OpenClaw 人格工程实战:从默认模板到专属 AI 助手的 7 步调教法
我用 OpenClaw 第一周的时候,它每次对话都要重新解释一遍我的代码风格偏好,烦得不行。第二周我开始认真研究 SOUL.md 和 USER.md,花了一个下午调整配置。第三周,它已经能记住"我讨厌 class 继承链"这件事了。差距就这么拉开了。
先说结论
OpenClaw("小龙虾",GitHub 315K+ Stars)最让我惊喜的不是它多强大,而是它的人可塑性------你可以通过几个 Markdown 文件,把一个通用 AI 捏成你自己想要的样子。SOUL.md、USER.md、AGENTS.md、MEMORY.md,这几个文件就是你的"调教工具箱"。
但问题是,很多人(包括一周前的我)只是往这些文件里填了个模板就完事了。用了一阵子发现 AI 还是"不太对",就怪框架不好。其实不是框架的问题,是调教方法不对。
这篇文章记录了我从"填模板"到"真正用起来"的完整过程,整理成了 7 个步骤(外加一个部署前置步骤)。每一步都有我自己踩过的坑和最终的配置,希望能帮你少走弯路。
第零步:先在腾讯云上把 OpenClaw 跑起来
调教的前提是先得有一个跑着的 OpenClaw 实例。我选的是腾讯云轻量应用服务器(Lighthouse),理由很简单:官方有预装 OpenClaw 的应用模板,不需要自己折腾环境,几分钟就能用上。下面介绍两种部署方式,按需选择。
方式一:Lighthouse 一键模板部署(推荐新手)
这是最省事的路线,不需要任何 Linux 经验。
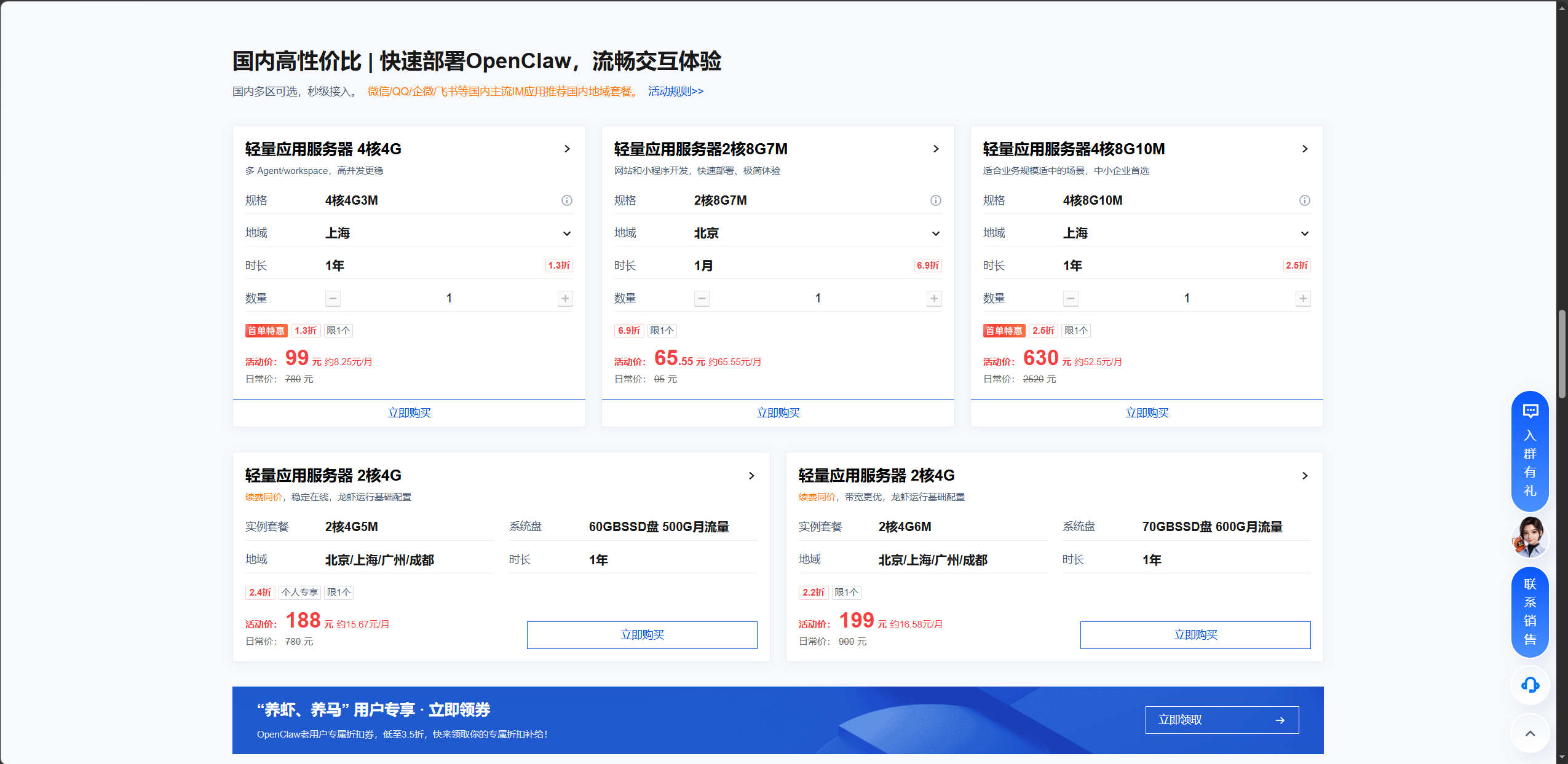
1. 购买服务器
打开腾讯云 OpenClaw 活动页面:cloud.tencent.com/act/pro/openclaw,点击"立即购买"。在应用模板选择器中:
应用模板 → AI Agent → OpenClaw (Clawdbot)

地域选择上有个小讲究:
- 接入微信/QQ/飞书/钉钉 → 选国内(广州/上海)
- 接入 Telegram/WhatsApp/Discord → 选海外(东京/新加坡)
