Hung-yi Lee 的课程
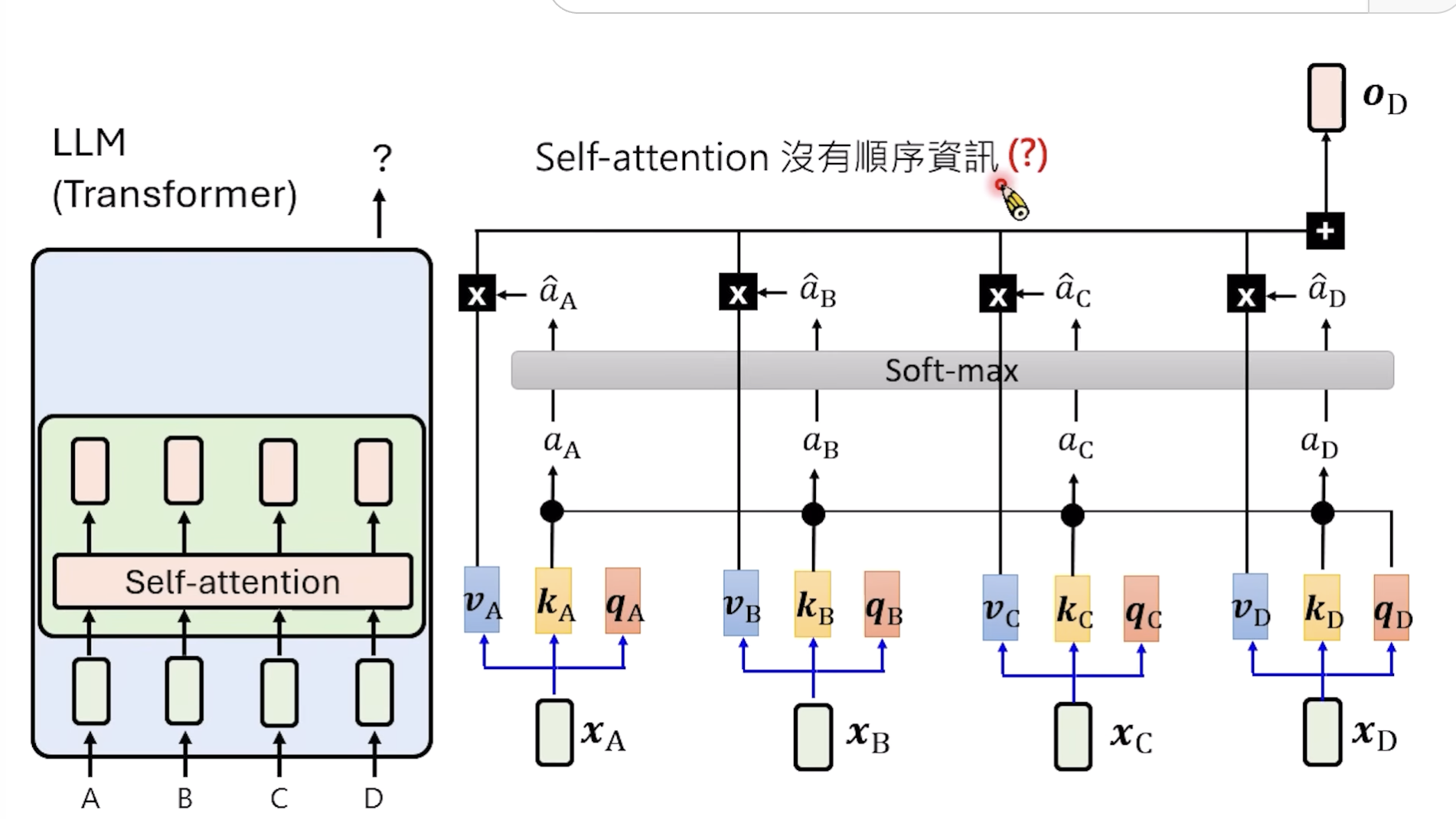
我们知道最初的Transformer论文里,一个token会映射成q, k ,v 三个向量,然后每个向量本身是没有位置信息的,但是没有位置信息的话会混淆语义。
Absolute Position Embedding
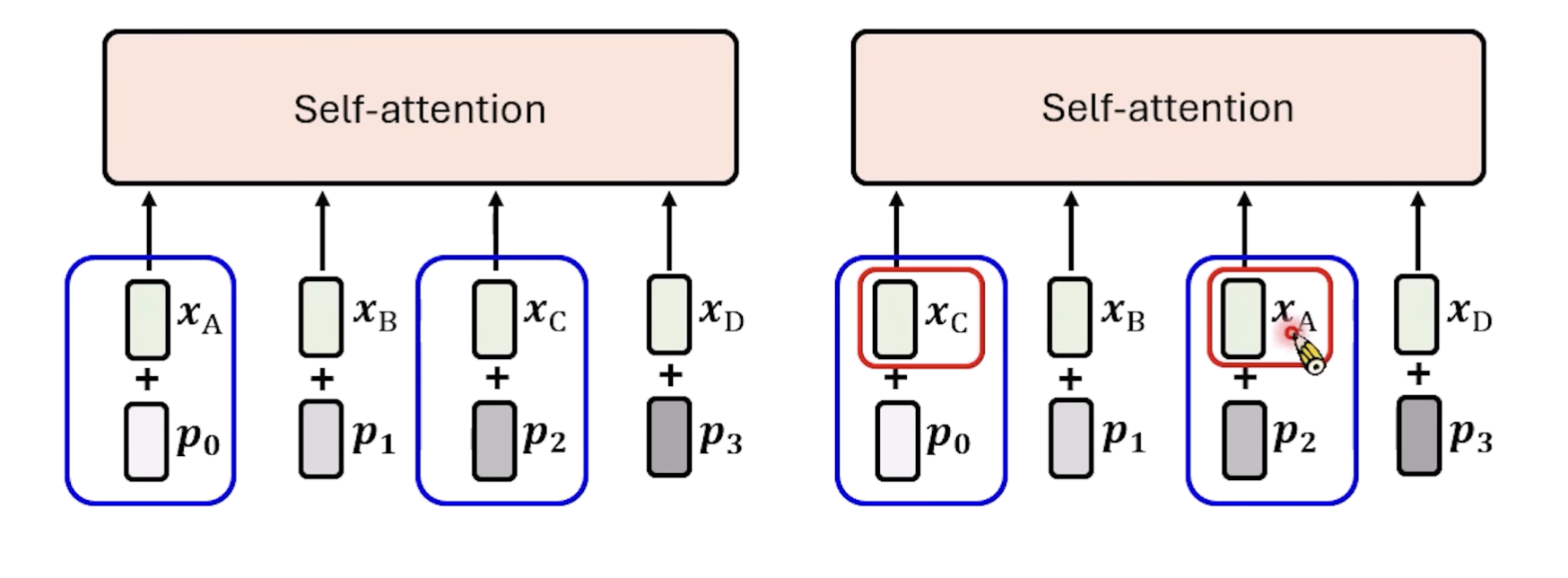
绝对位置编码就是对每一个位置设计一个embedding,然后可以在原来token的embedding上,加上这个位置向量,这样的话,同一个token的在不同位置的input结果就会有了差异,有了位置信息在里面。下面就是最初Transformer论文里的Positionnal Embedding的做法
Sinusoidal postion embedding
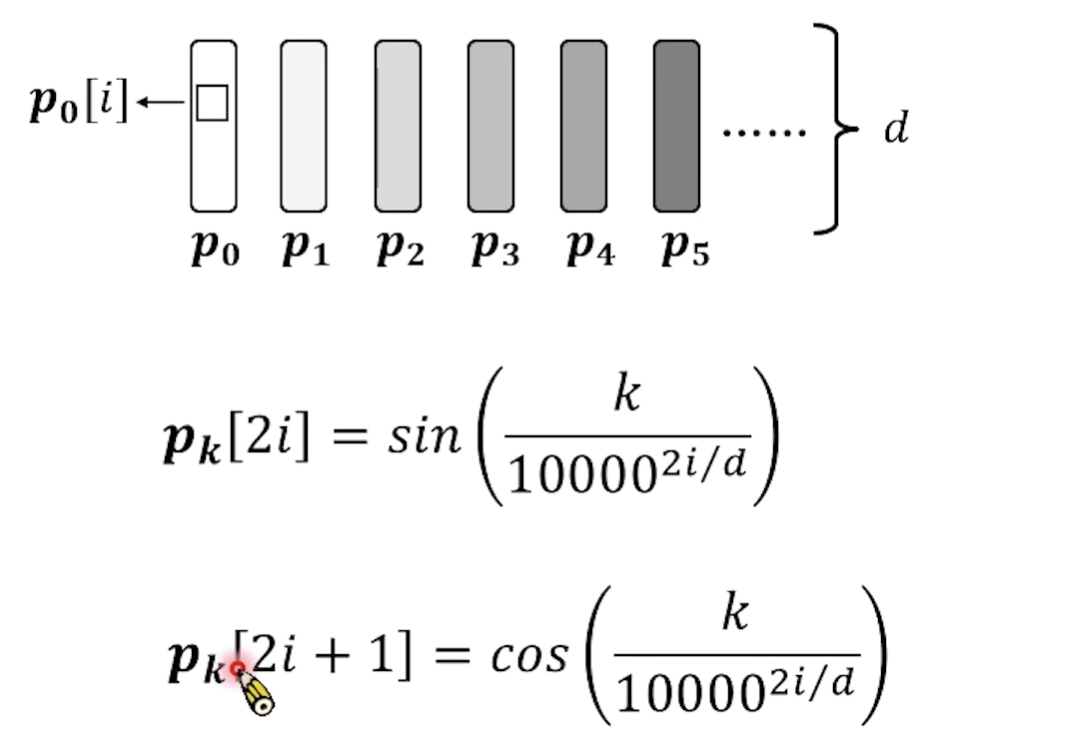
- 对于某个位置的位置编码 p k p_k pk, 他的偶数位置和奇数位置的编码方式是不一样的,偶数位置是用sin函数进行编码,奇数位置是用cos进行编码;
- k是第几个position的embedding;
- i下面是第几个dimension。
具体的第0/1/10个dimension的形状曲线,不同dimension位置的周期是不一样的,dimension越大,周期约长
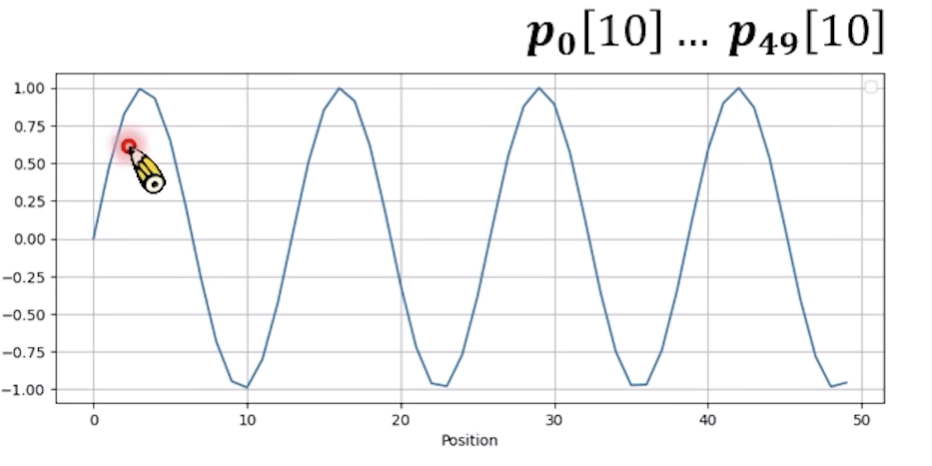
我们把所有的都绘制出来,可以看到一张类似三维的图谱:
每个row是sin/cos交错的, dimension越大,变化越缓慢
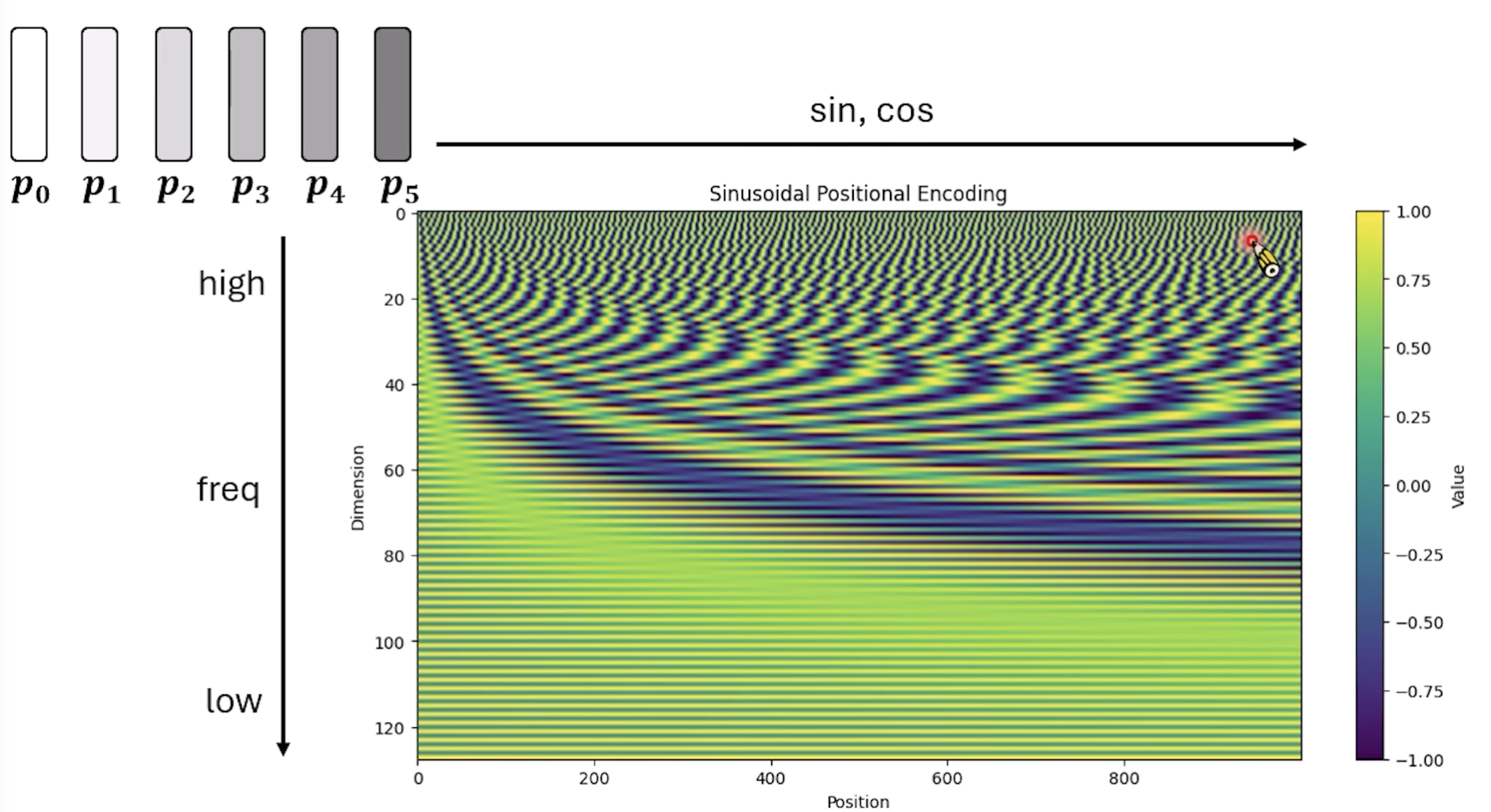
可以看到很大深色/浅色交替的条纹,其实就是postional embedding产生数值的方法是来自于sin/cos函数,是交替的。
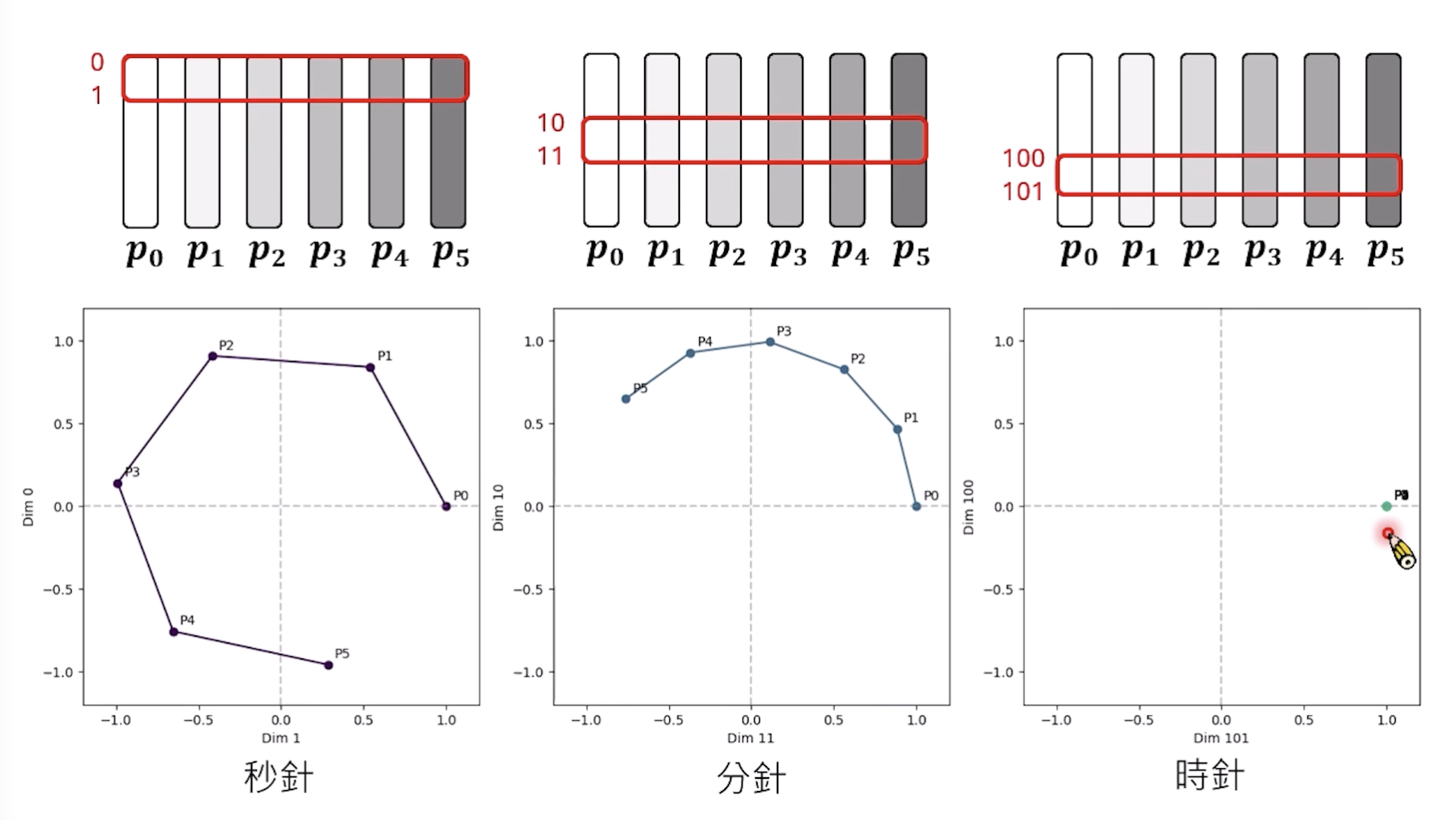
为神马要这么设计,原论文里提到了是想要强调相对位置
Intuition 理解
举个例子,当猫和鱼之间的距离不变时,无论猫前面有多少个字,算出来的始终是0.7
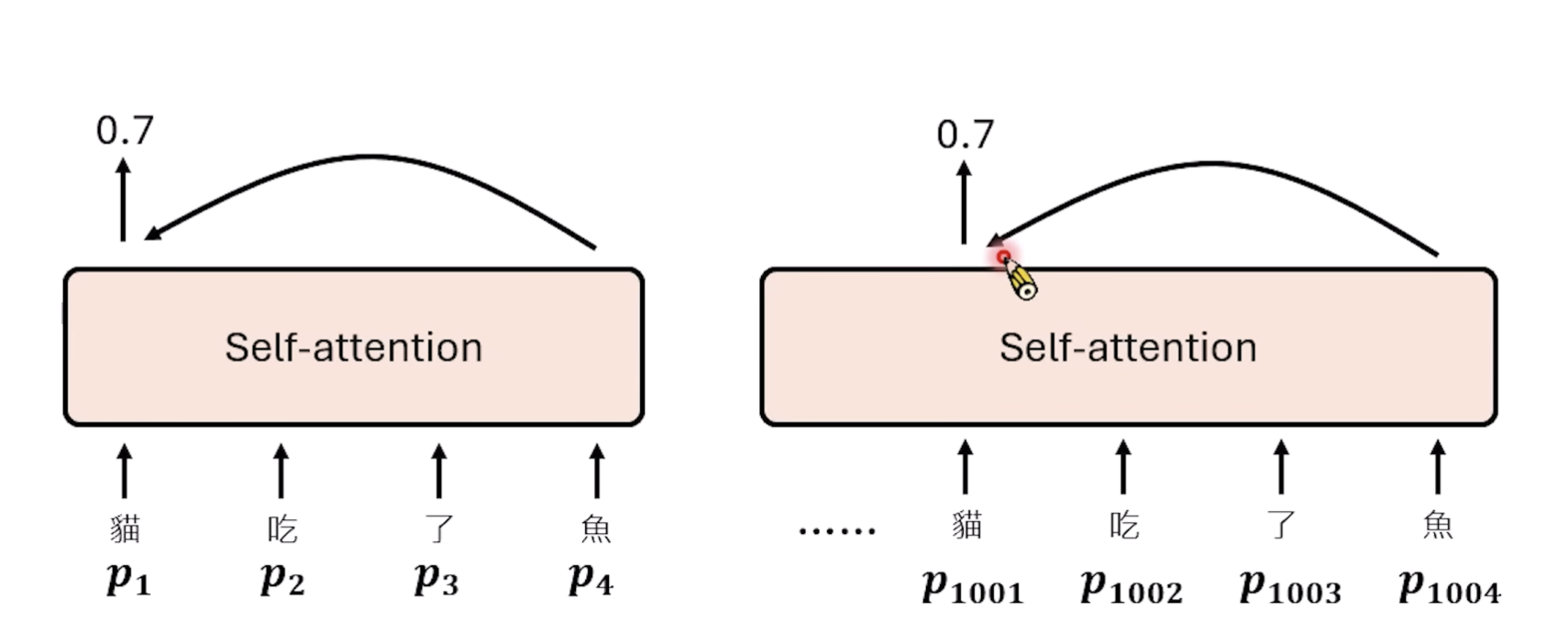
