多任务
为什么需要多任务?
可以大大提高程序的执行效率
之前所写的程序都是单任务的,也就是说一个函数或者方法执行完成 , 另外一个函数或者方法才能执行。要想实现多个任务同时执行就需要使用多任务。多任务的最大好处是充分利用CPU资源,提高程序的执行效率。多任务的两种形式
并发
在一段时间内交替去执行多个任务例如:对于单核cpu处理多任务,操作系统轮流让各个任务交替执行,假如:软件1执行0.01秒,切换到软件2,软件2执行0.01秒,再切换到软件3,执行0.01秒......这样反复执行下去 , 实际上每个软件都是交替执行的 . 但是,由于CPU的执行速度实在是太快了,表面上我们感觉就像这些软件都在同时执行一样 . 这里需要注意单核cpu是并发的执行多任务的
并行
在一段时间内真正的同时一起执行多个任务对于多核cpu处理多任务,操作系统会给cpu的每个内核安排一个执行的任务,多个内核是真正的一起同时执行多个任务。这里需要注意多核cpu是并行的执行多任务,始终有多个任务一起执行。
多进程
一、进程的概念
1、程序中实现多任务的方式
在Python中,想要实现多任务可以使用==多进程==来完成2、进程的概念
进程(Process)是资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位,通俗理解:一个正在运行的程序就是一个进程
例如:正在运行的qq , 微信等 他们都是一个进程3、多进程的作用
提高执行效率未使用多进程
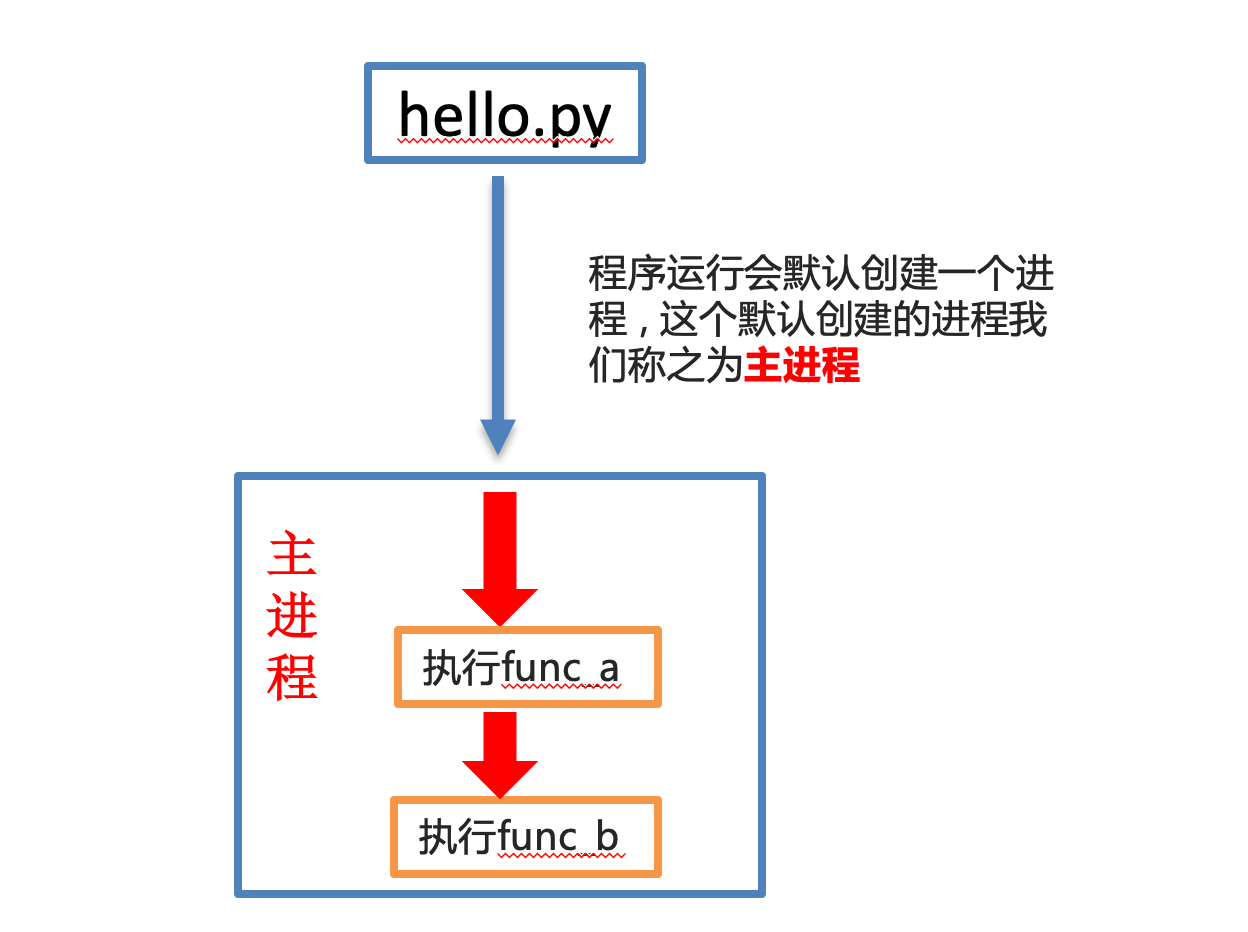
使用了多进程
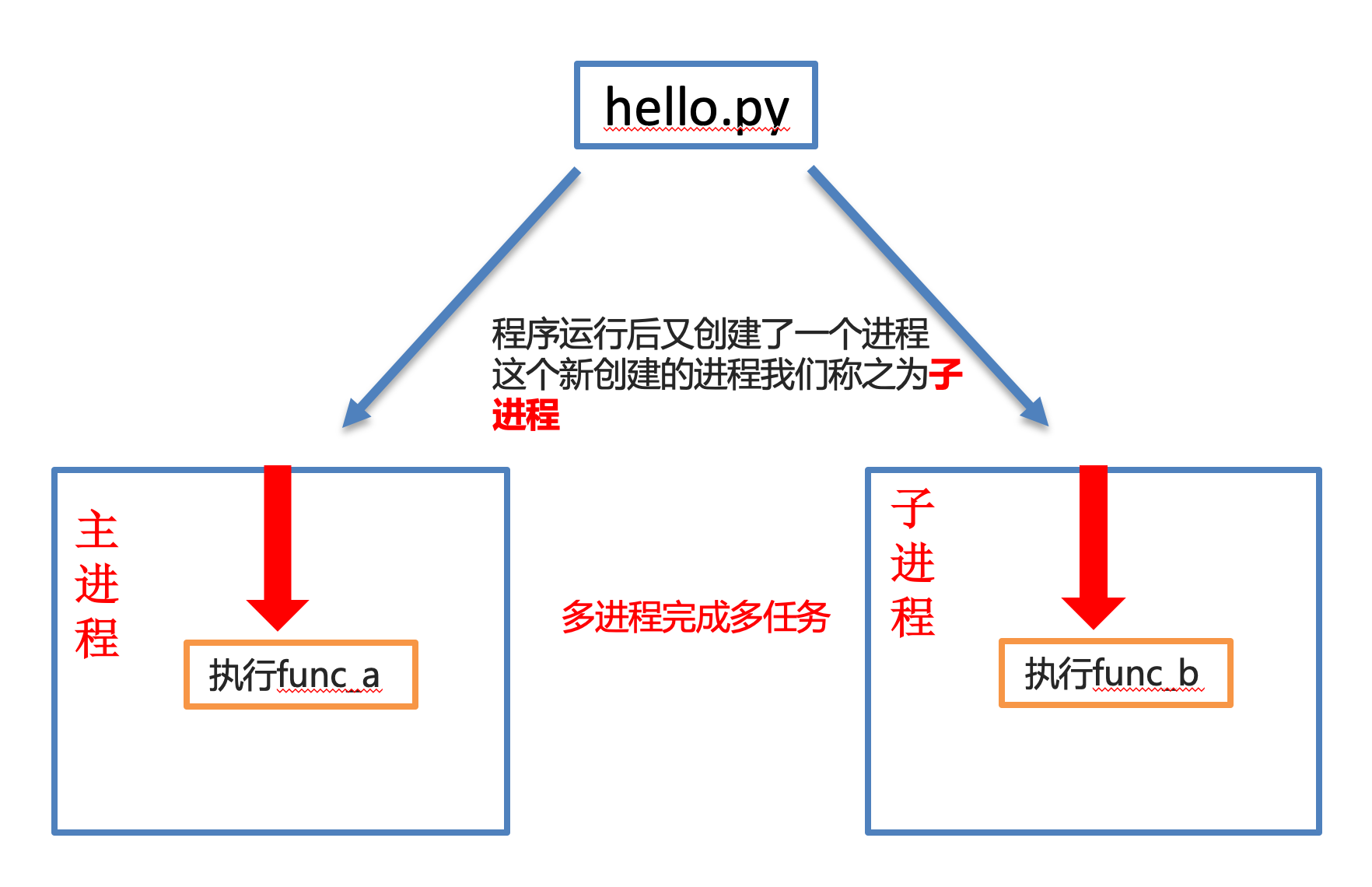
二、多进程完成多任务
1、基本语法
python
① 导入进程包
import multiprocessing
② 通过进程类创建进程对象
进程对象 = multiprocessing.Process()
③ 启动进程执行任务
进程对象.start()2、通过进程类创建进程对象
进程对象 = multiprocessing.Process([group [, target [, name [, args [, kwargs]]]]])参数说明
| 参数名 | 说明 |
|---|---|
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 进程名,一般不用设置 |
| group | 进程组,目前只能使用None |
| args | 以元组的方式给执行任务传参,args表示调用对象的位置参数元组,args=(1,2,'anne',) |
| kwargs | 以字典方式给执行任务传参,kwargs表示调用对象的字典,kwargs= |
3、进程创建与启动的代码
边吃饭边敲代码:
python
import time, multiprocessing
def eat():
for i in range(3):
print(f"{i}:eating~~~")
time.sleep(0.2)
def coding():
for i in range(3):
print(f"{i}:coding~~~")
time.sleep(0.2)
if __name__ == '__main__':
# 创建进程对象
eat_process = multiprocessing.Process(target=eat)
coding_process = multiprocessing.Process(target=coding)
# 启动进程执行任务
eat_process.start()
coding_process.start()
#输出
"""
0:eating~~~
0:coding~~~
1:eating~~~
1:coding~~~
2:eating~~~
2:coding~~~
"""4、进程执行带有参数的任务
注意:args和kwargs不可以同时使用,优先使用kwargs 不按照顺序、根据key获取对应的value
python
import time, multiprocessing
def eat(num, name):
for i in range(num):
print(name)
print(f"{i}:eating~~~")
time.sleep(0.2)
def coding(name,count):
for i in range(count):
print(f"{name}:coding~~~{count}")
time.sleep(0.3)
if __name__ == '__main__':
# 创建进程对象
eat_process = multiprocessing.Process(target=eat, args=(3, "starting multi_process1"))
coding_process = multiprocessing.Process(target=coding, kwargs={"count": 4, "name": "starting multi_process2"})
# 启动进程执行任务
eat_process.start()
coding_process.start()
#输出
"""
starting multi_process1
0:eating~~~
starting multi_process2:coding~~~4
starting multi_process1
1:eating~~~
starting multi_process2:coding~~~4
starting multi_process1
2:eating~~~
starting multi_process2:coding~~~4
