前言
这篇论文打破的一个常识误区:单纯给模型喂触觉传感器数据(Touch as input alone)并不能带来稳定的性能提升
HTD 成功的本质在于它强迫 Transformer 主干网络去"预测/想象"未来的受力与触觉潜在状态(Touch Dreaming),这种自监督的辅助目标才真正让模型学到了具备物理接触感知的世界表示
第一部分 Learning Versatile Humanoid Manipulation with Touch Dreaming
1.1 引言与相关工作
1.1.1 引言
如原论文所述,现实世界中的仿人机器人"行走---操作"(loco-manipulation)仍然具有根本性的挑战
- 因为这类任务需要在全身稳定性、末端执行器的完全灵巧性以及具备触觉意识的感知之间实现高度协调
- 特别是在高接触密度任务中,微小的姿态或力控制误差都可能迅速累积,导致打滑、卡死或失去平衡。对于人形机器人而言,这些挑战尤为突出,因为手部灵巧交互与躯干姿态、运动模式以及足---地支撑紧密耦合在一起 7,8
因此,仅仅实现精确的手部运动远远不够;成功的人形机器人操作还需要具备鲁棒的全身执行能力以及对接触状态的及时理解
-
第一个瓶颈是系统能力
富接触的人形机器人操作需要一条实用的真实世界管线,能够同时支持稳定的全身执行、完整的灵巧手控制以及触觉感知尽管近期的人形系统在运动跟踪、遥操作和示教收集方面已有改进 9--11,但表 I 突出说明,很少有系统在单一平台上同时集成全身控制、完整末端执行器(手部)灵巧性以及触觉传感/建模,用于实现灵巧的、富接触的操作
为了解决这一问题,作者构建了一个集成式全身人形操控系统,将基于强化学习(RL)的全身控制器(WBC)、VR 遥操作、上半身逆运动学(IK)、灵巧手重定向以及分布式触觉感知 结合在一起
该设计为采集高质量的真实世界示教提供了一个稳定的平台,同时使操作员能够将注意力集中在任务意图和灵巧交互上 -
第二个瓶颈是表征学习
仅依赖动作监督,从视觉和本体感受信号进行的行为克隆,在接触丰富(contact-rich)的操作任务中往往表现不佳,因为接触信息只能被部分观测到,而且可能会突然变化12因此,触觉感知是一种天然的互补模态,已有工作在视觉-触觉操作和预测式触觉学习中证明了其价值 13--16
然而,大多数现有的触觉学习方法都是为臂-手操作设计的,并且往往依赖于单独的触觉预训练、显式的世界模型模块、多阶段推理,或绑定到特定触觉布局的人工设计虚拟目标 15--19更广泛地说,像 I-JEPA 20 和 V-JEPA2 21 这类联合嵌入预测架构(Joint-Embedding PredictiveArchitectures)中的预测潜变量学习表明,在潜在空间中进行未来预测,可以在无需重建原始观测或训练一个单独的生成式管线
然而,这些思想很少被引入到一个单阶段的全身人形体模仿策略中,而这样的策略必须同时处理灵巧操作、与运动相关的动作生成以及快速变化的接触
受这一研究空白的启发,来自的研究者提出了具身触觉梦境的人形 Transformer(HumanoidTransformer with Touch Dreaming,HTD)

