布隆过滤器是什么?
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用来判断:一个元素一定不存在/可能存在,它不能100%确定元素存在,但可以100%确定元素不存在。
核心原理
- 初始化一个全0的比特数组(bit array)
- 插入元素:
- 用K个不同的哈希函数计算元素的K个哈希值
- 把比特数组对应下标的位置设为1
- 查询元素:
- 同样用K个哈希函数计算下标
- 如果任意一个下标是0,则可判断,这个元素一定不存在
- 如果全部是1,则只能判断,这个元素可能存在
两大特性
布隆过滤器判断不存在的元素,则100%不存在;布隆过滤器判断存在的元素,则是可能存在的,假阳性,也可能是误判的,因为哈希冲突。
不支持的操作
- 不支持删除元素,多个元素可能共享同一个比特位
- 不支持动态扩容,扩容则需要重建过滤器
关键参数
实现布隆过滤器必须确定三个参数:
- m:比特数组长度,越大误判率越低
- k:哈希函数个数,太少误判高,太多速度慢
- n:预计存储的元素数量
最优公式
- 最优哈系数:k = ln2 * m / n,约等于,0.7 * m / n
- 误判率公式:p = (1 - e^(-kn/m)) ^ k
经验值
- 想误判率 < 0.1% -> 每个元素分配10~14bit
- 想误判率 < 0.01% -> 每个元素分配14~18bit
优缺点
优点
- 极省内存:100万元素只需要约1.2MB空间
- 速度极快:插入/查询都是O(k),k很小(3~10)
- 无元素存储,只存比特位,隐私性好
缺点
- 有假阳性误判
- 不支持删除
- 元素数量超过预估后,误判率会飙升
使用场景
- 缓存穿透防护,判断key是否存在,不存在直接返回
- 爬虫URL去重
- 黑名单/白名单快速校验
- 数据库查询前预过滤
- 大数据去重
总结
【程序员都必须会的技术,面试必备【布隆过滤器详解】,Redis缓存穿透解决方案】https://www.bilibili.com/video/BV1zK4y1h7pA?vd_source=51bf4e3845fa5f000f98df6975f93695
布隆过滤器是为了解决缓存穿透的问题,本质是一个二进制数组,数组元素都是由0与1组成的,分别代表存在与不存在的关系,
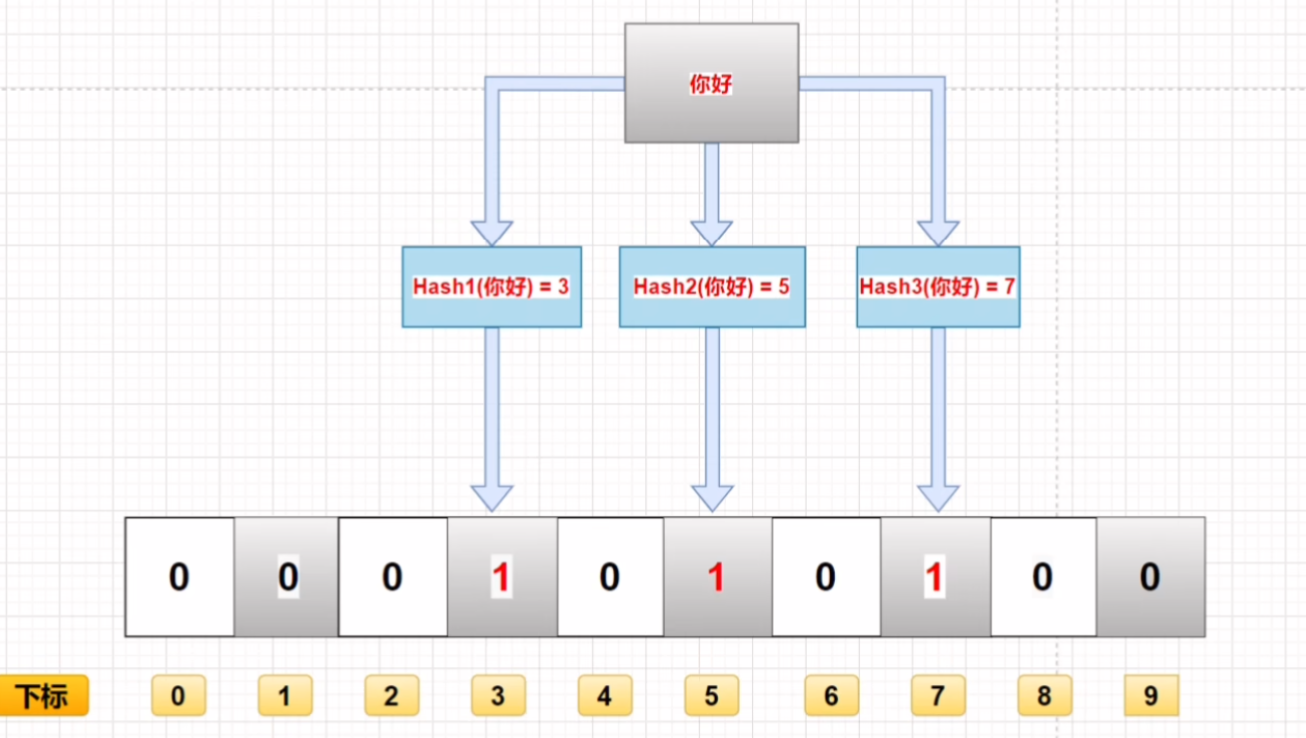
如图,假设我们计算出最优比特数组长度为3,则一个元素"你好"的哈希值就分为了三个,Hash1、Hash2、Hash3,值分别为3 5 7,并映射到数组中的对应的位置上。
查询同理,我们需要根据元素去计算得到这个数据的哈希值,找到对应的位置,从而判断数据是否存在。
布隆过滤器元素的删除很难实现,因为不同的元素可能计算出的部分哈希值是相同的,这就导致这个位置上的1分别证明着不同的数据是存在的,如果单方面删除一个元素而导致这个位置上的数字变为0,这样就导致了另一个元素也变成了不存在。
golang实现布隆过滤器
包的命名与库的导入
package bloom
import (
"math"
"math/big"
"github.com/spaolacci/murmur3"
)自定义实现布隆过滤器的结构体
// SBloomFilter
// self-BloomFilter 自定义布隆过滤器结构体
type SBloomFilter struct {
bitArray *big.Int // 比特数组
m uint // 数组大小
k uint // 哈希函数数量
}其中,big.Int类型,用来存放比特位,是一个每个格子只能写0或1的数组
返回一个结构体实例,暴露结构体方法,实现面向接口编程
// NewBloomFilter 创建布隆过滤器实例
// @param n 预计存入的元素数量
// @param p 期望的错误率
// @return *SBloomFilter
func NewBloomFilter(n uint, p float64) *SBloomFilter {
// 计算最优数组长度m
m := getOptimalBitArrayLength(n, p)
// 计算最优哈希函数数量k
k := getOptimalHashFunction(n, m)
return &SBloomFilter{
bitArray: big.NewInt(0),
m: m,
k: k,
}
}其中,n为预计存入的元素数量,比如预见向布隆过滤器中存入100万个短链接信息;p为期望的错误率,比如期望错误小于0.1%或0.01%
计算最优的比特数组长度,根据公式m = -n * ln(p) / (ln(2) * ln(2))
// getOptimalBitArrayLength 计算最优数组长度m
// @param n 预计存入的元素数量
// @param p 期望的错误率
// @return uint 最优数组长度m
// 依据公式: m = -n * ln(p) / (ln(2) * ln(2))
func getOptimalBitArrayLength(n uint, p float64) uint {