starting multi_process2:coding~~~4
"""三、获取当前进程编号
1、进程编号作用
当程序中进程的数量越来越多时 , 如果没有办法区分主进程和子进程还有不同的子进程 , 那么就无法进行有效的进程管理 , 为了方便管理实际上每个进程都是有自己编号的2、两种进程编号
a、获取当前进程编号
getpid()b、获取当前进程的父进程ppid = parent pid
getppid()3、获取当前进程编号
基本语法
python
import os
def work():
# 获取当前进程的编号
print('work进程编号', os.getpid())
# 获取父进程的编号
print('work父进程的编号', os.getppid())
work()案例:获取父进程与子进程编号
python
import time, multiprocessing, os
def eat(num, name):
# 分别获取进程id与父进程id
print(f"pid:{os.getpid()},ppid:{os.getppid()}")
for i in range(num):
print(name)
print(f"{i}:eating~~~")
time.sleep(0.2)
def coding(name, count):
# 分别获取进程id与父进程id
print(f"pid{os.getpid()},ppid:{os.getppid()}")
for i in range(count):
print(f"{name}:coding~~~{count}")
time.sleep(0.3)
if __name__ == '__main__':
# 获取进程id
print(f"main_pid:{os.getpid()}")
# 创建进程对象
eat_process = multiprocessing.Process(target=eat, args=(3, "starting multi_process1"))
coding_process = multiprocessing.Process(target=coding, kwargs={"count": 4, "name": "starting multi_process2"})
# 启动进程执行任务
eat_process.start()
coding_process.start()
#输出
"""
main_pid:20600
pid:11060,ppid:20600
starting multi_process1
0:eating~~~
pid20968,ppid:20600
starting multi_process2:coding~~~4
starting multi_process1
1:eating~~~
starting multi_process2:coding~~~4
starting multi_process1
2:eating~~~
starting multi_process2:coding~~~4
starting multi_process2:coding~~~4
"""四、进程应用注意点
1、进程间不共享全局变量
进程间、主进程与子进程之间,各个子进程之间都不会共享变量
python
import multiprocessing, os, time
my_list = []
def write_list(num):
print(f"writr_list: pid:{os.getpid()} ppid:{os.getppid()}")
for i in range(num):
my_list.append(i)
time.sleep(0.2)
print(f"{os.getpid()}:{my_list}")
def read_list():
print(f"read_list: pid:{os.getpid()} ppid:{os.getppid()}")
time.sleep(1)
print(f"{os.getpid()}:{my_list}")
if __name__ == '__main__':
print(f"main_pid:{os.getpid()}")
write_process = multiprocessing.Process(target=write_list, kwargs={"num": 4})
read_process = multiprocessing.Process(target=read_list)
write_process.start()
read_process.start()
my_list.append("abc")
print(f"{os.getpid()}:{my_list}")
#输出
"""
main_pid:20960
20960:['abc']
writr_list: pid:11192 ppid:20960
read_list: pid:18820 ppid:20960
11192:[0, 1, 2, 3]
18820:[]
"""2、主进程与子进程的结束顺序
主进程结束之后,对应子进程都要结束。默认主进程结束后,子进程不会自动结束,需要认为代码干预
正常情况:主进程需要在子进程执行完成之后再结束。或者主进程结束后,对应的子进程都要自动结束
python
import multiprocessing, time, os
def working(num):
print(f"pid:{os.getpid()},ppid:{os.getppid()}")
for i in range(num):
print("working....")
