
AI行业正在经历一场从技术炫技到效率理性的深刻转变。全球企业级AI应用中约50%的Token正在被浪费,企业和开发者开始重新审视AI应用的成本效益。数字经济应用实践专家骆仁童博士表示,如今当AI从"能聊天"走向"能干活",这才发现,超跑的油耗根本扛不住日常通勤的高频消耗。
Token是什么? 简单说,它是AI时代的计费单位,就像手机的流量费。你喂给AI的文字、图片越多,消耗的Token就越多,费用就越高。
一、成本危机的真相:从盲目追求到理性回归
企业和开发者正在用最贵的车跑最短的路。《财经》报道指出,AI应用从"对话"转向"执行",这些计算资源流向了较贵的大型旗舰模型,Agent在复杂多轮任务中,历史文件、对话会不断累积,大量无用、冗余、过期的信息会不断产生并且重复计算,Token消耗因此指数级增长。
一个客服Agent的真实案例 :处理一张工单需要调用模型十几次------理解意图、查询知识库、判断优先级、生成回复、核查格式。如果同时有几千张工单在处理,每天的调用量轻松进入百万级别。
今年3月,开发者shelvenzhou在Github的测试引发广泛讨论:第一轮对话Token成本0.0050美元;第五轮0.0665美元(13.3倍);第10轮0.13美元(26倍)。
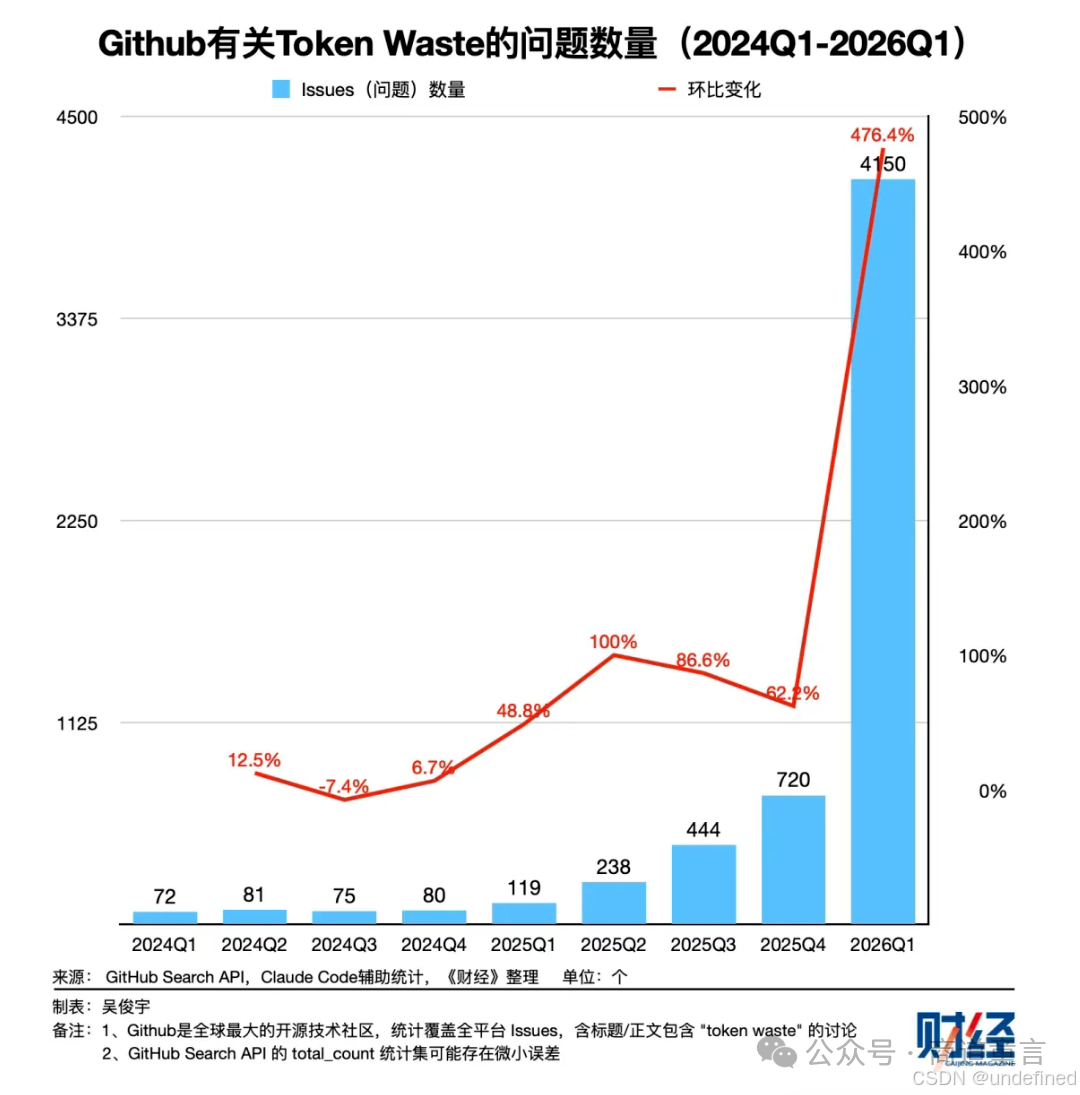
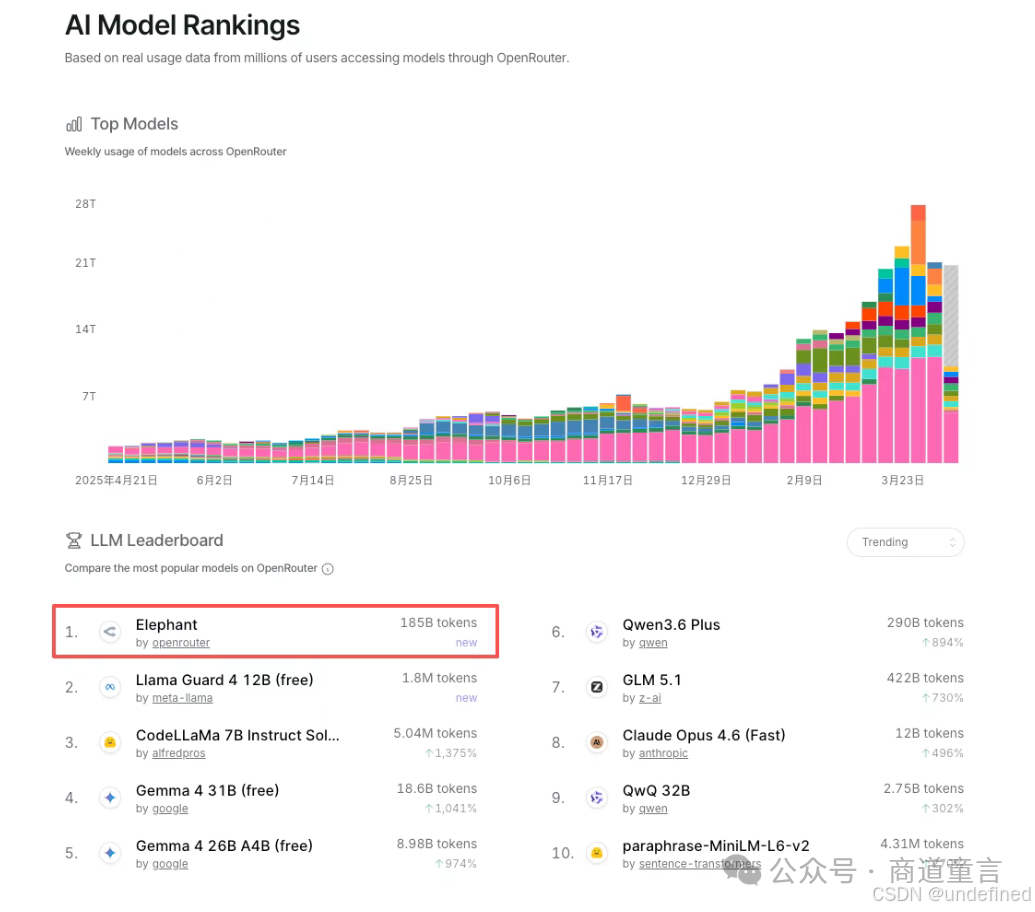
市场信号已经很明显 :OpenRouter数据显示,旗舰级模型调用占比在下降,100B--300B区间模型调用量明显上升。100B模型Elephant单日流量暴涨500%。GitHub上"Token Waste"相关讨论超过5200个,仅2026年一季度就诞生4150个。
