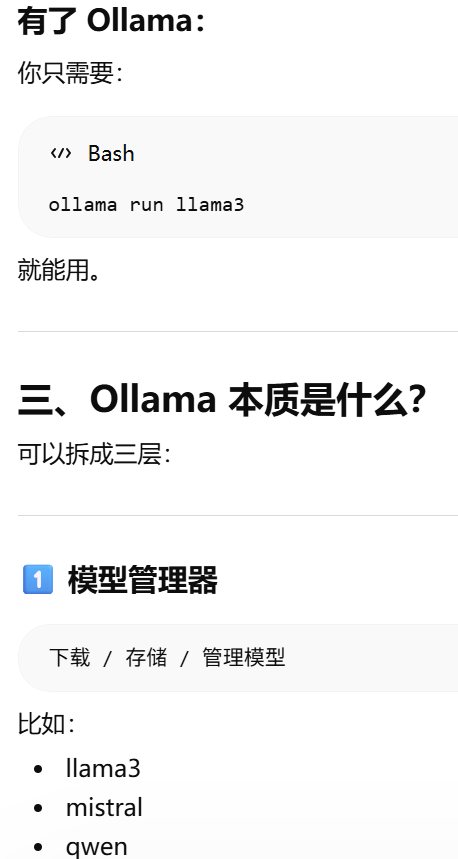
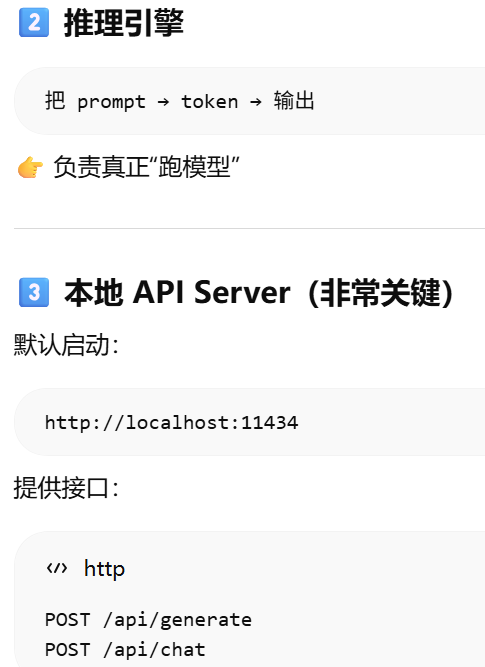
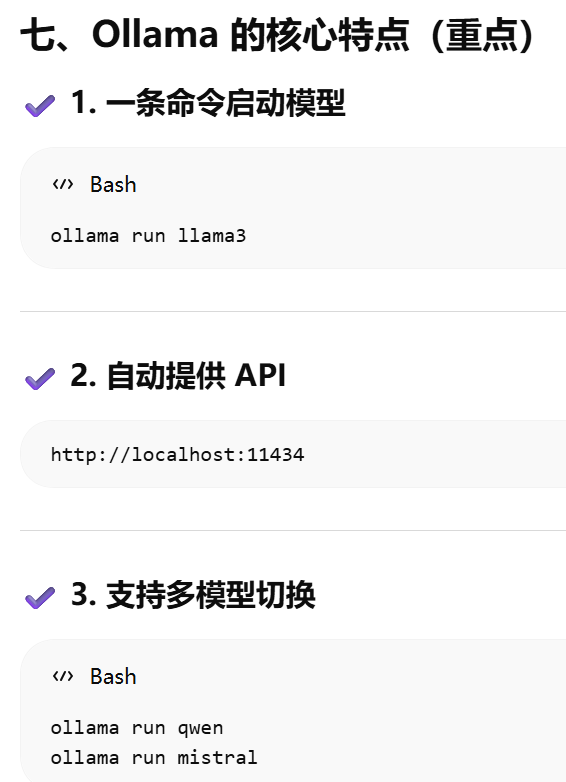
Ollama 的作用可:让你在本地像"调用 API 一样运行大模型"
Ollama = "本地大模型运行 + API 服务封装器"


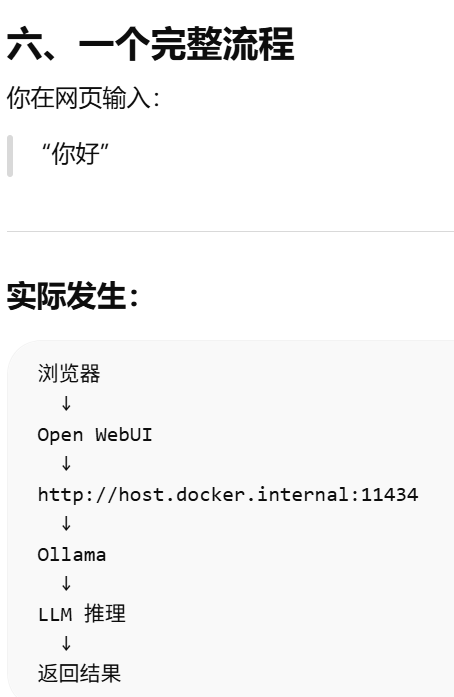
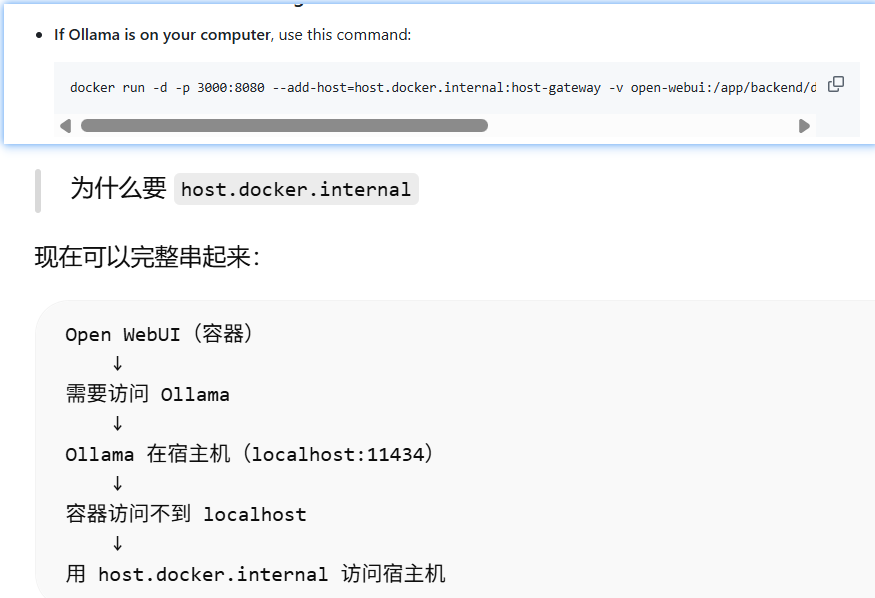
Open WebUI


