XXL-JOB 详解:从 @Scheduled 到分布式调度,Java 微服务定时任务到底该怎么选?
文章目录
- [XXL-JOB 详解:从 `@Scheduled` 到分布式调度,Java 微服务定时任务到底该怎么选?](#XXL-JOB 详解:从
@Scheduled到分布式调度,Java 微服务定时任务到底该怎么选?) -
- 前言
- [一、什么是 XXL-JOB?](#一、什么是 XXL-JOB?)
- [二、为什么很多项目开始放弃 `@Scheduled`?](#二、为什么很多项目开始放弃
@Scheduled?) -
- [1. 集群部署下容易重复执行](#1. 集群部署下容易重复执行)
- [2. 修改调度规则成本高](#2. 修改调度规则成本高)
- [3. 缺乏运维视角](#3. 缺乏运维视角)
- [三、XXL-JOB 的核心优势](#三、XXL-JOB 的核心优势)
-
- [1. 可视化管理:任务终于不再是黑盒](#1. 可视化管理:任务终于不再是黑盒)
- [2. 接入简单:对 Spring Boot 生态非常友好](#2. 接入简单:对 Spring Boot 生态非常友好)
- [3. 原生支持分布式调度](#3. 原生支持分布式调度)
- [4. 支持动态修改参数和 Cron](#4. 支持动态修改参数和 Cron)
- [5. 支持任务分片,适合大数据量处理](#5. 支持任务分片,适合大数据量处理)
- [四、XXL-JOB 的局限性:别只看优点,不看边界](#四、XXL-JOB 的局限性:别只看优点,不看边界)
-
- [1. 依赖数据库](#1. 依赖数据库)
- [2. 本质上是中心化调度](#2. 本质上是中心化调度)
- [3. 不擅长复杂 DAG 工作流](#3. 不擅长复杂 DAG 工作流)
- [4. 对 Java 生态最友好](#4. 对 Java 生态最友好)
- [五、XXL-JOB 和常见方案怎么选?](#五、XXL-JOB 和常见方案怎么选?)
- [六、哪些场景特别适合用 XXL-JOB?](#六、哪些场景特别适合用 XXL-JOB?)
-
- [场景 1:微服务里的统一定时任务管理](#场景 1:微服务里的统一定时任务管理)
- [场景 2:业务经常调整任务时间](#场景 2:业务经常调整任务时间)
- [场景 3:大数据量批处理](#场景 3:大数据量批处理)
- [场景 4:任务不能因为单机故障中断](#场景 4:任务不能因为单机故障中断)
- [七、哪些场景不建议用 XXL-JOB?](#七、哪些场景不建议用 XXL-JOB?)
-
- [1. 小项目、单体系统、任务极少](#1. 小项目、单体系统、任务极少)
- [2. 毫秒级高频调度](#2. 毫秒级高频调度)
- [3. 复杂工作流编排](#3. 复杂工作流编排)
- [八、实战代码:一个标准的 XXL-JOB 任务怎么写?](#八、实战代码:一个标准的 XXL-JOB 任务怎么写?)
-
- [1. 标准任务模板](#1. 标准任务模板)
- [2. 分片任务示例](#2. 分片任务示例)
- [九、使用 XXL-JOB 的 5 条最佳实践](#九、使用 XXL-JOB 的 5 条最佳实践)
-
- [1. 一个任务只做一件事](#1. 一个任务只做一件事)
- [2. 一定要保证幂等性](#2. 一定要保证幂等性)
- [3. 日志一定要打全](#3. 日志一定要打全)
- [4. 核心业务逻辑放 Service 层](#4. 核心业务逻辑放 Service 层)
- [5. 关注日志清理和高可用](#5. 关注日志清理和高可用)
- 十、一个真实项目中的落地方向
- [十一、总结:XXL-JOB 值不值得用?](#十一、总结:XXL-JOB 值不值得用?)
- 参考资料
前言
你有没有过这样的经历:
- 本地测试一切正常,到了生产环境,定时任务却开始"失控"
- 服务一上集群,
@Scheduled任务就重复执行 - 业务临时要改 Cron,只能改代码、发版、重启
- 任务失败了没人知道,任务有没有执行过,也说不清楚
很多团队一开始都觉得:
"定时任务嘛,不就是写个 Cron 表达式的事。"
可真正到了生产环境才发现,问题从来不是"能不能跑",而是:
它能不能稳定跑?失败后能不能看见?规则能不能动态改?多节点下会不会重复执行?
