一、什么是 RAG(检索增强生成)
Retrieval Augmented Generation(RAG) 是一种用来弥补大模型缺陷的技术方案,主要解决:
- 长文本处理能力有限(上下文窗口限制)
- 容易"胡说八道"(幻觉问题)
- 缺乏私有知识 / 实时数据
其主要流程如下:
- 用户提问
- 去向量数据库检索相关内容
- 将"检索结果 + 用户问题"一起喂给大模型
- 大模型基于上下文生成答案
二、Spring AI 中的 RAG 支持
Spring AI 对 RAG 的支持有两个层次:
开箱即用的Advisor API
- 快速实现常见 RAG 流程
- 适合大多数业务场景
可扩展的模块化 RAG 架构
- 自定义完整 RAG Pipeline
- 适合复杂场景(重排序、多阶段检索等)
2.1QuestionAnswerAdvisor
QuestionAnswerAdvisor是最常用的API。其主要作用如下
- 从 VectorStore(向量数据库)中检索相关文档
- 自动拼接到用户问题中
- 形成增强后的 Prompt
入门案例
- 添加相关依赖
xml
<!-- 向量存储 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-vector-store</artifactId>
</dependency>
<!-- 向量Advisors -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>- 测试使用SimpleVectorStore,将向量数据放在内存当中
java
@Bean
public VectorStore vectorStore(EmbeddingModel openAiEmbeddingModel) {
return SimpleVectorStore.builder(openAiEmbeddingModel).build();
}- 为了方便测试,把一些测试数据放到SimpleVectorStore
java
@Component
public class DataInitializer {
private final VectorStore vectorStore;
public DataInitializer(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@PostConstruct
public void init() {
List<Document> documents = List.of(
new Document("Spring AI 是一个用于构建 AI 应用的框架,支持对接大模型、向量数据库和RAG流程。"),
new Document("RAG(检索增强生成)通过从向量数据库中检索相关文档来增强大模型回答的准确性。"),
new Document("VectorStore 是用于存储文本向量并支持相似度搜索的组件,比如 Redis、Milvus、PGVector。"),
new Document("SimpleVectorStore 是一个基于内存的向量存储实现,适用于测试和开发环境。"),
new Document("Embedding 是将文本转换为向量的过程,用于语义搜索和相似度计算。"),
new Document("topK 表示从向量数据库中返回最相似的前K条数据。"),