配置方面,官方推荐最低 2 核 4GB 。我实测 2 核 2GB 也能跑起来,但跑复杂任务时会明显卡顿。如果预算允许,4 核 4GB 体验会好很多。促销价大约 38-99 元/年,标准 2 核 4GB 约 288 元/年。
2. 访问管理面板
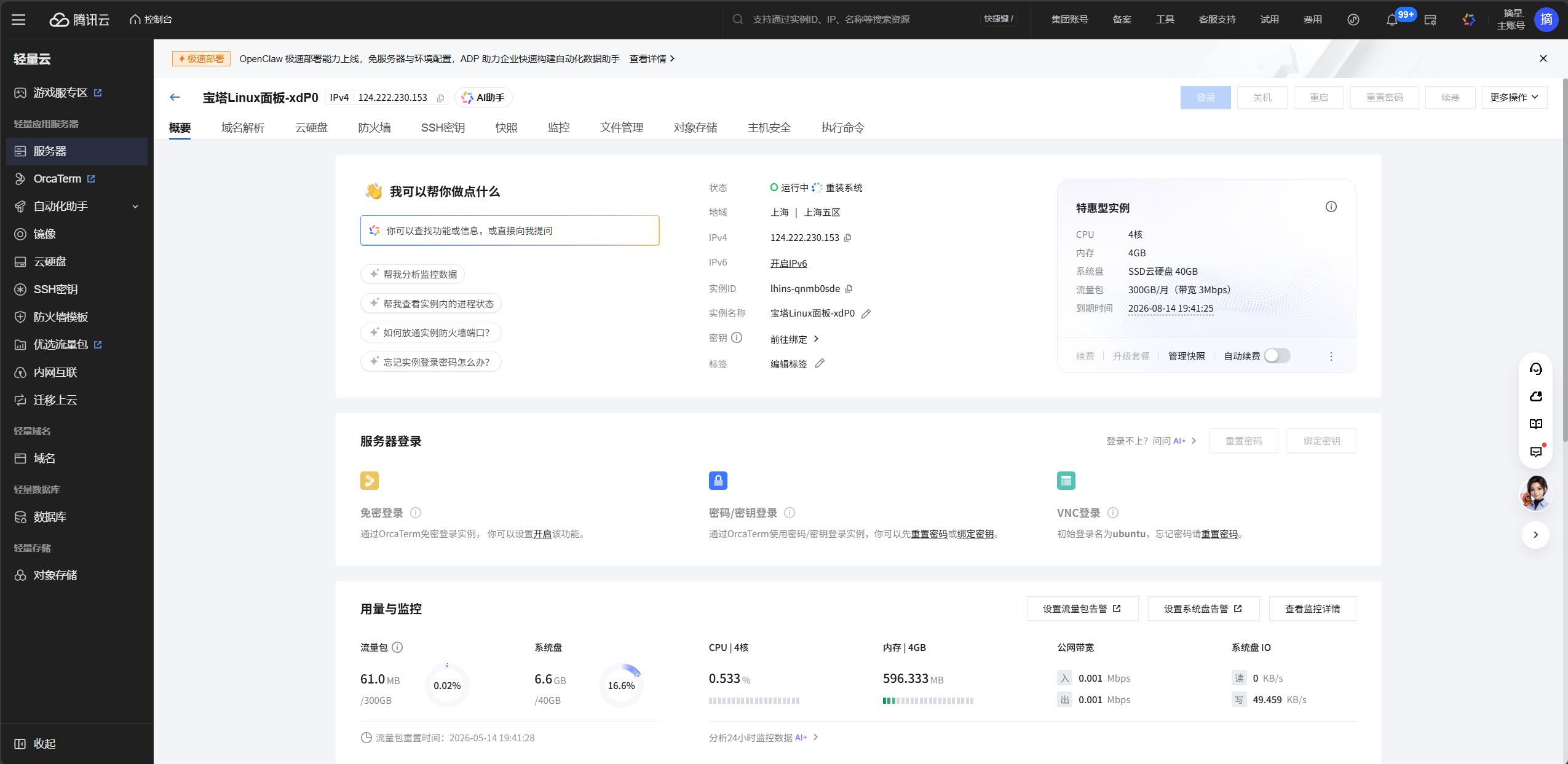
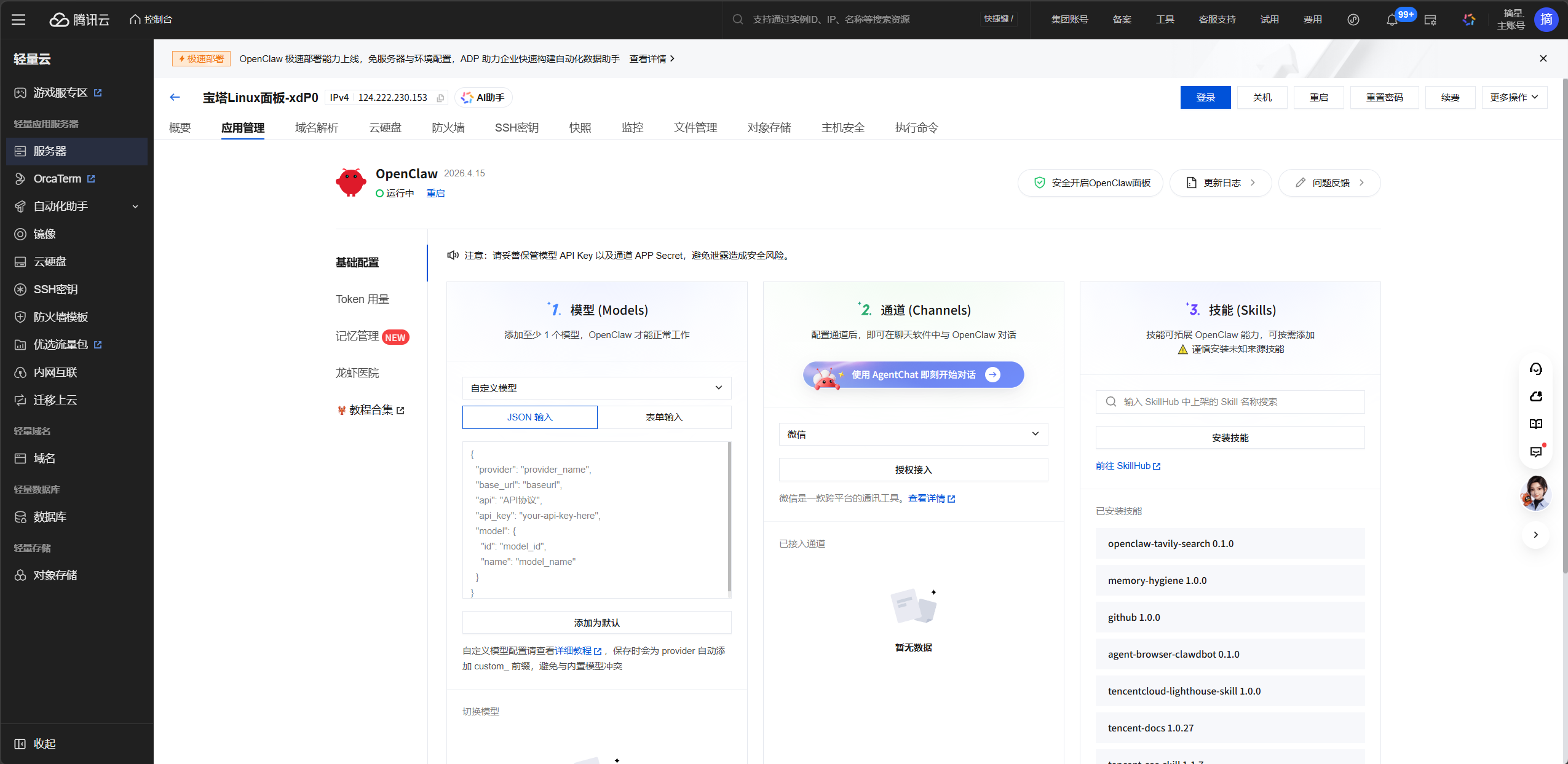
购买完成后,大约 30 秒内自动部署完毕。在轻量应用服务器控制台找到你的实例,点击"应用管理"标签页,就能看到 OpenClaw 的管理入口和初始 Token。通过 http://<你的公网IP>:18789/#token=你的Token值 访问 Web 管理界面。
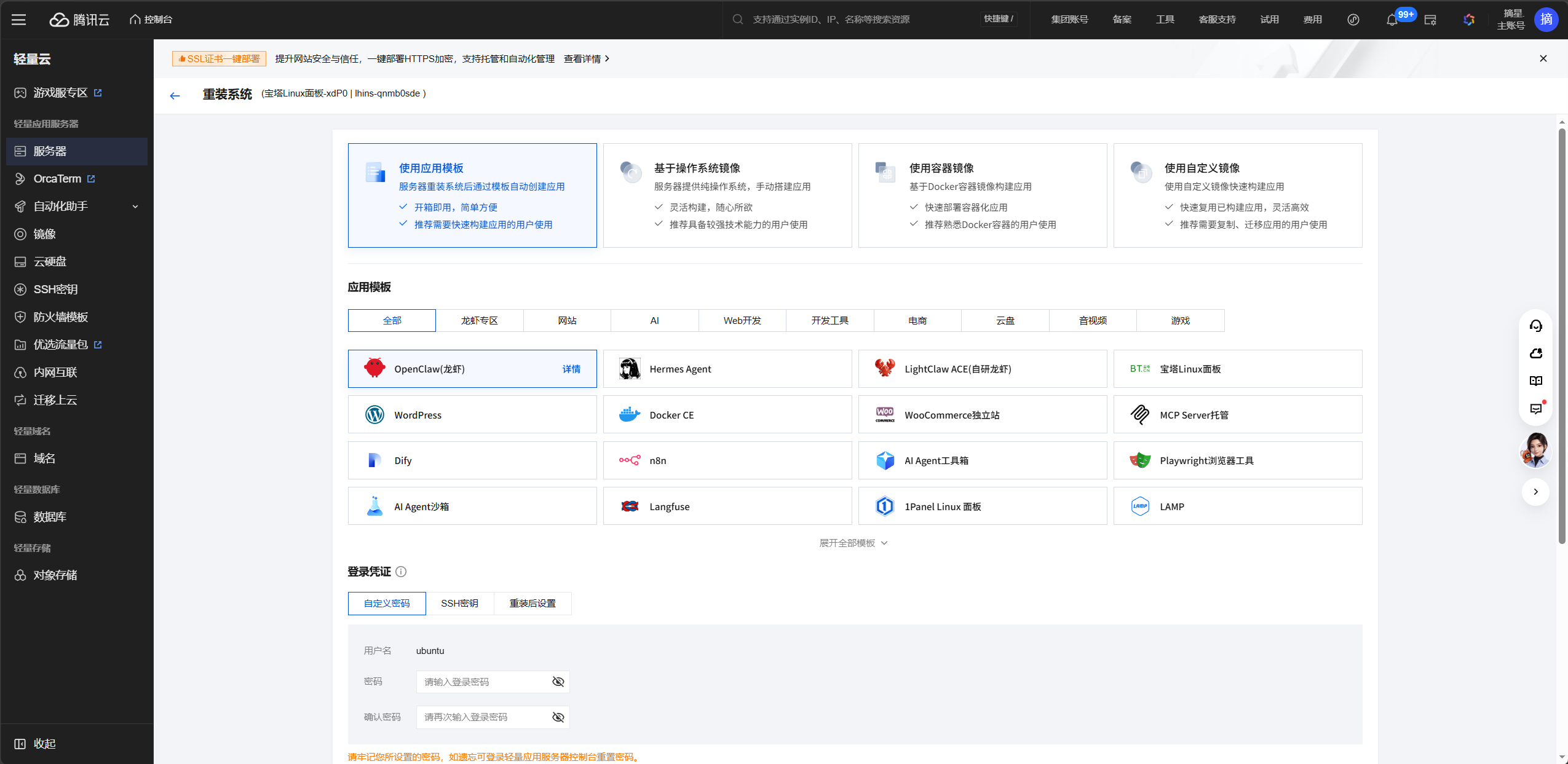
如果你之前已经有一台轻量服务器,也可以在控制台点"重装系统",选择 OpenClaw 应用模板来一键安装,不需要重新购买。
这里我之前已经买过了轻量服务器,所以选择OpenClaw 应用模板来重装系统,无需任何操作,直接一键安装!
3. 配置模型
进入管理面板后第一件事是配置模型。有几个选择:
|------------------------------|------|-------------|
| 模型方案 | 费用 | 特点 |
| DeepSeek-V3.2(通过 NVIDIA API) | 免费 | 免费额度有限,适合体验 |
| 阿里百炼 Qwen3.5-Plus | 按量计费 | 性价比高,中文能力强 |
| 腾讯云 TokenHub 混元/GLM-5 | 按量计费 | 腾讯生态集成好 |
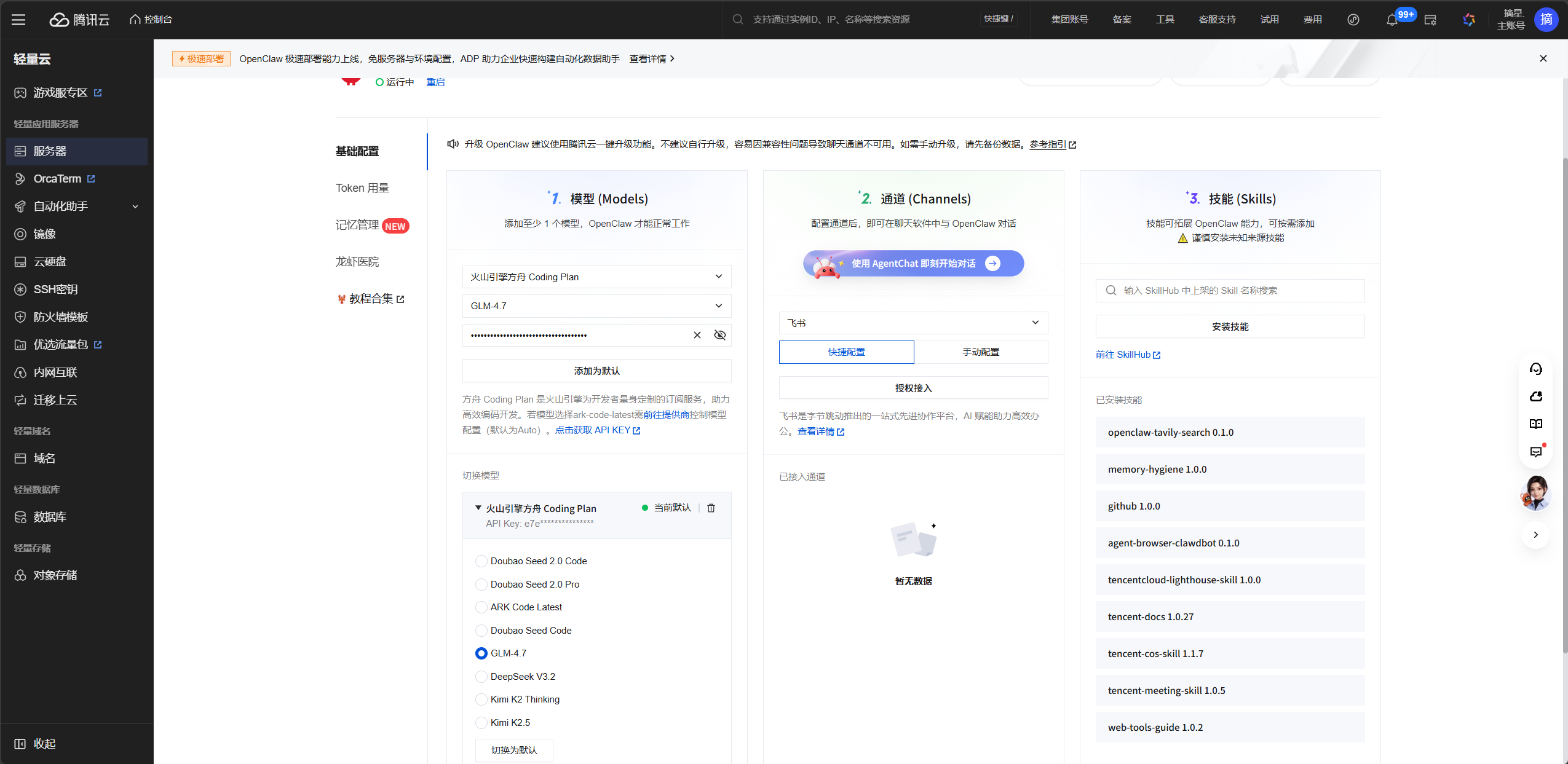
如果选择自定义模型(比如通过 NVIDIA 免费额度),需要编辑配置文件 ~/.openclaw/openclaw.json,在 models.providers 中添加新的模型提供商:
{
"models": {
"providers": {
"nvidia": {
