如果说 GMP 是工厂的调度中心,那内存管理就是仓库管理系统:怎么申请货架(分配)、货物该放临时货架还是长期仓库(逃逸)、怎么防止仓库爆仓(泄漏),都是今天的内容。
一、Go 语言是如何分配内存的?
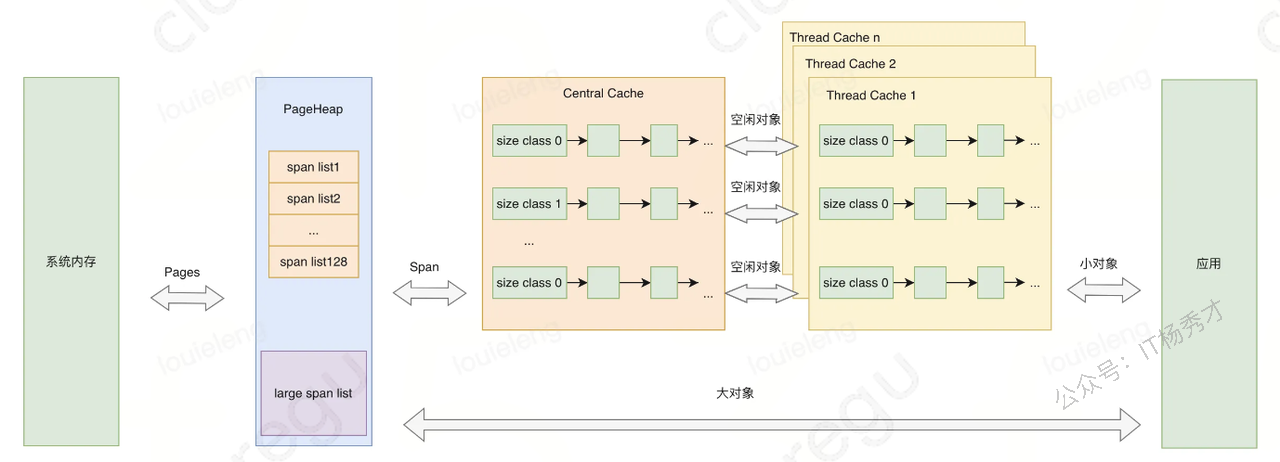
1.1 核心架构:TCMalloc 模型
Go 的内存分配器脱胎于 Google 的 TCMalloc(Thread-Caching Malloc) ,采用三级缓存架构:
G(工人)申请内存
│
▼
┌─────────────┐ ← 第一级:mcache(P 的私有仓库)
│ mcache │ 每个 P 一个,无锁,极速
│ (本地缓存) │
└──────┬──────┘
│ 没有合适规格
▼
┌─────────────┐ ← 第二级:mcentral(中央仓库)
│ mcentral │ 按 size class 分类,需要加锁
│ (全局缓存) │
└──────┬──────┘
│ 也没有
▼
┌─────────────┐ ← 第三级:mheap(总仓库)
│ mheap │ 向 OS 申请大块内存,再切分
│ (堆内存) │
└──────┬──────┘
│ 不够
▼
操作系统(mmap)1.2:Span、Size Class、Slot 到底是什么关系?
