- AI 智能生成试卷:根据知识库内容或用户自由描述,自动生成包含单选、多选、文本题的试卷,并自动分配分值。
- AI 批量阅卷:用户提交答案后,AI 一次性批改所有题目,返回包含详细评分、正确答案和评语的完整成绩单。
本文将提供 可直接运行的代码、数据库脚本以及提示词模板,并对关键逻辑添加详细注释,帮助开发者快速落地自己的 AI 应用。完整代码使用CRUD生成即可
一、技术栈与架构说明
| 技术组件 | 版本 / 说明 |
|---|---|
| 基础框架 | RuoYi-Vue-Plus 5.x(Spring Boot 3.5 + JDK 17 + Sa-Token) |
| ORM | MyBatis-Plus |
| JSON 处理 | Fastjson2 |
| HTTP 客户端 | Hutool HttpUtil |
| AI 模型 | DeepSeek(兼容 OpenAI API 格式) |
| 数据库 | MySQL 8.0(支持 JSON 字段) |
整体流程:
bash
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 前端 Vue3 │ ───→ │ Controller 层 │ ───→ │ AI 生成/阅卷服务 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │
↓ ↓
┌─────────────────┐ ┌─────────────────┐
│ MyBatis-Plus │ │ DeepSeek API │
└─────────────────┘ └─────────────────┘
二、数据库设计(含完整建表脚本)
以下为实际项目使用的表结构,包含 RuoYi 框架的标准字段(租户、部门、逻辑删除等)。JSON 字段用于存储灵活的配置和答案快照。
sql
CREATE TABLE `a_exam_paper` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(100) NOT NULL COMMENT '试卷名称',
`gen_type` char(1) NOT NULL COMMENT '生成方式:1=知识库 2=自由描述',
`gen_config` varchar(500) DEFAULT NULL COMMENT '生成配置快照(如目录ID、描述原文、模型参数)',
`total_score` int NOT NULL DEFAULT '0' COMMENT '试卷总分',
`question_count` int NOT NULL DEFAULT '0' COMMENT '题目总数',
`status` char(1) NOT NULL DEFAULT '0' COMMENT '状态:0生成中 1已生成 2已作废',
`create_by` varchar(64) DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_by` varchar(64) DEFAULT NULL COMMENT '更新人',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`tenant_id` varchar(20) DEFAULT '000000' COMMENT '租户编号',
`create_dept` bigint DEFAULT NULL COMMENT '创建部门',
`del_flag` int DEFAULT '0' COMMENT '删除标志',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='试卷主表';
CREATE TABLE `a_exam_question` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`paper_id` bigint NOT NULL COMMENT '所属试卷ID',
`type` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '题型:1=单选 2=多选 3=文本',
`content` text NOT NULL COMMENT '题干',
`options` text COMMENT '选项列表(仅单选/多选有值)',
`answer` text NOT NULL COMMENT '标准答案(单选存A,多生存JSON数组,文本存要点)',
`analysis` text COMMENT '答案解析',
`score` int NOT NULL DEFAULT '0' COMMENT '分值',
`sort` int NOT NULL DEFAULT '0' COMMENT '排序',
`tenant_id` varchar(20) DEFAULT '000000' COMMENT '租户编号',
`create_dept` bigint DEFAULT NULL COMMENT '创建部门',
`del_flag` int DEFAULT '0' COMMENT '删除标志',
`create_by` varchar(64) DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_by` varchar(64) DEFAULT NULL COMMENT '更新人',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_paper_id` (`paper_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='题目明细表';
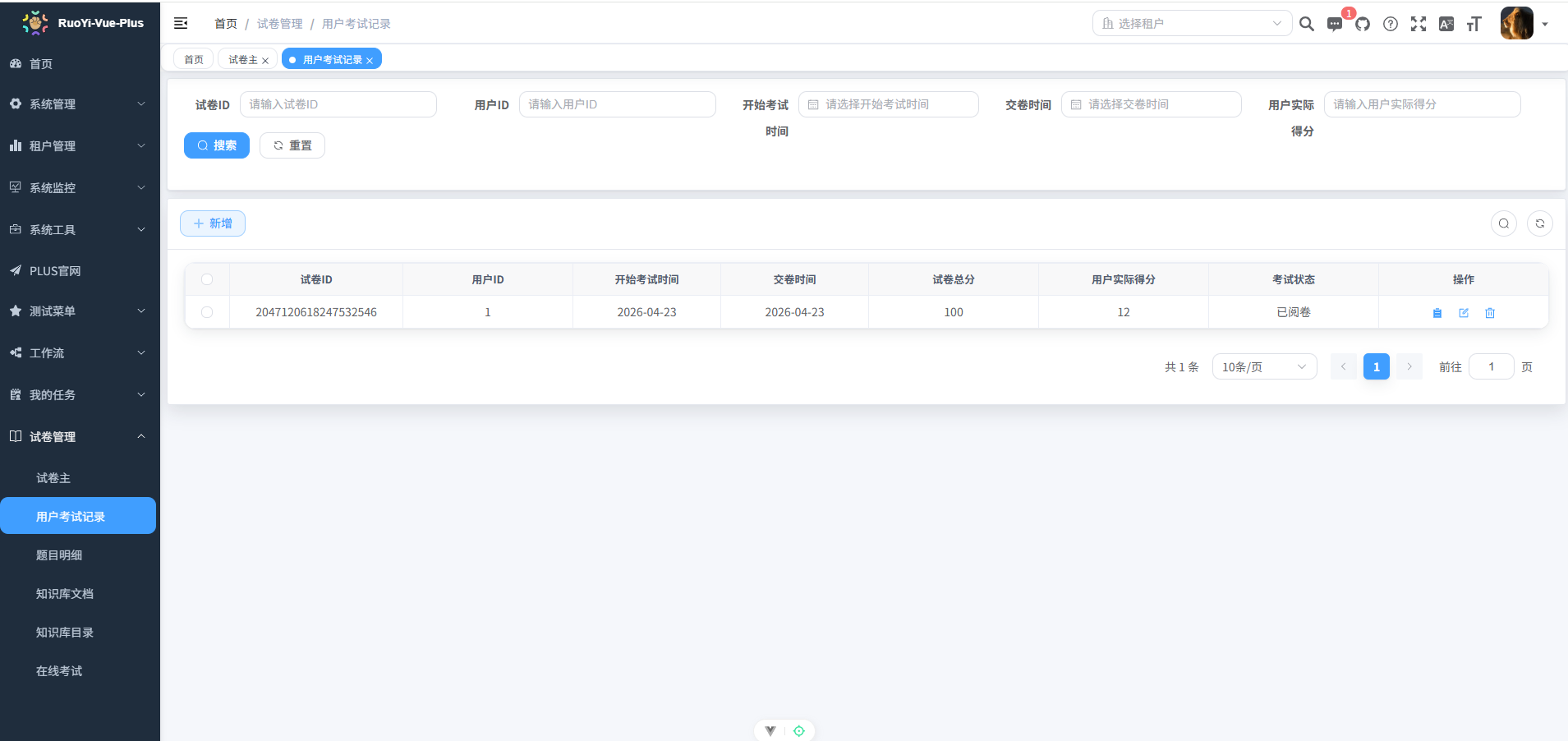
CREATE TABLE `a_exam_user_record` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`paper_id` bigint NOT NULL COMMENT '试卷ID',
`user_id` bigint NOT NULL COMMENT '用户ID(关联sys_user)',
`start_time` datetime DEFAULT NULL COMMENT '开始考试时间',
`end_time` datetime DEFAULT NULL COMMENT '交卷时间',
`total_score` int NOT NULL DEFAULT '0' COMMENT '试卷总分(冗余,便于统计)',
`user_score` int NOT NULL DEFAULT '0' COMMENT '用户实际得分',
`status` char(1) NOT NULL DEFAULT '0' COMMENT '考试状态:0进行中 1已完成 2已阅卷',
`answers_snapshot` json DEFAULT NULL COMMENT '用户全部答案快照(JSON格式,便于回溯)',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`tenant_id` varchar(20) DEFAULT '000000' COMMENT '租户编号',
`create_dept` bigint DEFAULT NULL COMMENT '创建部门',