- 其paper地址为:Learning Versatile Humanoid Manipulation with Touch Dreaming
- 其项目地址为:humanoid-touch-dream.github.io
其github为:github.com/chrisyrniu/humanoid-touch-dream
作者宣称,The code for whole-body controller, teleoperation, and HTD policy learning will be released by early May 2026(即26年5月初发布*). Thanks for your patience!*
具体而言,这是一种多模态编码--解码式 Transformer,用于灵巧的人形体移动与操作一体化控制(loco-manipulation)。HTD 将触觉与多视角视觉和本体感受一起建模为核心模态,并采用单阶段训练:利用行为克隆,并辅以触觉梦境增强
- 除了预测动作片段外,HTD 还预测未来的手部关节受力以及未来的触觉潜变量
触觉监督目标由指数滑动平均(Exponential Moving Average,EMA)目标编码器生成,在不需要单独的触觉预训练阶段的前提下,提供稳定的潜在表示监督 - 与其将未来触觉预测作为独立的世界模型或推理阶段模块,HTD 将其用作一个辅助目标,用于正则化共享的Transformer 主干,使其学习感知接触的潜在动力学,同时保持部署过程的简洁
// 待更
1.1.2 相关工作
首先,对于人形机器人整体身体控制与远程操作操控
-
近年来,人形机器人操作领域的进展主要得益于全身控制、运动追踪以及遥操作基础设施方面的突破。在人形机器人全身控制中,一个核心问题是:如何在多样化的动作行为(包括行走、行走-操作一体化以及上肢操作)中,统一表示并执行任务指令
-
以往工作通常根据具体任务与操作者接口的不同,采用不同的控制接口,例如根部(躯干)追踪、关节空间追踪、基于身体关键点或姿态的追踪等 1, 5, 26, 27
有一条研究路线是通过分解提升鲁棒性,将下肢稳定、上肢追踪、力适应或顺应性调节等功能解耦开来,例如
双智能体力自适应控制 28
跨多种控制模式的异构元控制 29
自适应顺应控制 30
以及面向灵巧全身行为的优化与学习混合框架 7,22相关系统还将学习到的全身控制与专用的遥操作硬件或追踪模块相结合,以实现更精细的行走-操作一体化控制 8, 31
-
另一条研究路线则致力于设计统一控制器,在单一的全身追踪框架内直接协调行走与操作 32, 33
与之互补的遥操作与运动追踪系统,进一步提升了通过基于 RGB 或基于姿态的"影子跟随"、沉浸式 VR 接口、便携式无光学标记设置以及闭环长时域追踪等方式来指挥人形机器人的实用性与可扩展性1, 5, 6, 9--11, 24, 26, 27, 34
在上述研究基础上,作者的系统将基于 RL 的全身控制器与基于 VR 的遥操作栈相结合,采用统一参考系、上肢逆运动学(IK)以及手部重定向,从而高效采集人形机器人全身操作演示,用于下游策略学习
