大语言模型微调是在模型训练,特定方面应用的一项关键的技术,我将从零开始讲解如何配置环境并在固有通用大模型的基础上,微调出一个符合自己要求的模型。本文覆盖了linux,pytorch,conda等一系列的相关知识。将以qween2.5-7B的模型为例进行操作。
前言
首先来说说什么是大语言模型的微调。那么第一个问题:大语言模型为什么叫大语言模型?我们分开来理解,大是指参数量大,训练数据规模庞大。语言是指它的核心任务是处理自然语言。它能理解、生成、翻译、总结、回答问题等。然后是模型:指它是一个数学和计算模型,通常基于深度学习中的Transformer架构。它通过大量文本训练,学习语言的模式和结构,最终形成一个能够预测和生成文本的概率系统。那么再来说说微调,微调就是喂给通用大模型一个数据集,然后通用大模型通过这个数据集进行训练从而提升自己在某个方面的能力。
Linux基础操作
文件与目录操作方面,cd命令用于切换工作目录,ls命令用于列出文件详细信息,pwd命令用于显示当前路径,mkdir命令用于递归创建目录,cp命令用于递归复制文件,mv命令用于移动或重命名文件,rm命令用于递归强制删除文件,vim命令创建并打开一个文件夹。
进程与资源管理方面,nvidia-smi命令用于查看GPU状态,我们从而可以了解到GPU的工作情况,如显存的大小以及使用情况,GPU的使用率。我们可以通过GPU的使用率知道如下的信息:
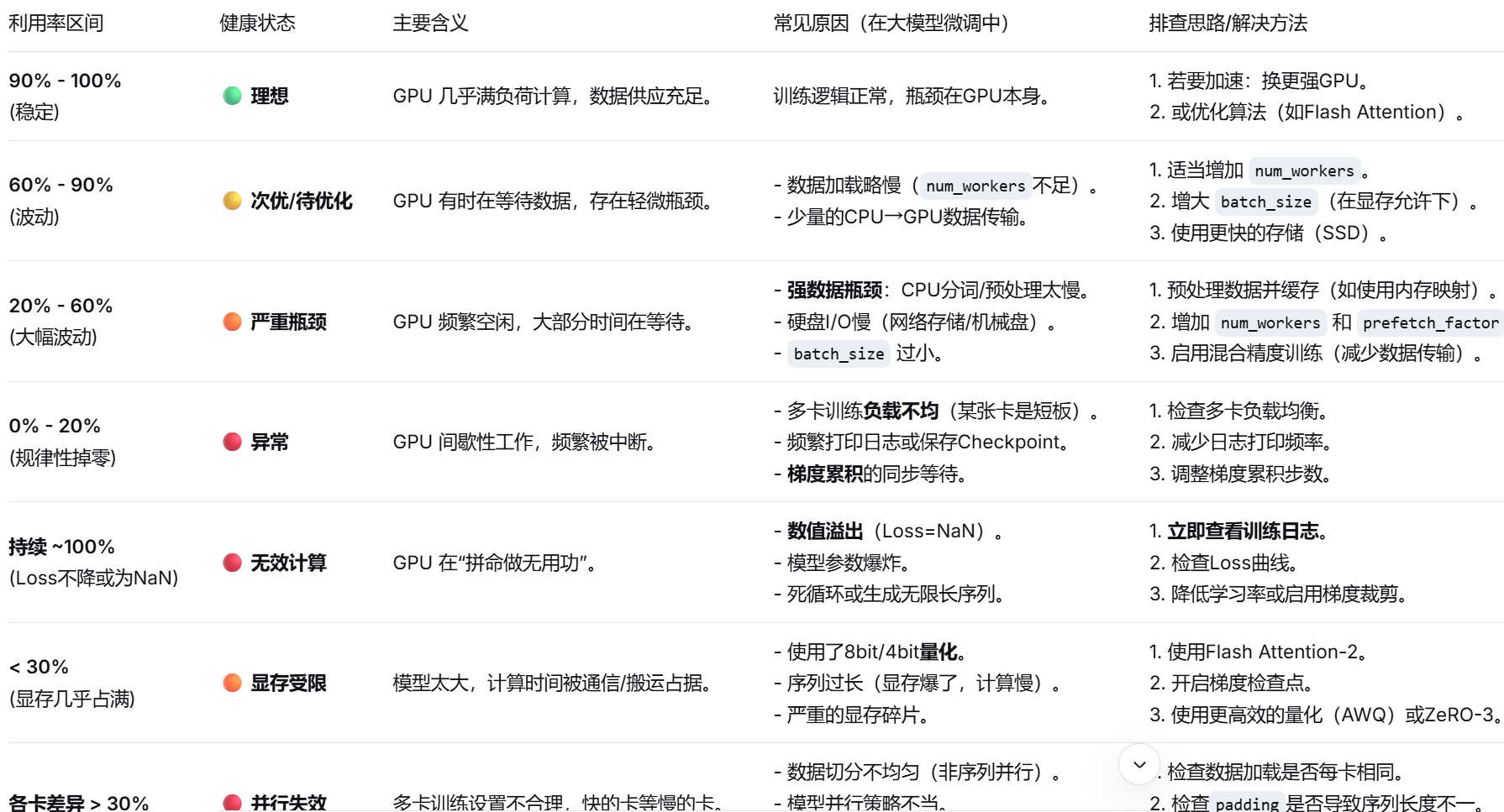
我们还可以通过这个命令知道是那个进程正在使用GPU,从而保证现在正在使用的GPU的是你自己的进程而不是别的进程。
我们还可以通过watch命令来监控GPU ,执行watch命令后相当于每隔一段时间就执行一次nvidia-smi命令,我们可以实时的看到GPU的状态,从而判断出是否出现了瓶颈,异常或者崩溃。
通过ps查看python进程,在我们运行python项目的时候,如果出现问题,我们可以通过ps命令来确定到底是哪一个python的进程出现了错误,从而更加精准的去解决问题。