`del_flag` int DEFAULT '0' COMMENT '删除标志',
`create_by` varchar(64) DEFAULT NULL COMMENT '创建人',
`update_by` varchar(64) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_paper_user` (`paper_id`,`user_id`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户考试记录表(含总分与答案快照)';
DROP TABLE IF EXISTS `a_kb_category`;
CREATE TABLE `a_kb_category` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`parent_id` bigint NOT NULL DEFAULT '0' COMMENT '父级ID,0为根目录',
`name` varchar(100) NOT NULL COMMENT '目录名称',
`sort` int NOT NULL DEFAULT '0' COMMENT '排序',
`create_by` bigint DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_by` bigint DEFAULT NULL COMMENT '更新人',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`tenant_id` varchar(20) DEFAULT '000000' COMMENT '租户编号',
`create_dept` bigint DEFAULT NULL COMMENT '创建部门',
`del_flag` int DEFAULT '0' COMMENT '删除标志',
PRIMARY KEY (`id`),
KEY `idx_parent_id` (`parent_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='知识库目录表';
CREATE TABLE `a_kb_document` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`category_id` bigint NOT NULL COMMENT '所属目录ID',
`title` varchar(200) NOT NULL COMMENT '文档标题',
`content` longtext NOT NULL COMMENT '文档正文(支持Markdown)',
`keywords` varchar(500) DEFAULT NULL COMMENT '关键词,多个用逗号分隔',
`status` char(1) NOT NULL DEFAULT '0' COMMENT '状态:0正常 1停用',
`create_by` bigint DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_by` bigint DEFAULT NULL COMMENT '更新人',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`tenant_id` varchar(20) DEFAULT '000000' COMMENT '租户编号',
`create_dept` bigint DEFAULT NULL COMMENT '创建部门',
`del_flag` int DEFAULT '0' COMMENT '删除标志',
PRIMARY KEY (`id`),
KEY `idx_category_id` (`category_id`),
FULLTEXT KEY `ft_content` (`title`,`content`,`keywords`) /*!50100 WITH PARSER `ngram` */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='知识库文档表';
三、AI 服务封装(AIService)
我们使用 Hutool 的 HttpUtil 直接调用 DeepSeek API,因其完全兼容 OpenAI 接口规范,无需额外 SDK。
java
package org.dromara.exam.utils;
import cn.hutool.core.util.StrUtil;
import cn.hutool.http.HttpRequest;
import cn.hutool.http.HttpResponse;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import jakarta.annotation.PostConstruct;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* AI 服务类,封装 DeepSeek API 调用
* 使用 HTTP 直连方式,兼容 OpenAI 格式
*/
@Slf4j
@Service
public class AIService {
@Value("${deepseek.api-key}")
private String apiKey;
@Value("${deepseek.model:deepseek-chat}")
private String model;
@Value("${deepseek.temperature:0.7}")
private Double temperature;
@Value("${deepseek.max-tokens:4096}")
private Integer maxTokens;
private static final String DEEPSEEK_URL = "https://api.deepseek.com/v1/chat/completions";
@PostConstruct
public void init() {
if (StrUtil.isBlank(apiKey)) {
log.error("❌ DeepSeek API Key 未配置,AI 服务将不可用");
} else {
log.info("✅ AI 服务初始化完成,模型:{}", model);
}
}
/**
* 发送聊天请求
* @param prompt 完整的提示词内容
* @return AI 生成的文本响应(通常为 JSON 字符串)
*/
public String chat(String prompt) {
if (StrUtil.isBlank(apiKey)) {
throw new RuntimeException("AI 服务未就绪,请检查 DeepSeek 配置");
}
// 构建 OpenAI 兼容格式的请求体
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", model);
requestBody.put("messages", List.of(Map.of("role", "user", "content", prompt)));
