暗黑破坏神2 MOD 修改工具里的"文件编辑"模块,本质上是一个面向 data/global/excel 目录下通用 TXT 表的编辑器入口。它并不只服务某一类游戏数据,而是覆盖装备、技能、怪物、地图、经验曲线、掉落规则、合成公式等多类表结构,因此这个模块会间接影响游戏中的大量表现。只要目标改动仍然落在 TXT 表驱动体系内,文件编辑模块就有可能成为最直接的入口。
从工具定位看,这个模块承担的是"原始表格层"的编辑职责。专用模块如装备编辑、怪物管理、物品管理更强调分组语义、业务约束和定制 UI,而文件编辑模块强调的是通用性、快速定位、低门槛改表和多表兼容。对于 MOD 作者而言,它适合做跨表修正、结构探索、字段试验和批量维护;对于二次开发者而言,它展示了一个典型的配置驱动表编辑器是如何把文件元信息、列说明、搜索过滤、分页展示、增删改存和缓存同步串成一个完整链路的;对于工具使用者而言,这个模块也是理解整套编辑工具"底层数据入口"最直接的观察窗口。
文章目录
- 文件说明
- 软件开发
-
-
- 页面入口代码
- 文件搜索、列映射与可见列控制代码
- 读取、过滤、分页与视图状态持久化代码
- 单元格渲染与公共组件复用代码
- 行级编辑与保存链路代码
- [后端 TXT 读写与 SQLite 同步代码](#后端 TXT 读写与 SQLite 同步代码)
- 布局控制代码
-
- 操作演示
- 总结
文件说明
从当前源码结构看,文件编辑模块由页面入口、通用编辑器页面、状态控制器、列映射解析器、增删改存辅助模块、表数据缓存加载器、持久化工具、元数据索引文件、列说明资源和 Tauri 后端命令共同构成。这个模块没有独立的布局 JSON 文件,布局控制主要由 EditorTab.vue 的模板结构和 style.css 里的公共样式类共同承担。也就是说,文件编辑模块的"配置层"更多体现在列元数据和文件索引上,而不是独立的页面布局描述文件上。
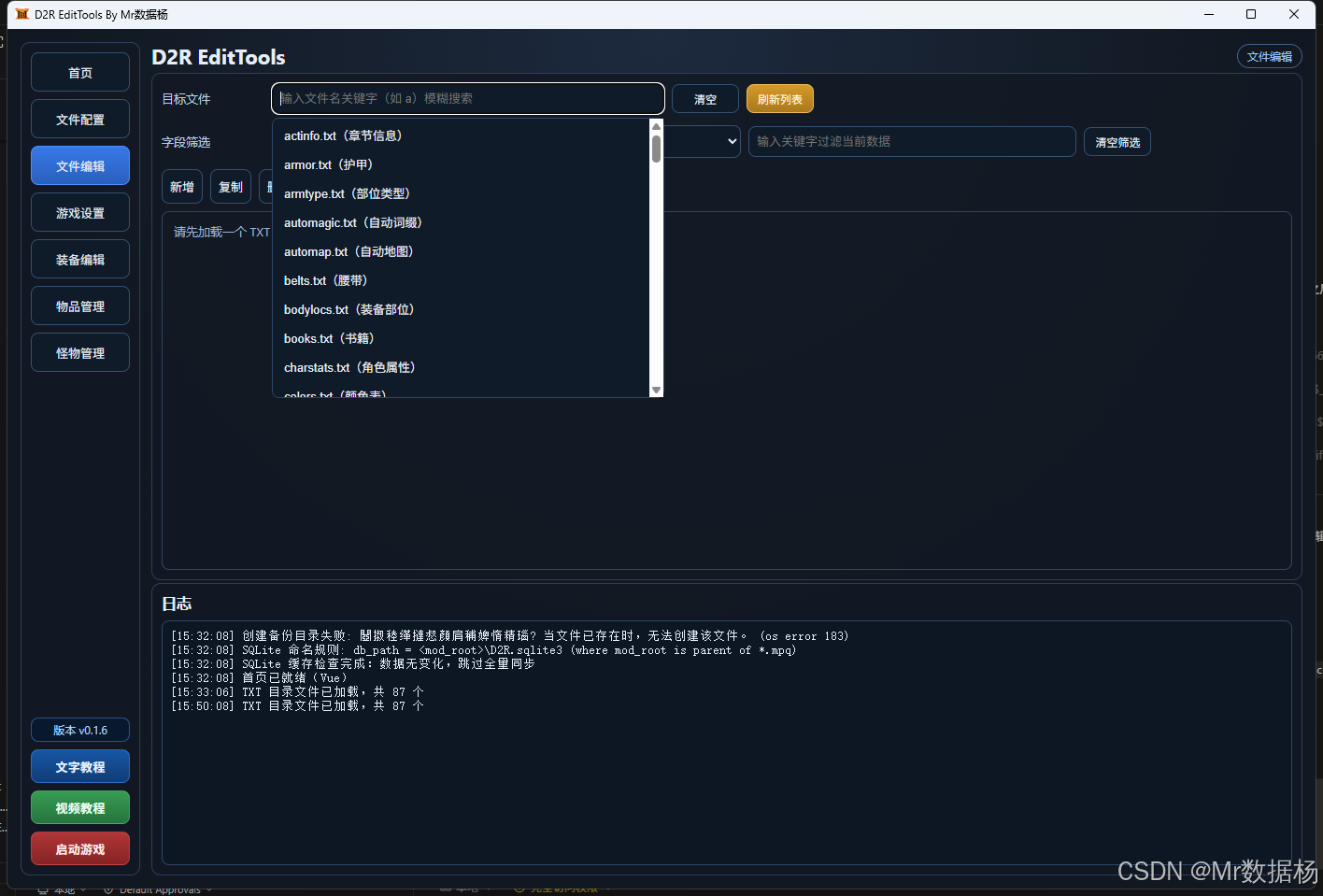
源码里还能看出一条很清晰的分层关系。HomePage.vue 负责把文件编辑模块挂进主页面一级导航,EditorTab.vue 负责真正的表格编辑界面,useHomePageController.js 负责构造并 provide 编辑上下文,editorMappingHelpers.js 负责把文件索引和列说明转换成界面可消费的数据,editorCrudHelpers.js 负责行级编辑和保存落盘,tableDataLoader.js 负责读取缓存,Rust 侧 files.rs 和 sqlite/commands.rs 负责把前端的读写动作真正落到文件系统和 SQLite 缓存。
模块文件职责表
| 文件名 | 文件类型 | 模块职责 | 与界面或数据处理的关系 | 备注 |
|---|---|---|---|---|
src/pages/HomePage.vue |
Vue | 主页面壳层 | activeTab === 'editor' 时挂载文件编辑模块 |
页面入口层 |
src/modules/editor/EditorTab.vue |
Vue | 文件编辑主界面 | 承载文件搜索、字段筛选、分页、表格渲染、增删改存操作 | 核心页面文件 |
src/modules/editor/editor.ts |
TS | 上下文注入封装 | 通过 inject('editorCtx') 获取文件编辑上下文 |
轻量封装层 |
src/pages/home/useHomePageController.js |
JS | 状态控制与上下文提供 | 构造 editorState、fileCandidates、visibleColumns、pagedRowEntries,并提供 editorCtx |
控制器层 |
src/pages/home/editorMappingHelpers.js |
JS | 文件元信息与列映射解析 | 处理文件搜索、列中文名、字段 tooltip、值映射、名称映射、搜索缓存构建 | 解析层 |
src/pages/home/editorCrudHelpers.js |
JS | 行级编辑与保存 | 处理新增、复制、删除、更新单元格、保存 TXT、同步 SQLite | 数据写入层 |
src/pages/home/tableDataLoader.js |
JS | 表数据缓存加载器 | 对 py_load_table 结果做缓存、去重并发和失效控制 |
读链路优化层 |
src/utils/uiPersist.js |
JS | 视图状态持久化 | 持久化文件名、筛选字段、关键字、分页大小等界面状态 | 本地状态层 |
src/assets/resources/index.json |
JSON | 文件索引元数据 | 提供文件中文名、说明和对应 columns.json 路径,用于文件搜索和列映射定位 |
配置索引层 |
src/assets/resources/files/*.columns.json |
JSON | 列级元数据资源 | 提供字段中文名、说明、值映射等信息,驱动列标题、tooltip 和映射显示 | 字段配置层 |
src/assets/css/style.css |
CSS | 编辑器布局与表格样式 | 控制 editor-panel、table-wrap、列头、单元格、选中态等视觉结构 |
布局层 |
src/modules/commonControls/VersionSelect.vue |
Vue | 版本选择控件 | 针对 version 列提供枚举下拉 |
通用控件 |
src/modules/commonControls/EnabledSelect.vue |
Vue | 启用状态控件 | 针对 enabled 列提供枚举下拉 |
通用控件 |
src/modules/commonControls/ClassSelect.vue |
Vue | 职业选择控件 | 针对 class、charclass 等列提供职业下拉 |
通用控件 |
src/modules/commonControls/ClassPickerDialog.vue |
Vue | 职业选择弹窗 | skills.txt 的 charclass 列通过弹窗选择职业编码 |
通用控件 |
src/utils/d2ColorText.js |
JS | 暗黑颜色码处理 | 处理技能名等文本的颜色码剥离和 HTML 渲染 | 显示增强层 |
src-tauri/src/commands/files.rs |
Rust | TXT 文件读写命令 | 提供 py_list_files、py_load_table、py_save_table_json 等能力 |
后端文件层 |
src-tauri/src/sqlite/commands.rs |
Rust | SQLite 缓存命令 | 提供 py_sync_txt_file_cache、py_query_txt_list 等能力 |
缓存同步层 |
这张表可以看出,文件编辑模块虽然在界面上只表现成一个通用表格页,但内部拆分并不粗糙。页面壳层、配置层、解析层、数据层和后端层都有明确边界,模块扩展并不是把新逻辑不断塞进一个 Vue 文件里,而是通过上下文和辅助模块逐步组织起来。
UI 相关字段/配置项说明表
| 字段/配置项/方法 | 所属文件 | 作用 | 在界面中的体现 | 修改后的影响 |
|---|---|---|---|---|
activeTab |
src/pages/home/useHomePageController.js |
一级页签状态 | 控制是否显示文件编辑模块 | 决定文件编辑页是否挂载 |
editorState.fileName |
src/pages/home/useHomePageController.js |
当前编辑文件名 | 顶部"目标文件"输入框和当前文件状态文本 | 决定加载哪个 TXT 文件 |
editorState.fileFilter |
src/pages/home/useHomePageController.js |
文件名搜索关键字 | 文件搜索输入框内容 | 决定候选文件列表 |
filteredFiles |
src/pages/home/useHomePageController.js |
文件筛选结果 | 文件候选列表的数据源 | 支持英文名、中文名、说明搜索 |
fileCandidates |
src/pages/home/useHomePageController.js |
候选文件展示列表 | 输入框下拉建议列表 | 限制候选展示数量 |
loadFiles |
src/pages/home/useHomePageController.js |
加载 TXT 文件列表 | 点击"刷新列表"或聚焦输入框时触发 | 读取目录内可编辑文件 |
openEditorFile |
src/pages/home/useHomePageController.js |
加载当前表格内容 | 选中文件后加载表头和数据行 | 打开具体 TXT 文件 |
editorState.colMeta |
src/pages/home/useHomePageController.js |
