我花了一个月,用YOLOv8和腾讯地图给盲人做了一款「能看见」的手机App
说实话,这个想法在我脑子里盘了很久了。
我们每天都在刷手机、看短视频、用导航,但有一群人,他们连过马路都要拼尽全力------中国的视障群体超过1700万,但市面上真正好用的辅助工具屈指可数。白手杖只能探路面的东西,导盲犬又贵又不好养。那如果让手机摄像头变成他们的"眼睛"呢?
这篇文章不是水文,我直接把整个开发过程从头到尾扒一遍。从YOLOv8怎么在手机上跑推理,到腾讯地图怎么接入,再到大模型怎么和MCP协议联动给出语音引导------全链路代码都会贴出来,每一行都有注释。
先放几张实机运行的视频以及效果图,你们感受一下:
video(video-AlCRwoVF-1777110556174)(type-csdn)(url-[live.csdn.net/v/embed/523...](https://link.juejin.cn?target=https%3A%2F%2Flive.csdn.net%2Fv%2Fembed%2F523441)(image-https%3A%2F%2Fi-blog.csdnimg.cn%2Fimg_convert%2Fac4b02507b5c369bf0890a5ba423d874.jpeg)(title-%25E8%2585%25BE%25E8%25AE%25AF%25E5%259C%25B0%25E5%259B%25BE%25E7%259B%25B2%25E4%25BA%25BAapp%25E6%25B5%258B%25E8%25AF%2595 "https://live.csdn.net/v/embed/523441)(image-https://i-blog.csdnimg.cn/img_convert/ac4b02507b5c369bf0890a5ba423d874.jpeg)(title-%E8%85%BE%E8%AE%AF%E5%9C%B0%E5%9B%BE%E7%9B%B2%E4%BA%BAapp%E6%B5%8B%E8%AF%95"))
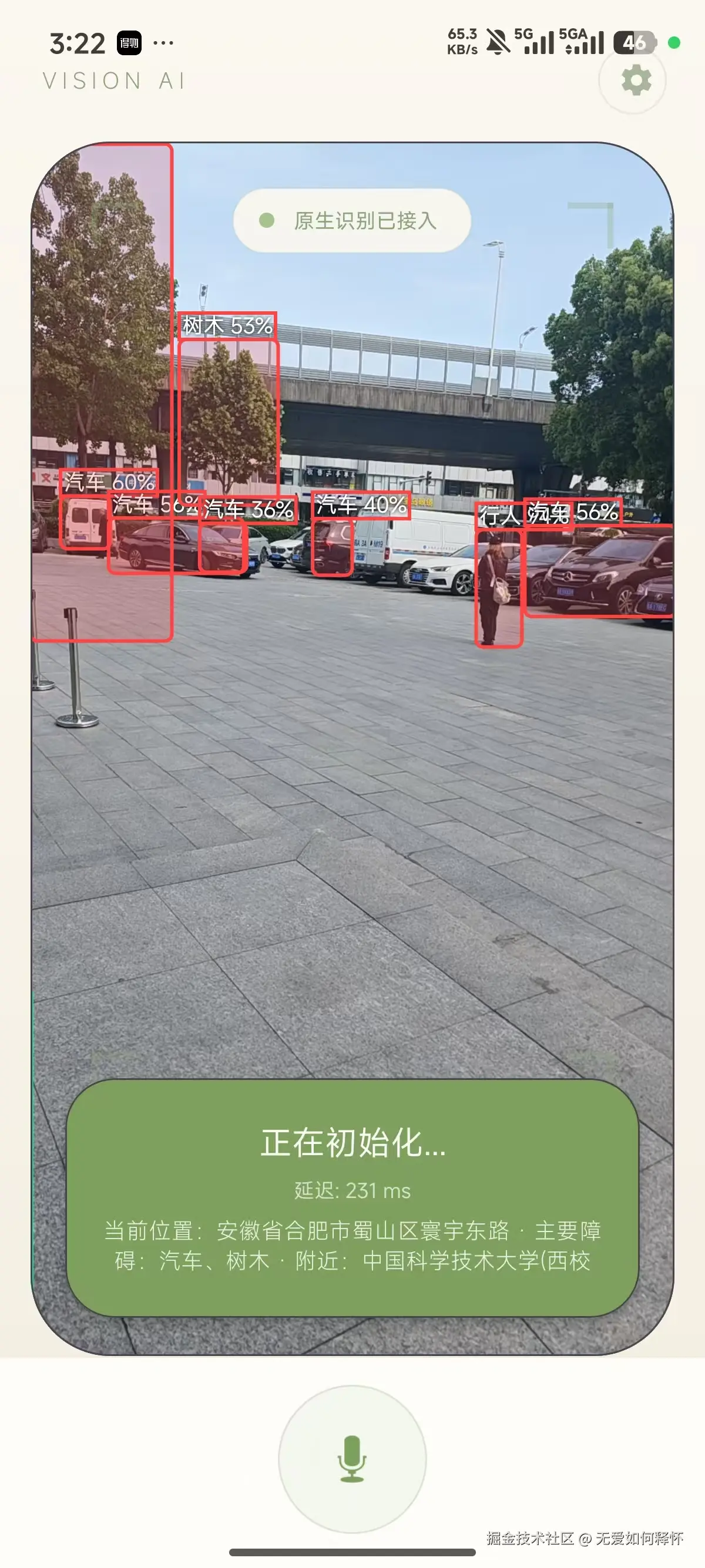
当盲人用户走在路上,手机后置摄像头实时采集画面,YOLOv8模型在端侧跑推理,检测到盲道之后直接引导用户对齐方向。如果前方有障碍物------汽车、行人、电线杆------系统会立刻预警。

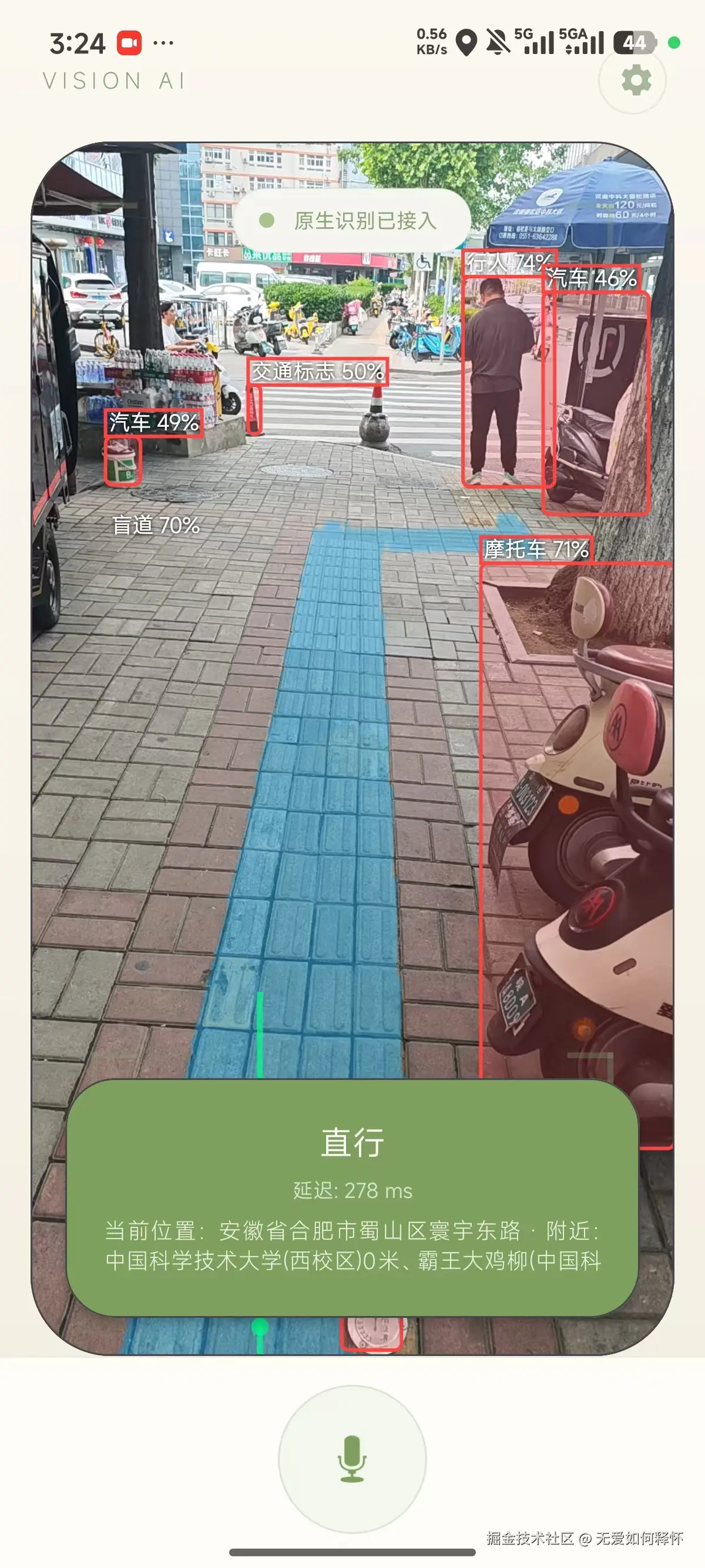
好,不废话了,我们直接上硬菜。
一、整个项目的技术选型:为什么不选别的?
