AI 聊天系统语音播放(TTS)技术方案
适用场景 :AI 对话、智能客服、语音播报等实时流式语音交互场景
核心策略:异步分段合成 + 流式预加载 + 语义级文本分割
1. 方案概述
1.1 背景与挑战
在 AI 聊天系统中,将大模型生成的文本回复实时转换为语音播放,面临三个核心挑战:
| 挑战 | 说明 | 本方案对策 |
|---|---|---|
| 延迟高 | 长文本一次性合成耗时长,用户等待久 | 首段优先合成,后续段后台预加载 |
| 断句生硬 | 机械截断导致语义破碎 | 基于标点层级的智能文本分割 |
| 资源浪费 | 重复播放重复合成 | 多级缓存机制(内存 + 浏览器缓存) |
1.2 功能特性
- ✅ 流式播放:首段合成完成即播放,无需等待全文
- ✅ 智能分句:三级分割策略(句末 > 逗号 > 强制截断)
- ✅ 无缝衔接:利用前段播放时间预加载后段
- ✅ 播放控制:支持播放 / 暂停 / 继续 / 停止 / 进度重置
- ✅ 会话隔离:切换会话自动终止当前播放流
- ✅ 异常自愈:合成失败自动重试,超限自动降级
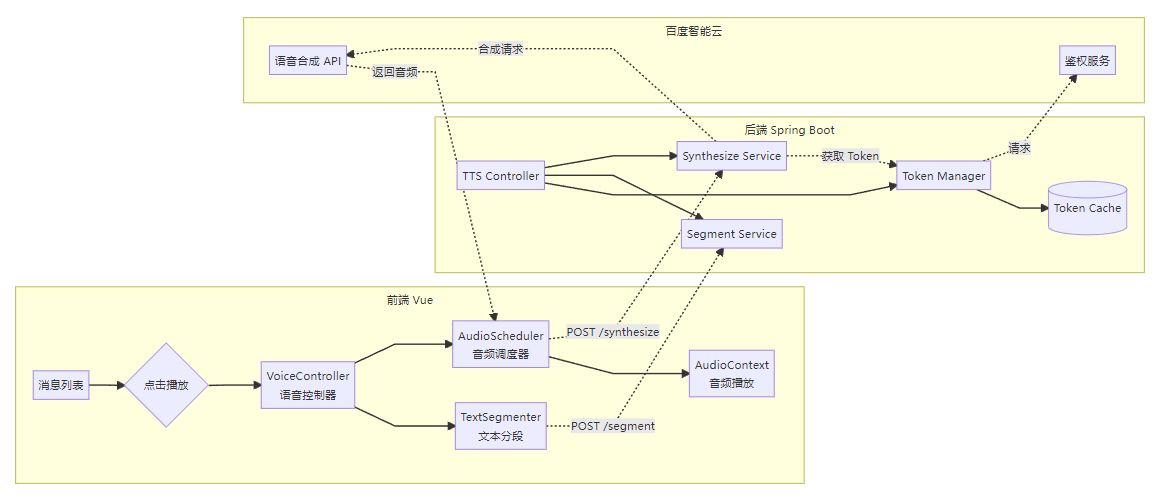
2. 系统架构
2.1 技术栈
| 层级 | 技术选型 | 职责 |
|---|---|---|
| 前端 | Vue 3 + Composition API | UI 交互、音频调度、状态管理 |
| 前端音频引擎 | HTML5 Audio API + Web Audio API | 音频播放、进度控制、音量调节 |
| 后端 | Spring Boot 3.x + Java 17 | 文本分段、Token 代理、流量控制 |
| TTS 服务 | 百度智能云语音合成 API | 语音合成 |
| 缓存 | Caffeine(本地)+ Redis(分布式) | Token 缓存、音频缓存 |
2.2 架构图
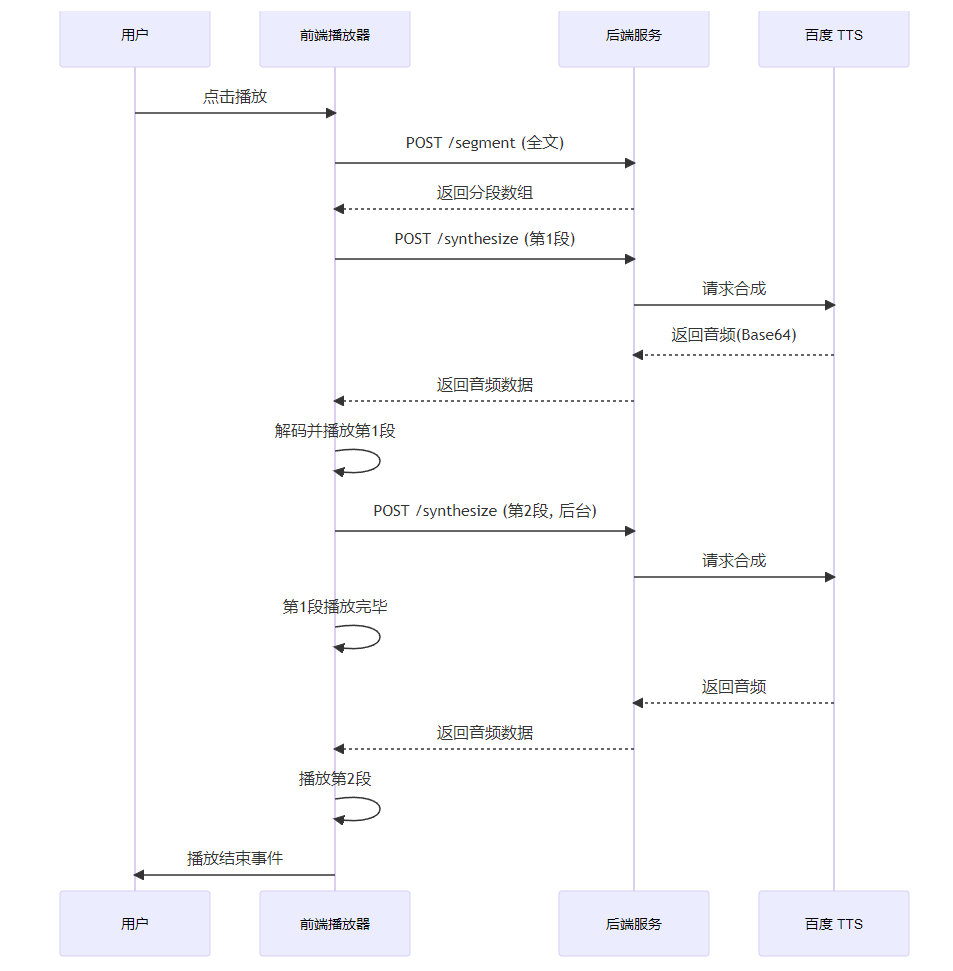
2.3 核心时序
3. 后端实现
3.1 配置类
使用 @ConfigurationProperties 实现类型安全的外部化配置:
java
@Data
@Component
@ConfigurationProperties(prefix = "baidu.tts")
public class BaiduTTSProperties {
/** API Key */
private String apiKey;
/** Secret Key */
private String secretKey;
/** 发音人:0=度小美(女声), 1=度小宇(男声), 3=度逍遥(男声), 4=度丫丫(女声) */
private Integer per = 0;
/** 语速:0-15,默认 5 */
private Integer spd = 5;
/** 音调:0-15,默认 5 */
private Integer pit = 5;
/** 音量:0-15,默认 5 */
private Integer vol = 5;
/** 音频格式:3=mp3, 4=pcm-16k, 5=pcm-8k, 6=wav */
private Integer aue = 3;
/** 是否启用 TTS */
private boolean enabled = false;
/** 单段最大字符数(百度限制 512,留余量) */
private Integer maxSegmentLength = 500;
}3.2 文本分段算法
采用三级回退策略,确保语义完整:
java
@Component
public class TextSegmenter {
/** 一级分隔符:句子结束 */
private static final String PRIMARY_DELIMITERS = "。!?.!?";
/** 二级分隔符:短停顿 */
private static final String SECONDARY_DELIMITERS = ",、,;";
/**
* 智能文本分段
* @param text 原始文本
* @param maxLength 最大段长(建议 300-500)
*/
public List<String> split(String text, int maxLength) {
List<String> segments = new ArrayList<>();
if (text == null || text.isEmpty()) {
return segments;
}
// 去除 Markdown 标记、URL 等干扰内容(可选)
String cleanText = cleanMarkdown(text);
int start = 0;
while (start < cleanText.length()) {
if (cleanText.length() - start <= maxLength) {
segments.add(cleanText.substring(start).trim());
break;
}
int end = findBestSplitPoint(cleanText, start, maxLength);
String segment = cleanText.substring(start, end).trim();
if (!segment.isEmpty()) {
segments.add(segment);
}
start = end;
}
return segments;
}
/**
* 查找最佳分割点:优先句末 > 逗号 > 强制截断
*/
private int findBestSplitPoint(String text, int start, int maxLength) {
int candidate = start + maxLength;
// 一级:在 maxLength 前找最后一个句末标点