当前文件列元数据 | 决定中文列名、tooltip、值映射 | 影响列展示质量 |
loadColumnMapping |
src/pages/home/editorMappingHelpers.js |
装载列映射 | 在文件加载后读取对应 columns.json |
驱动列中文说明 |
visibleColumns |
src/pages/home/useHomePageController.js |
当前可见列集合 | 表头和表格列渲染的数据源 | 若有映射则只展示带中文标题的列 |
editorState.filterColumn |
src/pages/home/useHomePageController.js |
当前字段筛选列 | "字段筛选"下拉框 | 限定关键字过滤作用列 |
editorState.filterKeyword |
src/pages/home/useHomePageController.js |
当前关键字 | "输入关键字过滤当前数据"输入框 | 影响数据行过滤结果 |
editorFilterKeywordActive |
src/pages/home/useHomePageController.js |
去抖后的关键字 | 不直接显示,参与计算过滤结果 | 避免输入过程中高频重算 |
filteredRowIndexes |
src/pages/home/useHomePageController.js |
行过滤结果索引 | 表格显示行集合 | 决定当前展示哪些记录 |
pagedRowEntries |
src/pages/home/useHomePageController.js |
当前页行数据 | 表格主体循环数据源 | 决定分页后的可见数据 |
editorState.pageSize / totalPages |
src/pages/home/useHomePageController.js |
分页大小与页数 | "页面过滤"区域和上一页/下一页按钮 | 影响单页显示数量 |
selectedRowSet |
src/pages/home/useHomePageController.js |
选中行集合 | 表格首列复选框和选中高亮 | 复制、删除依赖这个集合 |
updateCell |
src/pages/home/editorCrudHelpers.js |
更新单元格 | 文本框、下拉框或弹窗选择后立即写入内存 | 影响保存内容 |
addRow |
src/pages/home/editorCrudHelpers.js |
新增一行 | 点击"新增"按钮触发 | 在存在编号列时自动生成下一个编号 |
copySelectedRows |
src/pages/home/editorCrudHelpers.js |
复制选中行 | 点击"复制"按钮触发 | 复制后插入新行并重算自增列 |
deleteSelectedRows |
src/pages/home/editorCrudHelpers.js |
删除选中行 | 点击"删除"按钮触发 | 从内存数据中移除选中记录 |
saveEditorFile |
src/pages/home/editorCrudHelpers.js |
保存当前文件 | 点击"保存"按钮触发 | 写回 TXT、生成备份并同步 SQLite |
cellMappedZh |
src/pages/home/editorMappingHelpers.js |
获取单元格中文映射 | 文本框下方的中文映射提示 | 提高字段可读性 |
colTooltip |
src/pages/home/editorMappingHelpers.js |
生成字段 tooltip | 表头 title 和部分单元格提示 | 展示字段中文说明 |
EDITOR_VIEW_STATE_STORAGE_KEY |
src/pages/home/homeState.js |
文件编辑视图状态存储键 | 不直接显示 | 持久化文件、筛选、分页状态 |
文件编辑模块更适合从"编辑状态"和"界面驱动字段"角度理解,因此再补一张更聚焦状态流的表,会更容易看清界面和数据是怎样串起来的。
| 字段名 | 中文含义 | 所属分组 | 前端展示方式 | 实际用途说明 |
|---|---|---|---|---|
header |
当前表头 | 编辑状态 | 表格列头 | 决定列顺序和列数 |
rows |
当前文件数据行 | 编辑状态 | 表格主体 | 所有编辑动作都作用在这里 |
colMeta |
列说明映射 | 配置解析 | 中文列名、tooltip、值映射 | 让原始字段变得可读 |
fileMetaMap |
文件索引映射 | 文件搜索 | 文件名联想和说明展示 | 把 index.json 转成查询结构 |
editorRowSearchCache |
行搜索缓存 | 搜索优化 | 不直接显示 | 加速全行关键字过滤 |
page |
当前页码 | 分页状态 | 分页区域 | 控制当前页数据切片 |
pageSize |
当前页容量 | 分页状态 | 页大小下拉框 | 支持全部、100、200、500、1000 |
itemNameMap |
名称映射表 | 展示增强 | 单元格下方中文补充 | 提升代码类字段可读性 |
encoding |
当前文件编码 | 文件读写 | 不直接显示 | 保存时按原编码回写 |
backupPath |
备份目录 | 保存链路 | 不在编辑页内直接编辑 | 决定保存时备份落点 |
从这些状态可以看出,文件编辑模块的核心不是"动态表单字段定义",而是"围绕一张二维表的读取、映射、筛选、编辑和保存"。这也是它和装备编辑、怪物管理这类领域模块最大的区别。
软件开发
文件编辑模块的开发核心,在于如何把一个通用 TXT 表编辑器做成既可复用又不至于太原始的结构。源码里的思路比较清楚:前端页面入口只负责挂载和取上下文,控制器负责拼装状态和计算属性,映射辅助模块负责把索引与列说明转成界面语义,增删改存辅助模块负责写内存和落盘,后端命令负责实际文件读写,SQLite 同步则作为保存后的补充链路。这样做的意义在于,文件编辑模块可以持续吸收新的通用能力,而不必在页面模板里硬编码越来越多的业务逻辑。
从当前代码能够确认,这个模块并没有采用"每种 TXT 表都单独写一套表单"的方案,而是选择了一张通用表格加一套映射机制。只要 index.json 能定位到对应的 columns.json,模块就能给文件搜索框提供中文信息,也能给表头和单元格提供中文解释。对应地,少量有明确枚举特征的字段再通过公共组件提升体验,例如 version、enabled 和职业相关字段。绝大多数列仍然保持文本输入,这种控制力度是有意识的:既不过度复杂化通用编辑器,也尽量避免把每个字段都写成定制组件。
核心实现结构表
| 实现层 | 核心文件/代码 | 作用说明 | 设计意义 |
|---|---|---|---|
| 页面入口层 | HomePage.vue + EditorTab.vue |
在一级页签里挂载文件编辑页面,并通过上下文提供状态 | 页面结构清晰,主页面不直接处理表格细节 |
| 状态控制层 | useHomePageController.js |
维护 editorState、文件候选、列集合、行过滤、分页和日志 |
通用逻辑集中,避免组件膨胀 |
| 配置层 | index.json + files/*.columns.json |
提供文件中文名、说明、列中文名、值映射 | 用配置替代硬编码列信息 |
| 解析层 | editorMappingHelpers.js |
处理文件搜索、列映射、单元格中文解释和搜索缓存 | 把静态元数据转成界面语义 |
| 编辑层 | editorCrudHelpers.js |
提供新增、复制、删除、更新和保存 | 把行级操作从页面抽离出来 |
| 读链路优化层 | tableDataLoader.js |
缓存表数据、合并并发请求 | 降低重复加载成本 |
| 后端文件层 | files.rs |
读取 TXT、保存 TXT、生成备份、列出文件 | 文件系统操作集中到 Rust |
| 缓存同步层 | sqlite/commands.rs + txt_sync.rs |
保存后同步单文件到 SQLite 缓存 | 维持后续查询和展示一致性 |
页面入口代码
vue
<template>
<template v-else-if="activeTab === 'editor'">
<EditorTab />
</template>
</template>
<script setup>
import EditorTab from '../modules/editor/EditorTab.vue'
import { useHomePageController } from './home/useHomePageController'
const {
activeTab,
} = useHomePageController()
</script>
js
const editorCtx = {
editorState,
showFileSuggestions,