new Document("similarityThreshold 用于控制相似度过滤,值越高结果越严格。"),
new Document("Spring Boot 可以很方便地集成 Spring AI 来构建智能问答系统。")
);
vectorStore.add(documents);
}
}- 编写测试接口
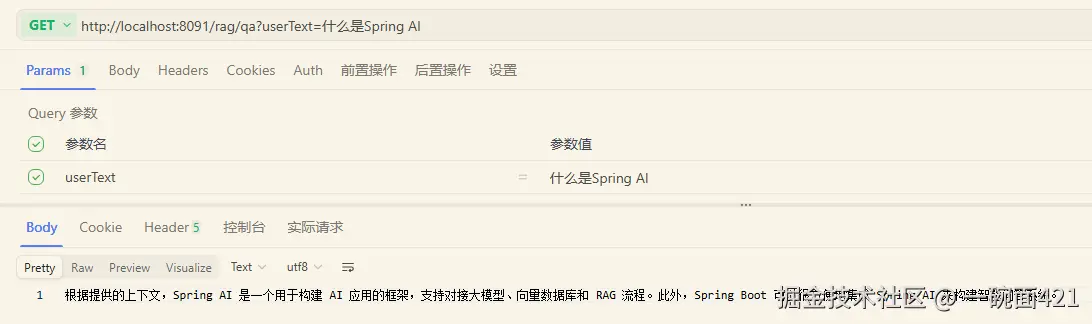
java
@GetMapping("/qa")
public String testRag(String userText) {
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.similarityThreshold(0.3d) // 相似度阈值 (根据实际情况调整,过高可能没有结果,过低可能引入噪声)
.topK(6) // 返回数量topK 不要太大(避免噪声)
.build())
.build();
return openAiChatClient.prompt()
.advisors(qaAdvisor)
.user(userText)
.call()
.content();
}- 测试
文档过滤功能
- 在添加文档的时候我们可以设置metadata。
yaml
List<Document> docs = List.of(
new Document(
"Spring AI 是一个AI框架",
Map.of("type", "Spring", "author", "zhangsan")
),
new Document(
"MySQL 是数据库",
Map.of("type", "Database", "author", "lisi")
),
new Document(
"Redis 是缓存系统",
Map.of("type", "Cache", "author", "zhangsan")
)
);
vectorStore.add(docs);- 在查询时添加过滤条件
java
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.build();
return openAiChatClient.prompt()
.advisors(a -> a.param(
// 检索过程变成:只在 metadata.type == "Spring" 的文档里做向量搜索
QuestionAnswerAdvisor.FILTER_EXPRESSION,
"type == 'Spring'"
))
.user(userText)
.call()
.content();自定义 Prompt 模板
SpringAI的默认RAG提示词模版可能不一定适合我们。这时就需要进行自定义了。默认 Prompt 不一定适合你,这时我们可以自定义:必须包含两个变量:
{query}→ 用户问题{question_answer_context}→ 检索内容
- 示例接口
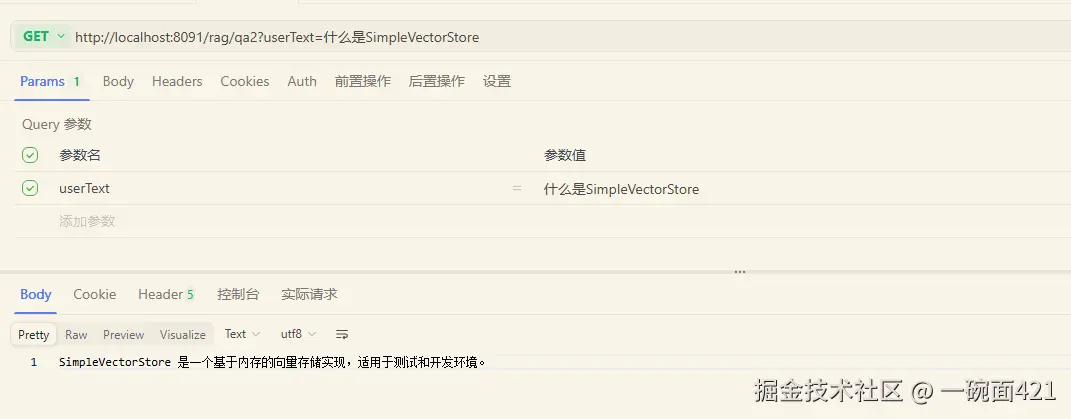
java
@GetMapping("/qa2")
public String testRag(String userText) {
PromptTemplate customPromptTemplate = PromptTemplate.builder()
.template("""
你是一个实用的AI助手.