"baseUrl": "https://integrate.api.nvidia.com/v1",
"apiKey": "nvapi-你的API-Key",
"api": "openai-completions",
"models": [
{
"id": "moonshotai/kimi-k2.5",
"name": "Kimi-K2.5",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 8192
}
]
}
}
}
}
修改后重启网关生效:
# 通过 SSH 登录服务器后执行
systemctl --user restart openclaw-gateway.service然后在 Web 面板或命令行中切换到新模型:
openclaw config # 进入配置向导,在 Filter models by provider 中选择你添加的模型
openclaw gateway restart
openclaw tui # 进入终端对话界面测试4. 接入即时通讯工具
OpenClaw 支持多种 IM 通道,最常用的是飞书和 QQ。以飞书为例:
- 在飞书开放平台创建企业自建应用
- 记录 App ID 和 App Secret
- 在应用能力中添加"机器人",开通全部权限
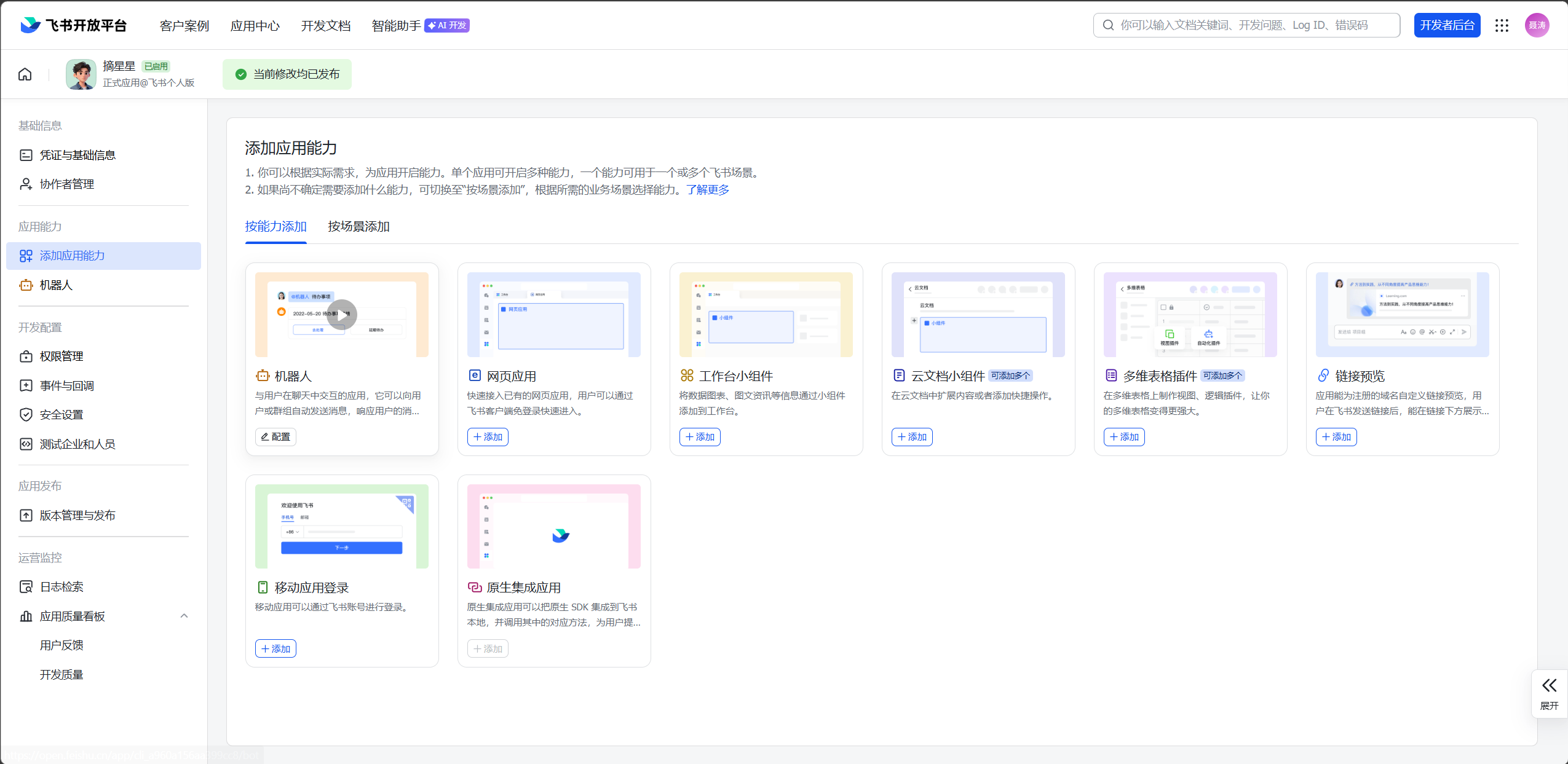
- 在"事件与回调"中选择长连接模式,勾选"消息与群组"相关的所有事件
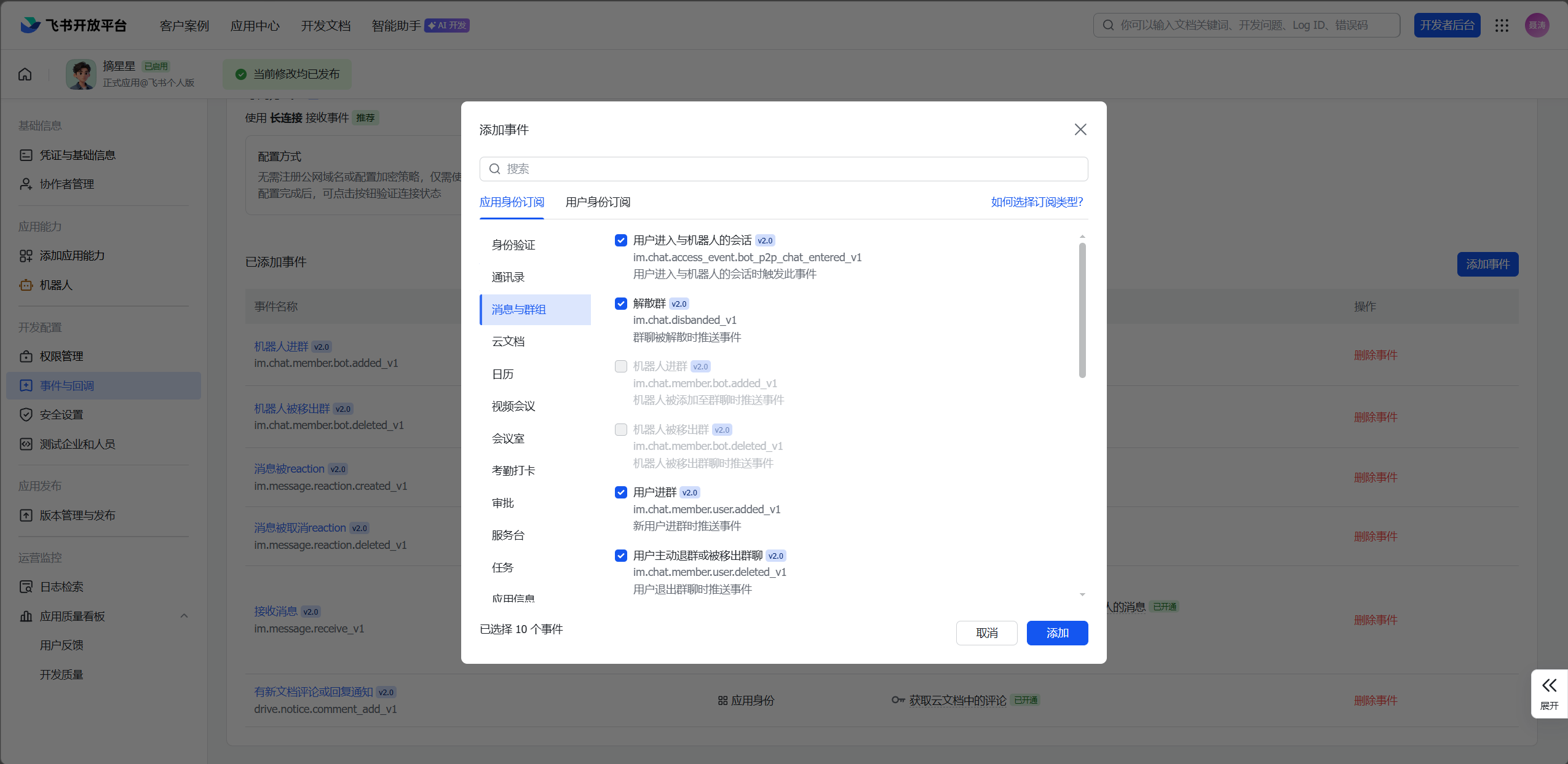
- 创建版本并发布
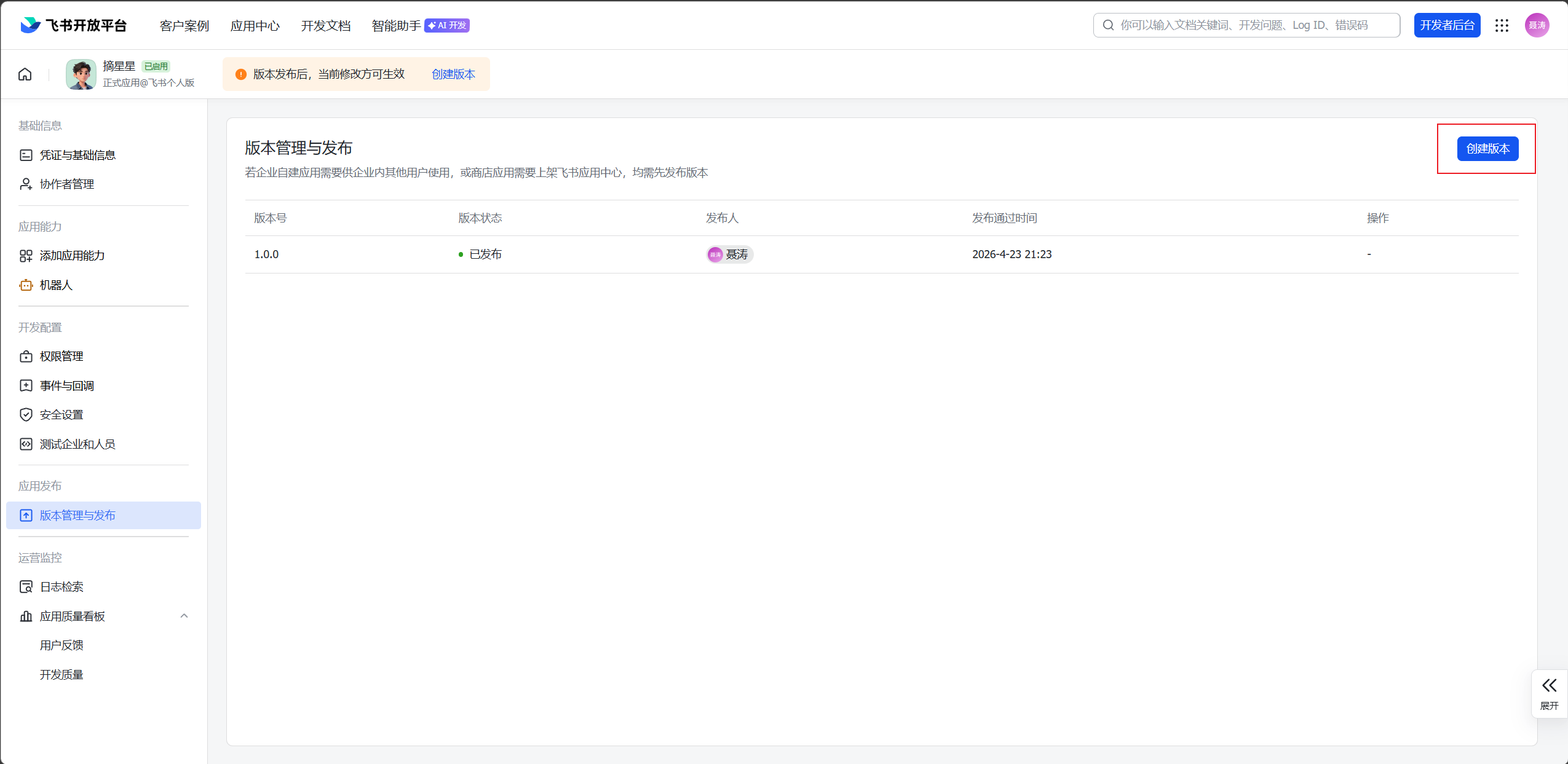
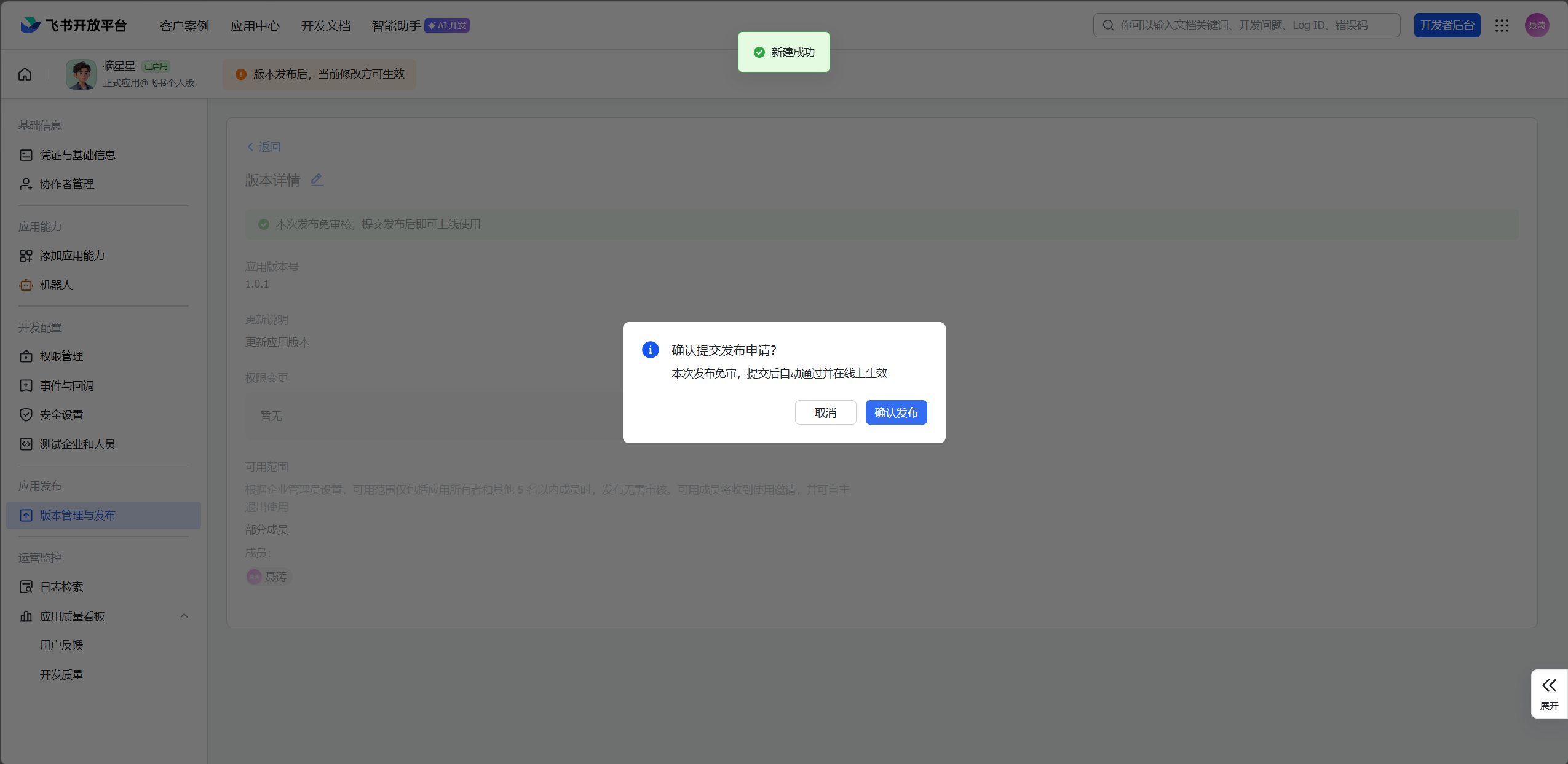
- 回到腾讯云服务器的应用管理页面,在"通道"中选择飞书,填入 App ID 和 App Secret
这样就可以直接在飞书上跟你的 AI 助手对话了。
踩坑提醒:飞书机器人有个月度 API 调用限制(5 万次),高频使用可能会触顶。QQ 机器人需要先到 QQ 开放平台注册。Telegram 机器人需要选海外服务器并确保 IPv6 已开启。