requestBody.put("temperature", temperature);
requestBody.put("max_tokens", maxTokens);
requestBody.put("response_format", Map.of("type", "json_object")); // 强制返回 JSON
String jsonBody = JSON.toJSONString(requestBody);
try (HttpResponse response = HttpRequest.post(DEEPSEEK_URL)
.header("Authorization", "Bearer " + apiKey)
.header("Content-Type", "application/json")
.body(jsonBody)
.execute()) {
if (!response.isOk()) {
log.error("DeepSeek API 调用失败,状态码:{},响应:{}", response.getStatus(), response.body());
throw new RuntimeException("AI 服务调用失败,状态码:" + response.getStatus());
}
JSONObject respJson = JSON.parseObject(response.body());
String content = respJson.getJSONArray("choices")
.getJSONObject(0)
.getJSONObject("message")
.getString("content");
log.debug("AI 响应:{}", content);
return content;
} catch (Exception e) {
log.error("AI 调用异常", e);
throw new RuntimeException("AI 服务异常:" + e.getMessage(), e);
}
}
}配置示例(application.yml):
bash
deepseek:
api-key: sk-your-api-key-here
model: deepseek-chat
temperature: 0.7
max-tokens: 4096四、提示词模板管理
将提示词独立为文件,便于维护和调优。使用 PromptTemplateLoader 从 classpath 加载。
4.1 提示词加载器
java
package org.dromara.exam.utils;
import cn.hutool.core.io.resource.ResourceUtil;
import org.springframework.stereotype.Component;
import java.nio.charset.StandardCharsets;
@Component
public class PromptTemplateLoader {
public String loadTemplate(String fileName) {
try {
return ResourceUtil.readStr("prompts/" + fileName, StandardCharsets.UTF_8);
} catch (Exception e) {
throw new RuntimeException("提示词模板加载失败: " + fileName, e);
}
}
}4.2 试卷生成提示词(generate_paper_prompt.txt)
bash
你是一名资深教育专家和出题老师。请严格依据以下【参考资料】生成 {question_count} 道题目,满分 {total_score} 分,题型分布建议:单选 60%、多选 20%、文本 20%。
【参考资料】
{reference_content}
【输出要求】
1. 输出必须是一个合法的 JSON 对象,不包含任何额外文字或注释。
2. JSON 结构必须严格遵循以下示例。
示例 JSON:
{
"questions": [
{
"type": "single",
"content": "Java中,下列哪个关键字用于创建线程?",
"options": ["A. extends", "B. implements", "C. new", "D. synchronized"],
"answer": "B",
"analysis": "实现Runnable接口使用implements关键字。",
"score": 1,
"sort": 1
},
{
"type": "multiple",
"content": "以下哪些属于HTTP请求方法?",
"options": ["A. GET", "B. POST", "C. SEND", "D. PUT", "E. DELETE"],
"answer": ["A","B","D","E"],
"analysis": "HTTP常见方法有GET、POST、PUT、DELETE等。",
"score": 1,
"sort": 2
},
{
"type": "text",
"content": "请简述面向对象编程的三大特性。",
"options": null,
"answer": "封装、继承、多态。",
"analysis": "封装隐藏内部实现,继承扩展父类功能,多态同一接口不同实现。",
"score": 1,
"sort": 3
}
]
}4.3 批量阅卷提示词(grading_batch_prompt.txt)
该模板要求 AI 一次性返回包含题目完整信息及评分结果的 JSON 数组,实现自包含的成绩单。
bash
你是一名严格的阅卷老师。请根据以下【题目列表】一次性批改所有题目,并按顺序返回每一道题的评分结果。
【题目列表】(共 {question_count} 道题)
{batch_questions_json}
【评分规则】
1. 单选题:学生答案与标准答案完全一致(忽略大小写)得满分,否则0分。
2. 多选题:完全正确得满分,部分正确得一半分,全错或漏选不得分。
3. 文本题:根据语义相似度和关键要点覆盖度判断,满分按比例折算(例如总分5分,语义匹配度80%则得4分)。
【输出要求】
必须返回一个严格的 JSON 数组,数组长度必须与题目列表数量一致,顺序一一对应。每个元素必须包含以下字段:
- question_id:题目ID(与输入一致)
- type:题型(与输入一致,取值为 single / multiple / text)
- content:题干(与输入一致)
- options:选项(与输入一致)
- standard_answer:标准答案(与输入一致)
- user_answer:学生答案(与输入一致)
- score:题目分值(与输入一致)
- is_correct:"1"(正确)或 "0"(错误)
- score_earned:实际得分(整数)
- feedback:简短评语,若错误需给出正确答案提示
【输出示例】
[
{
"question_id": 1,
"type": "single",
"content": "Java支持哪种继承方式?",
"options": ["A. 单继承", "B. 多继承", "C. 接口多继承", "D. 以上都是"],
"standard_answer": "A",
"user_answer": "A",
"score": 5,