但是当猫和鱼中间插入了很多个字的时候,那么最终的计算结果就会发生较大改变。
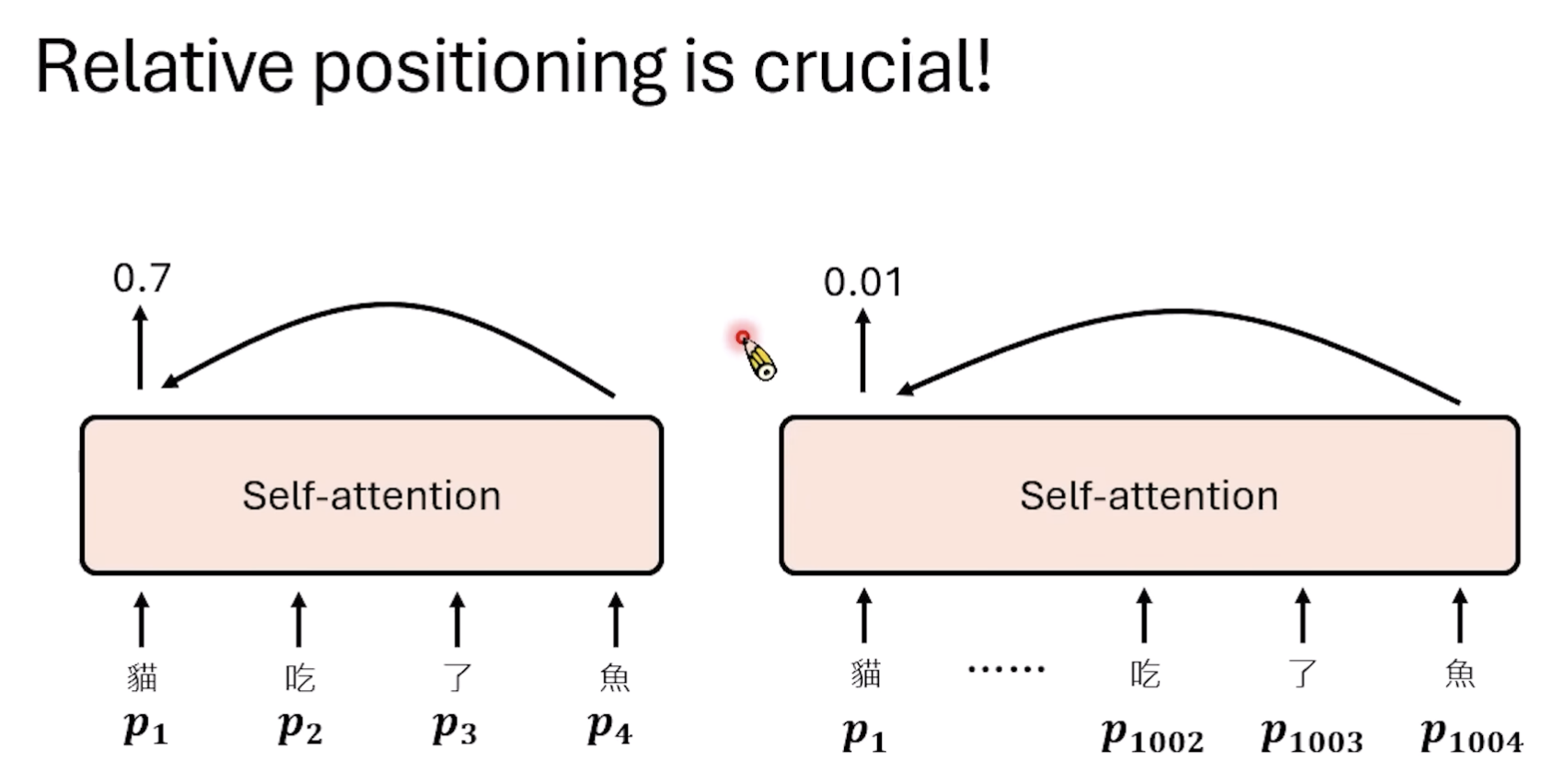
数学上解释
所谓相对位置,在数据上即是满足这个性质: P k + r = M r P k P_{k+r} = M_r P_k Pk+r=MrPk,下面是一些数学上的推导:
我们看下 p k p_{k} pk和 p k + r p_{k+r} pk+r , 根据位置函数,编码如下:
p k 2 i = sin ( k z ) , p k 2 i + 1 = cos ( k z ) , p k + r 2 i = sin ( k + r z ) , p k + r 2 i + 1 = cos ( k + r z ) p_k2i = \sin\left(\frac{k}{z}\right), \quad p_k2i+1 = \cos\left(\frac{k}{z}\right), \\ \\ p_{k+r}2i = \sin(\frac{k + r}{z}), \quad p_{k+r}2i+1 = \cos(\frac{k + r}{z}) pk2i=sin(zk),pk2i+1=cos(zk),pk+r2i=sin(zk+r),pk+r2i+1=cos(zk+r)
我们使用使用三角函数合角公式
sin ( a + b ) = sin a cos b + cos a sin b \sin(a+b)=\sin a \cos b + \cos a \sin b sin(a+b)=sinacosb+cosasinb
cos ( a + b ) = cos a cos b − sin a sin b \cos(a+b)=\cos a \cos b - \sin a \sin b cos(a+b)=cosacosb−sinasinb
令:
a = k z , b = r z a = \frac{k}{z}, \quad b = \frac{r}{z} a=zk,b=zr
我们把最终公式展开