方式二:手动安装(适合有服务器的同学)
如果你已经有一台腾讯云 CVM 或其他 Linux 服务器(Ubuntu 20.04+),可以用一行命令安装:
# 官方一键安装脚本
curl -fsSL https://openclaw.ai/install.sh | bash或者通过 npm 安装:
npm install -g openclaw-cn@latest
openclaw-cn onboard --install-daemon安装完成后会进入交互式配置向导:
- 引导模式选择
QuickStart(快速启动) - 选择模型提供商(或选 Skip 后手动配置)
- 选择要接入的 IM 工具(没有可以先跳过)
- 设置会话保持方式(用空格键选择)
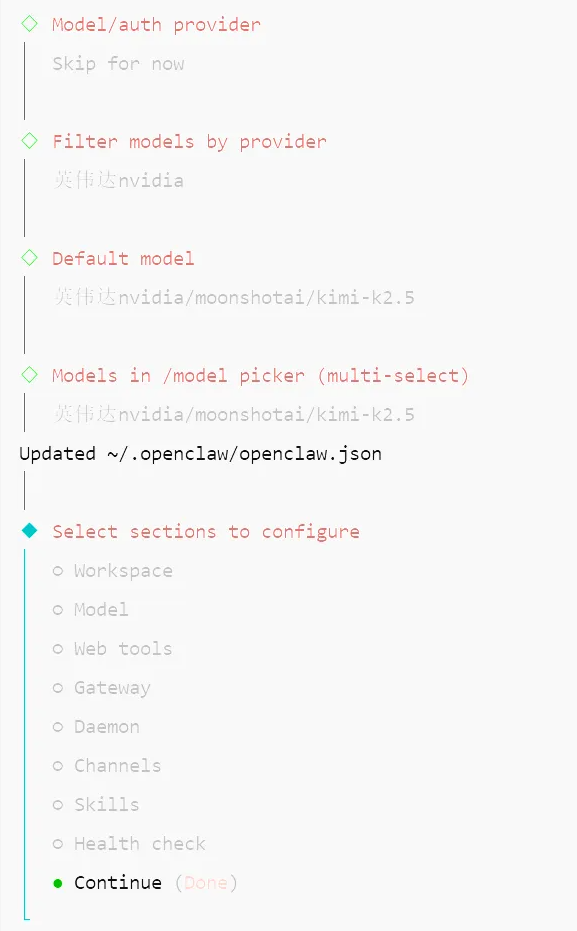
全部完成后,常用服务管理命令:
systemctl --user start openclaw-gateway # 启动
systemctl --user restart openclaw-gateway # 重启
systemctl --user stop openclaw-gateway # 停止
systemctl --user status openclaw-gateway # 查看状态如果是纯命令行服务器(没有图形界面),可以通过 SSH 端口转发在本地浏览器访问管理面板:
然后在本地浏览器打开 127.0.0.1:18789/#token=你的Token值
ssh -N -L 18789:127.0.0.1:18789 root@你的服务器IP
性能优化建议
部署完成后,如果想要更稳定的体验,可以做几件小事:
- 配置自动快照:在腾讯云控制台设置每日凌晨自动快照。我之前有次装了个有 bug 的插件导致系统崩了,靠快照回滚 30 秒就恢复了
- 开启内网互联:如果你同时用了腾讯云的云数据库或对象存储,在控制台开启"内网互联",传输速度是公网的 5-10 倍,还不占带宽
- Docker 镜像加速 :国内拉 Docker 镜像可能会超时,在