二、分层调用架构:AI商业应用的新范式
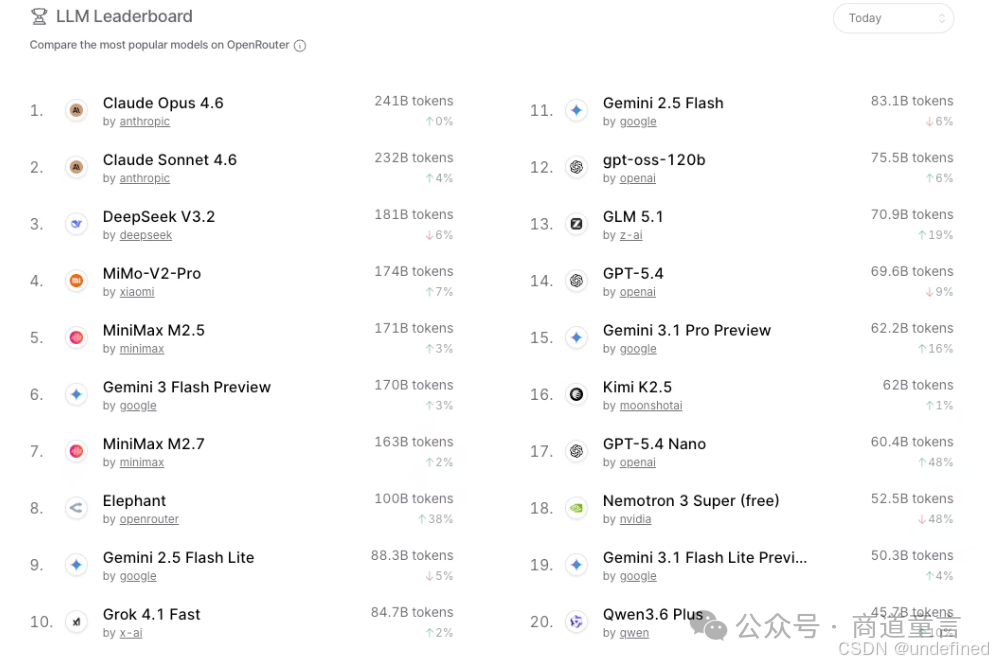
"大模型控榜,小模型控场" ------这是当前模型格局的真实写照。根据OpenRouter 4月16日数据,传统大尺寸旗舰模型依然掌握复杂任务话语权,但主打轻量化、高性价比的小尺寸模型形成了不可忽视的"腰部力量"。
小尺寸模型涨幅惊人:GPT-5.4 Nano涨幅48%,Elephant单日涨幅38%。OpenClaw、Hermes Agent等应用成为这些小尺寸模型的"最大流量贡献"。
分层调用的核心逻辑 :大型模型负责决策,小型模型快速执行。以OpenAI的Codex为例,GPT-5.4负责规划、协调与最终判断,GPT-5.4 mini并行处理代码库检索、大文件审阅等子任务。
某电商企业的实践 :通过分层架构,将AI客服成本降低65%。旗舰模型处理复杂投诉,小模型处理标准咨询,整体响应速度提升40%。
三、Token效率优化的8个实战策略
策略1:清理"烂菜叶"------提升输入纯度
AI按阅读字数收费,无论内容是否有用。直接把PDF扔给AI是最常见的浪费------页眉、页脚、隐藏水印都要计费。
立即行动 :把PDF转成干净的Markdown文本。10MB的PDF变成10KB的干净文本,省下99%的费用,AI运行速度还更快。
策略2:压缩图片------控制视觉Token消耗
图片Token消耗=宽度像素×高度像素÷750。1000×1000像素的图片消耗1334个Token,压缩到200×200像素只消耗54个Token------差了25倍。
