1.简易小白教程
实践项目来串联概念
做一个智能家居系统:
嵌入式端(STM32 + C)采集传感器数据
网关(Go或Python)接收数据并转发
后端(Java或Go)处理业务逻辑,存入数据库
前端(Vue/React)展示数据
AI模块(Python + TensorFlow)做异常检测
这样你就一次性接触了嵌入式、网络、后端、前端、AI。
小白教程讲解,完整讲解每一步怎么做
需要按顺序讲解每个部分的实现,包括环境搭建、代码编写、运行测试。使用Docker或本地服务均可。
可以选择:
-
嵌入式端:C程序模拟温度/湿度传感器,通过串口或MQTT发送数据?为了让网关接收,最简单是用UDP或TCP socket发送JSON数据。
-
网关用Python(简单)接收并转发到后端(用HTTP或消息队列)。
-
后端用Java Spring Boot,存储到MySQL。
-
前端用Vue + axios展示实时数据图表。
-
AI模块用Python Flask提供API,后端调用它进行异常检测,或者AI模块从数据库读取数据检测。
因为AI模块做异常检测,可以离线训练简单模型(如孤立森林或自动编码器),检测温度异常。在线检测:后端将每个数据点发送给AI服务,返回是否异常。
为了简化但完整,我们可以:
-
嵌入式模拟器(C程序):每5秒生成随机温湿度,通过TCP发送到网关的指定端口。
-
网关(Python):监听TCP端口,接收数据,然后通过HTTP POST转发到后端API。
-
后端(Java Spring Boot):提供接收数据的API,存入MySQL;提供查询API给前端;调用AI服务进行异常检测(异步或同步)。为了简单,同步调用AI服务,如果AI返回异常,额外记录或标记。
-
前端(Vue3 + axios + chart.js):展示实时数据列表和图表,轮询后端获取最新数据。
-
AI模块(Python Flask + TensorFlow):加载预训练的异常检测模型(简单模型如基于统计或自编码器),提供predict API接收数据特征返回是否异常。训练数据可以用模拟正常数据生成。
还要包括MySQL数据库设计,表结构。
讲解每一步:从安装所需软件(Python, Java, Node.js, MySQL, TensorFlow等)到编写代码,运行。
因为是教程,需要详细到命令行。需要提供所有代码文件的内容,并解释。
下面是一份完整的小白级教程 ,带你从零搭建一个智能家居系统原型。你将亲手实现:嵌入式端(模拟)采集数据 → 网关转发 → 后端存储 + AI异常检测 → 前端展示。整个项目覆盖了嵌入式、网络、后端、前端、AI五大模块,帮你用实践串联概念。
📌 本教程假设你熟悉基础的编程语法(C、Python、Java、JavaScript),但对各框架不熟也没关系,代码会逐行解释。
💡 为了降低硬件门槛,嵌入式端用 C程序模拟传感器数据,通过TCP发送。你完全可以在自己的电脑上运行所有组件,理解后再移植到真实STM32上。
一、整体架构与数据流
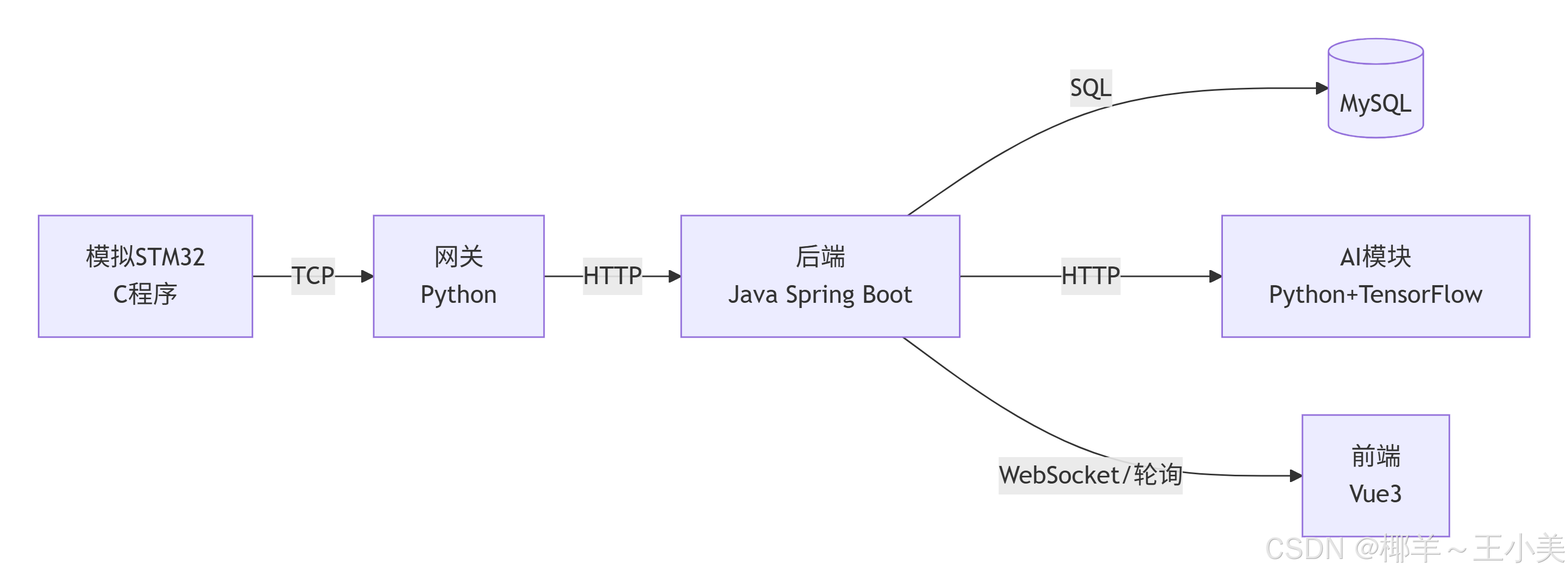
-
嵌入式端:每秒生成随机温湿度,打包成JSON,通过TCP发送到网关。
-
网关:接收TCP数据,不做业务处理,直接转发给后端HTTP接口。
-
后端:接收数据存入MySQL;同时调用AI模块判断是否异常,将异常状态也存入数据库;提供REST API供前端查询最新数据。
-
AI模块 :加载预训练好的异常检测模型(用TensorFlow实现一个简单的自编码器),对每个数据点返回
is_anomaly标志。 -
前端:每3秒轮询后端,获取最近20条数据,用表格和折线图展示,异常点高亮显示。
二、准备工作
2.1 安装必要软件
| 组件 | 所需环境 | 下载/安装方式 |
|---|---|---|
| 嵌入式模拟 | GCC (MinGW或Linux) | Linux自带;Windows可装MinGW |
| 网关 | Python 3.8+ | python.org |
| 后端 | JDK 17+、Maven、MySQL 8.0 | Oracle JDK、Maven、MySQL |
| 前端 | Node.js 16+、npm/yarn | nodejs.org |
| AI模块 | Python 3.8+、TensorFlow 2.x | 同上Python,然后pip install tensorflow flask |
💡 所有组件都运行在同一台电脑上,端口分配:
嵌入式 → 网关 TCP:8888
网关 → 后端 HTTP:8080/api/data
后端 → AI模块 HTTP:5000/predict
前端开发服务器:5173 (Vite默认)
2.2 创建项目总目录
text
smart_home/
├── embedded_simulator/ # C程序
├── gateway/ # Python网关
├── backend/ # Spring Boot后端
├── ai_module/ # Flask AI服务
├── frontend/ # Vue前端
└── database/ # SQL脚本三、数据库设计(MySQL)
创建数据库smart_home,一张表sensor_data:
sql
CREATE DATABASE smart_home;
USE smart_home;
CREATE TABLE sensor_data (
id INT AUTO_INCREMENT PRIMARY KEY,
temperature DECIMAL(5,2),
humidity DECIMAL(5,2),
is_anomaly BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);执行脚本(可用MySQL Workbench或命令行)。
四、嵌入式端模拟器(C语言)
模拟STM32定时采集传感器数据,通过TCP发送给网关。
4.1 代码实现(embedded_simulator/main.c)
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <time.h>
#define SERVER_IP "127.0.0.1"
#define PORT 8888
// 模拟读取温度(15~30度)和湿度(40%~70%)
void read_sensor(float *temp, float *hum) {
*temp = 15.0f + (rand() % 1500) / 100.0f; // 15.00 ~ 29.99
*hum = 40.0f + (rand() % 3000) / 100.0f; // 40.00 ~ 69.99
}
int main() {
int sockfd;
struct sockaddr_in server_addr;
char buffer[128];
float temp, hum;
srand(time(NULL));
// 创建TCP socket
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
exit(1);
}
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr.s_addr = inet_addr(SERVER_IP);
// 连接网关
if (connect(sockfd, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("connect");
