Interaction服务
问题1:在这个项目中,点赞功能使用了Redis Lua脚本来实现,请解释:
-
为什么需要使用Lua脚本而不是普通的Redis命令?
-
这段Lua脚本是如何保证原子性和幂等性的?
-
如果Lua脚本执行失败,应该如何处理?
参考答案 :
- 为什么使用Lua脚本 :
-
原子性 :Lua脚本在Redis中是原子执行的,不会被其他命令打断,可以保证多个操作的一致性
-
减少网络开销 :将多次Redis操作合并到一个脚本中执行,减少网络往返时间
-
复杂逻辑 :可以在脚本中实现更复杂的业务逻辑判断
- 原子性和幂等性保证 :
Lua
-- 检查用户是否已经存在于点赞集合中(幂等性关键)
local is_member = redis.call('SISMEMBER', KEYS[1], ARGV[1])
-- 如果用户已经点赞,直接返回当前计数(不执行写操作)
if is_member == 1 then
local current_count = redis.call('GET', KEYS[2])
return {1, tonumber(current_count or 0)}
end
-- 执行点赞操作(原子性)
redis.call('SADD', KEYS[1], ARGV[1]) -- 加入集合
local new_count = redis.call('INCR', KEYS[2]) -- 计数器+1
return {0, new_count}原子性 :整个Lua脚本在Redis中作为一个整体执行,中间不会插入其他命令 幂等性 :通过 SISMEMBER 检查用户是否已点赞,避免重复计数
- 失败处理 :
-
Redis客户端会返回错误,应用层需要捕获并处理
-
可以选择:重试、降级到数据库操作、记录日志告警
-
确保最终一致性:通过消息队列异步补偿或定期对账
问题2:缓存版本控制策略
项目中使用了缓存版本号机制(如 PostCacheVersionKey ),请解释:
-
这种缓存失效策略的原理是什么?
-
相比直接删除缓存key,这种方式有什么优缺点?
-
在什么场景下适合使用这种策略?
参考答案 :
- 原理 :
Go
// common/redis/keys.go:16
PostCacheVersionKey = KeyPrefix + "post:cache_version:"
// service/content/rpc/internal/logic/cache_helper.go:34-40
func buildPostDetailCacheKey(ctx context.Context, svcCtx *svc.ServiceContext, postID uint64) string {
return fmt.Sprintf("%s%s:v%s", redis.PostInfoKey, strconv.FormatUint(postID, 10),
getPostCacheVersion(ctx, svcCtx, postID))
}
// 失效缓存时,只需要增加版本号
func invalidatePostCaches(ctx context.Context, svcCtx *svc.ServiceContext, postID uint64) {
_, _ = svcCtx.Redis.Incr(ctx, fmt.Sprintf("%s%d", redis.PostCacheVersionKey, postID))
}工作流程 :
-
缓存key中包含版本号: schill:post:info:{id}:v{version}
-
需要失效缓存时,不删除key,而是 INCR 版本号
-
下次读取时使用新版本号,自然读取不到旧缓存
- 优缺点 :
优点 :
-
避免缓存击穿:旧缓存key仍然存在,直到过期,大量并发请求不会同时打到数据库
-
实现简单:只需要维护一个版本号key
-
可以优雅降级:即使版本号操作失败,仍可使用旧版本缓存
-
减少网络开销:不需要遍历和删除多个相关缓存key
缺点 :
-
内存占用:旧缓存key会在Redis中保留直到过期
-
缓存不一致窗口期:在版本号更新后,旧缓存仍然有效(短暂时间)
-
需要额外存储:每个实体需要维护一个版本号key
- 适用场景 :
-
读多写少的场景
-
对一致性要求不是特别严苛(接受短暂不一致)
-
需要防止缓存击穿的热点数据
-
缓存key较多,失效成本高的场景
问题3:消息队列的异步处理模式
项目中使用Kafka处理各种事件(如 PostStarMessage ),请分析:
-
为什么点赞成功后要发送消息而不是直接更新数据库?
-
这种异步模式可能会带来什么问题?如何解决?
-
消息发送失败怎么办?
