 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
-
- 一、背景与核心痛点
- [二、知识背景:LR 图 PEC 方法论](#二、知识背景:LR 图 PEC 方法论)
-
- [2.1 定义一个简化的 InfluxQL CFG](#2.1 定义一个简化的 InfluxQL CFG)
- [2.2 构建 LR(0) 自动机------解析器执行逻辑的可视化](#2.2 构建 LR(0) 自动机——解析器执行逻辑的可视化)
- [2.3 彻底搞懂"归约"------解析器的核心动作](#2.3 彻底搞懂"归约"——解析器的核心动作)
- [2.4 构建 InfluxQL 的 LR 图](#2.4 构建 InfluxQL 的 LR 图)
- [2.5 在 LR 图上"走"一遍目标查询](#2.5 在 LR 图上"走"一遍目标查询)
- 三、论文方法的工程局限
-
- [3.1 硬伤 1:LR 图在递归文法上天然无限](#3.1 硬伤 1:LR 图在递归文法上天然无限)
- [3.2 硬伤 2:文法合法 ≠ 引擎可执行](#3.2 硬伤 2:文法合法 ≠ 引擎可执行)
- [3.3 硬伤 3:抽象终结符具体化是"摊平的随机采样"](#3.3 硬伤 3:抽象终结符具体化是"摊平的随机采样")
- [3.4 硬伤 4:负测试的 witness 机制不完备](#3.4 硬伤 4:负测试的 witness 机制不完备)
- 四、完整解决方案
-
- [4.1 LR 图的防爆炸机制](#4.1 LR 图的防爆炸机制)
-
- [防线 1:PEC 按"每条产生式一棵树"生成(`pec.py::pec_generate`)](#防线 1:PEC 按"每条产生式一棵树"生成(
pec.py::pec_generate)) - [防线 2:最短派生 Knuth 不动点(`pec.py::shortest_derivations`)](#防线 2:最短派生 Knuth 不动点(
pec.py::shortest_derivations)) - [防线 3:context 搜索深度预算 + 记忆化(`pec.py::expand_with_hole`)](#防线 3:context 搜索深度预算 + 记忆化(
pec.py::expand_with_hole)) - [防线 4:深度有界随机采样(`pec.py::depth_bounded_enumeration`)](#防线 4:深度有界随机采样(
pec.py::depth_bounded_enumeration)) - [防线 5:文法层收紧(`grammar.py`)](#防线 5:文法层收紧(
grammar.py)) - 五重防线协同效果
- [防线 1:PEC 按"每条产生式一棵树"生成(`pec.py::pec_generate`)](#防线 1:PEC 按"每条产生式一棵树"生成(
- [4.2 派生树 → 可执行 SQL(核心章节)](#4.2 派生树 → 可执行 SQL(核心章节))
-
- [4.2.1 整体流程](#4.2.1 整体流程)
- [4.2.2 Step 1:递归 emit 压扁](#4.2.2 Step 1:递归 emit 压扁)
- [4.2.3 Step 2:抽象终结符 → 具体 token](#4.2.3 Step 2:抽象终结符 → 具体 token)
- [4.2.4 Step 3:空白粘合(`_join` + `_GLUE_BEFORE_LPAREN`)](#4.2.4 Step 3:空白粘合(
_join+_GLUE_BEFORE_LPAREN)) - [4.2.5 Seed 机制:决定论、可复现、扇出控制](#4.2.5 Seed 机制:决定论、可复现、扇出控制)
-
- [Seed 的三个注入点](#Seed 的三个注入点)
- [Seed 在 Phase A 与 Phase B 中的不同用法](#Seed 在 Phase A 与 Phase B 中的不同用法)
- [为什么要"每棵树重置 rng"而不是"全局递增"](#为什么要"每棵树重置 rng"而不是"全局递增")
- [Seed 值的可复现保证](#Seed 值的可复现保证)
- 一个具体例子
- [4.2.6 两种扇出模式在同一个 `generate.py` 里合流](#4.2.6 两种扇出模式在同一个
generate.py里合流) -
- [Phase A:plain 模式(多 seed 扇出)](#Phase A:plain 模式(多 seed 扇出))
- [Phase B:metamorphic 模式(4-kind 变体组)](#Phase B:metamorphic 模式(4-kind 变体组))
- [Phase C:interleave + 写 sidecar](#Phase C:interleave + 写 sidecar)
- 两种扇出对比
- [为什么把 metamorphic 合并进 PEC 实例化阶段是架构升级](#为什么把 metamorphic 合并进 PEC 实例化阶段是架构升级)
- [4.2.7 血统可追溯](#4.2.7 血统可追溯)
- [4.3 本方法与论文的差异](#4.3 本方法与论文的差异)
- 五、解空间量化分析
-
- [5.1 第一层:LR 图理论解空间(递归不设限)](#5.1 第一层:LR 图理论解空间(递归不设限))
- [5.2 第二层:五重防线剪枝后的派生树空间](#5.2 第二层:五重防线剪枝后的派生树空间)
- [5.3 第三层:PEC 树实例化(同一个 `generate.py` 调用同时产出两路)](#5.3 第三层:PEC 树实例化(同一个
generate.py调用同时产出两路)) -
- [Phase A:plain 通道(多 seed 扇出)](#Phase A:plain 通道(多 seed 扇出))
-
- [PEC 派生树 → SQL 的量化放大链路](#PEC 派生树 → SQL 的量化放大链路)
- [Phase B:metamorphic 通道(`_build_metamorphic_groups`)](#Phase B:metamorphic 通道(
_build_metamorphic_groups)) -
- 解空间压缩链路
- [为什么要限制 metamorphic 的组合数](#为什么要限制 metamorphic 的组合数)
- [5.4 第四层:语义约束后的可执行解空间](#5.4 第四层:语义约束后的可执行解空间)
-
- [Plain 通道:36 条 validator 过滤 + DELETE 降采样](#Plain 通道:36 条 validator 过滤 + DELETE 降采样)
- [Metamorphic 通道:TAG 金丝雀 + `--max-metamorphic-groups` 封顶](#Metamorphic 通道:TAG 金丝雀 +
--max-metamorphic-groups封顶) - 综合语料规模
- [5.5 三层空间对比总表](#5.5 三层空间对比总表)
- 六、方法论总结
-
- [6.1 三条核心原则](#6.1 三条核心原则)
- [6.2 一句话结论](#6.2 一句话结论)
一、背景与核心痛点
解析器(parser)是任何 SQL 方言执行的"入口",它把人类可读的查询语句转化为计算机可执行的语法树。一旦解析器出现 bug,可能导致查询报错、结果失真,甚至数据库崩溃------例如 InfluxDB 历史上曾出现 SELECT time FROM sensor 的错误解析 bug,本质就是解析器在特定归约上下文下,错误地把关键字 time 归约为普通字段而非时间戳字段。
在时序数据库兼容性测试 场景里,问题更复杂一层:xstor TSDB 自己实现了一套 InfluxQL parser + planner + executor,需要与开源 InfluxDB 做行为等价性验证。常见的测试方法有三类:
| 方法 | 优势 | 局限 |
|---|---|---|
| 手工枚举 | 语义精准、场景明确 | 维度组合穷不尽,长尾路径漏测 |
| 文法驱动(Rossouw-Fischer PEC) | 覆盖每条归约规则、规模可控 | 只覆盖 parser 层,对语义约束、类型、执行正确性无保证 |
| 随机 fuzz / SQLsmith | 规模大、意外发现多 | 信噪比低,两端都拒绝的垃圾样本爆炸 |
所有这些方法都存在三大致命痛点:
- 路径爆炸:从 LR 自动机起点盲目遍历,路径数量会随文法复杂度指数级增长------哪怕是简化版 InfluxQL,朴素 BFS 也会在稍大的表达式文法上跑出 620 条 prefix 仍未收敛。
- 覆盖不全面 :仅覆盖文法规则,忽略归约上下文 ------同样的语法单元(如
ID),在不同场景下(SELECT 后、FROM 后)归约逻辑不同。同样的,Tag 和 Field 在语法层都是<VAR>,但它们在时序数据库里的运行时语义天差地别(Tag 带倒排索引用于过滤,Field 无索引用于聚合)------传统测试无法精准覆盖这种语义等价类。 - 负测试依赖预言机:生成的非法语句需要人工或外部参考解析器验证,代价高、易出错;即便用参考引擎作 oracle,如果双端都有 bug,结果也不可信。
针对这些痛点,论文提出了"LR 图建模 + PEC 正测试生成 + 路径变异负测试"的方案------用 LR 图显式化解析器执行逻辑,用 PEC 算法高效覆盖所有归约场景,用路径变异生成无需预言机的负测试用例。
但是论文方法天生假设 SUT = 纯 parser,在真实时序数据库上直接套用会出现 96.6 % 两端都拒绝的 BOTH_ERROR------把 LR 图从数学模型变成工程可用的差分测试方法,还需要补上若干关键机制。
下面先梳理 LR 图 PEC 方法的理论基础,再逐一解析论文方案的工程局限,以及我们在 influxql_verify/ 仓库里给出的完整解决方案。
二、知识背景:LR 图 PEC 方法论
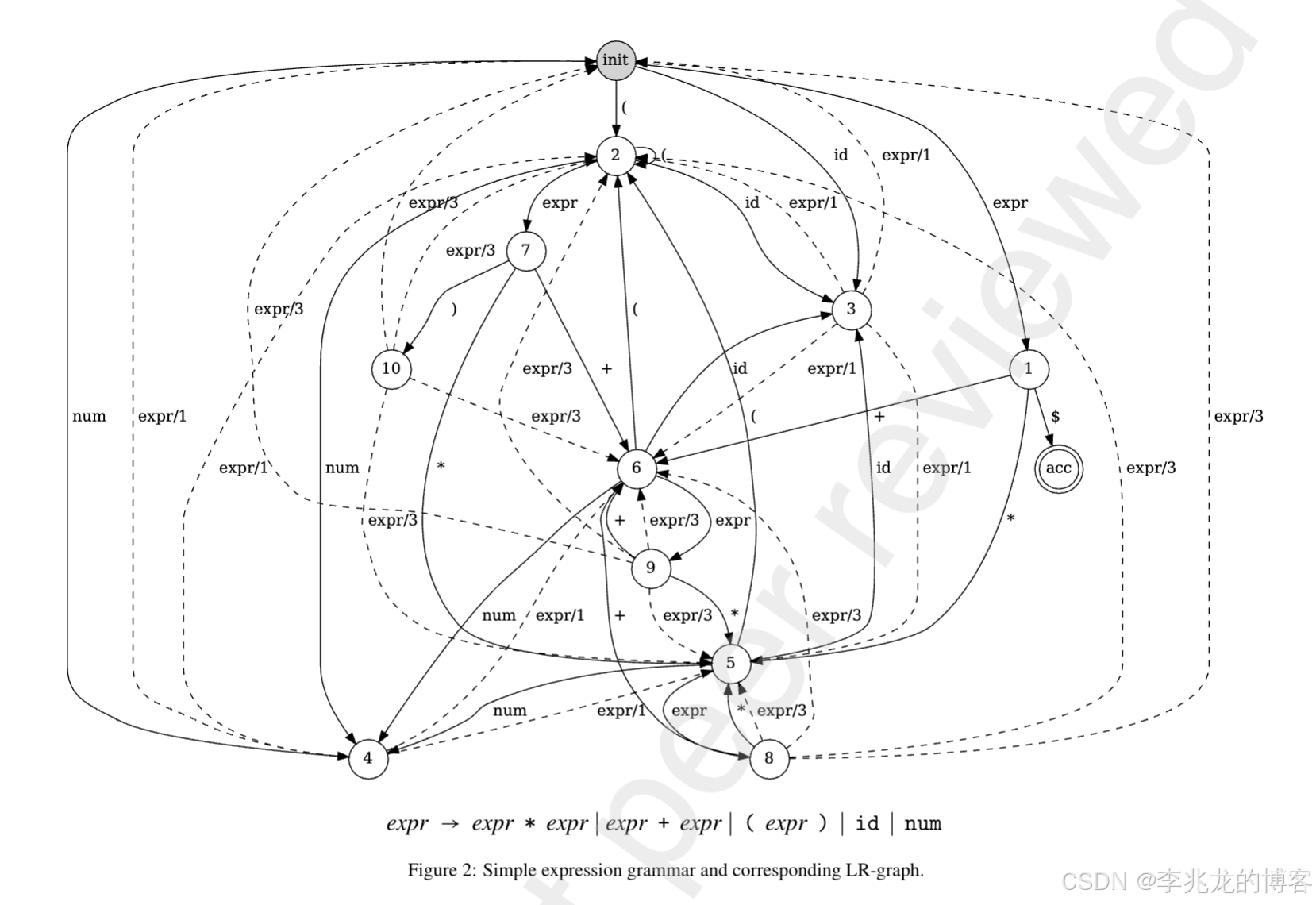
2.1 定义一个简化的 InfluxQL CFG
InfluxQL 的完整语法相当复杂,为演示方便我们取一个核心子集:
sql
SELECT <field> FROM <measurement> WHERE time <operator> <time_expr>对应的上下文无关文法 G = ( N , T , P , S ) G = (N, T, P, S) G=(N,T,P,S):
| 元素 | 内容 | 说明 |
|---|---|---|
| 非终结符 N | {Query, SelectClause, FromClause, WhereClause, Field, Measurement, TimePred, Op, TimeExpr} |
语法结构的抽象单元 |
| 终结符 T | {SELECT, FROM, WHERE, ID, TIME, >, NOW, $} |
解析器能直接识别的词法单元 |
| 开始符号 S | Query |
一条完整查询 |
产生式规则 P:
bnf
1. Query → SelectClause FromClause WhereClause
2. SelectClause → SELECT Field
3. FromClause → FROM Measurement
4. WhereClause → WHERE TimePred
5. Field → ID
6. Measurement → ID
7. TimePred → TIME Op TimeExpr
8. Op → >
9. TimeExpr → NOW后续所有步骤将围绕目标查询展开:
sql
SELECT temp FROM sensor WHERE time > now()对应终结符序列:SELECT ID FROM ID WHERE TIME > NOW $。
2.2 构建 LR(0) 自动机------解析器执行逻辑的可视化
LR 自动机是解析器的底层模型,本质是"状态 + 转移"的集合。论文把 LR 图建立在 LR(0) 自动机上。
LR(0) 项目 :在产生式右部加一个 dot •,表示"当前解析器识别到的位置":
Query → • SelectClause FromClause WhereClause:初始状态;Query → SelectClause • FromClause WhereClause:已识别完 SelectClause,等待 FromClause。
从拓广开始符号 Query' → • Query 出发,通过闭包运算 和 GO 函数,生成 InfluxQL 子集的核心状态集:
| 状态 ID | 核心项目集 | 说明 |
|---|---|---|
| I0 | Query' → • Query;Query → • SelectClause FromClause WhereClause;SelectClause → • SELECT Field |
初始状态 |
| I1 | Query' → Query • |
接受状态 |