实用原则 :识别文字或简单判断时,用最小可用分辨率。4K分辨率在多数场景下是纯浪费。
策略3:立规矩------控制AI的表达欲
输出Token比输入Token贵3-5倍。那些"好的,我已完全理解您的需求"的礼貌开场白,在API账单上都是要花钱的。
一次投入永久受益 :用系统指令明确告诉AI------不要寒暄,不要解释,不要复述需求,直接给答案。实测显示,将500字提示词压缩到180字,Token消耗骤降64%,质量几乎无波动。
策略4:一个任务一个对话框------避免重复计费
AI每次回答都要重读整个对话历史。追踪496个真实对话发现:第1条消息成本3.6美分,第50条消息成本4.5美分------贵了80%。
简单习惯 :话题聊完就开启新对话。别让AI当永远不关机的聊天窗口。
策略5:用压缩功能------给对话做"赛博断舍离"
Claude Code的/compact命令能将长对话浓缩成简短摘要。当上下文很长时,这是最有效的省钱手段。
策略6:启用提示词缓存------重复内容只付一次钱
反复使用同一段系统提示词或参考文档时,AI会缓存这部分内容。缓存命中的Token价格是正常价格的1/10(Anthropic)或降低约50%(OpenAI)。
重要前提 :内容和顺序必须保持一致,放在对话最前面。一旦改动,缓存失效重新按全价计费。
策略7:按任务选模型------别开保时捷去买菜
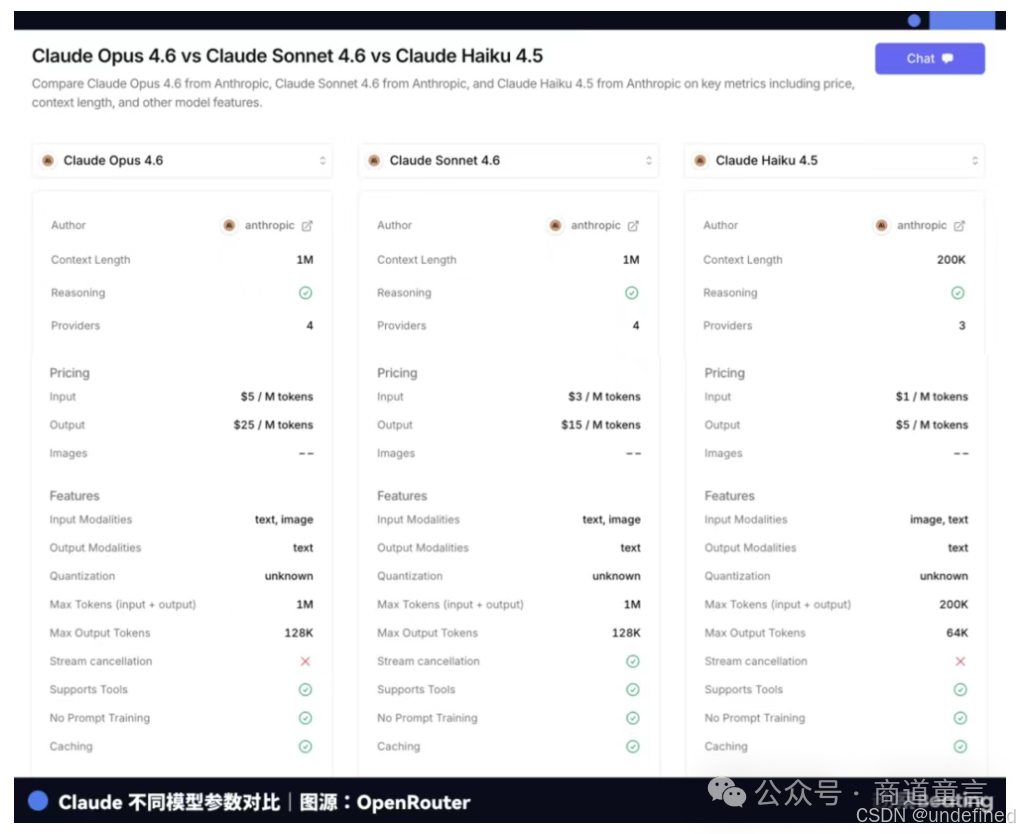
Claude Opus 4.6每百万Token输入5美元、输出25美元,Claude Haiku 3.5只要0.8美元输入、4美元输出------差了6倍。
