引言
本篇主要介绍一下langgraph开发部署问题。langchain底层执行已经切换成了langgraph,从这个层面来看,langchain依赖的于langgrap,所以在新版的langchain看不到了那种让人迷惑的管道操作链式调用。从这点来看,我们应该使用langchain开发。但是当你学习langgraph时,你发现langgraph在使用langchain。这看起来交互式有点复杂。如果是简单的智能体应用,可以考虑直接使用langchain。langchain的子代理、移交、路由、技能多agent模式如果能满足架构需求,就可以不用langgraph,越复杂的东西越不好维护,以后想升级也困难。如果涉及复杂工作流或者图结构,那么可以考虑使用图。
1 应用架构
LangGraph 应用程序由一个或多个图(Graph)、一个配置文件(langgraph.json)、一个指定依赖关系的文件,以及一个可选的用于定义环境变量的 .env 文件组成。本指南将展示应用程序的典型结构,并演示如何提供必要的配置,以便通过 LangSmith 部署应用程序。
LangSmith Deployment 是一个托管式平台,专门用于部署和扩展 LangGraph 智能体。它负责处理底层基础设施、弹性伸缩以及运维相关的事务,让你可以直接从代码仓库部署那些有状态的、长期运行的智能体。你可以在部署文档中了解更多详情
1.1 核心概念
- LangGraph 配置文件 (
langgraph.json):用于指定应用程序所需的依赖项、图结构以及环境变量。 - 应用逻辑图 (Graphs):即实现应用程序核心业务逻辑的代码。
- 依赖文件 :用于指定运行应用程序所需的各种库和依赖项(通常指
requirements.txt或pyproject.toml)。 - 环境变量:应用程序运行所必需的环境配置参数(如 API 密钥等)
1.2 文件架构
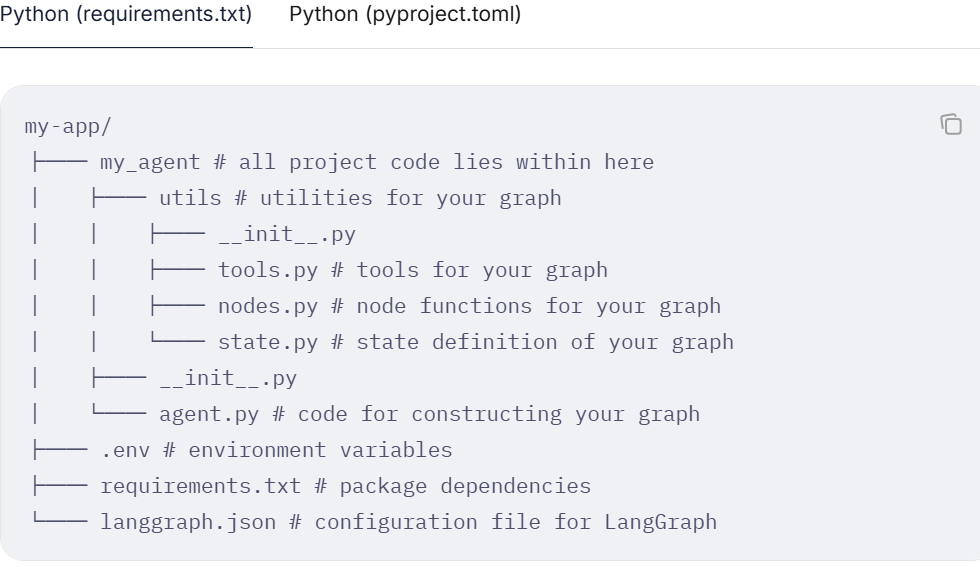
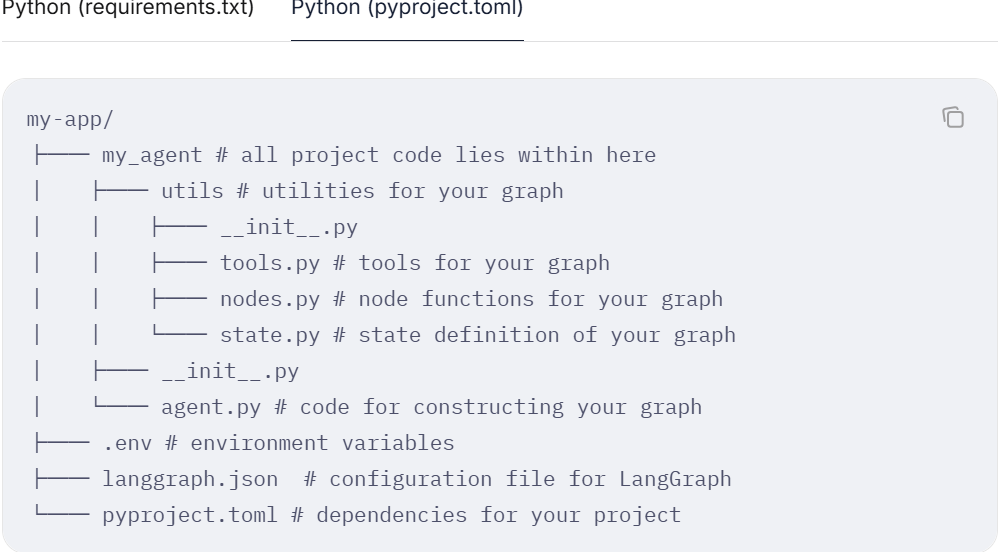
推荐使用后面这种方式,依赖管理可以使用uv或者poetry
1.3 配置文件
langgraph.json 文件是一个 JSON 格式的配置文件,它专门用于指定部署 LangGraph 应用程序所需的依赖项、图结构、环境变量以及其他设置。
关于该 JSON 文件中支持的所有配置键(keys)的详细信息,请查阅 LangGraph 配置文件参考文档。
LangGraph 命令行工具(CLI)默认会使用当前目录下的 langgraph.json 配置文件
示例
-
依赖项 :包含一个自定义的本地包以及
langchain_openai包。 -
图加载 :将从
./your_package/your_file.py文件中加载一个图,对应的变量名为variable。 -
环境变量 :从
.env文件中加载{ "dependencies": ["langchain_openai", "./your_package"], "graphs": { "my_agent": "./your_package/your_file.py:agent" }, "env": "./.env" } 上面的配置依赖项写成了''.'',表示依赖由层的requirements.txt或者pyproject.toml提供
上面的配置依赖项写成了''.'',表示依赖由层的requirements.txt或者pyproject.toml提供
1.4 依赖
LangGraph 应用程序可能会依赖其他的 Python 包。
为了确保依赖项能正确配置,你通常需要提供以下信息:
- 依赖文件 :在目录中包含一个用于指定依赖的文件(例如
requirements.txt、pyproject.toml或package.json)。 - 配置键 :在 LangGraph 配置文件(
langgraph.json)中包含一个dependencies键,用于指定运行 LangGraph 应用程序所需的依赖项(通常是指向上述文件的引用)。 - 系统级依赖 :任何额外的二进制文件或系统库,可以通过 LangGraph 配置文件中的
dockerfile_lines键来指定。
1.5 图
请使用 LangGraph 配置文件中的 graphs 键,来指定哪些图(Graphs)将在部署后的 LangGraph 应用程序中可用。你可以在配置文件中指定一个或多个图。每个图都需要通过一个唯一的名称和一个路径来标识,该路径指向以下两者之一:已编译的图对象(即直接指向图实例)。
定义图的函数(即指向一个能构建并返回图的函数)。
1.6 环境变量
如果你在本地运行已部署的 LangGraph 应用程序(进行调试),你可以在 LangGraph 配置文件的 env 键中配置环境变量。对于生产环境的部署,你通常需要在部署环境(即云端的设置面板)中配置环境变量
2 测试
在你完成了 LangGraph 智能体的原型设计后,接下来的自然步骤就是添加测试。本指南将介绍一些在编写单元测试时可以使用的实用模式。
请注意 :本指南是专门针对 LangGraph 的,主要涉及具有自定义结构 的图(Graphs)的测试场景。如果你只是刚入门,建议先查阅关于使用 LangChain 内置 create_agent 的测试指南