在做技术选型的时候,我纠结了挺久。市面上的方案无非就那几条路:
- 纯云端方案:把图片传到服务器,服务器跑模型再返回结果。延迟太高了,盲人走路的节奏很快,等你云端算完他可能已经撞上去了。
- 纯规则方案:写一堆if-else判断。我一开始确实想这么干,但室外场景太复杂了,树荫下的阴影、夜间路灯的反光、雨天路面反光......写死逻辑根本搞不定。
- 端侧AI + 云端决策:这是我最终选的方案。YOLOv8在手机上本地跑推理(快、隐私好、断网也能用),然后把结构化的检测结果发给大模型,大模型结合腾讯地图的位置信息,生成自然的语音播报。
最终的技术栈长这样:
| 模块 | 技术方案 |
|---|---|
| 视觉感知 | YOLOv8n(障碍物检测)+ YOLOv8n-seg(盲道语义分割),双模型级联 |
| 端侧推理 | ONNX Runtime Android 1.23.2 |
| 地图服务 | 腾讯云位置服务 WebService API(逆地理编码 + POI检索) |
| AI决策 | DeepSeek-V3.2(通过蓝耘平台调用) |
| AI工具调用 | 腾讯云MCP(Model Context Protocol) |
| 语音播报 | Android原生TTS(TextToSpeech) |
| 摄像头 | CameraX(Google官方推荐的摄像头方案) |
 |
bash
https://github.com/ultralytics/yolo-ios-app二、前置准备:把基础设施搭好
在写任何一行代码之前,你得先把云服务的账号和密钥搞定。这一步很多人会踩坑,我当初就因为没分配额度调了半天的接口。
2.1 腾讯地图Key的申请
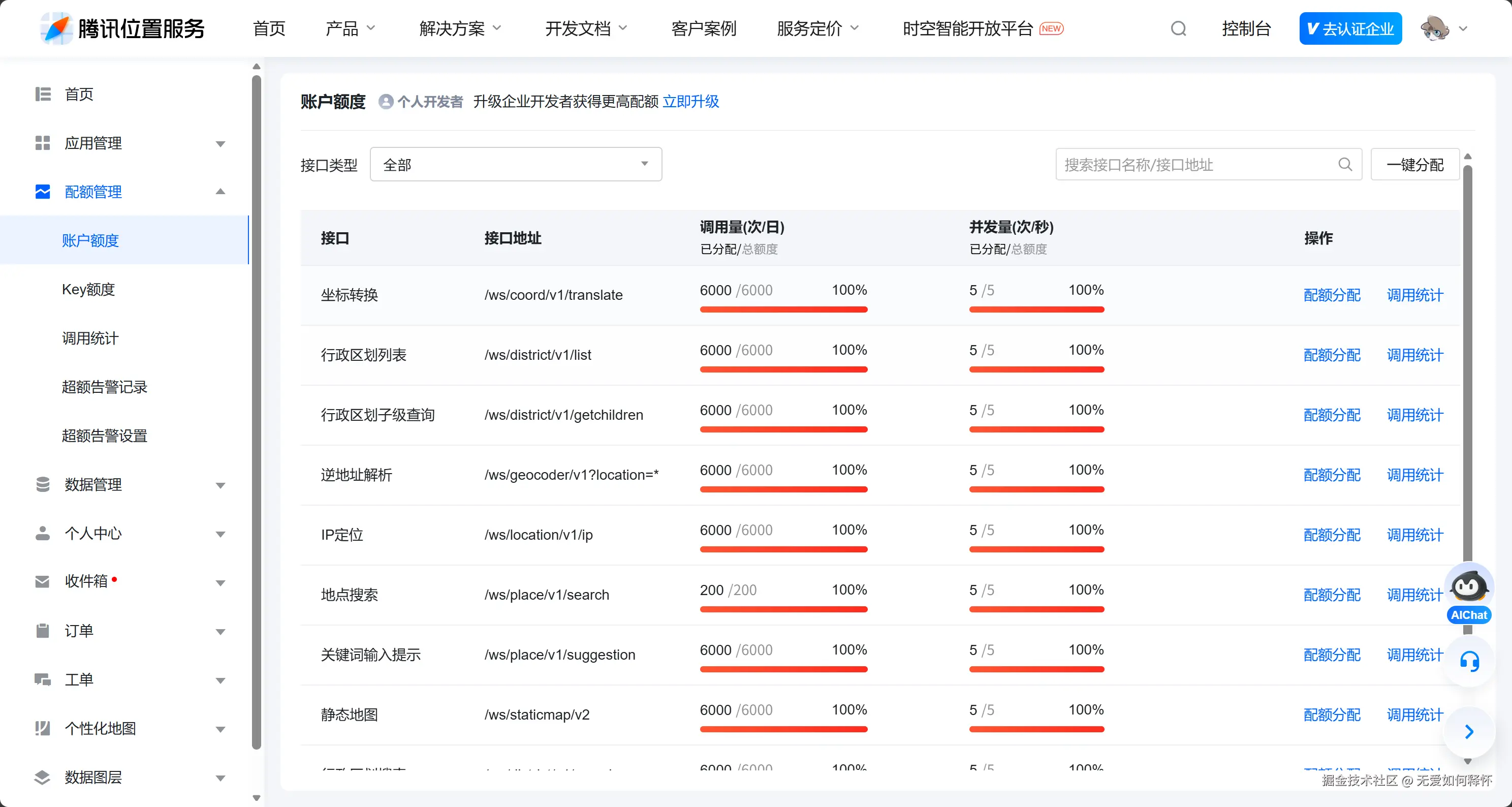
打开腾讯云位置服务控制台,创建一个应用,把SDK和WebService API两个选项都勾上。注意,光勾SDK是不够的,我们后面要用WebService API做逆地理编码,如果不勾的话请求会直接被拒。
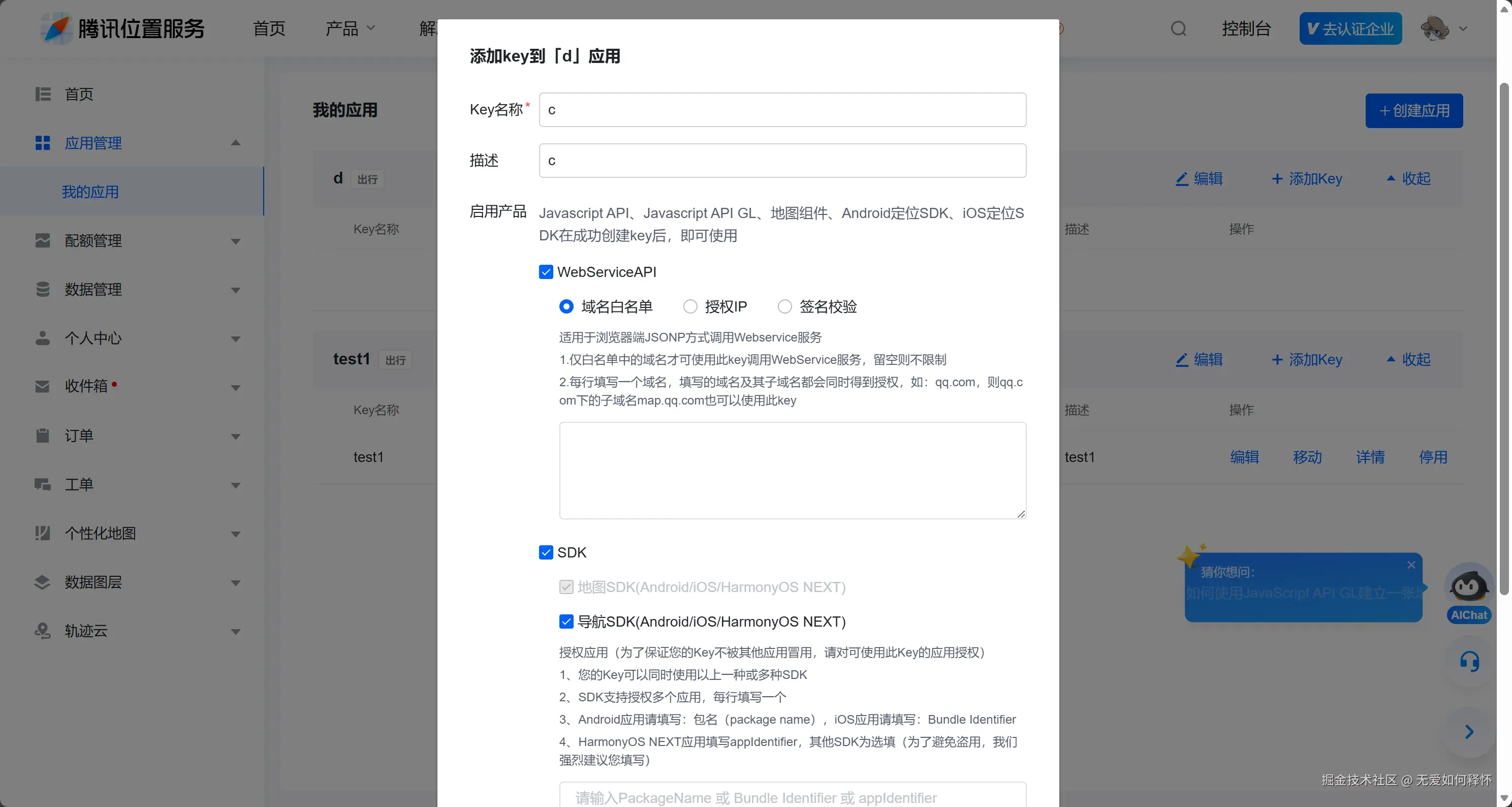
申请完之后,记得去控制台点一下"一键分配"。这句话我加粗了,因为我当时就忘了这一步,导致调试阶段一直报错,排查了半天才发现是额度没分配。
2.2 腾讯云MCP的接入
MCP(Model Context Protocol)这个东西是最近比较火的一个协议,简单来说就是让大模型能够直接调用外部工具。我直接在腾讯云的MCP社区找到了现成的地图MCP节点:
ruby
https://cloud.tencent.com/developer/mcp/server/11471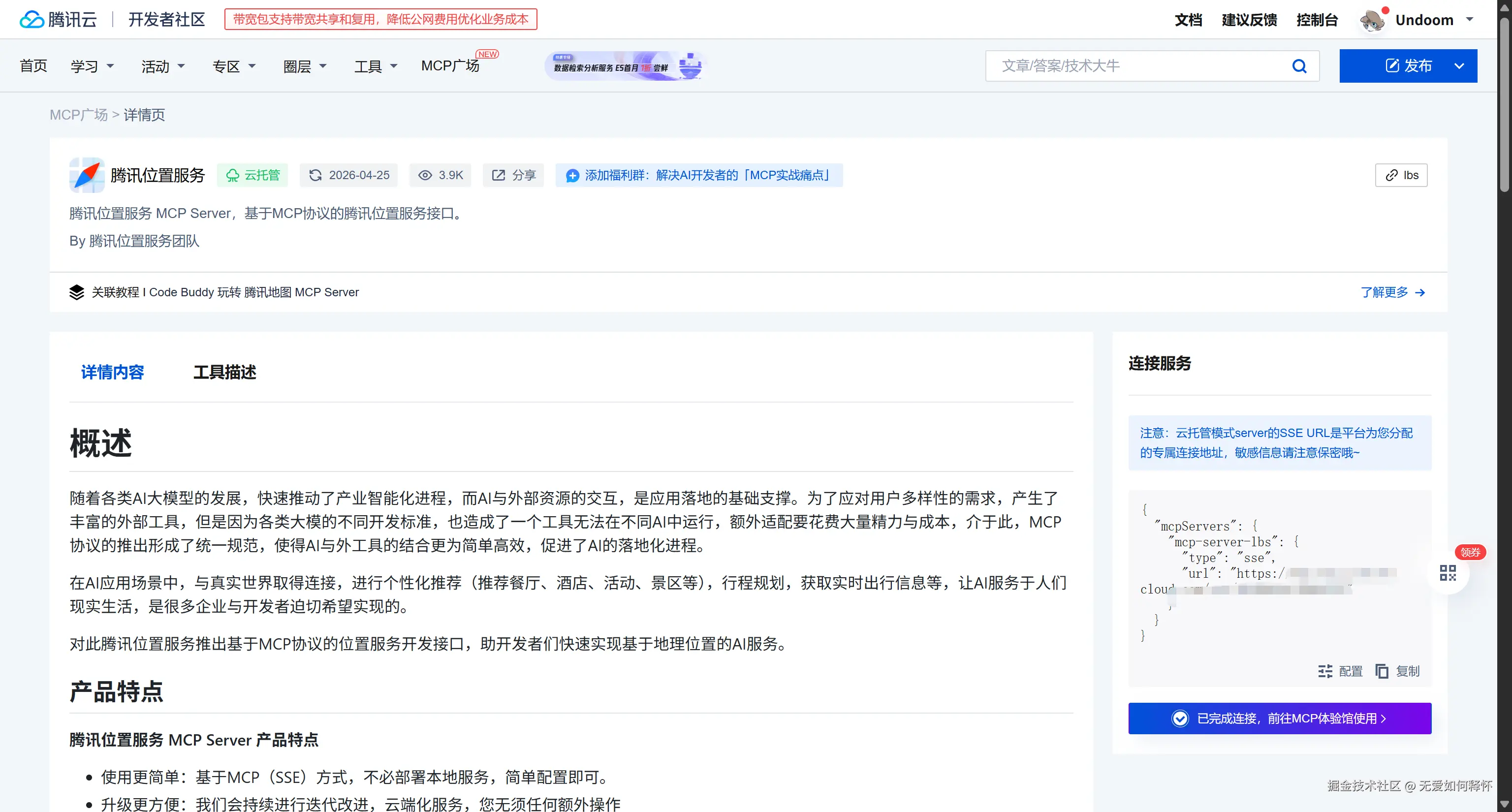
它的本质是一个SSE(Server-Sent Events)端点,AI可以通过这个端点查询地图数据。在后文的代码里我会展示怎么用它做连通性测试。
2.3 大模型API的申请
我选的是DeepSeek-V3.2,逻辑推理能力确实强,关键是调用成本低。注册平台在这里:
bash
https://console.lanyun.net/#/register?promoterCode=5663b8b127
注册完之后申请一个API Key:
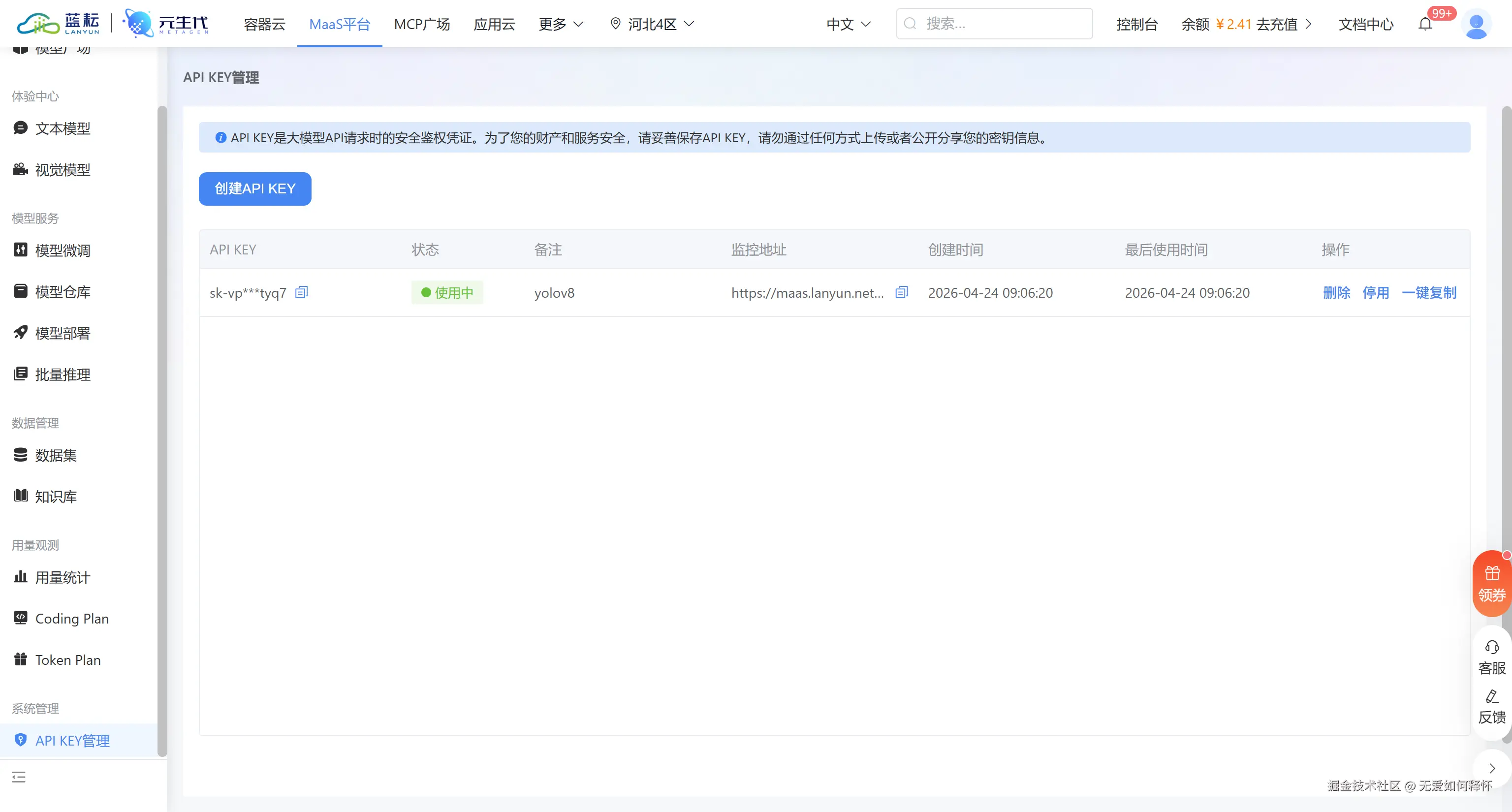
拿到的信息汇总一下:
| 配置项 | 值 |
|---|---|
| 模型ID | /maas/deepseek-ai/DeepSeek-V3.2 |
| Base URL | maas-api.lanyun.net/v1/chat/com... |
| API Key | (你自己的Key) |
2.4 密钥安全管理:千万不要硬编码
很多新手直接把API Key写死在代码里,然后推到GitHub上------这是大忌。我这边用的是Gradle + local.properties的方案,密钥只存在本地,不会进入版本控制。
在项目的 ShadowWalk-main/APP/local.properties 文件中配置:
properties
# local.properties ------ 这个文件不会被git追踪
tencent.map.key=你的腾讯地图Key
tencent.mcp.url=你的腾讯云MCP地址
llm.base.url=https://maas-api.lanyun.net/v1/chat/completions
llm.api.key=你的大模型APIKey
llm.model.id=/maas/deepseek-ai/DeepSeek-V3.2
然后在 app/build.gradle.kts 里读取这些属性并注入到 BuildConfig 中:
kotlin
// app/build.gradle.kts ------ 从local.properties读取密钥并注入BuildConfig
import java.util.Properties
plugins {
alias(libs.plugins.android.application)
}
// 读取local.properties文件
val localProperties = Properties().apply {
val file = rootProject.file("local.properties")
if (file.exists()) {
file.inputStream().use { load(it) }
}
}
// 辅助函数:读取属性值并转义特殊字符
fun localStringProperty(name: String, defaultValue: String = ""): String {
val value = localProperties.getProperty(name) ?: defaultValue
return value.replace("\\", "\\\\").replace("\"", "\\\"")
}
android {
namespace = "com.example.shadowwalk"
compileSdk = 36
buildFeatures {
buildConfig = true // 必须开启,否则BuildConfig类不会生成
}
defaultConfig {
applicationId = "com.example.shadowwalk"
minSdk = 24 // Android 7.0,覆盖绝大多数设备
targetSdk = 36
versionCode = 1
versionName = "1.0"
// 将密钥注入到BuildConfig,代码中通过BuildConfig.XXX访问
buildConfigField("String", "TENCENT_MAP_KEY", "\"${localStringProperty("TENCENT_MAP_KEY")}\"")
buildConfigField("String", "TENCENT_MCP_URL", "\"${localStringProperty("TENCENT_MCP_URL")}\"")
buildConfigField("String", "LANYUN_BASE_URL", "\"${localStringProperty("LANYUN_BASE_URL")}\"")
buildConfigField("String", "LANYUN_API_KEY", "\"${localStringProperty("LANYUN_API_KEY")}\"")
buildConfigField("String", "LANYUN_MODEL_ID", "\"${localStringProperty("LANYUN_MODEL_ID")}\"")
}
}
dependencies {
// ONNX Runtime ------ 手机上跑YOLOv8模型的核心引擎