主流大模型部署方式
Ollama

vLLM

TGI(HuggingFace 推理服务)

LM Studio(GUI 本地运行)

llama.cpp(极致轻量 CPU 部署)

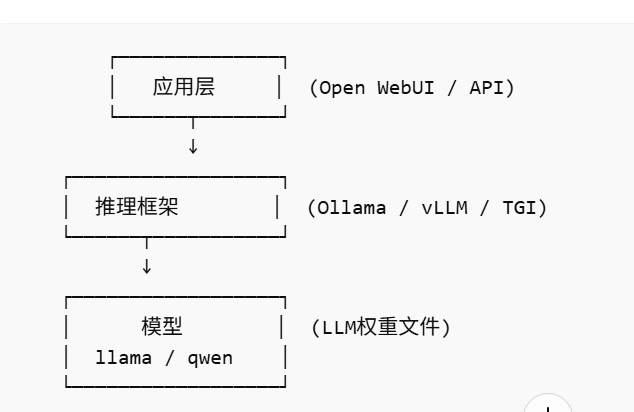
LLM、推理框架到底是什么关系。
👉 LLM 是"脑子(模型)"
👉 推理框架是"让脑子能工作起来的发动机 + 操作系统"
在大模型系统里,其实是三层:
① 模型(LLM权重)
② 推理框架(Inference Engine)
③ 应用(Web UI / API / Chat
❗ LLM 不是软件
❗ LLM 是"数据(权重)"
👉 推理框架才是"运行系统"
模型 = 文件(权重)推理框架 = 运行这个文件的程序
👉 LLM 是模型的一种👉 模型只是"参数文件"
👉 推理框架才是真正运行模型的系统
模型(Model)是什么?任何机器学习训练出来的函数"


LLM 是什么?一堆参数(几十 GB),不会自己运行,只是数学函数,只是文件
为什么不能直接用模型?
因为模型文件本身:
❌ 不会接收 HTTP 请求
❌ 不会管理 GPU
❌ 不会做并发
❌ 不会 batch
❌ 不会 stream 输出
👉 换句话说:
模型 ≠ 可运行服务


推理框架是什么?运行模型的引擎
显存分配 / KV cache???




应用层是什么?把输入发给模型,把输出展示给用户"

量化 把"模型参数精度降低",换取更快更省显存



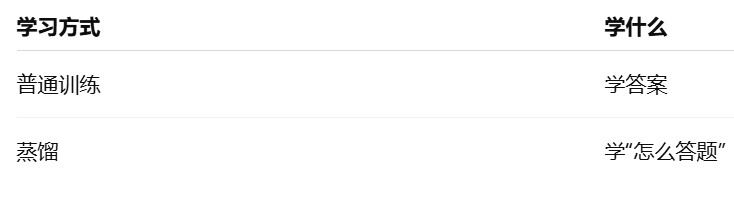
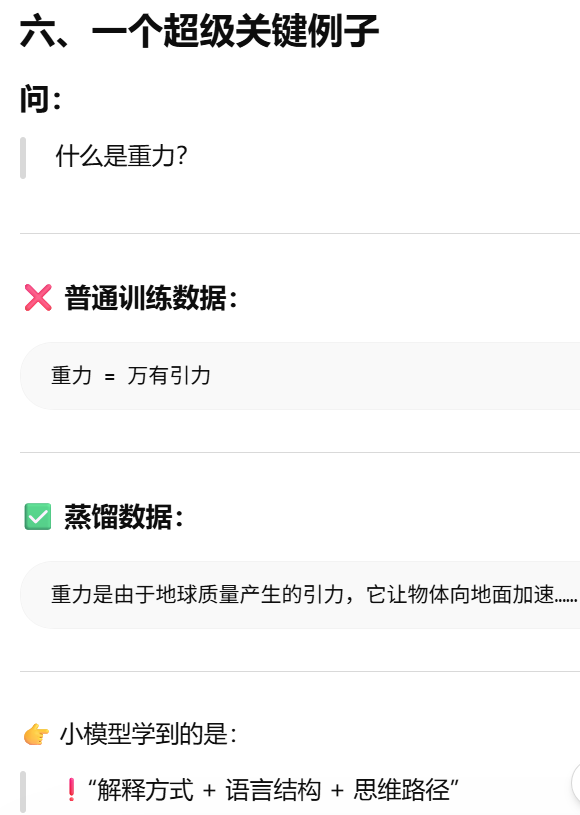
蒸馏:用"大模型的输出结果当输入
蒸馏:
把问题交给大模型 , 让它生成"标准回答" , 用这些回答训练小模型