m := uint(-float64(n) * math.Log(p) / (math.Log(2) * math.Log(2)))
if m == 0 {
m = 1
}
return m
}计算最优的哈希函数数量,根据公式k = m * ln(2) / n
// getOptimalHashFunction 计算最优哈希函数数量k
// @param n 预计存入的元素数量
// @param m 最优数组长度m
// @return uint 最优哈希函数数量k
// 依据公式: k = m * ln(2) / n
func getOptimalHashFunction(n, m uint) uint {
k := uint(float64(m) * math.Log(2) / float64(n))
if k == 0 {
k = 1
}
return k
}计算一个元素对应的多个哈希位置
// getHashPositions 计算元素的k个哈希下标
// @param data 元素数据
// @return []uint 元素的k个哈希下标
func (sbf *SBloomFilter) getHashPositions(data []byte) []uint {
var positions []uint
// 使用murmur3双哈希生成k个独立的哈希值
hash1, hash2 := murmur3.Sum128(data)
for i := uint(0); i < sbf.k; i++ {
// 组合哈希 生成第i个哈希值
combined := hash1 + uint64(i)*hash2
// 取模得到比特位下标
position := uint(combined % uint64(sbf.m))
positions = append(positions, position)
}
return positions
}因为,一个元素会被映射到k个不同的bit位置上,涉及到布隆过滤器规则,添加元素时,把k个位置全部设为1,查询元素时,检查k个位置是否都为1,如果全部是1,那只能说明这个元素是可能存在的,但是如果有一个位置为0,则说明这个元素是一定不存在的。
双哈希法
核心代码行:hash1, hash2 := murmur3.Sum128(data) 生成两个128位哈希值,即双哈希法
由于一个数据对应k个哈希值,这样我们就需要计算出k个不同的下标位置,就是写k个不同的哈希算法。但是缺点显而易见,需要写不同的计算哈希值的方法,代码量大,难以维护
因此双哈希值算法,算是一个比较简单、偷懒的算法,通过murmur3.Sum128方法计算出两个不同的哈希值,然后通过循环递增i,每次通过公式hash1 + uint64(i) * hash2逐个获得哈希值,当sbf.k为3时,hash1与hash2分别为100 200时,则得到的哈希值为100 300 500,取模得到比特数组下标,就是将哈希值映射到数组的下标上,与数据结构中的哈希表一样。
将元素添加到布隆过滤器中
// AddBloomFilterElem 添加元素到布隆过滤器
// @param data 元素数据
func (sbf *SBloomFilter) AddBloomFilterElem(data []byte) {
position := sbf.getHashPositions(data)
for _, pos := range position {
sbf.bitArray.SetBit(sbf.bitArray, int(pos), 1)
}
}添加到结构体中的字段中。
判断元素是否存在
// IsExistElem 判断元素是否存在
// @param data 元素数据
// @return bool 元素是否存在
// false代表元素绝对不存在
// true代表元素可能存在
func (sbf *SBloomFilter) IsExistElem(data []byte) bool {
positions := sbf.getHashPositions(data)
for _, pos := range positions {
if sbf.bitArray.Bit(int(pos)) == 0 {
return false
}
}
return true
}原理就是,计算得到这个元素映射到哈希表中的位置,判断这些位置是否都是0
整体代码 部分优化
package bloom
import (
"fmt"
"math"
"math/big"
"sync"
"github.com/spaolacci/murmur3"
)
// SBloomFilter
// self-BloomFilter 自定义布隆过滤器结构体
type SBloomFilter struct {
bitArray *big.Int // 比特数组
m uint // 数组大小
k uint // 哈希函数数量
mu sync.RWMutex // 读写锁
}
// NewBloomFilter 创建布隆过滤器实例
// @param n 预计存入的元素数量
// @param p 期望的错误率