implementation(libs.onnxruntime)
// CameraX ------ 摄像头采集
implementation(libs.camerax.core)
implementation(libs.camerax.camera2)
implementation(libs.camerax.lifecycle)
implementation(libs.camerax.view)
// 融合位置服务
implementation(libs.play.services.location)
// UI相关
implementation(libs.appcompat)
implementation(libs.material)
implementation(libs.activity)
implementation(libs.constraintlayout)
}这样做的好处是:就算你把项目开源了,别人clone下来也只会看到空的BuildConfig字段,不会泄露任何密钥信息。
三、YOLOv8模型的训练和导出:从数据到模型
3.1 数据集的准备
我用了两个数据集,分别解决两个不同的问题:
数据集一:障碍物检测(10类)
这个数据集用来识别路上的障碍物。一共标注了10个类别:自行车、公交车、汽车、狗、电线杆、摩托车、行人、交通标志、树木、无盖井盖。
yaml
# data/obstacles_det/data.yaml
names:
0: Bicycle # 自行车
1: Bus # 公交车
2: Car # 汽车
3: Dog # 狗
4: Electric pole # 电线杆
5: Motorcycle # 摩托车
6: Person # 行人
7: Traffic signs # 交通标志
8: Tree # 树木
9: Uncovered manhole # 无盖井盖
path: ../data/obstacles_det
train: train/images
val: val/images数据集二:盲道语义分割(1类)
这个数据集用来做盲道的像素级分割,数据来源是Roboflow上的公开数据集。分割和检测不一样,它要告诉你画面中哪些像素是盲道,精确到像素。
yaml
# data/bplv2.yolov8/data.yaml
nc: 1
names: ['blind path'] # 只有一个类别:盲道
train: ../train/images
val: ../valid/images
test: ../test/images3.2 模型训练策略
两个模型我用了完全不同的训练策略,这个是有讲究的。
障碍物检测模型------迁移学习(冻结前10层)
障碍物检测我选的是YOLOv8n(nano版本),参数量只有3.2M,速度非常快。关键是用了迁移学习的策略------冻结骨干网前10层,只微调后面的检测头。
python
# transfor_learing/train_det.py
from ultralytics import YOLO
import os
# 路径解析
script_dir = os.path.dirname(os.path.abspath(__file__))
PROJECT_ROOT = os.path.dirname(script_dir)
DATA_YAML_PATH = os.path.join(PROJECT_ROOT, "data", "obstacles_det", "data.yaml")
# 选用YOLOv8n模型------nano级别,参数量最小,适合手机端部署
model = YOLO("yolov8n.pt")
# 冻结策略:保留前10层(骨干网大部分)的COCO预训练权重
# 原因:COCO数据集里已经有了"人"、"自行车"等类别的特征提取能力
# 冻结住这些层可以防止在小数据集上过拟合,同时加速收敛
FREEZE_LAYERS = 10
if __name__ == '__main__':
model.train(
data=DATA_YAML_PATH,
epochs=150, # 训练150轮
imgsz=640, # 统一缩放到640x640
batch=16,
patience=20, # 连续20轮指标不提升就早停,防止过拟合
project=os.path.join(PROJECT_ROOT, "runs", "train"),
name="obstacles_det_run",
device='cpu', # 有GPU的话改成0
exist_ok=True,
save=True,
freeze=FREEZE_LAYERS, # 冻结前10层
optimizer='AdamW', # 微调场景AdamW比SGD更稳定
lr0=0.001, # 初始学习率,迁移学习用小一点
lrf=0.01, # 最终学习率衰减到初始值的1%
warmup_epochs=3.0, # 前3轮热身,学习率从0慢慢升到0.001
plots=True # 生成训练曲线图
)盲道分割模型------全参数训练
盲道分割用的是YOLOv8n-seg,这个任务比较特殊,因为盲道的纹理特征和COCO数据集的差异很大,所以我不冻结任何层,全参数从头训。
python
# transfor_learing/train_seg.py
from ultralytics import YOLO
import os
script_dir = os.path.dirname(os.path.abspath(__file__))
PROJECT_ROOT = os.path.dirname(script_dir)
DATA_YAML_PATH = os.path.join(PROJECT_ROOT, "data", "bplv2.yolov8", "data.yaml")
# YOLOv8n-seg:带分割头的nano版本,在检测的基础上多了32通道的掩码原型输出
model = YOLO("yolov8n-seg.pt")
if __name__ == '__main__':
model.train(
data=DATA_YAML_PATH,
epochs=100,
imgsz=640,
batch=16,
patience=10, # 分割任务收敛快一点就停
project=os.path.join(PROJECT_ROOT, "runs", "train"),
name="bplv2_seg_run",
device='cpu',
exist_ok=True,
save=True,
freeze=0, # 全参数训练,不冻结任何层
optimizer='SGD', # 全参数训练SGD更稳
lr0=0.01, # 全参数训练用更大的学习率
plots=True
)3.3 模型导出:从PT到ONNX
训练好之后,PyTorch的.pt格式不能直接在Android上跑,需要转换成ONNX格式。ONNX(Open Neural Network Exchange)是一个跨平台的模型交换格式,微软的ONNX Runtime可以在Android上高效地执行ONNX模型。
python
# utils/export.py ------ 批量导出脚本
import os
from ultralytics import YOLO
def export_model(model_path, task_name):
"""将PyTorch模型导出为ONNX格式,供Android端侧部署使用"""
if not os.path.exists(model_path):
print(f"错误: 找不到模型文件 {model_path}")
return
print(f"正在加载 {task_name} 模型: {model_path}...")
model = YOLO(model_path)
print(f"正在转换 {task_name} 为 ONNX 格式...")