p k + r 2 i = sin ( k + r z ) = sin ( k z + r z ) = s i n ( k z ) c o s ( r z ) + cos ( k z ) sin ( r z ) p_{k+r}2i = \sin\left(\frac{k+r}{z}\right) = \sin\left(\frac{k}{z} + \frac{r}{z}\right) = sin(\frac{k}{z})cos(\frac{r}{z}) + \cos(\frac{k}{z})\sin(\frac{r}{z}) pk+r2i=sin(zk+r)=sin(zk+zr)=sin(zk)cos(zr)+cos(zk)sin(zr)
p k + r 2 i + 1 = cos ( k + r z ) = cos ( k z + r z ) = c o s ( k z ) c o s ( r z ) − sin ( k z ) sin ( r z ) p_{k+r}2i + 1 = \cos\left(\frac{k+r}{z}\right) = \cos\left(\frac{k}{z} + \frac{r}{z}\right) = cos(\frac{k}{z})cos(\frac{r}{z}) - \sin(\frac{k}{z})\sin(\frac{r}{z}) pk+r2i+1=cos(zk+r)=cos(zk+zr)=cos(zk)cos(zr)−sin(zk)sin(zr)
然后可以进一步得到:
P k + r 2 i = P k 2 i c o s ( r z ) + P k 2 i + 1 s i n ( r z ) P_{k+r}2i = P_k2icos(\frac{r}{z}) + P_k2i+1sin(\frac{r}{z}) Pk+r2i=Pk2icos(zr)+Pk2i+1sin(zr)
P k + r 2 i + 1 = P k 2 i + 1 c o s ( r z ) − p k 2 i s i n ( r z ) P_{k+r}2i + 1 = P_k2i + 1cos(\frac{r}{z}) - p_k2isin(\frac{r}{z}) Pk+r2i+1=Pk2i+1cos(zr)−pk2isin(zr)
我们用矩阵表示就可以得到:
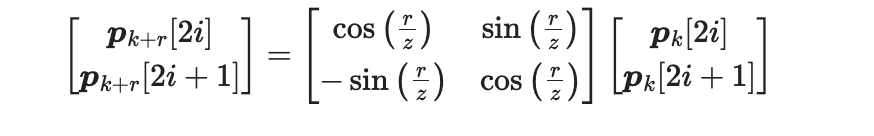
可以看到, P k + r P_{k+r} Pk+r 和 P k P_k Pk 之间的距离和k是没有任何关系的,也就是只是两者之间的相对关系!!