用户问题:
{query}
上下文信息如下:
---------------------
{question_answer_context}
---------------------
Rules:
1. 如果上下文没有答案,回答:不知道
2. 不要说"根据上下文"
3. 不要编造
""")
.build();
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.promptTemplate(customPromptTemplate)
.searchRequest(SearchRequest.builder()
.similarityThreshold(0.6d)
.topK(5)
.build())
.build();
return openAiChatClient.prompt()
.advisors(qaAdvisor)
.user(userText)
.call()
.content();
}- 进行测试
2.2RetrievalAugmentationAdvisor(进阶版 RAG)
对于QuestionAnswerAdvisor而言,它存在以下几个问题:
- 只能做"检索 + 拼接上下文"
- 缺少可插拔能力
- 无法控制 query 改写 / 文档处理
- 不适合复杂业务(企业知识库)
于是乎就有了RetrievalAugmentationAdvisor。 它不仅仅是一个Advisor,而是一个可编排的 RAG Pipeline 框架 。
一个完整的RAG Pipeline通常是以下一个流程:
- 用户提问
- QueryTransformer进行重写问题
- 向量库中检索问题
- 用DocumentPostProcessor进行处理结果(去重,重排序,去噪,压缩等等)
- 把处理好的结果发给大模型
- 大模型进行回答
一个栗子
- 添加依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>- 编写RetrievalAugmentationAdvisor
java
@Bean
public Advisor myRetrievalAugmentationAdvisor(
VectorStore pineconeVectorStore,
ChatClient.Builder chatClientBuilder
) {
return RetrievalAugmentationAdvisor.builder()
//QueryTransformer(查询增强 / 重写)
//把用户问题"翻译成更适合检索的 query"
.queryTransformers(
RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build()
)
//DocumentRetriever(检索层)
.documentRetriever(
VectorStoreDocumentRetriever.builder()
.vectorStore(pineconeVectorStore)
.similarityThreshold(0.5)
.topK(3)
.build()
)
//DocumentPostProcessor(文档后置处理)
.documentPostProcessors(new DocumentPostProcessor[]{
new MyDocumentPostProcessor()
})
//ContextualQueryAugmenter(上下文控制)
.queryAugmenter(
ContextualQueryAugmenter.builder()
.allowEmptyContext(true) // 如果检索结果为空,是否允许 LLM 自主回答
.build()
)
.build();
}- 自定义文档处理器
java
public class MyDocumentPostProcessor implements DocumentPostProcessor {
@Override
public List<Document> process(Query query, List<Document> documents) {
System.out.println("MyDocumentPostProcessor#process called执行了: ");
System.out.println("query: " + query.text());
System.out.println("documents: " + documents.toString());
return documents.stream()
.distinct()
.map(doc -> {
String content = doc.getText();
// 防止上下文过长
if (content.length() > 200) {
content = content.substring(0, 200);
}
return new Document(content, doc.getMetadata());
})
.toList();
}
}- 接口测试
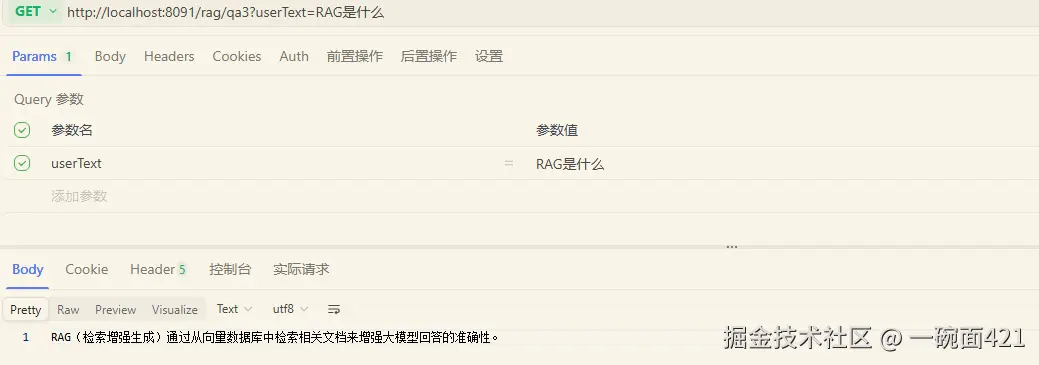
java
@GetMapping("/qa3")
public String testRag3(String userText) {
return openAiChatClient.prompt()
.advisors(myRetrievalAugmentationAdvisor)
.user(userText)
.call()
.content();
}- 控制台输出

- 测试结果
三、RAG模块化介绍
Spring AI 把 RAG整个过程拆分成 4 层:
3.1Pre-Retrieval(检索前优化)
Query Transformation(查询转换)
其主要目标是 让"用户问题"变得更适合检索 。所以要进行 Query Transformation(查询转换/增强)。在SpringAI中目前有三个QueryTransformer
CompressionQueryTransformer(上下文压缩)
CompressionQueryTransformer 的作用是"补全对话中的隐含信息",把多轮对话问题转换成独立可检索的标准问题。 其主要作用是 把"对话历史 + 当前问题" → 压缩成一个独立问题
下方是一个示例:
java
/**
UserMessage("什么是 RAG?"),
AssistantMessage("RAG 是检索增强生成,通过向量数据库检索相关文档来增强大模型回答。")
UserMessage("它的核心原理是什么?")