nohup命令用于将训练任务放在后台运行,这样我们就可以在跑模型的时候退出终端去干一些别的事情。
使用conda对模型进行管理
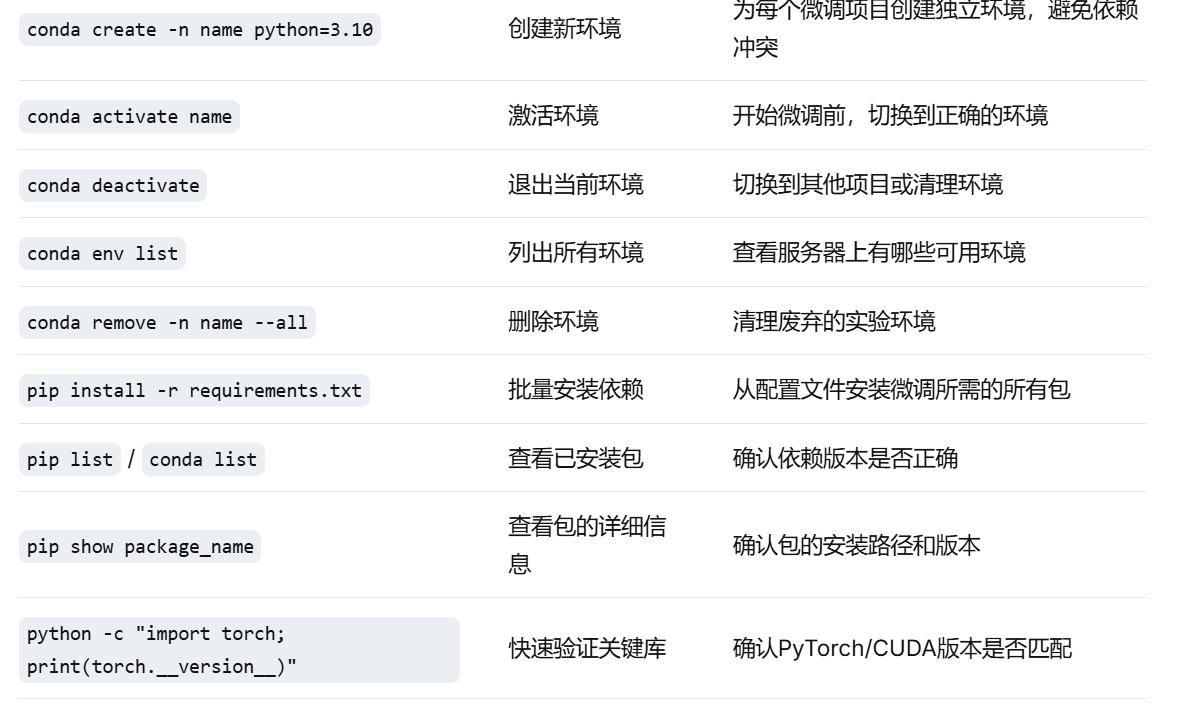
pytorch与CUDE的配置
我们需要配置与cude相适配的pytorch,我们可以通过nvidia-smi命令来查看cude的版本从而安装适配的pytorch

在跑模型的过程中,如果觉得速度过慢可能是使用里国外源的原因,我们可以通过换到清华源等国内的源来进行解决。
模型加载与量化技术
由于是第一次做微调,所以我们可以先进行一下量化的操作,从而减少对显存的占用,更快的得到调整好的模型。这里我们使用到了4-bit量化技术
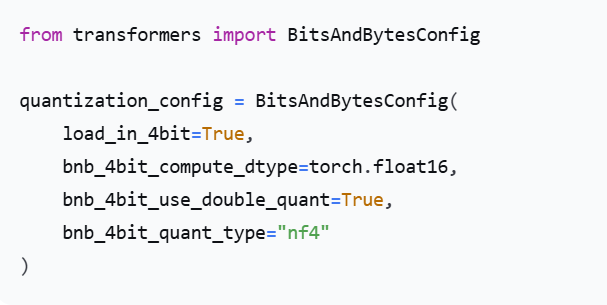
参数高效微调技术
这里我们介绍一下QLoRA和LoRA(这里明天补上,学不动了)
数据集构建