这也是为什么,越来越多 Java 项目,尤其是 Spring Boot / Spring Cloud 微服务项目 ,开始从 @Scheduled 转向 XXL-JOB。
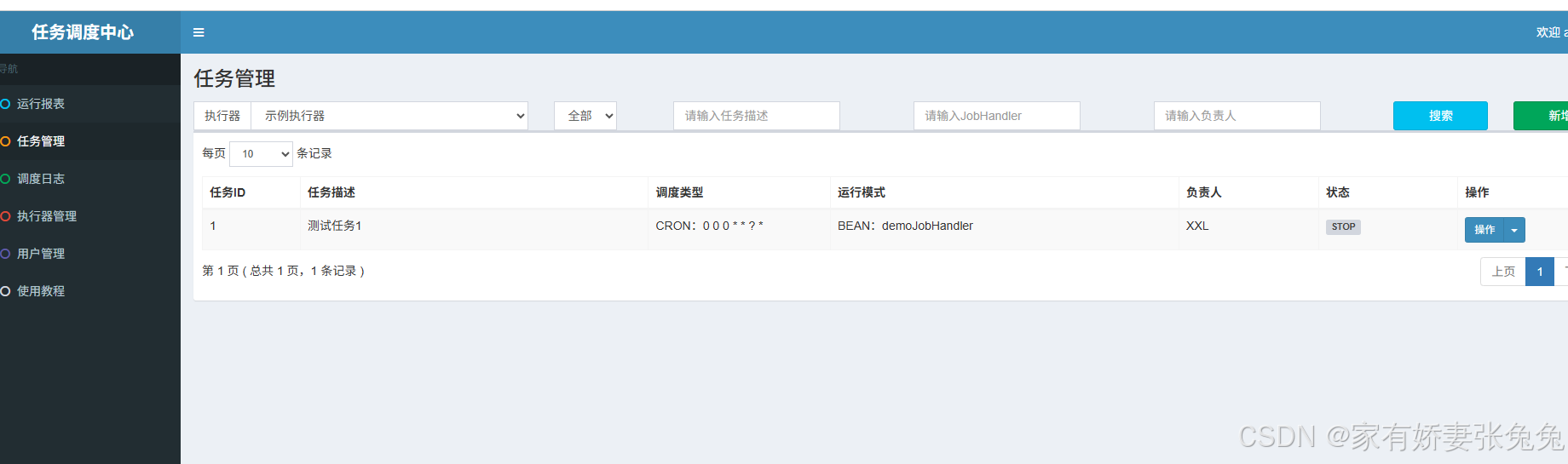
一、什么是 XXL-JOB?
XXL-JOB 是一个开源的分布式任务调度平台,核心特点可以概括为:
- 可视化管理
- 分布式调度
- 轻量易接入
- 支持动态配置
- 支持日志、告警、分片、路由
如果说 @Scheduled 只是一个"定时执行器",那么 XXL-JOB 更像一个完整的"任务调度中控台"。
它解决的不是"任务能不能执行",而是:
- 任务怎么统一管理
- 集群环境下怎么避免重复执行
- 任务失败后怎么追踪
- 业务临时改时间时怎么快速生效
- 大批量任务怎么并行处理
一句话总结:
@Scheduled解决的是"定时执行",XXL-JOB 解决的是"任务调度治理"。
二、为什么很多项目开始放弃 @Scheduled?
先看最常见的写法:
java
@Component
public class DemoTask {
@Scheduled(cron = "0 0 2 * * ?")
public void cleanTempFile() {
System.out.println("凌晨2点清理临时文件");
}
}单机环境下,这种方式确实简单直接。
但一旦进入真实业务场景,它的问题就会逐渐暴露。
1. 集群部署下容易重复执行
如果你的服务部署了 3 台机器,那么这个任务很可能会被执行 3 次。
对于下面这些任务,重复执行往往就是事故:
- 发券
- 对账
- 归档
- 状态变更
- 定时通知
2. 修改调度规则成本高
业务一句话:"把任务从 8 点改成 7 点半。"
如果你用的是 @Scheduled,大概率要经历:
- 改代码
- 提交测试
- 发布上线
- 重启服务
只为了改一个 Cron,代价太高。
3. 缺乏运维视角
你很难快速回答这些问题:
- 这个任务最近执行了几次?