对Attetion的影响是什么
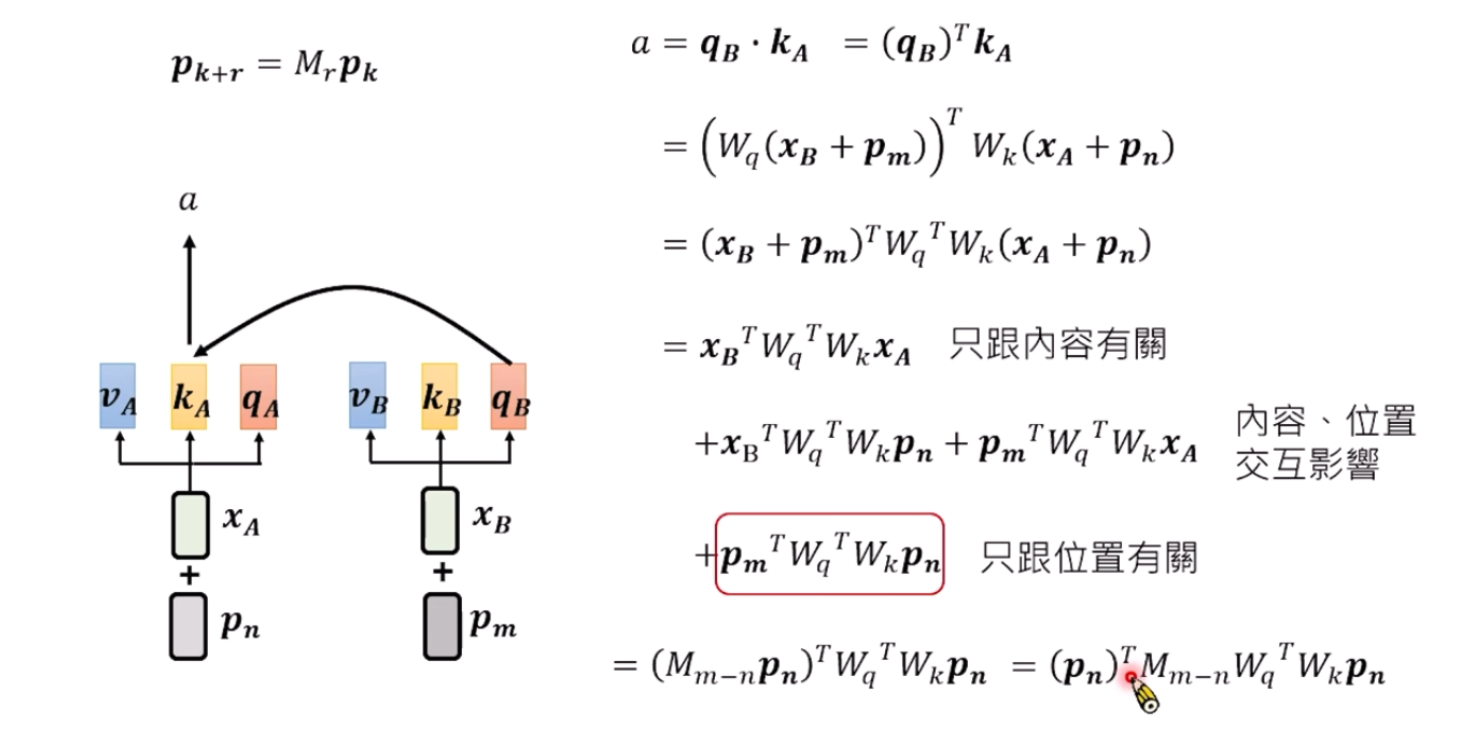
可以看出来,有一部分和相对位置有关系,但是没有那么纯粹
Relative positional
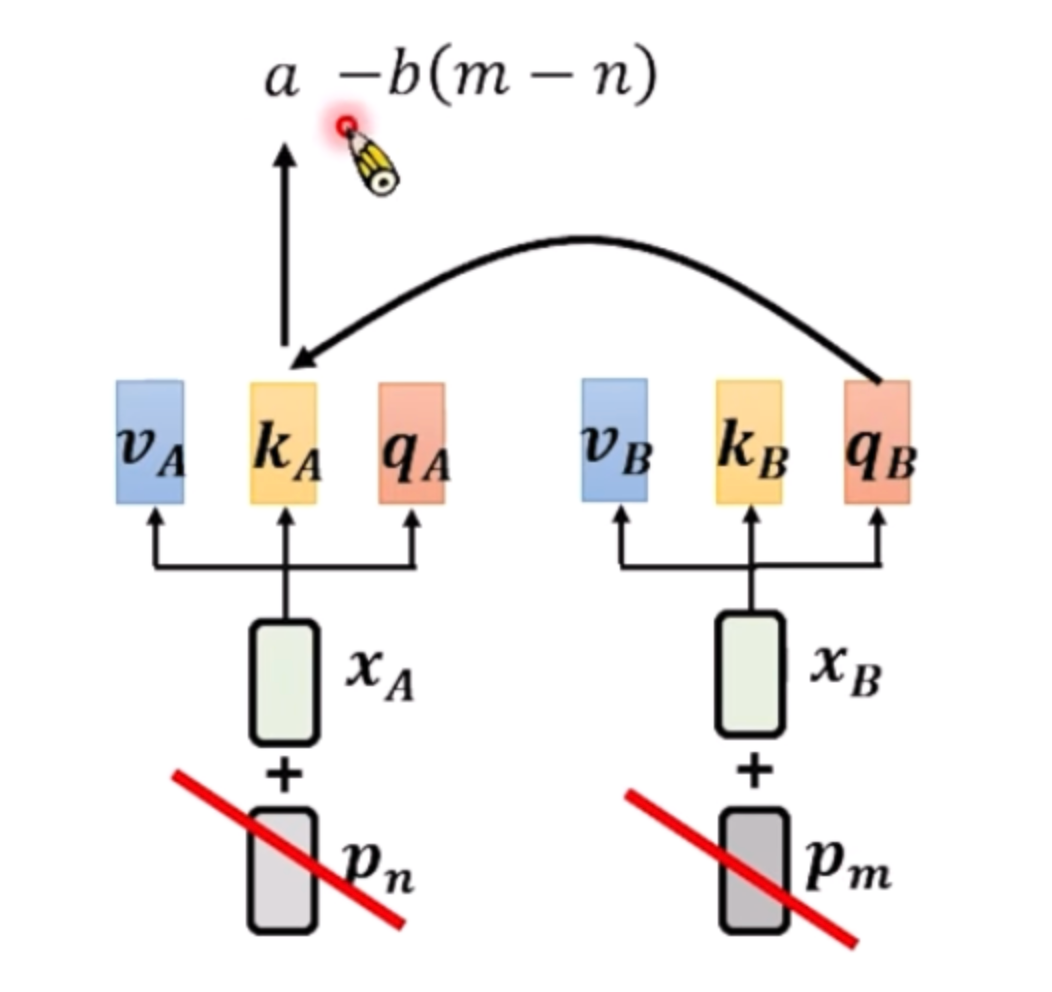
Attention with Linear Biases(ALiBI)
attention的结果,减去相对距离的结果,达到的效果就是距离越远,attention越小!
其中b是超参数,手动设置,可以设置多种值。
RoPE(Rotary Position Embedding)
使用在Llama、Qwen、Gemma等模型中,直接把原始的token的Embedding结果进行旋转。
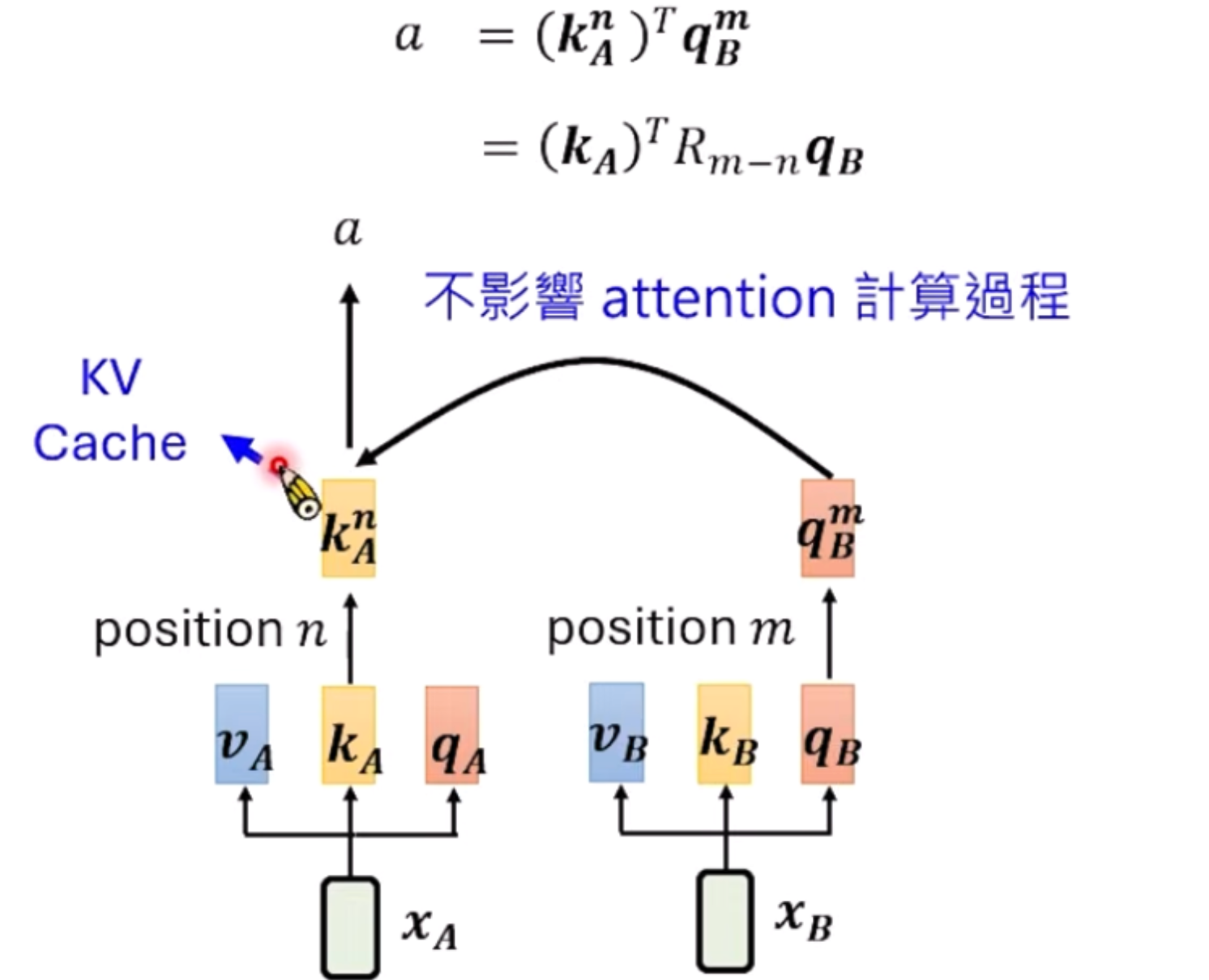
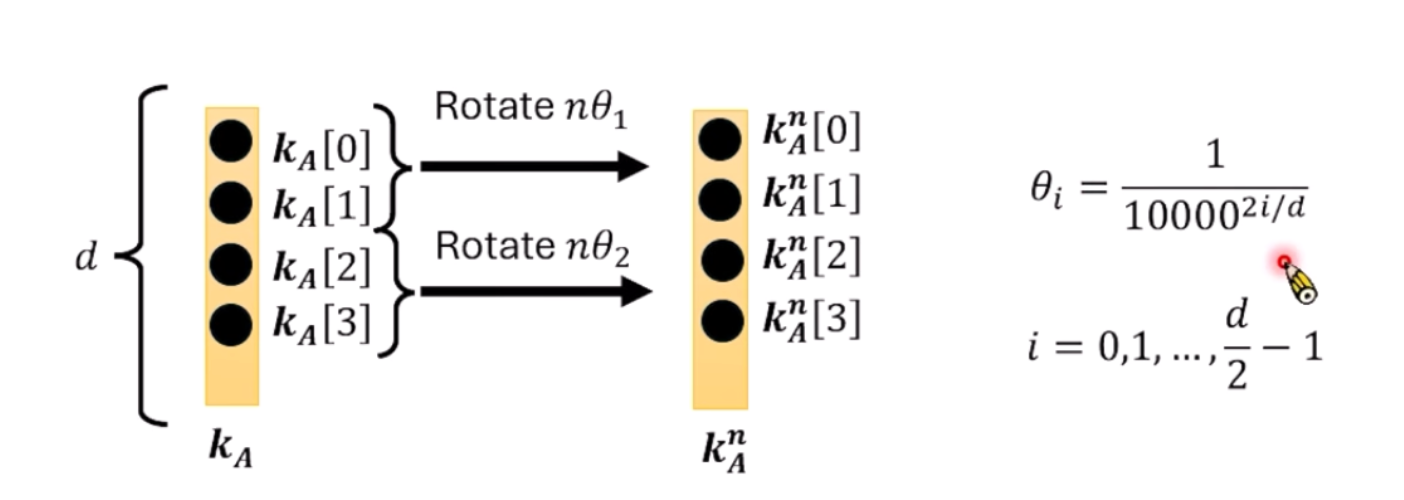
具体的,每两维设置一个不同的旋转角度