这三个概念是 Go 内存分配的**"物理单位"** ,很多人混淆是因为它们在不同层级出现。我用**"木板切割"**的比喻给你彻底拆开。
| 概念 | 本质 | 比喻 | 谁管理 |
|---|---|---|---|
| Span | 连续的一页或多页内存(8KB/页),是向操作系统申请内存的最小物理单位 | 一块完整的大木板(比如 32KB) | mheap |
| Size Class | 对象大小的规格/模板(8B, 16B, 24B...32KB,共 67 种),每个 size class 对应一种切分 Span 的方式。 | 切割模板(比如"切成 16B 的小块") | 全局预定义 |
| Slot | Span 被切割后形成的等大小格子,分配给具体对象使用 | 木板上的一个小格子(16B) | mspan |
1.2 它们的关系(从大到小)
操作系统给 Go 一块地(mmap)
│
▼
mheap 把地切成大木板(Span)
│
▼
Span 按照 Size Class 模板,切成小格子(Slot)
│
▼
对象申请内存时,拿走一个小格子(Slot)具体例子:
假设你要分配一个 24 字节的对象:
-
mheap 向 OS 申请了一块 8KB(1页) 的内存,这就是一个 Span。
-
这个 Span 的 Size Class 是 24B(Go 内部编号对应 24B 的规格)。
-
这块 8KB 的 Span 被切成
8192 / 24 ≈ 341个 Slot,每个 Slot 24 字节。 -
你申请 24B,Go 给你一个空闲的 Slot。
一个 Span(8KB = 8192 字节)
├──────────┬──────────┬──────────┬──────────┬───────┐
│ Slot 0 │ Slot 1 │ Slot 2 │ Slot 3 │ ... │
│ 24B │ 24B │ 24B │ 24B │ │
│ [已分配] │ [空闲] │ [已分配] │ [空闲] │ │
└──────────┴──────────┴──────────┴──────────┴───────┘
↑
你的对象占用了 Slot 0关键理解:
-
Span 是物理容器,它本身有大小(1页、2页、4页...)。
-
Size Class 是分类标准,决定这个 Span 被切成多大块。
-
Slot 是分配单元,对象最终拿到的是 Slot。
1.3 三级分配详解
第一级:mcache(P 的私有仓库)
每个 P 都有一个 mcache,里面有一个数组 alloc[numSpanClasses],每个元素指向一个 Span(这个 Span 已经被切成 Slot 了)。
type mcache struct {
tiny uintptr // 微小对象分配器(<16B 的小对象)
tinyoffset uintptr
alloc [numSpanClasses]*mspan // 每个 size class 一个 span
}分配过程:
-
你需要 24B → 对应 size class 编号
c。 -
看
mcache.alloc[c]指向的 Span 有没有空闲 Slot。 -
有?直接拿走一个 Slot,无锁,极快。
-
这是 99% 的情况。
-
没有?进入第二级。
第二级:mcentral(中央仓库)
每个 size class 都有一个全局的 mcentral:
type mcentral struct {
lock mutex
nonempty mSpanList // 还有空闲 slot 的 span 链表
empty mSpanList // 已满的 span 链表
}分配过程:
-
mcache 向 mcentral 申请一个 Span。
-
mcentral 从
nonempty链表拿一个 Span 给 mcache。 -
mcache 拿到后,从 Span 里拿一个 Slot 给你。
-
如果
nonempty空了,进入第三级。 -
注意: 这里需要加锁,但因为 mcache 命中率高,实际走到这里的次数很少。
第三级:mheap(总仓库)
type mheap struct {
lock mutex
free mTreap // 空闲 span 集合(按大小组织的树)
}分配过程:
-
mcentral 向 mheap 申请一个 Span。
-
mheap 先在
free里找有没有合适大小的空闲 Span。 -
没有?通过
mmap向操作系统申请新内存(通常一次申请 64KB 或更大),切成 Span,给 mcentral。
为什么分 size class?为了减少内存碎片。你要 17B 的对象,Go 不会给你精确 17B,而是给你 24B 的 slot(向上取整到最近的 size class)。虽然有点浪费,但换来的是极快的分配速度 和极低的碎片率。
1.4 对象大小的三条分流路径
Go 根据对象大小,走完全不同的分配路径:
| 对象大小 | 类型 | 分配路径 |
|---|---|---|
| 0~16B(且不包含指针) | Tiny 对象 | mcache.tiny 分配器,多个 tiny 对象挤在一个 slot 里 |
| 16B ~ 32KB | 小对象 | 按 size class 走 mcache → mcentral → mheap |
| > 32KB | 大对象 | 直接找 mheap 分配,不经过 mcache/mcentral |
Tiny 对象优化: 对于小于 16B 且不含指针的对象(比如小整数),Go 不会给它们各分配一个 slot,而是把它们塞进同一个 16B slot里,进一步减少碎片。
二、Go 的内存逃逸是什么?