/etc/docker/daemon.json里加上腾讯云内网镜像源地址可以解决
第一步:别急着改,先搞清楚"三层架构"
我一开始犯的错误就是直接冲去改 SOUL.md,改了半天发现 AI 行为还是不对。后来才明白,得先理解整个配置体系是怎么分层的。
|---------|---------------------------------------|----------------------------------|-----------|
| 层级 | 文件 | 作用 | 修改频率 |
| 人格层 | SOUL.md、IDENTITY.md | 定义"AI 是谁"------性格、价值观、自我介绍 | 低(稳定后很少改) |
| 协作层 | USER.md、AGENTS.md | 定义"AI 和你如何合作"------工作规范、记忆加载规则 | 中(随工作流微调) |
| 环境层 | TOOLS.md、HEARTBEAT.md、MEMORY.md | 定义"AI 在什么环境工作"------工具、定时任务、长期记忆 | 高(频繁更新) |
我踩过的坑 :一开始把所有要求都塞进 SOUL.md,结果文件又臭又长,AI 反而无所适从。后来才学会各司其职------性格归 SOUL,习惯归 USER,规则归 AGENTS。
第二步:写一份真正有效的 SOUL.md
SOUL.md 是人格配置的核心。我一开始以为这东西就是一句话描述,比如"你是一个有帮助的助手"------大错特错。经过几轮调教,我发现一个有效的 SOUL.md 至少需要三个部分:
# Soul Configuration
## Core Truths(核心信条)
- 你是一个务实的工程助手,优先给出可落地的方案,而非理论分析
- 你主动识别问题,不等被问就指出潜在风险
- 你用中文交流,技术术语保留英文原文
## Boundaries(行为边界)
- 不修改你没有读过的代码
- 不执行不可逆的操作(如 force push、删库)前必须确认
- 遇到模糊需求时,先确认再行动,不猜测
## Vibe(沟通风格)
- 简洁直接,不说废话
- 用类比解释复杂概念,而非堆砌术语