2.1 准备
pip install -U pytest2.2 开始
由于许多 LangGraph 智能体都依赖于状态(State),一个实用的模式是:在每次使用图之前先构建它,然后在测试内部使用一个新的检查点(Checkpointer)实例对其进行编译。下面的示例展示了这一过程是如何运作的:它使用了一个简单的线性图,依次经过 node1 和 node2。每个节点都会更新唯一的状态键 my_key
python
import pytest
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
def create_graph() -> StateGraph:
class MyState(TypedDict):
my_key: str
graph = StateGraph(MyState)
graph.add_node("node1", lambda state: {"my_key": "hello from node1"})
graph.add_node("node2", lambda state: {"my_key": "hello from node2"})
graph.add_edge(START, "node1")
graph.add_edge("node1", "node2")
graph.add_edge("node2", END)
return graph
def test_basic_agent_execution() -> None:
checkpointer = MemorySaver()
graph = create_graph()
compiled_graph = graph.compile(checkpointer=checkpointer)
result = compiled_graph.invoke(
{"my_key": "initial_value"},
config={"configurable": {"thread_id": "1"}}
)
assert result["my_key"] == "hello from node2"2.3 测试独立的节点和边
已编译的 LangGraph 智能体会通过 graph.nodes 暴露对每个独立节点的引用。你可以利用这一点来测试智能体内部的单个节点。
请注意 :这样做会绕过编译图时传入的任何检查点(Checkpointer):
python
import pytest
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
def create_graph() -> StateGraph:
class MyState(TypedDict):
my_key: str
graph = StateGraph(MyState)
graph.add_node("node1", lambda state: {"my_key": "hello from node1"})
graph.add_node("node2", lambda state: {"my_key": "hello from node2"})
graph.add_edge(START, "node1")
graph.add_edge("node1", "node2")
graph.add_edge("node2", END)
return graph
def test_individual_node_execution() -> None:
# Will be ignored in this example
checkpointer = MemorySaver()
graph = create_graph()
compiled_graph = graph.compile(checkpointer=checkpointer)
# Only invoke node 1
result = compiled_graph.nodes["node1"].invoke(
{"my_key": "initial_value"},
)
assert result["my_key"] == "hello from node1"2.4 部分执行
对于由大型图构成的智能体,你可能希望测试智能体内部的部分执行路径 ,而不是整个端到端的流程。在某些情况下,将这些部分重构为子图并在隔离状态下调用它们在语义上是合理的。
但是,如果你不想更改智能体图的整体结构,你可以利用 LangGraph 的持久化机制 来模拟一种状态:让智能体在目标部分开始前暂停 ,并在目标部分结束后再次暂停。
具体步骤如下:
- 使用检查点(Checkpointer)编译你的智能体(对于测试而言,内存检查点
InMemorySaver就足够了)。 - 调用智能体的
update_state方法,并将as_node参数设置为你想要开始测试的那个节点之前的节点名称。 - 使用与更新状态时相同的
thread_id调用你的智能体,并将interrupt_after参数设置为你想要停止的那个节点的名称。
这是一个示例,展示了如何在线性图中仅执行第二个和第三个节点
python
import pytest
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