2.1 一句话定义
内存逃逸(Escape Analysis) 是 Go 编译器在编译阶段做的一项分析:它判断一个变量应该分配在栈 上还是堆 上。如果编译器发现变量在函数返回后仍然可能被访问 ,就把它放到堆 上,这就叫**"逃逸到堆"**。
2.2 为什么叫"逃逸"?
栈是函数私有的临时空间,函数返回后栈帧就被回收了。如果变量本该在栈上,但编译器发现它**"逃"出了函数的生命周期** ,只能把它放到堆(全局仓库)上。
2.3 什么情况下会发生逃逸?
① 返回局部变量的指针
func foo() *int {
a := 10
return &a // a 逃逸到堆!因为调用者还要通过指针访问 a
}编译器分析:a 的地址被返回了,函数结束后调用者还能用,所以 a 必须在堆上分配。
② 闭包引用外部变量
func foo() func() int {
a := 10
return func() int {
return a // a 被闭包捕获,逃逸到堆
}
}③ Slice 底层数组或 Map 的桶
func foo() []int {
s := []int{1, 2, 3} // 底层数组逃逸到堆
return s
}Slice 的头部(指针+len+cap) 可能在栈上,但底层数组如果生命周期超出函数,就会逃逸。
④ 向 Channel 发送指针
func foo(ch chan *int) {
a := 10
ch <- &a // a 的地址要传给其他 goroutine,逃逸!
}⑤ 接口(interface)类型
func foo() interface{} {
a := 10
return a // 接口内部会装箱(boxing),a 逃逸到堆
}接口的底层结构
Go 的接口不是"魔法黑盒",它在底层是一个结构体 。以空接口 interface{} 为例:
type eface struct {
_type *_type // 指向类型元数据的指针
data unsafe.Pointer // 指向具体数据的指针
}非空接口是:
type iface struct {
tab *itab // 接口表(类型+方法集)
data unsafe.Pointer // 指向具体数据的指针
}关键发现:接口内部有一个 data 指针!
为什么值类型赋给接口会逃逸?
当你写:
func foo() interface{} {
a := 10 // a 是局部变量,本来在栈上
return a // 返回 interface{}
}编译器看到的不是"返回 10",而是:
-
创建一个
eface结构体(包含_type和data)。 -
data是一个指针,必须指向某个内存地址。 -
如果
a在栈上,data指向栈地址。但函数返回后栈帧销毁,data变成悬垂指针。 -
为了安全,编译器必须把
a拷贝到堆上 ,然后让data指向堆地址。
这就是装箱(Boxing):值被装进箱子里(堆分配),接口拿着箱子的地址。
逃逸的触发条件
| 代码 | 是否逃逸 | 原因 |
|---|---|---|
var i interface{} = 10 |
是 | 10 被装箱到堆 |
func f(x interface{}) { ... } 调用 f(10) |
是 | 10 被装箱 |
var i fmt.Stringer = myStruct{} |
是 | myStruct 被装箱 |
优化建议: 如果函数参数是 interface{},传入值类型必然逃逸。如果性能敏感,考虑用泛型或具体类型。
⑥ 不确定大小的内存
func foo(n int) []int {
s := make([]int, n) // n 不是编译期常量,无法确定大小,逃逸到堆
return s
}如果 make 的大小是编译期常量(如 make([]int, 10)),可能在栈上;如果是变量,一定逃逸到堆。
⑦ 反射(reflect)
使用反射的变量通常都会逃逸,因为编译器无法追踪其生命周期。
2.4 逃逸的影响
| 影响 | 说明 |
|---|---|
| 堆分配开销 | 栈分配只需移动 SP 指针(一条指令),堆分配需要走 mcache→mcentral→mheap 三级路径,还要加锁 |
| GC 压力 | 堆上的对象需要 GC 跟踪和回收。逃逸越多,堆越大,GC 频率越高,STW 越长 |
| 缓存命中率下降 | 栈内存通常在 CPU L1/L2 缓存里,堆内存访问更随机,缓存命中率低 |
| 内存碎片 | 频繁堆分配导致 span 碎片化 |
2.5 如何查看逃逸分析结果?