参考答案 :
- 为什么使用异步 :
Go
// service/interaction/rpc/internal/logic/starpostlogic.go:59-78
if status == 0 {
go func() {
msg := mq.PostStarMessage{
PostID: in.PostId,
UserID: in.UserId,
Timestamp: timestamp,
}
if err := l.svcCtx.KafkaProducer.SendEvent(...); err != nil {
logx.Errorf("send post star event failed: %v", err)
}
}()
}原因 :
-
性能优化 :Redis操作很快,用户可以立即得到响应,数据库更新异步进行
-
解耦 :互动服务不需要直接依赖内容服务的数据库更新逻辑
-
削峰填谷 :高并发点赞时,消息队列可以缓冲请求
-
扩展性 :可以有多个消费者处理同一事件(如更新计数、生成Feed、通知等)
- 异步模式的问题与解决方案 :
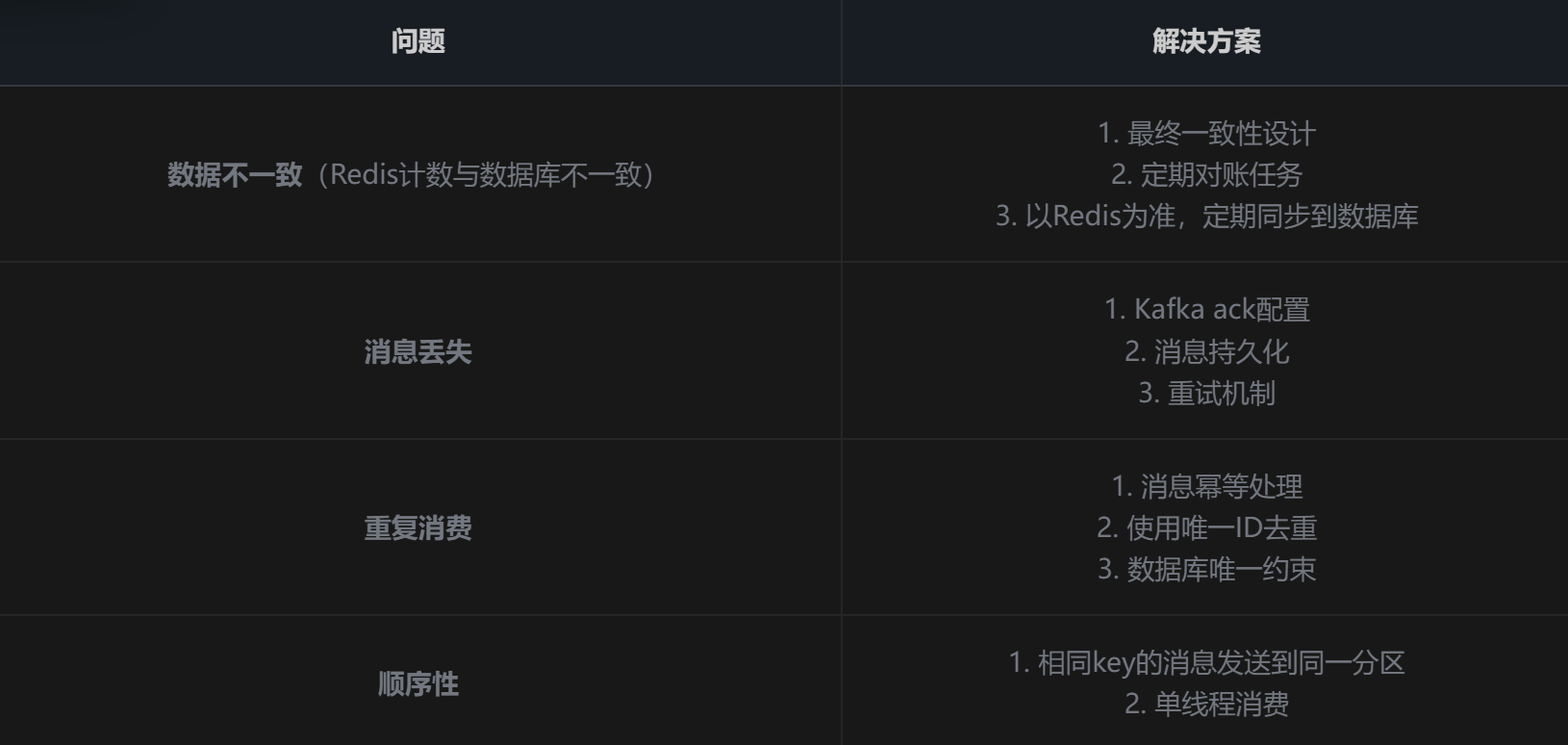
comment服务
问题:评论投票 Lua 脚本原子性实现
问题 :分析 votecommentlogic.go 中的 Lua 脚本:
-
这个脚本解决了什么问题?
-
如何保证幂等性?
