🎬 video-use:用「对话」剪辑视频------browser-use 团队开源的 AI 视频编辑神器
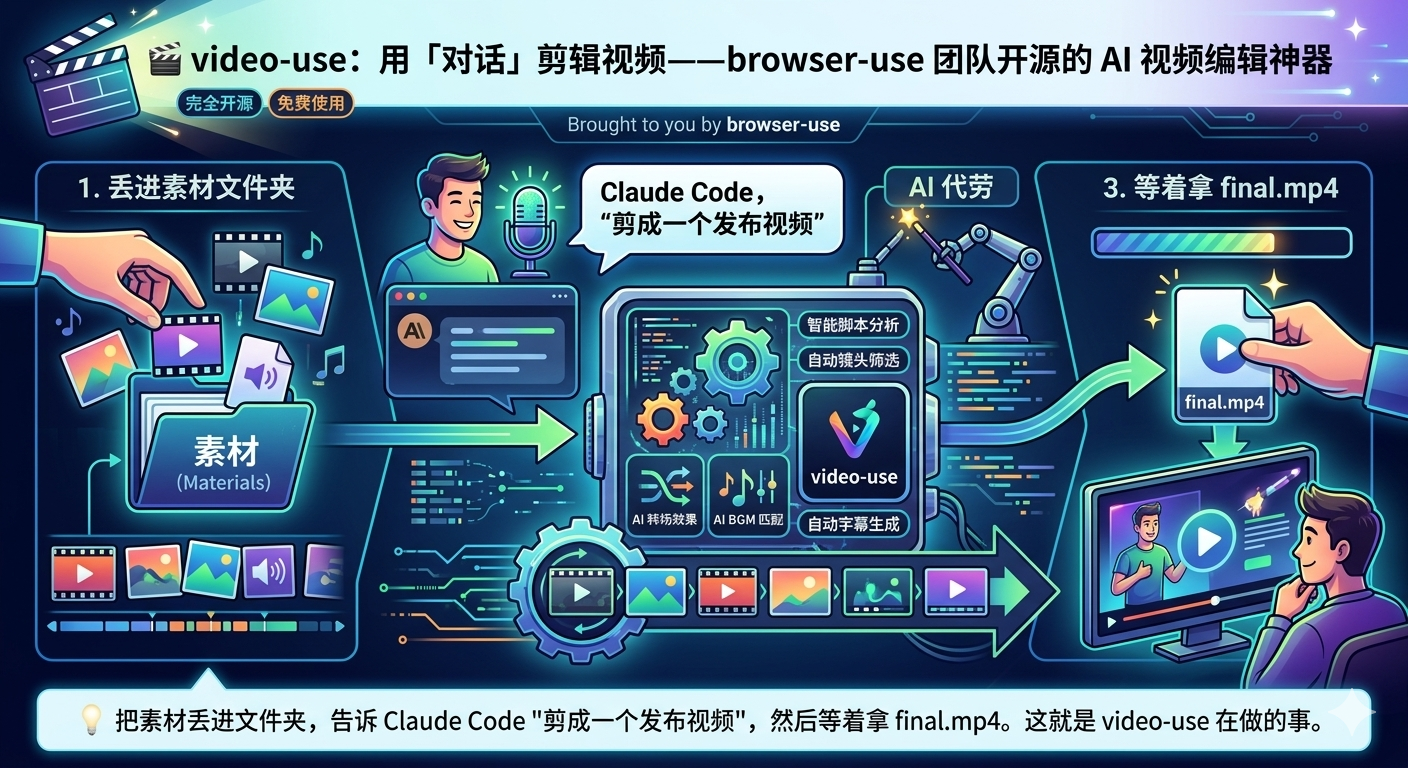
💡 把素材丢进文件夹,告诉 Claude Code "剪成一个发布视频",然后等着拿 final.mp4。这就是 video-use 在做的事。
📌 目录
- [1. 它是什么?](#1. 它是什么?)