go build -gcflags="-m" main.go编译器会输出每个变量的逃逸情况:
./main.go:5:9: &a escapes to heap
./main.go:5:2: moved to heap: a三、Channel 是分配在栈上还是堆上?
3.1 结论
hchan 结构体本身(Channel 的实体)分配在堆上。但指向 Channel 的指针变量可能在栈上。
3.2 为什么 hchan 必须在堆上?
当你写 ch := make(chan int) 时,编译器会把这个 make 翻译成 runtime.makechan,而 makechan 函数内部会调用 new(hchan),显式在堆上分配。
原因有三:
① 生命周期不确定
Channel 通常用于跨 goroutine 通信。创建 Channel 的函数可能已经返回了,但 Channel 还在被其他 goroutine 使用。如果放在栈上,函数返回后栈帧销毁,Channel 就没了。
② 编译器无法确定作用域
编译器做逃逸分析时,看到 make(chan),知道这个对象会被多个执行流共享(发送方和接收方可能完全不同),无法保证只在当前栈帧使用,所以直接标记为逃逸。
③ Runtime 设计如此
runtime.makechan 的源码(runtime/chan.go):
func makechan(t *chantype, size int) *hchan {
// ...
var c *hchan
c = (*hchan)(mallocgc(hchanSize, nil, true)) // 显式堆分配!
// ...
return c
}注意返回值是 *hchan(指针),而且这个指针被返回给调用方,调用方可能继续传递。这本身就触发了逃逸。
3.3 那 ch 这个变量在哪?
func foo() {
ch := make(chan int) // ch 是局部变量(指针),在栈上
// 但 ch 指向的 hchan 结构体在堆上
}-
ch(指针变量):在foo的栈帧上,占 8 字节(64位系统)。 -
ch指向的hchan:在堆上,占几十到上百字节(含缓冲区)。
四、Go 语言的内存泄漏是什么?
4.1 一句话定义
内存泄漏 = 程序中已分配的内存,不再被实际需要,但仍然被 GC 标记为"可达",导致无法被回收,内存持续增长。
4.2 Go 有 GC,为什么还会泄漏?
Go 的 GC 是标记-清除(Mark-Sweep) 算法,它只回收不可达(unreachable) 的对象。如果一个对象理论上还能被访问到(有引用链连着),GC 就不会动它,哪怕你的业务逻辑其实已经不需要它了。
4.3 什么情况会发生内存泄漏?
① Goroutine 泄漏(最常见)
Goroutine 阻塞在某个 Channel 或锁上,永远无法退出,它占用的栈内存和引用的对象永远无法释放。
// 泄漏示例:发送方无接收方
func leak() {
ch := make(chan int)
go func() {
ch <- 1 // 永久阻塞!
}()
}② 全局 Map / Cache 无限增长
var cache = make(map[string][]byte)
func add(key string, data []byte) {
cache[key] = data // 只加不减,内存只涨不跌
}③ time.After 的误用
for {
select {
case <-time.After(time.Minute): // 每次循环创建新 Timer,旧 Timer 不释放
// do something
}
}正确做法是用 time.NewTimer 复用。
time.After 为什么泄漏?
time.After(d) 的源码本质是:
func After(d Duration) <-chan Time {
return NewTimer(d).C
}每次调用 time.After 都会创建一个新的 Timer 对象。
问题出在 select 的循环里:
for {
select {
case <-ch:
// 处理业务逻辑
case <-time.After(time.Minute): // 每次循环都创建新 Timer!