time.sleep(0.1)
if __name__ == '__main__':
print(f"{os.getpid()} starting...")
work_process = multiprocessing.Process(target=working, kwargs={"num": 4})
work_process.start()
time.sleep(0.2)
print(f"{os.getpid()} end...")
#输出
"""
13456 starting...
13456 end...
pid:11200,ppid:13456
working....
working....
working....
working....
"""如何保证主进程退出子进程销毁
解决方案一:设置守护进程
设置守护主进程,主进程退出后子进程直接销毁,不再执行子进程中的代码
python
import multiprocessing, time, os
def working(num):
print(f"pid:{os.getpid()},ppid:{os.getppid()}")
for i in range(num):
print("working....")
time.sleep(0.1)
if __name__ == '__main__':
print(f"{os.getpid()} starting...")
work_process = multiprocessing.Process(target=working, kwargs={"num": 5})
# 设置守护进程,当主进程出后子进程直接销毁,不再执行子进程中的代码
work_process.daemon = True
# 子进程启动
work_process.start()
time.sleep(0.3)
# 主进程结束
print(f"{os.getpid()} end...")
# 输出:
"""
6936 starting...
pid:13684,ppid:6936
working....
6936 end...
"""解决方案二:销毁子进程
直接在主进程结束前,让子进程直接销毁,表示终止执行
python
import multiprocessing, time, os
def working(num):
print(f"pid:{os.getpid()},ppid:{os.getppid()}")
for i in range(num):
print("working....")
time.sleep(0.1)
if __name__ == '__main__':
# 主进程开始执行
print(f"{os.getpid()} starting...")
work_process = multiprocessing.Process(target=working, kwargs={"num": 5})
# 设置守护进程,当主进程出后子进程直接销毁,不再执行子进程中的代码
# work_process.daemon = True
# 子进程启动
work_process.start()
time.sleep(0.3)
# 让子进程直接销毁,表示终止执行, 主进程退出之前,把所有的子进程直接销毁就可以了
work_process.terminate()
# 主进程结束
print(f"{os.getpid()} end...")
#输出
"""
18792 starting...
pid:21124,ppid:18792
working....
18792 end...
"""多线程
一、线程的概念
1、概念
在Python中,想要实现多任务还可以使用多线程来完成
线程是程序执行的最小单位 , 实际上进程只负责分配资源 , 而利用这些资源执行程序的是线程 。 也就说进程是线程的容器 , 一个进程中最少有一个线程来负责执行程序 。同时线程自己不拥有系统资源,只需要一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源 。这就像通过一个QQ软件(一个进程)打开两个窗口(两个线程)跟两个人聊天一样 , 实现多任务的同时也节省了资源。2、为什么使用线程?
进程是分配资源的最小单位 , 一旦创建一个进程就会分配一定的资源 , 就像跟两个人聊QQ就需要打开两个QQ软件一样是比较浪费资源的 .3、多线程的作用
用比较小的资源消耗,多个任务一起执行,从而提高执行效率单线程执行
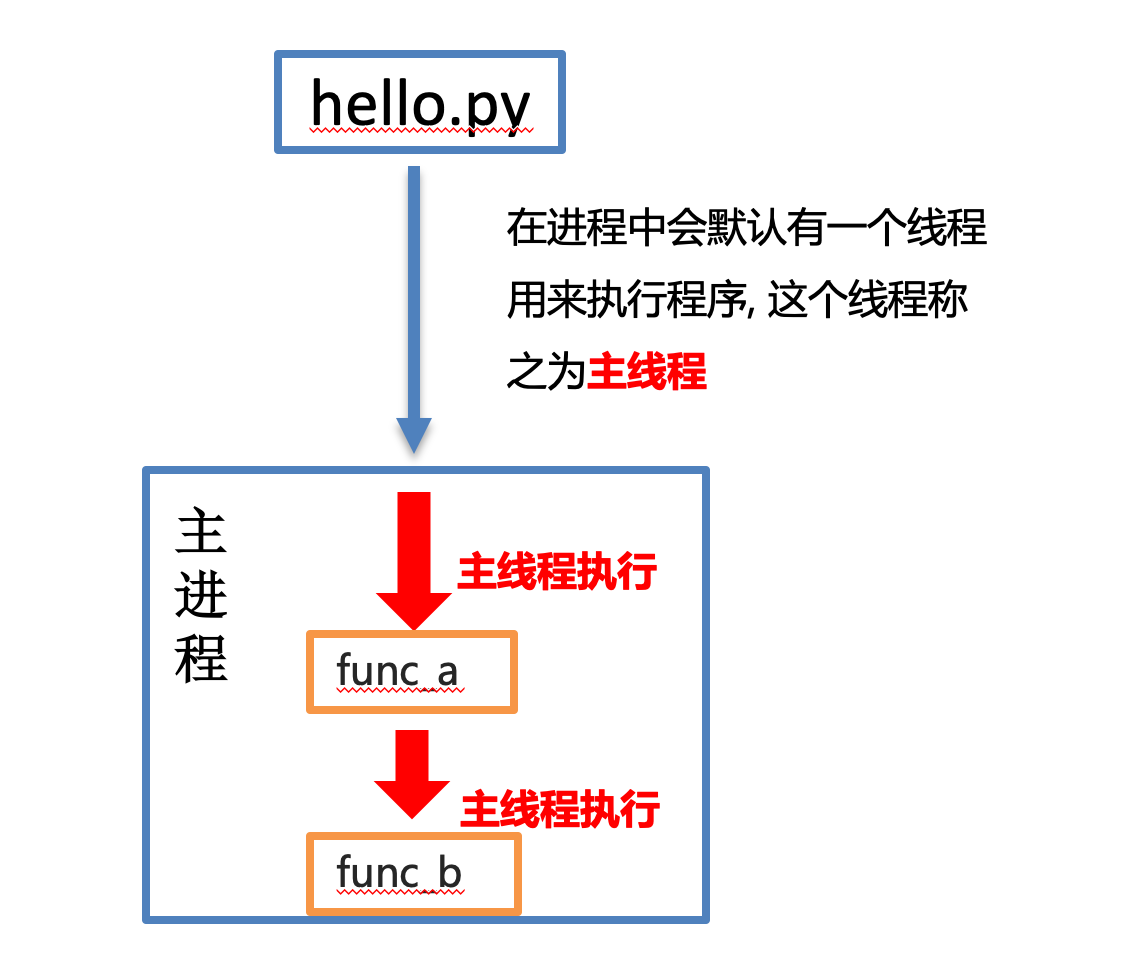
多线程执行
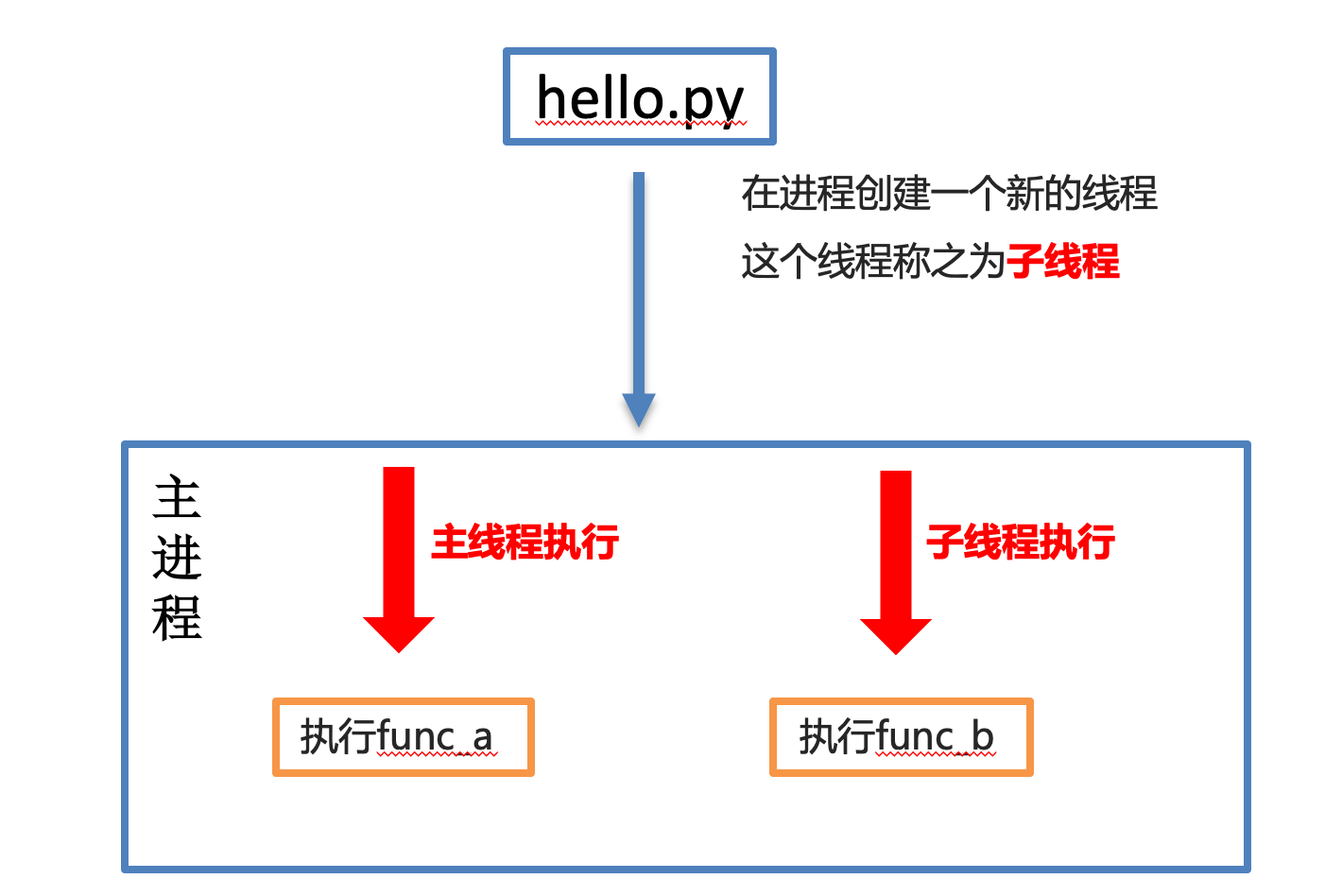
二、多线程完成多任务
1、多线程完成多任务
python
① 导入线程模块
import threading