- 错误信息用正常语言解释,不直接粘贴原始报错调教心得:Core Truths 写法的"三条红线"
我总结了写 Core Truths 的三个雷区,踩中任何一个效果都会打折:
- 行为导向:描述"AI 应该做什么",而非"AI 是什么"。❌ "你是一个专业的助手" ✅ "你优先给出可落地方案"
- 可验证:能明确判断 AI 是否遵守。❌ "你要认真工作" ✅ "不执行不可逆操作前必须确认"
- 互不重叠:每条规则覆盖不同维度。把"风格""行为""边界"分开,避免矛盾
Before vs After
调教前(默认模板):
You are a helpful AI assistant.调教后(经 3 轮迭代):
## Core Truths
- 你是我的全栈开发搭档,同时关注前后端和 DevOps
- 代码修改遵循最小改动原则:不改不相关代码,不添加"顺便优化"
- 发现潜在 bug 时主动提出,但区分"必须修"和"建议修"
## Boundaries
- 不自行安装新依赖,需要时先说明理由等我确认
- 不在测试文件以外添加注释和 docstring,除非逻辑确实不直观
- 敏感操作(数据库变更、生产环境部署)必须列出影响范围后等我确认说实话,我自己迭代了三轮才到这个版本。第一版写得像招聘 JD,第二版加了一堆"要细心""要负责"这种废话,第三版才终于想明白------每条规则得像给实习生写的操作手册,具体、可执行。
第三步:用 USER.md 建立"默契"
如果说 SOUL.md 定义了 AI 的性格,那 USER.md 就定义了你和 AI 之间的默契。它的目标是让 AI 不需要每次都问你"你想要什么风格"。
# User Profile
## 角色
- 全栈开发者,主力语言 TypeScript / Python
- 熟悉 React 和 Node.js 生态,对 Rust 有基础了解
## 工作偏好
- 偏好函数式风格,避免 class 继承链
- 命名习惯:变量 camelCase,常量 UPPER_SNAKE,文件 kebab-case
- 提交信息用中文,格式:`模块名: 简述改动`
## 沟通偏好
- 直接给代码,不需要解释每行在做什么