| I2 | Query → SelectClause • FromClause WhereClause;FromClause → • FROM Measurement |
已识别 SELECT 子句 |
| I3 | SelectClause → SELECT • Field;Field → • ID |
看到 SELECT,等待 ID |
| I4 | SelectClause → SELECT Field • |
SELECT 子句归约完毕 |
| I5 | Field → ID • |
一个 ID 被当作 Field |
| I6 | Query → SelectClause FromClause • WhereClause;WhereClause → • WHERE TimePred |
等待 WHERE |
| I7 | FromClause → FROM • Measurement;Measurement → • ID |
看到 FROM,等待 ID |
| I8 | FromClause → FROM Measurement • |
FROM 子句归约完毕 |
| I9 | Measurement → ID • |
一个 ID 被当作 Measurement |
| I10 | Query → SelectClause FromClause WhereClause • |
Query 即将归约 |
| I11 | WhereClause → WHERE • TimePred;TimePred → • TIME Op TimeExpr |
看到 WHERE,等待时间谓词 |
| I12 | WhereClause → WHERE TimePred • |
WHERE 子句归约完毕 |
| I13 | TimePred → TIME • Op TimeExpr;Op → • > |
看到 TIME,等待运算符 |
| I14 | TimePred → TIME Op • TimeExpr;TimeExpr → • NOW |
看到 >,等待时间表达式 |
| I15 | Op → > • |
> 归约为 Op |
| I16 | TimePred → TIME Op TimeExpr • |
完整的时间谓词 |
| I17 | TimeExpr → NOW • |
NOW 归约为 TimeExpr |
2.3 彻底搞懂"归约"------解析器的核心动作
归约的本质是"自底向上的语法合并" ,与之配合的是移进(Shift):把终结符读进解析器栈里。
类比拼乐高:
- Shift :从盒子里拿出一块积木(
SELECT、temp),放到工作台(栈)上; - Reduce :工作台上的几块积木刚好能拼成一个大部件(
temp → Field、SELECT + Field → SelectClause),把它们换成这个大部件。
以 SELECT temp FROM sensor WHERE time > now() 为例,终结符序列 [SELECT, ID, FROM, ID, WHERE, TIME, >, NOW],完整演示解析器的移进与归约过程:
| 步骤 | 解析器栈 | 剩余输入 | 动作 | 对应规则 |
|---|---|---|---|---|
| 1 | [] |
SELECT, ID, FROM, ... | Shift | --- |
| 2 | [SELECT] |
ID, FROM, ... | Shift | --- |
| 3 | [SELECT, ID] |
FROM, ... | Reduce | Field → ID |
| 4 | [SELECT, Field] |
FROM, ... | Reduce | SelectClause → SELECT Field |
| 5 | [SelectClause] |
FROM, ... | Shift | --- |
| 6 | [SelectClause, FROM] |
ID, WHERE, ... | Shift | --- |
| 7 | [SelectClause, FROM, ID] |
WHERE, ... | Reduce | Measurement → ID |
| 8 | [SelectClause, FROM, Measurement] |
WHERE, ... | Reduce | FromClause → FROM Measurement |
| 9 | [SelectClause, FromClause] |
WHERE, ... | Shift | --- |
| 10 | [..., WHERE] |
TIME, >, NOW | Shift | --- |
| 11 | [..., WHERE, TIME] |
>, NOW | Shift | --- |
| 12 | [..., TIME, >] |
NOW | Reduce | Op → > |
| 13 | [..., TIME, Op] |
NOW | Shift | --- |
| 14 | [..., TIME, Op, NOW] |
--- | Reduce | TimeExpr → NOW |
| 15 | [..., TIME, Op, TimeExpr] |
--- | Reduce | TimePred → TIME Op TimeExpr |
| 16 | [..., WHERE, TimePred] |
--- | Reduce | WhereClause → WHERE TimePred |
| 17 | [SelectClause, FromClause, WhereClause] |
--- | Reduce | Query → SelectClause FromClause WhereClause |
| 18 | [Query] |
--- | Accept | --- |
最关键的一点:归约上下文决定归约结果。
看上面的步骤 3 和步骤 7:
- 步骤 3:栈里是
[SELECT],ID(temp)归约为 Field------归约上下文是"SELECT 后面"; - 步骤 7:栈里是
[SelectClause, FROM],ID(sensor)归约为 Measurement------归约上下文是"FROM 后面"。
如果解析器错误地忽略归约上下文(比如把 FROM 后面的 ID 归约为 Field),就会导致查询解析错误。传统基于文法的测试只覆盖了"ID 可以被归约为 Field 或 Measurement"这种规则级事实,但并不系统地区分这两个不同的归约上下文------这正是 LR 图要解决的核心问题。
2.4 构建 InfluxQL 的 LR 图
LR 图是论文最核心的建模对象:它在 LR 自动机的基础上,把转移关系拆成两类显式的边,让归约上下文变得"可走可覆盖"。
给定 LR 自动机 L R G = ( Q , δ , ρ , q i n i t , q a c c ) LR_G = (Q, \delta, \rho, q_{init}, q_{acc}) LRG=(Q,δ,ρ,qinit,qacc),论文定义的 LR 图 L R G → = ( Q , E , q i n i t , q a c c ) LR_G^{\to} = (Q, E, q_{init}, q_{acc}) LRG→=(Q,E,qinit,qacc) 包含两类边:
| 边类型 | 对应解析器动作 | 记号 | 含义 |
|---|---|---|---|
| Push 边 | Shift 或 Goto | q → X q ′ q \to_X q' q→Xq′ | 从 q 看到符号 X,到达 q' |
| Pop 边 | Reduce | q ⇢ A / ∣ α ∣ q ′ q \dashrightarrow_{A/|\alpha|} q' q⇢A/∣α∣q′ | 在状态 q 应用规则 A → α A \to \alpha A→α,栈顶弹 ∣ α ∣ |\alpha| ∣α∣ 个状态后回到 q' |
为什么要拆? 传统 PDA 里,一次归约是"弹若干栈帧 + 推入非终结符"的原子动作,栈顶之下的状态被隐藏起来;LR 图把归约拆成一条 Pop 边,于是每种栈顶上下文对应一条独立的 Pop 边------这恰好把归约上下文显式化了。
InfluxQL 子集的核心 Pop 边(每个归约对应一条):
| 规则 | Pop 边 | 归约上下文 |
|---|---|---|
Field → ID |
I 5 ⇢ F i e l d / 1 I 3 I_5 \dashrightarrow_{Field/1} I_3 I5⇢Field/1I3 | SELECT 之后的 ID |
Measurement → ID |
I 9 ⇢ M e a s u r e m e n t / 1 I 7 I_9 \dashrightarrow_{Measurement/1} I_7 I9⇢Measurement/1I7 | FROM 之后的 ID |
Op → > |
I 15 ⇢ O p / 1 I 13 I_{15} \dashrightarrow_{Op/1} I_{13} I15⇢Op/1I13 | TIME 之后的 > |
TimeExpr → NOW |
I 17 ⇢ T i m e E x p r / 1 I 14 I_{17} \dashrightarrow_{TimeExpr/1} I_{14} I17⇢TimeExpr/1I14 | > 之后的 NOW |
SelectClause → SELECT Field |
I 4 ⇢ S e l e c t C l a u s e / 2 I 0 I_4 \dashrightarrow_{SelectClause/2} I_0 I4⇢SelectClause/2I0 | SELECT 子句合并 |
FromClause → FROM Measurement |
I 8 ⇢ F r o m C l a u s e / 2 I 2 I_8 \dashrightarrow_{FromClause/2} I_2 I8⇢FromClause/2I2 | FROM 子句合并 |
TimePred → TIME Op TimeExpr |
I 16 ⇢ T i m e P r e d / 3 I 11 I_{16} \dashrightarrow_{TimePred/3} I_{11} I16⇢TimePred/3I11 | 时间谓词合并 |
WhereClause → WHERE TimePred |
I 12 ⇢ W h e r e C l a u s e / 1 I 6 I_{12} \dashrightarrow_{WhereClause/1} I_6 I12⇢WhereClause/1I6 | WHERE 子句合并 |
Query → SelectClause FromClause WhereClause |
I 10 ⇢ Q u e r y / 3 I 0 I_{10} \dashrightarrow_{Query/3} I_0 I10⇢Query/3I0 | 顶层查询合并 |
Pop 边 I 5 ⇢ F i e l d / 1 I 3 I_5 \dashrightarrow_{Field/1} I_3 I5⇢Field/1I3 和 I 9 ⇢ M e a s u r e m e n t / 1 I 7 I_9 \dashrightarrow_{Measurement/1} I_7 I9⇢Measurement/1I7 共享文法规则中相同的 ID,但是两条不同的边 ------这就是 LR 图把"归约上下文"显式化的方式。覆盖所有 Pop 边 ≡ 覆盖所有归约上下文。
2.5 在 LR 图上"走"一遍目标查询
目标:SELECT temp FROM sensor WHERE time > now()。在 LR 图上,一次完整的解析 = 一条从 q i n i t = I 0 q_{init}=I_0 qinit=I0 到 q a c c = I 1 q_{acc}=I_1 qacc=I1 的交替路径,终结符 Push 边由输入驱动,每条 Pop 边必须紧跟一条相同非终结符的 Push 边(对应 Goto):
| 步 | 动作 | 边 | 下一状态 |
|---|---|---|---|
| 1 | 读入 SELECT | Push I 0 → S E L E C T I 3 I_0 \to_{SELECT} I_3 I0→SELECTI3 | I3 |
| 2 | 读入 ID | Push I 3 → I D I 5 I_3 \to_{ID} I_5 I3→IDI5 | I5 |
| 3 | 归约 Field→ID |
Pop I 5 ⇢ F i e l d / 1 I 3 I_5 \dashrightarrow_{Field/1} I_3 I5⇢Field/1I3 | I3 |
| 4 | Goto Field | Push I 3 → F i e l d I 4 I_3 \to_{Field} I_4 I3→FieldI4 | I4 |
| 5 | 归约 SelectClause→SELECT Field |