-
如果 Redis 宕机,数据如何恢复?
const voteScript = `
local voteKey = KEYS[1]
local infoKey = KEYS[2]
local newVote = ARGV[1]
local expire = ARGV[2]-- 获取旧的投票状态
local oldVote = redis.call('get', voteKey)
if not oldVote then
oldVote = '0'
end-- 如果状态没有变化,直接返回当前计数
if oldVote == newVote then
local likeCount = redis.call('hget', infoKey, 'like_count') or '0'
local dislikeCount = redis.call('hget', infoKey, 'dislike_count') or '0'
return {likeCount, dislikeCount, newVote}
end-- 计算计数变化
local likeDelta = 0
local dislikeDelta = 0-- 减去旧状态的计数
if oldVote == '1' then
likeDelta = -1
elseif oldVote == '2' then
dislikeDelta = -1
end-- 加上新状态的计数
if newVote == '1' then
likeDelta = likeDelta + 1
elseif newVote == '2' then
dislikeDelta = dislikeDelta + 1
end-- 应用修改
if newVote == '0' then
redis.call('del', voteKey)
else
redis.call('set', voteKey, newVote)
redis.call('expire', voteKey, expire)
endif likeDelta ~= 0 then
redis.call('hincrby', infoKey, 'like_count', likeDelta)
end
if dislikeDelta ~= 0 then
redis.call('hincrby', infoKey, 'dislike_count', dislikeDelta)
end-- 返回最新的计数
local likeCount = redis.call('hget', infoKey, 'like_count') or '0'
local dislikeCount = redis.call('hget', infoKey, 'dislike_count') or '0'return {likeCount, dislikeCount, newVote}
` -
解决的问题 :
-
原子性 :多个 Redis 操作原子执行,防止并发问题
-
数据一致性 :投票状态和计数保持一致
-
性能优化 :减少网络开销
- 幂等性保证 :
```
-- 检查状态是否变化
if oldVote == newVote then
-- 直接返回,不执行修改
return {likeCount, dislikeCount, newVote}
end
```
-
相同请求多次执行结果一致
-
不会重复计数
- Redis 宕机恢复策略 :
-
方案A:Kafka 事件回溯 (当前实现)
// 1. 投票先写 Redis,然后发送 Kafka
go func() {
if err := l.svcCtx.KafkaProducer.SendMessage(
l.svcCtx.Config.KqProducerConf.TopicCommentVote,
voteEvent); err != nil {
logx.Errorf("发送投票事件消息失败: %v", err)
}
}()// 2. Consumer 消费消息落库
func (c *CommentConsumer) handleVoteEvent(event mq.VoteEvent) error {
// 数据库持久化投票记录
// 更新计数
}
方案B:定期对账
func reconcileVoteCounts() {
// 1. 扫描数据库最近1小时的投票记录
// 2. 与 Redis 中的计数对比
// 3. 不一致时以数据库为准
}方案C:降级处理
// 当前代码已实现降级
if err != nil {
logx.Errorf("执行投票Lua脚本失败: %v", err)
// 降级到数据库处理
return l.voteCommentDB(in)
}问题:游标分页 vs Offset 分页对比
问题 :看 comment 服务的分页实现:
-
为什么使用 cursor 分页而不是 offset?
-
这种实现有什么局限性?
-
如何支持跳转到第 N 页?