② 通过线程类创建线程对象
线程对象 = threading.Thread(target=任务名)
② 启动线程执行任务
线程对象.start()| 参数名 | 说明 |
|---|---|
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 线程名,一般不用设置 |
| group | 线程组,目前只能使用None |
2、线程创建与启动代码
单线程案例:
python
def walk(num):
for i in range(num):
print(f"{i} walking....")
time.sleep(0.2)
def music(num):
for i in range(num):
print(f"{i} listening....")
time.sleep(0.1)
walk(num=4)
music(num=3)
# 输出
"""
0 walking....
1 walking....
2 walking....
3 walking....
0 listening....
1 listening....
2 listening....
"""多线程案例:
python
import threading, time
def walk(num):
for i in range(num):
print(f"{i} walking....")
time.sleep(0.2)
def music(num):
for i in range(num):
print(f"{i} listening....")
time.sleep(0.1)
if __name__ == '__main__':
# 创建线程对象
walk_thread = threading.Thread(target=walk, kwargs={"num":4})
music_thread = threading.Thread(target=music, kwargs={"num":3})
# 启动线程
walk_thread.start()
music_thread.start()
#输出:
"""
0 walking....
0 listening....
1 listening....
1 walking....
2 listening....
2 walking....
3 walking....
"""3、线程执行带有参数的任务
| 参数 | 说明 |
|---|---|
| args | 以元组的方式给执行任务传参 |
| kwargs | 以字典方式给执行任务传参 |
python
import threading, time
def walk(num):
for i in range(num):
print(f"{i} walking....")
time.sleep(0.2)
def music(num):
for i in range(num):
print(f"{i} listening....")
time.sleep(0.1)
if __name__ == '__main__':
# 创建线程对象
walk_thread = threading.Thread(target=walk, args=(4,))
music_thread = threading.Thread(target=music, kwargs={"num":3})
# 启动线程
walk_thread.start()
music_thread.start()
# 输出
"""
0 walking....
0 listening....
1 listening....
1 walking....
2 listening....
2 walking....
3 walking....
"""4、主线程和子线程的结束顺序
默认主线程(进程启动时,会默认启动一个线程),子线程会继续执行。但是正常使用场景,需要主进程结束之后,对应的子线程也需要以及关闭,这个需要代码去手动干预
python
import threading, time
def show(num):
for i in range(num):
print(f"{threading.current_thread().name} excuted {i+1} time.")
time.sleep(0.1)
if __name__ == '__main__':
print(f"{threading.current_thread().name} starting...")
show_thread = threading.Thread(target=show, args=(4,))
show_thread.start()
print(f"{threading.current_thread().name} end.")