for (int i = candidate - 1; i > start; i--) {
if (PRIMARY_DELIMITERS.indexOf(text.charAt(i)) >= 0) {
return i + 1;
}
}
// 二级:找逗号类标点(至少保留 20 字符,避免段过短)
int minLength = Math.min(20, maxLength / 2);
for (int i = candidate - 1; i > start + minLength; i--) {
if (SECONDARY_DELIMITERS.indexOf(text.charAt(i)) >= 0) {
return i + 1;
}
}
// 三级:强制截断(但避免截断英文单词或数字)
return findSafeTruncatePoint(text, start, candidate);
}
/**
* 安全截断:避免在英文单词或数字中间截断
*/
private int findSafeTruncatePoint(String text, int start, int candidate) {
if (candidate >= text.length()) return text.length();
// 如果截断点是字母或数字,向前回退到非字母数字处
while (candidate > start + 10 &&
Character.isLetterOrDigit(text.charAt(candidate - 1))) {
candidate--;
}
return candidate;
}
private String cleanMarkdown(String text) {
// 简单去除 Markdown 链接,保留文本
return text.replaceAll("\\[(.*?)]\\(.*?\\)", "$1")
.replaceAll("[#*`>]", "");
}
}3.3 Token 管理(带缓存)
百度 TTS 需要 Access Token,有效期通常为 30 天,应集中管理避免重复获取:
java
@Service
@Slf4j
public class BaiduTokenManager {
@Autowired
private BaiduTTSProperties props;
/** 本地缓存,Token 提前 5 分钟过期 */
private final Cache<String, String> tokenCache = Caffeine.newBuilder()
.expireAfterWrite(25, TimeUnit.MINUTES)
.build();
private static final String TOKEN_URL =
"https://aip.baidubce.com/oauth/2.0/token";
public String getAccessToken() {
String cached = tokenCache.getIfPresent("baidu_tts_token");
if (cached != null) {
return cached;
}
synchronized (this) {
// 双重检查
cached = tokenCache.getIfPresent("baidu_tts_token");
if (cached != null) return cached;
String token = fetchTokenFromRemote();
tokenCache.put("baidu_tts_token", token);
return token;
}
}
private String fetchTokenFromRemote() {
String url = TOKEN_URL + "?grant_type=client_credentials" +
"&client_id=" + props.getApiKey() +
"&client_secret=" + props.getSecretKey();
try {
RestTemplate rest = new RestTemplate();
ResponseEntity<Map> response = rest.postForEntity(url, null, Map.class);
Map body = response.getBody();
if (body == null || body.get("access_token") == null) {
throw new RuntimeException("获取百度 Token 失败: " + body);
}
return (String) body.get("access_token");
} catch (Exception e) {
log.error("获取百度 TTS Token 异常", e);
throw new RuntimeException("语音服务暂不可用", e);
}
}
}3.4 单段合成服务
java
@Service
@Slf4j
public class TTSService {
@Autowired
private BaiduTTSProperties props;
@Autowired
private BaiduTokenManager tokenManager;
private static final String TTS_URL =
"https://tsn.baidu.com/text2audio";
/**
* 合成单段文本
* @return Base64 编码的音频数据
*/
public TTSResult synthesize(String text) {
if (!props.isEnabled()) {
throw new IllegalStateException("TTS 服务未启用");