Pop I 4 ⇢ S e l e c t C l a u s e / 2 I 0 I_4 \dashrightarrow_{SelectClause/2} I_0 I4⇢SelectClause/2I0 | I0 |
| 6 | Goto SelectClause | Push I 0 → S e l e c t C l a u s e I 2 I_0 \to_{SelectClause} I_2 I0→SelectClauseI2 | I2 |
| 7 | 读入 FROM | Push I 2 → F R O M I 7 I_2 \to_{FROM} I_7 I2→FROMI7 | I7 |
| 8 | 读入 ID | Push I 7 → I D I 9 I_7 \to_{ID} I_9 I7→IDI9 | I9 |
| 9 | 归约 Measurement→ID |
Pop I 9 ⇢ M e a s u r e m e n t / 1 I 7 I_9 \dashrightarrow_{Measurement/1} I_7 I9⇢Measurement/1I7 | I7 |
| 10 | Goto Measurement | Push I 7 → M e a s u r e m e n t I 8 I_7 \to_{Measurement} I_8 I7→MeasurementI8 | I8 |
| ... | (略,以此类推) | ... | ... |
| 27 | Accept | --- | --- |
把路径上所有终结符 Push 边 的标签按序收集起来,就得到正测试用例:SELECT ID FROM ID WHERE TIME > NOW。替换成具体标识符即为目标查询。
PEC 算法的核心洞察 :每一条 Pop 边在 LR 图中都对应唯一一条规范的归约路径(Push 前缀 + Pop 边本身 + Goto 回推):
r = ι ( p ∈ E → ∣ α ∣ ∣ v ( p ) = q ′ ⋯ q ) ⏟ push 前缀 ∘ ( q ⇢ A / ∣ α ∣ q ′ ) ⏟ Pop 边 ∘ ι ( q ′ → A q ′ ′ ) ⏟ Goto r = \underbrace{\iota(p \in E_{\to}^{|\alpha|} \mid v(p)=q'\cdots q)}{\text{push 前缀}} \circ \underbrace{(q \dashrightarrow{A/|\alpha|} q')}{\text{Pop 边}} \circ \underbrace{\iota(q' \to_A q'')}{\text{Goto}} r=push 前缀 ι(p∈E→∣α∣∣v(p)=q′⋯q)∘Pop 边 (q⇢A/∣α∣q′)∘Goto ι(q′→Aq′′)
覆盖一条 Pop 边 ≡ 走完它唯一的归约路径,不用搜索,直接构造。时间复杂度 O(|E⇢|),线性于 Pop 边数。
三、论文方法的工程局限
论文方法在 "SUT 就是 parser" 的场景(SQLite 单元测试、GCC 前端测试)里是成立的:只要能派生出的 SQL 就是"合法正例"。但把它直接套到 xstor / InfluxDB 的兼容性测试上,会遇到三个硬伤:
3.1 硬伤 1:LR 图在递归文法上天然无限
LR 图在数学上 是有限的(InfluxQL 子集约 179 状态 + 360 push 边 + 97 pop 边),但它生成的语言 L(G) 无限------任何路径都可以绕回起点重新走一遍。InfluxQL 里尤其棘手的是两类递归产生式:
bnf
# 子查询递归
measurement → <MEASUREMENT>
| <REGEX_LIT>
| <LPAREN> select_stmt <RPAREN> ← 可无限嵌套
# 表达式递归
expr_bool → expr_rel
| expr_rel <OP_LOGIC> expr_bool ← 右递归
expr_arith → expr_atom
| expr_atom <OP_ARITH> expr_arith ← 右递归
expr_atom → <LPAREN> expr <RPAREN> ← 括号嵌入 expr
| function_call ← 函数内嵌 expr论文原版的 BFS(Algorithm 1/2/3)在稍大一点的表达式文法上就跑出 620 条 prefix 仍未收敛,对 InfluxQL 这种带子查询的文法更是指数爆炸。
3.2 硬伤 2:文法合法 ≠ 引擎可执行
论文假设"语法 = 语义"。但 InfluxQL 在 parser 之上还有多层隐式约束:
- 词法层 :
time(、fill(、tz(之间必须无空格,SELECT time ( 1h )会被拒绝; - 语义层 :SELECT 子句不允许
AND/OR/=/<>;ORDER BY只支持time;GROUP BY time()要求 SELECT 含聚合;WHERE 子句必须为布尔; - 类型层 :
min/max不接受 string;time + 'abc'非法;tag 只能用=/!=/=~,不能</>=; - 时序特有语义层:Tag vs Field 的运行时语义差异。
论文原版 PEC 跑出的 1 658 条"文法合法" SQL,直接打到 xstor + InfluxDB 双端,96.6 % 被两端同时拒绝------这些样本在差分测试里是零信号的纯噪音。
3.3 硬伤 3:抽象终结符具体化是"摊平的随机采样"
论文的 terminalizer 只是"把抽象终结符换成某个具体值"的简单映射。但时序数据库里有一个关键区分:Tag 与 Field 在语法上都是 <VAR>,但运行时语义完全不同:
| 维度 | Tag | Field |
|---|---|---|
| 存储 | 倒排索引 | 无索引的列 |
| WHERE 运算符 | =, !=, =~(禁 <, >=) |
=, !=, <, <=, >, >= |
| GROUP BY | 自然可分组 | 一般不允许 |
| 聚合 | count(tag) 合法,sum(tag) 非法 |
全聚合(类型允许下) |
如果 terminalizer 只是从 ALL_FIELDS 里随机抽一个名字塞进 <FIELD_KEY>,类型维度就被"摊平"了------PEC 派生树里的 min(<FIELD_KEY>) 有 50 % 概率被 terminalize 成 min(status)(非法),要么被过滤规则 drop,要么污染差分信号。论文方法根本没有"同一结构下变换列类型"的概念,于是 Tag/Field 语义错位这类 TSDB 核心 bug 直接漏测。
3.4 硬伤 4:负测试的 witness 机制不完备
论文的路径变异依赖 follow/precede/witness 集合来保证变异后"一定非法"。在 TSDB 差分测试里:
- "一定非法"的定义本身有歧义------到底是 parser 拒绝,还是 analyzer 拒绝,还是类型拒绝?
- 两端引擎行为可能不同------xstor 接受 InfluxDB 拒绝恰恰是高价值 bug,绝不能被 witness 机制过滤掉。
因此负测试这条路在差分测试场景里信噪比天然偏低:真正有信号的反而是正例里隐藏的宽严分歧、静默失败、跨类型错位。
四、完整解决方案
针对以上四个硬伤,influxql_verify/ 仓库给出的方案是把论文方法当作一条生成管线的骨架,在它之上叠加三层工程机制,并把 metamorphic 完全融入 PEC 实例化阶段:
Grammar(148 产生式)
│
│ ① PEC + 防爆炸机制 → 派生树
▼
派生树池 (PEC + 深度采样 + 结构签名去重)
│
│ ② terminalizer 在同一个 generate.py 里一次产出两路 SQL
│ ├─ Phase A (plain): kind_override=None,多 seed 扇出
│ └─ Phase B (metamorphic): 每棵"带列槽"且 TAG 变体语义合法的树
│ 用同一个 tree_seed 派生 4 条
│ (TAG / NUMERIC / BOOL / STRING) 变体
▼
<out>.sql + sidecar <out>.sql.meta.jsonl (逐行元信息)
plain 在前、 {"meta_group_id": null} -- plain
metamorphic {"meta_group_id": "mg_00000",
4 条一组连续 "meta_kind": "TAG"} -- 变体 1/4
在后 ... -- 2/4, 3/4, 4/4
│
│ ③ 36 条 validator 方言语义过滤
▼
可执行 SQL (plain ≈ 1.6 万条; metamorphic 组 ≤ 2000 组 × 4)
│
│ ④ run_diff_all.py 差分执行
│ ├─ plain: 单条 SQL 双端对比
│ └─ metamorphic: 按 meta_group_id 缓冲 4 条变体
│ 4 条都跑完后调 metamorphic_oracle.evaluate()
▼
xstor vs influxdb关键架构要点 :一次 generate.py 调用同时产出 plain 语料 + metamorphic 语料 + 侧车元数据文件。不再有独立的 run_metamorphic_pec.py------metamorphic 仅仅是生成阶段 Terminalizer 的"第二路模式"、执行阶段 run_diff_all.py 的"第二类 Oracle"。两路共享同一份派生树池、同一个 Terminalizer 实例、同一套 validator,配置开关即 --metamorphic / --no-metamorphic + --max-metamorphic-groups。
4.1 LR 图的防爆炸机制
在 pec.py + grammar.py 里用五重防线同时压制递归:
防线 1:PEC 按"每条产生式一棵树"生成(pec.py::pec_generate)
PEC 的核心对应关系是:|P| 条产生式 ↔ |P| 条 Pop 边 ↔ |P| 条测试树。产生式集合 P 在编译 grammar 的时候就已经定死(148 条),不会随递归深度膨胀。
python
for p_idx, (A, rhs) in enumerate(g.productions): # 148 次循环
# 1. 建 RHS 子树:RHS 中每个非终结符用 "最短派生" 填充
children = []
for sym in rhs:
if g.is_terminal(sym):
children.append(sym)
else:
children.append(shortest[sym]) # 关键:递归在这里被截断
subtree = (A, p_idx, children)
# 2. 把 subtree 嵌入到"从 START 到 A 的最浅上下文"
ctx = find_context(A)
tests.append(_plug(ctx, subtree))防线 2:最短派生 Knuth 不动点(pec.py::shortest_derivations)
对每个非终结符 A 预计算"能派生出它的最小终结符数量树"。这是一个经典不动点迭代:
python
cost: Dict[str, float] = {A: INF for A in g.nonterminals}
changed = True
while changed:
changed = False
for i, (A, rhs) in enumerate(g.productions):
c = sum of 1 per terminal + cost[NT] per non-terminal
if feasible and c < cost[A]:
cost[A] = c; best_prod[A] = i; changed = True这条算法对所有可终止的非终结符都返回有限大小的树 。对 select_stmt,shortest[select_stmt] 只是最简的 SELECT * FROM <MEASUREMENT>------不含任何递归嵌套(因为那种路径 cost 更高)。子查询非终结符的最短派生就是"没有子查询"。
防线 3:context 搜索深度预算 + 记忆化(pec.py::expand_with_hole)
python
def expand_with_hole(A, depth_budget):
if A == target_nt:
return ("__HOLE__", target_nt)
if depth_budget <= 0:
return None # 硬截断
if A in memo:
return memo[A]
memo[A] = None # 打破环
best = None
for p in g.by_lhs.get(A, []):
sub = expand_with_hole(sym, depth_budget - 1)
...