# 输出
"""
MainThread starting...
Thread-1 (show) excuted 1 time.
MainThread end.
Thread-1 (show) excuted 2 time.
Thread-1 (show) excuted 3 time.
Thread-1 (show) excuted 4 time.
"""设置守护线程方式一
threading.Thread(target=show, args=(4,), daemon=True) # 创建线程时添加daemon守护线程
python
import threading, time
def show(num):
for i in range(num):
print(f"{threading.current_thread().name} excuted {i+1} time.")
time.sleep(0.1)
if __name__ == '__main__':
print(f"{threading.current_thread().name} starting...")
show_thread = threading.Thread(target=show, args=(4,), daemon=True)
show_thread.start()
print(f"{threading.current_thread().name} end.")
# 输出
"""
MainThread starting...
Thread-1 (show) excuted 1 time.
MainThread end.
"""设置守护线程方式二
线程对象.setDaemon(True) 该方法已废弃
可以使用:warnings.filterwarnings(action="ignore",category=DeprecationWarning) 进行忽略,需要导入warnings包
python
import threading, time
def show(num):
for i in range(num):
print(f"{threading.current_thread().name} excuted {i+1} time.")
time.sleep(0.1)
if __name__ == '__main__':
print(f"{threading.current_thread().name} starting...")
show_thread = threading.Thread(target=show, args=(4,))
show_thread.setDaemon(True)
show_thread.start()
print(f"{threading.current_thread().name} end.")
# 输出
"""
MainThread starting...
Thread-1 (show) excuted 1 time.
MainThread end.
"""5、线程间的执行顺序
线程之间执行是无序的,是由CPU调度决定某个线程先执行的
python
for i in range(5):
sub_thread = threading.Thread(target=task)
sub_thread.start()当我们在进程中创建了多个线程,其线程之间是如何执行的呢?按顺序执行?一起执行?还是其他的执行方式呢?
线程之间的执行是无序的,验证
python
import threading, time
def show():
time.sleep(0.1)
print(f"{threading.current_thread().name}:excuting....")
if __name__ == '__main__':
for i in range(10):
show_thread = threading.Thread(target=show)
show_thread.start()
# 输出
"""
Thread-2 (show):excuting....
Thread-3 (show):excuting....
Thread-1 (show):excuting....
Thread-7 (show):excuting....
Thread-10 (show):excuting....
Thread-8 (show):excuting....
Thread-6 (show):excuting....
Thread-5 (show):excuting....
Thread-4 (show):excuting....
Thread-9 (show):excuting....
Process finished with exit code 0
"""获取当前线程信息
threading.current_thread().native_id # 获取当前线程id
threading.current_thread().name # 获取当前线程名称
python
import threading, time, os
def walk(num):
print(f"walk`s pid:{os.getpid()}")
print(f"walk thread:{threading.current_thread().native_id},{threading.current_thread().name}")
for i in range(num):
print(f"{i} walking....")
time.sleep(0.2)
def music(num):
print(f"music`s pid:{os.getpid()}")
print(f"music thread:{threading.current_thread().native_id},{threading.current_thread().name}")
for i in range(num):
print(f"{i} listening....")
time.sleep(0.1)
if __name__ == '__main__':
print(f"main`s pid:{os.getpid()}")
print(f"main thread:{threading.current_thread().native_id},{threading.current_thread().name}")
# 创建线程对象
walk_thread = threading.Thread(target=walk, args=(4,))
music_thread = threading.Thread(target=music, kwargs={"num":3})
# 启动线程
walk_thread.start()
music_thread.start()
# 输出
"""
main`s pid:13280
main thread:15092,MainThread
walk`s pid:13280
walk thread:16660,Thread-1 (walk)
0 walking....
music`s pid:13280
music thread:10944,Thread-2 (music)
0 listening....
1 listening....
1 walking....
2 listening....
2 walking....
3 walking....
"""6、线程间共享全局变量
多个线程都是在同一个进程中 , 多个线程使用的资源都是同一个进程中的资源 ,因此多线程间是共享全局变量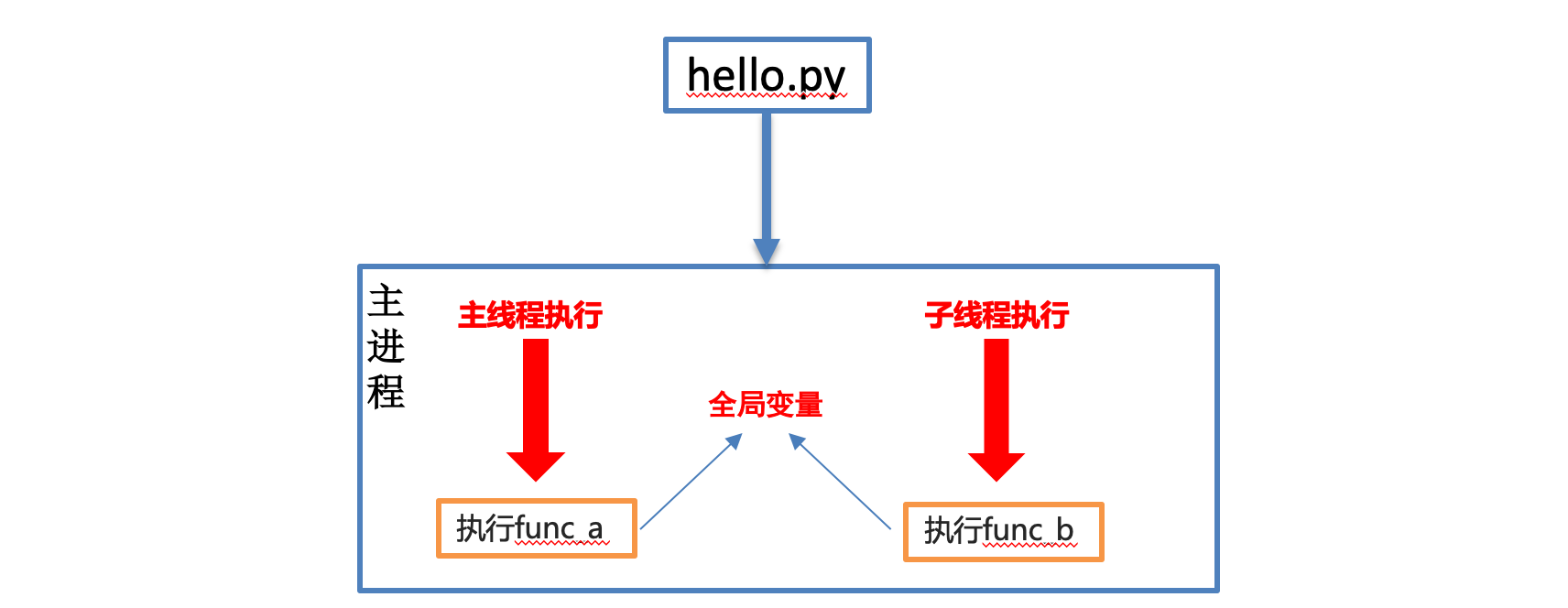
示例代码:
python
import threading, os, time
my_list = []
def write_list(num):
for i in range(num):
my_list.append(i)
print(f"write_list:{my_list}")
def read_list():
time.sleep(0.2)
print(f"read_list:{my_list}")
if __name__ == '__main__':
