建议:本题又进阶了,自己先去独立做一做,然后在看题解,对代码技巧会有很深的体会。
题目链接:https://leetcode.cn/problems/reverse-string-ii/ 视频链接:https://www.bilibili.com/video/BV1dT411j7NN
一、看到题目的第一想法
- 题目要求理解 :给定一个字符串
s和整数k,规则是:- 每计数
2k个字符,就反转前k个字符; - 如果剩余字符少于
k个,则全部反转; - 如果剩余字符大于等于
k但小于2k个,则反转前k个字符。
- 每计数
- 核心思路 :直接按题目规则,用一个步长为
2k的循环来遍历字符串。每次循环里,反转当前区间内的前k个字符,同时用min()函数处理字符串末尾不足k个字符的情况,避免越界。 - 初步实现念头 :
- 用
for (int i = 0; i < n; i += 2*k)作为外层循环,每次跳2k步。 - 反转区间是
[i, i+k),但要注意末尾的边界,所以结束位置用min(i + k, n)来保证不超出字符串长度。 - 直接调用 C++ 标准库的
reverse()函数来完成局部反转,简化代码。
- 用
二、实现过程中遇到的困难
- 边界条件的处理
- 一开始没考虑字符串末尾不足
k个字符的情况,直接写了s.begin() + i + k,导致下标越界报错。后来才想到用min(i + k, n)来动态调整反转的结束位置,适配剩余字符数不足k的场景。 - 步长的控制也容易出错:一开始错误地写成
i += k,导致重复反转或反转顺序错乱,后来才反应过来,题目是每2k个字符为一组处理,步长应该是2*k。
- 一开始没考虑字符串末尾不足
reverse()函数的使用细节- 一开始对
reverse()的区间规则不熟悉:reverse(first, last)反转的是[first, last)左闭右开区间,所以结束迭代器应该指向 "要反转的最后一个字符的下一个位置"。 - 错误地把结束迭代器写成了
s.begin() + min(i + k, n) - 1,导致反转少了一个字符,后来才纠正过来。
- 一开始对
- 对题目规则的理解偏差
- 一开始误以为 "剩余字符少于
2k个时,反转所有剩余字符",忽略了题目中 "剩余字符大于等于k时,只反转前k个" 的规则,导致部分测试用例不通过。
- 一开始误以为 "剩余字符少于
- 字符串长度为 0 或 1 的特殊情况
- 一开始没考虑
s为空或长度小于k的情况,后来发现min(i + k, n)和循环条件i < n天然处理了这些情况,不需要额外写if判断。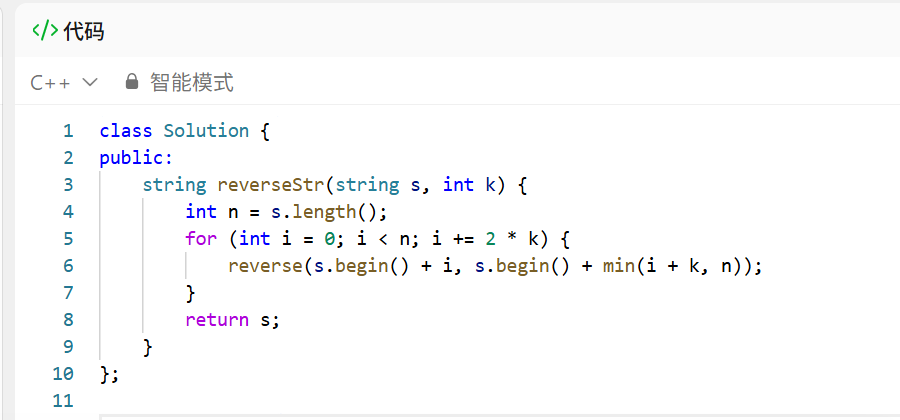
- 一开始没考虑
三、今日收获心得
- 对 "分段处理" 思想的掌握 这道题让我学会了如何按固定步长对字符串进行分段处理,通过
i += 2*k的循环,把字符串拆成多个2k长度的片段,再对每个片段的前k个字符反转,这种思路可以推广到很多字符串分段操作的问题中。 std::reverse与迭代器的灵活使用- 彻底搞懂了
reverse()函数的左闭右开区间规则,学会了用s.begin() + i这样的迭代器来定位字符串的任意位置,实现局部反转。 - 也理解了
min()函数在边界处理中的妙用,它能优雅地解决 "剩余字符不足 k" 的问题,避免了大量if-else判断,让代码更简洁。
- 彻底搞懂了
- 对题目规则的严谨理解 这道题的规则有多个分支(大于等于 2k、大于等于 k 小于 2k、小于 k),但通过步长控制和
min()函数,可以把所有分支用同一段代码处理,让我意识到:写代码前一定要把规则拆解得足够清晰,才能找到通用的解法。 - 代码简洁性与鲁棒性的提升 原来以为要写很多条件判断的逻辑,用步长循环和
min()函数就能一行搞定,既减少了冗余代码,也降低了出错概率。同时也体会到了 C++ 标准库函数在处理这类问题时的便利性。 - 对时间复杂度的理解加深整个算法的时间复杂度是 \(O(n)\),每个字符最多被反转一次,循环和反转的操作都是线性的,没有多余的嵌套循环,这让我更理解了 "局部反转" 类问题的时间复杂度优化思路。