tree = expand_with_hole(g.start, depth_budget=60)三重保险:depth_budget=60 硬上限;memo 打破左递归环;只在"必然到达 target"的分支上递归。
防线 4:深度有界随机采样(pec.py::depth_bounded_enumeration)
PEC 只给 O(|P|) = 148 棵树,结构多样性不够。第二路生成用深度有界随机采样:
python
def sample(A, depth_left):
if depth_left <= 0:
return shortest[A] # 硬截断:用最短派生
prods = g.by_lhs[A]
if depth_left == 1:
all_term = [p for p in prods if all terminal]
if all_term:
prods = all_term # 消除尾巴递归
p = rng.choice(prods)
return (A, p, [sample(sym, depth_left-1) for sym in rhs])典型参数:深度 5 / 10 / 15 三档,每档 15 000 棵树,seen_sig 结构签名去重。
防线 5:文法层收紧(grammar.py)
部分递归在文法层就被砍掉:
| 原 EBNF | 收紧 | 目的 |
|---|---|---|
field = expr |
select_expr → select_arith(无关系/逻辑/regex) |
SELECT 禁递归到 expr_bool/expr_rel |
| `sort_field = time | FIELD_KEY [ASC | DESC]` |
fields = * 可与 field_list 混排 |
`fields → * | field_list`(互斥) |
literal 含 REGEX_LIT |
regex 只在 regex_match_op 里 |
regex 递归点大幅减少 |
| `distinct(*) | distinct(field)` | 剔除 distinct(*) |
SHOW/DELETE 共用 expr |
独立 meta_where 非终结符 |
SHOW/DELETE 的 WHERE 空间降到受限子集 |
五重防线协同效果
| 防线 | 位置 | 性质 |
|---|---|---|
| 1. PEC 按产生式生成 | pec_generate |
规模上限 = 常数 |P| = 148 |
| 2. shortest_derivations 截断 | shortest_derivations |
最短树有限、无递归嵌套 |
| 3. context 搜索深度预算 | expand_with_hole |
硬上限 60、memo 打破环 |
| 4. 深度有界采样 | depth_bounded_enumeration |
深度 5/10/15,触底用 shortest |
| 5. 文法收紧 | grammar.py |
消除整类递归入口 |
LR 图作为数学对象有限,生成的语言无限;五重防线让实际采样到的派生树空间也变得可控:每棵树节点数都有明确上限,整个语料规模由"|P| + 深度档数 × 每档树数 × seed 数"线性控制。
4.2 派生树 → 可执行 SQL(核心章节)
拿到派生树池之后,terminalizer.py 负责把树上的抽象终结符 (<SELECT>、<FIELD_KEY>、<INT_LIT> 等)替换成具体 token,拼成可直接发给 xstor 的 SQL。这一步是整个管线最关键、最容易被低估的环节------同一棵派生树可以产出从"单条代表性 SQL"到"上万条候选 SQL"到"4 条精确等价类变体 SQL"的完全不同的语料,全看 terminalizer 怎么配置。
在最新的工程实现里,整个 metamorphic 生成逻辑已经被完全吸收进 generate.py 的 Phase B (函数 _build_metamorphic_groups)。不再有独立的 run_metamorphic_pec.py 脚本:一次 CLI 调用同时产出 plain SQL + 4-kind 变体组,并把"哪一行属于哪个 meta_group_id 的哪个 meta_kind"写进 sidecar <out>.sql.meta.jsonl。下游 run_diff_all.py 读取 sidecar 即可识别变体组并触发 metamorphic Oracle。
4.2.1 整体流程
派生树池 (pec.py)
│
▼
[step 1] _emit() 递归 DFS 压扁 ───► token 列表(仍含抽象终结符)
│
▼
[step 2] _emit_terminal() 抽象 → 具体
│ ├─ 关键字 1:1 映射
│ ├─ 字面量池随机采样 (INT_LIT / STRING_LIT / DURATION_LIT ...)
│ ├─ 函数族随机采样 (FN_AGG_NUM / FN_TRANSFORM ...)
│ └─ 列槽 (FIELD_KEY / NUMERIC_FIELD / TAG_KEY / TAG_VALUE)
│ ├─ kind_override=None → 随机采样 (Phase A / plain)
│ └─ kind_override=TAG/NUM/BOOL/STR → 强制替换 (Phase B / metamorphic)
│ 其中 saw_column_slot 会被置位,作为本树是否值得
│ 派生 4 变体的判据
│
▼
[step 3] _join() 空白粘合 + _GLUE_BEFORE_LPAREN
│
▼
[step 4] generate.py 的三段扇出(Phase A / B / C)
├─ Phase A plain: trees × 多 seeds ───► 约 1.6 万条 unique SQL
├─ Phase B metamorphic: 每棵树单 tree_seed × 4 kinds
│ (TAG 变体先过 validator 作语义金丝雀,
│ 过得了才真正产出 4 条;
│ 4 条全相同的退化组会被直接丢弃)
│ ───► ≤ 2 000 组 × 4 = ≤ 8 000 条
└─ Phase C interleave + emit
plain 在前 + metamorphic 4 条一组连续在后,
同时写 <out>.sql 与 <out>.sql.meta.jsonl 两份文件4.2.2 Step 1:递归 emit 压扁
python
def _emit(self, node):
if isinstance(node, str): # 终结符
return self._emit_terminal(node)
if isinstance(node, tuple) and node[0] == "__HOLE__":
return ["/*HOLE*/"] # 未插好的占位
lhs, _prod, children = node
out = []
for c in children:
out.extend(self._emit(c)) # DFS
return out输入派生树 ("select_stmt", 0, ["<SELECT>", ..., ("from_clause", ..., ["<FROM>", "<MEASUREMENT>"])]),输出 ["SELECT", "*", "FROM", "\"gd_select\""]。
4.2.3 Step 2:抽象终结符 → 具体 token
这是整个 terminalizer 的核心。抽象终结符分四类,每类的具体化方式不同:
(A) 关键字:1:1 映射
python
_KEYWORD_MAP = {
"<SELECT>": "SELECT", "<FROM>": "FROM", "<WHERE>": "WHERE",
"<GROUP_BY>": "GROUP BY", "<ORDER_BY>": "ORDER BY", ...
}总计 53 个关键字,纯字典查询,无随机性。
(B) 字面量池:从 schema.py 的值池随机采样
python
if t == "<INT_LIT>": return [str(r.choice(schema.INT_LITS))]
if t == "<FLOAT_LIT>": return [str(r.choice(schema.FLOAT_LITS))]
if t == "<STRING_LIT>": return ["'" + r.choice(schema.STRING_LITS) + "'"]
if t == "<DURATION_LIT>":return [r.choice(schema.DURATION_LITS)]
if t == "<REGEX_LIT>": return [r.choice(schema.REGEX_LITS)]schema.py 定义了每个字面量类型的值池(摘录):
| 抽象终结符 | 值池 | 池大小 | 示例 |
|---|---|---|---|
<INT_LIT> |
INT_LITS |
7 | 0, 1, 3, 10, 50, 100, 1000 |
<FLOAT_LIT> |
FLOAT_LITS |
5 | 0.0, 0.5, 1.5, 50.0, 99.9 |
<STRING_LIT> |
STRING_LITS |
5 | 'alpha', 'beta', 'gamma', 'delta', 'unknown' |
<DURATION_LIT> |
DURATION_LITS |
9 | 1u, 1ms, 1s, 30s, 1m, 5m, 1h, 1d, 1w |
<REGEX_LIT> |
REGEX_LITS |
3 | /./、/^multi_./、/host0-3/ |
<TZ_STRING> |
TZ_ARGS |
4 | UTC, Asia/Shanghai, America/New_York, Europe/Berlin |
© 函数族:从函数目录随机采样
python
if t == "<FN_AGG_NUM>": return [r.choice(schema.AGG_NUMERIC)]
if t == "<FN_AGG_ANY>": return [r.choice(schema.AGG_ANY)]
if t == "<FN_SELECTOR>": return [r.choice(schema.SELECTORS)]
if t == "<FN_TRANSFORM>":return [r.choice(schema.TRANSFORMS)]
if t == "<OP_ARITH>": return [r.choice(schema.ARITH_OPS)]
if t == "<OP_REL>": return [r.choice(schema.REL_OPS)]
if t == "<OP_LOGIC>": return [r.choice(schema.LOGIC_OPS)]| 抽象终结符 | 目录 | 大小 | 内容 |
|---|---|---|---|
<FN_AGG_NUM> |
AGG_NUMERIC |
7 | sum, mean, median, mode, spread, stddev, integral |
<FN_AGG_ANY> |
AGG_ANY |
6 | count, first, last, min, max, distinct |
<FN_SELECTOR> |
SELECTORS |
4 | first, last, min, max |
<FN_TOPBOTTOM> |
TOP_BOTTOM |
2 | top, bottom |
<FN_TRANSFORM> |
TRANSFORMS |
7 | derivative, non_negative_derivative, difference, non_negative_difference, cumulative_sum, moving_average, elapsed |
<OP_ARITH> |
ARITH_OPS |
5 | +, -, *, /, % |
<OP_REL> |
REL_OPS |
7 | =, !=, <>, <, <=, >, >= |
<OP_LOGIC> |
LOGIC_OPS |
2 | AND, OR |
(D) 列槽:v7 新增分类,也是 metamorphic 融合的核心
python
_COLUMN_SLOT_TERMS = {"<FIELD_KEY>", "<NUMERIC_FIELD>", "<TAG_KEY>"}
KIND_COLUMN = {"TAG":"host", "NUMERIC":"cpu", "BOOL":"status", "STRING":"info"}
KIND_LITERAL = {"TAG":"'host0'","NUMERIC":"50","BOOL":"true","STRING":"'alpha'"}
if t in _COLUMN_SLOT_TERMS:
self.saw_column_slot = True
if self.kind_override is not None:
return [f'"{KIND_COLUMN[self.kind_override]}"'] # 强制替换
# 无 override 时走随机采样
if t == "<FIELD_KEY>": return [f'"{r.choice(schema.ALL_FIELDS)}"']
if t == "<NUMERIC_FIELD>":return [f'"{r.choice(schema.NUMERIC_FIELDS)}"']
if t == "<TAG_KEY>": return [f'"{r.choice(schema.TAG_KEYS)}"']
if t == "<TAG_VALUE>":
if self.kind_override is not None:
return [KIND_LITERAL[self.kind_override]] # 跟随 kind
k = r.choice(schema.TAG_KEYS)
return ["'" + r.choice(schema.TAG_VALUES[k]) + "'"]列槽和其他终结符的关键区别:它们是 metamorphic 变体的"锚点"。通过三个开关支持两种模式:
_COLUMN_SLOT_TERMS:定义哪些抽象终结符算"列槽"------只有这些槽的值会因kind_override而变化;saw_column_slot:派生树一旦触碰列槽就置位,标志这棵树是否有 metamorphic 变异点;KIND_COLUMN+KIND_LITERAL:两张替换表保证"强制 kind"时列名与<TAG_VALUE>字面量搭配一致 (例如kind=BOOL时列名"status"配字面量true,而不是'alpha')。
4.2.4 Step 3:空白粘合(_join + _GLUE_BEFORE_LPAREN)
InfluxQL lexer 对 time(、fill(、tz( 以及所有函数名 ( 的组合要求无空格:
python
_GLUE_BEFORE_LPAREN = {
"time", "fill", "tz", # 3 个保留字
"count", "sum", "mean", "median", "mode",
"spread", "stddev", "integral", # 7 个数值聚合
"first", "last", "min", "max", "distinct", # 5 个选择器
"top", "bottom", "percentile", "sample", # 4 个 top/bottom
"derivative", "non_negative_derivative",
"difference", "non_negative_difference",
"cumulative_sum", "moving_average", "elapsed", # 7 个 transform
"holt_winters", "holt_winters_nonneg", # 2 个 predictor
}
def _join(self, tokens):
buf = []
for tok in tokens:
last = buf[-1].lstrip() if buf else None
if tok == "(" and last in _GLUE_BEFORE_LPAREN:
buf.append(tok); continue
if tok in {")", ",", "."} or last in {"(", "."}:
buf.append(tok)
else:
buf.append(" " + tok)
return "".join(buf)若不做这一步,time (1h) 会直接被两端拒绝------这是论文 terminalizer 完全没提、但在 InfluxQL 方言上不可缺的环节。
4.2.5 Seed 机制:决定论、可复现、扇出控制
上面的 Step 2 反复出现 r.choice(...)、r.randint(...)------这个 r 是 Terminalizer.rng,一个 random.Random(seed) 实例。整个 terminalizer 的"随机性"全部由这一个 PRNG 驱动,seed 值决定了:
- 同一棵树在同一 seed 下的输出完全相同(可复现、可回归);
- 同一棵树在不同 seed 下几乎必然输出不同 SQL(扇出放大的源头);
- 同一个 seed 内的 4 次
kind_override调用,非列槽终结符抽到完全相同的值(metamorphic 等价类的成立基础)。
Seed 的三个注入点
python
# terminalizer.py ------ 类内部与公开入口
class Terminalizer:
def __init__(self, measurement, seed=42, kind_override=None):
self.rng = random.Random(seed) # (1) 构造期 seed:基线 rng
def tree_to_sql(self, tree, seed=None, kind_override=...):
if seed is not None:
self.rng = random.Random(seed) # (2) 每棵树 seed:本次调用独占 rng
self._cache = {}
self.saw_column_slot = False
...