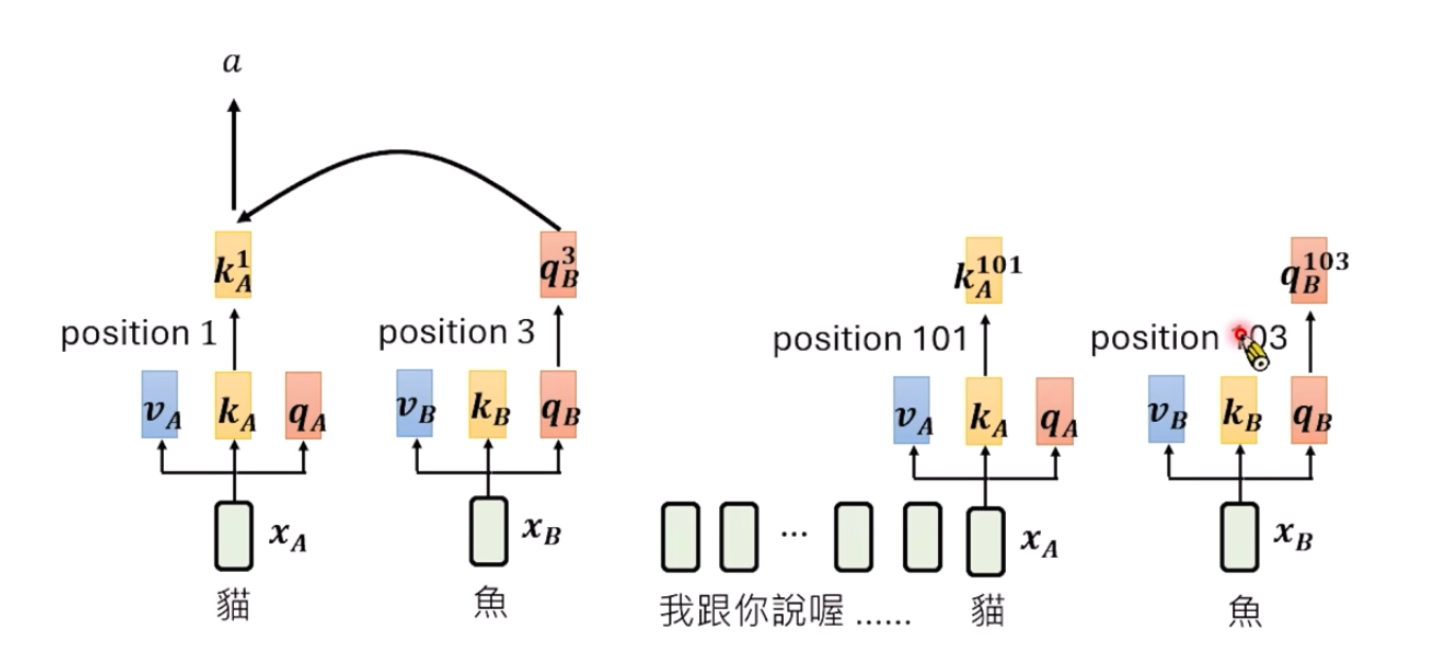
我们可以看下RoPE的效果, 数学上是如下的效果: k A n ∗ q B m = k A n + r ∗ q B m + r k_A^n * q_B^m = k_A^{n + r} * q_B^{m +r} kAn∗qBm=kAn+r∗qBm+r
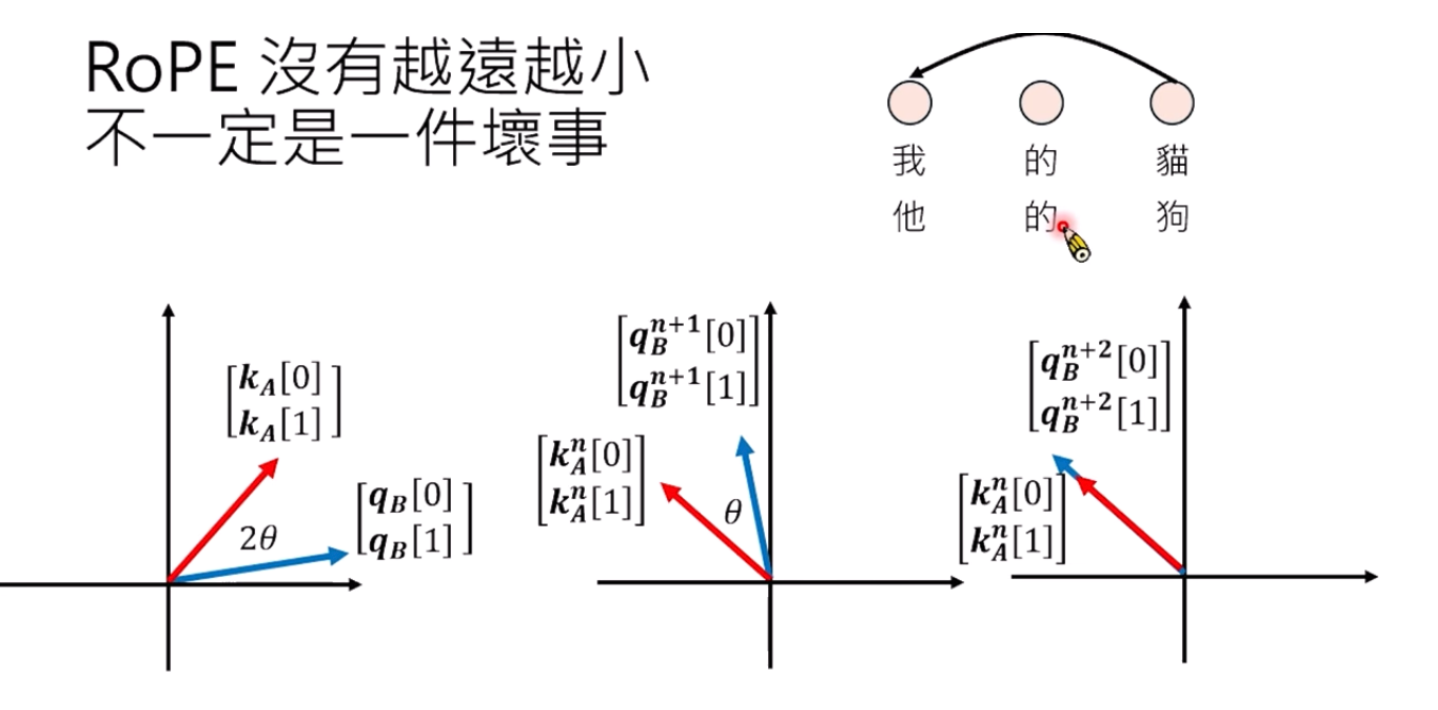
q和k距离越远,RoPE不一定保证attention越来越小,但不一定是一件坏事?例如下图,我们有的时候应该更加关注我和猫,中间的的 好像没那么重要,RoPE可以做到跳过一些东西关注一些东西。
Train Short,Test Long
最后一点,就是我们希望模型可以在测试/推理时,支持比训练时更长的Sequence而不发生崩坏!
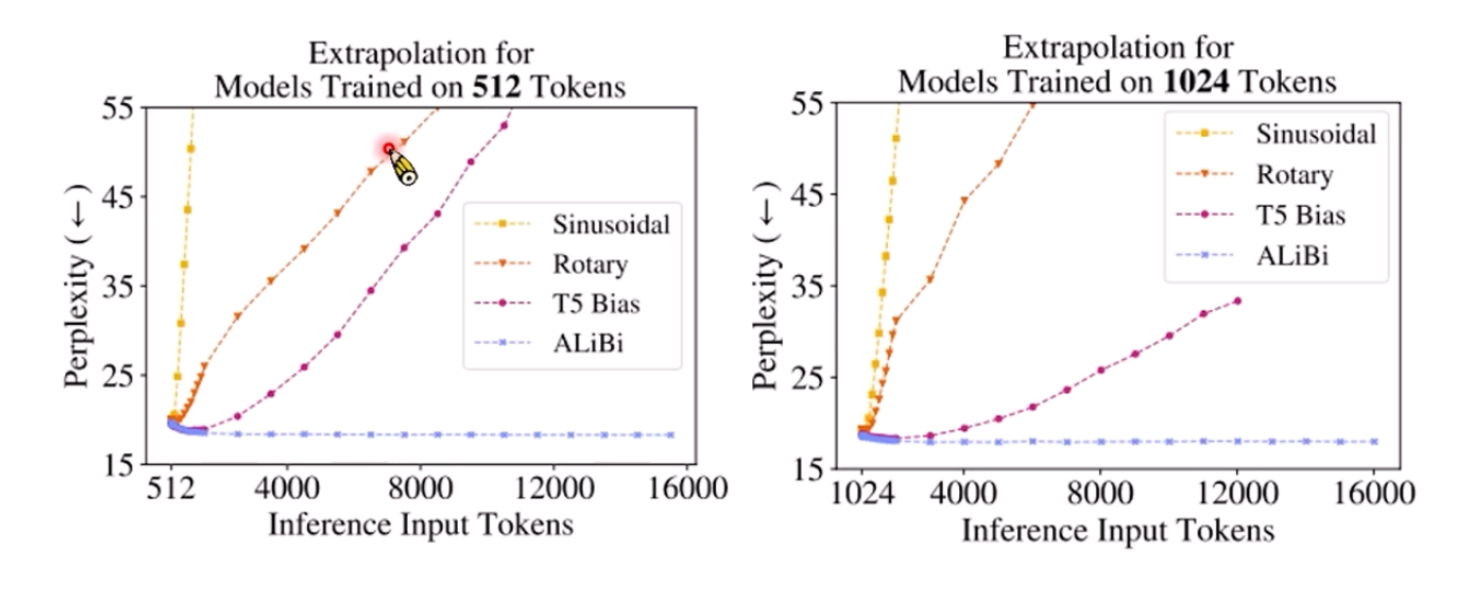
通过下图可以看出,RoPE(Rotary)在更长的Sequence时,会崩坏!