}
String token = tokenManager.getAccessToken();
// 构建请求参数
Map<String, Object> params = new HashMap<>();
params.put("tex", UriUtils.encode(text, StandardCharsets.UTF_8));
params.put("tok", token);
params.put("cuid", generateCuid()); // 设备唯一标识
params.put("ctp", 1);
params.put("lan", "zh");
params.put("spd", props.getSpd());
params.put("pit", props.getPit());
params.put("vol", props.getVol());
params.put("per", props.getPer());
params.put("aue", props.getAue());
try {
RestTemplate rest = new RestTemplate();
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_FORM_URLENCODED);
String body = params.entrySet().stream()
.map(e -> e.getKey() + "=" + e.getValue())
.collect(Collectors.joining("&"));
HttpEntity<String> request = new HttpEntity<>(body, headers);
ResponseEntity<byte[]> response = rest.postForEntity(
TTS_URL, request, byte[].class);
byte[] audioBytes = response.getBody();
if (audioBytes == null || audioBytes.length == 0) {
throw new RuntimeException("合成返回空数据");
}
// 百度成功时返回音频二进制,失败时返回 JSON(以 "err" 开头)
if (audioBytes.length < 100 && new String(audioBytes).contains("err")) {
String error = new String(audioBytes);
log.error("百度 TTS 合成错误: {}", error);
throw new RuntimeException("语音合成失败: " + error);
}
String base64Audio = Base64.getEncoder().encodeToString(audioBytes);
return TTSResult.builder()
.audioData(base64Audio)
.format(getAudioFormat(props.getAue()))
.duration(estimateDuration(text, props.getSpd())) // 预估时长
.build();
} catch (Exception e) {
log.error("TTS 合成异常, text={}", text.substring(0, Math.min(50, text.length())), e);
throw new RuntimeException("语音合成服务异常", e);
}
}
private String generateCuid() {
// 使用服务器标识 + 随机数,确保唯一性
return "server_" + System.currentTimeMillis();
}
private String getAudioFormat(int aue) {
return switch (aue) {
case 3 -> "mp3";
case 4, 5 -> "pcm";
case 6 -> "wav";
default -> "mp3";
};
}
/**
* 预估音频时长(秒),用于前端进度条
*/
private int estimateDuration(String text, int spd) {
// 粗略估算:中文字符约 0.3s/字,spd 每增加 1 减少约 5%
double baseTime = text.length() * 0.3;
double speedFactor = 1 - (spd - 5) * 0.05;
return (int) Math.ceil(baseTime * speedFactor);
}
}3.5 控制器层
java
@RestController
@RequestMapping("/api/tts")
@RequiredArgsConstructor
public class TTSController {
private final TextSegmenter segmenter;
private final TTSService ttsService;
private final BaiduTTSProperties props;
@GetMapping("/config")
public Result<TTSConfigVO> getConfig() {
TTSConfigVO vo = new TTSConfigVO();
vo.setEnabled(props.isEnabled());
vo.setVoices(List.of(
new VoiceVO(0, "度小美", "女声", "标准"),
new VoiceVO(1, "度小宇", "男声", "标准"),
new VoiceVO(3, "度逍遥", "男声", "情感"),