其次,对于人形机器人操作的模仿学习
-
基于这些进展,近期工作使得通过示范来学习人形机器人操作变得越来越可行。诸如 HumanPlus5 和 OmniH2O 1 等系统,将真实环境中的全身遥操作与行为克隆相结合;而更新的方法则通过便携式数据采集、更强的策略参数化方式以及基于人工数据的监督来提升可扩展性和泛化能力
-
包括TWIST2 9、Choice Policies 35、3D diffusionpolicies 36、无机器人示教接口 24、单视频模仿37、人-类人形机器人协同训练 38,以及面向灵巧人形机器人操作的"预训练-再微调"流程 25
整体而言,这些工作大幅降低了学习超越小规模、仅限机器人行为克隆的全身 humanoid 技能的门槛
表 I 突出了一个尚未弥合的空白
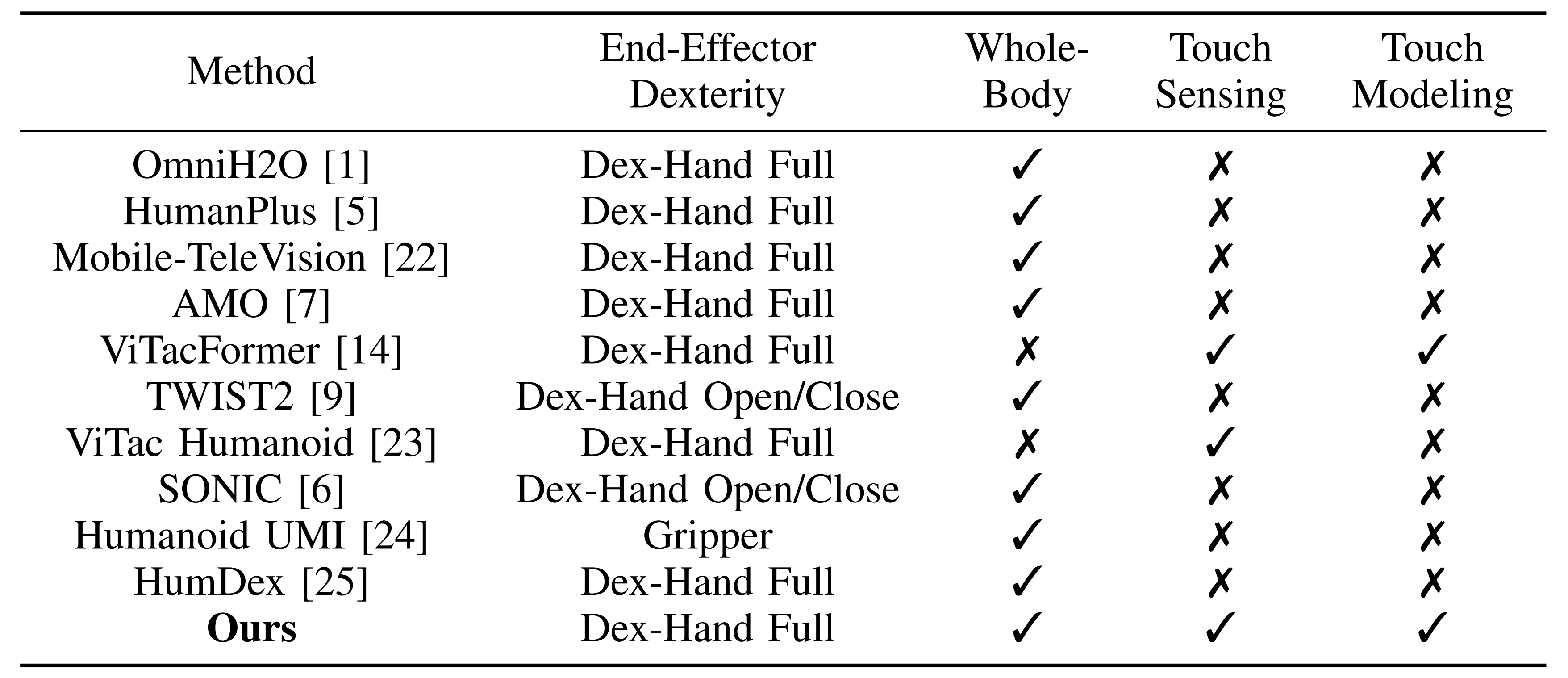
-
此前的人形系统,如 OmniH2O 1、HumanPlus 5、Mobile-TeleVision 22、AMO 7、TWIST2 9、SONIC6 和 HumDex 25,在端执行器灵巧程度各不相同的前提下,都支持全身人形操作;而 HumanoidUMI 24 则专注于从无机器人数据中学习基于夹爪的全身操作
-
然而,这些方法大多没有引入触觉传感,更少有在学习到的策略中显式建模触觉信号。与之相对,以触觉为中心的工作,如 ViTacFormer14 和 Kwon 等人 23 提出的人形视觉-触觉-动作数据集,展示了触觉信息的价值,但并未提供一种能够同时结合全身控制、完整端执行器灵巧性、触觉传感和触觉建模的人形操作系统
作者的方法正是针对这一缺失的交叉点:通过未来触觉预测,以单阶段方式学习具备完整端执行器灵巧性、触觉传感以及隐式触觉建模的、具备触觉感知能力的人形操作策略
最后,对于利用触觉传感进行高接触操作的表征学习
触觉传感正日益成为研究的重点,因为它与其将其仅视为任务特定的感知模块,不如把它看作是一个表征学习问题
- 早期的视觉-触觉操作研究表明,在部分可观测条件下,触觉可以补充视觉,用于判定接触状态 12, 13。更近期的工作则学习可在不同传感器、任务和具身形式之间迁移的触觉表征,从而提升下游操作中的数据效率和复用能力 17,39
- 与此同时,一条不断发展的视觉-触觉动作建模研究路线,将触觉或力信息直接纳入用于富接触操作的策略之中,其中包括基于扩散(diffusion)、基于 Transformer,以及 VLA 风格的方法 14, 16,18, 19, 40--49
这些工作一致表明,触觉在力、滑移、顺应性以及接触转换等方面提供了至关重要的信息,而这些信息仅凭视觉很难推断出来
-
一个密切相关的研究方向是利用预测式触觉学习来改进具备接触感知能力的表征。已有工作在自监督多模态预测框架下研究了用于高接触频率任务的学习方法12,而更近期的方法则显式预测未来的触觉观测、触觉潜变量或相关的接触物理量 14--16, 18,19, 46, 50, 51
这些方法表明,对未来触觉的预判可以提升表征质量、规划能力或反馈控制性能。其中一部分方法还依赖于与特定触觉传感器布局绑定的、人工设计的虚拟目标 18, 19