def create_graph() -> StateGraph:
class MyState(TypedDict):
my_key: str
graph = StateGraph(MyState)
graph.add_node("node1", lambda state: {"my_key": "hello from node1"})
graph.add_node("node2", lambda state: {"my_key": "hello from node2"})
graph.add_node("node3", lambda state: {"my_key": "hello from node3"})
graph.add_node("node4", lambda state: {"my_key": "hello from node4"})
graph.add_edge(START, "node1")
graph.add_edge("node1", "node2")
graph.add_edge("node2", "node3")
graph.add_edge("node3", "node4")
graph.add_edge("node4", END)
return graph
def test_partial_execution_from_node2_to_node3() -> None:
checkpointer = MemorySaver()
graph = create_graph()
compiled_graph = graph.compile(checkpointer=checkpointer)
compiled_graph.update_state(
config={
"configurable": {
"thread_id": "1"
}
},
# The state passed into node 2 - simulating the state at
# the end of node 1
values={"my_key": "initial_value"},
# Update saved state as if it came from node 1
# Execution will resume at node 2
as_node="node1",
)
result = compiled_graph.invoke(
# Resume execution by passing None
None,
config={"configurable": {"thread_id": "1"}},
# Stop after node 3 so that node 4 doesn't run
interrupt_after="node3",
)
assert result["my_key"] == "hello from node3"3 LangSmith Studio
请参看langchain篇
4 Agent Chat UI
请参看langchain篇
5 LangSmith 部署
请参看langchain篇
6 LangSmith 监测
请参看langchain篇
7 前端
7.1 概览
构建能够实时可视化 LangGraph 管道(pipelines)的前端。这些模式展示了如何渲染多步骤的图执行过程,包括每个节点的状态 以及来自自定义 StateGraph 工作流的流式内容
7.1.1 架构
LangGraph 的图是由通过边连接的命名节点 组成的。每个节点执行一个步骤(如分类、研究、分析、综合),并将输出写入特定的状态键(state key) 。在前端方面,useStream 提供了对节点输出、流式 Token 和图元数据的响应式访问 ,使你可以将每个节点映射为一个 UI 卡片
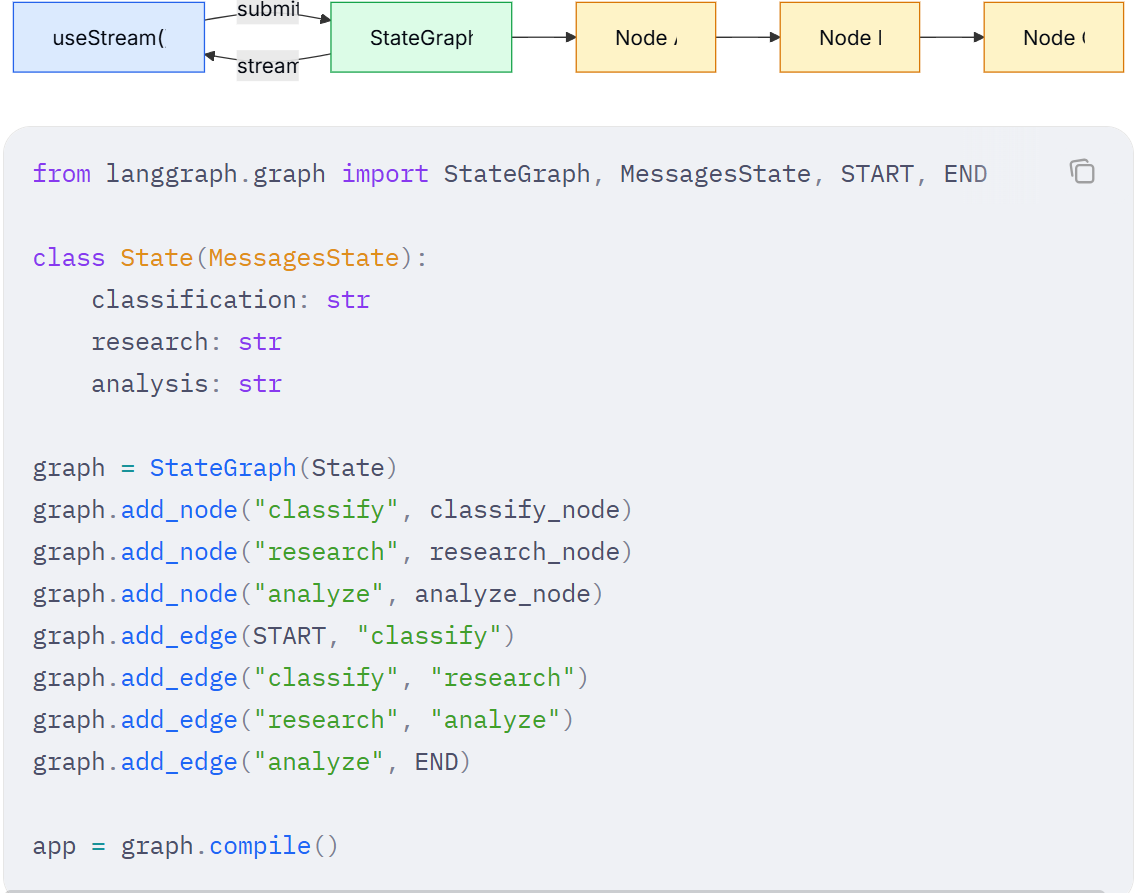
在前端,useStream 暴露了 stream.values 用于获取已完成节点的输出,以及 getMessagesMetadata 用于识别每个流式 Token 是由哪个节点生成的
import { useStream } from "@langchain/react";
function Pipeline() {
const stream = useStream<typeof graph>({
apiUrl: "http://localhost:2024",
assistantId: "pipeline",
});
const classification = stream.values?.classification;
const research = stream.values?.research;
const analysis = stream.values?.analysis;
}7.1.2 模式
**图执行:**可视化多步骤的图管道,展示每个节点的状态和流式内容
7.1.3 相关模式
LangChain 的前端模式------包括 Markdown 消息、工具调用、乐观更新等------适用于任何 LangGraph 图。无论你使用的是 createAgent、createDeepAgent 还是自定义的 StateGraph,useStream 钩子都提供相同的核心 API