- 哪次成功,哪次失败?
- 失败原因是什么?
- 能不能手动执行一次?
- 能不能临时暂停?
很多团队的定时任务,最后都变成了"祖传代码":
平时没人管,出事全靠猜;
真到凌晨报警时,大家一起围着日志"考古"。
而 XXL-JOB,本质上就是来解决这些问题的。
三、XXL-JOB 的核心优势
1. 可视化管理:任务终于不再是黑盒
XXL-JOB 自带 Web 管理后台,可以直接:
- 新增任务
- 修改 Cron 表达式
- 手动触发执行
- 暂停/恢复任务
- 查看执行日志
- 配置失败告警
相比 Quartz 还需要自己开发一套管理页面,XXL-JOB 最大的优势就是:开箱即用,运维友好。
2. 接入简单:对 Spring Boot 生态非常友好
对于 Java 项目来说,XXL-JOB 的接入门槛并不高。
一个最基础的任务写法如下:
java
@XxlJob("deviceStatusCheckJob")
public void deviceStatusCheckJob() {
System.out.println("执行设备状态巡检");
}开发侧几乎没有太高学习成本,尤其适合 Spring Boot / Spring Cloud 项目快速落地。
3. 原生支持分布式调度
这是 XXL-JOB 相比 @Scheduled 最核心的价值之一。
它支持:
- 执行器自动注册
- 多节点部署
- 故障转移
- 路由策略调度
常见路由策略包括:
- 轮询
- 随机
- 一致性 Hash
- 最不经常使用
- 最近最久未使用
这意味着:
当某个服务节点宕机时,任务可以自动调度到其他可用节点执行。
对于微服务环境来说,这一点非常重要。
4. 支持动态修改参数和 Cron
生产环境里,最常见的需求不是"写任务",而是"改任务"。
比如:
- 报表任务从每天 8:00 改成 7:30
- 巡检任务从每小时执行一次改成每 30 分钟一次
- 临时追加参数,补跑某个时间段的数据
XXL-JOB 支持直接在后台修改配置,无需重启服务。
这对业务变化快、运维介入多的项目,价值非常明显。
5. 支持任务分片,适合大数据量处理
如果一个任务要处理几十万甚至上百万条数据,单机跑往往太慢。
这时可以使用 XXL-JOB 的分片广播能力,让多台机器并行处理。
示例代码:
java
@XxlJob("archiveDataJob")
public void archiveDataJob() {
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
// 每台机器只处理自己对应的那部分数据
dataService.archive(shardIndex, shardTotal);
}典型 SQL 写法:
sql
SELECT *
FROM device_log
WHERE MOD(id, #{shardTotal}) = #{shardIndex}适合这类场景:
- 百万日志归档
- 批量数据同步
- 定时数据清洗
- 海量设备并行巡检
四、XXL-JOB 的局限性:别只看优点,不看边界
技术选型最怕一件事:
只看宣传,不看代价。
XXL-JOB 很实用,但并不是万能的。
1. 依赖数据库
XXL-JOB 调度中心依赖 MySQL 存储任务配置、执行日志等信息。
这意味着:
- 高频调度会增加数据库压力
- 日志表需要定期清理
- 秒级任务场景要谨慎评估
所以它更适合:
- 分钟级任务
- 小时级任务
- 天级周期任务
- 常规业务调度场景
而不适合极高频、极低延迟的调度需求。
2. 本质上是中心化调度
虽然 XXL-JOB 支持调度中心集群部署,但整体上仍然是中心化架构,并依赖数据库协调调度。
简单理解:
- 执行器挂了:任务还能切到其他节点继续执行
- 调度中心异常:任务触发会受到影响
所以在生产环境中,调度中心和数据库本身也要做好高可用。
3. 不擅长复杂 DAG 工作流
如果你的任务依赖关系非常复杂,比如:
- A 成功后触发 B 和 C
- B、C 都成功后再触发 D
- 中间还带条件判断、审批、补偿、回滚
那 XXL-JOB 就不是最优解。
这类场景更适合:
- Apache Airflow
- DolphinScheduler
因为它们天生就是为 DAG 编排设计的。
4. 对 Java 生态最友好
XXL-JOB 对 Java 的支持最好。
虽然也支持 GLUE 脚本模式去执行 Shell、Python 等脚本,但整体体验和工程化能力,还是更偏向 Java 项目。
五、XXL-JOB 和常见方案怎么选?