tokens = self._emit(tree) # 递归 _emit → _emit_terminal → r.choice
return self._join(tokens)
python
# terminalizer.py ------ 批量入口
def trees_to_sqls(trees, measurement=..., base_seed=42):
term = Terminalizer(measurement=measurement, seed=base_seed)
out = []
for i, t in enumerate(trees):
out.append(term.tree_to_sql(t, seed=base_seed + i)) # (3) 每棵树独立递增
return out三个 seed 注入点分工如下:
| 注入点 | 作用 | 典型调用方 |
|---|---|---|
(1) Terminalizer(seed=...) |
构造期设置一个"兜底 rng",若后续 tree_to_sql 不传 seed 就沿用之 |
共享实例、序列化多棵树 |
(2) tree_to_sql(tree, seed=S) |
每棵树独立重置------这是工程中最常用的用法 | Phase A 多 seed 扇出、Phase B 4 变体组 |
(3) trees_to_sqls(trees, base_seed=B) |
内部对第 i 棵树用 seed=B+i,保证"同一批树的每棵树 seed 全局唯一" |
Phase A 的默认 batch 入口 |
Seed 在 Phase A 与 Phase B 中的不同用法
Phase A(plain 多 seed 扇出)走 trees_to_sqls(base_seed=s):
base_seed=42, trees=[t0, t1, t2, ...]
→ t0 用 seed=42 + 0 = 42
→ t1 用 seed=42 + 1 = 43
→ t2 用 seed=42 + 2 = 44
...
base_seed=100, trees=[t0, t1, t2, ...]
→ t0 用 seed=100 + 0 = 100
→ t1 用 seed=100 + 1 = 101
...同一棵树 t0 在两个 base_seed 下拿到 seed=42 和 seed=100 ,两次 r.choice 序列完全不同,因此字面量、函数名、列名的抽取结果也几乎必然不同。seen_plain 用 SQL 字符串去重,最终得到多个不同版本的 t0。
Phase B(metamorphic 4 变体组)走自定义 tree_seed:
python
# generate.py 片段
for base_seed in seeds:
for tree_idx, tree in enumerate(trees):
tree_seed = base_seed * 1_000_003 + tree_idx # 每组唯一 seed
tag_sql = term.tree_to_sql(tree, seed=tree_seed, kind_override="TAG")
numeric_sql = term.tree_to_sql(tree, seed=tree_seed, kind_override="NUMERIC")
bool_sql = term.tree_to_sql(tree, seed=tree_seed, kind_override="BOOL")
string_sql = term.tree_to_sql(tree, seed=tree_seed, kind_override="STRING")关键细节 :4 次 tree_to_sql 传入同一个 tree_seed 。因为 tree_to_sql 开头会 self.rng = random.Random(seed),每次调用 rng 状态完全一致------于是:
<INT_LIT>、<OP_REL>、<FN_AGG_NUM>、<ALIAS_ID>等非列槽终结符在 4 次遍历中抽到完全相同的值;- 只有列槽和
<TAG_VALUE>因kind_override分支而产出不同字面量(绕开 rng,直接查KIND_COLUMN/KIND_LITERAL表)。
乘子 1_000_003 是一个大质数,作用是把 base_seed 与 tree_idx 两个维度"拉开距离",避免两个组意外拿到相近的 seed 值导致 rng 状态趋同。
为什么要"每棵树重置 rng"而不是"全局递增"
一个似乎更自然的实现是:在 Terminalizer 里全局保留一个 rng,按遍历顺序往下抽。但这样做有两个问题:
- 不可复现单棵树:要重现第 500 棵树的 SQL,必须从头遍历 499 棵树耗尽 rng,否则状态对不上;
- Phase B 无法做到"非列槽终结符一致" :4 次
kind_override遍历本是对同一棵树做 4 次,但如果 rng 全局延续,第二次遍历时 rng 状态已经被第一次耗光,非列槽终结符的抽取结果就会漂移,metamorphic 等价类彻底失效。
因此工程实现严格遵守"一次 tree_to_sql 调用 = 一次 rng 重置 "的契约。副作用是浅层树在相邻 seed 间有一定重复(seen_plain 去重能兜底);收益是 metamorphic 等价类的每个非列槽终结符都按位对齐。
Seed 值的可复现保证
整个生成管线的 seed 来源链如下:
用户 CLI:
--seed 42 (args.seed: depth-bounded 采样结构)
--seeds 42,100,200 (args.seeds: terminalizer base_seed 列表)
│ │
▼ ▼
pec.depth_bounded_enumeration( trees_to_sqls(base_seed=s)
seed = args.seed + d * 131) → term.tree_to_sql(tree, seed = s + i)
│ │ │
▼ ▼ ▼
结构采样 rng batch rng 每棵树 rng- 结构采样 (派生树的产生式选择)由
args.seed + depth * 131驱动; - 终结符实例化 由
base_seed + tree_index(Phase A)或base_seed * 1_000_003 + tree_idx(Phase B)驱动; - 两层完全独立,一层 seed 不变时另一层也 100 % 复现。
这意味着:给定相同的 --seed / --seeds / --depths / --max-trees / --max-metamorphic-groups,两次 generate.py 调用一定输出字节级相同的 <out>.sql + <out>.sql.meta.jsonl 。这是差分测试回归对比的根基------否则同一个 bug 在两次运行中出现在不同行号,.sql 的 diff 就是噪声的海洋。
一个具体例子
派生树:
SELECT <FN_AGG_NUM>(<NUMERIC_FIELD>) FROM m
WHERE <TAG_KEY> <OP_REL> <TAG_VALUE>
# Phase A,base_seed=42,tree_idx=7 → seed=49
rng = Random(49)
<FN_AGG_NUM> → r.choice(AGG_NUMERIC) = "mean"
<NUMERIC_FIELD> → r.choice(NUMERIC_FIELDS) = "cpu"
<TAG_KEY> → r.choice(TAG_KEYS) = "host"
<OP_REL> → r.choice(REL_OPS) = "!="
<TAG_VALUE> → (k = r.choice(TAG_KEYS) = "host";
r.choice(TAG_VALUES["host"]) = "host2")
→ SELECT mean("cpu") FROM "m" WHERE "host" != 'host2'
# Phase B,base_seed=42,tree_idx=7 → tree_seed = 42 * 1000003 + 7 = 42000133
rng = Random(42000133) # 与 Phase A 不同
for kind in TAG, NUMERIC, BOOL, STRING:
rng 重置为 Random(42000133) # 4 次调用全部重置到同一状态
# 因此 <FN_AGG_NUM>/<OP_REL> 四次都抽到同一个值,例如:
<FN_AGG_NUM> → "count" # 全组 4 条都是 count
<OP_REL> → "=" # 全组 4 条都是 =
# 列槽与 <TAG_VALUE> 走 kind_override 分支:
TAG 变体: count("host") = 'host0'
NUMERIC 变体: count("cpu") = 50
BOOL 变体: count("status") = true
STRING 变体: count("info") = 'alpha'Phase A 的"mean / cpu / host / != / host2"与 Phase B 的"count / = / 4 kind"之间没有任何复用------两次调用从完全不同的 seed 起跳,彼此独立。但一次 Phase B 调用内部的 4 条变体完全对齐 ,这正是 metamorphic oracle 对比 XSTOR_OVER_ACCEPTS / CROSS_KIND_XSTOR_INCONSISTENT 等 finding 时最看重的等价性。
4.2.6 两种扇出模式在同一个 generate.py 里合流
同一份 Terminalizer 实例在工程侧衍生出两种互补 的 SQL 扇出方式,并且被合并到同一个 generate.py 调用的 Phase A / Phase B / Phase C 三段流程里:
Phase A:plain 模式(多 seed 扇出)
python
# generate.py 片段(简化)
plain_sqls = []
seen_plain = set()
for s in seeds: # 例如 [42]
for sql in trees_to_sqls(all_trees,
measurement=args.measurement,
base_seed=s): # kind_override=None
if sql not in seen_plain:
seen_plain.add(sql)
plain_sqls.append(sql)trees_to_sqls 内部对每棵树调用一次 tree_to_sql(tree, seed=...);每次 seed 不同,rng 重置后所有抽象终结符(字面量、函数、列)都重新独立采样 。seeds 数量通过 --seeds 42,100,... 控制。
以一个具体的树为例:
派生树:
SELECT <FN_AGG_NUM>(<NUMERIC_FIELD>) FROM m WHERE <TAG_KEY> <OP_REL> <INT_LIT>
└── seed=42 → SELECT sum("cpu") FROM "gd_select" WHERE "host" > 100
└── seed=100 → SELECT mean("mem") FROM "gd_select" WHERE "region" = 0
└── seed=200 → SELECT stddev("cpu") FROM "gd_select" WHERE "host" != 50放大机制是"一棵树 = 一个 SQL 模板 ":同一结构下,每个抽象终结符叶子独立走一次 rng.choice,组合空间是笛卡儿积。对一棵深度 10 含 ~20 个抽象终结符叶子、平均池大小 5 的树,理论展开空间 ≈ 5 20 ≈ 10 14 \approx 5^{20} \approx 10^{14} ≈520≈1014 条 SQL------实际按 seed 采样 + seen 去重,典型产出 10 万量级唯一 SQL。
Phase B:metamorphic 模式(4-kind 变体组)
Phase B 的实现集中在 _build_metamorphic_groups() 函数里:
python
# generate.py 片段(简化)
def _build_metamorphic_groups(trees, measurement, seeds,
max_groups, start_group_idx=0):
term = Terminalizer(measurement=measurement, seed=seeds[0])
out, seen_group_sigs = [], set()
group_idx = start_group_idx
for base_seed in seeds:
for tree_idx, tree in enumerate(trees):
if len(out) >= max_groups:
return out, group_idx
tree_seed = base_seed * 1_000_003 + tree_idx # 每组唯一 seed
# (1) TAG 变体:作为语义金丝雀
tag_sql = term.tree_to_sql(tree, seed=tree_seed,
kind_override="TAG")
if not term.saw_column_slot: continue # 无列槽的树跳过
ok, _ = is_semantically_valid(tag_sql)
if not ok: continue # TAG 非法的树跳过
# (2) 同 seed 派生其余 3 个 kind
variants = [("TAG", tag_sql)]; sqls_set = {tag_sql}
for k in ("NUMERIC", "BOOL", "STRING"):
sql = term.tree_to_sql(tree, seed=tree_seed,
kind_override=k)
variants.append((k, sql)); sqls_set.add(sql)
# (3) 退化组/重复组拒收
if len(sqls_set) == 1: continue
sig = tuple(s for _, s in variants)
if sig in seen_group_sigs: continue
seen_group_sigs.add(sig)
gid = f"mg_{group_idx:05d}"
group_idx += 1
out.append((gid, variants))
return out, group_idx关键:4 次调用用同一个 tree_seed------这意味着:
- 所有非列槽 终结符(
<INT_LIT>、<OP_REL>、<ALIAS_ID>、<DURATION_LIT>、函数名 ...)在 4 次 rng.choice 里抽到完全相同的值; - 只有列槽 (及跟随的
<TAG_VALUE>)因kind_override而变化。
得到的是"除列类型外全部等价"的 4 条 SQL------metamorphic 测试所必需的语义等价类:
派生树:
SELECT count(<FIELD_KEY>) FROM m WHERE <TAG_KEY> <OP_REL> <TAG_VALUE>
# 同一 tree_seed → OP_REL 四次都抽到 "="
TAG : SELECT count("host") FROM "gd_select" WHERE "host" = 'host0'
NUMERIC : SELECT count("cpu") FROM "gd_select" WHERE "cpu" = 50
BOOL : SELECT count("status") FROM "gd_select" WHERE "status" = true
STRING : SELECT count("info") FROM "gd_select" WHERE "info" = 'alpha'Phase B 通过三道"丢弃门"控制信噪比:saw_column_slot == False 的树丢弃(没有锚点)、TAG 变体 validator 不通过的树丢弃(整棵树本身就非法)、4 条变体塌陷成同一 SQL 的组丢弃(退化变体)。最终由 --max-metamorphic-groups(默认 2 000)封顶。
Phase C:interleave + 写 sidecar
python
# generate.py 片段(简化)
out_fh = open(args.out, "w")
meta_fh = open(args.out + ".meta.jsonl", "w")
# 先写 plain,每行对应 {"meta_group_id": null}
for sql in plain_sqls:
out_fh.write(sql + "\n")
meta_fh.write(json.dumps({"meta_group_id": None}) + "\n")
