSwapInt32(&m.state, old, new) { // 抢锁
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime() // 开始等待计时
}
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 唤醒之后的逻辑
... ...
} else {
old = m.state // 更新失败, 重新走一遍流程
}直接进入休眠队列.
下面是被唤醒后的逻辑.
golang
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state // 唤醒后更新状态
if old&mutexStarving != 0 {
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
delta := int32(mutexLocked - 1<<mutexWaiterShift) // 加锁并减去一个等待队列
if !starving || old>>mutexWaiterShift == 1 { // 如果饥饿模式下当前g等待时间少于1ms或等待队列为空,解除饥饿模式
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta) // 更新状态
break
}每当g被唤醒后, 都会判断当前g是否等待时间太久, 判断是否继续维持饥饿模式.
这里代码是 starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
而不是
starving = runtime_nanotime()-waitStartTime > starvationThresholdNs,
因为第一个将普通模式切换为饥饿模式的g会重新走一遍循环, 此时waitStartTime重新被更新, 该g如果太快被唤醒, 可能会被判定为非饥饿, 而实际上该g是因为饥饿模式入队的, 所以要保留之前判定的结果.
如果当前为饥饿模式, 映入眼帘的第一个if是状态不一致的防御性编码, 当然根据前面和后面介绍的释放锁的逻辑可以推测, 这个if条件是不可能成立的.
饥饿模式下, 被唤醒的g直接默认持有锁, 所以后面直接加locked标志位, 等待队列-1并退出循环. 如果当前g的等待时间小于1ms(starving == false), 就从饥饿模式切换为普通模式.
TryLock
尝试获取锁而并发生阻塞操作.
golang
func (m *Mutex) TryLock() bool {
if old&(mutexLocked|mutexStarving) != 0 {
return false // 当处于锁被占用或处于饥饿模式时(不可抢占状态), 默认不可上锁
}
if !atomic.CompareAndSwapInt32(&m.state, old, old|mutexLocked) {
return false // 尝试抢锁
}
return true
}以下情况会发生阻塞, 所以直接退出:
- 锁被占用
- 饥饿模式(每个g都要排队领锁)
- 抢不到锁
Unlock
释放锁操作. 源码:
golang
func (m *Mutex) Unlock() {
// Fast path
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// slow path
m.unlockSlow(new)
}
}fast path
跟Lock操作的fast path 相反的操作. 一般unlock操作时, 当前锁应该是被占用状态, 所以fast path按理论来说是成立的, 不过类似下面的代码, 则会破坏这个逻辑:
golang
mu := sync.Mutex{}
mu.Unlock()此时new肯定不为0, 在unlockSlow方法会有对应的防御编码, 如有类似上面, lock的调用和unlock的调用不一致, 则panic.
new不为0, 表示目前状态比较复杂, 需要去通过slow path处理
slow path
golang
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
fatal("sync: unlock of unlocked mutex")
} // 防止lock跟unlcok 调用不一致, 导致状态异常
if new&mutexStarving == 0 {
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 { // mutexLocked mutexWoken 表示有其他g在抢锁, 所以不用唤醒, starving 表示其他g抢到锁并触发了饥饿模式, 也不用处理
return
}
// Grab the right to wake someone.
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
runtime_Semrelease(&m.sema, true, 1) // 饥饿模式直接handoff (直接夺取当前m进行调度本g)
}
}unlock逻辑跟lock比较简单了许多.
-
当前是饥饿模式下, 直接调用
sema.semarelease唤醒等待队列中的g, 此时handoff为true, 被唤醒的g将直接被分配锁. 具体流程可以看看part2部分. -
当前是普通模式下,
sql
if old>>mutexWaiterShift == 0 || old&(mutexWoken) != 0 { // mutexLocked mutexWoken 表示有其他g在抢锁, 所以不用唤醒, starving 表示其他g抢到锁并触发了饥饿模式, 也不用处理
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state第一次循环, old不可能会有locked和starving标志位, 所以上述代码先删除相关逻辑.
那么old就只有以下三种可能,
如果不存在等待队列, 那就是当前一定有被唤醒的g, 表明当前存在锁竞争且至少存在1个g在抢锁, 此时不需要唤醒新的g, 直接结束.
如果有等待队列且woken标志位也不为0, 跟上个情景一样, 有锁竞争, 直接结束.
如果有等待队列且woken标志位为0, 此时继续走下面的唤醒流程: 等待队列-1, woken标志位置为1, 更新状态, 唤醒新的g, 这里的semarelease的参数handoff为false.
如果状态更新失败, 获取最新状态进行第二次循环, 这时就可能出现 starving标志位为1 或 locked标志位为1的情况.
第二次循环:
golang
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 { // mutexLocked mutexWoken 表示有其他g在抢锁, 所以不用唤醒, starving 表示其他g抢到锁并触发了饥饿模式, 也不用处理
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state这里除了第一次循环的三种情况之外, 还多了以下几种情况:
在分析之前我们先明确一点, lock跟unlock是同步操作, 也就是说只会像下面的顺序运行:
golang
lock()
unlock()
lock()
unlock()
... ...当前有g持有锁, 也就是说已经有下一个lock抢到锁了, 此时unlock应该什么都不做, 将唤醒流程交给下一个unlock.
当前为饥饿模式, 表示已经有其他unlock先唤醒了一个新的g, 而新的g会自动获取锁从而执行新的lock, 所以当前unlock也应该什么都不做, 结束.
后记
普通模式下, 资源利用率高, 但是缺少公平性, 饥饿模式下则相反, 所以Mutex在高并发场景下, 主要通过普通模式和饥饿模式的轮流替换在兼顾公平性的基础上实现高可用. 而且通过源码的解读可以发现, Mutex实现比较妙的地方在于除了最后的休眠唤醒流程需要用到系统线程级别的锁之外(runtime.sema 有对应的锁控制), 锁竞争逻辑仅通过原子操作基本实现无锁化处理.
初稿定于 2026.4.23