这是很多人最关心的问题。
| 方案 | 可视化 | 分布式能力 | 学习成本 | 动态改配置 | 适用场景 |
|---|---|---|---|---|---|
@Scheduled |
❌ | ❌ | 低 | ❌ | 单机、小项目、简单任务 |
| Quartz | ❌(一般需自研) | 可做集群,但较复杂 | 中 | 一般 | 传统单体应用、老项目 |
| XXL-JOB | ✅ | ✅ | 低 | ✅ | Java 微服务、中小规模调度 |
| Elastic-Job | ✅ | ✅ | 高 | ✅ | 高可用、复杂分布式调度 |
| Airflow / DolphinScheduler | ✅ | ✅ | 高 | ✅ | 复杂 DAG 工作流 |
一句话建议
- 任务少、单机部署 :直接用
@Scheduled - Java 微服务常规定时任务 :优先考虑 XXL-JOB
- 复杂依赖编排:用 Airflow / DolphinScheduler
- 高复杂度分布式调度治理:再看 Elastic-Job
六、哪些场景特别适合用 XXL-JOB?
场景 1:微服务里的统一定时任务管理
如果你的系统是 Spring Cloud 架构,服务节点不止一个,继续使用 @Scheduled 很容易出现重复执行问题。
XXL-JOB 可以帮你做到:
- 统一配置
- 统一管理
- 统一日志
- 统一运维
这几乎是它最典型的落地场景。
场景 2:业务经常调整任务时间
现实中最常见的一句话就是:
"这个任务时间改一下,明天就要生效。"
如果每次都要走发版流程,效率会很低。
而 XXL-JOB 可以直接在后台改 Cron,实时生效。
场景 3:大数据量批处理
例如:
- 每天凌晨归档百万条历史日志
- 每小时汇总设备环境数据
- 批量扫描用户状态并触发处理逻辑
这类任务往往适合配合分片广播来提升吞吐能力。
场景 4:任务不能因为单机故障中断
例如:
- 设备状态巡检
- 告警通知
- 定时报表
- 对账任务
- 控制指令下发
这些任务要求"节点挂了,业务不能停",XXL-JOB 在这类场景下非常实用。
七、哪些场景不建议用 XXL-JOB?
1. 小项目、单体系统、任务极少
如果你的项目只有一台机器,定时任务也就一两个,比如:
- 每天清理一次临时文件
- 每晚发一封邮件
- 每小时跑一次统计
那直接使用 @Scheduled 就够了。
这时候上 XXL-JOB,反而容易变成"为了技术而技术"。
2. 毫秒级高频调度
如果任务触发频率是毫秒级,比如每 100ms 执行一次,那么 XXL-JOB 并不适合。
原因很简单:
- 数据库协调有成本
- HTTP 通信有开销
- 调度链路更偏"业务型"而不是"极致性能型"
这类场景更适合:
- 时间轮
- 内存队列
- 专用调度组件
3. 复杂工作流编排
如果你的任务之间依赖关系非常重,比如 ETL、审批流、多级流水线,那么就别勉强用 XXL-JOB 了。
工具没选对,后期维护成本只会越来越高。
八、实战代码:一个标准的 XXL-JOB 任务怎么写?