在微调的过程中比较关键的一步就是数据集的构建,数据集相当于学习资料,模型通过数据集的提供的问答对,来学习我们想让他学习的知识从而让模型在我们想让它变得更加专业的领域更加专业。
下面是对不同格式的数据集的汇总

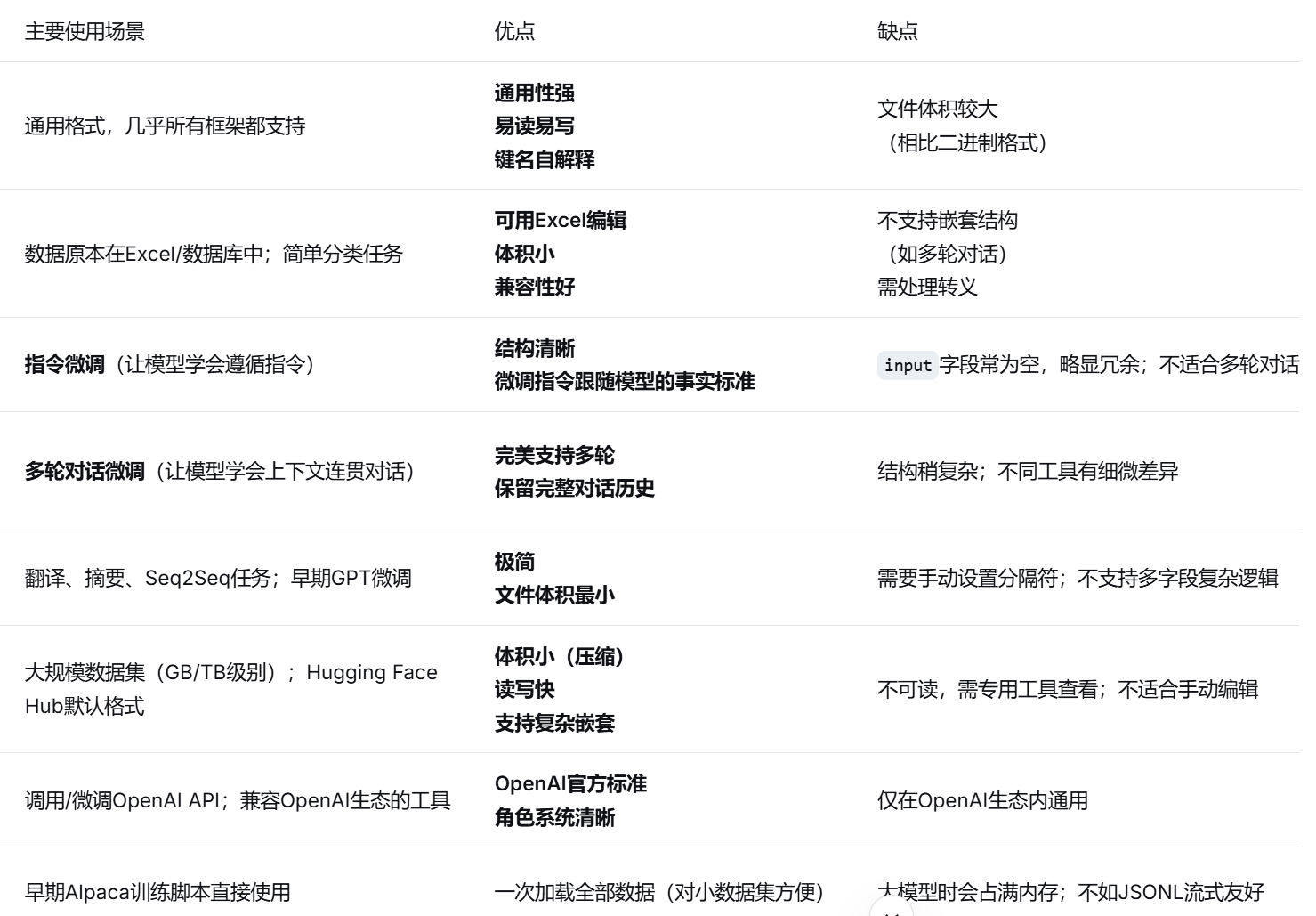
除了数据集,我们还可以跟模型设置系统提示词。
系统提示词的核心作用是为模型设定全局行为准则:它定义了模型的角色身份(如专业医生、客服)、回应规则(如禁止编造信息)、输出格式(如JSON)和对话边界(如拒绝违规内容)。通过这一顶层指令,开发者无需修改模型参数,即可控制对话的风格、安全性和任务适配性,同时减轻用户重复说明的负担,确保模型在多轮交互中保持行为一致性。
在这次操作中,我们加入了一个关于身份的系统提示词。
模型评估
首次评估使用的是人工测评,我们使用了测评的脚本对模型在各个方面的能力进行了测绘。然后在尝试使用EvalScope进行测评,后续会进行补充。