new VoiceVO(4, "度丫丫", "女声", "童声")
));
vo.setDefaultSpd(props.getSpd());
vo.setDefaultPit(props.getPit());
vo.setDefaultVol(props.getVol());
return Result.success(vo);
}
@PostMapping("/segment")
public Result<SegmentVO> segmentText(@RequestBody @Valid SegmentRequest request) {
List<String> segments = segmenter.split(
request.getText(),
props.getMaxSegmentLength()
);
SegmentVO vo = new SegmentVO();
vo.setSegments(segments);
vo.setTotalSegments(segments.size());
vo.setTotalChars(request.getText().length());
return Result.success(vo);
}
@PostMapping("/synthesize")
public Result<TTSResult> synthesize(@RequestBody @Valid SynthesizeRequest request) {
// 单段长度校验
if (request.getText().length() > props.getMaxSegmentLength()) {
return Result.fail("单段文本过长,请先调用分段接口");
}
TTSResult result = ttsService.synthesize(request.getText());
return Result.success(result);
}
}4. 前端实现
4.1 语音播放器核心类
采用 State Machine(状态机) 管理播放生命周期:
typescript
// types.ts
export type PlayerState =
| 'idle' // 空闲
| 'loading' // 加载中(首段合成)
| 'buffering' // 缓冲中(后续段合成)
| 'playing' // 播放中
| 'paused' // 已暂停
| 'ended' // 已结束
| 'error'; // 错误
export interface TTSResult {
audioData: string; // Base64
format: string; // mp3 / wav
duration: number; // 预估时长(秒)
}
export interface SegmentInfo {
text: string;
index: number;
audio?: TTSResult;
status: 'pending' | 'loading' | 'ready' | 'error';
}
typescript
// VoicePlayer.ts
export class VoicePlayer extends EventTarget {
// 状态
private _state: PlayerState = 'idle';
private currentMessageId: string | null = null;
private segments: SegmentInfo[] = [];
private currentIndex: number = 0;
// 音频对象
private audioContext: AudioContext | null = null;
private currentAudio: HTMLAudioElement | null = null;
// 缓存与并发控制
private audioCache = new Map<number, TTSResult>();
private pendingRequests = new Set<number>();
private abortController: AbortController | null = null;
// 配置
private readonly API_BASE = '/api/tts';
constructor() {
super();
// 监听页面可见性变化,后台时暂停(可选策略)
document.addEventListener('visibilitychange', () => {
if (document.hidden && this._state === 'playing') {
this.pause();
}
});
}
get state(): PlayerState {
return this._state;
}
// ==================== 公共控制接口 ====================
/**
* 切换播放状态(入口方法)
*/
async toggle(messageId: string, text: string): Promise<void> {
if (this.currentMessageId === messageId) {
// 同一消息:根据当前状态切换
switch (this._state) {
case 'playing':
await this.pause();
return;
case 'paused':
await this.resume();
return;
case 'loading':
case 'buffering':
this.stop(); // 取消加载
return;
default:
await this.play(messageId, text);
return;
}
}
// 不同消息:先停止,再播放新消息