fileCandidates,
fileDesc,
fileDisplayName,
onFileInputFocus,
onFileInputChange,
onFileInputBlur,
applyFileSearchSelection,
pickFile,
clearFileSearch,
isLoadingFile,
loadFiles,
visibleColumns,
fieldFilterLabel,
colZh,
colTooltip,
clearDataFilter,
addRow,
copySelectedRows,
deleteSelectedRows,
saveEditorFile,
filteredRowCount,
totalPages,
pagedRowEntries,
selectedRowSet,
toggleRow,
updateCell,
cellTooltip,
cellMappedZh,
}
provide('editorCtx', editorCtx)
ts
import { inject } from 'vue'
export function useEditorCtx() {
const ctx = inject('editorCtx')
if (!ctx) {
throw new Error('editorCtx missing')
}
return ctx
}这一层实现说明了文件编辑模块是如何被挂载进主页面体系的。HomePage.vue 只根据 activeTab 决定是否渲染 EditorTab,真正的编辑能力不从 props 层层传递,而是在控制器里统一构造成 editorCtx 再通过 provide/inject 注入。这样的好处是状态边界清楚,页面本身更像一个"消费上下文的视图层",后续如果要拆分子组件,编辑状态仍然能沿用这一套注入结构。
文件搜索、列映射与可见列控制代码
js
import columnMapIndex from '../../assets/resources/index.json'
export function useHomePageController() {
const columnSchemaModules = import.meta.glob('../../assets/resources/files/*.columns.json')
const savedEditorViewState = loadPersistedJson(EDITOR_VIEW_STATE_STORAGE_KEY, {})
const editorState = reactive({
fileName: String(savedEditorViewState?.fileName || ''),
encoding: 'utf-8',
header: [],
rows: [],
colMeta: {},
itemNameMap: {},
fileFilter: String(savedEditorViewState?.fileFilter || ''),
filterColumn: String(savedEditorViewState?.filterColumn || ''),
filterKeyword: String(savedEditorViewState?.filterKeyword || ''),
page: Math.max(1, Number(savedEditorViewState?.page || 1)),
pageSize: (() => {
const value = Number(savedEditorViewState?.pageSize || 100)
if (value === -1) return -1
if ([100, 200, 500, 1000].includes(value)) return value
return 100
})(),
})
}
js
const fileMetaMap = computed(() => {
const map = {}
const files = Array.isArray(columnMapIndex?.files) ? columnMapIndex.files : []
for (const item of files) {
const key = normKey(item?.file)
if (key) {
map[key] = item
}
}
return map
})
const filteredFiles = computed(() => {
const keyword = normKey(editorState.fileFilter)
if (!keyword) return state.files
return state.files.filter((item) => {
const meta = fileMeta(item)
return (
normKey(item).includes(keyword) ||
normKey(meta?.file_zh).includes(keyword) ||
normKey(meta?.desc_zh).includes(keyword)
)
})
})
const fileCandidates = computed(() => filteredFiles.value.slice(0, 120))
js
async function loadColumnMapping(fileName) {
editorState.colMeta = {}
const files = Array.isArray(columnMapIndex?.files) ? columnMapIndex.files : []
const entry = files.find((item) => normKey(item.file) === normKey(fileName))
if (!entry?.json) {
return
}
const modulePath = `../../assets/resources/${entry.json}`
const loader = columnSchemaModules[modulePath]
if (!loader) {
appendLog(`未找到字段映射文件: ${entry.json}`)
return
}
try {
const schema = await loader()
const columns = schema?.columns || {}
const mapped = {}
for (const [key, value] of Object.entries(columns)) {
mapped[normKey(key)] = value
}
editorState.colMeta = mapped
} catch (error) {
appendLog(`加载字段映射失败: ${String(error)}`)
}
}
const hasColMapping = computed(() => Object.keys(editorState.colMeta || {}).length > 0)
const visibleColumns = computed(() =>
editorState.header
.map((col, index) => ({ col, index, meta: colMeta(col) }))
.filter(({ meta }) => {
if (!hasColMapping.value) return true
return String(meta?.zh || '').trim().length > 0
}),
)这里的关键点,是把"文件索引"和"列索引"拆成两层配置。index.json 负责告诉模块某个文件对应哪份 columns.json,也顺便提供文件中文名和说明;columns.json 再负责提供列中文名、中文描述和值映射。文件搜索因此不仅能按 skills.txt 这种文件名命中,也能按中文文件名和说明命中。列展示也不是把 header 原样输出,而是优先使用元数据里的中文标题。更重要的是,visibleColumns 在存在列映射的情况下只展示带中文标题的列,这个策略明显是在服务"通用但可读"的编辑器目标,而不是做纯原始表查看器。
读取、过滤、分页与视图状态持久化代码
js
export function createTableDataLoader(loadTableFn, options = {}) {
const cacheMax = Number(options.max || 32)
const cacheTtlMs = Number(options.ttlMs || 30 * 60 * 1000)
const tableLoadCache = new Map()
const tableLoadInflight = new Map()
function getCachedTableResult(folder, file) {
const key = tableCacheKey(folder, file)