评估的作用是什么呢,首先我们来了解一下灾难性遗忘:灾难性遗忘是指神经网络在学习新任务时,会"剧烈地"覆盖掉此前学到的参数,从而导致在旧任务上的表现断崖式下跌。这一现象在大语言模型微调中尤为关键------当你用特定领域数据微调模型后,模型虽然在新任务上表现优异,但很可能已经忘记了原本掌握的通用知识(如常识推理、代码生成或安全规范)。因此,对微调后的模型进行全面测试,其核心意义在于**验证模型的"知识权衡"是否成功**:通过对比微调前后在通用基准(如MMLU、C-Eval)和专用任务上的表现,确保模型既获得了新技能,又没有以"灾难性遗忘"为代价牺牲原有能力。缺乏这种测试,你的微调模型可能会成为一个"偏科专家"------在特定问题上很聪明,但在更广泛场景中却变得不可靠甚至更笨。
微调的结果
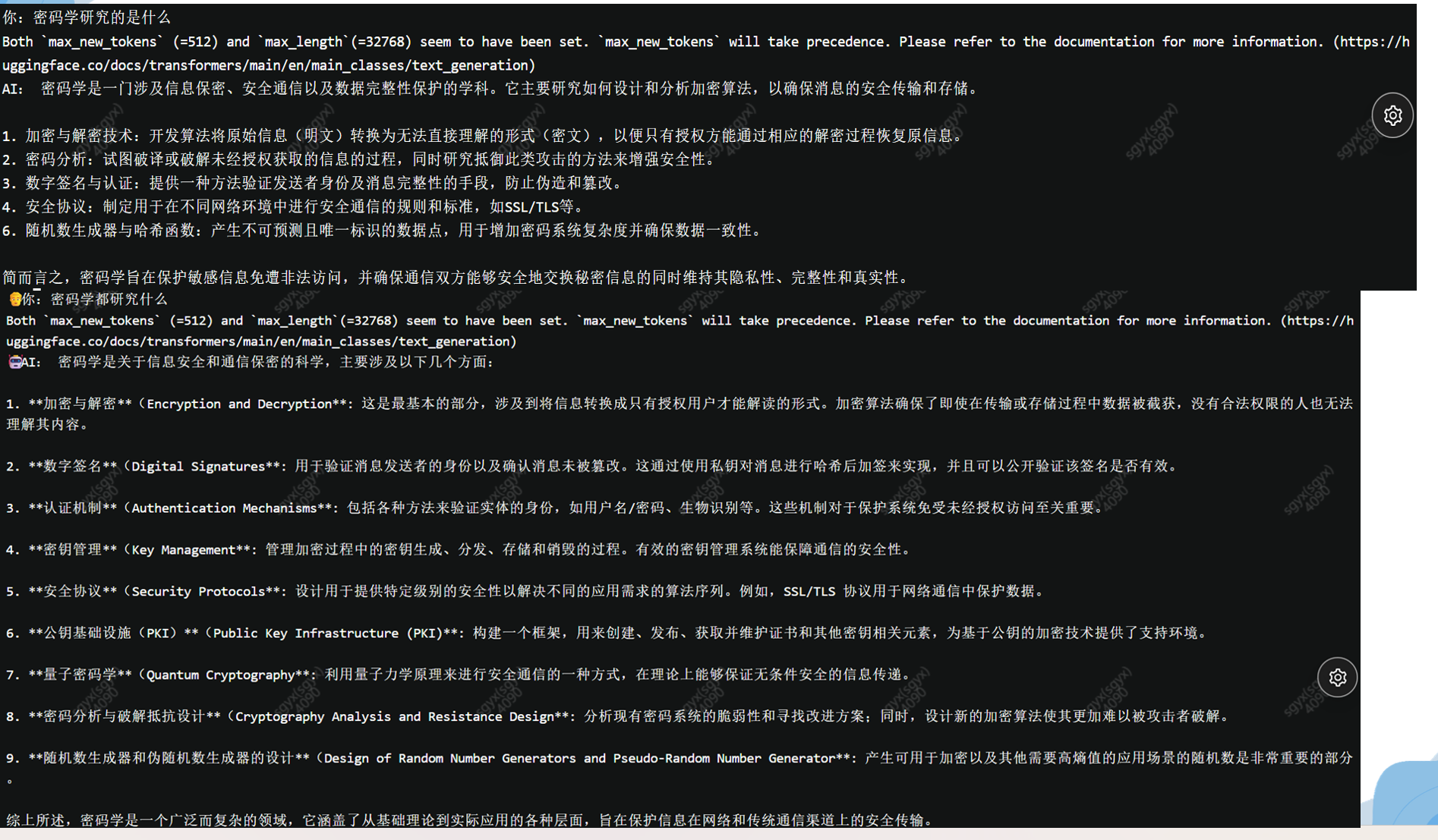
上面的部分是微调之前的问答情况,下面的是微调之后的问答情况,我们看到模型的回答在专业性和条理方面得到了提升。
(微调过程中,使用到了模型下载,模型训练,模型测试等一系列脚本后再后续进行单独的讲解)