this.stop();
await this.play(messageId, text);
}
/**
* 开始播放流程
*/
async play(messageId: string, text: string): Promise<void> {
try {
this.currentMessageId = messageId;
this._setState('loading');
// 1. 文本分段
const segmentData = await this.fetchSegments(text);
this.segments = segmentData.segments.map((text: string, idx: number) => ({
text,
index: idx,
status: 'pending'
}));
// 2. 合成并播放第一段
this.currentIndex = 0;
await this.synthesizeAndPlay(0);
// 3. 后台预加载后续段
this.preloadRemaining();
} catch (error) {
this._setState('error');
console.error('[VoicePlayer] 播放失败:', error);
this.dispatchEvent(new CustomEvent('error', { detail: error }));
}
}
async pause(): Promise<void> {
if (this.currentAudio && this._state === 'playing') {
this.currentAudio.pause();
this._setState('paused');
}
}
async resume(): Promise<void> {
if (this.currentAudio && this._state === 'paused') {
await this.currentAudio.play();
this._setState('playing');
}
}
stop(): void {
// 取消所有进行中的请求
if (this.abortController) {
this.abortController.abort();
this.abortController = null;
}
if (this.currentAudio) {
this.currentAudio.pause();
this.currentAudio.src = '';
this.currentAudio = null;
}
this.pendingRequests.clear();
this.currentMessageId = null;
this.currentIndex = 0;
this.segments = [];
this._setState('idle');
}
// ==================== 核心播放逻辑 ====================
/**
* 合成指定段并播放
*/
private async synthesizeAndPlay(index: number): Promise<void> {
if (index >= this.segments.length) {
this._setState('ended');
this.dispatchEvent(new CustomEvent('ended'));
return;
}
this.currentIndex = index;
// 获取音频数据(优先缓存)
const audioData = await this.getSegmentAudio(index);
if (!audioData) {
throw new Error(`第 ${index} 段音频获取失败`);
}
// 播放
await this.playAudio(index, audioData);
}
/**
* 获取段音频(带缓存和去重)
*/
private async getSegmentAudio(index: number): Promise<TTSResult | null> {
// 1. 检查内存缓存
if (this.audioCache.has(index)) {
return this.audioCache.get(index)!;
}
// 2. 检查是否已有请求在进行
if (this.pendingRequests.has(index)) {
// 等待已有请求完成
while (this.pendingRequests.has(index)) {
await this.delay(50);
}
return this.audioCache.get(index) || null;
}
// 3. 发起新请求
this.pendingRequests.add(index);
this.segments[index].status = 'loading';
try {
const result = await this.fetchSynthesize(this.segments[index].text);
this.audioCache.set(index, result);
this.segments[index].audio = result;
this.segments[index].status = 'ready';
return result;
} catch (error) {
this.segments[index].status = 'error';
console.error(`[VoicePlayer] 第 ${index} 段合成失败`, error);
return null;
} finally {
this.pendingRequests.delete(index);
}
}
/**
* 播放音频段