// 超时处理
}
}泄漏机制:
-
假设循环跑了 10000 次,每次
ch都立即有数据(不走超时分支)。 -
每次循环都创建了 1 个 Timer,共 10000 个 Timer。
-
这些 Timer 被 Go 的**全局定时器堆(timer heap)**管理。
-
即使
select走了ch分支,time.After创建的 Timer 还在堆里,直到 1 分钟后才会被触发和回收。 -
在这 1 分钟内,内存里有大量无用的 Timer 对象,且数量随循环次数线性增长 → 内存泄漏。
time.NewTimer 复用为什么不会泄漏?
timer := time.NewTimer(time.Minute)
defer timer.Stop()
for {
timer.Reset(time.Minute) // 复用同一个 Timer
select {
case <-ch:
// 处理业务
case <-timer.C:
// 超时
}
}原因:
-
只创建了 1 个 Timer 对象。
-
Reset只是重置这个 Timer 的到期时间,不会创建新对象。 -
无论循环多少次,定时器堆里只有 1 个 Timer → 不会泄漏。
④ 闭包引用大对象
func process() {
bigData := make([]byte, 1<<20) // 1MB
go func() {
// 只使用了 bigData 的前 10 字节
_ = bigData[0]
// 但闭包引用了整个 bigData,1MB 无法释放!
}()
}⑤ Channel 的缓冲区残留
向有缓冲 Channel 发送大量数据后,如果没有接收方消费,数据一直留在缓冲区里。
⑥ 循环引用 + Finalizer
如果两个对象互相引用,且都设置了 runtime.SetFinalizer,GC 可能无法正确回收(虽然 Go 1.4+ 后循环引用一般能被回收,但 Finalizer 会延迟回收)。
Finalizer 是什么?
runtime.SetFinalizer(obj, func) 给对象设置一个"临终遗言":当 GC 发现 obj 不可达时,不立即回收,而是先执行你设置的函数,下一轮 GC 再真正回收。
type Node struct {
next *Node
data []byte
}
func main() {
a := &Node{data: make([]byte, 1<<20)}
b := &Node{data: make([]byte, 1<<20)}
a.next = b
b.next = a // 循环引用!
runtime.SetFinalizer(a, func(n *Node) {
fmt.Println("a is dying")
})
}为什么会出问题?
-
循环引用本身不是问题 :Go 从 1.8 开始使用混合写屏障(Hybrid Write Barrier),能正确回收循环引用的对象。
-
Finalizer 会延迟回收 :如果
a有 Finalizer,GC 第一轮发现a和b不可达,但a有 Finalizer,于是:-
把
a标记为"待执行 Finalizer"。 -
a和b在这一轮不会被回收 (因为a还要活着执行 Finalizer)。 -
由于
a还活着,b通过a.next仍然可达,所以b也不会被回收。 -
下一轮 GC 执行
a的 Finalizer,再下一轮 GC 才能真正回收a和b。
-
-
结果 :对象被延迟了 2 轮 GC 才回收。如果对象很大或 GC 压力大,这会造成内存峰值 和回收延迟。
五、如何定位和优化内存泄漏?
5.1 定位工具
① 逃逸分析(编译期)
go build -gcflags="-m -l" main.go查看哪些变量逃逸到了堆上,优化不必要的堆分配。
② Heap Profile(运行时)
import _ "net/http/pprof"
go func() {
http.ListenAndServe("localhost:6060", nil)
}()然后访问:
go tool pprof http://localhost:6060/debug/pprof/heap常用命令:
# 查看内存分配最多的位置
(pprof) top
# 查看分配火焰图
(pprof) web
# 对比两个时间点的内存
go tool pprof -base base.prof current.prof③ Goroutine Profile
curl http://localhost:6060/debug/pprof/goroutine?debug=1查看哪些 goroutine 阻塞在哪里,定位 goroutine 泄漏。
④ Trace 工具
go test -trace=trace.out
go tool trace trace.out可视化查看 GC 频率、goroutine 状态、阻塞原因。
5.2 优化策略
| 问题 | 优化方案 |
|---|---|
| 频繁小对象分配 | 使用 sync.Pool 复用对象 |
| 大量字符串拼接 | 用 strings.Builder 替代 + |
| Slice/Map 预分配 | make([]int, 0, 1000) 避免多次扩容 |
| Goroutine 泄漏 | 使用 context.WithCancel 或 done channel 控制生命周期 |
| 全局缓存无限增长 | 使用 LRU 缓存,限制容量,定期清理 |
| 不必要的逃逸 | 避免返回局部变量指针,减少闭包捕获,用值传递替代指针传递 |
| 大对象频繁分配 | 对象池化,或复用缓冲区 |
5.3 sync.Pool 示例
var bufPool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
func process() {
buf := bufPool.Get().([]byte) // 从池里拿
defer bufPool.Put(buf) // 用完放回
// 使用 buf...