# 再写 metamorphic,每组 4 条连续,行行对应
# {"meta_group_id": "mg_00000", "meta_kind": "TAG"} ...
for gid, variants in meta_groups:
for kind, sql in variants:
out_fh.write(sql + "\n")
meta_fh.write(json.dumps(
{"meta_group_id": gid, "meta_kind": kind}) + "\n")这份 sidecar 是整条管线的关键黏合剂 :下游 run_diff_all.py 启动时按行号对齐读取,把 plain 和 metamorphic 组分流------plain 走单条差分 Oracle,metamorphic 组按 meta_group_id 缓冲 4 条变体,全部跑完后调用 metamorphic_oracle.evaluate(stmt_type, variants_by_kind, group_id)。
执行端 (run_diff_all.py)
─────────────────────────────
for i, sql in enumerate(sqls):
meta = sidecar[i] # {"meta_group_id": ..., "meta_kind": ...}
rec = run_diff(sql) # 双端并行执行
if meta["meta_group_id"] is None:
emit(rec) # plain 路径
else:
buffer[meta["meta_group_id"]][meta["meta_kind"]] = rec
if len(buffer[group_id]) == 4: # 组内 4 条都齐了
findings = metamorphic_oracle.evaluate(
stmt_type, buffer[group_id], group_id)
emit_findings(findings) # metamorphic 路径metamorphic_oracle.py 独立成模块,产出 6 类结构化 bug 签名:XSTOR_OVER_ACCEPTS / XSTOR_REJECTS_VALID / XSTOR_DELETE_SILENT_FAIL / XSTOR_DELETE_OVER_DELETES / XSTOR_FIELD_DELETE_AS_TAG / CROSS_KIND_XSTOR_INCONSISTENT。
两种扇出对比
| 维度 | Phase A (plain) | Phase B (metamorphic) |
|---|---|---|
| 起点 | 同一份派生树池 | 同一份派生树池(结构签名再去重) |
| 非列槽终结符 | 每 seed 重新采样 | 同一 tree_seed 内冻结 |
| 列槽终结符 | 按 seed 随机采样 | 4 变体强制 TAG/NUM/BOOL/STR |
| 扇出倍数 | × seeds 数量 | × 4 kinds |
| 典型规模 | 约 10 万条 unique SQL | ≤ 2 000 组 × 4 = ≤ 8 000 条 |
| 丢弃条件 | 字符串去重 | 无列槽 / TAG 语义非法 / 4 变体塌陷 |
| 输出行元信息 | {"meta_group_id": null} |
{"meta_group_id": "mg_xxxxx", "meta_kind": "..."} |
| Oracle 粒度 | 单条 SQL 双端对比 | 组内跨 kind 结构化关系对比 |
| Oracle 实现 | run_diff_all.py 内联 |
metamorphic_oracle.evaluate() 独立模块 |
| 产出 bug 类型 | 正确性 / 宽严分歧 / crash | Tag/Field 错位 / field 条件被忽略 / 静默失败 |
为什么把 metamorphic 合并进 PEC 实例化阶段是架构升级
历史上 metamorphic 走过两条弯路:
- 最早:手工 SQL 模板(13 模板 × 4 kind = 52 变体)。场景覆盖全靠人想,与文法演进脱钩。
- 中期 :独立的
run_metamorphic_pec.py脚本。生成端和执行端都各自复制一份 terminalizer 逻辑,语料版本与 plain 差分跑批对不齐。
当前架构 把 metamorphic 完全融进 generate.py,好处有三:
- 一次调用同时产出两路语料 :plain 和 metamorphic 共用同一棵派生树 + 同一个
Terminalizer实例,版本绝对一致; - Sidecar 解耦生成端与执行端 :
<out>.sql.meta.jsonl让run_diff_all.py无需关心 metamorphic 是怎么生成的,只要"按行号查 meta"即可; - Oracle 模块化 :
metamorphic_oracle.py独立成包,输入输出契约明确(stmt_type+variants_by_kind+group_id→findings),可以被任何需要 4-kind 关系检查的脚本复用,也方便单元测试。
核心理念不变 :metamorphic 不是独立的测试层,而是在 PEC 终结符实例化阶段启用的"Oracle 变换" 。关掉 --no-metamorphic 就是普通差分测试;开着就是 metamorphic 测试。这种融合保留了论文 PEC 的数学覆盖保证,同时把类型/Tag/Field 专属 Oracle 免费接入。
4.2.7 血统可追溯
最终每一条可执行 SQL 的血统清晰:
- 哪条产生式覆盖(PEC / 深度采样);
- 哪个 seed 具体化 (Phase A: base_seed;Phase B:
tree_seed = base_seed × 1 000 003 + tree_idx); - 哪个 kind 绑定(Phase B only:TAG / NUMERIC / BOOL / STRING);
- 哪条 validator 通过(SELECT 24 / SHOW 6 / DELETE 6 条方言语义规则);
- 属于哪个 meta_group_id (sidecar
.meta.jsonl中的行号对齐关系)。
所有信息写进 jsonl,便于 bug 定位、回归测试和消融实验。
4.3 本方法与论文的差异
| 维度 | 论文(Rossouw-Fischer 2023) | 本方法 |
|---|---|---|
| SUT 假设 | 纯 parser(CFG 为唯一规范) | TSDB(parser + analyzer + planner + storage) |
| 正例定义 | CFG 可派生即正例 | CFG 可派生 ∧ 方言 validator 全部通过 |
| LR 图递归处理 | BFS flooding,对递归文法会爆炸 | 五重防线(PEC + shortest + depth budget + 深度采样 + 文法收紧) |
| 终结符化 | 通用空白规则 | 方言词法感知 的粘合规则 (_GLUE_BEFORE_LPAREN) |
| 列槽处理 | 无此概念,所有 <VAR> 等价 |
列槽分类 + kind_override 钩子,支持类型感知与 metamorphic 变体 |
| Oracle | accept/reject 单一 oracle | 多条 Oracle 分支:一对一差分 + 跨变体 metamorphic + sandbox+verify + CRASH 自愈 |
| 负例构造 | edge/stack mutation + witness | 默认不启用(差分场景信噪比低);依赖正例里的宽严分歧 |
| 失败诊断 | 只能看"是否被接受" | 每层 drop 计数 + 跨 kind 关系 + verify 查询物理状态 |
| 领域适配 | 换一种文法需重写 CFG | 同一 CFG + 不同 validator + 不同 Oracle 分支,换方言只需替换这两个 |
| 有效样本率 | 在 InfluxQL 上 ~3.4 % | 在 InfluxQL plain 通道上 ~85 %(BOTH_ERROR 15.7 %);metamorphic 通道经 TAG 变体 validator 筛选后接近 100 % |
一句话概括 :论文方法是一个生成器 ;本方法把它升级为一条从文法到可执行 SQL 到跨类型 Oracle 的完整差分测试流水线 ------并且 plain 与 metamorphic 在同一个 generate.py 调用里一次产出,通过 sidecar .meta.jsonl 与下游 run_diff_all.py + metamorphic_oracle.py 串成闭环。
五、解空间量化分析
从 LR 图的理论解空间出发,经过三次剪枝,最终得到实际跑批的 SQL 规模。
5.1 第一层:LR 图理论解空间(递归不设限)
深度有界派生树数 ∣ T d ( G ) ∣ |T_d(G)| ∣Td(G)∣:深度 ≤ d 的合法派生树总数。对 InfluxQL grammar(|P|=148、|N|=44、|T|=76):
T ( A , d ) = ∑ A → α ∈ P ∏ X ∈ α { 1 X terminal T ( X , d − 1 ) otherwise T(A, d) = \sum_{A \to \alpha \in P} \prod_{X \in \alpha} \begin{cases} 1 & X \text{ terminal} \\ T(X, d-1) & \text{otherwise} \end{cases} T(A,d)=A→α∈P∑X∈α∏{1T(X,d−1)X terminalotherwise
递归爆炸点:
measurement → (select_stmt)形成 T ( select_stmt , d ) ≈ c ⋅ T ( select_stmt , d − 1 ) T(\text{select\_stmt}, d) \approx c \cdot T(\text{select\_stmt}, d-1) T(select_stmt,d)≈c⋅T(select_stmt,d−1) 的指数增长;expr_bool / expr_arith / expr_atom / meta_where四条右递归叠加;function_call::transform(inner_numeric ...)嵌套聚合。
| 深度 d | 结构树数 | 量级 |
|---|---|---|
| ≤ 5 | ~5 600 | 扁平 SELECT |
| ≤ 7 | ~490 000 | expr_arith 两层嵌套 |
| ≤ 10 | ∼ 1.3 × 10 28 \sim 1.3 \times 10^{28} ∼1.3×1028 | 双层子查询 + 深嵌套 expr |
| ≤ 15 | ∼ 10 57 \sim 10^{57} ∼1057 | 无实际意义的超深结构 |
加上终结符实例化 。每棵深度 10 的树通常含约 20 个抽象终结符叶子,平均池大小 k ˉ ≈ 5 \bar k \approx 5 kˉ≈5,每棵树展开约 5 20 ≈ 10 14 5^{20} \approx 10^{14} 520≈1014 条 SQL。
| 深度 d | 结构 × 实例化 | 量级 |
|---|---|---|
| ≤ 5 | ≈ 5.1 × 10 8 \approx 5.1 \times 10^8 ≈5.1×108 | 5 亿 |
| ≤ 7 | ≈ 9.2 × 10 13 \approx 9.2 \times 10^{13} ≈9.2×1013 | 92 万亿 |
| ≤ 10 | ≥ 10 40 \geq 10^{40} ≥1040 | 宇宙级 |
结论 :理论解空间无限 ,深度 10 已经是 10 40 10^{40} 1040 量级,任何有限测试集除以它都趋于 0。
5.2 第二层:五重防线剪枝后的派生树空间
PEC 按产生式生成 + shortest 填充 + context 深度预算 + 深度有界采样 + 文法收紧,实际采样参数:
PEC : 148 棵(确定性)
depth=5 采样 : 15 000 棵
depth=10 采样 : 15 000 棵
depth=15 采样 : 15 000 棵
─────────────────────────────
独立派生树 ≈ 45 300 棵 (trees)解空间规模压缩:
- 原始理论空间(d=10): ∼ 10 40 \sim 10^{40} ∼1040 条;
- 递归限制后派生树:45 300 棵;
- 压缩比: 10 40 / 4.5 × 10 4 ≈ 2 × 10 35 10^{40} / 4.5 \times 10^4 \approx 2 \times 10^{35} 1040/4.5×104≈2×1035------五重防线砍掉了 35 个数量级。
覆盖率保证:
- 148 / 148 产生式覆盖 = 100 %(PEC 构造定理);
- 97 / 97 Pop 边覆盖 = 100 %;
- 360 / 360 Push 边覆盖 = 100 %。
砍了 10³⁵ 个数量级,LR 图结构覆盖率仍是 100 %------这正是 PEC 的数学保证。
5.3 第三层:PEC 树实例化(同一个 generate.py 调用同时产出两路)
派生树池进入 terminalizer,按 Phase A / Phase B 两条路径在同一次生成调用中一并扇出。两路共享派生树池,但 Oracle 粒度不同。
Phase A:plain 通道(多 seed 扇出)
45 300 棵派生树 × --seeds 数量
─────────────────────────────
候选 SQL 总数 依 seeds 数量线性放大
字符串签名去重
─────────────────────────────