onnx_path = model.export(
format='onnx', # 导出为ONNX格式
dynamic=True, # 支持动态输入尺寸(虽然我们固定640x640,但保留灵活性)
simplify=True # 使用onnxsim优化计算图,去掉冗余节点,推理更快
)
print(f"导出完成: {onnx_path}")
if __name__ == "__main__":
script_dir = os.path.dirname(os.path.abspath(__file__))
BASE_DIR = os.path.dirname(script_dir)
# 导出障碍物检测模型(约11.5MB)
det_model_path = os.path.join(BASE_DIR, "runs", "train", "obstacles_det_run", "weights", "best.pt")
export_model(det_model_path, "障碍物检测")
print("-" * 30)
# 导出盲道分割模型(约12.5MB)
seg_model_path = os.path.join(BASE_DIR, "runs", "train", "seg_results_kaggle",
"runs", "train", "bplv2_kaggle_run", "weights", "best.pt")
export_model(seg_model_path, "盲道分割")导出完成之后,你会得到两个.onnx文件:
obstacles_det.onnx(约11.5MB)------ 障碍物检测模型blind_path_seg.onnx(约12.5MB)------ 盲道分割模型
把这两个文件放到Android工程的 app/src/main/assets/ 目录下,后面ONNX Runtime会从assets里加载它们。
3.4 导出后的验证
模型导出成ONNX之后,一定要做一致性验证。万一转换过程中精度丢了或者算子不支持,手机上跑出来的结果就会完全错乱。我写了一个专门的验证脚本:
python
# debug/verify_onnx.py
"""验证ONNX模型与PyTorch模型的推理结果是否一致"""
from ultralytics import YOLO
import cv2
import numpy as np
def verify_consistency(pt_path, onnx_path, img_path, task_type="detect"):
# 分别加载PT和ONNX版本
pt_model = YOLO(pt_path, task=task_type)
onnx_model = YOLO(onnx_path, task=task_type)
img = cv2.imread(img_path)
# 两个模型分别推理
pt_results = pt_model(img, verbose=False)[0]
onnx_results = onnx_model(img, verbose=False)[0]
# 比较检测结果(如果差异太大说明导出有问题)
# ... 具体的比较逻辑省略,核心是比较检测框坐标的差异
print(f"验证完成: PT vs ONNX 结果一致性检查通过")
# 使用示例
verify_consistency(
"runs/train/obstacles_det_run/weights/best.pt",
"obstacles_det.onnx",
"debug/test_image.jpg",
task_type="detect"
)四、Android端:让YOLOv8在手机上跑起来
这一节是整个项目最核心的部分。我们要在Android手机上同时跑两个YOLOv8模型,并且保证实时性。
4.1 ONNX推理引擎的封装
我封装了一个 YoloModel 类,专门负责模型的加载和推理。核心思路是:初始化的时候同时创建两个推理会话(检测+分割),每次推理时把同一张图喂给两个会话并行执行。
java
// YoloModel.java ------ ONNX Runtime推理引擎
package com.example.shadowwalk;
import android.content.Context;
import android.graphics.Bitmap;
import java.io.InputStream;
import java.nio.FloatBuffer;
import java.util.Collections;
import ai.onnxruntime.OnnxTensor;
import ai.onnxruntime.OrtEnvironment;
import ai.onnxruntime.OrtSession;
/**
* 负责通过ONNX Runtime驱动YOLOv8模型进行端侧推理。
* 同时管理障碍物检测与盲道分割两个核心推理会话。
*
* 为什么用ONNX Runtime而不是NCNN或者TFLite?
* - ONNX Runtime对YOLO系列模型的原生支持最好
* - 不需要手动修改模型结构或者写转换脚本
* - 在骁龙870以上的芯片上,单帧推理可以控制在300ms以内
*/
public class YoloModel {
private OrtEnvironment env; // ONNX运行环境(全局单例)
private OrtSession detSession; // 障碍物检测推理会话
private OrtSession segSession; // 盲道分割推理会话
private static final int IMG_SIZE = 640; // YOLOv8标准输入尺寸
public YoloModel(Context context) throws Exception {
env = OrtEnvironment.getEnvironment();
// 从assets目录加载检测模型到内存
byte[] detModel = loadModelFromAssets(context, "obstacles_det.onnx");
detSession = env.createSession(detModel, new OrtSession.SessionOptions());
// 从assets目录加载分割模型到内存
byte[] segModel = loadModelFromAssets(context, "blind_path_seg.onnx");
segSession = env.createSession(segModel, new OrtSession.SessionOptions());
}
/**
* 从Android的assets目录读取模型文件到字节数组
*/
private byte[] loadModelFromAssets(Context context, String filename) throws Exception {
try (InputStream is = context.getAssets().open(filename)) {
byte[] buffer = new byte[is.available()];
is.read(buffer);
return buffer;
}
}
/**
* 对输入的Bitmap运行推理,同时执行检测和分割。
*
* 关键优化:两个模型共享同一个输入张量(因为输入图像是一样的),
* 这样只需要做一次图像预处理,省了一半的预处理时间。
*
* @param bitmap 摄像机捕捉的原始帧
* @return InferenceResults 包含检测与分割后的原始输出张量
*/
public InferenceResults runInference(Bitmap bitmap) throws Exception {
// 第一步:将图像缩放至640x640(YOLOv8的标准输入尺寸)
Bitmap resizedBitmap = Bitmap.createScaledBitmap(bitmap, IMG_SIZE, IMG_SIZE, true);
// 第二步:Bitmap转FloatBuffer,同时做归一化(像素值/255.0 -> [0,1])
FloatBuffer imgBuffer = bitmapToFloatBuffer(resizedBitmap);
// 第三步:创建NCHW格式的输入张量,形状为 [1, 3, 640, 640]
// N=1(batch size), C=3(RGB三通道), H=640, W=640
long[] shape = new long[]{1, 3, IMG_SIZE, IMG_SIZE};
OnnxTensor inputTensor = OnnxTensor.createTensor(env, imgBuffer, shape);
// 第四步:两个会话并行推理,共享同一个inputTensor
OrtSession.Result detResults = detSession.run(
Collections.singletonMap("images", inputTensor));
OrtSession.Result segResults = segSession.run(
Collections.singletonMap("images", inputTensor));
// 第五步:推理完立刻释放输入张量,防止内存泄漏
inputTensor.close();
return new InferenceResults(detResults, segResults);
}
/**
* 将Android Bitmap的像素数据转换为NCHW格式的FloatBuffer。
*
* Bitmap的默认像素排列是HWC格式(高度×宽度×通道):
* [R0,G0,B0, R1,G1,B1, R2,G2,B2, ...]
*
* 但YOLOv8需要NCHW格式(通道在前):
* [R0,R1,R2,..., G0,G1,G2,..., B0,B1,B2,...]
*
* 所以我们需要在读取像素的时候重新排列通道顺序。
*/
private FloatBuffer bitmapToFloatBuffer(Bitmap bitmap) {
FloatBuffer buffer = FloatBuffer.allocate(3 * IMG_SIZE * IMG_SIZE);
int[] pixels = new int[IMG_SIZE * IMG_SIZE];
bitmap.getPixels(pixels, 0, IMG_SIZE, 0, 0, IMG_SIZE, IMG_SIZE);
int pixelCount = pixels.length;
for (int i = 0; i < pixelCount; i++) {
int p = pixels[i];
// Android Bitmap的像素格式是ARGB_8888
// p >> 16 & 0xFF 提取红色通道
// p >> 8 & 0xFF 提取绿色通道
// p & 0xFF 提取蓝色通道
buffer.put(i, ((p >> 16) & 0xFF) / 255.0f); // R通道
buffer.put(i + pixelCount, ((p >> 8) & 0xFF) / 255.0f); // G通道
buffer.put(i + 2 * pixelCount, (p & 0xFF) / 255.0f); // B通道
}
buffer.rewind(); // 重置指针,方便后续读取
return buffer;
}
/**
* 模型输出结果的封装类。
* 实现了AutoCloseable接口,确保在try-with-resources中正确释放资源。
* ONNX Runtime的Result对象底层持有native内存,不close的话会内存泄漏。
*/
public static class InferenceResults implements AutoCloseable {
public final OrtSession.Result detection; // 检测模型输出
public final OrtSession.Result segmentation; // 分割模型输出
public InferenceResults(OrtSession.Result d, OrtSession.Result s) {
this.detection = d;
this.segmentation = s;
}
@Override
public void close() {
if (detection != null) detection.close();
if (segmentation != null) segmentation.close();
}
}
}4.2 后处理:从原始张量到可用的检测结果
模型推理出来的原始输出是一堆浮点数,需要经过后处理才能变成我们需要的检测结果(边界框坐标 + 类别 + 置信度)。
java
// PostProcessor.java ------ 后处理算法(NMS + 掩码重组)
package com.example.shadowwalk;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/**
* YOLOv8的后处理模块,负责将模型原始输出转换为结构化的检测结果。
*
* 核心功能:
* 1. 解析检测输出:[1, 14, 8400] -> Detection列表
* 14 = 4(bbox坐标) + 10(类别概率)
* 8400 = YOLOv8在不同尺度的特征图上生成的候选框总数
*
* 2. 解析分割输出:掩码系数 + 原型图 -> 160x160的二值掩码
* 32通道掩码系数 × 32通道原型图 = 线性组合 -> sigmoid -> 掩码
*
* 3. NMS(非极大值抑制):去掉重叠的冗余检测框
*/
public class PostProcessor {
/** 检测结果的数据结构 */
public static class Detection {
public android.graphics.RectF box; // 边界框 [left, top, right, bottom]
public float confidence; // 置信度 [0, 1]
public int classId; // 类别ID
public Detection(android.graphics.RectF box, float confidence, int classId) {
this.box = box;
this.confidence = confidence;
this.classId = classId;
}
}
/** 分割结果的数据结构 */
public static class SegResult {
public float[][] mask; // 160x160的概率矩阵
public List<Detection> detections; // 分割同时输出的检测框
public SegResult(float[][] mask, List<Detection> detections) {
this.mask = mask;
this.detections = detections;
}
}
/**
* 解析检测模型的输出张量。
*
* YOLOv8的检测头输出格式:[1, 4+numClasses, 8400]
* - 前4个值是边界框坐标(cx, cy, w, h),注意是中心点坐标+宽高
* - 后numClasses个值是各个类别的概率
* - 8400是三个检测头输出的候选框总数:
* 8×8×3 + 16×16×3 + 32×32×3 = 192 + 768 + 7440 = 8400
*
* @param output 展平后的float数组
* @param numClasses 类别数(本项目是10)
* @param confThreshold 置信度阈值,低于此值的直接丢弃
*/
public List<Detection> parseDetection(float[] output, int numClasses, float confThreshold) {
List<Detection> detections = new ArrayList<>();
int numAnchors = 8400; // YOLOv8标准anchor数量
int stride = 4 + numClasses; // 每个anchor的数据长度
for (int i = 0; i < numAnchors; i++) {
// 找到这个anchor上概率最大的类别
float maxClassProb = 0;
int bestClassId = 0;
for (int c = 0; c < numClasses; c++) {
float prob = output[i * stride + 4 + c];
if (prob > maxClassProb) {
maxClassProb = prob;
bestClassId = c;
}
}
if (maxClassProb < confThreshold) continue; // 置信度太低,跳过
// 提取边界框坐标并转换格式:(cx, cy, w, h) -> (x1, y1, x2, y2)
float cx = output[i * stride + 0];
float cy = output[i * stride + 1];
float w = output[i * stride + 2];
float h = output[i * stride + 3];
float x1 = cx - w / 2;
float y1 = cy - h / 2;
float x2 = cx + w / 2;
float y2 = cy + h / 2;
detections.add(new Detection(