"is_correct": "1",
"score_earned": 5,
"feedback": "回答正确"
},
{
"question_id": 2,
"type": "multiple",
"content": "以下哪些属于HTTP请求方法?",
"options": ["A. GET", "B. POST", "C. SEND", "D. PUT", "E. DELETE"],
"standard_answer": ["A","B","D","E"],
"user_answer": ["A","C"],
"score": 5,
"is_correct": "0",
"score_earned": 2,
"feedback": "漏选D、E,多选C,正确答案为A、B、D、E"
},
{
"question_id": 3,
"type": "text",
"content": "请简述面向对象编程的三大特性。",
"options": null,
"standard_answer": "封装、继承、多态",
"user_answer": "封装、继承、多态",
"score": 10,
"is_correct": "1",
"score_earned": 10,
"feedback": "要点齐全,回答正确"
}
]五、核心业务实现(IAIGenerateService)
该类集成了试卷生成和批量阅卷两大核心功能,可以使用 @Async 实现异步处理,避免阻塞前端(本文章为了演示未使用)。
5.1 AI 生成试卷
流程:根据生成方式获取参考资料 → 构建提示词 → 调用 AI → 解析 JSON 并批量插入题目。
java
@Transactional(rollbackFor = Exception.class)
public void generatePaper(PaperBo bo ) {
try{
String reference = "";
// 生成方式:1=知识库 2=自由描述
if ("1".equals(bo.getGenType())) {
// 知识库生成:genConfig 为逗号分隔的文档ID字符串
String[] ids = bo.getGenConfig().split(",");
//通过文档ID获取文档内容
List<Document> documents = documentMapper.selectByIds(List.of(ids));
if (documents != null && !documents.isEmpty()) {
// 拼接文档标题和内容
reference = documents.stream()
.map(doc -> "【" + doc.getTitle() + "】\n" + doc.getContent())
.reduce((a, b) -> a + "\n\n---\n\n" + b)
.orElse("");
} else {
reference = "暂无相关参考资料。";
}
} else {
// 自由描述生成:genConfig 为用户输入的描述
reference = bo.getGenConfig();
}
// 2. 构建提示词
String template = promptUtil.loadTemplate("generate_paper_prompt.txt");
// 替换模板中的占位符 共3个:{question_count}、{reference_content}、{total_score}分别对应试卷参数中的题目数量、参考内容、总分数
String prompt = template
.replace("{question_count}", String.valueOf(bo.getQuestionCount()))
.replace("{reference_content}", reference)
.replace("{total_score}", String.valueOf(bo.getTotalScore()))
.toString();
// 3. 调用 AI 服务
String aiResponse = aiService.chat(prompt);
log.info("AI 响应:{}", aiResponse);
// 4. 解析题目并入库
parseAndSaveQuestions(aiResponse, bo.getId());
}catch (Exception e){
log.error("生成试卷失败", e);
throw new RuntimeException("生成试卷失败", e);
}
}
/**
* 解析题目并入库
* @param aiResponse AI 响应的 JSON 字符串
* @param paperId 试卷ID
*/
private void parseAndSaveQuestions(String aiResponse, Long paperId) {
// 解析题目并入库的逻辑
String json = aiResponse.replaceAll("```json", "").replaceAll("```", "").trim();
JSONObject root = JSON.parseObject(json);
// 从 JSON 中提取 questions 数组
JSONArray questions = root.getJSONArray("questions");
//TODO 解析题目并入库的逻辑
//从 questions 数组中提取每个对象
List<Question> questionsList = new ArrayList<>();
for (Object question : questions) {
Question newQuestion = new Question();
newQuestion.setPaperId(paperId);
JSONObject q = JSON.parseObject(question.toString());
newQuestion.setType(q.getString("type"));
newQuestion.setContent(q.getString("content"));
newQuestion.setOptions(q.getString("options"));
newQuestion.setAnswer(q.getString("answer"));
newQuestion.setAnalysis(q.getString("analysis"));
newQuestion.setScore(q.getLong("score"));
newQuestion.setSort(q.getLong("sort"));
questionsList.add(newQuestion);
}
boolean flag = questionMapper.insertBatch(questionsList);
if (flag) {
LambdaUpdateWrapper<Paper> luw = Wrappers.lambdaUpdate();
luw.eq(Paper::getId, paperId);
luw.set(Paper::getStatus, "1");
paperMapper.update(luw);
}
log.info("解析到 {} 道题目", questions.size());