write_thread = threading.Thread(target=write_list, args=(4,))
read_thread = threading.Thread(target=read_list)
write_thread.start()
read_thread.start()
print(f"main:{my_list}")
# 输出
"""
write_list:[0, 1, 2, 3]
main:[0, 1, 2, 3]
read_list:[0, 1, 2, 3]
"""7、线程间共享变量存在问题------多个线程同时更改某个变量------互斥锁
线程互斥锁:
Python 线程互斥锁通过封装操作系统的原生互斥量,提供了线程间的排他性访问控制。其核心目的是保护共享资源免受竞态条件影响。
在实际开发中,应优先使用 with lock: 语法来确保锁的安全释放
并合理设计锁粒度以平衡安全性与性能。作用
在多个线程同时调用全局共享变量时,防止因python自带GIL失败(数据量过大时),可能在字节码执行间隙发生线程切换,导致数据竞争,导致多个线程同时修改数据引发的冲突基本语法:
lock = threading.Lock() # 创建互斥锁对象
lock.acquire() #添加互斥锁,在调用全局变量前
lock.release() # 释放锁,在调用全局变量后
python
import threading, time
lock = threading.Lock()
nums = 0
def add1():
lock.acquire()
global nums
for i in range(1000000):
nums += 1
lock.release()
print(nums)
def add2():
lock.acquire()
global nums
for i in range(1000000):
nums += 1
lock.release()
print(nums)
if __name__ == '__main__':
add1_thread = threading.Thread(target=add1)
add2_thread = threading.Thread(target=add2)
add1_thread.start()
add2_thread.start()线程互斥锁与 GIL(全局解释器锁) 的关系:
Python 的全局解释器锁(GIL)仅保护解释器内部状态(如内存管理),不保护用户数据。
即使有 GIL,像 counter += 1 这样的复合操作(读取-修改-写入)仍可能在字节码执行间隙发生线程切换,导致数据竞争。因此,必须使用 Lock显式同步用户级的共享状态。关键特性
互斥锁具备以下三个关键特性,以确保同步的正确性:
原子性(Atomicity):获取锁和释放锁的操作本身是不可中断的原子操作,确保锁状态转换的正确性。
排他性(Exclusivity):同一时间只允许一个线程持有锁并访问受保护的共享资源。
所有者原则(Ownership):通常只有获取锁的线程才能释放它,防止其他线程错误地释放锁导致逻辑混乱。使用注意事项与最佳实践
A.避免死锁(Deadlock)
死锁是指两个或多个线程互相等待对方持有的锁,导致程序永久停滞。常见原因:
锁未释放:例如在异常发生时未执行 release()。
嵌套锁顺序不一致:线程 A 先锁 L1 再锁 L2,线程 B 先锁 L2 再锁 L1。
解决方案:
使用 with 语句(上下文管理器),确保无论是否发生异常,锁都会被自动释放。
固定锁的获取顺序。
B. 推荐使用 with 语句
手动调用 acquire() 和 release() 容易因遗漏释放或异常中断而导致死锁。Python 推荐利用上下文管理器协议:
python
import threading
lock = threading.Lock()
shared_data = []
# ✅ 推荐方式:自动处理锁的获取与释放
with lock:
shared_data.append("item")
# 即使此处发生异常,锁也会被正确释放C. 锁粒度(Granularity)
建议:仅对必要的"读-改-写"复合操作加锁,避免在持有锁期间执行耗时操作(如网络请求、文件IO)锁太粗 :会严重限制并发性能,使多线程退化为串行执行。
锁太细:增加管理开销,且容易引发复杂的死锁问题。
三、进程和线程对比
1、关系对比
a、线程是依附在进程里面的,没有进程就没有线程
b、 一个进程默认提供一条线程,进程可以创建多个线程2、区别对比
① 进程之间不共享全局变量
② 同一进程下的线程之间共享全局变量
③ 创建进程的资源开销要比创建线程的资源开销要大
④ 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位3、优缺点对比
进程优缺点:
优点:可以用多核
缺点:资源开销大线程优缺点
优点:资源开销小
缺点:不能使用多核多协程
一、python中的迭代器和生成器
迭代器
一个实现了 __iter__() 和 __next__() 方法的对象,就是迭代器
特点:
适用于处理大数据、无限序列、流式数据,不占内存
惰性计算:数据不是一次性全部生成出来,而是使用一个,再生成一个,可以节约大量的内存,可以记住遍历位置
遍历一次就耗尽,不能重复使用实现原理
__iter__():返回迭代器对象自身(通常return self)。
__next__():返回下一个元素,若无元素则抛出StopIteration异常。
for循环底层机制:先调用iter()获取迭代器,再反复调用next()直到捕获异常使用场景
1. 处理超大文件 / 大数据(不爆内存)
普通列表会把所有数据加载进内存,迭代器 / 生成器一行行读。
python
def read_large_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
yield line.strip()2、无限序列(无法用列表实现)
比如无限自然数、无限斐波那契数列:(可以根据需求生成)
python
def infinite_nums():
num = 0
while True:
yield num
num += 13、管道式数据处理(流式处理)
全程不占内存,用到才计算。
python
nums = (i for i in range(10000))
even = (i for i in nums if i % 2 == 0)
square = (i*i for i in even)4、节省内存的遍历
比如只需要遍历一次的序列,优先用生成器,不用列表。
生成器
用 yield 关键字 或生成器表达式创建的特殊迭代器
特点:
数据不是一次性全部生成出来,而是使用一个,再生成一个,可以节约大量的内存
执行到 yield 暂停,下次调用从暂停处继续
代码更简洁,不用手动写 __iter__ 和 __next__
本质还是迭代器,只是写法更优雅创建生成器
a、生成器推导式
语法类似于列表推导式,但使用圆括号 () 代替方括号 []
python
# 列表推导式:立即创建整个列表,占用内存
lis = [x * x for x in range(5)]
# 生成器表达式:创建生成器对象,惰性计算
gen = (x * x for x in range(5))
for g in gen:
print(g)支持next()调用
python
gen = (x * x for x in range(5))
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
# 输出
"""
0
1
4
9
"""注意:Python 中没有"元组生成式",(x for x in range(5)) 是生成器表达式,而非元组
b、yield 关键字
代码执行到 yield 会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
python
def generator(n):
for i in range(n):
print('开始生成...')
yield i
print('完成一次...')