-
相比之下,作者的方法直接从未来手部力数据和经 EMA 监督的触觉潜变量中进行学习,从而避免了此类与传感器强相关的目标工程
同时,大量相关文献主要聚焦于臂-手一体的操作任务,并且往往依赖单独的触觉预训练过程、显式的世界模型模块,或者多阶段推理
其中预测得到的触觉信号被送入下游的策略或规划器中 15--17
相比之下,作者并不将未来触觉预测用作一个单独的世界模型或推理阶段模块,而是将其作为单阶段全身人形体模仿策略中的一个辅助目标
- 作者的框架在行为克隆的基础上引入了"触觉梦境"(touch dreaming):在 EMA 教师的监督下,同时预测未来的手部作用力以及未来的触觉潜变量
这样可以对共享的 Transformer 主干进行正则化,使其学习到感知接触的潜在动力学,同时保持训练与部署过程的简单性 - 总之,不同于以往以臂-手系统或多阶段视觉-触觉流水线为中心的工作,作者的方法将未来触觉预测直接集成到单阶段策略中,用于完成灵巧且接触丰富的全身人形体操纵
1.2 HTD的完整方法论
图2展示了作者用于学习真实世界中灵巧、富接触的人形机器人操作的系统
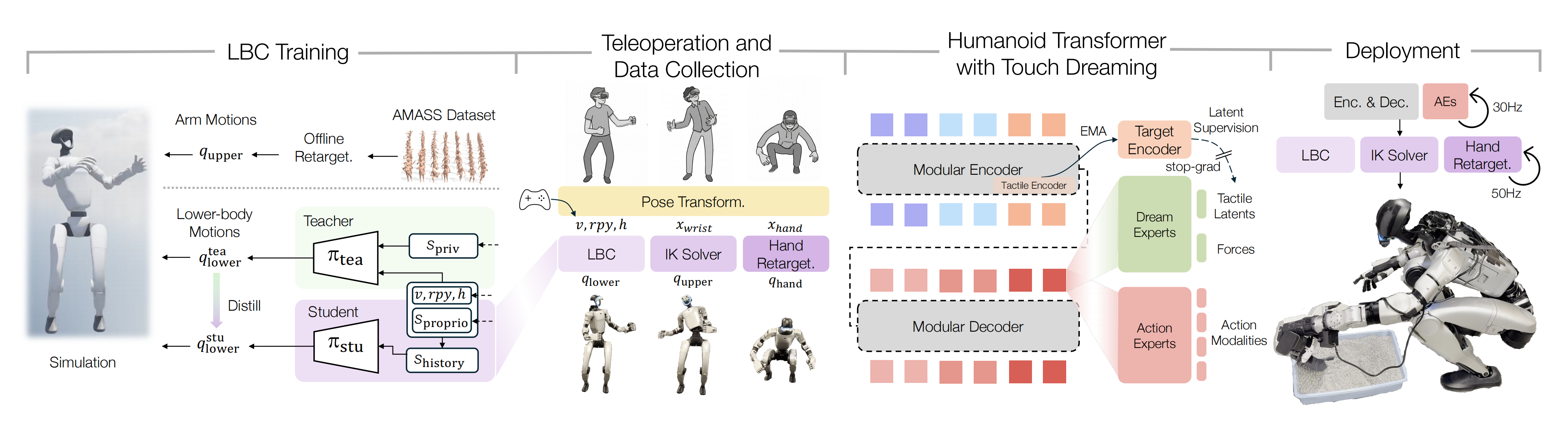
简言之
- 左侧(LBC 训练):采用教师-学生框架训练下半身控制器(LBC),以跟踪机体质心速度、躯干姿态和高度,并在此过程中鲁棒地处理从 AMASS 数据集中重定向得到的手臂动作
- *中左(远程操作):人类在 VR 中的动作被映射为统一的躯干指令(供 LBC 使用)、*末端执行器位姿(供 IK 使用),以及手部目标(用于重定向) ,同时**通过摇杆控制机体质心速度
- 中右(触觉梦境):多模态 Transformer 策略++融合视觉、触觉和本体感觉信息++,预测动作片段,同时预测未来手部关节受力和**触觉潜变量
未来的触觉潜变量 由带有停梯度(stop-gradient)的 EMA目标编码器(target encoder) 「第 III-E 节中的教师编码器」监督,从而提供稳定的潜在目标- 右侧(部署):该策略以 30 Hz 的频率连续输出动作片段,发送给LBC、IK 求解器和手部重定向模块,这三者均以 50 Hz 的频率运行
总之,该系统由四个阶段构成:1 下肢控制器(LBC)训练、2 基于 VR 的遥操作与数据收集、3 使用带触觉梦境机制的人形Transformer(Humanoid Transformer with TouchDreaming,HTD)进行策略学习,以及 4部署
具体而言
-
其基础是一种基于强化学习的 LBC,在操作过程中为下肢和躯干提供稳定的控制执行
且作者在仿真中采用教师--学生框架训练该控制器:
教师策略在重定向的手臂运动条件下学习鲁棒的下肢行为
最终得到的 LBC 能够跟踪底座速度、躯干姿态以及高度指令,并在遥操作和部署阶段都作为执行骨干 -
在该控制器的基础上,作者通过 VR 远程操控收集全身人形机器人的示范数据
人的头部、手腕和手部运动被转换到统一的机器人参考坐标系中,并被分解为躯干控制指令,用于LBC、用于 IK 求解器的末端执行器位姿目标,以及用于灵巧重定向的手部目标