}5.2 AI 批量阅卷
流程:解析用户提交的极简答案 → 构建包含题目完整信息的 JSON 数组 → 调用 AI 批量评分 → 将 AI 返回的完整成绩单直接覆盖 answers_snapshot
java
/**
* 阅卷(批量模式)
*/
@Transactional(rollbackFor = Exception.class)
public void gradePaper(UserRecordBo bo) {
try {
//用户全部答案JSON 格式 [
// { "questionId": 1, "answer": "B" },
// { "questionId": 2, "answer": "[\"A\",\"C\"]" }
//]
String answersSnapshot = bo.getAnswersSnapshot();
if (StrUtil.isBlank(answersSnapshot)) {
throw new IllegalArgumentException("答案快照不能为空");
}
//获取试卷
Paper paper = paperMapper.selectById(bo.getPaperId());
if (paper == null) {
throw new IllegalArgumentException("试卷不存在");
}
// 1. 获取题目列表
LambdaQueryWrapper<Question> qw = Wrappers.lambdaQuery();
qw.eq(Question::getPaperId, paper.getId());
qw.orderByAsc(Question::getSort);
List<Question> questions = questionMapper.selectList(qw);
if (CollUtil.isEmpty(questions)) {
throw new IllegalArgumentException("试卷中没有题目");
}
// 2. 解析用户提交的原始答案(极简格式)
List<AnswerItem> answerItems = JSON.parseArray(answersSnapshot, AnswerItem.class);
// 从用户提交的答案原始格式中提取题目ID和答案
Map<Long, String> answerMap = answerItems.stream()
.collect(Collectors.toMap(AnswerItem::getQuestionId, AnswerItem::getAnswer));
// 3. 构建批量阅卷的输入 JSON 数组
JSONArray batchInput = new JSONArray();
for (Question q : questions) {
JSONObject item = new JSONObject();
item.put("question_id", q.getId());
item.put("type", q.getType());
item.put("content", q.getContent());
item.put("options", q.getOptions() == null ? null : JSON.parseArray(q.getOptions()));
item.put("standard_answer", q.getAnswer());
item.put("score", q.getScore());
// 从用户提交的答案中获取该题的答案
item.put("user_answer", answerMap.getOrDefault(q.getId(), ""));
batchInput.add(item);
}
// 4. 加载提示词模板并构建 Prompt
String template = promptUtil.loadTemplate("grading_batch_prompt.txt");
// 替换模板中的占位符 共2个:{question_count}、{batch_questions_json}分别对应试卷参数中的题目数量、批量阅卷的输入 JSON 数组
String prompt = template
.replace("{question_count}", String.valueOf(questions.size()))
.replace("{batch_questions_json}", batchInput.toJSONString());
// 5. 调用 AI 批量评分
String aiResponse = aiService.chat(prompt);
log.info("AI 响应:{}", aiResponse);
// 从 JSON 中提取 results 数组
JSONArray resultArray = JSON.parseArray(aiResponse);
//TODO 解析 AI 返回的 JSON 数组然后入库到数据库
//6. 计算总分并校验结果长度
int totalScore = 0;
if (resultArray.size() != questions.size()) {
log.warn("AI 返回结果数量 {} 与题目数量 {} 不一致,将按实际匹配计分",
resultArray.size(), questions.size());
}
for (int i = 0; i < resultArray.size(); i++) {
JSONObject gradeObj = resultArray.getJSONObject(i);
totalScore += gradeObj.getIntValue("score_earned");
}
// 7. 更新考试记录:总分、状态、完整成绩单快照
LambdaUpdateWrapper<UserRecord> luw = Wrappers.lambdaUpdate();
luw.eq(UserRecord::getId, bo.getId());
luw.set(UserRecord::getUserScore, totalScore);
luw.set(UserRecord::getStatus, "2");
// 覆盖为完整成绩单
luw.set(UserRecord::getAnswersSnapshot, resultArray.toJSONString());
userRecordMapper.update(null, luw);
} catch (Exception e) {
log.error("阅卷失败, recordId: {}", bo.getId(), e);
throw new RuntimeException("阅卷失败: " + e.getMessage(), e);
}
}阅卷前:
bash
[
{ "questionId": 1, "answer": "B" },
{ "questionId": 2, "answer": "[\"A\",\"C\"]" }
]阅卷后:
bash
[
{
"questionId": 1,
"content": "Java中,哪个关键字用于实现封装?",
"userAnswer": "B",
"standardAnswer": "B",
"scoreEarned": 5,
"aiFeedback": "回答正确"
...