- [2. 核心设计理念](#2. 核心设计理念)
- [3. 双层读取系统:LLM 如何"看"视频](#3. 双层读取系统:LLM 如何"看"视频)
- [4. 完整工作流程](#4. 完整工作流程)
- [5. 12 条硬性规则(制作正确性)](#5. 12 条硬性规则(制作正确性))
- [6. 剪辑工艺详解](#6. 剪辑工艺详解)
- [7. 动画系统](#7. 动画系统)
- [8. 安装与使用](#8. 安装与使用)
- [9. 适用场景与优缺点](#9. 适用场景与优缺点)
- [10. 总结](#10. 总结)
1. 它是什么?
video-use 是由 browser-use 团队(没错,就是那个做 AI 浏览器自动化的明星团队)开源的 AI 视频编辑工具。
它的核心理念极其简洁:
🎯 对话式视频编辑------用自然语言指挥 AI 完成专业级剪辑
工作流程:
原始素材 → 放入文件夹 → 启动 Claude Code → 说"剪成发布视频" → AI 自动完成转录/剪辑/调色/字幕/动画 → 输出 final.mp4一句话定位: 视频编辑界的"AI 副驾驶"------你负责创意决策,AI 负责技术执行。
2. 核心设计理念
video-use 不是简单的"自动剪辑",而是一套基于对话的专业视频制作工作流:
| 原则 | 说明 |
|---|---|
| 📝 文本 + 按需视觉 | LLM 主要阅读转录文本(12KB),只在决策点查看视觉合成图 |
| 🎙️ 音频主导,视觉跟随 | 剪辑候选来自语音边界和静默间隙 |
| ✅ 询问 → 确认 → 执行 → 迭代 → 持久化 | 绝不未经用户确认就动剪刀 |
| 🎨 艺术自由是默认 | 除硬性规则外,一切风格、字体、颜色、技术都可自由发挥 |
| 🔍 自我验证 | 在展示给用户前,AI 先自我检查渲染输出 |
核心功能一览
| 功能 | 说明 |
|---|---|
| ✂️ 智能剪辑 | 自动去除填充词(umm, uh)和无效片段间的死寂 |
| 🎨 自动调色 | 温暖电影感、中性增强,或自定义 ffmpeg 滤镜链 |
| 🔊 音频处理 | 每处剪辑点 30ms 淡入淡出,消除爆音 |
| 📝 字幕烧录 | 默认两词大写块,完全可定制样式 |
| ✨ 动画生成 | 通过 Manim/Remotion/PIL 生成叠加动画,并行子代理加速 |
| 🧠 会话记忆 | 在 project.md 中持久化,下次会话无缝衔接 |
| 🔍 自我评估 | 在每个剪辑边界检查视觉/音频问题,最多 3 轮修复 |
3. 双层读取系统:LLM 如何"看"视频
video-use 的精髓在于让 LLM 高效"阅读"视频,而非盲目处理每一帧。
Layer 1:音频转录(始终加载)
使用 ElevenLabs Scribe 进行单次调用,获取:
- 词级时间戳(word-level timestamps)
- 说话人分离(speaker diarization)
- 音频事件标记 (
(laughter),(applause),(sigh))
所有素材打包成单个约 12KB 的 takes_packed.md------这就是 LLM 的主要阅读视图。
markdown
## C0103 (duration: 43.0s, 8 phrases)
[002.52-005.36] S0 Ninety percent of what a web agent does is completely wasted.