const cached = tableLoadCache.get(key)
if (!cached) return null
if (Date.now() - cached.cachedAt > cacheTtlMs) {
tableLoadCache.delete(key)
return null
}
return normalizeTableResult(cached.result)
}
function setCachedTableResult(folder, file, result) {
const key = tableCacheKey(folder, file)
tableLoadCache.set(key, {
cachedAt: Date.now(),
result: normalizeTableResult(result),
})
if (tableLoadCache.size > cacheMax) {
const firstKey = tableLoadCache.keys().next().value
if (firstKey) tableLoadCache.delete(firstKey)
}
}
async function loadTableData(folder, file, options = {}) {
const force = options.force === true
const key = tableCacheKey(folder, file)
if (!force) {
const cached = getCachedTableResult(folder, file)
if (cached) return cached
}
if (!force && tableLoadInflight.has(key)) {
const inflight = await tableLoadInflight.get(key)
return normalizeTableResult(inflight)
}
const task = Promise.resolve(loadTableFn(folder, file))
tableLoadInflight.set(key, task)
try {
const fresh = await task
setCachedTableResult(folder, file, fresh)
return normalizeTableResult(fresh)
} finally {
tableLoadInflight.delete(key)
}
}
return {
loadTableData,
invalidateTableCache,
setCachedTableResult,
}
}
js
async function openEditorFile(force = false) {
if (!state.excelPath || !editorState.fileName) {
appendLog('请先定位 TXT 目录并选择文件')
return
}
try {
isLoadingFile.value = true
editorState.header = []
editorState.rows = []
const start = performance.now()
const result = await loadTableData(state.excelPath, editorState.fileName, { force })
await loadColumnMapping(editorState.fileName)
editorState.encoding = result.encoding || 'utf-8'
editorState.header = result.header || []
editorState.rows = (result.rows || []).map((row) => [...row])
editorState.filterColumn = ''
editorState.filterKeyword = ''
editorFilterKeywordActive.value = ''
editorState.page = 1
if (!Object.keys(editorState.itemNameMap || {}).length && state.itemNamesPath) {
await loadItemNameMapping()
}
rebuildEditorRowSearchCache()
selectedRowSet.value = new Set()
state.currentFile = editorState.fileName
activeFilePath.value = result.path || currentFilePath.value
appendLog(`已加载编辑文件: ${editorState.fileName}(${Math.round(performance.now() - start)}ms)`)
} catch (error) {
appendLog(`加载文件失败: ${String(error)}`)
} finally {
isLoadingFile.value = false
}
}
js
watch(
() => editorState.filterKeyword,
(value) => {
if (editorFilterKeywordTimer) {
clearTimeout(editorFilterKeywordTimer)
}
editorFilterKeywordTimer = setTimeout(() => {
editorFilterKeywordActive.value = value || ''
}, 180)
},
{ immediate: true },
)
const filteredRowIndexes = computed(() => {
const keyword = normSearchText(editorFilterKeywordActive.value)
if (!keyword) {
return editorState.rows.map((_, idx) => idx)
}
const colName = editorState.filterColumn
const colIndex = colName ? editorState.header.findIndex((item) => item === colName) : -1
const matched = []
for (let rowIndex = 0; rowIndex < editorState.rows.length; rowIndex += 1) {
if (colIndex >= 0) {
const value = normSearchText(searchableCellText(rowIndex, colIndex))
if (value.includes(keyword)) matched.push(rowIndex)
continue
}
const cached = editorRowSearchCache.value[rowIndex] || ''
const hit = cached.includes(keyword)
if (hit) matched.push(rowIndex)
}
return matched
})
const totalPages = computed(() => {
if (editorState.pageSize === -1) return 1
return Math.max(1, Math.ceil(filteredRowCount.value / editorState.pageSize))
})
const pagedRowEntries = computed(() =>
(editorState.pageSize === -1
? filteredRowIndexes.value
: filteredRowIndexes.value.slice(pageStart.value, pageStart.value + editorState.pageSize)
).map((rowIndex) => ({
rowIndex,
row: editorState.rows[rowIndex] || [],
})),
)
watch(
() => [
editorState.fileName,
editorState.fileFilter,
editorState.filterColumn,
editorState.filterKeyword,
editorState.page,
editorState.pageSize,
],
() => {
savePersistedJson(EDITOR_VIEW_STATE_STORAGE_KEY, {
fileName: String(editorState.fileName || ''),