此外,操作员还通过操纵杆提供底座速度指令最终得到的数据集包含同步的相机视角、自身感知(本体感受)、手部力信号和触觉观测,并与全身动作目标配对
-
利用这些示范数据,作者训练了 HTD,这是一种多模态、具备触觉感知能力的行走---操作一体化策略
HTD使用模块化的编码器---解码器式 Transformer,将多视角图像、机器人和手部本体感受(proprioception)、手部受力信号以及触觉输入token化 为一个共享的潜在表征,并为机体与双手解码出结构化的动作输出
HTD 还引入了触觉"梦境"头(touch-dreaming heads) ,用于预测未来的未来的触觉潜在表示Tactile Latents以及手部关节受力F orces
HTD introducestouch-dreaming heads that predict future hand jointforcesand**future tactile latents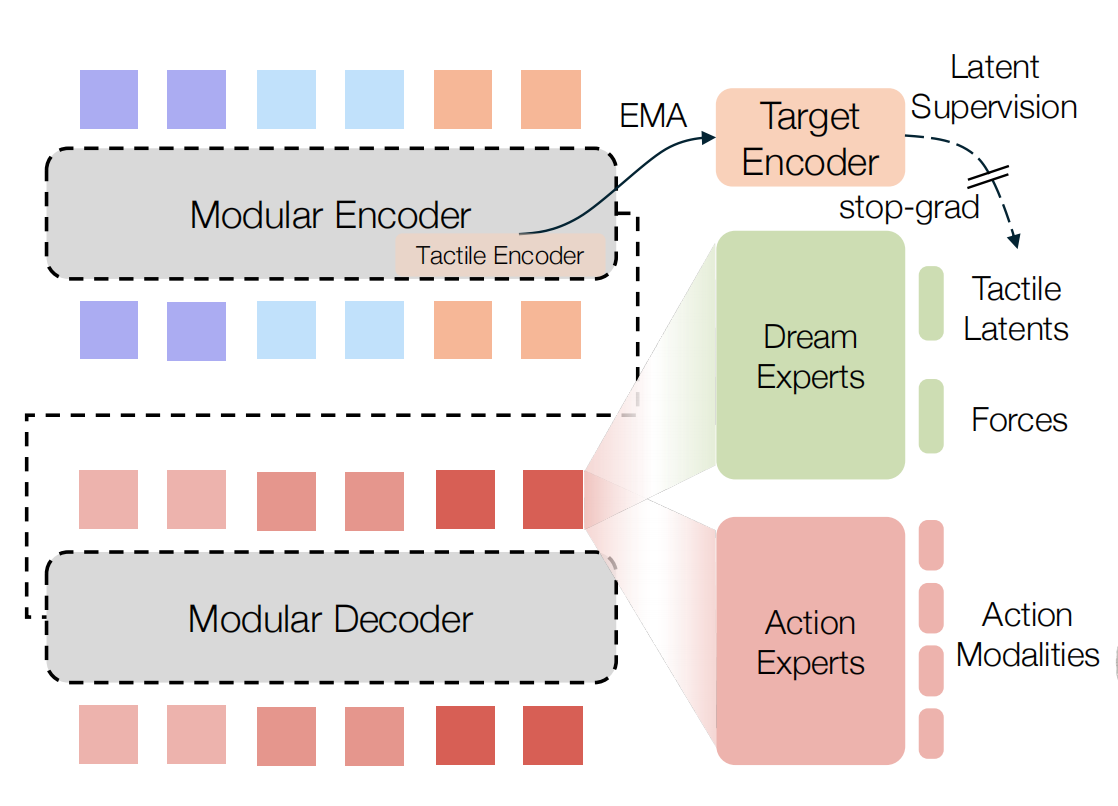
未来触觉潜在表示由一个 EMA目标编码器监督,该编码器在不需要单独的触觉预训练阶段的情况下,提供稳定的潜在目标;且通过EMA 编码器的梯度被截断,因此它仅作为一个缓慢演化的目标网络
上述辅助目标对共享的 Transformer 主干起到正则化作用,使其能够学习到具有接触感知能力的潜在动力学 -
在部署阶段
该策略以流式方式向 LBC、IK 求解器和手部重定向 模块输出动作片段,而***"梦境"头dream heads*** 仅在训练时使用,在推理阶段不会被执行
1.2.1 下肢控制器Lower-body Controller
作者在使用Isaac Lab 52 的大规模并行仿真中训练类人下肢策略。下肢策略依赖指令进行条件控制,目标是跟踪机体运动和躯干姿态目标
在每个控制步,可部署的本体感知观测
定义为
在这里
- 且
动作输出 是一个15 维的目标关节位置向量:两条腿为2 × 6,腰部电机为3
作者采用教师-学生框架来训练下肢策略
- 首先在仿真中使用具备特权信息访问能力的PPO 53 训练教师策略
- 随后通过DAgger 54 将其蒸馏到学生策略中
学生策略仅观测现实世界中可获得的信息,因此可以用于遥操作和自主执行
在训练过程中,上半身关节不由该策略控制;相反,重放从AMASS 55 中采样并重定向的手臂关节参考,以模拟上半身操作所产生的力矩和扰动
此外
-
教师策略被形式化为
为补偿部分可观测性,学生连接了2 个时间步长的本体感受观测历史
在训练过程中,学生在模拟中基于自身动作进行滚动执行,同时在每个时间步都由教师的参考动作进行监督,最小化学生与教师输出之间的L2损失
-
训练细节
在训练过程中,指令信号在预定义范围内进行均匀采样,以覆盖多样的运动行为
作者还应用域随机化来提升从仿真到现实的可迁移性
1.2.2 远程操作与数据采集Teleoperation and Data Collection
如图2 所示
作者的演示流程将基于VR 的动作映射与全身指令执行相结合,用于在真实环境中收集同步的人形机器人轨迹