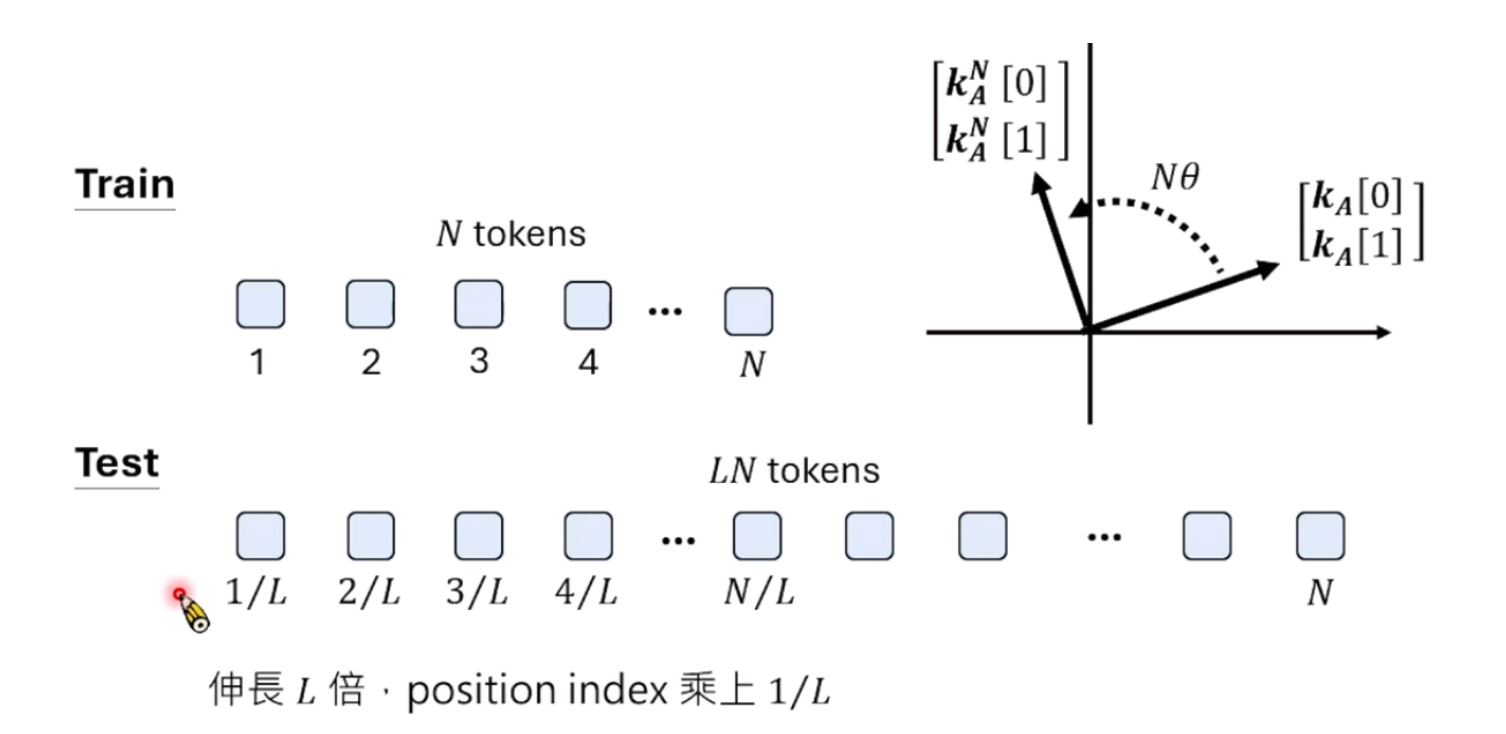
Position Interpolation
如何调整RoPE,当测试tokens数量远远大于训练时,我们把位置的进行压缩,可以保证最大的Position的编号和Train一致
Frequency-Based Approach
在缩放的时候,考虑了Dimension的位置
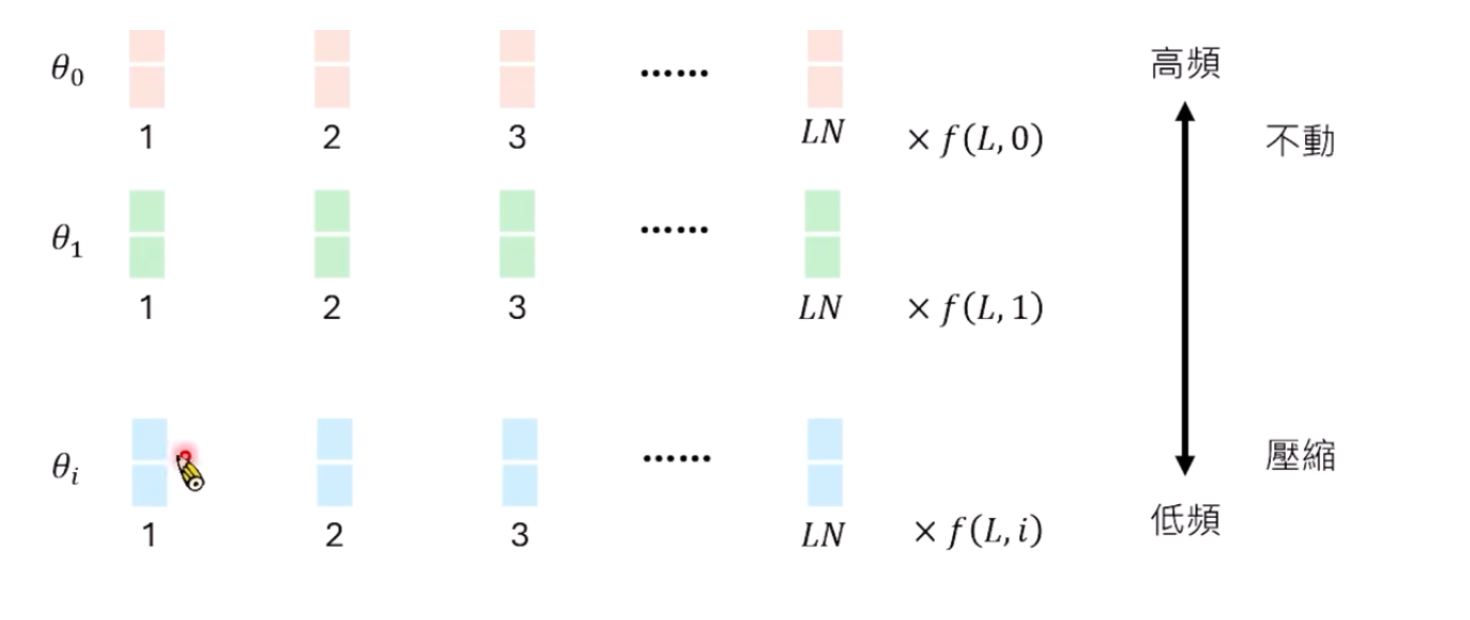
为什么这么设计?下图可以看出来,高频的都看过了,其实扩展无所谓,但是低频的情况下,很多没看过,太长的就会有影响,所以要压缩的狠一些!
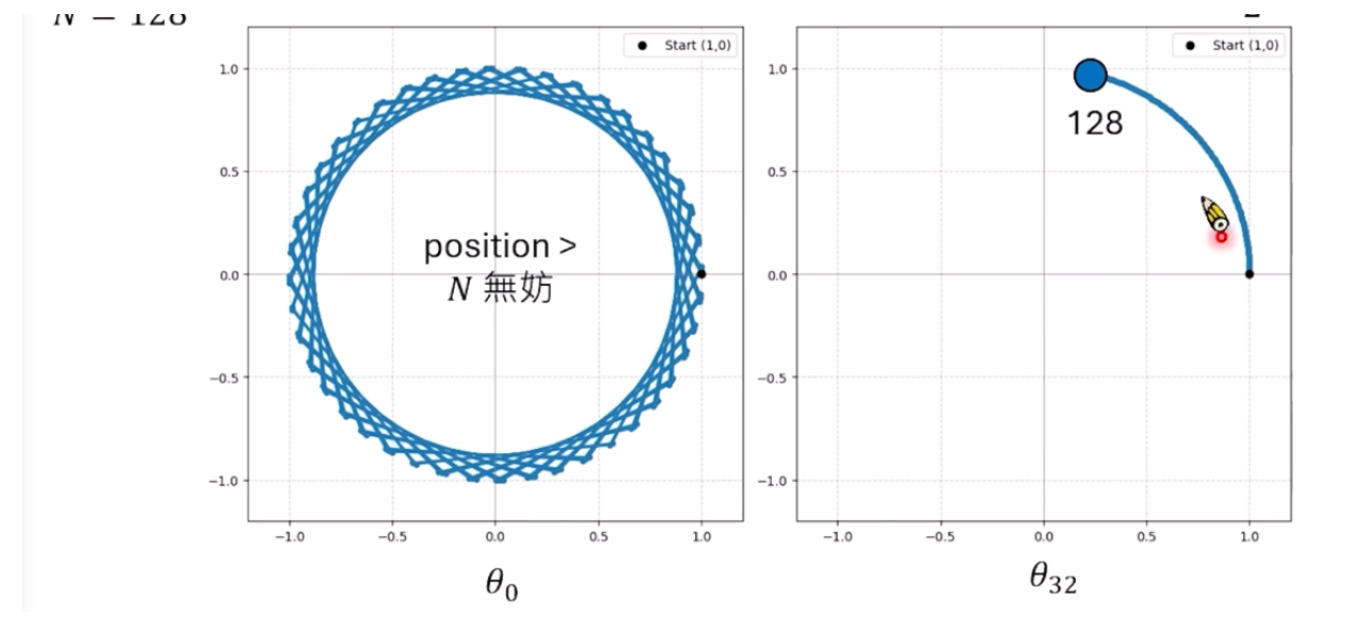
Dynamic Scaling
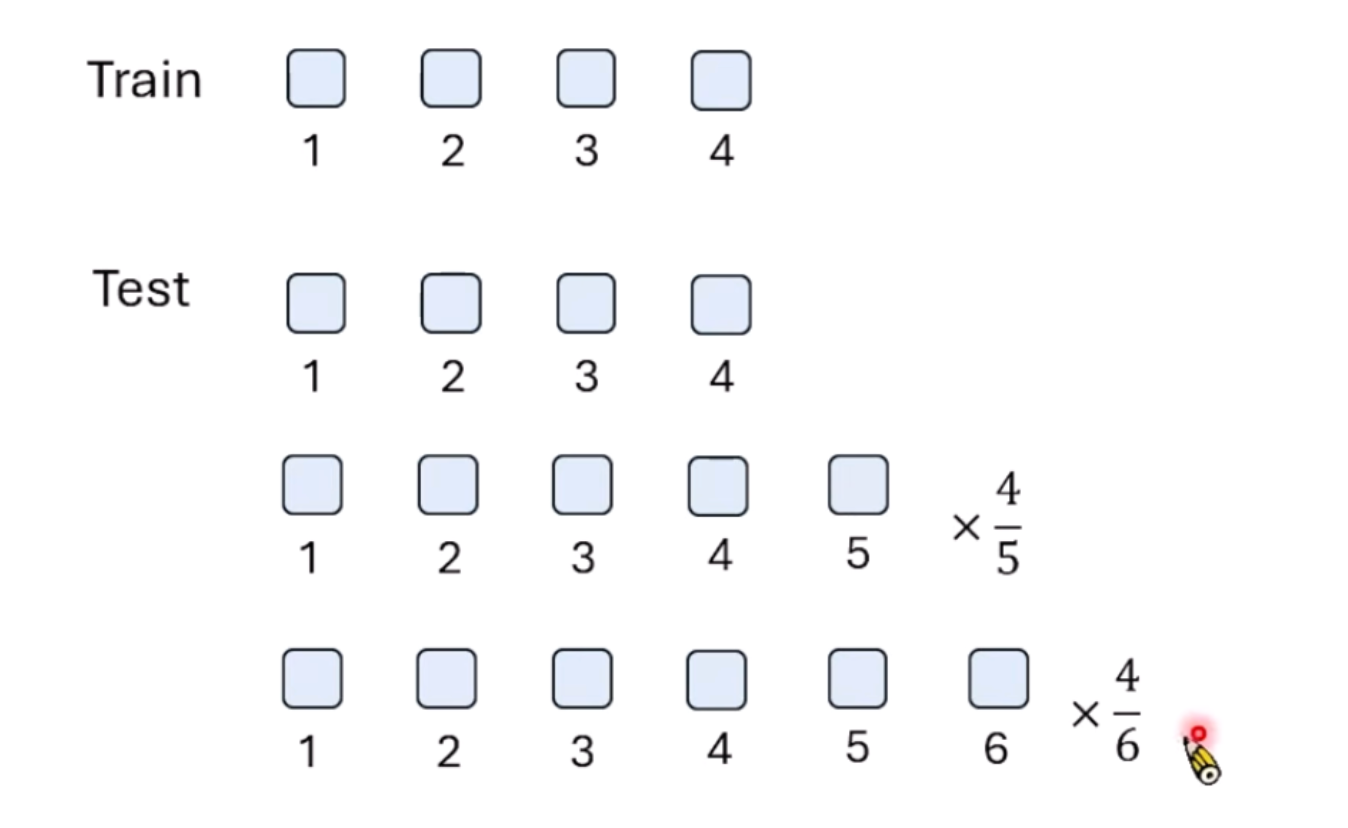
看起来很有道理,但是无法做K-V Cache
最后的灵魂拷问,我们真的需要Positional Embedding吗?