fileFilter: String(editorState.fileFilter || ''),
filterColumn: String(editorState.filterColumn || ''),
filterKeyword: String(editorState.filterKeyword || ''),
page: Math.max(1, Number(editorState.page || 1)),
pageSize: Number(editorState.pageSize || 100),
})
},
)
js
export function loadPersistedJson(key, fallback = null) {
try {
const raw = localStorage.getItem(String(key || ''))
if (!raw) return fallback
const parsed = JSON.parse(raw)
return parsed && typeof parsed === 'object' ? parsed : fallback
} catch (_error) {
return fallback
}
}
export function savePersistedJson(key, value) {
try {
localStorage.setItem(String(key || ''), JSON.stringify(value))
} catch (_error) {
// ignore storage errors
}
}这一段把文件编辑模块的使用体验拉高了一个层级。读取文件不是每次都直接打后端,而是通过 tableDataLoader 做本地缓存和并发复用;关键字过滤不是输入一字符就立即重算,而是做了 180ms 去抖;全行搜索也不是每次遍历每个单元格临时拼接字符串,而是通过 editorRowSearchCache 保存标准化后的行搜索文本;连文件名、筛选列、关键字、页码和分页大小都会持久化到本地。这类设计不会改变业务功能边界,却非常影响通用编辑器的稳定度和可用性。
单元格渲染与公共组件复用代码
vue
<td v-for="item in visibleColumns" :key="`cell-${entry.rowIndex}-${item.index}`">
<div v-if="isSkillClassColumn(item.col)" class="cell-wrap skill-class-wrap">
<div class="skill-class-input-row">
<input
type="text"
:value="skillClassDisplayValue(entry.row[item.index])"
:title="entry.row[item.index] || ''"
readonly
/>
<button type="button" class="skill-class-op-btn" @click.stop="openSkillClassPicker(entry.rowIndex, item.index)">+</button>
<button type="button" class="skill-class-op-btn danger" @click.stop="clearSkillClass(entry.rowIndex, item.index)">-</button>
</div>
</div>
<div v-else-if="isSkillsNameColumn(item.col)" class="cell-wrap">
<input
type="text"
:value="d2PlainText(cellMappedZh(entry.rowIndex, item.index) || entry.row[item.index])"
:style="d2TextStyle(cellMappedZh(entry.rowIndex, item.index) || entry.row[item.index])"
:title="entry.row[item.index] || ''"
readonly
/>
</div>
<div v-else-if="isVersionColumn(item.col)" class="cell-wrap">
<VersionSelect
:model-value="entry.row[item.index]"
@update:model-value="updateCell(entry.rowIndex, item.index, $event)"
/>
</div>
<div v-else-if="isEnabledColumn(item.col)" class="cell-wrap">
<EnabledSelect
:model-value="entry.row[item.index]"
@update:model-value="updateCell(entry.rowIndex, item.index, $event)"
/>
</div>
<div v-else-if="isClassColumn(item.col)" class="cell-wrap">
<ClassSelect
:model-value="entry.row[item.index]"
@update:model-value="updateCell(entry.rowIndex, item.index, $event)"
/>
</div>
<div v-else class="cell-wrap">
<input
type="text"
:value="entry.row[item.index]"
:title="entry.row[item.index] || ''"
@input="updateCell(entry.rowIndex, item.index, $event.target.value)"
/>
<div v-if="cellMappedZh(entry.rowIndex, item.index)" class="cell-map-zh">
<span v-html="d2HtmlText(cellMappedZh(entry.rowIndex, item.index))"></span>
</div>
</div>
</td>
vue
<template>
<select :value="normalizedValue" :disabled="disabled" @change="onChange">
<option value="">未设置</option>
<option value="0">经典</option>
<option value="100">资料片</option>
</select>
</template>
vue
<template>
<div v-if="visible" class="class-picker-mask" @click="$emit('cancel')">
<div class="panel class-picker-panel" @click.stop>
<div class="class-picker-title">{{ title }}</div>
<div class="class-picker-options">
<label v-for="item in D2_CLASS_OPTIONS" :key="`${radioName}-${item.code}`" class="class-picker-option">
<input
:checked="selected === item.code"
type="radio"
:name="radioName"
:value="item.code"
@change="$emit('update:selected', item.code)"
/>
<span>{{ item.zh }}({{ item.code }})</span>
</label>
</div>
<div class="class-picker-actions">
<button type="button" @click="$emit('cancel')">取消</button>
<button type="button" class="success" @click="$emit('confirm')">确定</button>
</div>
</div>
</div>
</template>
js
export function stripD2ColorCodes(value) {
return normalizeD2ColorPrefixes(value).replace(/\u00FFc[0-9a-z;]/gi, '')
}
export function detectD2FirstColor(value) {
const normalized = normalizeD2ColorPrefixes(value)
const match = normalized.match(/\u00FFc([0-9a-z;])/i)