去重后 unique SQL 典型取 10 万量级(本文基线 168 509 条)放大机制:每棵树 = 一个 SQL 模板,每个 seed 各自对所有抽象终结符叶子独立采样。放大倍数取决于树的叶子数和池大小乘积。浅层树(叶子少)多 seed 下易重复;深层树几乎必然产出多条不同 SQL。
典型去重率约 25 %,说明浅层树有 seed 重复,大部分组合仍然新鲜。
PEC 派生树 → SQL 的量化放大链路
一棵 PEC 派生树到可执行 SQL 的转化本质是抽象终结符实例化的笛卡尔积采样。量化这条链路需要三个维度:每棵树有多少非终结符叶子、每个叶子的值池有多大、采样多少次(seed 数量)。
维度 1:每棵树的抽象终结符叶子数
关键字类终结符(<SELECT>、<FROM> 等 53 种)为 1:1 固定映射,不贡献组合数。真正贡献组合数的是字面量、函数、运算符、列槽四类非关键字叶子:
| 树深度 | 典型非关键字叶子数 | 代表结构 |
|---|---|---|
| ≤ 3 | 2--4 | SELECT * FROM m、SHOW MEASUREMENTS |
| 5 | 5--8 | SELECT fn(col) FROM m WHERE tag = val |
| 10 | 10--15 | 含 GROUP BY + ORDER BY + 嵌套表达式 |
| 15 | 15--25 | 含子查询或多层函数嵌套 |
维度 2:各类抽象终结符的值池大小
| 类别 | 抽象终结符 | 池大小 k k k |
|---|---|---|
| 数值聚合函数 | <FN_AGG_NUM> |
7 |
| 任意聚合函数 | <FN_AGG_ANY> |
6 |
| 选择器函数 | <FN_SELECTOR> |
4 |
| 变换函数 | <FN_TRANSFORM> |
7 |
| 算术运算符 | <OP_ARITH> |
5 |
| 关系运算符 | <OP_REL> |
7 |
| 逻辑运算符 | <OP_LOGIC> |
2 |
| 整数字面量 | <INT_LIT> |
7 |
| 浮点字面量 | <FLOAT_LIT> |
5 |
| 字符串字面量 | <STRING_LIT> |
5 |
| 时间字面量 | <DURATION_LIT> |
9 |
| 正则字面量 | <REGEX_LIT> |
3 |
| 列槽(字段) | <FIELD_KEY> / <NUMERIC_FIELD> |
~4 |
| 列槽(标签) | <TAG_KEY> |
~3 |
| 标签值 | <TAG_VALUE> |
~5(按 key 分组) |
维度 3:单树展开空间与 seed 采样
一棵含 n n n 个非关键字叶子的树,理论展开空间为笛卡尔积:
∣ SQL ( t ) ∣ = ∏ i = 1 n k i |\text{SQL}(t)| = \prod_{i=1}^{n} k_i ∣SQL(t)∣=i=1∏nki
以一棵典型深度 10 的 SELECT 树为例:
SELECT <FN_AGG_NUM>(<NUMERIC_FIELD>) FROM m
WHERE <TAG_KEY> <OP_REL> <TAG_VALUE>
GROUP BY time(<DURATION_LIT>)
LIMIT <INT_LIT>该树有 7 个非关键字叶子: 7 × 4 × 3 × 7 × 5 × 9 × 7 = 185 220 7 \times 4 \times 3 \times 7 \times 5 \times 9 \times 7 = 185\,220 7×4×3×7×5×9×7=185220 条理论 SQL。而对含 20 个叶子、平均池大小 k ˉ ≈ 5 \bar{k} \approx 5 kˉ≈5 的深层树: 5 20 ≈ 10 14 5^{20} \approx 10^{14} 520≈1014------单棵树的展开空间就已经是"不可穷举"级别。
--seeds 参数决定每棵树实际采样几次。每个 seed 对应一次完整的 rng 重置,所有抽象终结符独立重新采样:
| seeds 配置 | 每棵树采样次数 | 45 300 棵树的候选上限 | 去重后典型产出 |
|---|---|---|---|
42(单 seed) |
1 | 45 300 | ~34 000 |
42,100,200(3 seeds) |
3 | 135 900 | ~102 000 |
42,100,200,300,400(5 seeds) |
5 | 226 500 | ~168 500(本文基线) |
整条链路的量化总结:
148 条产生式 ⏟ PEC 数学保证 → +采样 45 300 棵树 ⏟ 五重防线 → × 5 seeds 168 509 条候选 ⏟ 笛卡尔积采样+去重 → 36 条 validator 16 421 条可执行 ⏟ 语义过滤 \underbrace{148 \text{ 条产生式}}{\text{PEC 数学保证}} \xrightarrow{\text{+采样}} \underbrace{45\,300 \text{ 棵树}}{\text{五重防线}} \xrightarrow{\times 5 \text{ seeds}} \underbrace{168\,509 \text{ 条候选}}{\text{笛卡尔积采样+去重}} \xrightarrow{\text{36 条 validator}} \underbrace{16\,421 \text{ 条可执行}}{\text{语义过滤}} PEC 数学保证 148 条产生式+采样 五重防线 45300 棵树×5 seeds 笛卡尔积采样+去重 168509 条候选36 条 validator 语义过滤 16421 条可执行
各步放大/压缩比:
| 步骤 | 输入 | 输出 | 比率 | 机制 |
|---|---|---|---|---|
| PEC + 深度采样 → 派生树 | 148 产生式 | 45 300 棵树 | ×306 | 结构多样性扩展 |
| 派生树 × seeds → 候选 SQL | 45 300 × 5 = 226 500 | 168 509 条 | ×0.74 | 笛卡尔积采样 + 字符串去重 |
| 候选 SQL → 可执行 SQL | 168 509 条 | 16 421 条 | ×0.097 | 36 条 validator 语义过滤 |
| 端到端 | 148 产生式 | 16 421 条 SQL | ×111 | 覆盖 100% 产生式/Pop 边/Push 边 |
关键洞察:从 148 条产生式到 16 421 条可执行 SQL,端到端放大 111 倍 。其中结构多样性贡献了 306 倍放大,seed 实例化在去重后贡献 ×3.7,语义过滤压缩到 9.7%。整条链路的瓶颈不在组合空间(理论 10 14 10^{14} 1014/棵树),而在 validator 的语义过滤率------这也是提升有效样本率的主要优化方向。
Phase B:metamorphic 通道(_build_metamorphic_groups)
Phase B 的代码实现细节已在 4.2.6 节展开(函数 _build_metamorphic_groups 的完整代码、五道门机制、具体筛选样例)。此处仅从解空间量化角度分析该通道的规模特征。
解空间压缩链路
从派生树池到最终 metamorphic 变体组,经历五道门控的逐级过滤:
| 门 | 过滤条件 | 典型留存占比(累计) | 被过滤的树类型 |
|---|---|---|---|
| 门 2(无列槽) | saw_column_slot == True |
~70 % | SHOW / 纯常量 SELECT / 纯 * SELECT |
| 门 3(TAG 非法) | is_semantically_valid(tag_sql) |
~45 % | mean(tag) / sum(tag) / tag 用 < >= 的谓词 |
| 门 4(4 变体塌陷) | len(sqls_set) > 1 |
~44 % | 列槽被 glue 吃掉等边缘情况 |
| 门 5(组签名重复) | 组签名 tuple(sqls) 首次出现 |
~35 % | 浅层树跨 base_seed 的重复 |
45 300 × 35 % ≈ 15 800 条候选 → 经 --max-metamorphic-groups=2000 封顶后留下 2 000 组 = 8 000 条 SQL。
45 300 棵树 ⏟ 派生树池 → 5 道门 ∼ 15 800 组候选 ⏟ 35% 留存 → 封顶 2 000 组 ⏟ CLI 参数 → × 4 kinds 8 000 条 SQL ⏟ 最终产出 \underbrace{45\,300 \text{ 棵树}}{\text{派生树池}} \xrightarrow{\text{5 道门}} \underbrace{\sim 15\,800 \text{ 组候选}}{\text{35\% 留存}} \xrightarrow{\text{封顶}} \underbrace{2\,000 \text{ 组}}{\text{CLI 参数}} \xrightarrow{\times 4 \text{ kinds}} \underbrace{8\,000 \text{ 条 SQL}}{\text{最终产出}} 派生树池 45300 棵树5 道门 35% 留存 ∼15800 组候选封顶 CLI 参数 2000 组×4 kinds 最终产出 8000 条 SQL
这解释了 Phase B 规模 / Phase A 规模 ≈ 5 %------Phase B 的聚焦是 Oracle 密度而不是覆盖广度。
为什么要限制 metamorphic 的组合数
上面的留存率给了一个"大约还能剩 35 %"的粗估,而一旦把 --max-metamorphic-groups 拉到远超实际上限(让门 0 完全不生效)、同时把 --depths 5,10,15 --max-trees 15000 --seeds 42,100,200,300,400 一起开起来,真实产出会直接跳到下面这个量级:
[metamorphic] produced 25 669 variant groups (= 102 676 SQLs)
from 32 936 unique trees分类明细(按 stmt type):
| stmt type | 独立变体组 | 展开后 SQL 条数(× 4) |
|---|---|---|
| DELETE / DROP | 14 821 | 59 284 |
| SHOW | 7 322 | 29 288 |
| SELECT | 3 526 | 14 104 |
| 合计 | 25 669 | 102 676 |
上限从何而来 :32 936 棵去重派生树经 _build_metamorphic_groups 的 3 道核心过滤(saw_column_slot + is_semantically_valid(TAG) + 4 变体不塌陷/组签名不重复)后剩下 25 669 组,也就是 102 676 条 SQL。
为什么 DELETE 组数远超 SELECT :grammar.py 里 DELETE / DROP SERIES 的产生式虽然只有 ~5 条,但每条都必然出现在"WHERE 含列槽"的构造里(DELETE WITHOUT WHERE 会被收紧规则拦掉,太少),而且 DELETE 的 WHERE 支持 tag_or_time_pred 组合出 AND/OR 深嵌套,PEC + 深度采样下极易命中不同的结构签名。SELECT 反而因为 projection 部分结构变化多端,但带列槽 的仅占一部分(其他命中"仅函数 / 仅 *"的被门 2 过滤掉了)。
实际执行的时间代价 (按 run_diff_all.py 的典型参数估算:--sleep-ms 8;每条 SELECT/SHOW ~0.2s;每条 DELETE ~2s = sandbox-write + execute + verify + drop 四段):
| stmt type | SQL 数 | 单条平均耗时 | 子总耗时 |
|---|---|---|---|
| SELECT | 14 104 | 0.2 s | ~47 min |
| SHOW | 29 288 | 0.2 s | ~98 min |
| DELETE | 59 284 | 2.6 s | ~43 小时 |
| 合计 | 102 676 | --- | ~45 小时 |
DELETE 是主要成本 ,因为每条都需要 sandbox 写入约 11 520 个数据点 + DROP 清理。这就是为什么默认值选 --max-metamorphic-groups=2000------它大致对应 1 000 组 SELECT/SHOW + 1 000 组 DELETE ≈ 2 000 groups × 4 = 8 000 变体 ,runner 里再对 DELETE 部分按 --delete-limit=2500 裁一次,整个 Phase B 跑完约 40 分钟,与 plain 通道的跑批耗时相当。
结论:--max-metamorphic-groups 是为了把 Phase B 的 DELETE sandbox 成本控制在 plain 通道的同一数量级,而不是出于信号密度的考虑。DELETE 的破坏性操作 + 物理状态 verify 的四段时延决定了它无法像 SELECT/SHOW 那样线性放大。
如果真要跑全量 25 669 组,有两种可行方案:
- 把 DELETE 组的 sandbox 写入从 11 520 点降到 ~100 点 (改
prepare_data.generate_line_protocol的DURATION_POINTS)→ DELETE 单条降到 ~0.3 s → 全量 DELETE 约 5 小时,总耗时约 8 小时; - 分批跑 :先跑 2 000 组(当前默认),根据发现的问题决定是否扩展(
--max-metamorphic-groups 25700 --delete-limit 60000,分 2-3 轮)。
两种方案都保留"每组 4 变体对齐"的 Oracle 契约,区别只在"一次性跑"还是"窗口式跑"------封顶参数是为工程可执行性而非数学完备性服务的。