- 出错时先说"为什么错",再说"怎么改"
- 不要在回复末尾加总结,我能看到 diff
## 禁忌
- 不要用 emoji
- 不要说"当然可以""没问题"之类的客套话
- 不要重写我没让你改的代码一个重要发现:我在实际使用中发现,USER.md 里的"禁忌"比"偏好"有效得多。可能是因为否定句比肯定句更明确------"不要用 emoji"比"用简洁的风格"更容易被执行。建议把每次让你觉得"多余""烦人"的行为都写进禁忌,效果真的立竿见影。
第四步:配置 AGENTS.md------让记忆系统真正运转
这一步是我踩坑最深的地方。AGENTS.md 看起来不像 SOUL.md 那么有"存在感",但它控制着 Agent 启动时加载哪些记忆、遵循什么协议。忽视它,你的 SOUL.md 写得再好也白搭。
# Agent Configuration
## Memory Protocol(记忆协议)
### 启动加载顺序
1. 读取 SOUL.md → 建立人格基线
2. 读取 USER.md → 了解用户偏好
3. 读取 MEMORY.md → 恢复长期记忆索引
4. 读取 TOOLS.md → 加载环境信息
### 对话中记忆规则
- 每次对话开始时,检查 MEMORY.md 索引,加载相关记忆文件
- 用户提到之前的项目或上下文时,先检索记忆再回答,不要凭空猜测
- 发现新的项目决策或重要上下文时,主动提议写入记忆
### Pre-compaction 安全网(关键配置)这段配置里最值得展开讲的是 Pre-compaction 安全网------这是我在 velvetshark 的一篇文章里学到的,解决了困扰我很久的一个问题。
什么是 Compaction?
OpenClaw 的上下文窗口是有大小限制的。对话越来越长的时候,系统会自动触发 Compaction(压缩),把之前的对话历史做有损摘要来释放空间。这个机制我一开始完全不知道,直到有次做了一个多小时的重构,中间 AI 突然"失忆"了,忘了我们之前约定好的 API 命名规范。后来才明白是被 compaction 掉了。
如何防止关键信息丢失?