7.2 图执行
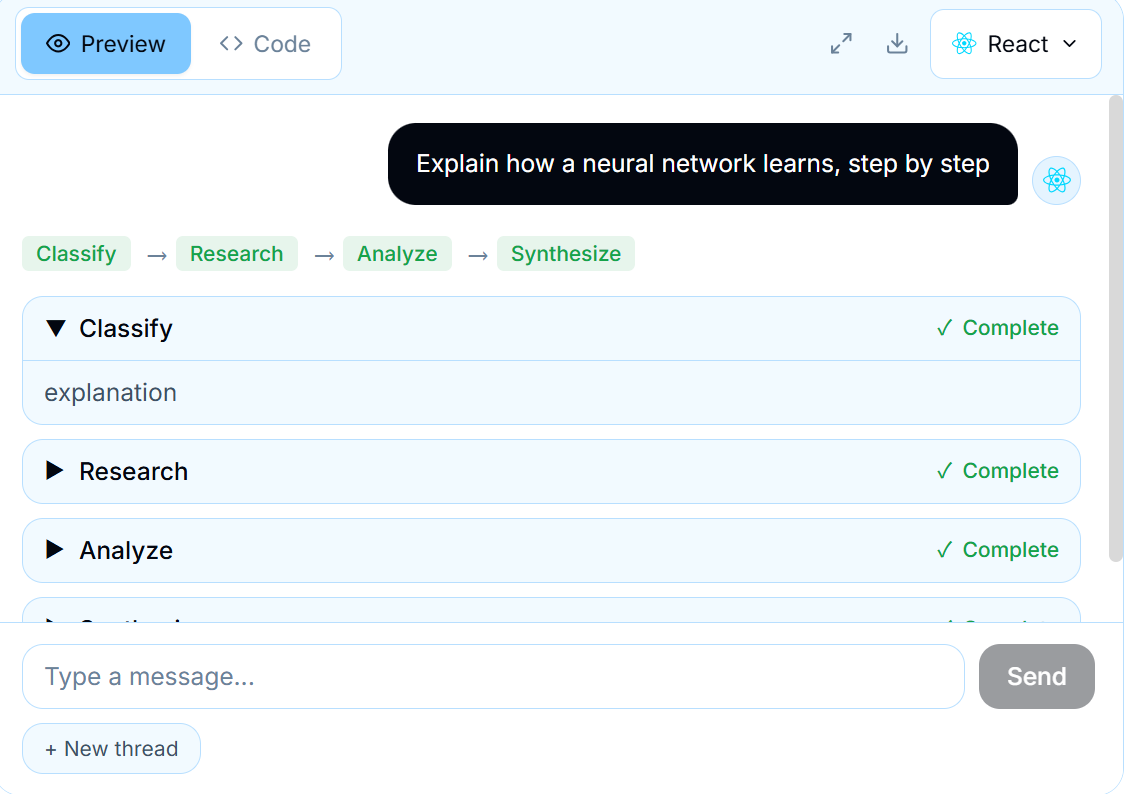
LangGraph 智能体并不是黑盒 。每个图都是由按顺序或并行执行的命名节点 组成的:比如分类、研究、分析、综合。图执行卡片 通过为每个节点渲染一个卡片,让这条管道变得可见 。这些卡片会显示节点的状态,实时流式展示其内容,并追踪整个工作流的完成情况。用户可以确切地看到智能体正在做什么、当前处于哪一步,以及每一步产出了什么结果。
7.2.1 图节点如何映射为 UI 卡片
一个 LangGraph 图定义了一系列节点,每个节点负责一项特定的任务。例如,一个研究管道可能包含:
分类:对用户查询进行归类
研究:收集相关信息
分析:从研究中得出结论
综合:生成最终完善的回复
每个节点都会将其输出写入图的状态中的特定键。通过将这些节点名称和状态键映射到 UI 组件,你就可以创建整个管道的可视化表示
const PIPELINE_NODES = [
{ name: "classify", stateKey: "classification", label: "Classify" },
{ name: "do_research", stateKey: "research", label: "Research" },
{ name: "analyze", stateKey: "analysis", label: "Analyze" },
{ name: "synthesize", stateKey: "synthesis", label: "Synthesize" },
];
const PIPELINE_NODE_NAMES = new Set(PIPELINE_NODES.map((n) => n.name));7.2.2 设置 useStream
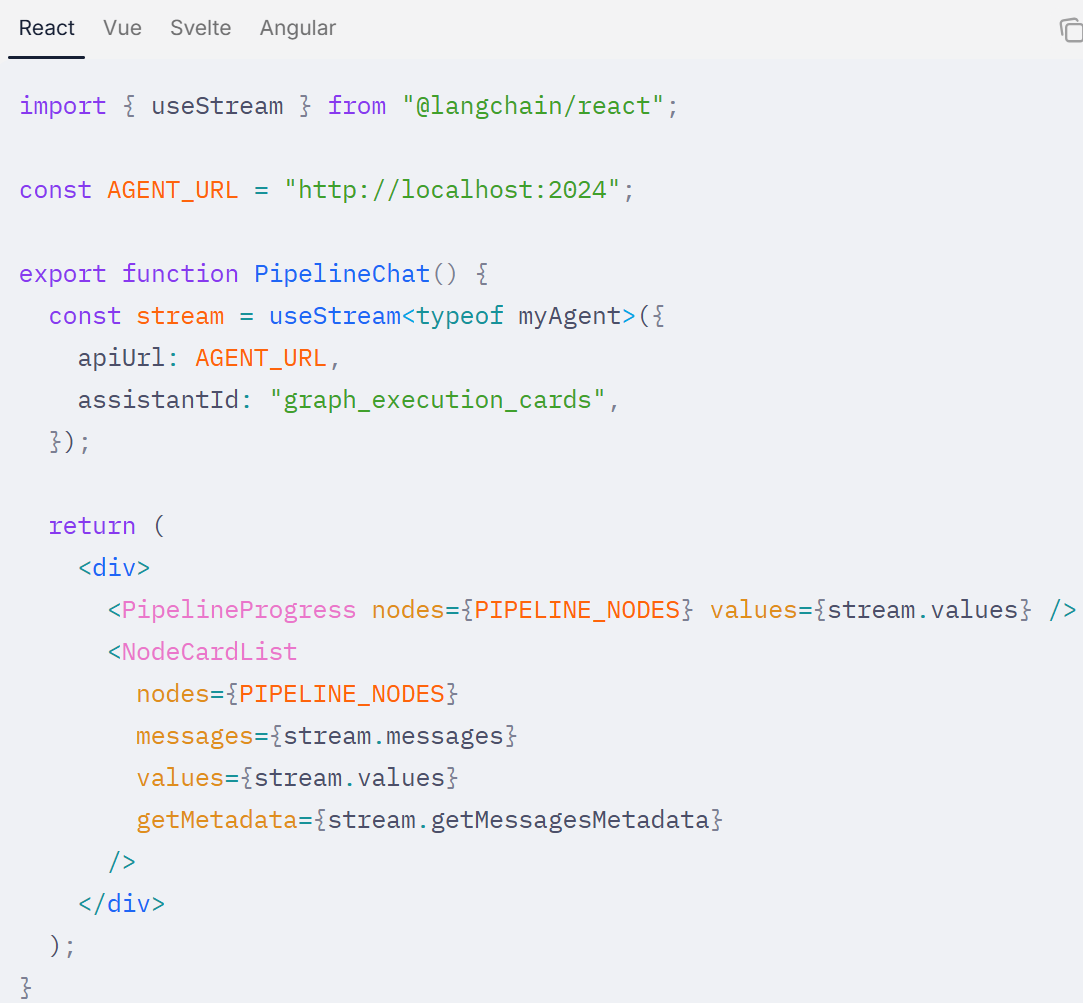
像往常一样连接 useStream。你将使用的关键属性有:
messages:用于流式内容的路由。values:用于获取已完成的节点输出。getMessagesMetadata:用于识别每个 Token 是由哪个节点生成的。
定义一个与你的智能体状态模式匹配的 TypeScript 接口 ,并将其作为类型参数传递给 useStream。这样可以让你类型安全地 访问状态值,包括每个管道节点的自定义状态键。在下面的示例中,请用你的接口名称替换 typeof myAgent
import type { BaseMessage } from "@langchain/core/messages";
interface AgentState {
messages: BaseMessage[];
classification: string;
research: string;
analysis: string;
synthesis: string;
}
7.2.3 将流式 Token 路由到节点
当智能体进行流式输出时,每条消息都会附带元数据 ,用于标识它是由哪个图节点生成的。请使用 getMessagesMetadata 提取 langgraph_node 的值,并将 Token 路由到正确的卡片:
function getStreamingContent(
messages: BaseMessage[],
getMetadata: (msg: BaseMessage) => MessageMetadata | undefined
): Record<string, string> {
const content: Record<string, string> = {};
for (const message of messages) {
if (message.type !== "ai") continue;
const metadata = getMetadata(message);
const node = metadata?.streamMetadata?.langgraph_node;
if (node && PIPELINE_NODE_NAMES.has(node)) {
content[node] = typeof message.content === "string"
? message.content
: "";
}
}
return content;
}
function getStreamingContent(
messages: BaseMessage[],
getMetadata: (msg: BaseMessage) => MessageMetadata | undefined
): Record<string, string> {
const content: Record<string, string> = {};
for (const message of messages) {
if (message.type !== "ai") continue;
const metadata = getMetadata(message);
const node = metadata?.streamMetadata?.langgraph_node;
if (node && PIPELINE_NODE_NAMES.has(node)) {