if (!match) return ''
const code = String(match[1] || '').toLowerCase()
return D2_COLOR_MAP[code] || ''
}
export function formatD2ColorHtml(value, fallback = '-') {
const raw = String(value || '')
if (!raw) return escapeHtml(fallback)
// ...
}这一组代码很能说明文件编辑模块并不是"所有字段一律文本框"。模块会针对 skills.txt 的 charclass 列启用职业弹窗,对 skill 列做只读映射显示和暗黑颜色码样式处理,对 version、enabled、职业类字段启用公共下拉组件,其余大部分字段仍旧保持文本输入。这种策略兼顾了通用编辑器的覆盖面和少量高频字段的易用性。从当前代码能够确认,字段类型识别目前是基于列名和文件名条件判断完成的,并不是一个完整的通用字段组件工厂。
行级编辑与保存链路代码
js
function findAutoNumberColIndex() {
const candidates = ['id', '*id', 'index', 'idx', '编号', '序号']
for (let i = 0; i < editorState.header.length; i += 1) {
const key = normalizeHeaderName(editorState.header[i])
if (candidates.includes(key)) {
return i
}
}
return -1
}
function nextAutoNumber(colIndex) {
let max = 0
for (const row of editorState.rows) {
const raw = String(row[colIndex] || '').trim()
if (!raw) continue
const num = Number(raw)
if (Number.isFinite(num)) {
max = Math.max(max, num)
}
}
return String(max + 1)
}
function addRow() {
if (!editorState.header.length) {
appendLog('请先加载文件')
return
}
const newRow = new Array(editorState.header.length).fill('')
const autoCol = findAutoNumberColIndex()
if (autoCol >= 0) {
newRow[autoCol] = nextAutoNumber(autoCol)
}
editorState.rows.push(newRow)
rebuildEditorRowSearchCache()
editorState.page = totalPages.value
appendLog('已新增一行')
}
function copySelectedRows() {
const selected = [...selectedRowSet.value].sort((a, b) => a - b)
if (!selected.length) {
appendLog('请先勾选要复制的行')
return
}
const autoCol = findAutoNumberColIndex()
let insertAt = selected[selected.length - 1] + 1
for (const rowIndex of selected) {
const src = editorState.rows[rowIndex]
if (!src) continue
const cloned = [...src]
if (autoCol >= 0) {
cloned[autoCol] = nextAutoNumber(autoCol)
}
editorState.rows.splice(insertAt, 0, cloned)
insertAt += 1
}
selectedRowSet.value = new Set()
rebuildEditorRowSearchCache()
appendLog(`已复制 ${selected.length} 行`)
}
function deleteSelectedRows() {
const selected = selectedRowSet.value
if (!selected.size) {
appendLog('请先勾选要删除的行')
return
}
editorState.rows = editorState.rows.filter((_, idx) => !selected.has(idx))
rebuildEditorRowSearchCache()
selectedRowSet.value = new Set()
appendLog('已删除选中行')
}
js
async function saveEditorFile() {
if (!state.excelPath || !editorState.fileName || !editorState.header.length) {
appendLog('请先加载要编辑的文件')
return
}
try {
const result = await invoke('py_save_table_json', {
folder: state.excelPath,
file: editorState.fileName,
encoding: editorState.encoding,
headerJson: JSON.stringify(editorState.header),
rowsJson: JSON.stringify(editorState.rows),
backupPath: backupPath.value || buildBackupPath(state.modPath),
})
appendLog(`Backup dir: ${backupPath.value || buildBackupPath(state.modPath)}`)
appendLog(`Backup file: ${result?.backup_path || '(none)'}`)
appendLog(`Backend dir: ${result?.backup_dir || '(none)'}`)
if (typeof syncSqliteTxtFile === 'function') {
await syncSqliteTxtFile(editorState.fileName, { logPrefix: '编辑器保存后 SQLite' })
}
appendLog(`保存成功: ${editorState.fileName}(${result.row_count} 行)`)
setCachedTableResult(state.excelPath, editorState.fileName, {
encoding: editorState.encoding,
header: [...editorState.header],
rows: cloneRows(editorState.rows),
row_count: editorState.rows.length,
path: joinExcelFilePath(state.excelPath, editorState.fileName),
})
} catch (error) {
appendLog(`保存失败: ${String(error)}`)
}
}这一部分完整展示了文件编辑模块的行级操作思想。新增和复制都会尝试识别自增列,候选列名包括 id、index、编号、序号 等,说明作者在做通用编辑器时已经考虑到一类高频表结构特征。保存链路也不只是把内存写回文件,而是同时传入编码、表头、行数据和备份目录,在保存成功后还会同步 SQLite 单文件缓存,并刷新本地表缓存。这说明文件编辑模块已经形成了一条完整的"内存编辑 -> 文件落盘 -> 备份生成 -> 缓存同步 -> 前端缓存回填"链路,而不是一次性的简单写盘动作。
后端 TXT 读写与 SQLite 同步代码
rust
pub fn list_files(folder: String) -> Result<Value, String> {
let dir = PathBuf::from(folder.trim());
if !dir.is_dir() {
return Err(format!("folder not found: {}", dir.to_string_lossy()));
}
let mut files: Vec<String> = fs::read_dir(&dir)
.map_err(|error| format!("read dir failed: {error}"))?