*/
private async playAudio(index: number, audioResult: TTSResult): Promise<void> {
return new Promise((resolve, reject) => {
// Base64 转 Blob URL
const blob = this.base64ToBlob(audioResult.audioData,
`audio/${audioResult.format}`);
const url = URL.createObjectURL(blob);
this.currentAudio = new Audio(url);
// 绑定事件
this.currentAudio.addEventListener('play', () => {
this._setState('playing');
});
this.currentAudio.addEventListener('ended', () => {
URL.revokeObjectURL(url); // 释放内存
this.cleanupAudio();
resolve();
// 自动播放下一段
this.synthesizeAndPlay(index + 1);
});
this.currentAudio.addEventListener('error', (e) => {
URL.revokeObjectURL(url);
reject(new Error('音频播放失败'));
});
// 播放
this.currentAudio.play().catch(reject);
});
}
/**
* 后台预加载剩余段
*/
private preloadRemaining(): void {
// 从当前播放段的下一段开始,预加载 2 段
const preloadCount = 2;
for (let i = 1; i <= preloadCount; i++) {
const targetIndex = this.currentIndex + i;
if (targetIndex < this.segments.length &&
!this.audioCache.has(targetIndex) &&
!this.pendingRequests.has(targetIndex)) {
// 不 await,后台执行
this.getSegmentAudio(targetIndex).catch(err => {
console.warn(`[VoicePlayer] 预加载第 ${targetIndex} 段失败`, err);
});
}
}
}
// ==================== 网络请求 ====================
private async fetchSegments(text: string): Promise<any> {
const res = await fetch(`${this.API_BASE}/segment`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ text })
});
if (!res.ok) throw new Error('分段请求失败');
return (await res.json()).data;
}
private async fetchSynthesize(text: string): Promise<TTSResult> {
this.abortController = new AbortController();
const res = await fetch(`${this.API_BASE}/synthesize`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ text }),
signal: this.abortController.signal
});
if (!res.ok) throw new Error('合成请求失败');
return (await res.json()).data;
}
// ==================== 工具方法 ====================
private base64ToBlob(base64: string, mimeType: string): Blob {
const byteCharacters = atob(base64);
const byteArrays: Uint8Array[] = [];
for (let offset = 0; offset < byteCharacters.length; offset += 512) {
const slice = byteCharacters.slice(offset, offset + 512);
const byteNumbers = new Array(slice.length);
for (let i = 0; i < slice.length; i++) {
byteNumbers[i] = slice.charCodeAt(i);
}
byteArrays.push(new Uint8Array(byteNumbers));
}
return new Blob(byteArrays, { type: mimeType });
}
private cleanupAudio(): void {
if (this.currentAudio) {
this.currentAudio.src = '';
this.currentAudio = null;
}
}
private delay(ms: number): Promise<void> {
return new Promise(resolve => setTimeout(resolve, ms));
}