[006.08-006.74] S0 We fixed this.Layer 2:视觉合成(按需调用)
timeline_view 生成胶片条 + 波形 + 词标签的 PNG,仅在决策点调用:
- 模糊停顿处
- 重拍对比时
- 剪辑点合理性检查
💡 对比:
- 朴素方法:30,000 帧 × 1,500 tokens = 4500 万 tokens 的噪声
- video-use:12KB 文本 + 少量 PNG
这和 browser-use 给 LLM 结构化 DOM 而非截图是同一个思路------用结构化数据代替原始像素。
4. 完整工作流程
转录(Transcribe) → 打包(Pack) → LLM 推理 → EDL → 渲染(Render) → 自我评估(Self-Eval)
↑___________________________|
发现问题则修复重渲染(最多3轮)8 步标准流程
| 步骤 | 动作 | 输出 |
|---|---|---|
| 1️⃣ 清点 | ffprobe 每个源,批量转录,生成 takes_packed.md |
转录文本 |
| 2️⃣ 预扫描 | 标记口误、明显错误 | 问题清单 |
| 3️⃣ 对话 | 描述所见,提问收集需求 | 需求文档 |
| 4️⃣ 提出策略 | 4-8 句话描述剪辑方案 | 策略确认 |
| 5️⃣ 执行 | 生成 EDL,并行动画,分段调色,渲染 | preview.mp4 |
| 6️⃣ 预览 | 生成 720p 快速预览 | preview.mp4 |
| 7️⃣ 自评估 | 在渲染输出上运行 timeline_view 检查剪辑边界 | 质检报告 |
| 8️⃣ 迭代+持久化 | 根据反馈调整,追加到 project.md |
final.mp4 |
目录结构
<videos_dir>/
├── <原始素材文件, untouched>
└── edit/
├── project.md ← 会话记忆,每次追加
├── takes_packed.md ← 短语级转录本(LLM 主阅读视图)
├── edl.json ← 剪辑决策
├── transcripts/ ← 缓存的原始 Scribe JSON
├── animations/slot_<id>/ ← 每个动画的源/渲染/推理
├── clips_graded/ ← 分段提取(含调色+淡入淡出)
├── master.srt ← 输出时间线字幕
├── downloads/ ← yt-dlp 下载
├── verify/ ← 调试图/时间线 PNG
├── preview.mp4
└── final.mp45. 12 条硬性规则(制作正确性)
这些不是风格偏好,而是技术正确性------违反会导致静默失败或损坏输出。
| # | 规则 | 原因 |
|---|---|---|
| 1 | 字幕在滤镜链最后应用 | 否则叠加层会遮挡字幕 |
| 2 | 分段提取 → 无损 -c copy 拼接 |
避免叠加层时的双重编码 |
| 3 | 每段边界 30ms 音频淡入淡出 | 消除剪辑点爆音 |
| 4 | 叠加层使用 setpts=PTS-STARTPTS+T/TB |
将叠加层帧 0 对齐窗口起始 |
| 5 | 主 SRT 使用输出时间线偏移 | 否则拼接后字幕错位 |
| 6 | 绝不在词中间剪辑 | 必须对齐词边界 |
| 7 | 每处剪辑边缘填充 30-200ms | 吸收 Scribe 50-100ms 时间戳漂移 |
| 8 | 仅词级逐字 ASR | SRT/短语模式会丢失亚秒级间隙数据 |
| 9 | 缓存每个源的转录 | 源文件不变则不重新转录 |
| 10 | 多个动画并行子代理 | 绝不顺序执行 |
| 11 | 执行前策略确认 | 未经用户确认不动剪刀 |
| 12 | 所有输出在 <videos_dir>/edit/ |
绝不写入项目目录 |
6. 剪辑工艺详解
音频优先的剪辑逻辑
- 剪辑候选来自: 词边界和静默间隙
- 保留峰值: 笑声、包袱、强调节拍------延伸到反应之后
- 说话人交接: 话语间留气,常用 400-600ms
- 静默间隙是剪辑候选: ≥400ms 通常最干净,150-400ms 需视觉检查,<150ms 不安全
示例剪辑填充(实际发布的 launch video)
- 第一个保留词前 50ms
- 最后一个词后 80ms
- 快节奏更紧,纪录片更松
- 保持在 30-200ms 工作窗口内
调色系统
基于 ASC CDL 模型:out = (in * slope + offset) ** power
| 预设 | 效果 |
|---|---|
| warm_cinematic | 复古/技术感,微妙青橙分离,去饱和 |
| neutral_punch | 最小校正:对比度提升 + 温和 S 曲线 |