print(generator())
g = generator(5)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g)) -----> 正常
print(next(g)) -----> 报错注意点:
① 代码执行到 yield 会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
② 生成器如果把数据生成完成,再次获取生成器中的下一个数据会抛出一个StopIteration 异常,表示停止迭代异常
③ while 循环内部没有处理异常操作,需要手动添加处理异常操作
④ for 循环内部自动处理了停止迭代异常,使用起来更加方便,推荐大家使用。
yield关键字和return关键字
有return的函数直接返回所有结果,程序终止不再运行,并销毁局部变量;
而有yield的函数则返回一个可迭代的 generator(生成器)对象,你可以使用for循环或者调用next()方法遍历生成器对象来提取结果。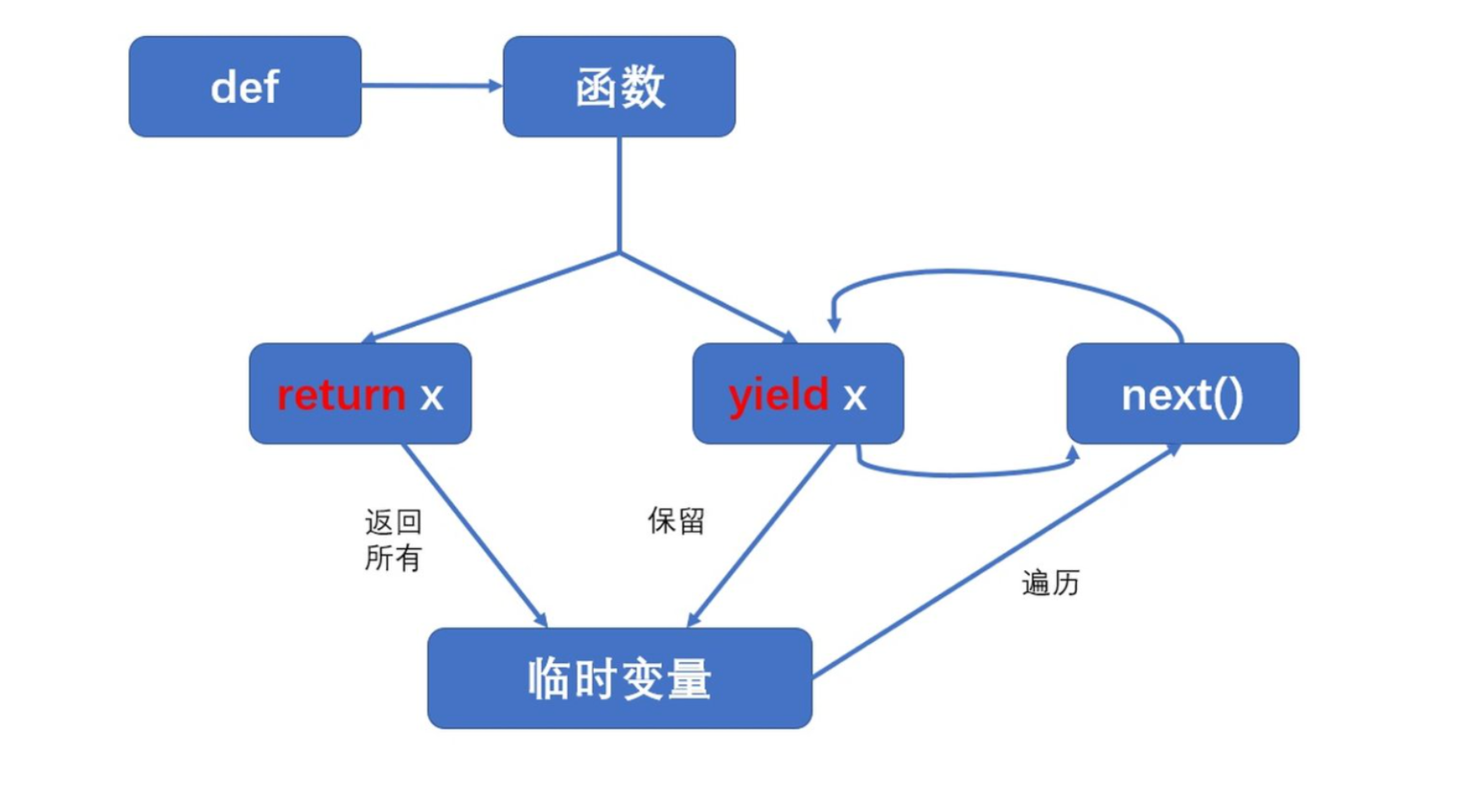
yield代码示例:
python
def example():
x = 1
y = 10
while x < y:
yield x
x += 1
print(example())
exp = example()
# print(next(exp))
# print(next(exp))
# print(next(exp))
# print(next(exp))
for i in exp:
print(i)
# 输出
"""
1
2
3
4
5
6
7
8
9
"""return:会直接终结循环
python
def example():
x = 1
y = 10
while x < y:
return x
x += 1
print(example())
#输出: 1使用场景示例------生成指定数目的斐波那契数
python
def fibonacci_generator(n):
"""
使用生成器产生前n个斐波那契数
:param n: 需要生成的斐波那契数的个数
:yield: 下一个斐波那契数
"""
a, b = 0, 1
count = 0
while count < n:
yield a
a, b = b, a + b
count += 1
if __name__ == "__main__":
# 获取前10个斐波那契数
num_terms = 10
print(f"前 {num_terms} 个斐波那契数列:")
for number in fibonacci_generator(num_terms):
print(number, end=" ")
print() # 换行
# 演示生成器的惰性求值和内存优势
print("\n使用next()逐个获取:")
fib_gen = fibonacci_generator(5)
try:
while True:
print(next(fib_gen), end=" ")
except StopIteration:
print("\n生成器已耗尽")二、Python中的协程
通过程序代码控制,在执行需要等待的、异步任务时,主动让出控制器,让调度器去执行其它线程,
协程是由 async def 定义的异步函数,它是一种实现了 Awaitable 协议的状态保持执行单元。其执行由事件循环调度,通过 await 表达式主动挂起,将控制权交还调度器,实现协作式并发
Python 的协程实现是从生成器发展而来的。一句话总结: 协程让 I/O 等待时不闲着,去干其他事!