压缩后: RAG 的核心原理是什么?
*/
.queryTransformers(
CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build(),
RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build()
)RewriteQueryTransformer(查询重写)
我们在上面已经使用过了,其主要作用是让用户的问题更加标准,更加适合检索。解决用户表达模糊,搜索命中率低。
TranslationQueryTransformer(查询翻译)
其主要解决的是用户语言到文档语言的翻译。比如我现在向量数据库存的是中文,用户使用英文来进行提问
用户:What is RAG
系统需要翻译成中文再去检索:RAG 是什么
java
.queryTransformers(
TranslationQueryTransformer.builder()
.targetLanguage("Chinese")
.chatClientBuilder(chatClientBuilder.build().mutate())
.build(),
RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build()
)Query Expansion(查询扩展)
比如用户问了一句: Spring AI 怎么做 RAG?
这个问题其实有点"模糊":
- 可能问架构
- 可能问组件
- 可能问实现方式
这时,我们可以利用 MultiQueryExpander 进行查询扩展
java
MultiQueryExpander expander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = expander.expand(
new Query("Spring AI 怎么做 RAG?")
);这样就把原始问题变成多个问题,提高了召回率。
- Spring AI 如何实现 RAG 流程?
- Spring AI RAG 需要哪些组件?
- 如何用 Spring Boot 构建 RAG 问答系统?
- Spring AI 怎么做 RAG?(原始)
3.2Retrieval(检索阶段)
检索阶段就是要从数据源中找到最相关内容
java
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(() -> new FilterExpressionBuilder()
.eq("tenant", TenantContextHolder.getTenantIdentifier())
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("什么是Spring AI"));Document Join(多路合并)
主要应用于多query,多数据源 的场景,可以做到多个文档拼接 ,自动去重,保留原 score。
结合之前扩展查询的示例代码如下:
自定义一个DocumentRetriever
java
public class MultiQueryDocumentRetriever implements DocumentRetriever {
private final MultiQueryExpander expander;
private final DocumentRetriever delegate;
private final DocumentJoiner joiner;
public MultiQueryDocumentRetriever(MultiQueryExpander expander,
DocumentRetriever delegate) {
this.expander = expander;
this.delegate = delegate;
this.joiner = new ConcatenationDocumentJoiner();
}
@Override
public List<Document> retrieve(Query query) {
List<Query> queries = expander.expand(query);
Map<Query, List<List<Document>>> documentsForQuery = new HashMap<>();
for (Query q : queries) {
List<List<Document>> docsFromSources = new ArrayList<>();
// 这里只用一个数据源(vector)
docsFromSources.add(delegate.retrieve(q));
documentsForQuery.put(q, docsFromSources);
}
return joiner.join(documentsForQuery);
}
}结合RetrievalAugmentationAdvisor使用
java
DocumentRetriever retriever = new MultiQueryDocumentRetriever(
MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build(),
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.5)
.topK(3)
.build()
);
RetrievalAugmentationAdvisor advisor =
RetrievalAugmentationAdvisor.builder()
.documentRetriever(retriever)
.build();3.3Post-Retrieval(检索后)
这一步的主要目标要做到让"检索结果"更适合给 LLM 用。比如重排序,去重,压缩,去噪等等。之前的MyDocumentPostProcessor就是一个例子
3.4Generation(生成)
核心就是把"检索结果"拼到 query 里,可以通过ContextualQueryAugmenter进行一些定制
java
.queryAugmenter(
ContextualQueryAugmenter.builder()
.promptTemplate() //配置prompt
.emptyContextPromptTemplate()
.allowEmptyContext(true) // 如果检索结果为空,是否允许 LLM 自主回答
.build()
)总结一下流程
- 用户发起问题
- Query Transformation(查询转换)