exit(1);
}
printf("Connected to gateway at %s:%d\n", SERVER_IP, PORT);
while (1) {
read_sensor(&temp, &hum);
// 构造JSON: {"temperature":23.5,"humidity":55.2}
snprintf(buffer, sizeof(buffer), "{\"temperature\":%.2f,\"humidity\":%.2f}", temp, hum);
send(sockfd, buffer, strlen(buffer), 0);
printf("Sent: %s\n", buffer);
sleep(2); // 每2秒发送一次
}
close(sockfd);
return 0;
}4.2 编译运行
bash
cd embedded_simulator
gcc main.c -o simulator
./simulator真实STM32移植:将此代码中的
socket部分换成lwip或AT指令,传感器读取换成ADC/I2C读取真实传感器(如DHT22)。
五、网关(Python)
网关监听TCP端口8888,收到数据后立即通过HTTP POST转发给后端http://localhost:8080/api/data。
5.1 代码实现(gateway/gateway.py)
python
import socket
import requests
import json
GATEWAY_HOST = '0.0.0.0'
GATEWAY_PORT = 8888
BACKEND_URL = 'http://localhost:8080/api/data'
def start_gateway():
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server_socket.bind((GATEWAY_HOST, GATEWAY_PORT))
server_socket.listen(5)
print(f"Gateway listening on {GATEWAY_HOST}:{GATEWAY_PORT}")
while True:
client_socket, addr = server_socket.accept()
print(f"Accepted connection from {addr}")
data = client_socket.recv(1024).decode('utf-8')
if data:
try:
# 转发给后端
response = requests.post(BACKEND_URL, json=json.loads(data), timeout=2)
print(f"Forwarded data, backend response: {response.status_code}")
except Exception as e:
print(f"Error forwarding: {e}")
client_socket.close()
if __name__ == '__main__':
start_gateway()5.2 运行网关
bash
cd gateway
pip install requests # 如果还没装
python gateway.py六、后端(Java Spring Boot)
6.1 创建Spring Boot项目
使用Spring Initializr (https://start.spring.io/) 生成项目,依赖选择:
-
Spring Web
-
Spring Data JPA
-
MySQL Driver
-
Lombok (可选)
下载解压到backend目录。
6.2 配置文件 (src/main/resources/application.properties)
properties
server.port=8080
spring.datasource.url=jdbc:mysql://localhost:3306/smart_home?useSSL=false&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=你的MySQL密码
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true6.3 实体类 (SensorData.java)
java
package com.example.smarthome.entity;
import lombok.Data;
import javax.persistence.*;
import java.time.LocalDateTime;
@Entity
@Table(name = "sensor_data")
@Data
public class SensorData {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private Double temperature;
private Double humidity;
private Boolean isAnomaly = false;
private LocalDateTime createdAt = LocalDateTime.now();
}6.4 Repository (SensorDataRepository.java)
java
package com.example.smarthome.repository;
import com.example.smarthome.entity.SensorData;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
public interface SensorDataRepository extends JpaRepository<SensorData, Integer> {
List<SensorData> findTop20ByOrderByCreatedAtDesc();
}6.5 AI模块调用客户端 (AIClient.java)
java
package com.example.smarthome.client;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestTemplate;
import java.util.HashMap;
import java.util.Map;
@Component
public class AIClient {
private final RestTemplate restTemplate = new RestTemplate();
private final String AI_URL = "http://localhost:5000/predict";
public boolean isAnomaly(double temp, double hum) {
Map<String, Double> request = new HashMap<>();
request.put("temperature", temp);
request.put("humidity", hum);
try {
Map response = restTemplate.postForObject(AI_URL, request, Map.class);