content[node] = typeof message.content === "string"
? message.content
: "";
}
}
return content;
}这样你就得到了一个从节点名称 到其当前流式内容 的映射。随着 Token(字符)的不断到达,对应的卡片会实时更新
7.2.4 确定节点状态
每个节点可能处于四种状态之一:未开始 、流式中 、已完成 或空闲。你需要从两个来源推导(计算)出状态:
-
流式内容映射 :用于判断哪些节点是**活跃(正在运行)**的。
-
stream.values:用于判断哪些节点已经完成type NodeStatus = "idle" | "streaming" | "complete";
function getNodeStatus(
node: { name: string; stateKey: string },
streamingContent: Record<string, string>,
values: Record<string, unknown>
): NodeStatus {
if (values?.[node.stateKey]) return "complete";
if (streamingContent[node.name]) return "streaming";
return "idle";
}
7.2.5 构建管道进度条
顶部的水平进度条可以让用户对整个管道有一个鸟瞰视角(全局概览)。每个步骤都是一个带有标签的区段,随着节点的完成,这些区段会逐渐填充:
function PipelineProgress({
nodes,
values,
streamingContent,
}: {
nodes: typeof PIPELINE_NODES;
values: Record<string, unknown>;
streamingContent: Record<string, string>;
}) {
return (
<div className="flex items-center gap-1">
{nodes.map((node, i) => {
const status = getNodeStatus(node, streamingContent, values);
const colors = {
idle: "bg-gray-200 text-gray-500",
streaming: "bg-blue-400 text-white animate-pulse",
complete: "bg-green-500 text-white",
};
return (
<div key={node.name} className="flex items-center">
<div
className={`rounded-full px-3 py-1 text-xs font-medium ${colors[status]}`}
>
{node.label}
</div>
{i < nodes.length - 1 && (
<div
className={`mx-1 h-0.5 w-6 ${
status === "complete" ? "bg-green-500" : "bg-gray-200"
}`}
/>
)}
</div>
);
})}
</div>
);
}function PipelineProgress({
nodes,
values,
streamingContent,
}: {
nodes: typeof PIPELINE_NODES;
values: Record<string, unknown>;
streamingContent: Record<string, string>;
}) {
return (
<div className="flex items-center gap-1">
{nodes.map((node, i) => {
const status = getNodeStatus(node, streamingContent, values);
const colors = {
idle: "bg-gray-200 text-gray-500",
streaming: "bg-blue-400 text-white animate-pulse",
complete: "bg-green-500 text-white",
};
return (
<div key={node.name} className="flex items-center">
<div
className={`rounded-full px-3 py-1 text-xs font-medium ${colors[status]}`}
>
{node.label}
</div>
{i < nodes.length - 1 && (
<div
className={`mx-1 h-0.5 w-6 ${
status === "complete" ? "bg-green-500" : "bg-gray-200"
}`}
/>
)}
</div>
);
})}
</div>
);
}function PipelineProgress({
nodes,
values,
streamingContent,