- 在运行时,操作员的头部、手腕和手部运动从VR 坐标系转换到统一的机器人参考系
基于这些信号,作者生成用于上半身执行的躯干姿态指令 - 底座速度指令
该设计使操作员能够专注于任务意图和灵巧交互,而机器人端控制栈负责稳定性和低层执行
这些目标通过一个三阶段栈来执行
- 首先
LBC 接收 - 其次
一个IK 求解器将期望的手腕/末端执行器位姿 - 第三
一个基于DexPilot 56 的手部重定向模块通过优化指尖距离一致性,将人手目标
整体而言,这个栈实现了协调的全身遥操作,同时保留了末端执行器的完整灵巧性
-
在远程操作过程中,作者从仿人机器人上记录同步的多模态观测数据,包括来自
双镜头头部相机和腕部相机的 RGB 图像、机器人和手部本体感知信息、来自灵巧手各关节的力反馈,以及来自双手的触觉读数 -
每只手提供一个 1062 维的触觉观测,该观测分布在 17 个空间感知区域上,这些区域覆盖了手指各节与手掌表面
这样的分布式触觉布局能够捕捉整只手表面上局部的接触模式,如图 3 所示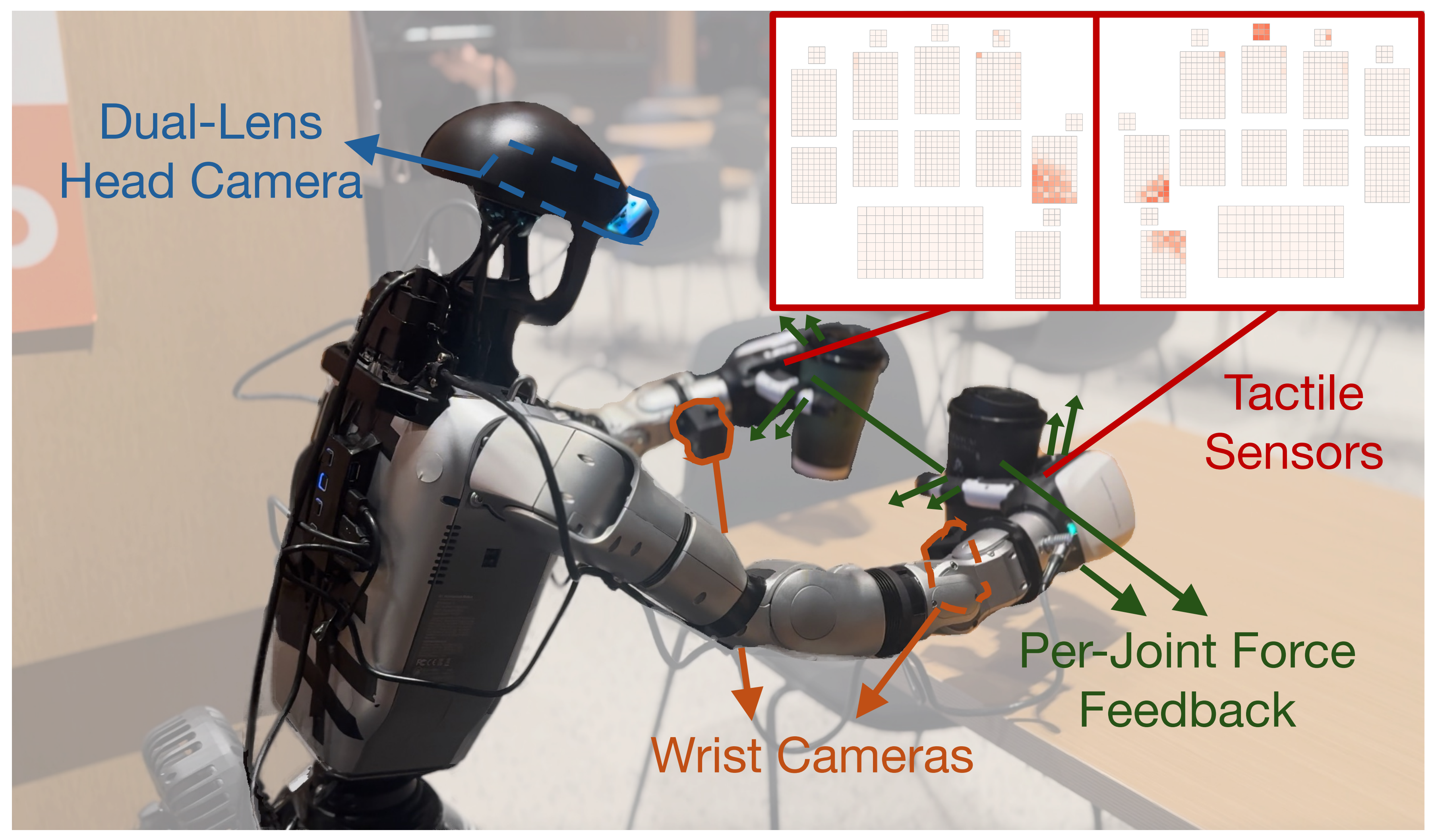
由此生成的数据集,将全身动作目标与多视角视觉、机器人和手部本体感知、逐关节手部力反馈以及分布式触觉观测进行配对,用于后续策略学习
1.2.3 通过触觉梦境学习灵巧操作
作者的目标是学习一种通用的人形机器人操作策略,把触觉作为核心模态来建模,从而鲁棒地处理富接触交互
即作者提出了带有触觉梦境机制的人形Transformer(Humanoid Transformer with TouchDreaming, HTD),如图 4 所示
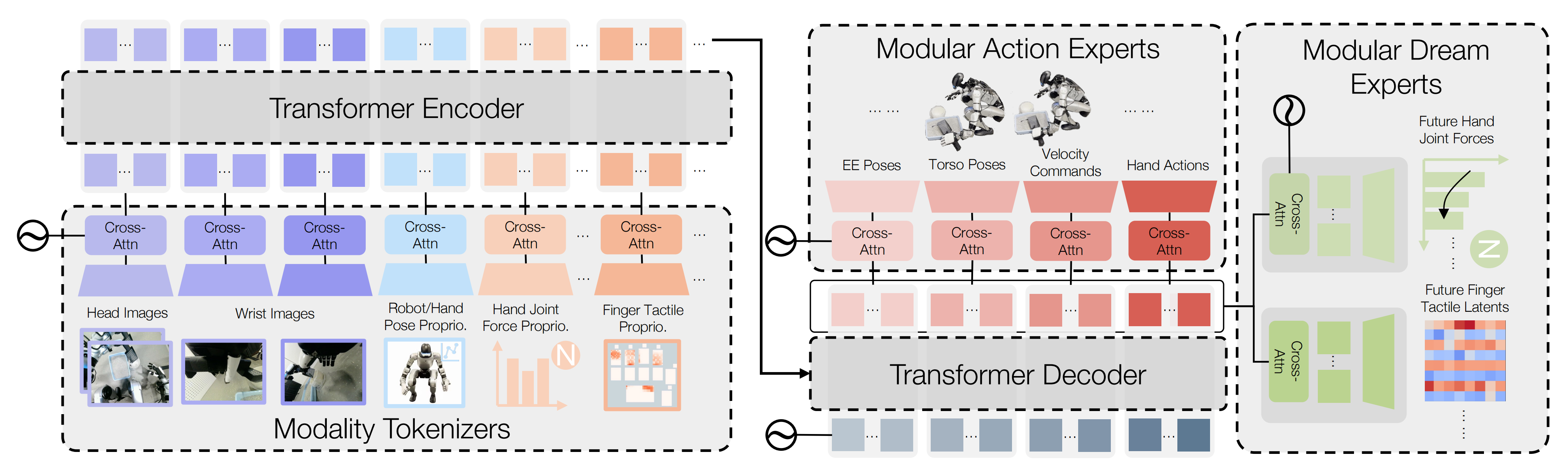
HTD 采用模块化设计,由三类组件构成:
- 模态分词器,将每一路观测流编码为一系列 token
- 编码器--解码器式的Transformer 主干,用于融合多模态信息并建模复杂动力学
- 模块化专家,将主干的输出解码为控制动作和辅助的触觉梦境的预测
modular experts that decode the trunk out-puts into both control actions and auxiliary touch-dreaming predictions
具体而言
- 在给定包含多视角视觉、机器人与手部本体感知、手部关节力信号以及触觉读数** 等观测的情况下,若干分词器tokenizer联合生成一串token序列
该序列再由 ++Transformer 编码器++进行特征融合 - 随后,++Transformer 解码器++输出一组固定数量的输出token ,并为每一种动作模态预留固定数量的token
这些token将被两类输出头所使用:
梦境专家会对所有动作模态的完整输出token集合进行注意力建模。这样的设计鼓励共享 Transformer 主干网络的潜在动态对接触信息保持敏感(即具备接触感知能力)
第一,对于模态分词器
每个分词器Tm 将原始模态映射为固定数量的tokens,这些tokens 以固定顺序连接,形成trans-former 编码器的输入,类似于57,58