}
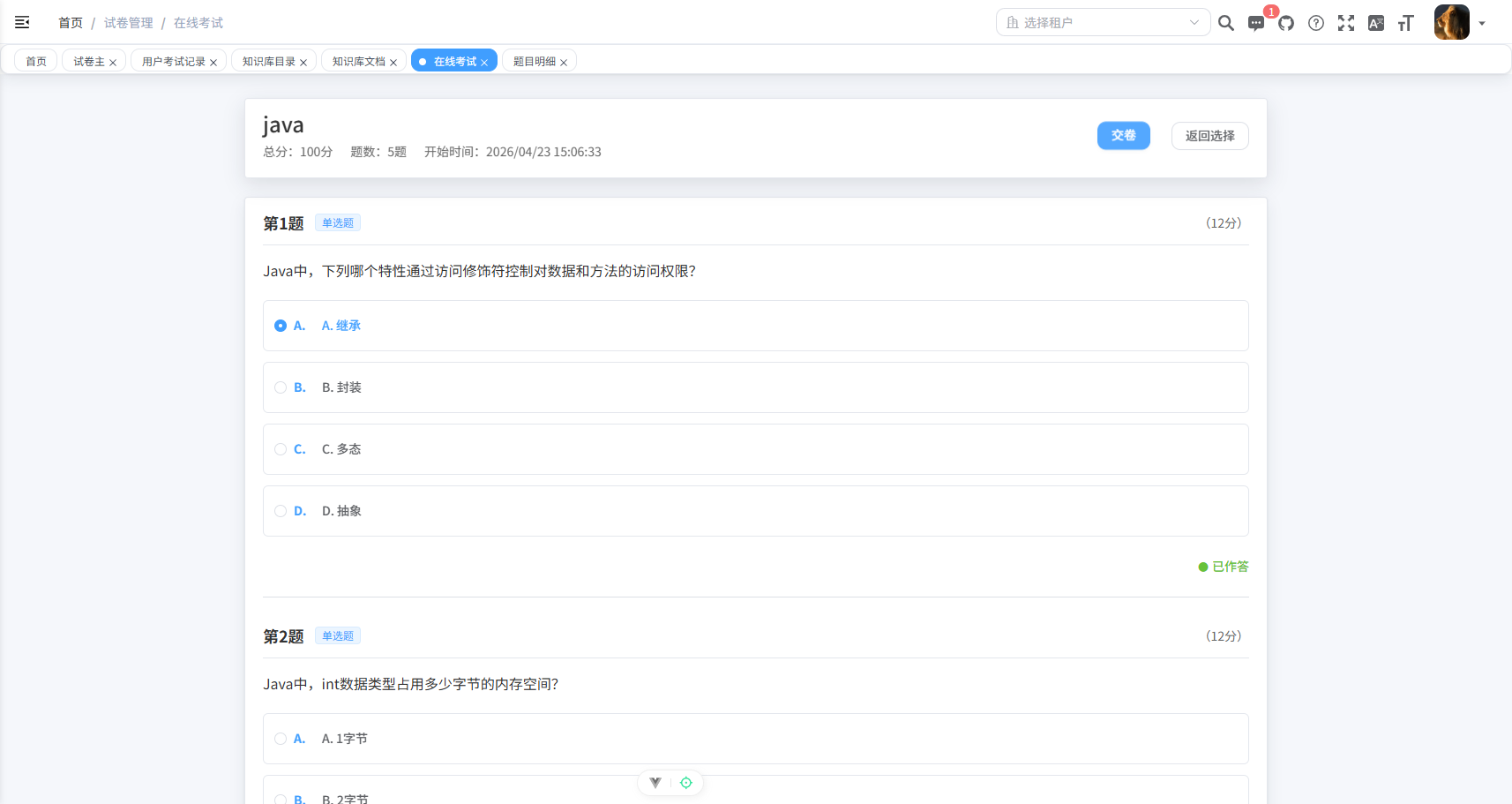
]六、运行效果展示
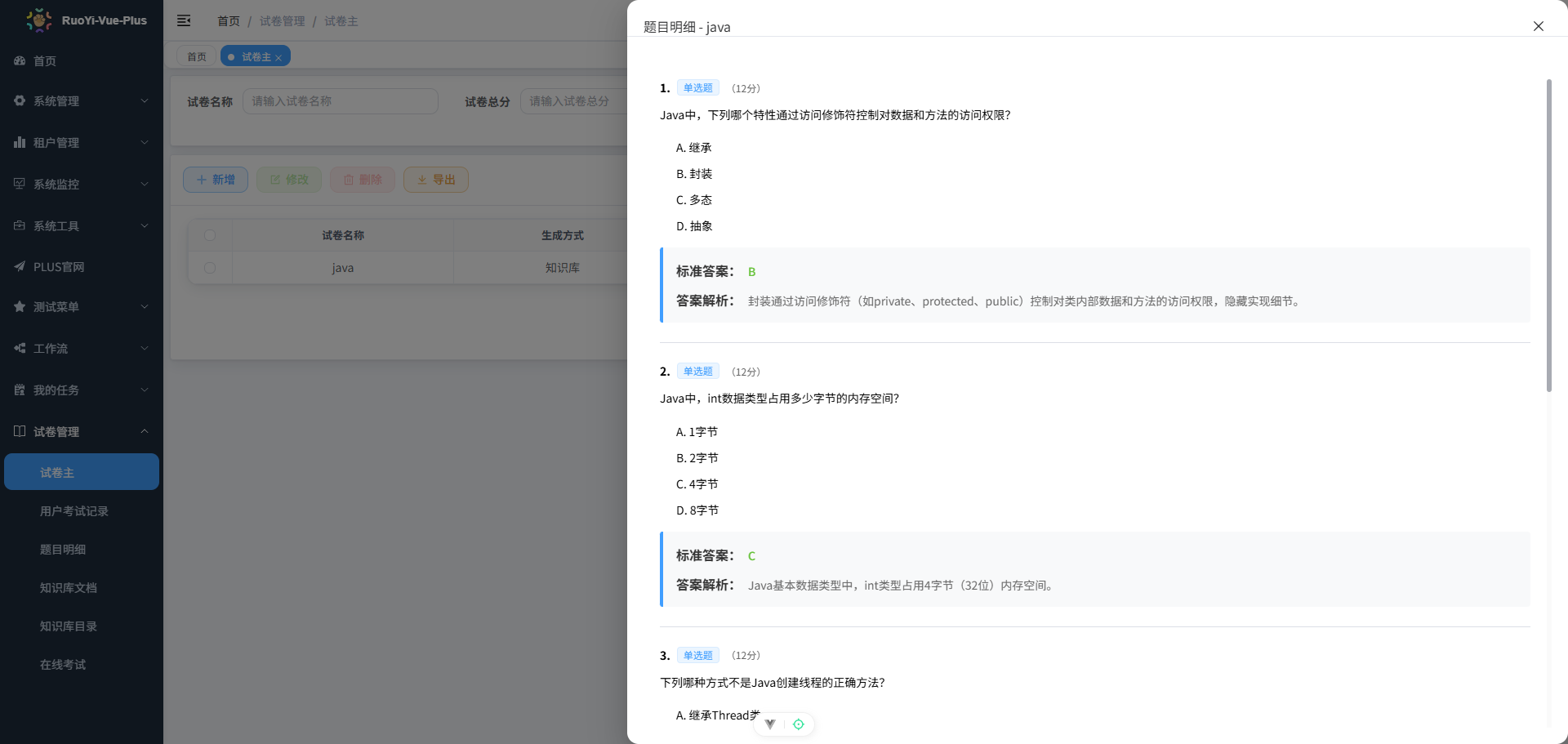
6.1 生成试卷示例
基于知识库目录 1,2,3是自定义到数据库的ID(Java 技术栈)生成 5 道题、总分 100 分的试卷,AI 返回并入库的题目如下(截取自数据库):
bash
{
"questions": [
{
"type": "single",
"content": "Java中,下列哪个关键字用于创建线程?",
"options": ["A. extends", "B. implements", "C. new", "D. synchronized"],
"answer": "B",
"analysis": "实现Runnable接口使用implements关键字。",
"score": 1,
"sort": 1
},
{
"type": "multiple",
"content": "以下哪些属于HTTP请求方法?",
"options": ["A. GET", "B. POST", "C. SEND", "D. PUT", "E. DELETE"],