private _setState(state: PlayerState): void {
this._state = state;
this.dispatchEvent(new CustomEvent('statechange', { detail: state }));
}
}4.2 Vue 3 组件封装示例
vue
<template>
<button
class="tts-button"
:class="playerState"
@click="handleToggle"
:disabled="!ttsEnabled"
>
<span class="icon">
<svg v-if="playerState === 'playing'" class="animate-pulse">...暂停图标</svg>
<svg v-else-if="playerState === 'loading' || playerState === 'buffering'" class="animate-spin">...加载图标</svg>
<svg v-else>...播放图标</svg>
</span>
<span class="label">{{ stateLabel }}</span>
</button>
</template>
<script setup lang="ts">
import { ref, computed, onUnmounted } from 'vue';
import { VoicePlayer, PlayerState } from './VoicePlayer';
const props = defineProps<{
messageId: string;
content: string;
}>();
const player = new VoicePlayer();
const playerState = ref<PlayerState>('idle');
// 监听状态变化
player.addEventListener('statechange', (e: any) => {
playerState.value = e.detail;
});
const ttsEnabled = ref(true); // 从 /api/tts/config 获取
const stateLabel = computed(() => {
const map: Record<string, string> = {
idle: '朗读',
loading: '准备中',
buffering: '缓冲中',
playing: '暂停',
paused: '继续',
ended: '重播',
error: '失败'
};
return map[playerState.value] || '朗读';
});
const handleToggle = () => {
player.toggle(props.messageId, props.content);
};
// 组件卸载时清理
onUnmounted(() => {
player.stop();
});
</script>5. 关键设计详解
5.1 异步合成策略
| 阶段 | 行为 | 目的 |
|---|---|---|
| P0(首段) | 阻塞等待,合成后立刻播放 | 最小化首响延迟 |
| P1(预加载) | 播放首段时,后台并发合成第 2~3 段 | 利用播放时间窗口 |
| P2(流式) | 每段播放结束时,下一段已就绪 | 实现无缝衔接 |
并发控制 :通过 pendingRequests Set 确保同一段不会重复请求,避免额度浪费。
5.2 智能文本分割策略
原文:今天天气真好,适合出去走走。你有什么计划吗?要不一起去公园?
策略执行:
1. 按 500 字符限制检查 → 未超限,无需分割
2. 若超限 20 字符:
- 在 "?" 处分割 → [..., "你有什么计划吗?", "要不一起去公园?"]
3. 若句末标点均不满足:
- 在 "," 处分割(保留至少 20 字符)
4. 若仍不满足:
- 强制截断,但避开英文单词边界5.3 音频缓存机制
采用三级缓存:
typescript
// L1: 内存缓存(当前会话)
this.audioCache: Map<number, TTSResult>
// L2: SessionStorage(同一会话内刷新保留)
sessionStorage.setItem(`tts_${messageId}_${index}`, JSON.stringify(result))
// L3: IndexedDB(长期缓存,可选)
// 适合高频固定文本(如系统提示语)5.4 内存管理
- Blob URL 释放 :每段播放结束后立即
URL.revokeObjectURL() - Audio 对象清理 :设置
src = ''解除引用 - AbortController :切换会话时取消未完成的
fetch请求
6. 会话与生命周期管理
6.1 会话切换控制
typescript
// 在会话管理器中注入
class SessionManager {
private voicePlayer: VoicePlayer;
switchSession(newSessionId: string) {
// 切换前停止当前播放
this.voicePlayer.stop();
// ... 加载新会话
}
}6.2 页面生命周期适配
| 场景 | 策略 |
|---|---|
| 页面隐藏(切 Tab) | 自动暂停,回到页面时询问是否继续 |
| 页面关闭 | 无需处理(进程结束自动释放) |
| 组件卸载 | 调用 player.stop() 清理资源 |
| 长文本中途离开 | 保留进度,支持断点续播(可选) |
7. 配置与部署
7.1 后端配置(application.yml)
yaml
baidu:
tts:
api-key: ${BAIDU_TTS_API_KEY}