- Query Expansion(查询扩展)
- Document Retrieval(文档检索)
- Document Join(文档合并)
- Post Processing(文档后置处理)
- Query Augmentation(结合文档结果进行查询增强)
- LLM生成最终答案
四、ETL Pipeline(RAG 的数据来源)
在前面我们讲的都是:如何用数据(检索 + 生成),而 ETL 解决的是:数据"从哪来 + 怎么变成可用"。
官方的定义是:ETL 是 RAG 数据处理的"骨架",负责把原始数据变成结构化向量数据 。
以下是一个ETL流程:
- 原始数据来源:PDF / txt / HTML / JSON / Docx
- Extract:读取数据
- Transform: 清洗 + 切分 + 结构化
- Load: 写入向量数据库
核心对象:Document
ETL 的核心数据结构是一个Document对象,一切数据都统一抽象成 Document,后面的embedding ,检索 RAG全部基于它。
ETL 三大核心组件
4.1.DocumentReader(Extract)
作用:从各种数据源读取数据
常见实现
TextReader(读取文本文件)
plain
@Component
public class MyTextReader {
private final Resource resource;
MyTextReader(@Value("classpath:text-source.txt") Resource resource) {
this.resource = resource;
}
public List<Document> loadText() {
TextReader textReader = new TextReader(this.resource);
textReader.getCustomMetadata().put("filename", "text-source.txt");
return textReader.read();
}
}特点:
- 整个文件加载为一个 Document
- 自动附带 metadata
- 整个文件都会加载到内存
JsonReader
plain
@Component
public class MyJsonReader {
private final Resource resource;
MyJsonReader(@Value("classpath:json-source.json") Resource resource) {
this.resource = resource;
}
public List<Document> loadJsonAsDocuments() {
JsonReader jsonReader = new JsonReader(this.resource);
return jsonReader.get();
}
}特点:
- JSON → Document
- 支持字段选择
HTML / Markdown Reader
- JsoupDocumentReader
- MarkdownDocumentReader
这两个主要用于网页抓取 / 知识库
html解析需要用到jsonp,需要引入额外的库
plain
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-jsoup-document-reader</artifactId>
</dependency>MarkdownDocumentReader也需要引入额外的库
plain
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>PDF Page/PDF Paragraph
这两者区别一个是按页切分一个按段落切分文档。需要注意的是PDF Paragraph会使用 PDF 目录 (例如 TOC) 信息将输入的 PDF 分成文本段落,并为每个段落输出一个 Document,但有的PDF可能没有PDF目录。
plain
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>4.2.DocumentTransformer(Transform)
转换阶段主要对数据做"处理和优化"
TokenTextSplitter
核心目标只有一个:让切分后的 chunk 既"语义完整",又"适合 embedding 和检索"。
以下是一段示例代码以及参数介绍:
plain
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(800)
.withMinChunkSizeChars(400)
.withMinChunkLengthToEmbed(20)
.withMaxNumChunks(5000)
.withKeepSeparator(true)
.withPunctuationMarks(List.of("。", "!", "?", ".", "?", "!", "\n"))
.build();- chunkSize(最重要)
| 场景 | 推荐 |
|---|---|
| 通用文档 | 500 ~ 800 |
| 技术文档 / API | 800 ~ 1200 |
| 长文本(书籍) | 1000 左右 |
| QA精确检索 | 300 ~ 500 |
- minChunkSizeChars ( 防止 chunk 太碎 )
- 中文:300 ~ 500
- 英文:200 ~ 400
- **minChunkLengthToEmbed **(小于这个长度的 chunk 直接丢弃)
- maxNumChunks(限制最大 chunk 数量 )
- keepSeparator ( 是否保留换行/标点 )
建议保留,可以保持语义结构(段落、句子,提升 embedding 质量
- punctuationMarks(控制句子切分的边界)
不同文档用不同策略
| 类型 | 策略 |
|---|---|
| API文档 | 按方法切 |
| 按段落 + token | |
| FAQ | 一问一chunk |
| 表格 | 一行一chunk |
ContentFormatTransformer
现实中的数据往往是:
plain
1. HTML标签:<div>xxx</div>
2. 多余换行:\n\n\n\n
3. OCR乱码:空格乱飞
4. Markdown符号:### ** **
5. PDF断行:一句话被切成多行ContentFormatTransformer主要用来做内容清洗,保持格式统一 ,提示 embedding 质量。
一下是一段伪代码
plain
List<Document> docs = ...