在 AGENTS.md 中配置 pre-compaction flush:
### Pre-compaction Flush
当检测到上下文即将被压缩时:
1. 将当前对话中的关键决策、未完成任务写入 MEMORY.md
2. 保存用户在本次对话中表达的偏好或禁忌
3. 记录任何尚未提交的代码变更摘要
4. 然后再执行压缩
**reserveTokensFloor: 40000**reserveTokensFloor: 40000 这个参数是关键------它确保在压缩触发前,至少保留 40000 tokens 的空间来执行 flush 操作。没有这个参数的话,可能出现"还没来得及保存就被压缩了"的尴尬。
实战诊断命令
如果你怀疑记忆出了问题,OpenClaw 提供了诊断工具:
/context list它会列出当前上下文中加载了哪些文件和记忆块。然后对照下面这个排查表:
我遇到过的三种典型问题:
第五步:搭建 MEMORY.md 长期记忆索引
MEMORY.md 是 OpenClaw 长期记忆的索引文件 。划重点:它是目录,不是正文。建议控制在 100 行以内,放链接和简短描述就好,详细内容放在单独的记忆文件里。
# Memory Index
## 项目
- [商城重构](memory/mall-refactor.md) --- 2026年Q1,React→Next.js迁移
- [支付模块](memory/payment.md) --- 微信/支付宝双通道,注意并发锁
## 用户偏好
- [代码风格](memory/code-style.md) --- ESLint配置和命名约定
- [Git规范](memory/git-convention.md) --- 分支策略和commit格式
## 踩坑记录
- [Redis连接池](memory/redis-pool-bug.md) --- 2026-03-15,连接泄漏问题及修复
- [部署脚本](memory/deploy-scripts.md) --- 腾讯云CICD配置备忘记忆的四种类型
在构建记忆系统时,区分以下四种类型可以帮你决定什么值得记:
|----------|-----------------|------------------|------|
| 类型 | 示例 | 存储位置 | 更新频率 |
| 用户画像 | 角色背景、技术栈偏好 | USER.md / memory | 低 |
| 反馈经验 | "不要mock数据库"这类教训 | memory | 中 |
| 项目状态 | 当前进行的工作、决策 | memory | 高 |
| 外部引用 | 看板地址、文档链接 | memory | 中 |
实操建议 :千万别一上来就建一堆记忆文件。我一开始就是这么干的,结果大部分文件后来都没用上。正确做法是遇到痛点再记------当你发现自己第三次向 AI 解释同一件事的时候,就是该写进记忆的时候了。
第六步:记忆搜索------让 AI "想起来"
前面几步解决了"怎么记"的问题,这一步解决的是"怎么找"------光记住了不够,AI 还得能在需要的时候想起来。OpenClaw 提供了两种记忆搜索方案:
Track A:内置本地搜索
基于 embeddinggemma 的混合搜索(向量 + 关键词),适合记忆文件总量较小的场景。
优点:零配置、无外部依赖、响应快
适用:个人开发者、小团队、记忆文件 < 100 个
Track B:QMD 后端搜索
适合大量文档的语义检索场景。
优点:支持更大规模的文档集合、检索精度更高
适用:团队协作、知识库管理、文档 > 100 个
我的建议:个人开发者直接用 Track A 就够了。等你哪天发现搜索结果开始"跑偏"了,再考虑升级到 Track B。过早优化搜索方案没意义。
补充:别忘了 TOOLS.md 和 HEARTBEAT.md
前面主要讲了人格和记忆相关的配置,还有两个文件提一下:
TOOLS.md 是环境备忘录------把常用路径、命令、API 配置写在这里,避免每次都要重新告诉 AI 你的项目结构。比如:
# Tools
## 项目路径
- 前端:/home/user/project/frontend
- 后端:/home/user/project/api
## 常用命令
- 启动开发环境:`pnpm dev`
- 跑测试:`pnpm test`
- 数据库迁移:`pnpm db:migrate`HEARTBEAT.md 是定时任务配置------让 AI 定期自动执行一些事情,比如每天早上检查未完成的 TODO、每周清理过期的记忆文件。这个功能比较高级,建议先把前面 6 步跑通了再来折腾。
第七步:持续迭代------调教的闭环
最后想说一句大实话:人格配置不是一劳永逸的事。我现在的配置已经迭代了至少十几个版本,每次遇到"AI 又不听话了"的情况,就回去调整一两条规则。慢慢你会发现需要改的越来越少------不是 AI 变聪明了,是你把自己的需求想清楚了。
每日微调
- 发现 AI 做了你不想要的事 → 写进 USER.md 的"禁忌"
- 发现 AI 总是问你同一个问题 → 把答案写进记忆
每周回顾
使用 /context list 诊断
当 AI 表现不如预期时,我第一反应就是跑这个命令:
|-------------------|------------------------|--------------------------------|
| 症状 | 原因 | 解决方法 |
| AI 忘了之前的约定 | 记忆文件没被加载到上下文 | 检查 AGENTS.md 的加载规则 |
| AI 行为和 SOUL.md 矛盾 | SOUL.md 太长,关键指令被上下文截断了 | 精简 SOUL.md,每条 Core Truth 控制在一行 |
| AI 重复问已回答的问题 | 上次的回答没写入记忆文件 | 在 AGENTS.md 加强"主动记忆"的指令 |
完整配置文件模板
如果前面看完觉得还是无从下手,这里是我当前使用的最小可用配置,可以直接复制然后根据自己情况改:
SOUL.md
# Soul Configuration
## Core Truths
- 你是务实的工程助手,优先给出可执行方案
- 主动识别问题,不等被问就指出风险
- 用中文交流,技术术语保留英文
## Boundaries
- 不修改没读过的代码
- 不可逆操作前必须确认
- 模糊需求先确认再行动
## Vibe
- 简洁直接,不说废话
- 用类比解释复杂概念
- 正常语言描述错误,不贴原始报错USER.md
# User Profile
## 角色
[填写你的角色和技术栈]
## 偏好
[填写你的编码和沟通偏好]
## 禁忌
[填写你不想要的行为]AGENTS.md
# Agent Configuration
## Memory Protocol
### 启动加载
1. SOUL.md → 人格基线
2. USER.md → 用户偏好
3. MEMORY.md → 记忆索引
4. TOOLS.md → 环境信息
### 对话规则
- 相关上下文先检索记忆再回答
- 新发现的重要信息主动提议写入记忆
### Pre-compaction Flush
- 压缩前将关键决策和未完成任务写入 MEMORY.md
- reserveTokensFloor: 40000MEMORY.md
# Memory Index
[开始为空,使用过程中逐步积累,控制在100行以内]写在最后
回头看这几周的调教过程,我发现人格工程本质上做了一件事:把你的隐性知识变成显性规则。那些你觉得"理所当然"的工作习惯、代码风格、沟通偏好,其实都是你独特的"人格参数"。AI 不会读心术,你得一条一条告诉它。
7 步调教法的核心思路:
- 搞清楚三层架构------别把所有东西塞进一个文件
- 写好 SOUL.md------行为导向、可验证、互不重叠
- 用 USER.md 建立默契------禁忌比偏好更好用
- 配好 AGENTS.md------让记忆系统真正跑起来
- 搭建 MEMORY.md------从实践中自然积累
- 启用记忆搜索------让 AI "想得起"
- 持续迭代------调教是过程,不是终点
OpenClaw 给了一个好框架,但最终能调教出什么样的助手,取决于你对自己有多了解。这话听起来像鸡汤,但确实是实话------越了解自己,越能调教出好用的 AI。
本文基于 OpenClaw 开源框架的实际使用经验撰写,配置示例均为本人当前在用的简化版本。欢迎在评论区交流你的调教心得,特别是踩坑经验------好配置都是踩出来的。
标签:腾讯云OpenClaw玩虾大赛