ZooKeeper 在分布式系统中扮演着"大脑"的角色,其稳定性直接影响到 Kafka、Hadoop、HBase 等组件。优化 ZooKeeper 需要平衡 写性能 、读取延迟 以及 故障恢复速度。
以下是针对核心场景的优化参数指南:
1. 核心资源配置 (JVM & 存储)
ZooKeeper 对磁盘延迟和内存交换极其敏感。
-
JVM 堆内存: 建议设置为 4G - 8G。ZooKeeper 会将所有 DataTree 缓存在内存中,堆内存不足会导致频繁 GC。
-
优化建议: 确保物理内存充足,避免使用 Swap(交换分区)。
配置JVM参数优化
在启动脚本中调整JVM参数,推荐配置:
- 堆内存:-Xms2G -Xmx2G(避免内存波动)
- GC策略:-XX:+UseG1GC(低延迟垃圾回收)
-
-
磁盘预分配 (
zookeeper.preAllocSize):- 默认 64MB。如果写吞吐量非常大,增加此值可减少事务日志文件的频繁分配带来的磁盘寻址开销。
-
Snap Count (
snapCount):- 默认 100,000。ZooKeeper 每处理 N 次事务会生成一个快照。增加该值可减少快照频率,降低 IO 抖动,但会导致服务器重启时恢复数据变慢。
独立数据与日志目录
默认配置中dataDir同时存储快照和事务日志,生产环境必须分离存储以避免IO竞争。建议将日志存储在高性能磁盘(如SSD):
# conf/zoo_sample.cfg
dataDir=/data/zookeeper/snapshots # 快照目录
dataLogDir=/data/zookeeper/logs # 事务日志目录(新增配置)2. 选举与集群通信 (Quorum)
在跨机房或网络波动环境下,这些参数至关重要。
| 参数 | 默认值 | 优化建议 | 作用说明 |
|---|---|---|---|
tickTime |
2000ms | 2000 | 基础心跳单位,不建议随意改动。 |
initLimit |
10 | 10 - 20 | Follower 连接 Leader 的超时(单位:tickTime)。数据量大时需调大。 |
syncLimit |
5 | 2 - 10 | Follower 同步 Leader 的超时。若网络差可适当调大,避免频繁踢出集群。 |
maxSessionTimeout |
20 * tickTime | 根据业务调整 | 建议设置为 40s - 60s,防止因短时间网络抖动导致客户端 Session 失效。 |
1. 调整会话心跳间隔(tickTime)
ZooKeeper的基本时间单位由tickTime参数控制(默认2000毫秒),所有超时时间都以此为基准倍数。生产环境建议设置为1000-2000ms ,过小将导致心跳频繁增加网络开销,过大则延长故障检测时间。
# conf/zoo_sample.cfg
tickTime=2000 # 推荐值:1000-2000ms2. 优化初始化同步限制(initLimit)
initLimit定义从 follower 连接到 leader 并完成数据同步的最大 tick 数(默认10)。集群规模超过5节点时建议调整为15-20,避免因网络延迟导致同步失败。
# conf/zoo_sample.cfg
initLimit=10 # 推荐值:15-20(大型集群)3. 调整请求响应超时(syncLimit)
syncLimit控制 leader 与 follower 之间请求响应的最大延迟(默认5个tick)。高网络延迟环境建议设为8-10,确保节点间通信稳定性。
# conf/zoo_sample.cfg
syncLimit=5 # 推荐值:8-10(跨机房部署)3. 并发限制与吞吐量
-
最大客户端连接数 (
maxClientCnxns):- 默认 60。对于 Kafka 等高并发场景,建议调大至 1000 - 2000,甚至更高(0 表示不限制,但存在 OOM 风险)。
-
强制刷新磁盘 (
forceSync):- 默认
yes。出于一致性考虑,ZooKeeper 每次写事务都会强刷磁盘。如果硬件层级有可靠的 BBU 电池加速卡,或对一致性要求极低,可以设为no以获得数倍的写性能提升。
- 默认
maxClientCnxns限制单个IP的并发连接数(默认60),高并发场景建议提高至100-200,但需配合系统文件描述符调整:
# conf/zoo_sample.cfg
maxClientCnxns=100 # 推荐值:100-200(根据客户端数量调整)4. 日志清理 (运维关键)
ZooKeeper 不会自动清理过旧的日志和快照,容易撑爆磁盘。
-
自动清理选项:
-
autopurge.snapRetainCount=3: 保留最近 3 个快照。 -
autopurge.purgeInterval=1: 每小时清理一次。
-
-
日志/快照路径分离:
- 关键: 将
dataDir(快照) 和dataLogDir(事务日志) 部署在不同的物理磁盘上。事务日志是 ZooKeeper 写操作的瓶颈,建议使用 NVMe/SSD。
- 关键: 将
ZooKeeper默认不清理历史快照和日志,需手动开启自动清理:
# conf/zoo_sample.cfg
autopurge.snapRetainCount=3 # 保留最近3个快照
autopurge.purgeInterval=1 # 每小时清理一次5. Linux 内核参数
除了 zoo.cfg,操作系统层面的设置也决定了性能上限:
-
文件描述符 (Limit):
ulimit -n 65536。ZooKeeper 每个连接都会占用一个 FD。
-
Dirty Ratio:
- 调低
vm.dirty_ratio和vm.dirty_background_ratio,让操作系统更频繁地后台刷盘,避免大块数据突发写入造成的系统卡死。
- 调低
6. 服务器数量对吞吐量的影响
集群规模直接影响读操作吞吐量。根据官方测试数据,读操作占比80%时,7节点集群吞吐量可达5节点的1.5倍:
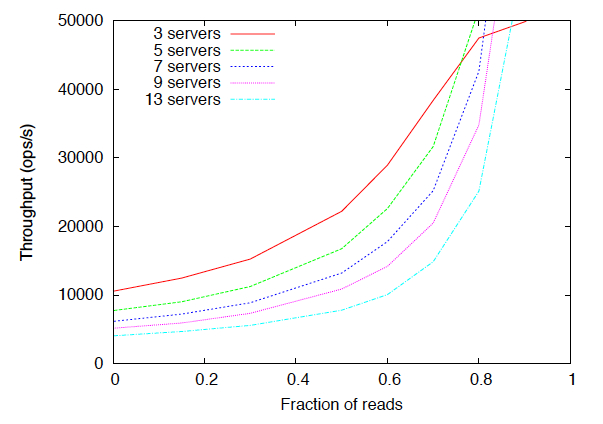
不同服务器数量下的ZooKeeper吞吐量表现(越高越好)
7. 客户端优化最佳实践
- 会话超时设置 :
sessionTimeoutMs=30000(3倍tickTime) - 连接池复用:使用Curator等客户端框架维护长连接
- 批量操作 :通过
multi()接口合并多个写请求
8. 监控关键性能指标
通过Ganglia等工具监控核心指标,重点关注:
zk_avg_latency:平均请求延迟(应<100ms)zk_outstanding_requests:未处理请求数(应接近0)zk_packets_received/sent:网络包吞吐量
避坑小贴士
-
不要在同一台机器部署过多节点: ZooKeeper 是 IO 密集型,多个实例争抢磁盘会导致性能骤降。
-
监控 Leader 延迟: 重点关注
avg_latency和max_latency。如果超过 10ms,通常说明磁盘 IO 或 JVM 出现了瓶颈。