Phase B 紧接着 Phase C 写入同一个 <out>.sql 文件(plain 在前、metamorphic 组连续在后),并逐行写 <out>.sql.meta.jsonl,让下游可以按行号对齐识别每条 SQL 所属的 meta_group_id 与 meta_kind。
5.4 第四层:语义约束后的可执行解空间
Plain 通道:36 条 validator 过滤 + DELETE 降采样
Phase A 的 168 509 条候选 SQL 送入 36 条 validator(SELECT 24 + SHOW 6 + DELETE 6),按语句类型分发:
candidate (168 509) ──┬──► SELECT 候选 : ~140 000
│ └─► 24 条 validator → 5 944 条
├──► SHOW 候选 : ~15 000
│ └─► 6 条 validator → 8 477 条
└──► DELETE 候选 : ~13 509
└─► 6 条 validator → 16 368 条(展开后)
└── 降采样 --delete-limit=2000
→ 实跑 2 000 条
合计 plain 通道实跑 = 5 944 + 8 477 + 2 000 = 16 421 条Metamorphic 通道:TAG 金丝雀 + --max-metamorphic-groups 封顶
Phase B 的筛选在生成端就已经发生:
saw_column_slot == True→ 树有锚点;- TAG 变体过
validators.is_semantically_valid()→ 整棵树在这个 seed 下能落地; - 4 变体互不塌陷 → 组内确实能产生跨 kind 差异。
通过三道门的组 ≤ 2 000,每组 4 条,metamorphic 通道 ≤ 8 000 条。
run_diff_all.py 进一步对 DELETE 类 metamorphic 组按 --delete-meta-group-limit 再做降采样(避免破坏性写太多),但 SELECT/SHOW 组 100 % 保留。
综合语料规模
plain 通道实跑 = 16 421 条
metamorphic 通道实跑 = ≤ 8 000 条(典型 ~6 000 条)
─────────────────────────────
总 corpus 规模(文法驱动部分) ≈ 22 000 ~ 24 000 条加上 category_based/ 手工枚举 5 753 条,仓库完整 corpus ≈ 28 000 ~ 30 000 条。
5.5 三层空间对比总表
| 层次 | 规模 | 相对理论空间 | 覆盖保证 |
|---|---|---|---|
| 理论解空间(d=10) | ∼ 10 40 \sim 10^{40} ∼1040 | 100 %(定义) | --- |
| 派生树池(五重防线) | 45 300 棵 | 4.5 × 10 − 37 4.5 \times 10^{-37} 4.5×10−37 % | 148/148 产生式 + 97/97 Pop 边 = 100 % |
| 候选 SQL(Phase A 多 seed 具体化) | 168 509 | 1.68 × 10 − 35 1.68 \times 10^{-35} 1.68×10−35 % | 81/83 终结符实例 = 97.6 % |
| 可执行 SQL(plain 通道) | 16 421 | 1.64 × 10 − 36 1.64 \times 10^{-36} 1.64×10−36 % | 整体 BOTH_ERROR 15.7 % |
| metamorphic 变体(Phase B) | ≤ 8 000(≤ 2 000 组) | 8 × 10 − 37 8 \times 10^{-37} 8×10−37 % | 4-kind 笛卡儿积 = 100 %;TAG validator 金丝雀 |
| 跨变体 Oracle 断言数 | 约 6 × 组数 | --- | 结构化 data-safety 信号(6 类 finding) |
三个关键比率:
理论空间 : 派生树 : 候选 SQL : 可执行 SQL : metamorphic
10^40 : 4.5×10^4: 1.68×10^5: 1.64×10^4 : ≤ 8×10^310 35 倍 ⏟ 递归剪枝 → 3.7 倍 ⏟ 实例化 → 10 倍 ⏟ 语义过滤 → 0.5 倍 ⏟ metamorphic 聚焦 \underbrace{10^{35}\text{ 倍}}{\text{递归剪枝}} \;\to\; \underbrace{3.7\text{ 倍}}{\text{实例化}} \;\to\; \underbrace{10\text{ 倍}}{\text{语义过滤}} \;\to\; \underbrace{0.5\text{ 倍}}{\text{metamorphic 聚焦}} 递归剪枝 1035 倍→实例化 3.7 倍→语义过滤 10 倍→metamorphic 聚焦 0.5 倍
解读:
- 递归剪枝 靠 PEC + 五重防线------LR 图结构仍然 100 % 覆盖,不牺牲论文 PEC 的数学保证;
- 实例化 靠多 seed 扇出(Phase A),把一棵"SQL 模板"变成多条具体 SQL;
- 语义过滤 靠 36 条 validator,把"文法合法但引擎拒绝"的垃圾样本剔除;
- metamorphic 聚焦 靠 Phase B 的
kind_override+ TAG 金丝雀,把一棵树变成 4 条等价类变体,换取跨变体 Oracle 的高信息密度。
整条流水线在一次 generate.py 调用里 把语料从"宇宙级"( 10 40 10^{40} 1040)压到"2.2 万",并额外加挂 2 000 个 metamorphic 变体组,同时保证:
- 148 / 148 产生式至少被每条至少一次跑到;
- Tag/Field 4 种等价类都被完整覆盖;
- 每条 validator 的拦截率可单独统计;
- plain 与 metamorphic 由 sidecar
<out>.sql.meta.jsonl对齐,生成端与执行端解耦; - 生成端和执行端的分离可做消融实验(
--no-metamorphic快速对比通道贡献)。
六、方法论总结
把本方法论按测试目标分层:
┌─────────────────────────────────────────────────────────────┐
│ L0 写路径差分 (line protocol) 未来方向 │
│ L1 Parser 归约覆盖 (PEC, 论文核心) grammar_driven │
│ L2 词法粘合 (_GLUE_BEFORE_LPAREN) terminalizer │
│ L3 方言语义 (36 条 validator) validators │
│ L4 类型 & Tag/Field (PEC-融合) generate.py:: │
│ _build_metamorphic_groups│
│ + metamorphic_oracle.py │
│ + sidecar .meta.jsonl │
│ L5 Oracle-free (TLP / NoREC / PQS) 推荐下一步 │
│ L6 破坏性操作 (sandbox + verify) run_diff_all │
│ L7 稳定性 (CRASH 自愈 + perf) CRASH 恢复已有 │
└─────────────────────────────────────────────────────────────┘每层独立产出 jsonl,generate_report.py 聚合。业界方法定位对照:
| 方法 | Oracle-free | 核心思路 | 本系统角色 |
|---|---|---|---|
手工枚举(category_based/) |
否 | 专家矩阵 | L4 保底 + parser 之外 |
| Rossouw-Fischer PEC | 否 | 文法覆盖 | L1 骨架 |
| 本方法三层约束 | 否 | PEC + lexer + semantic | L1-L3 可执行 |
| PEC-融合 metamorphic | 否 | kind_override + sidecar + metamorphic_oracle.evaluate() |
L4 Tag/Field 等价类 |
| SQLancer-TLP | ✓ | 三元分区等价 | L5 谓词 bug |
| SQLancer-NoREC | ✓ | 参考引擎构造等价 | L5 optimizer bug |
| SQLancer-PQS | ✓ | pivot-row 包含 | L5 边界值 |
| Jepsen | ✓ | 故障注入 | L7 分布式 |
6.1 三条核心原则
回头看整套方法论,有三条原则贯穿始终:
原则 1:把论文的"文法合法即正例"解耦成"文法合法 + 语义合法 + 类型合法 + 物理状态合法"。
每一条合法性检查有独立位置、独立可观测性、独立可关闭:
- 文法:在
grammar.py的收紧产生式里; - 语义:在
validators.py的 36 条规则里; - 类型:在
terminalizer.py的列槽分类 +kind_override里; - 物理状态:在
run_diff_all.py的 sandbox + verify 两段比较里。
原则 2:metamorphic 不是独立的测试层,而是 PEC 实例化阶段的"Oracle 变换"开关。
工程落地体现在三个地方:
- 生成端 :
generate.py的 Phase B_build_metamorphic_groups与 Phase A plain 并列,共享派生树池和Terminalizer实例。--no-metamorphic可一键关闭。 - 对齐机制 :sidecar
<out>.sql.meta.jsonl按行号标注meta_group_id+meta_kind,让生成端和执行端彻底解耦------生成换策略不用动 runner。 - Oracle 端 :
metamorphic_oracle.py独立模块,契约明确(stmt_type, variants_by_kind, group_id) → findings,6 类结构化 bug 签名。run_diff_all.py只负责按meta_group_id缓冲 4 条变体、四条到齐后调evaluate()。
同一套 PEC 生成管线上,关闭 metamorphic 就是普通差分测试(覆盖广度),开启就是 metamorphic 测试(类型等价类精确打击)。两种模式共享派生树池,物理产出 SQL 各异,Oracle 类型互补。
原则 3:剩余 BOTH_ERROR 不是必须消灭的噪音,而是"两端一致拒绝"的兼容性证据。
15.7 % 的 BOTH_ERROR 中 98 % 集中在 SHOW 支路(meta_pred 的 tag 运算符),通过一轮语法收紧即可降到 < 5 %。剩下的 0.5 % 本身就是 oracle 自洽性证据------两端一致拒绝等于达成"都不支持这类语法"的兼容性保证。过度压缩 BOTH_ERROR 反而会屏蔽真实 bug:比如"只有 xstor 失败"的签名一旦写入 validator 就被遮蔽。
6.2 一句话结论
把 CFG 视作语法规范,把 validator 视作语义规范,把
kind_override+ sidecar.meta.jsonl+metamorphic_oracle视作类型等价类 Oracle,把 sandbox + verify 视作物理状态 Oracle,把 CRASH 自愈视作差分测试基础设施。把 parser 层的 PEC 正例当作这些 Oracle 的"原材料",而不是"最终测试用例"。
当前仓库从 10 40 10^{40} 1040 的理论空间出发,用五重防线砍到 45 300 棵派生树,在一次 generate.py 调用中通过 Phase A 扇出约 17 万条 unique plain SQL、通过 Phase B 另外派生 ≤ 2 000 组 metamorphic 变体(≤ 8 000 条),再用 36 条 validator 把 plain 通道压到 ~1.6 万条可执行 SQL;Phase C 把两路写入同一个 <out>.sql + sidecar .meta.jsonl;下游 run_diff_all.py 按行号分流,plain 走单条差分 Oracle、metamorphic 走 metamorphic_oracle.evaluate() 的 6 类结构化签名。LR 图的 100 % 产生式/Pop 边/Push 边覆盖 + Tag/Field 4-kind 等价类 100 % 覆盖,由同一条生成管线一次性交付------这是整套方法论的数学内核,也是当前工程架构的核心升级。
参考文献:
- Rossouw & Fischer, Grammar-Based Test Suite Construction using Coverage-Directed Algorithms over LR-Graphs, SSRN 4423845 (2023)
- Rigger & Su, Testing Database Engines via Pivoted Query Synthesis (PQS), OSDI '20
- Rigger & Su, Finding Bugs in Database Systems via Query Partitioning (TLP), OOPSLA '20
- Rigger & Su, Detecting Optimization Bugs in DBMSs via Non-optimizing Reference Engine Construction (NoREC), FSE '20
- Kyle Kingsbury, Jepsen --- https://jepsen.io
- InfluxData, InfluxQL Reference