return (boolean) response.get("is_anomaly");
} catch (Exception e) {
System.err.println("AI service error: " + e.getMessage());
return false; // 服务不可用时默认正常
}
}
}6.6 Controller (SensorDataController.java)
java
package com.example.smarthome.controller;
import com.example.smarthome.client.AIClient;
import com.example.smarthome.entity.SensorData;
import com.example.smarthome.repository.SensorDataRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/api")
@CrossOrigin // 允许前端跨域
public class SensorDataController {
@Autowired
private SensorDataRepository repository;
@Autowired
private AIClient aiClient;
// 网关调用此接口上报数据
@PostMapping("/data")
public String receiveData(@RequestBody SensorData data) {
// 调用AI判断异常
boolean anomaly = aiClient.isAnomaly(data.getTemperature(), data.getHumidity());
data.setIsAnomaly(anomaly);
repository.save(data);
return "OK";
}
// 前端获取最近20条数据
@GetMapping("/latest")
public List<SensorData> getLatest() {
return repository.findTop20ByOrderByCreatedAtDesc();
}
}6.7 启动后端
bash
cd backend
mvn spring-boot:run七、AI模块(Flask + TensorFlow)
我们训练一个非常简单的自编码器(Autoencoder),用正常数据训练,重构误差大于阈值则判定为异常。
7.1 生成训练数据(ai_module/generate_normal_data.py)
为了演示,先模拟生成1000组正常温湿度(温度20~28度,湿度45~65%,且满足一定相关性):
python
import numpy as np
import pandas as pd
np.random.seed(42)
n = 1000
temp = np.random.uniform(20, 28, n)
# 湿度与温度负相关大致趋势
hum = 65 - (temp - 20) * 0.8 + np.random.normal(0, 2, n)
hum = np.clip(hum, 45, 65)
df = pd.DataFrame({'temperature': temp, 'humidity': hum})
df.to_csv('normal_data.csv', index=False)
print("Generated normal_data.csv")7.2 训练自编码器(ai_module/train_ae.py)
python
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from sklearn.preprocessing import StandardScaler
import joblib
# 加载数据
df = pd.read_csv('normal_data.csv')
X = df[['temperature', 'humidity']].values
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
joblib.dump(scaler, 'scaler.pkl')
# 构建自编码器
input_dim = 2
encoding_dim = 1
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
decoded = Dense(input_dim, activation='linear')(encoded)
autoencoder = Model(input_layer, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
# 训练
history = autoencoder.fit(X_scaled, X_scaled, epochs=50, batch_size=32, validation_split=0.1, verbose=1)
autoencoder.save('autoencoder.h5')
# 确定阈值 (重构误差的95%分位数)
reconstructions = autoencoder.predict(X_scaled)
mse = np.mean(np.square(X_scaled - reconstructions), axis=1)
threshold = np.percentile(mse, 95)
print(f"Threshold = {threshold}")
with open('threshold.txt', 'w') as f:
f.write(str(threshold))7.3 预测API服务(ai_module/app.py)
python
from flask import Flask, request, jsonify
import tensorflow as tf
import numpy as np
import joblib
app = Flask(__name__)
# 加载模型和预处理器
model = tf.keras.models.load_model('autoencoder.h5')
scaler = joblib.load('scaler.pkl')
with open('threshold.txt', 'r') as f:
threshold = float(f.read())
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json()
temp = data['temperature']
hum = data['humidity']
X = np.array([[temp, hum]])
X_scaled = scaler.transform(X)
reconstruction = model.predict(X_scaled)
mse = np.mean(np.square(X_scaled - reconstruction))
is_anomaly = bool(mse > threshold)
return jsonify({'is_anomaly': is_anomaly, 'reconstruction_error': float(mse)})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)7.4 运行AI模块