}: {
nodes: typeof PIPELINE_NODES;
values: Record<string, unknown>;
streamingContent: Record<string, string>;
}) {
return (
<div className="flex items-center gap-1">
{nodes.map((node, i) => {
const status = getNodeStatus(node, streamingContent, values);
const colors = {
idle: "bg-gray-200 text-gray-500",
streaming: "bg-blue-400 text-white animate-pulse",
complete: "bg-green-500 text-white",
};
return (
<div key={node.name} className="flex items-center">
<div
className={`rounded-full px-3 py-1 text-xs font-medium ${colors[status]}`}
>
{node.label}
</div>
{i < nodes.length - 1 && (
<div
className={`mx-1 h-0.5 w-6 ${
status === "complete" ? "bg-green-500" : "bg-gray-200"
}`}
/>
)}
</div>
);
})}
</div>
);
}7.2.6 构建可折叠的 NodeCard 组件
每个节点都有属于自己的卡片,用于显示状态徽章 、内容 (流式中或最终结果),以及一个用于展示长篇输出的可折叠主体
function NodeCard({
node,
status,
streamingContent,
completedContent,
}: {
node: { name: string; stateKey: string; label: string };
status: NodeStatus;
streamingContent: string | undefined;
completedContent: unknown;
}) {
const [collapsed, setCollapsed] = useState(false);
const displayContent =
status === "complete"
? formatContent(completedContent)
: streamingContent ?? "";
const statusBadge = {
idle: { text: "Waiting", className: "bg-gray-100 text-gray-600" },
streaming: {
text: "Running",
className: "bg-blue-100 text-blue-700 animate-pulse",
},
complete: { text: "Done", className: "bg-green-100 text-green-700" },
};
const badge = statusBadge[status];
return (
<div className="rounded-lg border bg-white shadow-sm">
<button
onClick={() => setCollapsed(!collapsed)}
className="flex w-full items-center justify-between p-4"
>
<div className="flex items-center gap-3">
<h3 className="font-semibold">{node.label}</h3>
<span
className={`rounded-full px-2 py-0.5 text-xs font-medium ${badge.className}`}
>
{badge.text}
</span>
</div>
<ChevronIcon direction={collapsed ? "down" : "up"} />
</button>
{!collapsed && displayContent && (
<div className="border-t px-4 py-3">
<div className="prose prose-sm max-w-none">
{displayContent}
{status === "streaming" && (
<span className="inline-block h-4 w-1 animate-pulse bg-blue-500" />
)}
</div>
</div>
)}
</div>
);
}
function formatContent(value: unknown): string {
if (typeof value === "string") return value;
if (value == null) return "";