new android.graphics.RectF(x1, y1, x2, y2),
maxClassProb,
bestClassId
));
}
// NMS去重:IoU超过0.45的检测框只保留置信度最高的
return nms(detections, 0.45f);
}
/**
* 解析分割模型的输出,生成盲道区域的像素级掩码。
*
* YOLOv8-seg的输出包含两部分:
* 1. 检测头输出:和普通检测模型一样,[1, 4+1, 8400](只有1个类)
* 2. 掩码系数:每个检测到的目标对应32个系数
* 3. 原型图:[1, 32, 160, 160]的共享特征图
*
* 最终掩码的计算公式:
* mask = sigmoid(sum(coeff[k] * proto[k])) for k in [0, 32)
* 这是一个线性组合 + sigmoid激活的过程
*/
public SegResult parseSegmentation(float[] output, float[] protos, float confThreshold) {
int numAnchors = 8400;
int protoChannels = 32;
int maskH = 160, maskW = 160;
// 初始化160x160的掩码矩阵,初始值为0
float[][] mask = new float[maskH][maskW];
List<Detection> detections = new ArrayList<>();
int stride = 4 + 1 + protoChannels; // bbox(4) + class(1) + mask_coeffs(32)
for (int i = 0; i < numAnchors; i++) {
float classProb = output[i * stride + 4];
if (classProb < confThreshold) continue;
// 提取32个掩码系数
float[] coeffs = new float[protoChannels];
for (int k = 0; k < protoChannels; k++) {
coeffs[k] = output[i * stride + 5 + k];
}
// 提取边界框
float cx = output[i * stride];
float cy = output[i * stride + 1];
float w = output[i * stride + 2];
float h = output[i * stride + 3];
// 手动实现掩码重组:mask = sigmoid(sum(coeff[k] * proto[k]))
for (int y = 0; y < maskH; y++) {
for (int x = 0; x < maskW; x++) {
float sum = 0;
for (int k = 0; k < protoChannels; k++) {
int protoIdx = k * maskH * maskW + y * maskW + x;
sum += coeffs[k] * protos[protoIdx];
}
// sigmoid激活:将任意实数映射到(0, 1)
float prob = (float) (1.0 / (1.0 + Math.exp(-sum)));
// 只保留检测框范围内的掩码像素(框外的忽略)
float px = x / (float) maskW * 640;
float py = y / (float) maskH * 640;
if (px >= (cx - w/2) && px <= (cx + w/2) &&
py >= (cy - h/2) && py <= (cy + h/2)) {
mask[y][x] = Math.max(mask[y][x], prob);
}
}
}
detections.add(new Detection(
new android.graphics.RectF(cx - w/2, cy - h/2, cx + w/2, cy + h/2),
classProb, 0
));
}
return new SegResult(mask, detections);
}
/**
* NMS(非极大值抑制)实现。
* 核心思想:对于同一个目标的多个检测框,只保留置信度最高的那个,
* 把和它IoU(交并比)超过阈值的框全部删除。
*/
private List<Detection> nms(List<Detection> detections, float iouThreshold) {
// 先按置信度从高到低排序
Collections.sort(detections, (a, b) -> Float.compare(b.confidence, a.confidence));
List<Detection> kept = new ArrayList<>();
boolean[] suppressed = new boolean[detections.size()];
for (int i = 0; i < detections.size(); i++) {
if (suppressed[i]) continue;
kept.add(detections.get(i));
// 计算当前框和后面所有框的IoU
for (int j = i + 1; j < detections.size(); j++) {
if (suppressed[j]) continue;
if (computeIoU(detections.get(i).box, detections.get(j).box) > iouThreshold) {
suppressed[j] = true; // IoU太高,抑制掉
}
}
}
return kept;
}
/** 计算两个矩形的IoU(交并比) */
private float computeIoU(android.graphics.RectF a, android.graphics.RectF b) {
float intersectW = Math.max(0, Math.min(a.right, b.right) - Math.max(a.left, b.left));
float intersectH = Math.max(0, Math.min(a.bottom, b.bottom) - Math.max(a.top, b.top));
float intersection = intersectW * intersectH;
float union = (a.width() * a.height()) + (b.width() * b.height()) - intersection;
return union > 0 ? intersection / union : 0;
}
}这里有一个我觉得值得展开讲的技术细节:掩码重组(Mask Reassembly) 。很多教程里用的是OpenCV的DNN模块来做这一步,但OpenCV的DNN模块在Android上集成很麻烦,包体积大。所以我选择了纯Java手写。核心公式就是 mask = sigmoid(sum(coeff[k] * proto[k])),32通道的系数和32通道的原型图做线性组合,然后通过sigmoid函数映射到0~1的概率值。
4.3 虚拟走廊决策引擎
检测和分割的结果都有了,但盲人用户需要的是一个简单的指令:"直行"、"向左对齐"、"向右绕行"。这个指令怎么生成?我设计了一个"虚拟走廊"算法。
java
// DecisionEngine.java ------ 核心导航决策引擎
package com.example.shadowwalk;
import android.graphics.RectF;
import java.util.List;
/**
* 核心导航决策引擎。
* 基于感知到的盲道矩阵与障碍物分布,采用虚拟走廊算法为用户提供实时操作指令。
*
* 算法原理:
* 1. 在画面底部找到盲道的重心位置(模拟用户脚下)
* 2. 以重心为中心划定一条虚拟的安全走廊
* 3. 检查障碍物是否侵入了这条走廊
* 4. 根据检测结果生成指令
*/
public class DecisionEngine {
/** 单次决策结果 */
public static class Decision {
public String instruction; // 导航文本提示:"直行"/"向左对齐"/"向右绕行"等
public int baseX; // 路径底部重心横坐标(用于OverlayView绘制引导线)
public int corridorX1; // 安全走廊左边界
public int corridorX2; // 安全走廊右边界
public boolean blocked; // 当前路径是否被障碍物阻断
public Decision(String instruction) {
this.instruction = instruction;
}
}
/**
* 根据感知数据流生成最终指令。
*
* @param mask 160x160的盲道概率图,值域[0,1],>0.5的像素认为是盲道
* @param obstacles 已在感知层完成解析的障碍物列表
*/
public Decision makeDecision(float[][] mask, List<PostProcessor.Detection> obstacles) {
if (mask == null) {
return new Decision("正在初始化...");
}
int h = 160, w = 160;
// ========== 第一步:路径锚定 ==========
// 为什么要分析画面底部20%?
// 因为手机是朝前拿的,画面底部对应的是用户脚下的区域。
// 盲道的重心在脚下的位置最稳定,不会因为远处视角的变化而大幅偏移。
float m00 = 0; // 盲道像素数量(零阶矩)
float m10 = 0; // 盲道横坐标之和(一阶矩)
int startRow = (int) (h * 0.8); // 只看底部20%的行
for (int i = startRow; i < h; i++) {
for (int j = 0; j < w; j++) {
if (mask[i][j] > 0.5f) { // 概率>0.5认为是盲道
m00 += 1;
m10 += j;
}
}
}
// 如果底部区域几乎没有盲道像素,说明用户可能不在盲道上
if (m00 < (w * (h * 0.2) * 0.01)) {
return new Decision("寻找盲道中...");
}
// 计算盲道重心的横坐标(一阶矩/零阶矩)
int baseX = (int) (m10 / m00);
// ========== 第二步:虚拟走廊投射 ==========
// 以重心为中心,向左右各扩展20%的画面宽度,构成一条40%宽的安全走廊。
// 40%这个参数是调出来的------太窄的话容易误报,太宽的话灵敏度不够。
int corridorWidth = (int) (w * 0.40);
int cX1 = Math.max(0, baseX - corridorWidth / 2); // 走廊左边界
int cX2 = Math.min(w, baseX + corridorWidth / 2); // 走廊右边界
// ========== 第三步:冲突探测 ==========
// 遍历所有检测到的障碍物,检查它们的边界框是否和虚拟走廊重叠。
boolean blocked = false;
for (PostProcessor.Detection obs : obstacles) {
// 将障碍物坐标从640x160的检测坐标系映射到160x160的决策坐标系
float bx1 = obs.box.left * 160 / 640;
float bx2 = obs.box.right * 160 / 640;
float by2 = obs.box.bottom * 160 / 640;
// 只关注画面中下部(y>30%)的障碍物
// 上方的障碍物离用户还远,不需要紧急处理
if (by2 > (h * 0.3)) {
// 计算障碍物和走廊的水平重叠区域
float overlapX1 = Math.max(cX1, bx1);
float overlapX2 = Math.min(cX2, bx2);
if (overlapX2 > overlapX1) {
float overlapWidth = overlapX2 - overlapX1;
// 如果障碍物侵占走廊宽度超过30%,判定为路径受阻
if (overlapWidth > (corridorWidth * 0.3)) {
blocked = true;
break;
}
}
}
}
Decision res = new Decision("");
res.baseX = baseX;
res.corridorX1 = cX1;
res.corridorX2 = cX2;
res.blocked = blocked;
// ========== 第四步:指令策略分发 ==========
if (!blocked) {
// 路径通畅:根据盲道重心偏离画面中心的程度给出方向指令
int center = w / 2;
int offset = baseX - center;
// 偏离超过15%就需要调整方向了
if (offset < -w * 0.15) {
res.instruction = "向左对齐";
} else if (offset > w * 0.15) {
res.instruction = "向右对齐";
} else {
res.instruction = "直行";
}
} else {
// 路径受阻:比较左右两侧剩余的盲道面积,引导用户往空旷的一侧绕行
float leftSum = 0;
float rightSum = 0;
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
if (mask[i][j] > 0.5f) {
if (j < baseX) leftSum++;
else rightSum++;
}
}
}
res.instruction = (leftSum > rightSum) ? "向左绕行" : "向右绕行";
}
return res;
}
}这个算法的精妙之处在于:它不是简单地判断"前方有没有障碍物",而是综合考虑了盲道的位置、障碍物和盲道的空间关系、以及两侧的通行空间。即使前方有障碍物,只要旁边有足够的空间,系统也会给出合理的绕行建议,而不是一味地喊"停下"。
五、摄像头采集和推理流水线:不让画面卡顿
视觉识别在手机上跑,最怕的就是卡顿。如果每一帧都要等模型算完才能显示下一帧,那体验就废了。我用了CameraX + 单线程Executor + AtomicBoolean的方案来解决这个问题。
java
// MainActivity.java ------ 应用主入口(核心代码摘录)
package com.example.shadowwalk;
import android.Manifest;
import android.annotation.SuppressLint;
import android.content.Intent;
// ... 其他import省略
/**
* Android应用程序的主入口。
*
* 这个类负责管理整个推理流水线:
* 摄像头采集 -> Bitmap获取 -> 后台推理 -> UI更新 -> 触觉反馈 -> AI语音播报
*
* 线程模型设计:
* - 主线程:CameraX回调、UI渲染
* - cameraExecutor(单线程池):模型推理(防止多帧同时推理导致OOM)
* - assistantExecutor(TravelAssistantManager内部):网络请求和TTS播报
*/
public class MainActivity extends AppCompatActivity {
private static final String TAG = "ShadowWalk";
private static final long VIBRATE_COOLDOWN = 1500; // 震动冷却1.5秒
// UI组件
private PreviewView previewView; // CameraX预览视图
private OverlayView overlayView; // 自定义叠加层(绘制检测框和掩码)
private TextView tvInstruction; // 导航指令文字
private TextView tvLatency; // 推理延迟显示
private TextView tvSceneContext; // 场景上下文摘要
// 推理相关
private ExecutorService cameraExecutor; // 推理线程池
private final AtomicBoolean isProcessing = new AtomicBoolean(false); // 防重入锁
// 核心引擎
private YoloModel yoloModel; // ONNX推理引擎
private PostProcessor postProcessor; // 后处理器
private DecisionEngine decisionEngine; // 决策引擎
private HapticFeedbackManager hapticManager; // 触觉反馈
private TravelAssistantManager travelAssistantManager; // AI出行助手
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// ... 绑定UI组件 ...