bash
cd ai_module
pip install tensorflow pandas scikit-learn flask joblib
python generate_normal_data.py
python train_ae.py
python app.py注意:如果训练时报错,可以降低
epochs。这个模型非常小,普通CPU即可运行。
八、前端(Vue3 + Vite + Chart.js)
8.1 创建Vue项目
bash
cd frontend
npm create vite@latest . -- --template vue
npm install axios chart.js vue-chartjs8.2 主组件 (src/App.vue)
vue
<template>
<div id="app">
<h1>智能家居监控中心</h1>
<div style="display: flex;">
<!-- 表格区 -->
<div style="flex:1; margin-right:20px;">
<h2>实时数据</h2>
<table border="1" cellpadding="5">
<thead>
<tr><th>时间</th><th>温度(℃)</th><th>湿度(%)</th><th>异常</th></tr>
</thead>
<tbody>
<tr v-for="item in sensorData" :key="item.id" :style="{backgroundColor: item.isAnomaly ? '#ffcccc' : 'white'}">
<td>{{ formatDate(item.createdAt) }}</td>
<td>{{ item.temperature }}</td>
<td>{{ item.humidity }}</td>
<td>{{ item.isAnomaly ? '⚠️异常' : '正常' }}</td>
</tr>
</tbody>
</table>
</div>
<!-- 图表区 -->
<div style="flex:2;">
<h2>温湿度趋势 (最近20条)</h2>
<Line :data="chartData" :options="chartOptions"/>
</div>
</div>
</div>
</template>
<script setup>
import { ref, onMounted, computed } from 'vue'
import axios from 'axios'
import { Line } from 'vue-chartjs'
import { Chart as ChartJS, Title, Tooltip, Legend, LineElement, CategoryScale, LinearScale, PointElement } from 'chart.js'
ChartJS.register(Title, Tooltip, Legend, LineElement, CategoryScale, LinearScale, PointElement)
const sensorData = ref([])
const fetchData = async () => {
const res = await axios.get('http://localhost:8080/api/latest')
sensorData.value = res.data
}
const formatDate = (isoString) => {
const d = new Date(isoString)
return d.toLocaleTimeString()
}
const chartData = computed(() => {
const reversed = [...sensorData.value].reverse()
return {
labels: reversed.map(d => formatDate(d.createdAt)),
datasets: [
{
label: '温度(℃)',
data: reversed.map(d => d.temperature),
borderColor: 'red',
fill: false
},
{
label: '湿度(%)',
data: reversed.map(d => d.humidity),
borderColor: 'blue',
fill: false
}
]
}
})
const chartOptions = {
responsive: true,
maintainAspectRatio: true
}
onMounted(() => {
fetchData()
setInterval(fetchData, 3000)
})
</script>8.3 解决跨域
后端已经加了@CrossOrigin,前端直接调用即可。
8.4 运行前端
bash
npm run dev访问 http://localhost:5173,看到数据和图表动态更新。
九、启动所有组件(顺序)
-
MySQL
-
AI模块(python app.py)
-
后端(mvn spring-boot:run)
-
网关(python gateway.py)
-
嵌入式模拟器(./simulator)
-
前端(npm run dev)
十、效果演示
-
嵌入式模拟器每2秒发送随机温湿度。
-
网关转发 → 后端存库 → 调用AI服务判断是否异常。
-
如果数据偏离正常模式(例如温度突然35度,湿度20%),AI模块会返回
is_anomaly=true,表格中该行变红,前端高亮显示。 -
图表动态更新。
十一、拓展与真实硬件移植
11.1 将模拟STM32换成真实STM32
-
使用STM32CubeMX配置ETH或WiFi模块(如ESP8266 AT指令)。
-
传感器用DHT22(单总线)或DS18B20。
-
代码中用
lwip的socketAPI,或通过串口+ESP8266发送TCP数据。 -
数据格式不变,网关无需修改。
11.2 优化网关
-
使用MQTT替代TCP直连:嵌入式发布到MQTT Broker,网关订阅。
-
网关增加数据校验、重传机制。
11.3 提升AI能力
-
使用LSTM处理时序异常检测。
-
边缘AI:将模型轻量化后直接跑在STM32上(TensorFlow Lite Micro)。
十二、常见问题排查
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
| 嵌入式连接网关失败 | 网关未启动或端口被占用 | 先启动网关,检查8888端口 |
| 后端保存数据失败 | MySQL未启动或密码错误 | 检查MySQL服务,修改application.properties |
| AI模块返回500 | TensorFlow版本或模型路径错误 | 确保train_ae.py已成功运行生成.h5文件 |
| 前端跨域 | 后端未加@CrossOrigin | 在Controller上添加该注解 |
| 图表不显示 | Chart.js未正确引入 | 检查依赖和组件注册 |
通过这个项目,你亲手实践了从传感器到AI决策再到可视化的完整物联网链路。每一步都是实际工程中的缩略版,但核心概念完全一致。祝你在智能家居与全栈开发的道路上更进一步!