1. 标准任务模板
java
@Slf4j
@Component
public class DeviceJob {
@Resource
private DeviceService deviceService;
@XxlJob("deviceInspectJob")
public void deviceInspectJob() {
long start = System.currentTimeMillis();
String param = XxlJobHelper.getJobParam();
XxlJobHelper.log("任务开始执行,param = {0}", param);
log.info("deviceInspectJob start, param={}", param);
try {
int count = deviceService.inspect(param);
long cost = System.currentTimeMillis() - start;
XxlJobHelper.log("任务执行成功,处理 {0} 条数据,耗时 {1} ms", count, cost);
log.info("deviceInspectJob success, count={}, cost={}ms", count, cost);
} catch (BusinessException e) {
log.error("deviceInspectJob business error", e);
XxlJobHelper.handleFail("业务异常:" + e.getMessage());
} catch (Exception e) {
log.error("deviceInspectJob system error", e);
XxlJobHelper.handleFail("系统异常:" + e.getMessage());
}
}
}这个模板的核心思路是:
- 参数通过
XxlJobHelper.getJobParam()获取 - 业务逻辑放在 Service 层
- 关键日志打全
- 异常分类处理
2. 分片任务示例
java
@XxlJob("archiveLogJob")
public void archiveLogJob() {
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
log.info("当前分片:{}/{}", shardIndex, shardTotal);
archiveService.archiveByShard(shardIndex, shardTotal);
}适合的典型场景:
- 日志归档
- 批量清理历史数据
- 多节点并发处理海量数据
九、使用 XXL-JOB 的 5 条最佳实践
1. 一个任务只做一件事
不要把"同步数据 + 清洗数据 + 生成报表 + 发通知"全堆在一个任务里。
拆开以后:
- 更清晰
- 更易排查
- 更方便复用
- 更利于失败补偿
2. 一定要保证幂等性
任务可能因为失败重试,也可能因为人工补跑而再次执行。
所以必须保证:
执行一次和执行多次,结果应该一致。
常见做法包括:
- 唯一业务 ID 去重
- 状态机控制
- 时间窗口防重
- 分布式锁兜底
3. 日志一定要打全
建议至少记录这些内容:
- 开始时间
- 结束时间
- 入参
- 处理数量
- 异常信息
- 耗时统计
因为线上排障时,日志就是你的"第二现场"。
4. 核心业务逻辑放 Service 层
Job 负责调度,不应该承载太复杂的业务代码。
推荐结构:
- Job:接参数、调服务、记日志
- Service:写核心业务逻辑
- DAO / Mapper:处理数据访问
这样后续测试、复用、排查都更容易。
5. 关注日志清理和高可用
生产环境里,XXL-JOB 的日志表会越来越大。
如果不清理,数据库迟早会有压力。
建议:
- 定期清理历史日志
- 管理端部署集群
- 数据库做好备份和高可用
- 关键任务增加失败告警
十、一个真实项目中的落地方向
如果你做的是设备、IoT、园区、监控、农业、能源类系统,XXL-JOB 通常很容易落地。
典型场景包括:
- 设备状态巡检:每 5 分钟检查设备在线情况
- 环境数据聚合:每小时汇总温湿度、光照、空气质量
- 异常检测任务:定时分析波动数据并触发告警
- 报表生成任务:每天凌晨生成日报、周报、月报
- 定时控制逻辑:固定时间下发开关、灌溉、遮阳等指令
这些任务的共同特点是:
- 业务重要
- 周期固定
- 需要人工可视化管理
- 经常会有运维介入
说白了,XXL-JOB 最适合的,就是这类"看似普通,实则最容易出事故"的任务场景。
十一、总结:XXL-JOB 值不值得用?
如果你是 Java 技术栈,尤其是 Spring Boot / Spring Cloud 项目,那么 XXL-JOB 基本可以看作是一个高性价比的默认选择。
它最大的价值,不是"让任务执行起来",而是让任务从"代码里的一个方法",升级为"系统里的可治理资产"。
它适合谁?
- 有多个定时任务的项目
- 有微服务部署的系统
- 需要动态修改 Cron 的业务
- 需要日志、告警、手动补跑能力的团队
它不适合谁?
- 单机小项目
- 毫秒级高频调度场景
- 复杂 DAG 工作流场景
最后送大家一句我自己很认同的话:
定时任务真正的难点,从来不是写出一个 Cron,而是让它在生产环境中可调度、可观测、可治理。
很多系统的问题,不是"任务没写",而是"任务写了以后,没人管得住"。
真正成熟的系统,拼的从来不是"能不能跑",而是:
- 跑得稳
- 查得到
- 改得快
- 扛得住
而 XXL-JOB,恰恰就是补齐这部分能力的工具。
参考资料
- XXL-JOB 官方文档:https://www.xuxueli.com/xxl-job/
- GitHub 源码:https://github.com/xuxueli/xxl-job