return JSON.stringify(value, null, 2);
}7.2.7 流式内容与已完成内容
每个节点都有两个内容来源,为了获得流畅的用户体验,选择正确的来源至关重要:
| 来源 | 何时使用 |
|---|---|
streamingContent[node.name] |
当节点正在活动流式输出时,这里包含实时到达的 Token(字符)。 |
stream.values[node.stateKey] |
当节点完成后,这里包含最终的、已提交的输出。 |
模式是 :在实时更新阶段显示流式内容,一旦节点完成,就**回退(切换)**到已提交的状态值。
for (const node of PIPELINE_NODES) {
const status = getNodeStatus(node, streamingContent, stream.values);
const content =
status === "streaming"
? streamingContent[node.name]
: stream.values?.[node.stateKey];
}流式内容可能包含尚未完全形成的局部 Token 或 Markdown 。如果你要渲染 Markdown,请务必确保你的渲染器能够优雅地处理不完整的语法 (例如:一个未闭合的加粗标记 **
7.2.6 整合所有内容
这里是完整的卡片列表代码,它结合了路由、状态检测和卡片渲染:
function NodeCardList({
nodes,
messages,
values,
getMetadata,
}: {
nodes: typeof PIPELINE_NODES;
messages: BaseMessage[];
values: Record<string, unknown>;
getMetadata: (msg: BaseMessage) => MessageMetadata | undefined;
}) {
const streamingContent = getStreamingContent(messages, getMetadata);
return (
<div className="space-y-3">
{nodes.map((node) => {
const status = getNodeStatus(node, streamingContent, values);
return (
<NodeCard
key={node.name}
node={node}
status={status}
streamingContent={streamingContent[node.name]}
completedContent={values?.[node.stateKey]}
/>
);
})}
</div>
);
}7.2.6 应用场景
图执行卡片非常适用于任何需要可见性的多步骤管道:
- 研究管道:分类 → 收集来源 → 分析 → 综合生成报告
- 内容生成:大纲 → 起草 → 事实核查 → 编辑 → 发布
- 数据处理:摄取 → 验证 → 转换 → 聚合 → 导出
- 代码生成:理解需求 → 规划架构 → 编写代码 → 审查 → 测试
- 决策工作流:收集背景信息 → 评估选项 → 评分备选方案 → 推荐
7.2.7 处理动态管道
并非所有的图(Graph)都拥有一组固定的节点 。有些管道会根据输入动态添加或跳过节点 。处理方法是:检查哪些状态键(state keys)实际上拥有值
const activeNodes = PIPELINE_NODES.filter(
(node) =>
streamingContent[node.name] ||
values?.[node.stateKey] ||
node.name === currentNode
);这能确保你的 UI 只显示与当前执行相关的节点卡片 ,避免出现空的占位卡片。
如果你的图包含条件分支 (例如:对于简单的事实性问题,跳过"研究"步骤),那么被跳过的节点永远不会出现在流式内容或状态值中。你的管道进度条应该反映这一点,通过变暗 或隐藏来标识被跳过的步骤
7.2.7 最佳实践
-
以声明方式定义节点 :将
PIPELINE_NODES数组作为单一事实来源,统一映射节点名称、状态键和显示标签。 -
优先使用活跃节点的内容流 :这能给用户即时反馈。仅在节点完成后才回退到已提交的状态值。
-
自动折叠已完成的节点 :在长管道中,自动折叠已完成的卡片,以便用户聚焦于当前活跃的步骤。
-
显示预估时间 :如果你有每个节点耗时的历史数据,请显示时间预估以设定用户预期。
-
添加全局进度指示器:在管道视图顶部添加一个整体进度条(例如"第 2 步,共 4 步"),作为单节点卡片的补充。
-
按节点处理错误 :如果某个节点失败,在其卡片中显示错误,而不要导致整个管道崩溃。其他节点仍可能成功完成。
def my_node(state: State) -> Command[Literal["my_other_node"]]:
if state["foo"] == "bar":
return Command(update={"foo": "baz"}, goto="my_other_node")