2.流程分析
你的流程(基本正确)
单片机(硬件) → 嵌入式(C) → 网关(Go) → 消息队列 → 后端(Java) → Python AI → 数据库 → 前端(Vue)
你画的这个流程大方向是对的 ,非常典型地体现了物联网/边缘计算+后端+AI的现代架构。不过如果从生产级系统的完整性来看,确实还缺几个关键环节。我帮你标注出来:
建议补充的环节(用 🔹 标出)
text
传感器/执行器 🔹
↓
单片机(硬件) → 嵌入式(C) ← 这里缺一个【设备管理/OTA】🔹
↓
[边缘计算节点(可选)] 🔹
↓
网关(Go) – 协议转换、高并发接收
↓
【消息队列(Kafka/RabbitMQ)】你已有,很好
↓
【流处理/数据清洗】🔹(可以用Flink、或者Go/Java写一个轻量的)
↓
后端(Java) – 复杂业务逻辑
↓
【API网关】🔹(对外统一入口,鉴权、限流)
↓
Python AI – 训练模型 & 推理(你可加上“推理服务”)
↓
【时序数据库】🔹(InfluxDB/TimescaleDB,物联网数据首选)
↓
【关系数据库】MySQL(存业务实体、用户等)
↓
【缓存】🔹(Redis,提速热数据)
↓
前端(Vue) – 展示
↓
【反向控制通道】🔹(前端下发指令到设备)重点解释几个你缺失但很关键的环节
1. 设备管理 & OTA(固件升级)
-
位置:嵌入式C与网关之间。
-
作用:记录设备在线/离线状态、远程升级固件、配置参数下发。
-
常用实现:MQTT的
$sys主题、阿里云IoT套件、自建EMQX + 后台。
2. 流处理/数据清洗(Stream Processing)
-
位置:消息队列之后,后端/数据库之前。
-
作用:过滤异常数据、聚合(比如求5秒平均温度)、格式统一。否则后端Java会承受大量原始"脏"数据。
-
可选方案:轻量用Go写一个consumer,重量用Flink/Kafka Streams。
3. 时序数据库(Time Series Database)
-
为什么MySQL不够?
物联网设备可能每秒上报数据,一年几十亿条,MySQL的B+树索引会很慢。时序数据库专门针对时间戳做高压缩、高写入、快速范围查询。
-
推荐:InfluxDB、TimescaleDB(基于PostgreSQL)、TDengine(国产)。
4. 缓存(Redis)
-
作用:存设备最新状态(实时看板)、设备配置、会话信息。避免每次请求都查MySQL。
-
典型用法:设备上报时,网关将最新值写入Redis;前端查询直接读Redis。
5. 反向控制通道(下行指令)
-
你的流程只有"数据上云",缺少"云端下发指令到设备"。
-
实现方式:
-
同步:HTTP + 设备长轮询(不推荐)。
-
异步:MQTT(设备订阅命令主题) + Redis记录命令状态。
-
-
所以需要在前端和后端之间增加一个指令下发服务(可用Go或Java写),调用MQTT publish。
6. API网关
-
位置:前端与后端之间。
-
作用:统一入口、认证鉴权、限流熔断、日志监控。
-
常见:Nginx + Lua,或者Kong、Traefik(Go)、Spring Cloud Gateway。
7. 边缘计算节点(可选但常见)
-
位置:嵌入式C与网关之间。
-
作用:靠近设备做一些预处理(比如温度突变报警、视频抽帧),减少云端压力、降低延迟。
-
硬件:树莓派、Jetson Nano,软件可用Python或Go。
修正后的完整生产级流程(可串行,也可并行)
text
【设备侧】
传感器/执行器 → 单片机(C固件) → (可选:边缘计算节点) → 网关(Go/EMQX)
↑ ↓
└──────────── 下行指令(MQTT) ← ← ← ← ← ← ← ← ← ← ← ← ┘
【云侧】
网关后 → 消息队列(Kafka)→ 流清洗(Flink/Go)→ 时序数据库(InfluxDB)
↓
业务后端(Java) → MySQL / Redis
↓
API网关(鉴权) ← 前端Vue
↓
Python AI(训练+推理服务)→ 结果写回MySQL/Redis
↓
反向控制服务(下发指令)→ MQTT → 设备总结:你的流程缺少的"灵魂"是 双向通信 + 数据分层存储 + 边缘处理
| 你的环节 | 是否必要 | 补充建议 |
|---|---|---|
| 单片机→嵌入式C | ✅ 核心 | 加上设备管理/OTA |
| 网关Go | ✅ 核心 | 可同时作为MQTT broker或桥接 |
| 消息队列 | ✅ 核心 | 注意分区键设计(设备ID) |
| 后端Java | ✅ 可选(Go也可) | 适合复杂事务逻辑 |
| Python AI | ✅ 合理 | 注意把推理服务化,不要训练和推理混在一起 |
| MySQL | ⚠️ 不足 | 加时序数据库+缓存 |
| Vue前端 | ✅ | 别忘了WebSocket实时推送 |
如果你只是做一个毕业设计或个人项目 ,原流程足够跑通;如果是真实产品 ,建议至少加入:时序数据库 + Redis + 反向指令通道。
3.结合运维
前面我们讨论的架构更像是"开发视角"的流水线,而运维(Operations,简称 Ops) 则是让这条流水线稳定、安全、高效地跑在生产环境中,并持续保障它不出问题。简单说:开发负责"造出来",运维负责"跑起来"。