| none | 直出,用户未要求时的默认 |
💡 可自定义任意 ffmpeg 滤镜链:
grade.py --filter '<raw ffmpeg>'
字幕系统
| 维度 | 选项 |
|---|---|
| 分块 | 1/2/3 词每行,或整句 |
| 大小写 | UPPERCASE / Title / Natural |
| 位置 | 底部边距(MarginV) |
bold-overlay(短视频/快节奏社交):
- 2 词块,大写
- 标点处断行
- Helvetica 18 粗体,白字黑边
MarginV=35
natural-sentence(叙事/纪录片/教育):
- 4-7 词块,句首大写
- 自然停顿处断行
MarginV=60-80,更大字体
7. 动画系统
video-use 支持三种动画工具,按需选择:
| 工具 | 适用场景 | 特点 |
|---|---|---|
| PIL + PNG 序列 | 简单叠加卡:计数器、打字机文本、条形揭示 | 快速迭代,任意美学 |
| Manim | 正式图表、状态机、方程推导、图形变换 | 数学/技术可视化 |
| Remotion | 字体排版、品牌对齐、Web 风格布局 | React/CSS 驱动 |
动画设计原则
时长规则(情境依赖):
| 类型 | 时长 | 说明 |
|---|---|---|
| 同步旁白解释 | 3s 地板,典型 5-7s,复杂图表 8-14s | 观众需以 1× 速度理解 |
| 节拍同步点缀 | 0.5-2s | 音乐视频/快剪,视觉点缀而非信息 |
| 最终帧保持 | ≥ 1s | 剪辑前必须保持 |
| 旁白叠加 | ≥ narration_length + 1s |
确保内容完整展示 |
缓动函数(绝不用 linear):
python
def ease_out_cubic(t): # 单揭示用------慢着陆
return 1 - (1 - t) ** 3
def ease_in_out_cubic(t): # 连续绘制用
if t < 0.5: return 4 * t ** 3
return 1 - (-2 * t + 2) ** 3 / 2并行生成:
每个动画是一个独立子代理,通过 Agent 工具并行生成------总耗时 ≈ 最慢的那个。
示例调色板(launch video 风格)
python
background = (10, 10, 10) # 近黑
accent = (255, 90, 0) # 橙色 #FF5A00
labels = (110, 110, 110) # 暗灰
font = "/System/Library/Fonts/Menlo.ttc" # index 1
# ≤2 种强调色,~40% 留白,最小装饰
# 结果:终端/复古技术感💡 这只是示例。如果品牌是温暖衬线体,就用那个;如果是多彩活泼,就用那个。无默认假设。
8. 安装与使用
快速安装(一键复制给 Agent)
text
Set up https://github.com/browser-use/video-use for me.
Read install.md first to install this repo, wire up ffmpeg, register the skill
with whichever agent you're running under, and set up the ElevenLabs API key ---
ask me to paste it when you need it. Then read SKILL.md for daily usage, and
always read helpers/ because that's where the editing scripts live. After install,
don't transcribe anything on your own --- just tell me it's ready and wait for me
to drop footage into a folder.手动安装
bash
# 1. 克隆并注册到 Agent 技能目录
git clone https://github.com/browser-use/video-use ~/Developer/video-use
ln -sfn ~/Developer/video-use ~/.claude/skills/video-use # Claude Code
# ln -sfn ~/Developer/video-use ~/.codex/skills/video-use # Codex
# 2. 安装依赖
cd ~/Developer/video-use
uv sync # 或 pip install -e .