如果Attention只有一层的时候,如果没有Positional的信息时,确实没有办法分辨猫吃鱼/鱼吃猫,但是实际上我们的Attention会做很多层,第一层的时候,就会有一个猫吃/鱼吃的Attention结果,其实这两个是不一样的,那么在第二层这个在作用时,其实是能发现不同的!
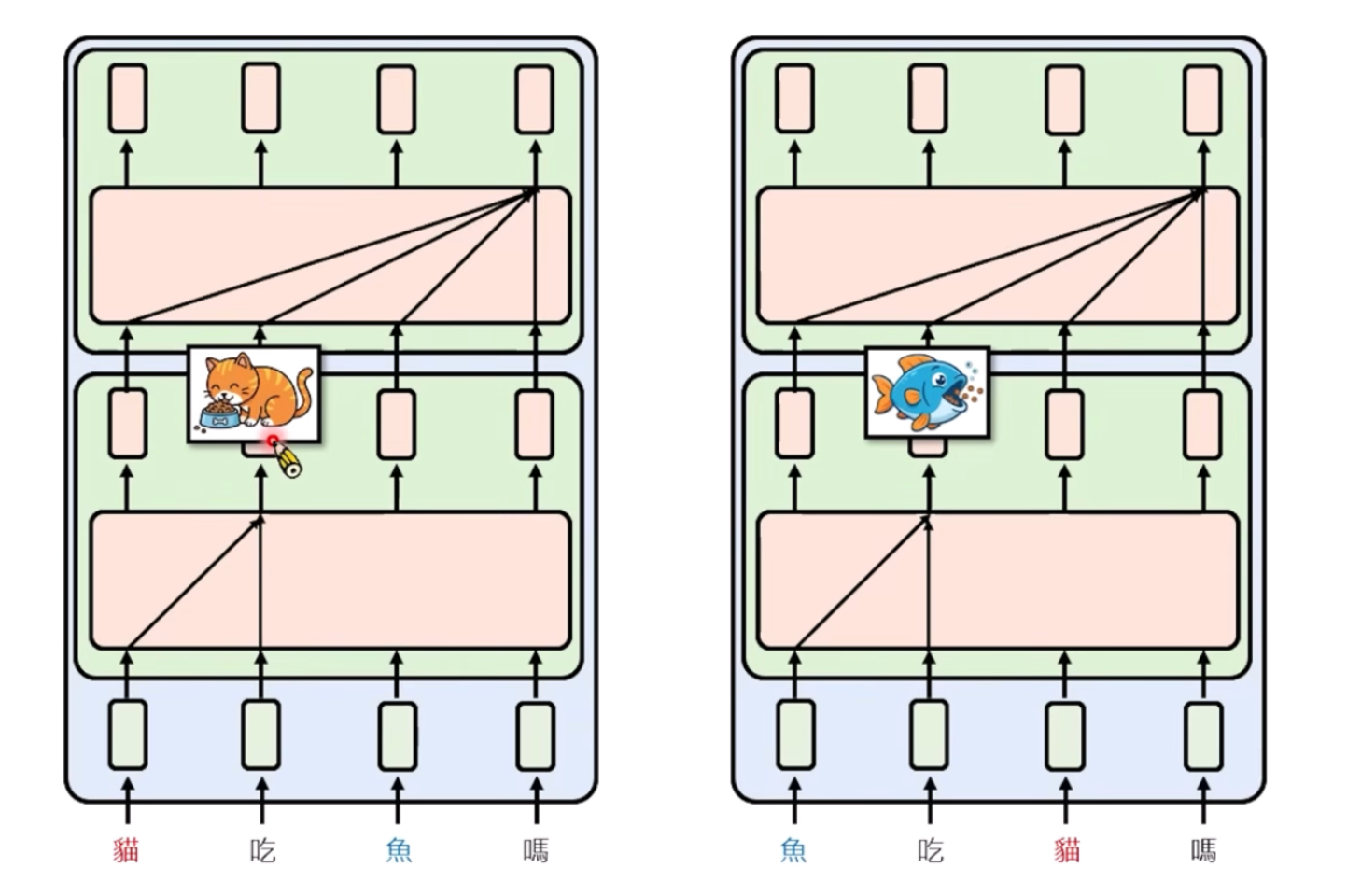
基于以上的思考,就有一个NoPE,发现没加Positional Embeding好像也没事!
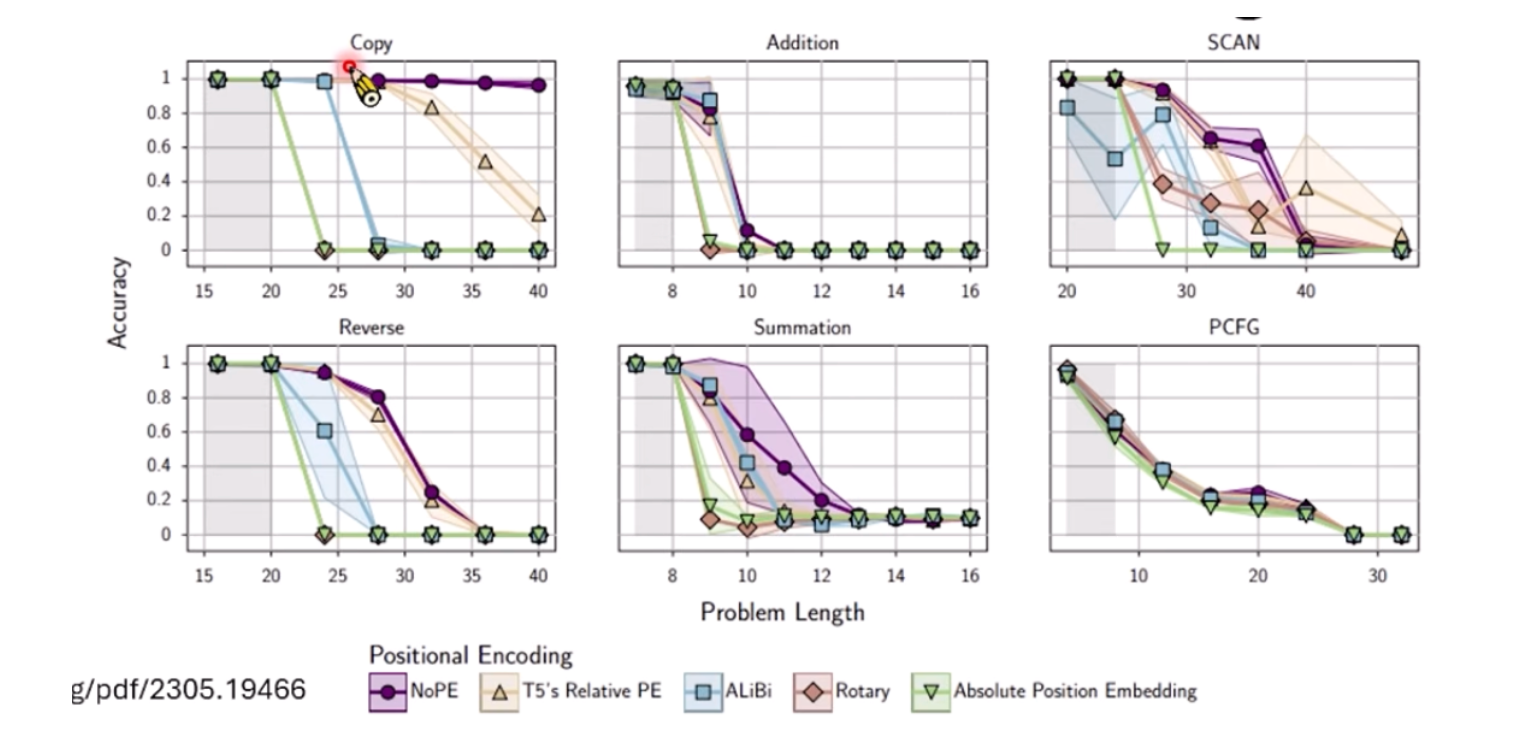
既然如此,为啥当今的大模型还需要位置编码呢?DroPE里面做了分析,发现NoPE在训练时其实是比不是RoPE的,那么我们可以把训练分为两段,开始用RoPE,后面去掉,切换为NoPE!