secret-key: ${BAIDU_TTS_SECRET_KEY}
per: 0 # 度小美
spd: 5 # 标准语速
pit: 5 # 标准音调
vol: 7 # 稍大音量(AI 场景建议稍大)
aue: 3 # MP3 格式(兼容性最佳)
enabled: true
max-segment-length: 500
# 限流配置(防止恶意刷接口)
rate-limiter:
tts:
qps: 10 # 单用户每秒最多 10 次合成请求7.2 环境变量(生产安全)
切勿将 Key 硬编码,应通过环境变量注入:
bash
# .env.production
BAIDU_TTS_API_KEY=your-key
BAIDU_TTS_SECRET_KEY=your-secret8. API 接口规范
| 接口 | 方法 | 请求体 | 响应 | 说明 |
|---|---|---|---|---|
/api/tts/config |
GET | - | TTSConfigVO | 获取配置、音色列表 |
/api/tts/segment |
POST | { text: string } |
SegmentVO | 文本智能分段 |
/api/tts/synthesize |
POST | { text: string } |
TTSResult | 单段合成(Base64) |
/api/tts/voices |
GET | - | List | 获取可用音色 |
8.1 关键 VO 定义
java
@Data
public class TTSResult {
private String audioData; // Base64 音频
private String format; // mp3 / pcm / wav
private int duration; // 预估时长(秒)
}
@Data
public class SegmentVO {
private List<String> segments;
private int totalSegments;
private int totalChars;
}9. 性能与稳定性优化
9.1 优化清单
| 优化点 | 实现方式 | 效果 |
|---|---|---|
| Token 缓存 | Caffeine 本地缓存 25 分钟 | 减少 90% 以上鉴权请求 |
| 音频缓存 | Map + SessionStorage | 重复播放零延迟 |
| 预加载窗口 | 当前段播放时预加载后 2 段 | 消除网络等待 |
| 连接复用 | RestTemplate / HTTP2 | 降低 TCP 握手开销 |
| 文本压缩 | 去除 Markdown、URL | 减少无效字符,提升合成质量 |
| Gzip 传输 | 开启 Nginx / Spring Boot Gzip | Base64 文本压缩率约 30% |
9.2 预估性能指标
- 首段延迟:< 800ms(文本 < 100 字,网络正常)
- 段间切换延迟:< 100ms(预加载命中时)
- 并发合成上限:取决于百度 QPS 额度(默认 100 QPS)
10. 错误处理与降级策略
10.1 错误码映射(百度 TTS)
| 错误码 | 含义 | 后端处理 | 前端提示 |
|---|---|---|---|
| 500 | 后端内部错误 | 记录日志,返回 500 | "服务繁忙,请稍后重试" |
| 502 | 额度用完 | 返回特定错误码 | "语音额度已用完,请联系管理员" |
| 503 | Token 失效 | 清除缓存,自动重试 1 次 | 无感刷新 |
| 506 | 文本过长 | 返回 400,提示分段 | "文本过长,已自动分段" |
| 511 | 并发超限 | 返回 429,触发限流 | "操作过于频繁,请稍候" |
| 网络超时 | 请求无响应 | 重试 2 次(指数退避) | "网络不稳定,正在重试..." |
10.2 降级策略
typescript
// 当 TTS 服务不可用时,提供降级方案
if (error.code === 'TTS_UNAVAILABLE') {
// 方案 A:提示用户自行阅读
showToast('语音服务暂不可用,请阅读文字内容');
// 方案 B:切换备用 TTS(如浏览器内置 speechSynthesis)
if ('speechSynthesis' in window) {
const utterance = new SpeechSynthesisUtterance(text);
window.speechSynthesis.speak(utterance);
}
}10.3 限流与防护
java
// Spring Boot + Bucket4j 限流示例
@RateLimited(
capacity = 10, // 令牌桶容量
refillTokens = 5, // 每秒补充 5 个
key = "#request.userId"
)
@PostMapping("/synthesize")
public Result<TTSResult> synthesize(...) { ... }11. 总结
本方案通过异步分段合成 与智能预加载机制,解决了 AI 聊天场景中长文本语音播放的三大痛点:
| 目标 | 达成方式 |
|---|---|
| 🚀 低延迟启动 | 首段优先合成,无需等待全文 |
| 🎵 流畅播放 | 后台预加载 + 音频缓存,段间无缝衔接 |
| 🧠 语义完整 | 三级智能分割,避免在词/句中截断 |
| ♻️ 资源高效 | 多级缓存 + 并发去重,避免重复合成 |
| 🛡️ 稳定可靠 | 异常重试 + 服务降级 + 限流防护 |
后续可扩展方向
- WebSocket 流式传输:后端合成一段推送一段,进一步降低延迟
- 情感识别 :根据文本情感(疑问、感叹)动态调整
pit(音调) - SSML 支持:支持停顿、重读等富文本标记
- 用户音色偏好记忆:记住用户选择的发音人、语速