// @return *SBloomFilter
func NewBloomFilter(n uint, p float64) (*SBloomFilter, error) {
if n == 0 || p <= 0 || p >= 1 {
return nil, fmt.Errorf("布隆过滤器参数异常 初始化实例失败")
}
// 计算最优数组长度m
m := getOptimalBitArrayLength(n, p)
// 计算最优哈希函数数量k
k := getOptimalHashFunction(n, m)
return &SBloomFilter{
bitArray: big.NewInt(0),
m: m,
k: k,
}, nil
}
// getOptimalBitArrayLength 计算最优数组长度m
// @param n 预计存入的元素数量
// @param p 期望的错误率
// @return uint 最优数组长度m
// 依据公式: m = -n * ln(p) / (ln(2) * ln(2))
func getOptimalBitArrayLength(n uint, p float64) uint {
m := math.Ceil(-float64(n)*math.Log(p) / (math.Ln2 * math.Ln2)) // 向上取整 避免低配位图
if m == 0 {
m = 1
}
return uint(m)
}
// getOptimalHashFunction 计算最优哈希函数数量k
// @param n 预计存入的元素数量
// @param m 最优数组长度m
// @return uint 最优哈希函数数量k
// 依据公式: k = m * ln(2) / n
func getOptimalHashFunction(n, m uint) uint {
// 具体与math.Ceil需要进行比较一下
k := math.Round(float64(m) * math.Ln2 / float64(n)) // 四舍五入 避免哈希函数数量为0
if k < 1 {
k = 1
}
return uint(k)
}
// getHashPositions 计算元素的i个哈希下标
// @param data 元素数据
// @return []uint 元素的i个哈希下标
func (sbf *SBloomFilter) getHashPositions(data []byte) []uint {
positions := make([]uint, 0, sbf.k) // 预分配容量 避免重复扩容
// 使用murmur3双哈希生成2个独立的哈希值
hash1, hash2 := murmur3.Sum128(data)
for i := uint(0); i < sbf.k; i++ {
// 后续自定义哈希值生成函数时 可以增大扰动因子 i -> i * i 让哈希值分布更均匀 避免哈希冲突增加
combined := hash1 + uint64(i)*hash2
// 取模得到比特位下标
position := uint(combined % uint64(sbf.m))
positions = append(positions, position)
}
return positions
}
// AddBloomFilterElem 添加元素到布隆过滤器
// @param data 元素数据
func (sbf *SBloomFilter) AddBloomFilterElem(data []byte) {
sbf.mu.Lock() // 加写锁 防止并发修改bitArray
defer sbf.mu.Unlock()
if len(data) == 0 { // 空数据保护
return
}
// 后续拓展方向 记录每个数据的插入次数
position := sbf.getHashPositions(data)
for _, pos := range position {
sbf.bitArray.SetBit(sbf.bitArray, int(pos), 1)
}
}
// IsExistElem 判断元素是否存在
// @param data 元素数据
// @return bool 元素是否存在
// false代表元素绝对不存在
// true代表元素可能存在
func (sbf *SBloomFilter) IsExistElem(data []byte) bool {
sbf.mu.RLock() // 加读锁 防止并发修改bitArray
defer sbf.mu.RUnlock()
if len(data) == 0 { // 空数据保护
return false
}
positions := sbf.getHashPositions(data)
for _, pos := range positions {
if sbf.bitArray.Bit(int(pos)) == 0 {
return false
}
}
return true
}