在你的架构中,运维的职责贯穿所有环节,可以分成四个维度:部署与发布、监控与告警、日志与追踪、备份与恢复。下面我逐一补充到你的流程里。
一、运维在各个环节的具体工作
| 环节 | 运维做什么 | 常用工具/平台 |
|---|---|---|
| 单片机/嵌入式 | 固件版本管理、远程升级(OTA)、设备注册与认证 | OTA服务器(如 Hawkbit)、设备管理平台(如 ThingsBoard)、工厂烧录工具 |
| 网关 (Go) | 部署网关服务(容器化或二进制)、配置管理、负载均衡、自动伸缩 | Docker/Kubernetes、Nginx、Consul、Envoy |
| 消息队列 (Kafka/RabbitMQ) | 集群部署、监控积压、磁盘容量、认证授权、topic 规划 | Kafka Manager、Prometheus + Grafana、Burrow |
| 后端 (Java) | 应用部署、JVM 调优、健康检查、滚动更新、熔断降级 | K8s、Spring Boot Actuator、Hystrix、Sentinel |
| Python AI 服务 | 模型版本管理、GPU 资源调度、推理服务高可用、定时训练任务 | Docker + NVIDIA runtime、Kubeflow、MLflow、Airflow |
| 时序数据库 (InfluxDB/TDengine) | 集群部署、备份策略、数据保留策略(Retention Policy)、降采样 | InfluxDB OSS/Enterprise、TimescaleDB 工具 |
| 关系数据库 (MySQL) | 主从复制、读写分离、慢查询分析、定期备份、故障切换 | MySQL Router、Percona XtraBackup、Orchestrator |
| 缓存 (Redis) | 哨兵/集群模式、内存监控、持久化配置、数据淘汰策略 | Redis Sentinel、Redis Cluster、Prometheus Redis exporter |
| API 网关 (Kong/Nginx) | 路由配置、SSL 证书管理、限流规则、日志记录 | Kong Manager、Nginx + Let's Encrypt、OpenResty |
| 前端 (Vue) | 静态文件托管、CDN 加速、版本发布(灰度) | Nginx、OSS + CDN(阿里云/腾讯云)、S3 + CloudFront |
二、运维的横向支撑平台(独立于业务环节)
除了对每个组件的维护,运维还会搭建统一的平台:
-
容器编排平台(Kubernetes)
-
管理所有云侧服务的部署、伸缩、自愈。
-
例:网关 Go、后端 Java、AI 推理、消息队列的消费者都可以跑在 K8s 上。
-
-
监控与告警系统
-
采集指标(CPU、内存、QPS、延迟、错误率)。
-
核心工具:Prometheus + Grafana。
-
告警通过 Alertmanager 发送到钉钉、微信、邮件。
-
-
日志系统
-
集中收集所有服务(Go/Java/Python/Nginx/MySQL)的日志。
-
工具栈:Fluentd/Logstash + Elasticsearch + Kibana (ELK) 或 Loki + Grafana。
-
-
链路追踪
-
追踪一个请求从前端 → 网关 → 后端 → 数据库 → 消息队列的完整调用链。
-
工具:Jaeger 、SkyWalking。
-
-
自动化运维工具
- 批量操作、配置管理、任务编排:Ansible 、SaltStack 、Terraform(基础设施即代码)。
-
安全与合规
-
漏洞扫描、容器镜像安全、网络策略、数据加密、访问控制。
-
工具:Clair 、Trivy 、Open Policy Agent (OPA)。
-
三、将运维融入你的流程图(修正版)
text
【开发阶段】
单片机C固件 → 嵌入式 → 网关Go → 消息队列 → Java后端 → AI Python → 数据库/缓存 → 前端Vue
↓ ↓ ↓ ↓ ↓ ↓ ↓
【运维阶段】
版本管理 镜像构建 CI/CD 集群部署 监控告警 日志采集 备份恢复
(OTA) (Docker) (GitLab CI/Jenkins) (Prometheus) (ELK) (定期快照)
【横向平台】
Kubernetes 集群(运行所有云上服务) + 服务网格(Istio,可选)四、开发与运维的衔接:DevOps
你问"那运维呢",其实现在更流行的做法是开发自运维(DevOps 文化),即:
-
开发人员写完代码后,通过 CI/CD 流水线(GitHub Actions、GitLab CI、Jenkins)自动打包、测试、部署到 K8s。
-
开发也要自己配置监控指标和日志输出,便于运维团队(或 SRE)接管。
所以你架构中缺的不是简单的"运维"两个字,而是:
-
CI/CD 流水线(从 git push 到上线自动完成)。
-
容器化(每个服务都有 Dockerfile)。
-
编排(K8s 的 Deployment、Service、Ingress)。
-
监控 + 告警 + 日志 + 追踪。
-
备份恢复策略(尤其是数据库和消息队列的重要数据)。
五、回答你可能的潜问题:运维需要会什么技术?