.flatten()
.filter_map(|entry| {
let p = entry.path();
if !p.is_file() {
return None;
}
let name = p.file_name()?.to_string_lossy().to_string();
if name.to_lowercase().ends_with(".txt") {
Some(name)
} else {
None
}
})
.collect();
files.sort_by_key(|name| name.to_lowercase());
Ok(json!({
"folder": dir.to_string_lossy(),
"files": files
}))
}
pub fn load_table(folder: String, file: String) -> Result<Value, String> {
let path = table_path(&folder, &file);
let (text, encoding) = read_text_with_encoding(&path)?;
let (header, rows) = parse_tab_text(&text);
if header.is_empty() {
return Err(format!("header empty: {}", file.trim()));
}
let backup_dir = backup_dir()?;
Ok(json!({
"folder": PathBuf::from(folder.trim()).to_string_lossy(),
"file": file.trim(),
"path": path.to_string_lossy(),
"encoding": encoding,
"backup_dir": backup_dir.to_string_lossy(),
"header": header,
"rows": rows,
"row_count": rows.len()
}))
}
rust
pub fn save_table_json(
folder: String,
file: String,
encoding: String,
header_json: String,
rows_json: String,
backup_path: Option<String>,
) -> Result<Value, String> {
let path = table_path(&folder, &file);
let header_values: Vec<Value> =
serde_json::from_str(&header_json).map_err(|error| format!("invalid header: {error}"))?;
let rows_values: Vec<Vec<Value>> =
serde_json::from_str(&rows_json).map_err(|error| format!("invalid rows: {error}"))?;
let header: Vec<String> = header_values
.into_iter()
.map(|v| v.to_string().trim_matches('"').to_string())
.collect();
let rows: Vec<Vec<String>> = rows_values
.into_iter()
.map(|row| {
row.into_iter()
.map(|v| match v {
Value::String(s) => s,
other => other.to_string(),
})
.collect()
})
.collect();
let backup_dir = normalize_backup_dir(backup_path.as_deref())?;
let backup_path = write_table(&path, &header, &rows, &encoding, Some(&backup_dir))?;
Ok(json!({
"file": file.trim(),
"path": path.to_string_lossy(),
"encoding": encoding,
"backup_path": backup_path,
"backup_dir": backup_dir.to_string_lossy(),
"row_count": rows.len()
}))
}
rust
#[tauri::command]
pub fn py_sync_txt_file_cache(
app: tauri::AppHandle,
excel_folder: String,
strings_folder: Option<String>,
hd_items_folder: Option<String>,
file_name: String,
) -> Result<Value, String> {
let excel_root = PathBuf::from(excel_folder.trim());
if !excel_root.is_dir() {
return Err(format!(
"excel folder not found: {}",
excel_root.to_string_lossy()
));
}
let strings_root = PathBuf::from(strings_folder.unwrap_or_default().trim());
let hd_root = PathBuf::from(hd_items_folder.unwrap_or_default().trim());
let (mut conn, db_path, db_name_rule) = open_cache_conn(&app, &excel_root, &strings_root, &hd_root)?;
let imported_at = OffsetDateTime::now_utc().unix_timestamp();
let stats = upsert_txt_file(&mut conn, &excel_root, &file_name, imported_at)?;
Ok(json!({
"db_path": db_path.to_string_lossy(),
"db_name_rule": db_name_rule,
"file": file_name,
"synced": {
"txt_files": stats.files,
"txt_rows": stats.rows
}
}))
}
rust
pub(crate) fn upsert_txt_file(
conn: &mut Connection,
excel_root: &Path,
file_name: &str,
imported_at: i64,
) -> Result<TxtImportStats, String> {
let target_name = file_name.trim();
if target_name.is_empty() {
return Err("txt file name is empty".to_string());
}
let target_path = excel_root.join(target_name);
if !target_path.is_file() {
return Err(format!(
"txt file not found: {}",
target_path.to_string_lossy()
));
}
let (text, encoding) = read_text_with_encoding(&target_path)?;
let (header, rows) = parse_tab_text(&text);
let header_json =
serde_json::to_string(&header).map_err(|error| format!("txt header json failed: {error}"))?;
let file_key = relative_key(excel_root, &target_path);
let tx = conn
.transaction()
.map_err(|error| format!("begin txt upsert transaction failed: {error}"))?;
tx.execute("DELETE FROM cache_txt_rows WHERE file_key = ?1", params![&file_key])
.map_err(|error| format!("clear old txt rows failed: {error}"))?;
tx.execute("DELETE FROM cache_txt_files WHERE file_key = ?1", params![&file_key])
.map_err(|error| format!("clear old txt file failed: {error}"))?;
// ...