"answer": ["A","B","D","E"],
"analysis": "HTTP常见方法有GET、POST、PUT、DELETE等。",
"score": 1,
"sort": 2
},
{
"type": "text",
"content": "请简述面向对象编程的三大特性。",
"options": null,
"answer": "封装、继承、多态。",
"analysis": "封装隐藏内部实现,继承扩展父类功能,多态同一接口不同实现。",
"score": 1,
"sort": 3
}
]
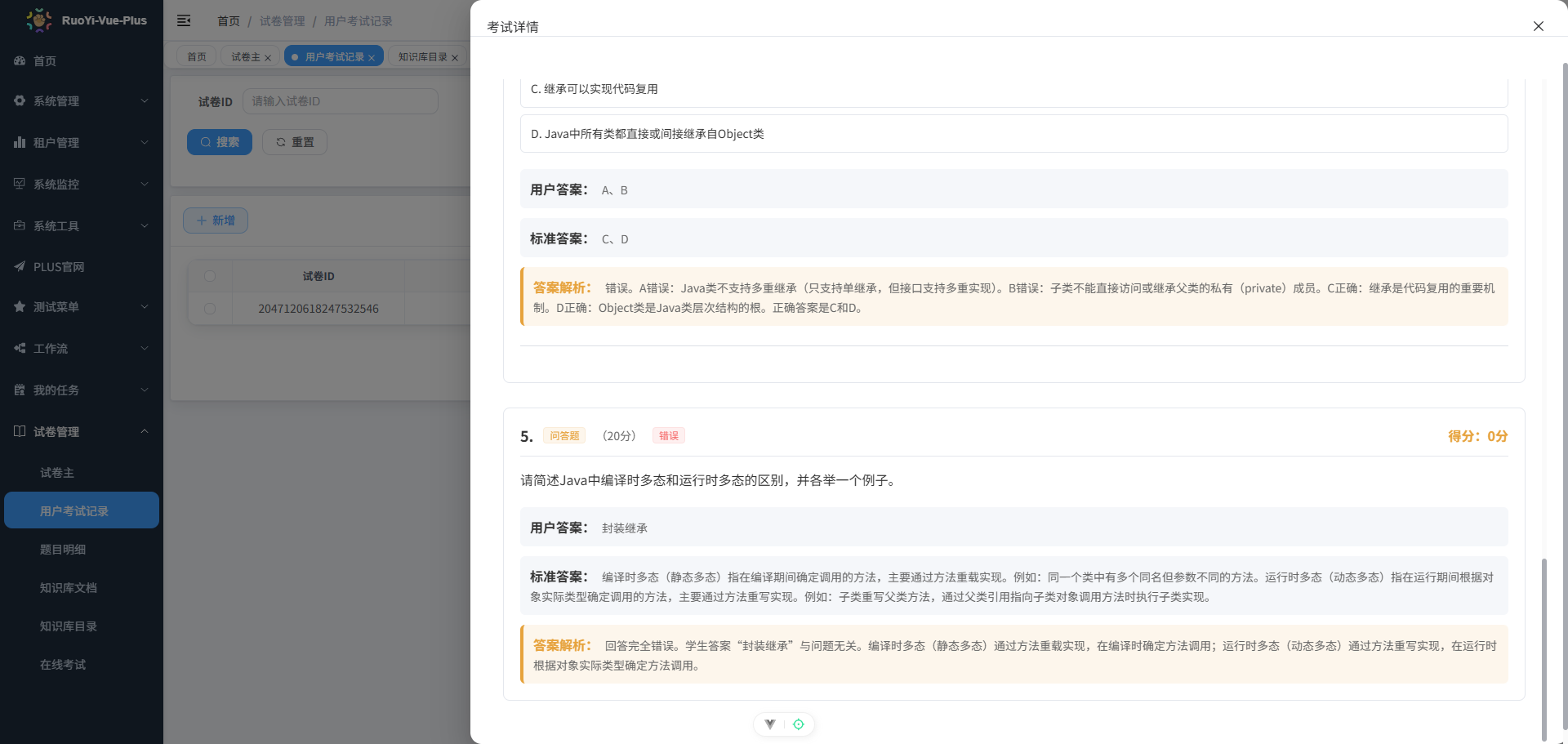
}6.2 阅卷结果示例
用户作答后,AI 批改并返回的 answers_snapshot 内容(已格式化为可读 JSON):
bash
[
{
"question_id": 2047120715656048642,
"type": "single",
"content": "Java中,下列哪个特性通过访问修饰符控制对数据和方法的访问权限?",
"options": ["A. 继承", "B. 封装", "C. 多态", "D. 抽象"],
"standard_answer": "B",
"user_answer": "A",
"score": 12,
"is_correct": "0",
"score_earned": 0,
"feedback": "错误。访问修饰符用于实现封装,正确答案是B。"
}
// ... 其他题目评分详情
]七、总结与扩展建议
本文详细介绍了如何在 RuoYi-Vue-Plus 框架中集成 DeepSeek 大模型,实现 AI 智能生成试卷与批量阅卷功能。核心要点回顾:
-
数据库设计 :使用 JSON 字段存储灵活配置,
answers_snapshot在阅卷前后切换格式,实现性能与可读性的平衡。 -
AI 调用:采用 HTTP 直连方式,兼容 OpenAI 规范,代码简洁且易于替换其他模型。
-
提示词工程:将提示词外置为文件,通过占位符动态替换,方便持续优化。
-
批量处理:阅卷采用一次请求处理全部题目,大幅降低延迟与成本。
希望本文能为您的 AI 应用开发提供清晰、可落地的参考。完整代码与数据库脚本已随文提供,欢迎实践与交流!