本周三件事值得聊。OpenAI 发布 GPT Image 2,推理模式让 AI 先"想"再画;GPT-5.5 智能体登顶但编程被 Claude 压制,模型开始"偏科";国产大模型 5 天密集发布 5 款旗舰。
一、GPT Image 2: AI 画图终于会"思考"了
OpenAI 发布 GPT Image 2,中文文字渲染准确率 99%+,推理模式让 AI 先"想"再画
4 月 21 日,OpenAI 正式发布 GPT Image 2,面向所有 ChatGPT 用户开放。最大突破:中文文字渲染从"一眼假"进化到"基本能用",准确率达 99% 以上;付费用户可启用 Thinking 推理模式,模型会先推理布局、调用网络搜索、分析素材再生成,一次可产出多张保持一致性的连续图像。全面超越此前标杆 Nano Banana Pro(Gemini 3 Pro Image)
个人点评:
我自己试了,提示词都简简单单,但效果震撼(可以参考我前面的文章)。嗯,很多设计师,可以下岗了。
二、GPT-5.5:智能体登顶,但编程不敌 Claude
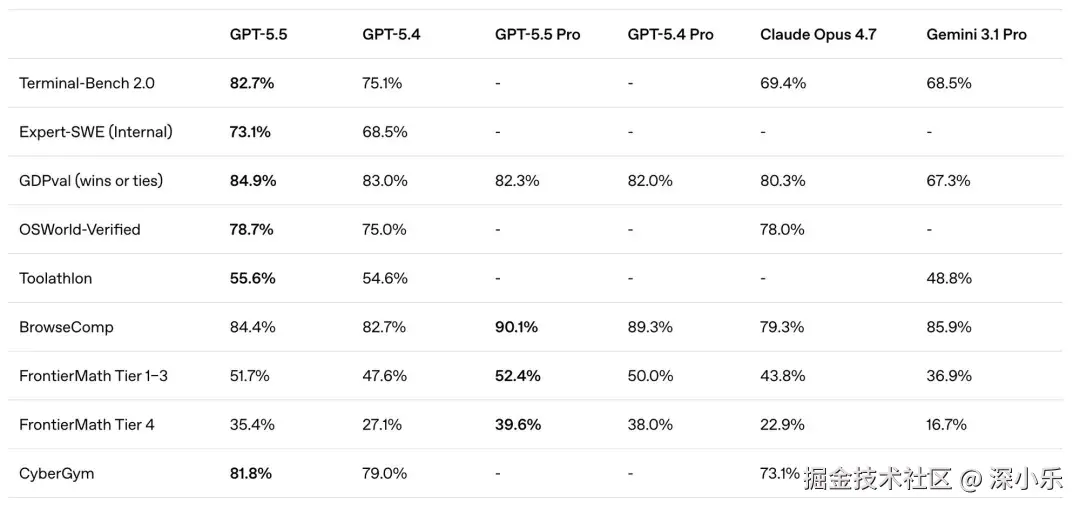
OpenAI 发布 GPT-5.5,智能体能力全面领先,但 SWE-Bench 被 Claude Opus 4.7 压制 6 个百分点
4 月 23 日,OpenAI 发布 GPT-5.5,这是自 GPT-4.5 以来首个完全重训的基座模型。核心亮点:Terminal-Bench 2.0 复杂命令行任务准确率 82.7%,领先 Claude Opus 4.7 13 个百分点;GDPval 知识工作任务胜率 84.9%, OSWorld 计算机环境操作准确率 78.7%,智能体能力全面登顶。
但并非全面碾压。在最接近"修复真实 GitHub issue"的 SWE-Bench Pro 测试中,GPT-5.5 得分 58.6%,被 Claude Opus 4.7 的 64.3% 压制;多语言问答(MMMLU)仅 83.2%,远低于 Claude 的 91.5% 和 Gemini 的 92.6%。定价为 30 per M token,是 GPT-5.4 的两倍,但因 token 消耗减少 40%,实际成本接近。
个人点评:
Agent 自主执行有进步,啥时候 Code 能力,能真正追上 Claude 呢?
三、国产大模型集体爆发:5 天 5 款旗舰

月之暗面、阿里、小米、腾讯、DeepSeek 五天内密集发布,国产大模型进入"闪电战"节奏
本周国产大模型迎来史无前例的密集发布潮。4 月 20 日,月之暗面发布 Kimi K2.6,长程编码能力不间断 13 小时、编写 4000+ 行代码;同日阿里发布 Qwen3.6-Max-Preview,Code Arena 编程盲测全球第二。4 月 23 日,小米 MiMo-V2.5-Pro 发布,距上代仅 36 天;同日腾讯发布混元 Hy3 preview,前 OpenAI 核心研究员姚顺雨加盟后首作,三个月完成重建。4 月 24 日,DeepSeek-V4 压轴登场,百万字上下文、全面开源。
个人点评:
本周啥日子,这么热闹。AI 这是要开始加速度了?可以开始左脚踩右脚了?