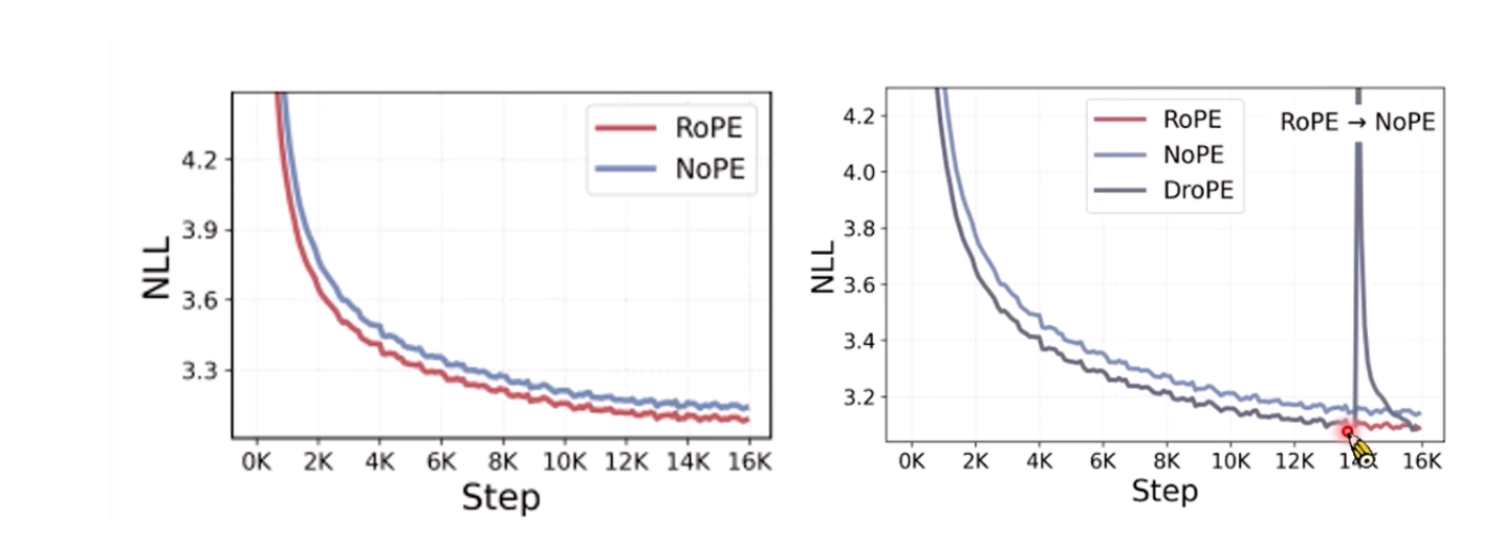
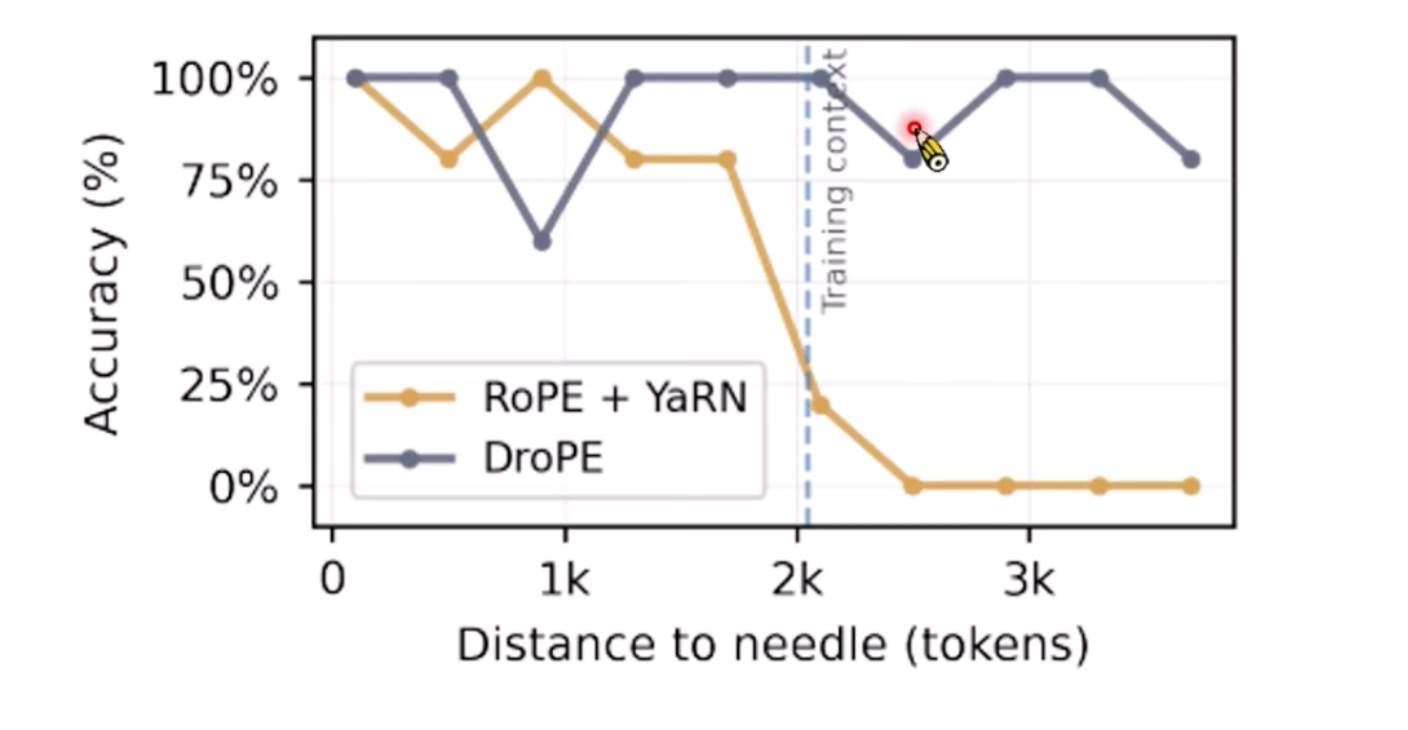
可以看到DroPE在长序列时,效果很好!
最后个人的一点思考和调研
当前 SoTA 模型用了什么?(2024-2025 调研)
百万 token 上下文已经是 SoTA 大模型的标配 ------ Gemini 2.5 支持 1M-2M,GPT-5 / Claude 4 支持 1M,Llama 4 Scout 甚至号称 10M。这一节梳理一下他们到底用了什么技术,和上面笔记里的内容什么关系。
工业界对应表
| 概念 | 工业界现状 |
|---|---|
| Sinusoidal | 几乎没人用了 |
| RoPE | Llama / Qwen / DeepSeek / Mistral / Gemma 全系标配 |
| ALiBi | MPT / BLOOM / Falcon 早期用过,现在边缘化 |
| Position Interpolation (PI) | 仍是基线,但已被 NTK / YaRN 取代 |
| Frequency-Based (NTK-aware) | YaRN 的前身 |
| Dynamic Scaling | 因为破坏 KV-cache 基本被废 |
| NoPE | 被 Llama 4 的 iRoPE 直接落地了! |
| DroPE | 学术探索,思想和 iRoPE 同源 |
主线方向是对的,缺的是 2024--2025 这一波工业界的"组合拳"。
1. ABF (Adjusted Base Frequency) ------ 最朴素的方法
最简单粗暴的扩展方法:直接把 RoPE 公式里的 base θ \theta θ 从 10000 调到一个更大的值(比如 500000、1M)。
回忆 RoPE 的频率定义:
θ i = base − 2 i / d \theta_i = \text{base}^{-2i/d} θi=base−2i/d
base 调大 → 所有维度的旋转周期都变长 → 训练时未见过的位置不会落在"完全没见过的相位"上。
Llama 3 / 3.1 用的就是这个,配合渐进式训练扩展到 128K。简单,但效果意外地好。
2. YaRN ------ NTK-aware 的精细化版本
笔记里"Frequency-Based Approach"对应的就是 NTK-aware scaling。YaRN 在它基础上做了改进:
把 RoPE 的维度按频率分成三组,分别处理:
- 高频维度:直接外推(don't touch)
- 中频维度:NTK 插值
- 低频维度:线性插值(PI 的方式)
直觉是:高频维度旋转得快,本来就在训练时见过各种相位,不需要压缩;低频维度旋转得慢,长序列会跑到从来没见过的相位区,需要狠狠压。
早期 Qwen、DeepSeek、Mistral 扩展上下文都用过它。
3. LongRoPE ------ 用进化搜索找每维度最优缩放
LongRoPE (Microsoft, 2024) 把"非均匀缩放"做到极致:
PI 是"全部一刀切压缩"
NTK / YaRN 是"按维度分组压缩"
LongRoPE 是"每个维度精确搜索最优压缩比"
具体做法:用进化搜索算法,给 RoPE 的每个维度都找一个最优的缩放因子。结果是在 LLaMA2 / Mistral 上把上下文扩展到 2048k tokens,且只需 1k 步微调。
LongRoPE2 (2025) 是它的进化版,Phi 系列在用。
4. iRoPE (Llama 4 Scout) ------ NoPE 思想的工业落地 ⭐
这个是重点。它实际上就是笔记最后讨论的 NoPE / DroPE 思想的工业落地版本!
Meta Llama 4 blog 的原话:
"A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings."
"i" stands for "interleaved", "RoPE" refers to the rotary position embeddings used in most layers.
具体架构(4 层为一组循环):
- 3 层 RoPE + chunked attention:窗口 8K,只能看到附近 8K 个 token 的上下文
- 1 层 NoPE + 全局 attention:没有位置编码,可以看到完整上下文
| 层类型 | 位置编码 | 注意力范围 | 作用 |
|---|---|---|---|
| RoPE 层 (×3) | 有 | 8K chunked window | 近距离精细语序 |
| NoPE 层 (×1) | 无 | 全局完整序列 | 远距离语义聚合 |
直觉:RoPE 层负责"近处看清楚",NoPE 层负责"远处看到全局"。这正好和我们笔记开头的灵魂拷问呼应 ------ 不是所有层都需要位置编码。
注意:DroPE 是在训练阶段维度 做混合(先 RoPE 后 NoPE),iRoPE 是在层维度做混合(每层都同时存在两种)。但底层洞察是一致的:RoPE 不必每层都有。
5. Inference-Time Temperature Scaling ------ 解决长序列 attention 被压平
这是 Llama 4 的另一个关键 trick,对应一个笔记里完全没涉及的问题:
做完位置编码之后,attention 分布本身在长序列上还会出问题。
原因是 softmax 的特性:序列越长,参与 softmax 的项越多,最终的 attention 分布会越来越平 ------ 想关注的 token 也得不到足够高的权重。
Llama 4 的做法是在 NoPE 全局层把 query 向量乘一个随位置变化的缩放因子:
q ′ = q ⋅ ( 1 + α ⋅ log ( 1 + n / β ) ) q' = q \cdot (1 + \alpha \cdot \log(1+n/\beta)) q′=q⋅(1+α⋅log(1+n/β))
让靠后位置的 token 有更"锋利"的 attention 分布。
6. 不只是位置编码 ------ 长上下文的组合拳
百万 token 不是单靠位置编码就能搞定的,需要训练、注意力、系统三个层面一起配合:
训练侧:
- 渐进式长度扩展:Llama 3 用 6 阶段,从 8K → 16K → 32K → 64K → 128K
- 长上下文 SFT 数据配比:短长数据混合(如 3:1)
- 预训练直接拉长:Llama 4 直接以 256K 预训练
注意力侧:
- Chunked / Sliding Window Attention:Mistral、Llama 4 都在用
- 混合注意力架构:局部 + 全局交错(Gemma 2、Llama 4)
- Native Sparse Attention (NSA):DeepSeek 提出的稀疏注意力
- GQA (Grouped Query Attention):减小 KV cache,几乎所有新模型必备
系统侧:
- Flash Attention / Ring Attention:让长序列的计算/内存可承受
- KV cache 量化 / 压缩
7. 回到笔记开头的灵魂拷问
"我们真的需要 Positional Embedding 吗?......第一层之后,attention 已经能区分'猫吃鱼/鱼吃猫'"
Llama 4 的 iRoPE 实质上验证了这个判断 ------ 不是全部去掉,而是"部分层去掉"。
现在的工业共识可以总结为:
短距离精细顺序需要 RoPE,长距离语义聚合 NoPE 反而更好;混合使用才是百万上下文的关键。
另外一个值得思考的点:
- 位置编码做"减法":iRoPE 减少 RoPE 的层数
- 位置编码做"精细化":LongRoPE 给每个维度找最优参数
- 位置编码之外做补丁:温度缩放、chunked attention
三个方向其实都在说同一件事 ------ 训练短序列上学到的位置先验,在外推到百万 token 时是不充分的,需要用各种手段去削弱它对长距离的过度自信。
8. 还没解决的问题
- Lost in the Middle:模型对中间位置的 token 关注不足,即使理论上能处理百万 token,中段信息检索能力仍弱
- 真实可用长度 ≠ 标称长度:经验上大多数模型的"有效长度"约为标称的 60-70%
- 多跳推理 vs 单点检索:Needle-in-a-haystack 测试只衡量单点检索,多文档跨上下文推理仍然是开放问题
- KV cache 成本:1M token 的 KV cache 在 70B 模型上可能占用上百 GB 显存,是部署时的硬瓶颈