}后端这一层把前端的通用编辑器真正落地成可用工具。list_files 只返回 TXT 文件,说明文件编辑模块的编辑边界就是当前目录内的 TXT 表;load_table 会保留编码、解析 header 与 rows,这也是前端能按原编码回写的重要前提;save_table_json 在写盘前会把前端传来的 JSON 还原成字符串表格,并通过 write_table 生成备份;py_sync_txt_file_cache 则把刚保存的目标文件单独增量写入 SQLite,而不是每次全量重建缓存。这种设计非常适合频繁调参的桌面工具场景。
从当前代码能够确认,文件编辑模块已经具备完整的后端保存链路,并不是只有前端内存修改。也正因为保存后会立即同步 SQLite,后续依赖 SQLite 查询能力的模块能够更快看到变更结果。至于更复杂的字段级合法性校验、跨文件引用一致性校验和事务性批量回滚,从当前模块代码里并没有看到通用实现,这部分不能在文章里写成已具备能力。
布局控制代码
css
.editor-panel {
flex: 1;
min-height: 0;
display: flex;
flex-direction: column;
gap: 8px;
}
.editor-toolbar {
display: flex;
align-items: center;
justify-content: space-between;
gap: 12px;
flex-wrap: wrap;
}
.table-wrap {
border: 1px solid #2f4665;
border-radius: 8px;
overflow-x: auto;
overflow-y: auto;
max-height: 100%;
flex: 1;
min-height: 220px;
}
.table-wrap table {
width: max-content;
min-width: 100%;
border-collapse: collapse;
}
.table-wrap th,
.table-wrap td {
border: 1px solid #2b3f5b;
padding: 4px;
white-space: nowrap;
text-align: center;
}
.table-wrap th {
background: #122338;
position: sticky;
top: 0;
z-index: 1;
vertical-align: middle;
padding: 0 4px;
height: 30px;
}
.cell-map-zh {
font-size: 11px;
line-height: 1.1;
color: #9fc2f5;
white-space: nowrap;
text-overflow: ellipsis;
overflow: hidden;
}
.table-wrap tbody tr.row-selected td {
background: rgba(55, 120, 232, 0.18);
border-color: #4d8dff;
}从布局实现可以直接看出,这个模块没有单独的布局配置 JSON。界面结构由 EditorTab.vue 模板和公共 CSS 类共同完成,表头采用 sticky 方式固定,主体区域允许横向与纵向滚动,中文映射文本放在输入框下方的第二行,选中行则通过背景和边框颜色强化。对于需要编辑大量列的 TXT 表来说,这套布局是非常典型的桌面工具风格,也比简单堆叠表单更适合通用编辑器场景。
操作演示
文件编辑模块在软件使用层面的路径比较清晰。进入文件编辑页后,先通过目标文件输入框选择要编辑的 TXT 文件,模块会自动加载表头、行数据和列映射;文件名支持模糊搜索,字段筛选则只在当前可见列范围内生效;数据区支持分页、全量显示、勾选选中、批量复制和删除;保存后会生成备份并同步单文件 SQLite 缓存。这个流程非常适合做高频调参和快速验证。
从当前代码能够确认的内容里,文件编辑模块并没有把回滚入口直接放在当前页面里。保存时虽然会生成备份,但备份的浏览和恢复能力更多挂在"文件配置"页相关逻辑上。也就是说,文件编辑页负责高频改,回滚能力则由其他页签配合完成,这个边界在使用说明里应当说清楚。
文件编辑模块操作演示表
| 操作阶段 | 界面表现 | 触发动作 | 对应代码 | 可确认结果 |
|---|---|---|---|---|
| 进入模块 | 左侧一级页签切到"文件编辑" | 点击侧栏按钮 | switchMainTab('editor') |
挂载 EditorTab,并在需要时预加载文件列表 |
| 选择目标文件 | 顶部"目标文件"输入框与候选列表 | 输入关键字、按回车或点选候选项 | filteredFiles、applyFileSearchSelection、pickFile |
文件名支持按英文名、中文名和说明模糊匹配 |
| 加载表格 | 顶部状态显示文件名、行数、列数 | 选中文件后自动加载 | openEditorFile() -> py_load_table |
加载 header、rows、encoding 和列映射 |
| 查看列说明 | 表头中文标题与 tooltip | 鼠标悬停列头 | loadColumnMapping、colZh、colTooltip |
显示字段中文名和说明 |
| 字段筛选 | "字段筛选"下拉框 | 选择目标列 | editorState.filterColumn |
关键字过滤只作用于当前列 |
| 关键字过滤 | 关键字输入框 | 输入搜索内容 | editorFilterKeywordActive、filteredRowIndexes |
180ms 去抖后过滤可见行 |
| 分页浏览 | "页面过滤"区域 | 选择 100、200、500、1000 或全部 | pageSize、pagedRowEntries |
控制单页展示规模 |
| 行级修改 | 表格单元格输入框、下拉框、弹窗 | 直接改值 | updateCell |
修改即时写入内存数据 |
| 新增记录 | 工具栏"新增"按钮 | 点击新增 | addRow |
追加空行;存在编号列时自动补下一个编号 |
| 复制记录 | 勾选复选框后点"复制" | 复制选中行 | copySelectedRows |
按当前选中集合插入克隆行 |
| 删除记录 | 勾选复选框后点"删除" | 删除选中行 | deleteSelectedRows |
从当前数据集中移除记录 |
| 保存结果 | 工具栏"保存"按钮 | 保存当前文件 | saveEditorFile -> py_save_table_json -> py_sync_txt_file_cache |
写回 TXT、生成备份、同步 SQLite、刷新前端缓存 |
这个流程里最值得强调的一点,是文件编辑模块并不是"保存即结束"的孤立页面。由于保存后会做单文件 SQLite 同步,后续再次加载或在其他依赖缓存的模块里查看对应数据时,一致性会更高。这种设计对频繁调试同一份 MOD 数据的场景很有价值。
总结
暗黑破坏神2 MOD 修改工具的文件编辑模块,是整套工具里最接近底层数据表的一层通用编辑入口。它不强调特定业务语义,而是围绕 TXT 表提供文件搜索、列映射、数据过滤、分页浏览、单元格编辑、批量复制删除、备份保存和 SQLite 单文件同步。正因为它足够通用,文件编辑模块才会影响装备、技能、怪物、地图、公式等多个方向的数据维护工作流。
从开发实现上看,这个模块的价值并不只是"能编辑表格"。更重要的是,它把通用编辑器拆成了稳定的几层:主页面壳层负责挂载,控制器负责状态和上下文,映射辅助模块负责把 index.json 与 columns.json 转成可读界面,CRUD 辅助模块负责行级操作,Tauri 后端负责真实读写,SQLite 命令负责同步缓存。这样的结构让文件编辑模块既能服务当前项目,也适合后续继续扩展。如果后面还要继续写这一系列 CSDN 稿件,文件编辑模块实际上就是理解整个工具底层数据工作方式的一把总钥匙。