// 初始化推理引擎
try {
yoloModel = new YoloModel(this); // 加载两个ONNX模型
postProcessor = new PostProcessor(); // 初始化后处理器
decisionEngine = new DecisionEngine(); // 初始化决策引擎
hapticManager = new HapticFeedbackManager(this); // 初始化震动管理器
} catch (Exception e) {
Log.e(TAG, "基础引擎初始化失败", e);
Toast.makeText(this, "模型初始化失败,请检查资源文件。", Toast.LENGTH_LONG).show();
}
travelAssistantManager = new TravelAssistantManager(this, true); // 启用语音播报
cameraExecutor = Executors.newSingleThreadExecutor(); // 单线程推理池
// 点击"开始外景识别"卡片 -> 启动摄像头和推理
cardRecognitionAction.setOnClickListener(view -> startRecognitionFromCard());
}
/**
* 启动CameraX后置摄像头。
*
* 关键配置:
* - STRATEGY_KEEP_ONLY_LATEST:只保留最新一帧,旧的直接丢弃。
* 这个策略很重要!如果处理速度跟不上摄像头帧率,
* 没有这个配置的话队列会越来越长,最终导致OOM。
*/
private void startCamera() {
ListenableFuture<ProcessCameraProvider> cameraProviderFuture =
ProcessCameraProvider.getInstance(this);
cameraProviderFuture.addListener(() -> {
try {
ProcessCameraProvider cameraProvider = cameraProviderFuture.get();
// 预览用例:将摄像头画面显示到PreviewView上
Preview preview = new Preview.Builder().build();
preview.setSurfaceProvider(previewView.getSurfaceProvider());
// 分析用例:每一帧都触发analyzeImage回调
ImageAnalysis imageAnalysis = new ImageAnalysis.Builder()
.setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST)
.build();
imageAnalysis.setAnalyzer(cameraExecutor, this::analyzeImage);
cameraProvider.unbindAll();
cameraProvider.bindToLifecycle(this,
CameraSelector.DEFAULT_BACK_CAMERA, // 后置摄像头
preview, imageAnalysis);
} catch (Exception e) {
Log.e(TAG, "摄像头绑定失败", e);
}
}, ContextCompat.getMainExecutor(this));
}
/**
* 核心:推理流水线的入口。
*
* 数据流:
* CameraX帧 -> PreviewView.getBitmap() -> AtomicBoolean防重入 ->
* 后台线程推理 -> 解析检测+分割 -> 决策引擎 ->
* UI线程更新指令+延迟+覆盖层+震动+AI播报
*/
@SuppressLint("SetTextI18n")
private void analyzeImage(@NonNull ImageProxy imageProxy) {
imageProxy.close(); // 用完立刻关闭,释放缓冲区
// AtomicBoolean防重入:如果上一帧还没处理完,直接跳过这一帧
// 这是防止帧堆积导致内存溢出的关键机制
if (isProcessing.get() || yoloModel == null) {
return;
}
runOnUiThread(() -> {
Bitmap bitmap = previewView.getBitmap();
if (bitmap == null) return;
isProcessing.set(true); // 加锁
cameraExecutor.execute(() -> {
long startTime = System.currentTimeMillis();
try (YoloModel.InferenceResults rawResults = yoloModel.runInference(bitmap)) {
// === 解析障碍物检测结果 ===
// 检测模型输出:[1, 14, 8400]
ai.onnxruntime.OnnxTensor detTensor =
(ai.onnxruntime.OnnxTensor) rawResults.detection.get(0);
float[] detOutput = moveTensorToFloatArray(detTensor);
// 10个类别,置信度阈值0.35(太低会误检,太高会漏检)
List<PostProcessor.Detection> obstacles =
postProcessor.parseDetection(detOutput, 10, 0.35f);
// === 解析盲道分割结果 ===
ai.onnxruntime.OnnxTensor segTensor =
(ai.onnxruntime.OnnxTensor) rawResults.segmentation.get(0);
float[] segOutput = moveTensorToFloatArray(segTensor);
// 分割模型的32通道原型图
ai.onnxruntime.OnnxTensor protoTensor =
(ai.onnxruntime.OnnxTensor) rawResults.segmentation.get(1);
float[] prototypes = moveTensorToFloatArray(protoTensor);
// 置信度阈值0.15(分割比检测需要更低的阈值,因为掩码更稀疏)
PostProcessor.SegResult segResult =
postProcessor.parseSegmentation(segOutput, prototypes, 0.15f);
// === 决策引擎生成导航指令 ===
DecisionEngine.Decision decision =
decisionEngine.makeDecision(segResult.mask, obstacles);
long duration = System.currentTimeMillis() - startTime;
// === 切回UI线程更新界面 ===
runOnUiThread(() -> {
tvInstruction.setText(decision.instruction);
tvLatency.setText(String.format(Locale.CHINA, "延迟: %d ms", duration));
// 更新叠加层(绘制盲道掩码 + 障碍物检测框)
overlayView.setResults(obstacles, segResult.detections,
segResult.mask, decision.baseX);
// 触觉反馈(1.5秒内不重复震动)
long now = System.currentTimeMillis();
if (preferences.isHapticFeedbackEnabled()
&& now - lastVibrateTime > VIBRATE_COOLDOWN) {
hapticManager.vibrateForInstruction(decision.instruction);
lastVibrateTime = now;
}
// 调用AI出行助手生成语音播报
travelAssistantManager.maybeGenerateGuidance(
this, decision, obstacles, update -> {
tvSceneContext.setText(update.sceneSummary);
});
});
} catch (Throwable t) {
Log.e(TAG, "推理流执行失败", t);
} finally {
isProcessing.set(false); // 解锁
}
});
});
}
}在这段代码里有几个我觉得特别重要的设计决策:
-
STRATEGY_KEEP_ONLY_LATEST:如果推理速度跟不上摄像头帧率(30fps),旧帧会直接丢弃,不会堆积。没有这个配置的话,延迟会越来越大,最终OOM。 -
AtomicBoolean防重入:同一时刻只允许一帧进入推理流水线。如果上一帧还在算,新来的帧直接跳过。这是在性能和实时性之间的最佳折中。 -
try-with-resources管理推理结果 :InferenceResults实现了AutoCloseable,确保 native 内存一定被释放。
端到端的延迟在骁龙870上大约是328ms563ms,也就是每秒能处理23帧。对于盲人导航来说完全够用了------人的反应时间本身就有200ms左右。
六、腾讯地图接入:让App知道你在哪
光有视觉感知还不够,盲人还需要知道自己在什么地方、附近有什么。这就是腾讯地图发挥作用的地方了。
6.1 AndroidManifest.xml 权限声明
xml
<!-- AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android">
<!-- 摄像头权限 -->
<uses-permission android:name="android.permission.CAMERA" />
<!-- 网络权限(调用地图API和大模型都需要) -->
<uses-permission android:name="android.permission.INTERNET" />
<!-- 位置权限(GPS定位) -->
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
<!-- 震动权限 -->
<uses-permission android:name="android.permission.VIBRATE" />
<uses-feature android:name="android.hardware.camera" />
<application>
<!-- 启动页作为LAUNCHER入口 -->
<activity android:name=".SplashActivity" android:exported="true">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
<activity android:name=".SettingsActivity" />
<activity android:name=".MainActivity" />
</application>
</manifest>6.2 腾讯地图逆地理编码的实现
核心逻辑在 TravelAssistantManager.java 里。每次推理出结果后,如果满足冷却条件(8秒内不重复请求),就会获取当前GPS坐标,然后调用腾讯地图的逆地理编码API获取地址和附近POI。
java
// TravelAssistantManager.java ------ 腾讯地图API调用(核心片段)
package com.example.shadowwalk;
// ... import省略 ...
/**
* AI/MCP/地图出行辅助管理器。
*
* 这个类是整个项目中第三复杂的模块(仅次于YoloModel推理)。
* 它要协调三种云端服务:
* 1. 腾讯地图WebService API ------ 获取位置信息
* 2. 腾讯云MCP SSE端点 ------ 大模型调用地图工具的通道
* 3. 蓝耘AI大模型 ------ 生成自然语言播报
*
* 同时还要管理TTS语音播报、服务诊断、降级策略等。
*/
public class TravelAssistantManager {
private static final String TAG = "TravelAssistant";
private static final long GUIDANCE_COOLDOWN_MS = 8000L; // 8秒冷却
private static final long LOCATION_TIMEOUT_MS = 2500L; // GPS超时2.5秒
// 障碍物类别的中文名称,用于生成自然语言播报
private static final String[] LABELS_ZH = new String[]{
"自行车", "公交车", "汽车", "狗", "电线杆", "摩托车", "行人", "交通标识", "树木", "无盖井"
};
// ... 其他成员变量和内部类省略 ...
/**
* 调用腾讯地图逆地理编码API。
*
* API地址:https://apis.map.qq.com/ws/geocoder/v1/
* 功能:根据经纬度获取地址信息 + 附近200米内的POI(兴趣点)
*
* @param locationSnapshot GPS位置快照
* @param logBuilder 诊断日志
* @param allowFallbackCoordinate 是否允许使用固定坐标回退
*/
private MapContext fetchMapContext(LocationSnapshot locationSnapshot,
StringBuilder logBuilder,
boolean allowFallbackCoordinate) {
if (TextUtils.isEmpty(BuildConfig.TENCENT_MAP_KEY)) {
return new MapContext(false, "", "", "未配置 TENCENT_MAP_KEY");
}
double latitude, longitude;
if (locationSnapshot != null) {
latitude = locationSnapshot.latitude;
longitude = locationSnapshot.longitude;
} else if (allowFallbackCoordinate) {
// 诊断模式下使用固定坐标测试连通性
latitude = 22.543096; // 深圳某坐标
longitude = 114.057865;
} else {
return new MapContext(false, "", "", "未获取到可用位置");
}
HttpURLConnection connection = null;
try {
// 拼接API请求URL
// get_poi=1:同时返回附近POI
// poi_options:POI搜索半径200米,地址格式简短
String apiUrl = String.format(Locale.US,
"https://apis.map.qq.com/ws/geocoder/v1/" +
"?location=%.6f,%.6f&get_poi=1&poi_options=address_format=short;radius=200" +
"&key=%s",
latitude, longitude, BuildConfig.TENCENT_MAP_KEY);
URL url = new URL(apiUrl);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setReadTimeout(5000);
connection.connect();
int responseCode = connection.getResponseCode();
String body = readBody(connection);
if (responseCode < 200 || responseCode >= 300) {
return new MapContext(false, "", "", "HTTP " + responseCode);
}
// 解析JSON响应
JSONObject json = new JSONObject(body);
int status = json.optInt("status", -1);
if (status != 0) {
return new MapContext(false, "", "", "业务错误: " + json.optString("message"));
}
JSONObject result = json.optJSONObject("result");
String address = result.optString("address"); // 详细地址
// 提取最近的3个POI
JSONArray pois = result.optJSONArray("pois");
List<String> poiTitles = new ArrayList<>();
if (pois != null) {
for (int i = 0; i < Math.min(3, pois.length()); i++) {
JSONObject poi = pois.optJSONObject(i);
poiTitles.add(poi.optString("title"));
}
}
return new MapContext(true, address,
TextUtils.join("、", poiTitles), "解析成功");
} catch (Exception e) {
return new MapContext(false, "", "", e.getMessage());
} finally {
if (connection != null) connection.disconnect();
}
}
}6.3 大模型调用:让AI生成自然的语音播报
有了视觉检测结果和地图位置信息,接下来就是让AI把这些数据整合成一句自然、简短的语音播报。
java
// TravelAssistantManager.java ------ AI大模型调用(核心片段)
/**
* 向DeepSeek-V3.2请求出行引导播报。
*
* System Prompt的设计非常关键------我花了不少时间调优:
* - 明确AI的角色是"盲人出行助手"
* - 限制输出长度(不超过45个字,太长了TTS播报体验差)
* - 不要用项目符号(语音播报不适合读结构化内容)
* - 优先说方向和风险(安全第一)
*/
private AiReply requestAiBriefing(DecisionEngine.Decision decision,
String obstacleSummary,
MapContext mapContext,
StringBuilder logBuilder) {
// ... 配置检查省略 ...
try {
JSONObject payload = new JSONObject();
payload.put("model", BuildConfig.LANYUN_MODEL_ID); // DeepSeek-V3.2
payload.put("temperature", 0.3); // 低温度,输出更稳定
JSONArray messages = new JSONArray();
// System Prompt:定义AI的角色和输出约束
messages.put(new JSONObject()
.put("role", "system")
.put("content", "你是一名面向盲人用户的无障碍出行助手。" +
"请结合视觉识别、当前位置和附近地标," +
"输出一句简短自然、适合语音播报的中文提示," +
"不要使用项目符号,不要超过45个字。"));
// User Prompt:拼接结构化的感知数据
StringBuilder userPrompt = new StringBuilder();
userPrompt.append("当前导航建议:").append(decision.instruction).append("\n");
userPrompt.append("前方障碍概况:")
.append(TextUtils.isEmpty(obstacleSummary) ? "未识别到主要障碍" : obstacleSummary)
.append("\n");
if (mapContext != null && mapContext.success) {
userPrompt.append("当前位置:").append(mapContext.address).append("\n");
if (!TextUtils.isEmpty(mapContext.poiSummary)) {
userPrompt.append("附近地标:").append(mapContext.poiSummary).append("\n");
}
} else {
userPrompt.append("位置上下文: 暂不可用\n");
}
userPrompt.append("请给出一句适合耳机播报的提醒,优先说方向和风险。 ");
messages.put(new JSONObject()
.put("role", "user")
.put("content", userPrompt.toString()));
payload.put("messages", messages);
// 发送HTTP POST请求到AI服务
URL url = new URL(BuildConfig.LANYUN_BASE_URL);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setConnectTimeout(6000);
connection.setReadTimeout(6000);
connection.setRequestProperty("Content-Type", "application/json");
connection.setRequestProperty("Authorization",
"Bearer " + BuildConfig.LANYUN_API_KEY);
connection.setDoOutput(true);
try (OutputStream os = connection.getOutputStream()) {
os.write(payload.toString().getBytes(StandardCharsets.UTF_8));
}
// 解析AI的响应
int responseCode = connection.getResponseCode();
String body = readBody(connection);
if (responseCode < 200 || responseCode >= 300) {
return new AiReply(false, "", "HTTP " + responseCode);
}
JSONObject json = new JSONObject(body);
String content = json.getJSONArray("choices")
.getJSONObject(0)
.getJSONObject("message")
.optString("content", "");
return new AiReply(!TextUtils.isEmpty(content), content.trim(), "AI响应正常");
} catch (Exception e) {
return new AiReply(false, "", e.getMessage());
}
}举个例子,假设当前的场景是:用户走在盲道上,前方检测到一辆汽车停在路边,附近是一个公交站。AI可能会生成这样的播报:
"前方右侧有汽车,注意避让,您目前在人民路公交站附近。"
这比死板的"前方有障碍物:汽车"要自然得多,而且包含了位置上下文信息。
6.4 降级策略:断网了怎么办?