两段式工作流 :第一阶段用廉价模型做资料搜集、格式清理、初稿生成;第二阶段用顶级模型做核心决策与深度精修。分析100页报告时,先用Gemini Flash提取关键数据成10页摘要,再交给Claude Opus深度分析。
策略8:人机协作------人的判断力是最好的过滤器
让AI自动处理邮件,会把每封邮件都当成独立任务,Token消耗巨大。花30秒手动筛掉明显不需要AI处理的邮件,成本立刻降到原来的一小部分。
ROI计算公式 :(优化前月成本-优化后月成本)/优化投入×100%
四、效率不是降级,是分工
旗舰模型不会消失。在需要跨领域深度推理、多步骤规划、复杂代码生成的任务上,它们仍然是必要的。但在日常业务执行层------那些占据大多数调用量的任务------用旗舰模型是在为不需要的能力付费。
最极致的节省不是算法的优化,而是决策的断舍离。
算力越来越贵的时代,最聪明的用法,不是让AI替代人,而是让AI和人去干各自擅长的事。当这种对Token的敏感性内化为一种条件反射,你才真正从算力的附庸,变回了算力的主人。
一条路线日渐清晰:规模继续重要,但效率开始定价。
数字经济应用实践专家骆仁童博士认为,在算法的世界里,精准是最高级的真诚,简洁是最高效的礼貌,断舍离是最智慧的囤积。这是对商业逻辑的回归------技术终究要服务于效率,而不是为了炫技而存在。
你的AI应用是否也在经历Token浪费的困扰?
A. 是的,成本已经影响业务决策
B. 有浪费,但还在可接受范围
C. 不太清楚,需要评估一下
欢迎在评论区分享你的选择和优化经验!
END
热推新书《AI提问大师》《DeepSeek应用能手》现已上架!