如图4(左)所示,作者首先提取特定模态的特征,然后使用交叉注意力聚合层将其压缩为tokens,其中一小组可学习的query("slot")tokens 对特征序列进行注意力计算
- 对于图像模态
作者使用预训练的ResNet 59 骨干网络(在训练过程中进行微调)提取特征,并为头部相机和每个手腕相机使用独立的分词器 - 对于类似状态的模态(例如,机器人/手部位姿和本体感受,以及与力相关的本体感受信号)
作者使用轻量级MLP特征提取器 - 对于触觉输入
作者使用专门的触觉编码器将原始触觉读数嵌入到紧凑的特征序列中,然后通过相同的交叉注意力聚合进行分词
第二,对于按手指/区域划分的触觉编码器
对于触觉输入,作者对每个手指或手部区域进行独立编码,而不是一开始就形成单一的整手触觉嵌入
具体而言,作者将触觉观测分解为解剖学上定义的输入,对应拇指、食指、中指、无名指、小指以及手掌
- 对于常规手指,185 维的触觉输入会进一步被划分为三个局部区域(指尖、指背以及朝向手掌的一侧区域);
- 对于拇指,210 维的输入被划分为四个小块(指尖、指背顶部、中段和掌心朝向区域);
- 而对于手掌部分,这 112 维的输入被视为一个整体的大块
每个局部小块会被重排成一个二维特征图,并由一个根据小块尺寸选取的专用 CNN 分支进行处理:对于小块采用轻量级的单层卷积,对于较大的小块则采用更深的两层 CNN 模块
得到的小块特征通过自适应池化被统一到固定的空间分辨率,再进行展平、拼接,并通过一个 MLP 融合为对应手指或区域的紧凑嵌入表示
随后,这些按区域划分的嵌入会被投影到 Transformer 的隐空间维度,并通过与其他模态分词器相同的交叉注意力聚合机制,转换为触觉 token
相同的按区域划分的触觉编码器架构也被用于构建 EMA 目标编码器,以在触觉"梦境"生成过程中提供稳定的潜在监督信号
第三,对于Transformer 主干
HTD 使用一种编码器--解码器式的 Transformer 主干,其输入和输出序列长度是固定的,由分配给每种模态以及每个输出组的 token数量共同决定
- 编码器将串联后的观测 token 上下文化,转化为统一的表示
- 解码器则在预先指定的位置上生成一组固定数量的输出 token
可学习的查询嵌入充当结构化接口,以支持多个下游专家模块。这种解耦方式使得编码器可以专注于多模态状态理解,而解码器则为控制与预测提供互不干扰的读出通道
第四,对于模块化动作专家
作者使用一组模块化动作专家来解码控制输出(图 4 右上)
每个专家使用一个交叉注意力层,从解码器输出的 token 中读取信息,并预测某一种特定的动作模态,包括末端执行器位姿目标、躯干位姿目标、速度指令(在适用时)以及手部动作
这样的模块化设计,使得具有不同维度和控制角色的动作模态可以被独立且自适应地读出
具体而言,每一种动作模态都被分配其自身固定数量的解码器输出 token,因此
- 那些维度较低但在行为上很重要的输出(例如速度指令)可以能够获得足够的表征能力
- 而诸如姿态或手部动作等更高维度的输出,则可以由与其复杂度相匹配的独立专家进行解码