brew install ffmpeg # 必需
brew install yt-dlp # 可选,下载在线源
# 3. 配置 ElevenLabs API key
cp .env.example .env
# 编辑 .env: ELEVENLABS_API_KEY=your_key_here日常使用
bash
cd /path/to/your/videos
claude # 或 codex, hermes, openclaw 等在会话中:
> edit these into a launch videoAgent 会:
- 清点素材
- 提出剪辑策略
- 等待你确认
- 执行剪辑、调色、动画、字幕
- 自我评估
- 输出
edit/final.mp4
9. 适用场景与优缺点
典型使用场景
| 场景 | 说明 |
|---|---|
| 🚀 产品发布视频 | 多段拍摄素材,选出最佳 take,剪辑成 launch video |
| 🎓 教程/知识分享 | 去除口误和停顿,添加字幕和代码动画 |
| 🎤 访谈/播客 | 多机位/多 take 选择,说话人分离,节奏优化 |
| ✈️ 旅行/Vlog | 素材整理,高光片段提取,添加转场和字幕 |
| 🎵 音乐/表演 | 节拍同步剪辑,视觉点缀动画 |
| 📊 技术演示 | Manim 动画 + 代码高亮 + 字幕 |
客观评价
| 维度 | ✅ 优势 | ⚠️ 注意 |
|---|---|---|
| 交互方式 | 对话式剪辑,自然语言指挥,无需学习复杂软件 | 需要 ElevenLabs API key(有成本) |
| 剪辑质量 | 专业级工艺:词级精度、音频淡入淡出、自我验证 | 不适合需要复杂时间轴操作的项目 |
| 动画能力 | Manim/Remotion/PIL 三选一,并行生成,缓动专业 | 动画风格需要用户明确指导或确认 |
| 调色系统 | ffmpeg 滤镜链完全可控,可自定义任意风格 | 无预设 LUT 库,需要懂基础调色原理 |
| 字幕系统 | 样式完全可定制,硬性规则确保正确性 | 中文支持需验证(当前示例为英文) |
| 工作流 | 8 步标准流程,project.md 持久化,可迭代 | 每次会话需要重新启动 Agent |
| 生态兼容 | 支持 Claude Code、Codex、Hermes、Openclaw | 需要 Agent 支持 skills 目录或系统提示导入 |
| 成本 | 开源免费,仅 ElevenLabs Scribe 按量计费 | 长视频转录成本需预估 |
不适合的场景
- ❌ 需要复杂多轨道混音的音乐制作
- ❌ 需要精细关键帧动画的特效合成
- ❌ 实时直播/流媒体剪辑
- ❌ 完全不懂视频基础概念的用户(需要理解剪辑、调色、字幕等基本概念)
10. 总结
video-use 代表了 AI 视频编辑的一个新方向:不是让 AI 替代剪辑师,而是让 AI 成为剪辑师的智能助手。
它的核心创新在于:
- 双层读取系统------让 LLM 高效"阅读"视频而非盲目处理像素
- 12 条硬性规则------确保技术正确性,避免静默失败
- 对话驱动工作流------策略确认 → 执行 → 自评估 → 迭代
- 专业级工艺------词级剪辑精度、30ms 音频淡入淡出、ASC CDL 调色
对于需要批量处理访谈、教程、产品视频 的创作者来说,这是一个能显著提效的工具。它不是 Premiere Pro 的替代品,而是和 Premiere Pro 互补的 AI 预处理层------让 AI 完成粗剪、调色、字幕的 dirty work,人类专注于创意决策。
推荐指数:⭐⭐⭐⭐⭐(对于目标用户群)
适合人群:
- 需要批量剪辑访谈/教程/产品视频的内容创作者
- 懂基础视频概念、愿意和 AI 协作的技术型创作者
- 已经在使用 Claude Code/Codex 等 Agent 工具的开发者
不适合人群:
- 完全不懂视频剪辑的小白
- 需要复杂特效和精细时间轴控制的专业后期
🔥 项目地址:https://github.com/browser-use/video-use
🏠 团队主页:https://github.com/browser-use(browser-use 团队)
📄 SKILL.md:https://github.com/browser-use/video-use/blob/main/SKILL.md
📄 install.md:https://github.com/browser-use/video-use/blob/main/install.md
🎙️ ElevenLabs:https://elevenlabs.io/app/settings/api-keys
标签:#AI视频剪辑 #browser-use #ClaudeCode #视频编辑 #对话式AI #Manim #Remotion #video-use