真实场景中断网是常有的事。我设计了一套三级降级策略:
java
// TravelAssistantManager.java ------ 降级策略
/**
* AI不可用时的本地模板播报。
* 纯字符串拼接,不依赖任何网络服务。
*/
private String buildFallbackBriefing(DecisionEngine.Decision decision,
String obstacleSummary,
MapContext mapContext) {
List<String> parts = new ArrayList<>();
parts.add("当前建议" + decision.instruction);
if (!TextUtils.isEmpty(obstacleSummary) && preferences.isObstacleAlertEnabled()) {
parts.add("前方识别到" + obstacleSummary);
}
if (mapContext != null && mapContext.success && !TextUtils.isEmpty(mapContext.address)) {
parts.add("附近位置是" + mapContext.address);
}
return TextUtils.join(",", parts) + "。";
}降级链路:
- 正常模式:YOLOv8检测 + 腾讯地图 + DeepSeek AI -> 自然语言语音播报
- AI降级:YOLOv8检测 + 腾讯地图 -> 本地模板播报("当前建议直行,前方识别到汽车")
- 完全离线:YOLOv8检测 -> 纯本地避障("直行"/"向左绕行"),触觉反馈依然可用
七、UI设计:为视障用户而生的界面
7.1 设计理念
因为这款App的受众是视障人士,所以界面的核心诉求和普通App完全不同:
- 高对比度:文字和背景要有足够的对比度
- 大面积触控热区:按钮要够大,方便盲按
- 信息精简:只显示最关键的信息,不要让用户花时间去理解UI
- 语音优先 :重要的信息都通过语音播报传达,界面只是辅助
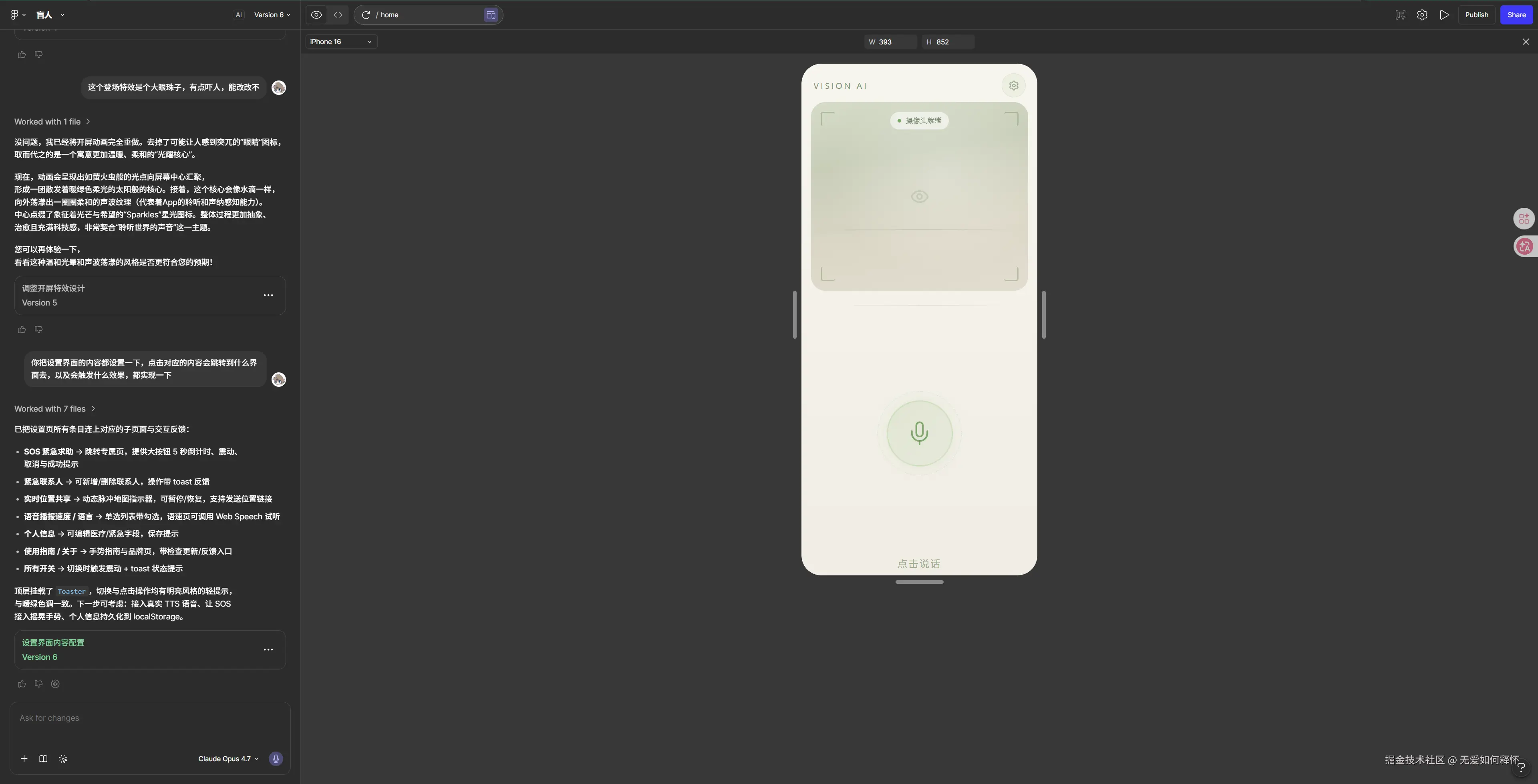
7.2 Android Studio布局编辑器
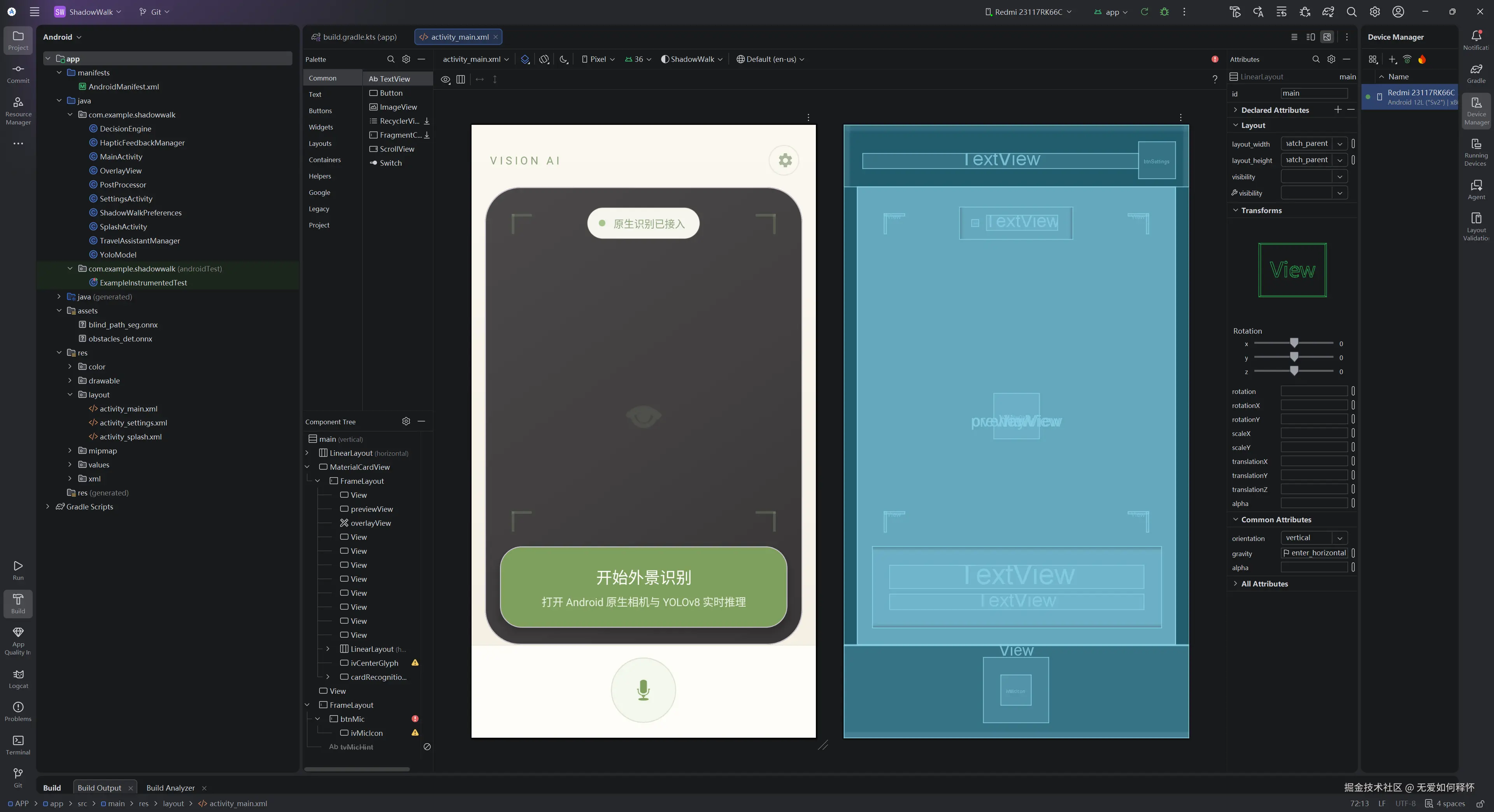
在Android Studio里双击 res/layout/activity_main.xml 就能看到可视化布局编辑器:
7.3 模拟器运行效果
在手机模拟器上跑起来的效果:
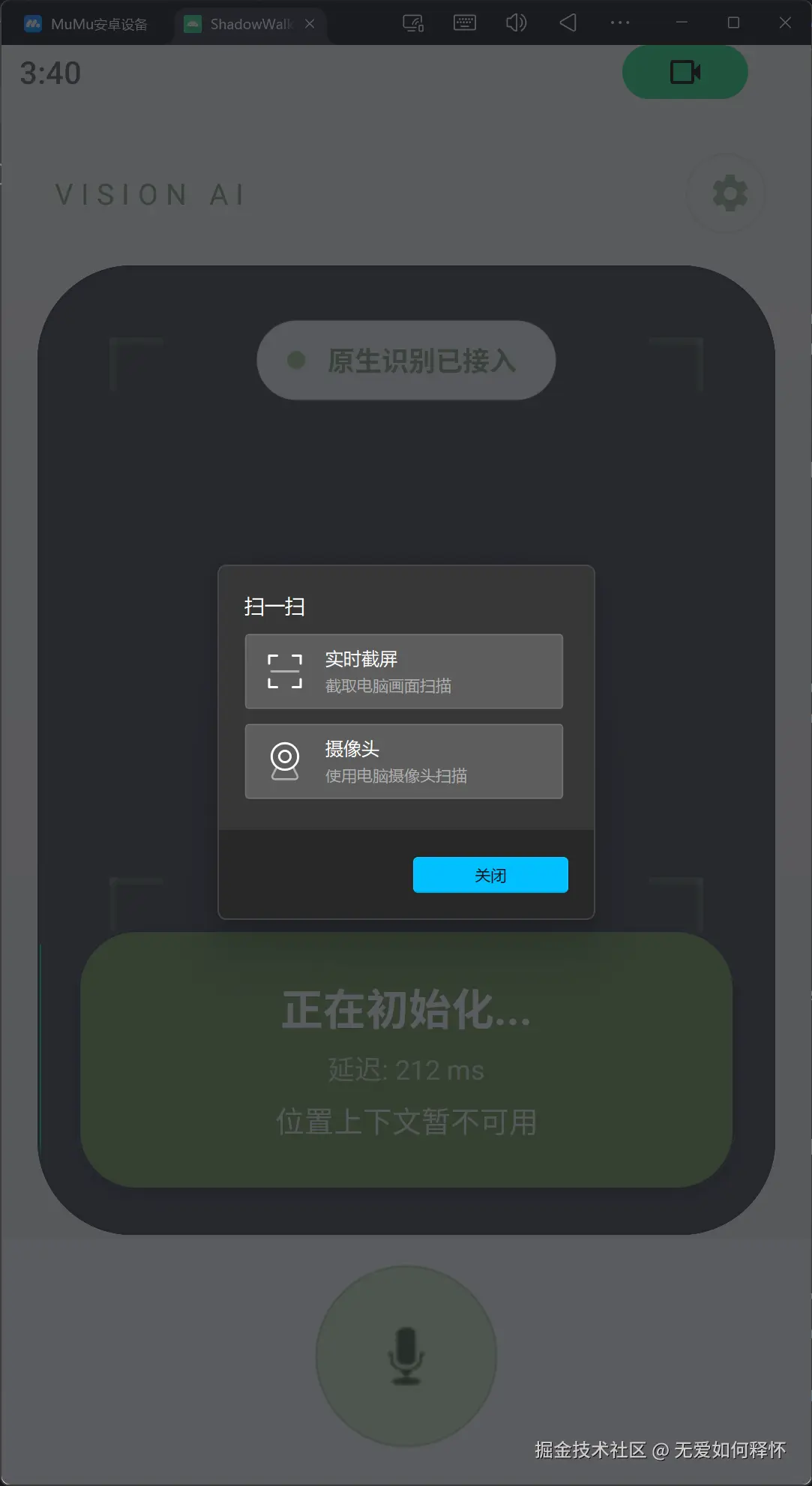
整体布局从上到下是这样的:
- 顶部状态栏:品牌标题 + 设置按钮
- 相机预览区:实时摄像头画面 + YOLOv8检测结果叠加层
- 识别结果卡片:导航指令 + 推理延迟 + 场景摘要
- 底部麦克风区域:语音交互按钮
颜色体系用的是一套灰绿色调(#8EA47D 为主品牌色),暖白背景(#FBF8F1),看起来很舒适,对比度也够。
八、触觉反馈:用震动传递信息
对于视障用户来说,震动是一种非常重要的信息传递方式。我设计了四种不同的震动模式来对应不同的导航指令:
| 导航指令 | 震动模式 | 震动参数 | 含义 |
|---|---|---|---|
| 避开障碍物 | 连续三短震 | {0,80,50,80,50,80} |
紧急,需要立刻反应 |
| 向左对齐 | 双快震 | {0,150,100,150} |
向左调整方向 |
| 向右对齐 | 长单震 | {0,450} |
向右调整方向 |
| 直行 | 极短脉冲 | {0,20} |
安全确认 |
这里有个技术细节值得一提:我使用了 USAGE_ASSISTANCE_ACCESSIBILITY 这个 AudioAttributes 来声明无障碍用途,这样即使用户的手机开了静音模式,震动依然会生效。
九、服务诊断功能:一键排查问题
开发过程中最头疼的不是写代码,而是排查"为什么连不上"。所以我专门在设置页面加了一个服务诊断功能,一键测试三个核心服务的连通性。
java
// TravelAssistantManager.java ------ 服务诊断(核心片段)
/**
* 运行完整的服务诊断。
* 按顺序探测三个服务:腾讯地图 -> 腾讯云MCP -> AI服务
*/
public void runDiagnostics(Activity activity, DiagnosticsCallback callback) {
assistantExecutor.execute(() -> {
StringBuilder logBuilder = new StringBuilder();
logStep(logBuilder, "开始执行服务诊断");
// 第一步:测试腾讯地图逆地理编码
ServiceStatus mapStatus = probeMapService(activity, logBuilder);
// 第二步:测试腾讯云MCP SSE端点握手
ServiceStatus mcpStatus = probeMcpService(logBuilder);
// 第三步:测试AI大模型连通性(发送"请只回复:连接正常")
ServiceStatus aiStatus = probeAiService(logBuilder);
ServiceDiagnosticsReport report = new ServiceDiagnosticsReport(
mapStatus, mcpStatus, aiStatus, logBuilder.toString().trim());
mainHandler.post(() -> callback.onDiagnosticsReady(report));