针对你上面这套架构,一个合格的运维工程师(或全栈+运维)需要掌握:
-
Linux 系统管理(必选)
-
Docker / Kubernetes(必选)
-
CI/CD 工具(Jenkins/GitLab CI)
-
Prometheus + Grafana 监控
-
ELK 或 Loki 日志
-
至少一种脚本语言(Python/Shell)
-
云平台基础(AWS/阿里云/腾讯云)
如果你现在是开发人员,想补齐运维视角,可以从Docker 化你的每个服务 开始,然后用 docker-compose 在本地跑起整套架构,再逐步迁移到 K8s 和 Prometheus。
总结一句话
运维就是为你的整个"单片机 → 云 → 前端"架构加上"眼睛"(监控)、"手脚"(自动部署/伸缩)、"保险柜"(备份)和"交通警察"(限流/熔断),保证它能在真实世界中7x24小时稳定运行。
你的架构如果只做开发,跑通 demo 没问题;但想上生产,必须把运维的四个支柱(部署、监控、日志、备份)加进去。
4.docker和k8s
Docker 和 Kubernetes(K8s)正是现代运维和微服务架构的基石。我把它们放在你之前的"单片机→云→前端"架构中,用最直白的方式解释清楚。
一、Docker:打包应用的可移植"集装箱"
1.1 它解决了什么问题?
-
传统痛点:代码在开发机跑得好好的,到测试/生产环境就报错(依赖不同、操作系统版本不同、库冲突)。
-
Docker 方案 :把应用 + 它的运行环境(操作系统、库、配置) 一起打包成一个镜像。镜像在任意有 Docker 的机器上启动,都得到完全一致的环境。
1.2 核心概念
| 概念 | 通俗理解 | 类比 |
|---|---|---|
| 镜像 (Image) | 一个只读的"安装包",里面包含你的程序和环境 | 类似一个 ISO 光盘文件 |
| 容器 (Container) | 镜像运行起来后的实例,可读写,可启动/停止/删除 | 光盘放入光驱后运行的系统 |
| 仓库 (Registry) | 存放镜像的地方,可以公开(Docker Hub)或私有 | 应用商店(App Store) |
| Dockerfile | 描述如何构建镜像的脚本 | 配方/说明书 |
1.3 对你架构的价值
-
每个服务(网关 Go、后端 Java、AI Python、MySQL、Redis、前端 Nginx) 都可以做成 Docker 镜像。
-
好处:
-
开发环境一键启动整套系统(
docker-compose up)。 -
测试、生产环境不再有"环境不一致"的借口。
-
方便水平扩展(多实例)和版本回滚。
-
小提醒 :单片机上的 C 固件不能直接 Docker 化(它是裸机/RTOS 环境),但固件的编译工具链、烧录脚本、模拟器可以放在 Docker 里,实现跨平台的固件编译。
二、Kubernetes (K8s):管理成千上万个容器的"集装箱调度中心"
2.1 它解决了什么问题?
-
Docker 的局限:你手动启动一个容器很简单,但如果有几十个微服务(网关、后端、AI、消息队列消费者...),每个服务需要多个副本(应对流量),还要自动重启、滚动升级、负载均衡、服务发现... 手动管理根本不可能。
-
K8s 方案 :一个容器编排平台,自动调度、伸缩、管理容器集群。
2.2 核心概念(简版)
| 概念 | 作用 | 通俗类比 |
|---|---|---|
| Pod | 最小部署单元,一个 Pod 里跑一个或多个容器(通常一个) | 集装箱里的一个房间 |
| Deployment | 控制 Pod 的副本数、滚动更新、回滚 | 房间的物业管理,保证始终有 N 个房间可用 |
| Service | 给一组 Pod 提供固定的 IP 和负载均衡 | 物业总机,你打一个电话,它自动转接到空闲的房间 |
| Ingress | 把外部 HTTP 请求路由到内部 Service | 大楼的门牌号和引导牌 |
| ConfigMap/Secret | 管理配置和敏感信息(密码、Token) | 大楼的公告栏和保险柜 |
| Namespace | 虚拟隔离环境,比如分"开发""测试""生产" | 不同楼层 |
2.3 对你架构的价值
-
自动伸缩:当网关 Go 服务 CPU 过高时,K8s 自动增加它的 Pod 数量。
-
自愈:某个 Java 后端崩溃了,K8s 自动重启一个新的。
-
滚动更新:发布新版本时,先启动一个新 Pod,等它正常服务后再停掉旧 Pod,全程不中断业务。
-
服务发现 :AI Python 服务不需要硬编码 MySQL 的 IP,只需访问
mysql-service这个域名,K8s 自动解析到实际的 Pod IP。 -
资源利用率:多个服务混合部署在一台物理机上,节省成本。
注意 :K8s 管理的对象必须是容器化的(通常是 Docker)。所以 Docker 是基础,K8s 是上层管理。
三、在你的完整架构中,Docker + K8s 怎么用?
3.1 哪些环节可以容器化?