参考答案 :
-
Cursor 分页的优势
// GetCommentList 使用游标分页
func (l *GetCommentListLogic) GetCommentList(in *pb.GetCommentListReq) (*pb.GetCommentListResp, error) {
// 使用 ZRangeByScore 游标查询
maxScore := "+inf"
minScore := "-inf"
if cursor > 0 {
maxScore = fmt.Sprintf("(%d", cursor)
}idStrings, err := l.svcCtx.Redis.ZRevRangeByScore( ctx, key, minScore, maxScore, 0, pageSize+1)}
Cursor 分页优势 :
-
性能稳定 :OFFSET 会扫描前 N 行后丢弃,数据量大时很慢
-
一致性好 :不受数据插入删除影响
-
实现简单 :Redis ZSet 原生支持
Offset 分页问题 :
-- offset 分页的性能问题
SELECT * FROM comment LIMIT 1000000, 20;
-- 需要扫描并扔掉前 1000000 行- Cursor 分页的局限性 :
-
无法跳转到任意页 :只能翻前/翻后
-
不支持页码显示 :没有页码概念
-
删除的评论会导致结果重复或丢失
-
支持跳转到第 N 页的方案
// 方案A:混合方案
func getCommentListHybrid(in *pb.GetCommentListReq) (*pb.GetCommentListResp, error) {
if in.Cursor > 0 {
// 使用游标分页
return getCommentListByCursor(in)
}if in.Page > 0 && in.Page <= 10 { // 前10页支持 offset 分页,预加载 return getCommentListByOffset(in) } // 超过10页引导用户使用搜索 return nil, errors.New("请使用搜索或缩小范围")}
// 方案B:构建页码索引(适合静态内容)
func buildPageIndex(postID uint64, sortType string) {
// 预计算每页的第一个评论ID
key := buildCommentListKey(postID, sortType)
commentIDs, _ := redis.ZRange(ctx, key, 0, -1)for i := 0; i < len(commentIDs); i += pageSize { pageIndexKey := fmt.Sprintf("comment:page_index:%s:%s:%d", postID, sortType, i/pageSize + 1) redis.Set(ctx, pageIndexKey, commentIDs[i], 1*time.Hour) }}
问题 :
-
用户体验差 :删除成功但评论还在列表里(直到 Consumer 处理)
-
数据不一致 :数据库删除但缓存未清理干净
-
没有处理子回复 :子回复变成孤儿
- 子回复的处理策略 :
选项A:级联软删除 (推荐)
func deleteCommentWithReplies(commentID uint64) error {
// 找到所有子回复
var allReplyIDs []uint64
var queue = []uint64{commentID}
for len(queue) > 0 {
currentID := queue[0]
queue = queue[1:]
allReplyIDs = append(allReplyIDs, currentID)
var replies []*model.Comment
db.Where("parent_id = ? AND deleted_at IS NULL", currentID).Find(&replies)
for _, r := range replies {
queue = append(queue, r.ID)
}
}
// 批量软删除
now := time.Now()
db.Model(&model.Comment{}).Where("id IN ?", allReplyIDs).
Updates(map[string]interface{}{
"deleted_at": &now,
"status": 3,
})
// 批量清理缓存
for _, id := range allReplyIDs {
redis.Del(ctx, fmt.Sprintf("%s%d", redis.CommentInfoKey, id))
redis.Del(ctx, fmt.Sprintf("%s%d", redis.CommentContentKey, id))
}
}选项B:显示"已删除"占位符
// 不删除子回复,只标记父评论
// 前端显示:此评论已删除问题:评论限流与防刷机制
问题 :看投票逻辑中的限流:
-
当前的防刷机制够吗?
-
如何防止恶意刷赞?
-
如何实现基于 IP 和设备的复杂限流?
参考答案 :
-
当前实现分析
// votecommentlogic.go
date := time.Now().Format("20060102")
userVoteKey := fmt.Sprintf("%s%d:%s", redis.UserVoteCountKey, in.UserId, date)
voteCount, err := l.svcCtx.Redis.Incr(l.ctx, userVoteKey)
if err != nil {
logx.Errorf("用户投票计数失败: %v", err)
// 不影响主流程
} else {
// 设置过期时间
if voteCount == 1 {
l.svcCtx.Redis.Expire(l.ctx, userVoteKey, time.Hour*24)
}
// 每日最大 200 次
if voteCount > 200 {
return nil, errutil.RpcBusinessError(errutil.ErrTooManyRequests)
}
}
当前的不足 :
-
只限制了用户级别的频率
-
没有 IP 限制
-
没有设备指纹
-
没有异常行为检测
-
没有滑动窗口限流
-
恶意刷赞防护方案
// 多级限流
func checkRateLimit(userID uint64, commentID uint64, ip string) error {