// 1. 切分
TokenTextSplitter splitter = TokenTextSplitter.builder().build();
List<Document> chunks = splitter.apply(docs);
// 2. 统一格式
ContentFormatTransformer formatter = new ContentFormatTransformer(new SimpleContentFormatter());
chunks = formatter.apply(chunks);4.3.DocumentWriter(Load)
把处理好的数据写入存储
VectorStore
把文档保存到向量数据库中,目前springai支持的向量数据库已经有很多了。使用对应的向量库需要引入对应的依赖,可以前往官网查询 :docs.spring.io/spring-ai/r...
这里我选择的是Pinecone(一个开箱即用的云向量数据库),需要去官网(app.pinecone.io/)注册一个账号
- 登录成功之后创建index

- 再创建一个api

- 添加依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pinecone</artifactId>
</dependency>- 修改配置
java
spring:
ai:
vectorstore:
pinecone:
api-key: 你的apikey
index-name: 你的index读取md文档保存到向量库:
主体过程如下:Markdown → Document → 切 chunk → embedding → 存向量库(Pinecone)
- 新增一个接口测试
java
@GetMapping("/ingestMarkdownToPinecone")
public void ingestMarkdownToPinecone() {
// 1. 读取
List<Document> documents = myMarkdownReader.loadMarkdown();
// 2. 切分