| 组件 | 是否可容器化 | 备注 |
|---|---|---|
| 单片机 C 固件 | ❌ 裸机运行 | 但编译工具链可放 Docker |
| 网关 Go | ✅ | 轻量级,非常适合 |
| 消息队列 Kafka | ✅ | 有官方镜像,但状态管理需用 StatefulSet |
| 后端 Java | ✅ | 典型 Spring Boot 应用 |
| AI Python 推理服务 | ✅ | 注意 GPU 调度(需安装 NVIDIA 容器工具) |
| MySQL / InfluxDB | ✅ | 推荐用云数据库或托管服务,自建需谨慎管理持久化 |
| Redis | ✅ | 有状态应用,可用 StatefulSet + 持久卷 |
| Nginx / Vue 前端 | ✅ | 静态文件打包成 Nginx 镜像 |
3.2 一个典型的部署拓扑(K8s 集群内)
text
用户请求 → Ingress (Nginx) → Service (前端Vue) → Service (API网关) → Service (后端Java) → 消息队列 Kafka (Headless Service)
↓
Service (AI推理) → 数据库 Service所有 Service 的 Pod 由 Deployment 管理,通过 ConfigMap 配置,Secret 存密码,HPA(Horizontal Pod Autoscaler)自动伸缩。
四、对比传统部署 vs Docker vs K8s
| 维度 | 传统部署(物理机/虚拟机) | Docker | Docker + K8s |
|---|---|---|---|
| 环境一致性 | 差 | 好 | 好 |
| 启动速度 | 分钟级(虚拟机) | 秒级 | 秒级 |
| 资源占用 | 大(每虚拟机有完整 OS) | 小(共享宿主机内核) | 小 |
| 扩容方式 | 手动加机器,部署应用 | 手动 docker run 多个实例 |
自动根据指标伸缩 Pod |
| 服务发现 | 硬编码 IP 或依赖配置中心 | 手动或借助 Consul 等 | 内置 DNS 和负载均衡 |
| 滚动更新 | 复杂,需要脚本 | 手动停止旧容器,启动新 | 自动滚动,支持健康检查 |
| 故障自愈 | 无(需监控脚本重启) | 无(进程死了需外部拉起) | 有(ReplicaSet 保证 Pod 数量) |
| 学习成本 | 低 | 中 | 高 |
所以,docker是容器化,k8s是容器集群化吗
是的,你这个总结非常精准,一句话抓住了核心区别:
-
Docker → 容器化(把应用打包成标准化的"集装箱",实现环境隔离和可移植性)。
-
Kubernetes (K8s) → 容器集群化(把成百上千个容器组织成一个集群,自动调度、伸缩、修复、服务发现)。
为了更严谨一点,可以这样表述:
Docker 是容器引擎 ,负责单机 上容器的构建、运行和生命周期管理。
K8s 是容器编排平台 ,负责多机集群中容器的部署、扩缩容、负载均衡和自愈。
5.k8s
Kubernetes(常简称为 K8s,因为 K 和 s 之间有 8 个字母) 是一个开源的容器编排平台 。它的核心任务是自动管理成百上千个容器,让它们像一支协同工作的军队,而不是一堆混乱的进程。
简单说:Docker 负责"把应用装进集装箱",Kubernetes 负责"在全世界码头上调度这些集装箱"。
一、Kubernetes 能做什么?(核心价值)
| 功能 | 通俗解释 |
|---|---|
| 自动部署与回滚 | 你声明"我要跑 10 个网关容器",K8s 会确保始终有 10 个在运行;更新版本时,先启新再停旧,全程不中断业务。 |
| 服务发现与负载均衡 | 容器会动态漂移(重启后 IP 会变),K8s 给一组容器一个固定的虚拟 IP(Service),自动把流量分发到后面的容器。 |
| 水平伸缩 | 网关 CPU 过高?一条命令或自动策略,把副本数从 3 提到 10。 |
| 自愈 | 容器挂了自动重启;节点宕机了,把该节点上的容器调度到健康节点。 |
| 存储编排 | 自动挂载云存储、NFS、本地盘给容器,容器漂移后存储也能跟着走。 |
| 配置管理 | 把配置(ConfigMap)和密码(Secret)注入容器,不用改镜像。 |
二、关键概念速览(对照你的架构)
| 概念 | 对应你架构里的例子 |
|---|---|
| Pod | 最小的调度单元,里面跑一个或多个容器。通常一个 Pod 跑一个网关容器。 |
| Deployment | 管理网关 Go 服务的副本数、滚动更新。你声明"网关需要 3 个 Pod",它负责维持。 |
| Service | 给网关 Pod 组提供一个固定 IP 和 DNS 名,其他服务(如后端 Java)通过 gateway-service 访问。 |
| Ingress | 外部 HTTP 请求(比如手机 App 的 API 调用)进入集群的门牌号 + 路由规则。 |
| Namespace | 把开发、测试、生产环境隔离在同一个集群内。 |
| PersistentVolume | 给 MySQL、InfluxDB 等有状态服务提供持久化存储,Pod 重启数据不丢。 |
三、为什么需要 Kubernetes?(没有它行不行?)
-
只有 Docker 的情况 :你可以在单台机器上手动
docker run几个容器,或者用docker-compose管理。
问题:机器挂了就全完蛋;流量高了得手动改配置、手动加机器;更新得自己写脚本停掉旧容器再启新的,有 downtime。 -
有 Kubernetes:所有问题自动化解决,集群可以跨几十上百台机器,开发者只管声明"我要什么",K8s 保证"是什么"。
四、在你的"单片机→云→前端"架构中,K8s 的位置
text
[边缘侧] 裸机/单片机 → 网关(Docker 容器,可选) → 互联网
↓
[云侧] Kubernetes 集群
├── Ingress (Nginx) → 前端 Vue Pods
├── Service (网关) → Go 网关 Pods (3 副本)
├── Service (后端) → Java 后端 Pods
├── Service (AI) → Python AI Pods
├── Kafka (用 StatefulSet 部署)
├── MySQL (用 StatefulSet + 持久卷)
└── Redis (Deployment + 持久卷)-
所有云上服务(除了云数据库可能用托管)都跑在 K8s 里。
-
开发者只需提交 YAML 文件(比如
gateway-deployment.yaml),K8s 自动创建、调度、监控。