且作者采用 action chunking 60 方法,其中每个专家在每次推理步骤中预测一小段时间范围内的目标
第五,对于模块化梦境专家与触觉"做梦"
除了动作专家之外,HTD 还包含模块化梦境专家,在训练过程中提供辅助预测目标(图 4 最右侧)
这些专家预测未来触觉结果,包括:
- 未来手部关节受力向量
- 未来手指/区域的触觉潜变量
作者将这些辅助预测称为触觉"做梦"(touch dreaming):在给定当前多模态观测的条件下,模型会"想象"最近将来的触觉反馈,从而对共享的 Transformer 主干进行正则化,使其学习到对接触敏感的表征
关键在于,对于触觉部分,作者在一个学习得到的潜在空间中进行预测,而不是在原始传感器空间中进行预测 ------直接在原始触觉空间回归往往会受到稀疏性和噪声的主导,而在潜在空间上的监督则提供了一个紧凑的目标,能够刻画接触结构
此外,作者使用一个基于 EMA 的触觉 tokenizer 作为教师(第 III-E 节),以获得稳定的潜在标签,并监督学生去匹配这些教师潜变量
当然,在部署阶段,只有动作专家会被用于控制;梦境专家的输出不会被使用
第六,对于模态分解
作者将语义上彼此不同的输入保持为独立的模态,并对它们分别进行分词
- 在输出端,作者同样使用独立的动作专家对不同的动作模态进行解码,并使用专门的"梦境专家"来解码触觉梦境(touch-dreaming)目标
- 鉴于不同输入/输出模态具有各自不同的统计特性,这种网络设计允许基于模态的专门化,同时共享的 Transformer 主干则学习统一表征并建模复杂动态过程
1.2.4 训练范式
作者在人形演示数据上采用单阶段的行为克隆(Behavioral Cloning,BC)范式来训练策略。作者架构的关键组件是触觉梦境(touch dreaming):此外除了预测动作片段之外,模型还被训练用于预测未来的触觉信号
具体来说
- 作者使用平滑 L1损失来预测未来的手部关节力向量
- 在由 EMA 教师编码器生成的稳定潜在空间中预测未来的触觉潜变量**
作者发现,相比直接回归原始触觉阵列,在潜在空间中监督触觉预测可以在真实机器人上带来显著更好的操作性能------ 因为这种方式提供了紧凑且语义丰富的学习信号,同时避免了重建稀疏且高维的传感器读数所带来的困难
这个辅助预测目标鼓励 Transformer 主干网络学习与接触相关的世界表征,从而迁移为更优的下游高接触操作能力
整体训练流程在算法 1 中进行了总结

首先,对于触觉潜变量的EMA 教师
令表示由θ 参数化的学生触觉分词器,
表示其EMA 对应模型
在每次优化步骤之后,教师参数都会作为学生参数的EMA 进行更新
并且不会对教师网络进行梯度反向传播。教师网络提供缓慢演化、在时间上保持一致的潜在目标。如果没有这样一种自蒸馏机制,学生触觉分词器和触觉去分词器将会发生模式崩塌,即所有触觉输入都会被映射到几乎相同的潜在表示,而不管实际接触状态如何
其次,对于目标
令数据集,其中
给定动作模态和触觉信号(力和触觉),总体损失为:
其中 和
为触觉相关目标的权重。对于一个批次
,带有动作分块的BC 损失为
其中表示片段中的第
个动作
接着,对于
最后,对于
// 待更