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(800)
.withMinChunkSizeChars(300)
.withMinChunkLengthToEmbed(20)
.build();
List<Document> chunks = splitter.apply(documents);
// 3. 清洗
ContentFormatTransformer formatter = new ContentFormatTransformer(new SimpleContentFormatter());
chunks = formatter.apply(chunks);
// 4. 入库
pineconeVectorStore.add(chunks);
}- 查看Pinecone已经保存成功
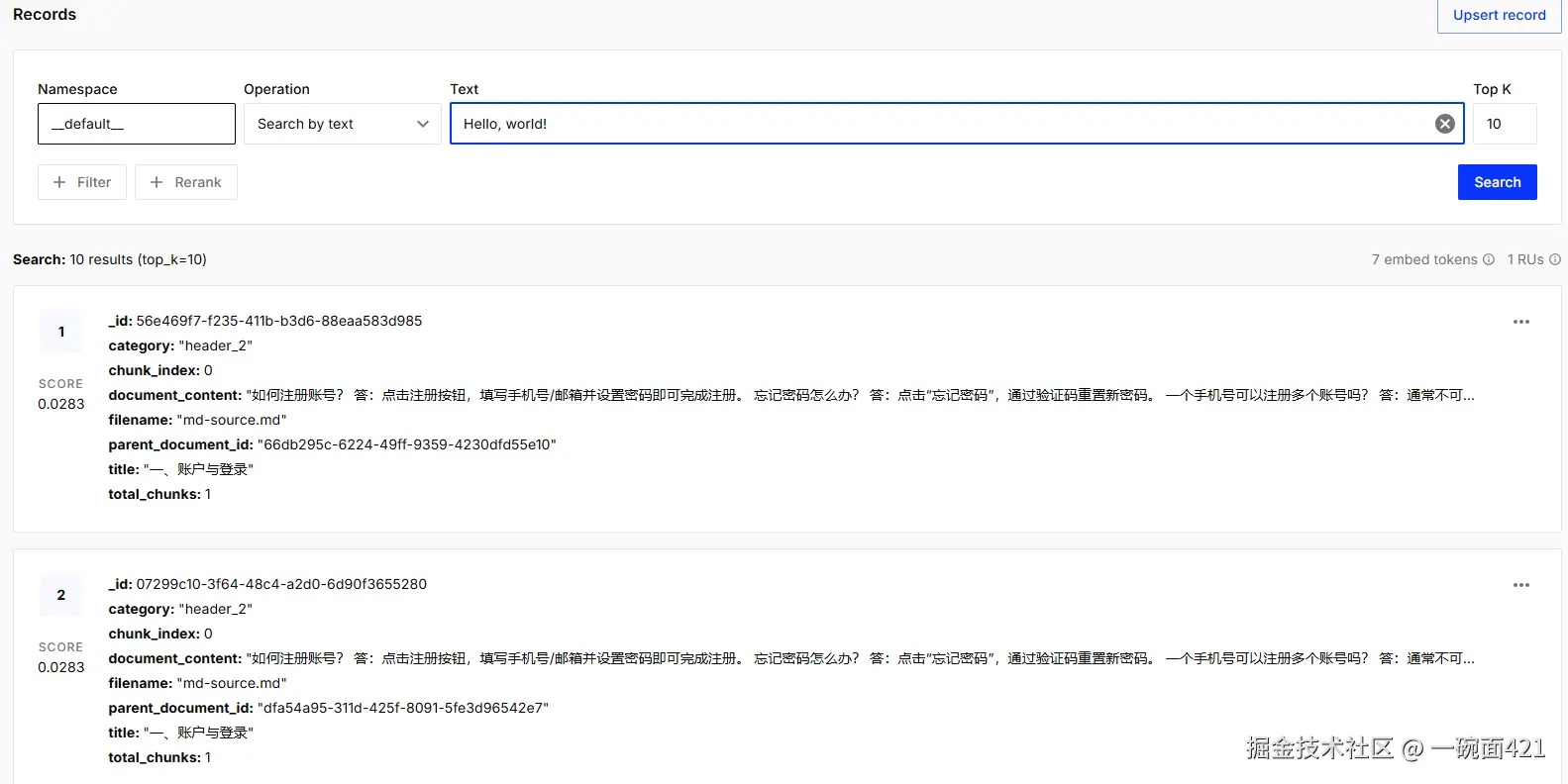
- 我们把之前配置的myRetrievalAugmentationAdvisor换成pineconeVectorStore
java
@Bean
public Advisor myRetrievalAugmentationAdvisor(
VectorStore pineconeVectorStore,
ChatClient.Builder chatClientBuilder
)- 新增问答接口
java
@GetMapping("/qa4")
public String testRag4(String userText) {
return openAiChatClient.prompt()
.advisors(myRetrievalAugmentationAdvisor)
.user(userText)
.call()
.content();
}- 进行测试
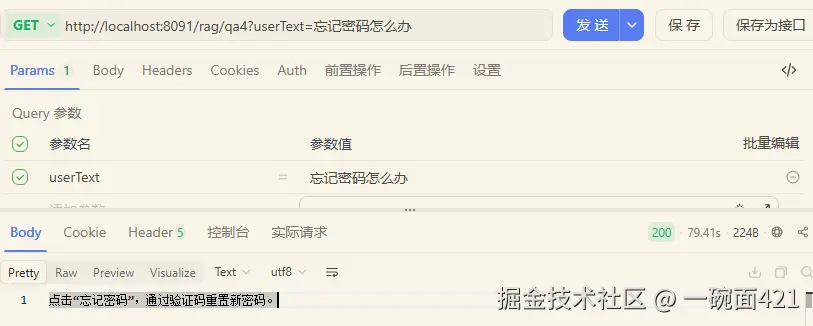
总结
写到这里,其实你可以把 RAG 理解成:让大模型在回答问题前,先"翻一翻资料"。资料准备得越好、找得越准、整理得越干净,最后给出的答案也就越靠谱。
博客相关代码已经更新到:github.com/byone421/sp...。感谢您的阅读。