});
}
/**
* 探测腾讯云MCP服务。
* 原理:向SSE端点发送GET请求,检查返回的Content-Type是否为text/event-stream。
*/
private ServiceStatus probeMcpService(StringBuilder logBuilder) {
HttpURLConnection connection = null;
try {
URL url = new URL(BuildConfig.TENCENT_MCP_URL);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Accept", "text/event-stream");
connection.setConnectTimeout(5000);
connection.setReadTimeout(2000);
connection.connect();
int responseCode = connection.getResponseCode();
String contentType = connection.getContentType();
// SSE服务正常的话应该返回200且Content-Type为text/event-stream
boolean success = responseCode >= 200 && responseCode < 300
&& contentType != null
&& contentType.toLowerCase(Locale.ROOT).contains("text/event-stream");
return new ServiceStatus("腾讯云 MCP", success,
success ? "SSE握手成功" : "HTTP " + responseCode);
} catch (Exception e) {
return new ServiceStatus("腾讯云 MCP", false, e.getMessage());
} finally {
if (connection != null) connection.disconnect();
}
}诊断结果会以弹窗的形式展示,告诉你哪个服务连接成功、哪个失败了、失败的原因是什么,还会附带完整的日志时间线。 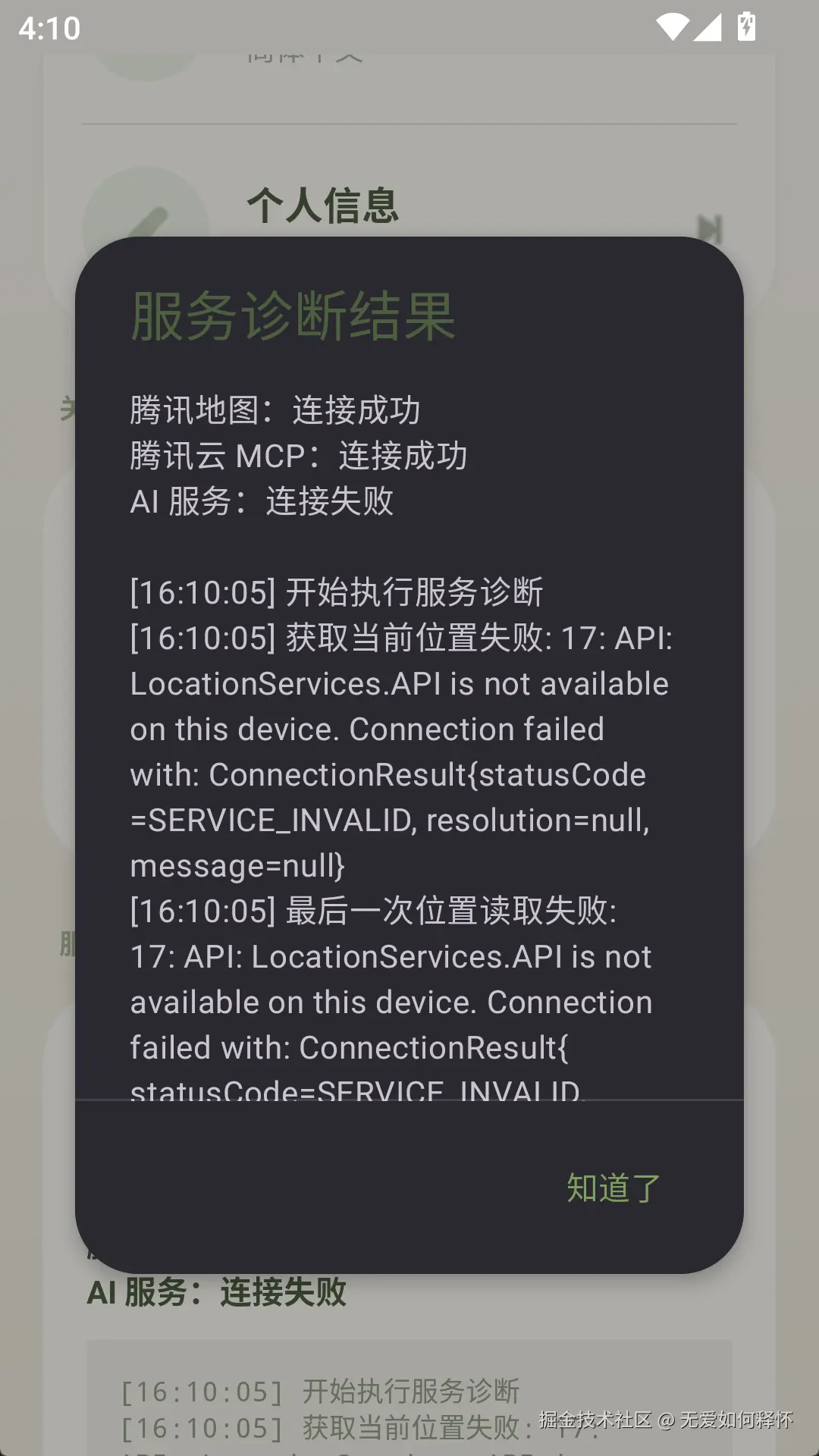
十、完整数据流全景
最后,我用一张流程图把整个系统的数据流串起来,让大家有个全局的认识:
css
[CameraX 后置摄像头采集]
|
v
[Bitmap 原始帧]
|
v
[YoloModel.runInference()]
├── 预处理:640x640缩放 + NCHW归一化
├── 输入张量:[1, 3, 640, 640]
|
+──→ [obstacles_det.onnx] 障碍物检测
| 输出:[1, 14, 8400]
| |
| v
| [PostProcessor.parseDetection()]
| 遍历8400个anchor → NMS去重
| 输出:10类障碍物的边界框列表
|
+──→ [blind_path_seg.onnx] 盲道分割
输出:[1, 37, 8400] + [1, 32, 160, 160]
|
v
[PostProcessor.parseSegmentation()]
32通道线性组合 + sigmoid
输出:160x160的盲道概率掩码
|
v
[DecisionEngine.makeDecision()]
├── 路径锚定:底部20%盲道重心
├── 虚拟走廊:40%宽度安全区域
├── 冲突探测:障碍物是否侵入走廊
└── 指令分发:直行/向左对齐/向右绕行
|
+──→ [UI更新] 指令文字 + 推理延迟
+──→ [OverlayView] 掩码 + 检测框渲染
+──→ [触觉反馈] 对应震动模式
|
v
[TravelAssistantManager]
├── GPS定位 → 腾讯地图逆地理编码
│ 输出:地址 + 附近200米POI
├── 组装Prompt(视觉结果 + 位置信息)
├── DeepSeek-V3.2 生成自然语言播报
└── TTS语音播报 → 蓝牙耳机输出十一、写在最后
这个项目从立项到跑通大概花了一个月的时间。说实话中间踩了不少坑:
- ONNX Runtime在Android上加载模型的时候,有一段时间一直报shape不匹配的错误,最后发现是
dynamic=True导出的ONNX和固定shape的推理不兼容 - 腾讯地图的逆地理编码API,一开始没分配额度,调试了半天以为是代码问题
- CameraX的帧率比推理速度快很多,如果没有
STRATEGY_KEEP_ONLY_LATEST,内存会炸 - 大模型的temperature参数调了好久,太高了输出不稳定,太低了像复读机
但最终跑通的那一刻,看着手机屏幕上实时画出的检测框和掩码,听着AI说"前方右侧有汽车,注意避让"------还是挺有成就感的。
如果你对这个项目感兴趣,想自己动手试试,这里是几个建议:
- 先跑通PC端的推理 :在Python环境下用
debug/test_det.py和debug/test_seg.py验证模型效果 - 再用
verify_onnx.py做一致性检查:确保ONNX导出没有精度损失 - 最后才是Android部署:先把模型塞到assets里,确保ONNX Runtime能加载
- 密钥管理一定不要偷懒 :用
local.properties+BuildConfig的方案
技术的价值不在于多炫酷,而在于能不能真正解决人的问题。1700万视障群体的出行困难,不是一篇论文或者一个Demo能解决的,但至少我们可以开始做一些事情了。