}sync.Pool 是 GC 友好的:GC 时会清空 Pool 里的对象,不会阻止回收。
思考题 1:strings.Builder 为什么比 + 拼接字符串快?它的底层是怎么分配内存的?
① + 拼接的问题
s := "a" + "b" + "c" + "d"每次 + 都会:
-
计算新字符串长度。
-
在堆上分配新内存。
-
把左右两边的字符串拷贝到新内存。
-
返回新字符串。
拼接 n 个字符串,时间复杂度是 O(n²),因为每次都要拷贝前面所有内容。
② strings.Builder 的原理
strings.Builder 底层就是一个 []byte:
type Builder struct {
buf []byte // 底层字节切片
}当你调用 WriteString 时:
func (b *Builder) WriteString(s string) (int, error) {
b.buf = append(b.buf, s...) // 向 buf 追加
return len(s), nil
}优势:
-
append会预分配容量(按 2 倍或 1.25 倍扩容)。 -
大部分追加操作只是往已有内存里写数据,不需要频繁申请新内存。
-
最后调用
String()时,直接把[]byte转成string(共享底层数组,不拷贝)。 -
时间复杂度接近 O(n)。
底层内存分配:
-
Builder对象本身可能在栈上(如果局部变量)。 -
但
buf []byte如果容量大或逃逸,底层数组在堆上。即便如此,它也只分配一次或少数几次,而不是每次拼接都分配。
思考题 2:如果你发现程序的内存一直涨,但 pprof heap 显示堆内存稳定,可能是什么原因?
答案:内存泄漏不在堆上,而在"堆外"或"运行时结构"。
可能原因 1:Goroutine 泄漏(最常见)
-
pprof heap只统计堆对象。 -
Goroutine 的栈内存不在 heap profile 里(虽然栈也在堆区,但 pprof heap 主要追踪显式分配)。
-
如果 goroutine 无限增长,每个 goroutine 占 2KB~几MB 栈空间,总内存会涨。
可能原因 2:mheap 向 OS 申请的内存未归还
-
Go 的内存分配器从 OS 申请内存后,不会立即归还给 OS(即使对象被 GC 了)。
-
这些内存被 mheap 的
free列表缓存,供后续复用。 -
pprof heap显示"已分配对象"稳定,但 RSS(进程实际占用内存)可能很高。 -
这是正常现象 ,不是泄漏。可通过
GODEBUG=madvdontneed=1让 Go 更积极归还内存。
可能原因 3:CGO / 外部库泄漏
-
CGO 调用的 C 代码分配的内存不受 Go GC 管理。
-
pprof heap看不到这些内存。
可能原因 4:Runtime 内部结构
-
大量 Timer、Channel、Mutex 等运行时对象累积。
-
比如
time.After的误用,Timer 对象在运行时内部堆中累积。
排查方法:
# 看 Goroutine 数量
curl http://localhost:6060/debug/pprof/goroutine
# 看运行时内存统计
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("HeapSys: %d, StackSys: %d, Sys: %d\n", m.HeapSys, m.StackSys, m.Sys)