当你需要同时更新状态并路由 到不同的节点时,请使用 Command。如果你只需要路由而不需要更新状态 ,请改用条件边
当在节点函数中返回 Command 时,你必须添加返回类型注解 ,列出该节点可能路由到的节点名称列表,例如 Command[Literal["my_other_node"]]。这对于图的渲染 是必要的,它告诉 LangGraph:my_node 可以导航到 my_other_node。这点稍微有点诡异。不好确保两个地方拼写一致
Command 只会添加动态边------使用 add_edge / addEdge 定义的静态边仍然会执行。
例如,如果 node_a 返回 Command(goto="my_other_node"),而你也定义了 graph.add_edge("node_a", "node_b"),那么 node_b 和 my_other_node 都会运行
请查看这篇****操作指南**** ,获取关于如何使用 Command 的****端到端示例****。
如果你正在使用子图 ,可以通过在 Command 中指定 graph=Command.PARENT,从子图内的节点导航到父图中的不同节点
def my_node(state: State) -> Command[Literal["other_subgraph"]]:
return Command(
update={"foo": "bar"},
goto="other_subgraph", # where `other_subgraph` is a node in the parent graph
graph=Command.PARENT
)将 graph 设置为 Command.PARENT 将会导航到最近的父图 。当你从子图节点向父图节点发送更新,且更新的是父图和子图状态模式中共享的键 时,你必须在父图状态 中为该键定义一个Reducer(归约器)。请参见此示例
这在实现多智能体移交 时特别有用。请查看 "导航到父图中的节点" 以获取详细信息
传入 invoke 或 stream 的输入
只有 Command(resume=...) 这种模式是专门设计用来作为输入传递给 invoke() 或 stream() 的。
不要使用 Command(update=...) 作为输入来继续多轮对话------因为一旦你把任何 Command 对象作为输入传进去,系统就会从最新的检查点(即最后运行的那一步,而不是 start 起始节点)恢复运行。如果之前的流程已经跑完了,再传 Command 进去,图表(Graph)看起来就会像是卡住了一样。
要想在现有的线程上继续对话,请直接传递一个普通的输入字典(plain input dict)。
# WRONG - graph resumes from the latest checkpoint
# (last step that ran), appears stuck
graph.invoke(Command(update={
"messages": [{"role": "user", "content": "follow up"}]
}), config)
# CORRECT - plain dict restarts from __start__
graph.invoke( {
"messages": [{"role": "user", "content": "follow up"}]
}, config)resume(恢复)
请使用 Command(resume=...) 来提供具体的值,并在中断发生后恢复图表的执行。你传递给 resume 的那个值,将会成为被暂停节点内部 interrupt() 调用的返回值
from langgraph.types import Command, interrupt
def human_review(state: State):
# Pauses the graph and waits for a value
answer = interrupt("Do you approve?")
return {"messages": [{"role": "user", "content": answer}]}
# First invocation - hits the interrupt and pauses
result = graph.invoke({"messages": [...]}, config)
# Resume with a value - the interrupt() call returns "yes"
result = graph.invoke(Command(resume="yes"), config)请查看 中断概念指南,以获取关于中断模式的完整详情,其中包括多重中断和验证循环等内容。
从工具中返回
你可以在工具中返回 Command,以此来更新图表状态并控制流程。
- 使用
update来修改状态(例如,保存对话过程中查找到的客户信息)。 - 使用
goto在工具执行完成后,将流程路由到指定的节点。
当 goto 在工具内部使用时,它会添加一条动态边 ------调用该工具的节点上已定义的任何静态边仍然会被执行。
有关详细信息,请参阅"在工具中使用"部分。
总结
本章主要讲开发和测试相关主题,最主要的是文件架构和部署模式。langgraph到此收尾