ctx := context.Background()// 1. 同一用户对同一评论限制 key1 := fmt.Sprintf("vote:limit:user:%d:%d", userID, commentID) if cnt, _ := redis.Incr(ctx, key1); cnt > 1 { return errors.New("不能重复投票") } redis.Expire(ctx, key1, 24*time.Hour) // 2. 用户频率限制(滑动窗口) key2 := fmt.Sprintf("vote:limit:user:%d", userID) now := time.Now().Unix() redis.ZAdd(ctx, key2, redis.Z{Score: float64(now), Member: strconv.FormatInt(now, 10)}) redis.ZRemRangeByScore(ctx, key2, "0", fmt.Sprintf("%d", now-3600)) // 只保留1小时内 if cnt, _ := redis.ZCard(ctx, key2); cnt > 100 { return errors.New("投票太频繁") } redis.Expire(ctx, key2, 2*time.Hour) // 3. IP 限制 key3 := fmt.Sprintf("vote:limit:ip:%s", ip) if cnt, _ := redis.Incr(ctx, key3); cnt > 500 { return errors.New("IP 受限") } redis.Expire(ctx, key3, time.Hour) // 4. 同一评论短时间内大量投票 key4 := fmt.Sprintf("vote:limit:comment:%d", commentID) windowStart := now - 60 // 1分钟窗口 redis.ZAdd(ctx, key4, redis.Z{Score: float64(now), Member: strconv.FormatUint(userID, 10)}) redis.ZRemRangeByScore(ctx, key4, "0", fmt.Sprintf("%d", windowStart)) if cnt, _ := redis.ZCard(ctx, key4); cnt > 50 { return errors.New("评论投票异常") } redis.Expire(ctx, key4, 5*time.Minute) return nil}
-
高级异常行为检测
func detectAbnormalBehavior(userID uint64) {
// 1. 检查用户是否在短时间内对大量不同评论投票
recentVotes := getRecentVotes(userID, time.Hour)
if len(recentVotes) > 200 {
flagUser(userID, "high_frequency_voter")
}// 2. 检查用户投票模式是否异常(只点赞,或只点踩) likeRatio := calculateLikeRatio(recentVotes) if likeRatio > 0.95 || likeRatio < 0.05 { flagUser(userID, "suspicious_voting_pattern") } // 3. 检查新账号异常活跃 userProfile := getUserProfile(userID) if userProfile.CreatedAt.After(time.Now().Add(-24*time.Hour)) && len(recentVotes) > 50 { flagUser(userID, "new_account_abnormal_activity") }}
问题:评论排序热更新问题
问题 :当一个评论的点赞数变化后,如何更新 Redis 中的排序?
-
当前实现如何处理?
-
有什么更高效的方案?
-
如何防止排序抖动?
参考答案 :
- 当前实现分析
当前代码中,投票后只是让缓存失效:
invalidatePostCommentListCache(l.ctx, l.svcCtx, comment.PostID)这种做法的问题:
-
缓存雪崩风险 :频繁失效缓存会大量查询数据库
-
性能差 :每次点赞都可能触发重建
-
用户体验差 :排序更新不及时
-
高效实时排序更新方案
func updateCommentScoreRealTime(postID uint64, commentID uint64, deltaLikes int32) {
ctx := context.Background()
key := fmt.Sprintf("%s%d:hot", redis.PostCommentsKey, postID)// 1. 获取评论当前信息 info, err := redis.HGetAll(ctx, fmt.Sprintf("%s%d", redis.CommentInfoKey, commentID)).Result() if err != nil || len(info) == 0 { return // 缓存未命中,等待重建 } // 2. 计算新分数 likeCount, _ := strconv.Atoi(info["like_count"]) replyCount, _ := strconv.Atoi(info["reply_count"]) createdAt, _ := strconv.ParseInt(info["created_at"], 10, 64) // 新分数(包含 delta) newScore := float64((likeCount+int(deltaLikes)) + replyCount*3) newScore -= float64(time.Now().Unix()-createdAt) / 3600 // 3. 更新分数 redis.ZAdd(ctx, key, redis.Z{Score: newScore, Member: commentID}) // 4. 同时更新 info 缓存 redis.HIncrBy(ctx, fmt.Sprintf("%s%d", redis.CommentInfoKey, commentID), "like_count", int64(deltaLikes))}
-
防止排序抖动
// 方案A:延迟更新 + 批量合并
type pendingScoreUpdate struct {
commentID uint64
delta int32
}var pendingUpdates = make(chan pendingScoreUpdate, 1000)
func batchUpdateScores() {
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()buffer := make(map[uint64]int32) for { select { case update := <-pendingUpdates: buffer[update.commentID] += update.delta // 缓冲区满或到时间,批量刷新 if len(buffer) >= 100 { flushBuffer(buffer) buffer = make(map[uint64]int32) } case <-ticker.C: if len(buffer) > 0 { flushBuffer(buffer) buffer = make(map[uint64]int32) } } }}
func flushBuffer(buffer map[uint64]int32) {
// 按帖子分组,批量更新
posts := groupByPost(buffer)
for postID, comments := range posts {
updatePostScores(postID, comments)
}
}// 方案B:阈值更新(只有变化足够大时才重新排序)
func shouldUpdateScore(oldLikeCount int32, newLikeCount int32) bool {
threshold := 0.1 // 10%的变化
if oldLikeCount == 0 {
return newLikeCount > 0
}
change := math.Abs(float64(newLikeCount-oldLikeCount)) / float64(oldLikeCount)
return change > threshold
}
relation服务
关注一个人但是同时他注销了怎么办?