| 特性 | 生成器 (Generator) | 协程 (Coroutine) |
|---|---|---|
| 主要目的 | 生成值序列 | 执行异步任务 |
| 控制流 | 单向:调用者 → 生成器 | 双向:调用者 ↔ 协程 |
| 数据流向 | 数据向外流动(产出值) | 数据双向流动(发送和接收) |
| 调度 | 由调用者驱动 | 由事件循环调度 |
| 关键字 | yield | async, await |
| 类型 | Generator | Coroutine |
协程三要素:
函数前加 async
等待处加 await
启动用 asyncio.run使用三步骤:
定义 async 函数:需要协程,执行等待的函数,必须添加。
用 create_task 创建任务
用 await 等待结果:当任务执行异步任务,需要等待时,主动让出控制权,让I/O去干其它事
python
import asyncio
async def out_time(name):
print(f"starting....{name}")
await asyncio.sleep(1) # 异步任务,需要等待
print(f"ending...{name}")
# asyncio.run(out_time(1))
async def main_app():
# 创建任务
s1 = asyncio.create_task(out_time("see hello"))
s2 = asyncio.create_task(out_time(name="see byebye"))
# 让出控制权,在程序等待期间
await s1
await s2
asyncio.run(main_app())
# 输出:
"""
starting....see hello
starting....see byebye
ending...see hello
ending...see byebye
"""批量调度------asyncio.gather实现并发调度多个协程
统一启动或等待已启动的任务
与create_task方式区别:create更加精细,gather实现同一管理,会并发调度多个协程,并等待它们全部完成
python
import time, asyncio, threading, multiprocessing
async def async_request_demo(deploy,name):
await asyncio.sleep(deploy)
return f'{name} complete!'
async def async_task():
start_time = time.time()
await asyncio.gather( # gather 会并发调度多个协程,并等待它们全部完成
async_request_demo(deploy=1, name="task 7"),
async_request_demo(deploy=1, name="task 8")
)
print(f"async_task spent {time.time() - start_time}")
async def async_task2():
start_time = time.time()
s1 = asyncio.create_task(async_request_demo(deploy=1,name="task 9"))
s2 = asyncio.create_task(async_request_demo(deploy=1,name="task 10"))
await s1
await s2
print(f"async_task2 spent {time.time() - start_time}")
if __name__ == '__main__':
asyncio.run(async_task())
asyncio.run(async_task2())
#输出:
"""
async_task spent 1.0001697540283203
async_task2 spent 1.0107088088989258
"""问题:
1、为什么不使用time.sleep() ?
time.sleep() 需要同步执行,执行完成之后才能执行之后的内容。不能异步执行,程序过一段时间之后来拿结果就行。
所以await时,需要使用await asyncio.sleep() 去模拟需要等待的异步请求
2、为什么下边代码会报错,不能直接调用执行out_time("see hello")?
python
import asyncio
async def out_time(name):
print(f"starting....{name}")
await asyncio.sleep(1) # 异步任务,需要等待,主动让出控制权
print(f"ending...{name}")
async def main_app():
out_time("see hello")
out_time("see byebye")
asyncio.run(main_app())a、协程对象不会自动执行:
在 Python 中,调用一个由 async def 定义的函数(如 out_time("see hello"))不会立即执行函数体内的代码,而是返回一个协程对象 (Coroutine Object)。
b、必须显式调度或等待:
这个返回的协程对象必须被"消费"掉,通常有两种方式:
使用 await 关键字:暂停当前协程,直到被调用的协程执行完毕。
使用 asyncio.create_task():将协程包装为 Task 对象,提交给事件循环并发执行。
由于这两个协程对象从未被 await 或调度,Python 垃圾回收时会检测到它们未被等待,从而抛出 RuntimeWarning。此外,因为没有被调度,print 语句实际上也永远不会执行。
python中的异步操作都有那些,那些可以支持让出控制权?
异步 I/O 操作 (Async I/O)
这是异步编程最主要的应用场景。当协程等待网络请求、文件读写或数据库查询时,底层驱动会注册回调并让出控制权,直到 I/O 操作完成。网络请求:如使用 aiohttp 发起 HTTP 请求
python
async with session.get(url) as response:
data = await response.json() # 等待网络响应,期间让出控制权异步文件/数据库操作:如使用 asyncpg、aiomysql 或异步文件库
三、协程 vs 线程 vs 进程区别
1、最全对比
| 对比项 | 协程 | 线程 | 进程 |
|---|---|---|---|
| 创建数量 | 轻松上万 | 最多几百 | 最多几十 |
| 适用场景 | I/O操作多(网络、文件) | I/O操作多 | 计算密集 |
| 内存占用 | 很小(几KB) | 较大(几MB) | 很大(几十MB) |
| 数据共享 | 直接共享 | 小心共享(加锁) | 不能直接共享 |
| 一句话总结 | 单线程内切换做事 | 看起来同时做事 | 真正同时做事 |
2、应用场景对比
python
# 选择指南:
if 主要是网络请求 or 文件读写: # I/O密集型
用协程 # 最佳选择
elif 主要是数学计算: # CPU密集型
用多进程 # 绕过GIL
else: # 简单的后台任务
用多线程 # 简单易用3、最简记忆法:
协程:单线程魔术师,手里抛接多个球(I/O等待时换件事做)
线程:多个魔术师,但只有一个能表演(GIL限制)
进程:多个魔术师,各自独立表演 (完全独立)
4、模拟请求------对比进程、线程、进程、协程执行时间
python
import time, asyncio, threading, multiprocessing
# 模拟网络请求
def request_demo(deploy,name):
time.sleep(deploy)
return f'{name} complete!'
async def async_request_demo(deploy,name):
await asyncio.sleep(deploy)
return f'{name} complete!'
# 同步任务实现
def syn_task():
start_time = time.time()
request_demo(deploy=1,name="task 1")
request_demo(deploy=1,name="task 2")
print(f"syn_task spent {time.time() - start_time}")
# 多进程实现
def multiprocess_task():
start_time = time.time()
task5_process = multiprocessing.Process(target=request_demo, kwargs={"deploy": 1, "name": "task 5"})
task6_process = multiprocessing.Process(target=request_demo, kwargs={"deploy": 1, "name": "task 6"})
task5_process.start()
task6_process.start()
task6_process.join()
task5_process.join()
print(f"multiprocess_task spent {time.time() - start_time}")
# 多线程实现
def thread_task():
start_time = time.time()
task3_thread = threading.Thread(target=request_demo, kwargs={"deploy": 1, "name": "task 3"})
task4_thread = threading.Thread(target=request_demo, kwargs={"deploy": 1, "name": "task 4"})
task3_thread.start()
task4_thread.start()
# 等待线程任务结束
task3_thread.join()
task4_thread.join()
print(f"thread_task spent {time.time() - start_time}")
# 多协程实现
async def async_task():
start_time = time.time()
await asyncio.gather(
async_request_demo(deploy=1, name="task 7"),
async_request_demo(deploy=1, name="task 8")
)
print(f"async_task spent {time.time() - start_time}")
async def async_task2():
start_time = time.time()
s1 = asyncio.create_task(async_request_demo(deploy=1,name="task 9"))
s2 = asyncio.create_task(async_request_demo(deploy=1,name="task 10"))
await s1
await s2
print(f"async_task2 spent {time.time() - start_time}")
if __name__ == '__main__':
syn_task()
thread_task()
multiprocess_task()
asyncio.run(async_task())
asyncio.run(async_task2())
# 输出:
"""
syn_task spent 2.001189708709717
thread_task spent 1.0030460357666016
multiprocess_task spent 1.3180301189422607
async_task spent 1.003774642944336
async_task2 spent 1.0120794773101807
"""